Best Practices for Data Versioning for Building Successful ML Models

Data overload is a significant problem for business leaders in the current information age. According to Forbes, 90% of the data is unstructured, making it more challenging for companies to analyze and derive insights from the data they collect.
This poses a significant issue for organizations that use artificial intelligence (AI) and machine learning (ML) to power their operations and products. Robust AI applications require high-quality data to deliver accurate results. However, the inability to analyze data hinders developers from implementing the right AI solutions.
Data versioning is one way to address these concerns. It optimizes management and analysis by tracking and recording changes in data over time.
In this post, we will discuss data versioning’s significance, challenges, best practices, and how you can use Encord to streamline your versioning pipeline.
Why is Data Versioning in ML Important?
Data versioning is a key element of effective ML and data science workflows. It ensures data remains organized, accessible, and reliable throughout the project lifecycle.
It helps maintain consistency and reproducibility by preserving records of dataset versions. The approach allows team members to recreate experiments and enhance machine learning models.
In addition, the practice facilitates efficient data management by tracking changes and organizing data systematically. The approach boosts data quality for training models and helps debug modeling issues.
Versioning also improves compliance by maintaining audit trails critical for meeting regulatory standards. Lastly, it supports performance tracking by linking specific datasets to model outputs and offers insights into how data changes affect results.
Challenges of Data Versioning
Implementing data versioning requires extensive expertise in data engineering, data modeling, and involvement from multiple stakeholders. To address these challenges efficiently, many organizations consider outsourcing development, enabling them to leverage specialized expertise and streamline the implementation process. The list below mentions some issues data scientists may encounter when developing a scalable data version control system.
- Limited Storage: Versioning large datasets can quickly consume significant storage space, especially with frequent updates or high-volume data. Managing storage efficiently without sacrificing access to older versions can be costly and technically demanding.
- Data Management Complexity: Organizing multiple versions of datasets, associated metadata, and preprocessing scripts can overburden the infrastructure. Developers must manage dependencies between different versions of data and code carefully to avoid errors or mismatches that could compromise model performance.
- Security: Ensuring the security of stored data versions is an additional challenge, particularly for sensitive or regulated datasets. As new versions emerge, maintaining robust access controls and complying with data privacy laws becomes more complex.
- Tool Integration: Many open-source version control tools may fail to handle large, unstructured datasets. Organizations must look for specialized platforms with relevant functionality for their use case. However, integrating specialized data versioning tools into existing ML pipelines and workflows can require additional expertise and effort.
- Collaboration and Coordination: Managing parallel dataset changes can lead to conflicts in team settings. Effective collaboration requires clear policies and tools to handle concurrent modifications and ensure that each version of the data is consistent and accurate.
Data Versioning Approaches
Organizations can overcome the challenges mentioned above by using different versioning approaches. The most common methods include:
- Data Duplication: Duplication is a straightforward technique that creates multiple copies of a dataset on a different machine. Users can preserve the original version in one location and make changes in another.

The approach works for small datasets, as duplicating large data volumes can occupy significant space.
- Metadata: Users can add timestamps to the existing schema, indicating the duration for which each version was relevant and active.
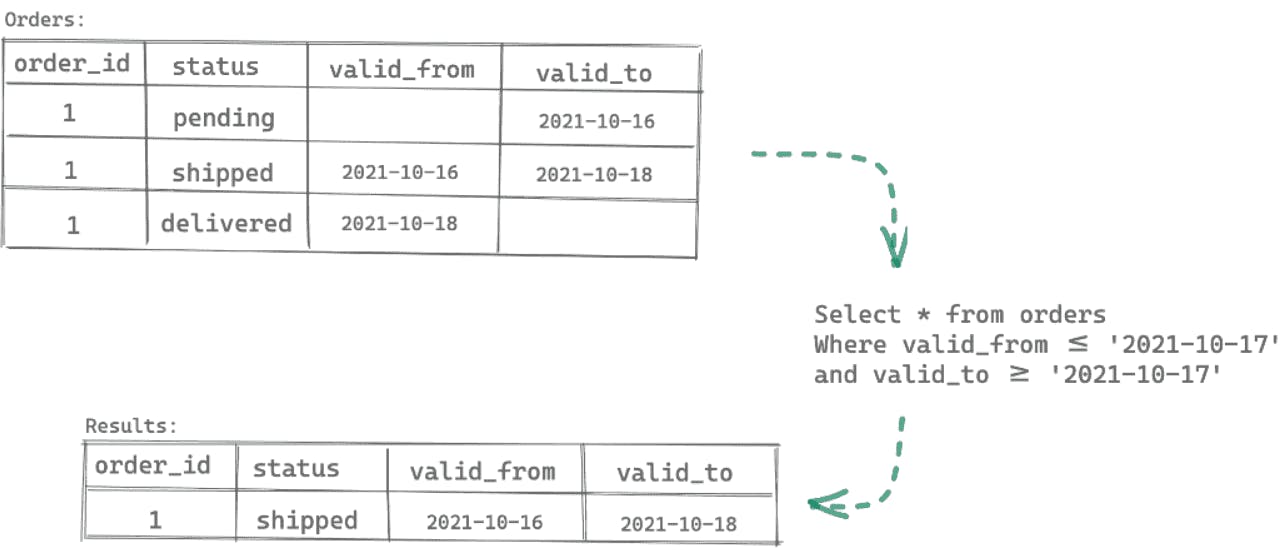
Including such metadata helps organizations time travel and quickly compare current and previous versions. However, as data size grows, space limitations can cause inefficiencies.
- Full Data Version Control: Organizations build a sustainable versioning solution as part of the native data environment using this method.

Full control includes associating data changes with the codebase and adding version numbers whenever modifications occur. It is compatible with all data structures and sizes and updates versions in real-time.
Data Versioning Best Practices
Organizations can address versioning challenges by implementing standardized procedures for creating, managing, and archiving dataset versions. While specific workflows may vary depending on the use case, adopting key best practices can enhance versioning efficiency and reliability.
The following sections outline practical tips to optimize data versioning processes across diverse applications.
1. Define the Scope and Granularity
Defining the scope and granularity is a foundational step in effective data versioning. Start by identifying which datasets need versioning and focus on the parts most critical to your ML workflow.
Granularity will determine how you track changes. Versioning every minor update ensures detailed traceability but can be resource-intensive. On the other hand, major-change versioning simplifies management but risks overlooking important updates.
Align granularity to project requirements to balance detail with practicality. Document the rationale behind versioning decisions to maintain consistency across teams. This will ensure all stakeholders understand the scope and level of detail in the versioning process.
2. Define and Track your Data Repositories
A data repository is a centralized system for storing and managing datasets. It allows you to organize, access, and track all relevant data. You must structure your repositories with clear directory hierarchies to reflect dataset versions, sources, or processing stages.
Organize datasets based on their specific functions to ensure clarity and prevent confusion. For example, store sales data in a dedicated directory and keep datasets for building ML models in another. Link your repositories directly to ML pipelines to streamline workflows. This integration automates the process, associating each ML experiment with its corresponding dataset.
Also, you must regularly audit repositories to remove redundant or outdated versions while retaining essential ones. A systematic approach ensures data consistency, improves collaboration, and simplifies navigating large, evolving datasets.
3. Commit Changes for Easy Time-traveling
In a robust version control system, commits are snapshots of the dataset at a specific point in time. They enable you to revert to earlier versions, compare changes, or troubleshoot issues.
Regularly committing changes is essential for effective data versioning, as it allows for easy "time-traveling" through dataset versions.
It is advisable to use descriptive commit messages to document what changed and why. This will make it easier to track updates. Plus, committing changes regularly helps maintain data traceability and reproducibility.
4. Integrate Versioning with Experiment Tracking Systems
Experiment tracking systems are tools or platforms designed to record, organize, and manage all aspects of ML experiments. These systems track key components such as datasets, model configurations, hyperparameters, code versions, training metrics, and outcomes.
They centralize information and help teams analyze experiment results, compare run performance, and reproduce workflows. Integrating data versioning with such systems ensures seamless coordination between datasets and ML workflows.
It also enhances efficiency in collaborative projects and prevents duplication of the same datasets. Additionally, it helps maintain a clear audit trail, streamlines debugging, and enables team members to identify which changes led to model performance improvements.
5. Data Version Branching and Merging
In data versioning, a user can create a branch of a primary dataset and implement changes in the branched version instead of changing the original one.
Branching is crucial for managing complex datasets in ML projects, primarily when multiple team members work on the same dataset. It allows you to create separate versions of data to experiment with different preprocessing steps, feature engineering methods, or model configurations.
This helps in testing variations without affecting the primary dataset. It also allows you to create isolated test environments for experimenting with new data.
Merging occurs when users want to integrate the branches with the main version. During a merge, a commit is created on the target branch to combine all the changes from the forked branches, ensuring no conflicts exist. This process keeps the original versions intact, and external users only see the changes after you merge the branch.
6. Automating the Versioning Process
You can automate versioning by implementing validation checks before and after specific events in the development lifecycle. For example, Git lets you use Git hooks, which are shell scripts that run only when you trigger particular events.
For instance, you can configure automated scripts to run whenever you trigger a commit. These scripts can validate the changes in the branch you are trying to merge with the main branch. They can check data integrity, verify preprocessing steps, and run tests to ensure the data does not introduce errors or inconsistencies.
If the script detects an issue, it halts the commit process, preventing the main branch from becoming corrupted. This approach helps maintain the integrity of the primary dataset and ensures you only merge validated, error-free versions.
7. Defining Data Disposal Policies
Defining data disposal policies is essential for maintaining data security and compliance in versioning workflows. Establish clear guidelines on when and how users should delete or archive outdated or unnecessary dataset versions.
Specify retention periods based on project requirements or regulatory standards to ensure that you keep the data as long as necessary. Also, automate data disposal processes where possible, using tools to safely remove obsolete versions. This practice reduces storage costs, minimizes data clutter, and prevents unauthorized access to outdated data.
8. Naming Conventions and Metadata Standards
Naming conventions should be clear, descriptive, and standardized. They should reflect the dataset's content, version, and update date. Following this practice ensures easy identification and retrieval of datasets.
Metadata standards should document key information such as the data source, preprocessing steps, transformations, and model dependencies. To provide full traceability, you must Include version numbers, data lineage, and change logs.
Standardizing naming and metadata practices improves data organization, enhances collaboration, and ensures team members can easily access, understand, and reproduce experiments.
9. Ensuring Data Privacy
Ensuring data privacy is crucial to preventing security breaches when handling sensitive information. Implement strict access controls using role-based permissions to restrict who can view or modify specific data versions.
Use encryption methods to protect data at rest and in transit, protecting it from unauthorized access. Regularly audit data versions to ensure they meet privacy regulations and apply data anonymization or de-identification techniques when needed to reduce privacy risks.
10. Selecting the Versioning Tool
You must choose an appropriate versioning tool that aligns with your data and project requirements. Consider factors such as the size of your datasets, team collaboration needs, and integration with existing tools.
Evaluate features such as automated version control, branching and merging support, and compatibility with cloud storage. Additionally, carefully weigh the costs and benefits of building an in-house versioning tool versus investing in a third-party solution.
If you choose a third-party tool, ensure the vendor is reliable, understands the specific needs of your data, and offers strong customer support. It is also essential to assess whether the tool is user-friendly and has an active community that provides support to help you quickly get up to speed.
Data Versioning using Encord
As organizations accumulate more data, they must seek scalable versioning tools capable of handling diverse data types and structures. While businesses can build custom solutions, this approach requires significant expertise and resources.
Moreover, the final product may lack the essential features needed to manage datasets' evolving nature effectively.
Alternatively, businesses can use specialized third-party platforms that provide comprehensive versioning and robust data management features to optimize the entire data lifecycle. One such solution is Encord, which enables efficient versioning and curation of large, unstructured datasets to meet your growing data needs.
Encord is an end-to-end AI-based multimodal data management platform that helps you curate, annotate, version, and validate data for ML models. It supports image, video, audio, and text data types and offers multiple metrics to assess data quality.

Encord Natural Language Search Feature
Key Features
- Version Large Datasets: Encord helps you version and explore extensive datasets through metadata-based granular filtering and natural language search features. It can handle various data types and organize them according to their contents.
- Data Annotation and Collections: The platform lets you annotate and classify multimodal (video, image, audio, text, document, DICOM) data with Encord agents, allowing you to customize labeling workflows according to your use case. You can also create data collections for each project by defining collection tags according to your data type.
- Data Security: The platform is compliant with major regulatory frameworks, such as the General Data Protection Regulation (GDPR), System and Organization Controls 2 (SOC 2 Type 1), AICPA SOC, and Health Insurance Portability and Accountability Act (HIPAA) standards. It also uses advanced encryption protocols to protect data privacy.
- Integrations: Encord supports integration with mainstream cloud storage platforms such as AWS, Microsoft Azure, and Google Cloud. You can also manage workflows programmatically using its Python SDK.
G2 Review
Encord has a rating of 4.8/5 based on 60 reviews. Users highlight the tool’s simplicity, intuitive interface, and several annotation options as its most significant benefits.
However, they suggest a few areas for improvement, including more customization options for tool settings and faster model-assisted labeling.
Overall, Encord’s ease of setup and quick return on investments make it popular among AI experts.
Data Versioning: Key Takeaways
Versioning datasets is no longer an optional activity. With increasing data complexity and usage, businesses must embed versioning systems within the development framework to maintain data integrity.
Below are a few key points regarding data versioning.
- Importance of Data Versioning: Versioning allows organizations to optimize data management, traceability, and reproducibility. The technique helps streamline model experimentation and debugging.
- Data Versioning Challenges: Storage limitations and the complexity of managing large datasets make versioning challenging. Ensuring data privacy, integration with existing systems, and data integrity during team collaboration further complicates the process.
- Encord for Data Versioning: Encord is a robust data management solution that lets you version, annotate, and curate large datasets for scalable ML models.
Frequently asked questions
Data versioning tracks and manages changes to datasets over time. It helps ensure data consistency, reproducibility, and traceability.
You can start implementing versioning in data by selecting a data repository and using versioning tools to commit data changes with clear naming conventions and metadata.
Data versioning tracks changes in datasets, while model versioning focuses on tracking changes in machine learning models.
Best practices for versioning data in a data engineering pipeline include defining data repositories, maintaining clear naming conventions, committing changes regularly, automating versioning, and integrating with experiment tracking systems.
Data versioning challenges include storage limitations, data complexity, privacy concerns, and integration issues. Scalable tools, robust access controls, and reliable versioning tools can mitigate these issues.
Data annotators using Encord log their annotations directly within the platform, which integrates seamlessly with project management. This process alleviates the need for manual input into spreadsheets, as the platform tracks time spent and output metrics automatically.
Encord includes robust version control features that help manage data changes throughout the AI development process. This ensures that users can track different versions of their datasets and models, maintaining organization and consistency across projects.
Encord streamlines workflows by providing comprehensive versioning capabilities and robust cloud support for data annotation. This ensures that teams can easily manage and access their data across different projects, enhancing collaboration and efficiency.
Encord includes a curation module that allows users to manage datasets effectively. Users can organize, clean, and version datasets by excluding duplicates and lower quality images, while also creating collections to streamline the annotation workflow.
Encord helps manage annotation workload by allowing users to create and prioritize datasets based on the availability of data. This ensures that teams can effectively allocate resources and focus on annotation tasks as data becomes available.
Encord provides robust tools for managing and curating large-scale data sets, allowing users to efficiently organize and update metadata. This is crucial for teams looking to optimize their data pipelines as they scale towards production.
Encord allows bulk editing for classifications that you want to change or validate, such as radio type selections. However, authoritative metadata, like location and date, cannot be updated in bulk once set.
Encord offers built-in tools for data splitting and versioning, enabling users to create different splits of their datasets or apply random splits based on their project needs.
No, Encord does not clone or copy data. Instead, assets remain linked to the original files in cloud storage, ensuring no duplication occurs and maintaining data integrity.