What is One-Shot Learning in Computer Vision

ML Lead at Encord
In some situations, machine learning (ML) or computer vision (CV) models don’t have vast amounts of data to compare what they’re seeing. Instead, a deep learning network has one attempt to verify the data they’re presented with; this is known as one-shot learning.
Automated passport scanners, turnstiles, and signature verifications limit what an algorithmic model can compare an object against, such as a single passport photo for one individual. Image detection scanners and the computer vision models behind them have one shot at verifying the data they’re being presented with. Hence the value of one-shot learning for face recognition.
This glossary post explains one-shot learning in more detail, including how it works and some real-world use cases.

What Is One-Shot Learning in AI?
One-shot learning is a machine learning-based (ML) algorithm that compares the similarities and differences between two images. The goal is simple: verify or reject the data being scanned. In human terms, it’s a computer vision approach for answering one question, is this person who they claim to be?
Unlike traditional computer vision projects, where models are trained on thousands of images or videos or detect objects from one frame to the next, one-shot classification operates using a limited amount of training set data to compare images against.
In many ways, one-shot algorithms are simpler than most computer vision models. However, other computer visions and ML models are given access to vast training set databases to improve accuracy and training outputs in comparison to one-shot or few-shot learning algorithms.
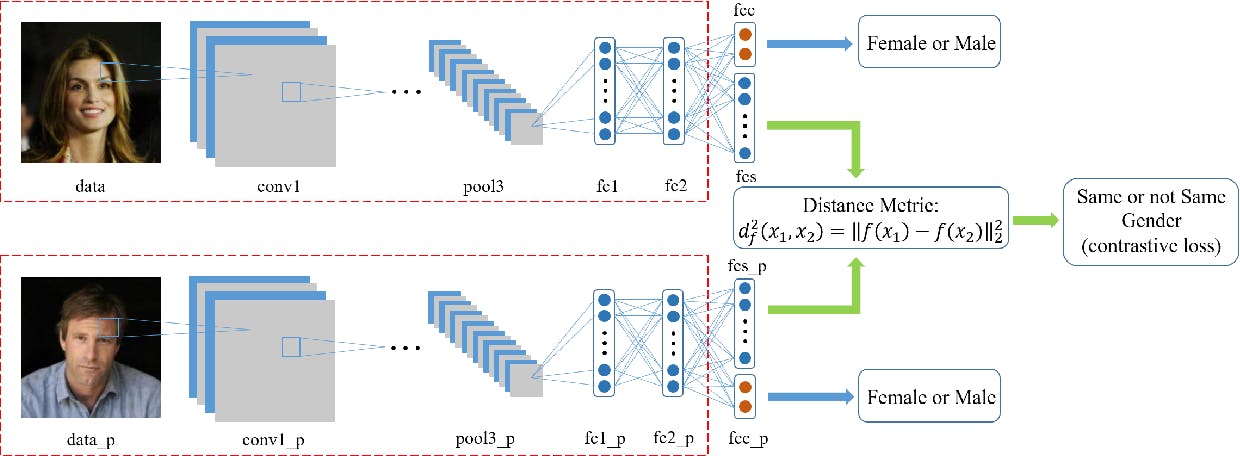
One shot learning using FaceNet. Source
One-Shot Learning in Context: N-Shot Learning
In computer vision, a “shot” is the amount of data a model is given to solve a one-shot learning problem. In most cases, computer vision and any type of algorithmic model are fed vast amounts of data to train, learn from, and generate accurate outputs.
Similar to unsupervised or self-supervised learning, n-shot is when a model is trained on a scarce or very limited amount of data.
N-shot is a sliding scale, from zero examples (hence, zero-shot) up to few-shot; no more than 5 examples to train a model on. One-shot is when a model only has one example to learn from and make a decision on: E.g. when a passport scanner sees the image on a passport, it has to answer one question: “Is this image the same as the image in the corresponding database?”
N-shot learning (and every approach on this sliding scale; zero, one, or few-shot) is when a deep learning model with millions or billions of parameters is trained to deliver outputs, usually in real-time, with a limited amount of training examples.
 In N-shot learning, we have:
In N-shot learning, we have: N = labeled examples of;
K = each class (N∗K)
For every K, there is an example in the Support Set: S
Plus, there’s a Query Set: Q
One-Shot vs. Few-Shot Learning
Few-shot learning is one of the subsets of N-shot learning and is similar to few-shot with one key difference. Few-shot means a deep learning or machine learning model has more than one image to make a comparison against instead of only one image; hence that approach is one-shot.
Few-shot learning works the same way as one-shot, using deep learning networks and training examples to produce accurate outputs from a limited amount of comparative images. Few-shot can be trained on anywhere from two to five images. It still operates as a comparison-based approach, except the CV model making the comparison has access to slightly more data.
The few-shot learning concept was first introduced in 2019 at the Conference on Computer Vision and Pattern Recognition with the following paper: Meta-Transfer Learning for Few-Shot Learning.
This state-of-the-art data science research paved the way for new meta-learning transfer and training methods for deep neural networks. With these, Prototypical Networks are combined with the most popular deep learning models to generate impressive results quickly.
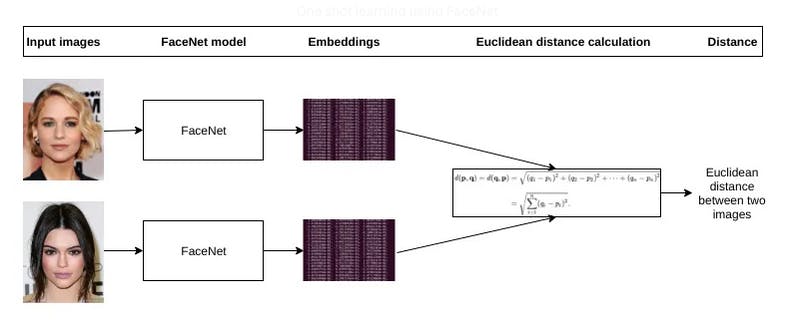
Euclidean distance calculation for one shot learning using FaceNet. Source
One-Shot vs. Zero-Shot Learning
One-shot is when a deep learning model is given one image to make a split-second decision on: a yes or no answer, in most cases.
As explained above, few-shot involves a slightly wider range of images, anywhere from two to five.
Zero-shot is when a model is expected to categorize unknown classes without any training data. In this case, we are asking a deep learning model to make a cognitive leap based on the metadata description of images. Imagine you’d never seen a lion in real life, online, in a book, or on TV. Someone describes a lion to you and then drops you in a nature reserve. Do you think you’d spot a lion compared to all of the other animals in the reserve?
That’s the same for zero-shot learning. Providing algorithmic models are trained on enough descriptions, then zero-shot is an effective method when data is scarce.
One-Shot vs. Less Than One-Shot Learning
Less than one-shot is another version of one-shot, similar to zero-shot whereby: “models must learn N new classes given only M < < N examples, and we show that this is achievable with the help of soft labels. We use a soft-label generalization of the k-Nearest Neighbors classifier to explore the intricate decision landscapes that can be created in the “less than one”-shot learning to set. We analyze these decision landscapes to derive theoretical lower bounds for separating N classes using M < N soft-label samples and investigate the robustness of the resulting systems.”
Image-based datasets for this approach are given soft labels, and then deep neural networks are trained on these descriptions to produce accurate outcomes.
For more information, it’s worth referencing the 2020 MIT researchers Ilia Sucholutsky and Matthias Schonlau's paper. How Does One-Shot Learning Work?
Unlike other, more complex computer vision models, one-shot learning isn’t about classification, identifying objects, or anything more involved.
One-shot learning is a computer vision-driven comparison exercise. Therefore, the problem is simply about verifying or rejecting whether an image (or anything else being presented) matches the same image in a database.
A neural network or computer vision model matches and compares the two data points, generating only one of two answers, yes or no.

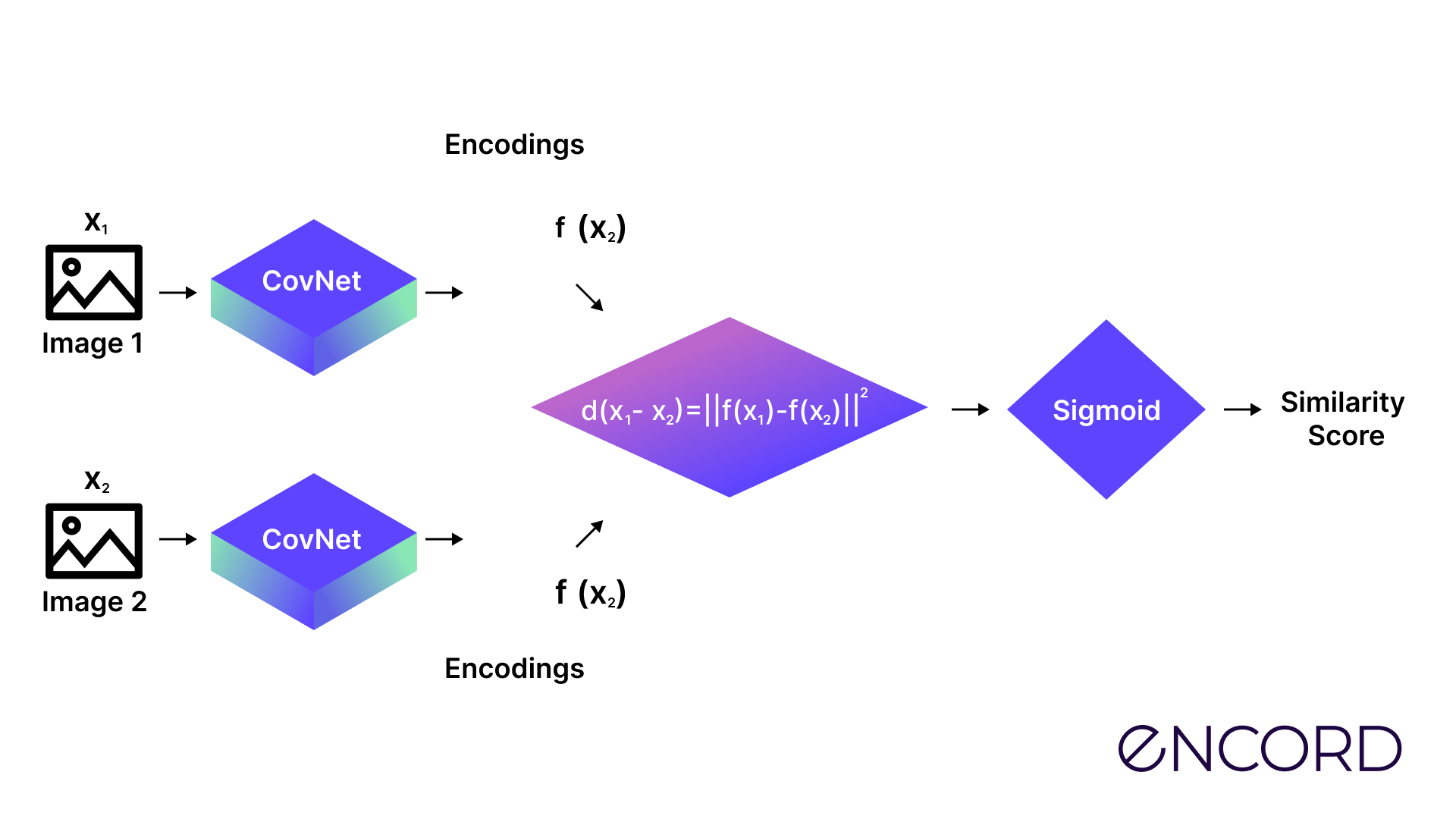
Siamese Neural Networks (SNNs) for one-shot learning
Generating that answer involves using a version of convolutional neural networks (CNNs) known as Siamese Neural Networks (SNNs). Training these models involves a verification and generalization stage so that the algorithms can make positive or negative verifications in real-world use cases in seconds.
Like Siamese cats or genetic twins, there are two identical networks that two identical instances are run through, with a dense layer using one Sigmoind score to produce a similarity score between 0 and 1 as their output function.
Training an SNN model involves putting datasets through verification and generalization stages. At the generalization stage, a triplet loss function is used for one-shot learning, where the model is given a positive, anchor, and negative image. The positive and anchor images are similar, and the negative is sufficiently different to help the model achieve better results. It’s important that the anchor and positive images are sufficiently similar so it won’t stumble in a real-world setting.

Advantages of SNNs for one-shot learning
The advantages of using SNNs compared to other convolutional neural networks:
- SNNs have been proven to outperform other neural networks when being trained to identify faces, objects, and other images.
- SNNs can be trained on vast datasets but equally can cope with limited datasets and don’t need a significant amount of re-training on new image classes.
- Both networks share the same parameters, improving generalization performance when images are similar but not identical.
Challenges of SNNs for one-shot learning
One of the main challenges is there’s significantly more computational power and memory required because SNNs involve an exact duplication of processing requirements for the training and validation stages.

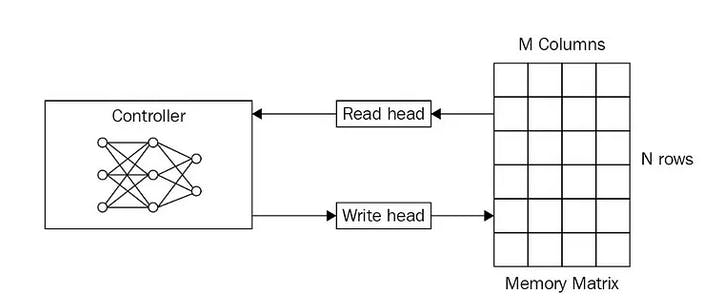
Memory-Augmented Neural Networks (MANNs) for one-shot learning
Memory-Augmented Neural Networks (MANN) are a type of recurrent neural network (RNN) based on a neural Turing machine (NTM) model. Unlike convolutional neural networks, which have layers, MANNs, and other NTM-based models are built using sequences.
Within these networks are memory layers so that input images from training datasets are stored, ready to solve the next stage of the learning problem. MANNs learn fast, have demonstrated positive generalization abilities, and are another way to implement one-shot, zero, and few-shot learning.
Use Cases of One-Shot and Few-Shot Learning in Computer Vision
One-shot and few-shot computer vision algorithms and models are mainly used in image classification, object detection, facial recognition, comparisons, localizations, and speech recognition.
Real-world use cases involve face and signature recognition and verification. Such as airport passport scanners or law enforcement surveillance cameras, scanning for potential terrorists in crowded public places.
Banks and other secure institutions (including government, security, intelligence, and military) use this approach to verify ID or biometric scans against the copy stored in their databases. As do hotels, to ensure keycards only open the door to the assigned room.
One-shot and few-shot learning is also used for signature verification. Plus, one-shot learning is integrated into drone and self-driving car technology, helping more complex algorithms detect objects in the environment. It’s also helpful when using neural networks during automated translations.
One-Shot Learning Key Takeaways
One-shot, few, and zero-shot learning is an effective way to use CNNs and other deep learning networks to train models on a limited amount of data so they can make rapid decisions based on the similarity between images.
Algorithmic models aren’t being asked to compare a large number of features or objects. Making this approach ideal for facial recognition and other computer vision applications.

Accelerate Machine Learning for Optimal, Accurate AI Models
For one-shot and few-shot computer vision projects, you need machine learning software to optimize and ensure accuracy for the AI-based (artificial intelligence) models you’re deploying in the field.
When you train a one-shot algorithm on a wider range of data, the results will be more accurate. One solution for this is Encord and Encord Active.
Encord improves the efficiency of labeling data, making AI models more accurate. Encord Active is an open-source active learning framework for computer vision: a test suite for your labels, data, and models.
Having the right tools is a valuable asset for organizations that need CV models to get it right the first time.
Encord is a comprehensive AI-assisted platform for collaboratively annotating data, orchestrating active learning pipelines, fixing dataset errors, and diagnosing model errors & biases. Try it for free today.
One-Shot Learning: Frequently Asked Questions (FAQs)
What is one-shot learning?
One-shot learning is a subset of n-shot learning, including less-than-one-shot, zero-shot, and few-shot learning. In every case, a deep learning, neural network, SNN, or MANN is trained on enough data so that in the real world, it can produce accurate results on anything from no inputs (metadata only) to up to 5 inputs, such as images.
What are the main use cases for one-shot, zero-shot, and few-shot learning in computer vision?
The main use cases are facial recognition, such as for passport or security verification and systems, signature or voice/audio, or biometric recognition. In every real-world use case, a system trained on one of these models only has one chance to produce an accurate outcome.
What's next?
“I want to start annotating” - Get a free trial of Encord Annotate here.
"I want to get started right away" - You can find Encord Active on Github here or try the quickstart Python command from our documentation.
"Can you show me an example first?" - Check out this Colab Notebook.
Want to stay updated?
- Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
- Join our Discord channel to chat and connect.
Frequently asked questions
Setting up training projects in Encord involves submitting two data sets: one with the images for training and another as a benchmark. This allows for effective comparison and validation during the training phase.