Qwen-VL and Qwen-VL-Chat: Introduction to Alibaba’s AI Models

 Qwen-VL is a series of open-source large vision-language models (LVLMs), offering a potent combination of advanced capabilities and accessibility. As an open-source project, Qwen-VL not only democratizes access to cutting-edge AI technology but also positions itself as a formidable competitor to established models from tech giants like OpenAI’s GPT-4V and Google’s Gemini.
Qwen-VL is a series of open-source large vision-language models (LVLMs), offering a potent combination of advanced capabilities and accessibility. As an open-source project, Qwen-VL not only democratizes access to cutting-edge AI technology but also positions itself as a formidable competitor to established models from tech giants like OpenAI’s GPT-4V and Google’s Gemini.
In the competitive landscape of LVLMs, Qwen-VL has quickly risen to the forefront, securing its place as a leader on the OpenVLM leaderboard. This leaderboard, which encompasses 38 different VLMs including GPT-4V, Gemini, QwenVLPlus, LLaVA, and others, serves as a comprehensive benchmark for evaluating model performance across 13 distinct multimodal tasks.
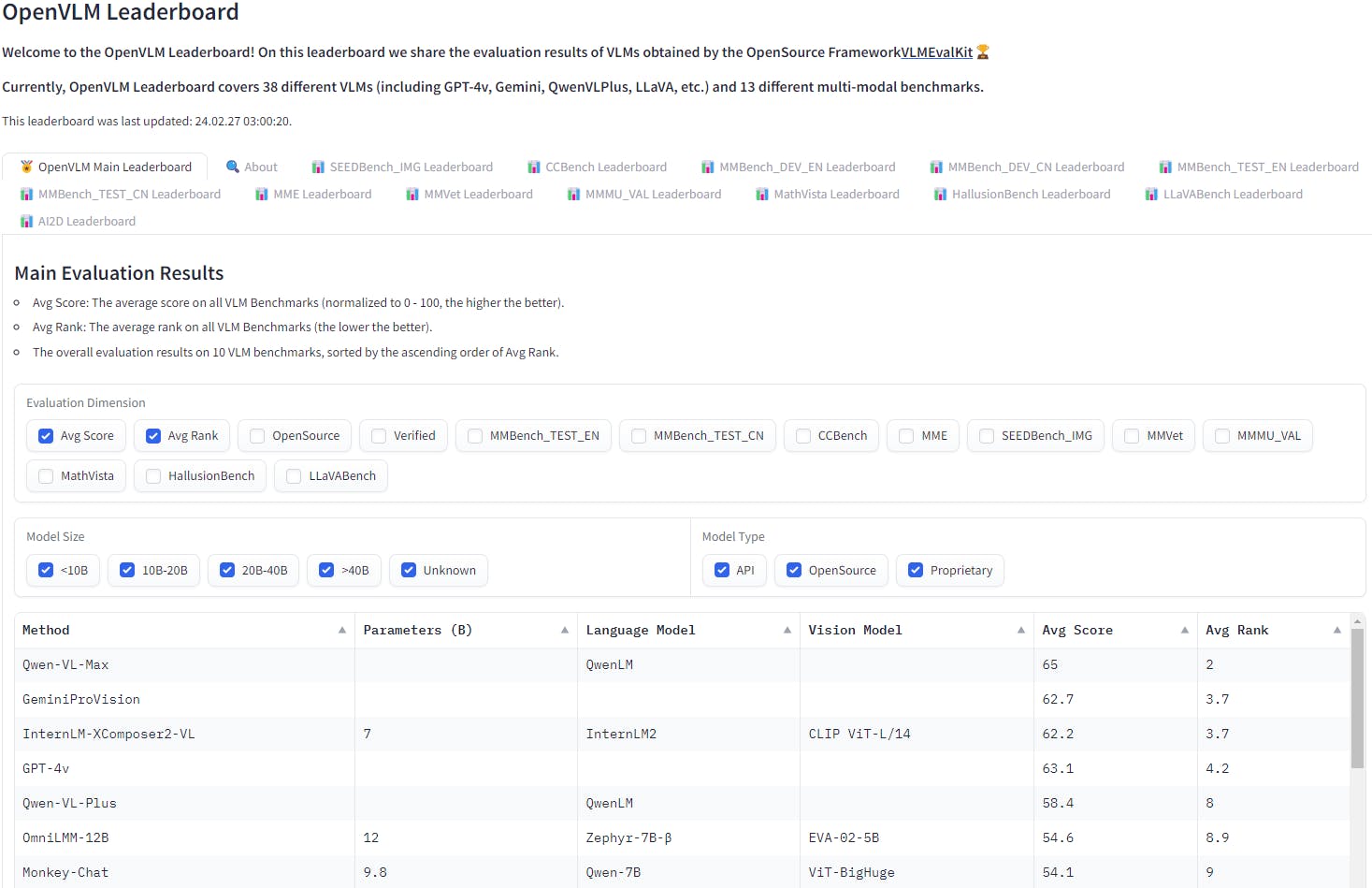
Qwen-VL's performance across these benchmarks underscores its versatility and robustness in handling various vision-language tasks with unparalleled accuracy and efficiency. By leading the charge on the OpenVLM leaderboard, Qwen-VL sets a new standard for excellence in the field, pushing the boundaries of what is possible with LVLMs and paving the way for future advancements in multimodal AI research.
Introduction to Large-scale Vision Language Models (LVLMs)
Large Language Models (LLMs) have attracted attention in recent years for their remarkable text generation and comprehension capabilities in the field of generative AI. However, their limitation to processing text alone has constrained their utility in various applications. In response to this limitation, a new class of models known as Large Vision Language Models (LVLMs) has come up, aiming to integrate visual data with textual information to address vision-centric tasks.
LVLMs improve conventional LLMs by integrating vision language learning, thus extending their applicability to include image datasets. However, despite their promising potential, open-source LVLM implementations encounter hurdles such as inadequate training and optimization when compared to proprietary models. Also, understanding visual content still remains a significant challenge for existing LVLM frameworks.
Overview of Qwen-VL
The Qwen-VL series represents a significant advancement in Large Vision Language Models (LVLMs), designed to overcome the limitations of existing models and equip LLMs with visual processing capabilities. Built upon the Alibaba Cloud’s 7 billion parameter model, Qwen-7B language model, the Qwen-VL series introduces a visual receptor architecture comprising a language-aligned visual encoder and a position-aware adapter.
This architecture enables Qwen-VL models to effectively process visual inputs, generate responses based on prompts, and perform various vision-language tasks such as image recognition, image captioning, visual question answering, and visual grounding. Qwen-VL models demonstrate leading performance on vision-centric benchmarks and support multiple languages, including English and Chinese.
Key Features of Qwen-VL
Qwen-VL models demonstrate good accuracy on a wide range of vision-centric understanding benchmarks, surpassing other SOTA models of similar scales. They excel not only in conventional benchmarks such as captioning and question-answering but also in recently introduced dialogue benchmarks.
Here are the key features of Qwen-VL:
- Multi-lingual Support: Similar to Qwen-LM, Qwen-VLs are trained on multilingual image-text data, with a substantial corpus in English and Chinese. This enables Qwen-VLs to naturally support English, Chinese, and other multilingual instructions.
- Multi-image Capability: During training, Qwen-VLs can handle arbitrary interleaved image-text data as inputs, allowing them to compare, understand, and analyze context when multiple images are provided.
- Fine-grained Visual Understanding: Qwen-VLs exhibit highly competitive fine-grained visual understanding abilities, thanks to their higher-resolution input size and fine-grained corpus used during training. Compared to existing vision-language generalists, Qwen-VLs demonstrate superior performance in tasks such as grounding, text-reading, text-oriented question answering, and fine-grained dialogue comprehension.
- Vision-centric Understanding: This allows the model to comprehensively interpret and process visual information. With advanced architecture integrating a language-aligned visual encoder and position-aware adapter, Qwen-VL excels in tasks like image captioning, question answering, and visual grounding. Its fine-grained analysis ensures precise interpretation of visual content, making Qwen-VL highly effective in vision-language tasks and real-world applications.
Design Structure of Qwen-VL
Beginning with the foundation of Qwen-LM, the model is enhanced with visual capacity through several key components:
- Visual Receptor:
Qwen-VL incorporates a carefully designed visual receptor, which includes a visual encoder and adapter. This component is responsible for processing image inputs and extracting fixed-length sequences of image features. - Input-Output Interface:
The model's input-output interface is optimized to differentiate between image and text feature inputs. Special tokens are utilized to delineate image feature input, ensuring seamless integration of both modalities. - 3-stage Training Pipeline:
Qwen-VL employs a sophisticated 3-stage training pipeline to optimize model performance. This pipeline encompasses comprehensive training stages aimed at fine-tuning the model's parameters and enhancing its ability to comprehend and generate responses for both text and image inputs. - Multilingual Multimodal Cleaned Corpus:
Qwen-VL is trained on a diverse multilingual multimodal corpus, which includes cleaned data encompassing both textual and visual information. This corpus facilitates the model's ability to understand and generate responses in multiple languages while effectively processing various types of visual content.
Model Architecture of Qwen-VL
The architecture of Qwen-VL comprises three key components, each contributing to the model's robustness in processing both text and visual inputs.
Large Language Model
Qwen-VL leverages a large language model as its foundational component. This machine learning model is initialized with pre-trained weights obtained from Qwen-7B, ensuring a strong linguistic foundation for the model's language processing capabilities.
Visual Encoder
Qwen-VL employs the Vision Transformer (ViT) architecture, utilizing pre-trained weights from Openclip's ViT-bigG. During both training and inference, input images are resized to a specific resolution. The visual encoder processes these images by dividing them into patches with a stride of 14, thereby generating a set of image features that encapsulate visual information.
Position-aware Vision-Language Adapter
To address efficiency concerns arising from long sequences of image features, Qwen-VL introduces a vision-language adapter. This adapter is designed to compress the image features, enhancing computational efficiency. It consists of a single-layer cross-attention module initialized randomly. This module utilizes a group of trainable embeddings as query vectors and the image features from the visual encoder as keys for cross-attention operations.
By employing this mechanism, the visual feature sequence is compressed to a fixed length of 256. To preserve positional information crucial for fine-grained image comprehension, 2D absolute positional encodings are incorporated into the query-key pairs of the cross-attention mechanism. This ensures that positional details are retained during the compression process.
The compressed image feature sequence of length 256 is then fed into the large language model, enabling Qwen-VL to effectively process both textual and visual inputs and perform a wide range of vision-language tasks with high accuracy and efficiency.
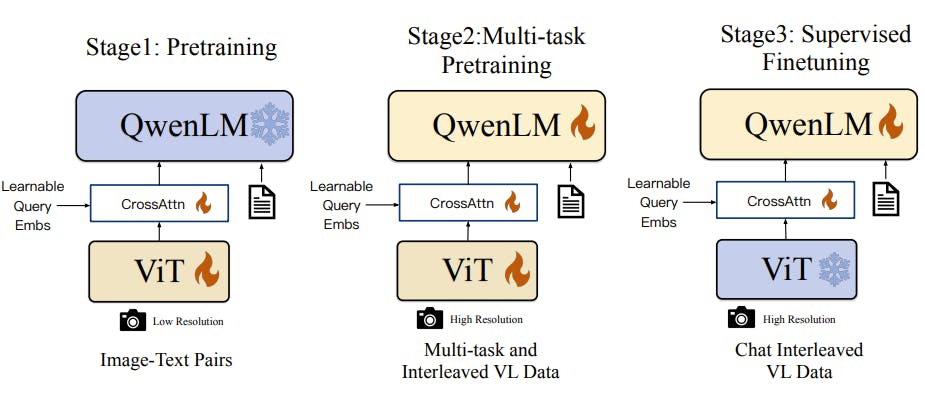
Training Pipeline of Qwen-VL series
Performance of Qwen-VL against State-of-The-Art LVLMs
The performance of Qwen-VL models, particularly Qwen-VL-Max, surpasses SOTA models such as Gemini Ultra and GPT-4V in various text-image multimodal tasks. Compared to the open-source version of Qwen-VL, these models achieve comparable results to Gemini Ultra and GPT-4V, while significantly outperforming previous best results from open-source models.
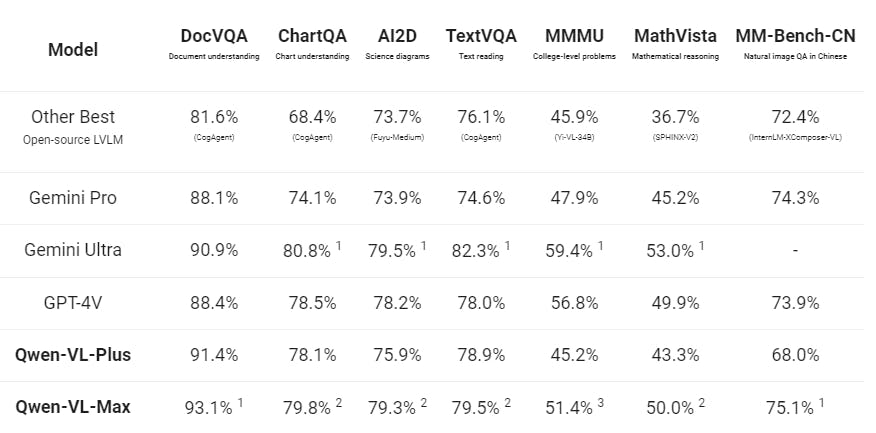
Performance of Qwen-VL-Plus and Qwen-VL-Max against other LVLM
In particular, Qwen-VL-Max demonstrates superior performance over GPT-4V from OpenAI and Gemini from Google in tasks related to Chinese question answering and Chinese text comprehension. This achievement highlights the advanced capabilities of Qwen-VL-Max and its potential to establish new benchmarks in multimodal AI research and application. It should also be noted that most SOTA models are not trained on chinese language.
Capabilities of Qwen-VL
Qwen-VL exhibits a diverse range of capabilities that enable it to effectively comprehend and interact with visual and textual information, as well as reason and learn from its environment. These capabilities include:
Basic Recognition Capabilities
Qwen-VL demonstrates strong basic recognition capabilities, accurately identifying and describing various elements within images, including common objects, celebrities, landmarks, and intricate details.

Recognition capabilities of Qwen-VL
Visual Agent Capability
As a visual agent, Qwen-VL is capable of providing detailed background information, answering questions, and analyzing complex visual content. It can also compose poetry in multiple languages inspired by visual stimuli and analyze everyday screenshots.

Visual Agent Capabilities of Qwen-VL
Visual Reasoning Capability
Qwen-VL possesses advanced visual reasoning capabilities, extending beyond content description to comprehend and interpret intricate representations such as flowcharts, diagrams, and other symbolic systems. It excels in problem-solving and reasoning tasks, including mathematical problem-solving and profound interpretations of charts and graphs.

Qwen-VL has advanced visual reasoning capabilities
Text Information Recognition and Processing
Qwen-VL exhibits enhanced text information recognition and processing abilities, efficiently extracting information from tables and documents, reformatting it to meet customized output requirements, and effectively identifying and converting dense text. It also supports images with extreme aspect ratios, ensuring flexibility in processing diverse visual content.

Advanced text information recognition and processing abilities of Qwen-VL
Few-shot Learning on Vision-Language Tasks
Qwen-VL demonstrates satisfactory in-context learning (few-shot learning) ability, achieving superior performance on vision-language tasks such as question answering and image captioning compared to models with similar numbers of parameters. Its performance rivals even larger models, showcasing its adaptability and efficiency in learning from limited data.
Qwen-VL Availability
Qwen-VL, including Qwen-VL-Plus and Qwen-VL-Max, is now readily accessible through various platforms, offering researchers and developers convenient access to its powerful capabilities:
- HuggingFace: Users can access Qwen-VL-Plus and Qwen-VL-Max through the Huggingface Spaces and Qwen website, enabling seamless integration into their projects and workflows.
- Dashscope APIs: The APIs of Qwen-VL-Plus and Qwen-VL-Max are available through the Dashscope platform, providing developers with the flexibility to leverage its capabilities for their AI applications. Detailed documentation and quick-start guides are available on the Dashscope platform for easy integration.
- QianWen Web Portal: By logging into the Tongyi QianWen web portal and switching to "Image Understanding" mode, users can harness the latest Qwen-VL-Max capabilities for image understanding tasks. This mode offers additional functionalities tailored specifically for image processing and understanding.
- ModelScope: The Qwen-VL-Chat demo is available on modelscope.
- GitHub Repository: The code and model weights of both Qwen-VL and Qwen-VL-Chat are openly available to download on GitHub, allowing researchers and developers to explore, modify, and utilize them freely. The commercial use of these resources is permitted, enabling their integration into commercial projects and applications.
Qwen-VL-Chat
Qwen-VL-Chat, as a generalist multimodal LLM-based AI assistant, supports complex interactions, including multiple image inputs, multi-round question answering, and creative capabilities. Unlike traditional vision-language chatbots, Qwen-VL-Chat's alignment techniques enable it to comprehend and respond to complex visual and textual inputs with superior accuracy and flexibility.
Here's how Qwen-VL-Chat stands out in real-world dialog benchmarks and compares with existing models:
Qwen-VL-Chat Vs. Vision-Language Chat
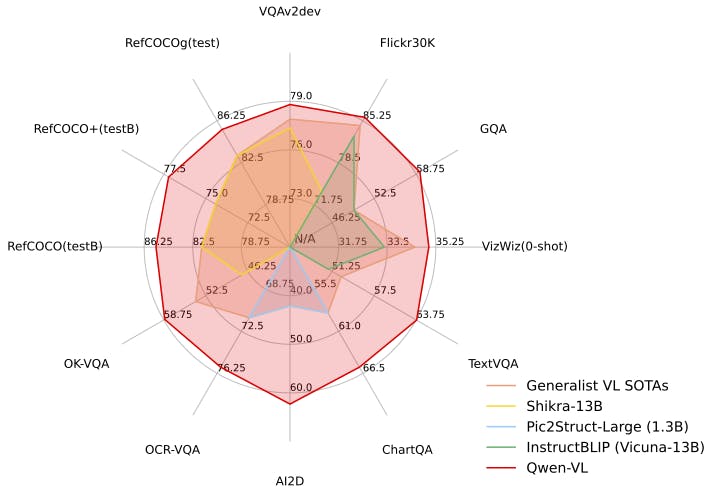
Performance of Qwen-VL against other generalist models across various tasks
Qwen-VL-Chat's advanced capabilities are evaluated using the TouchStone benchmark, which assesses overall text-image dialogue capability and alignment with humans. Unlike conventional models like chatGPT or Bard, Qwen-VL-Chat excels in handling direct image input, thanks to fine-grained image annotations provided by human labeling.

With a comprehensive coverage of 300+ images, 800+ questions, and 27 categories, including attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, and math problem solving, Qwen-VL-Chat achieves superior performance in understanding and responding to complex visual and textual inputs.
Real-world Dialog Benchmark
Qwen-VL-Chat's outstanding results in other multimodal benchmarks, such the MME Benchmark and Seed-Bench, demonstrate that its performance evaluation extends beyond the TouchStone benchmark. In both the perceptual and cognition tracks, Qwen-VL-Chat obtains state-of-the-art scores in the MME Benchmark, an extensive evaluation of multimodal large language models.
The Qwen series, which includes Qwen-VL-Chat, achieves state-of-the-art performance in Seed-Bench, a benchmark consisting of 19K multiple-choice questions with precise human annotations.
Qwen-VL: What’s Next?
The release of the Qwen-VL series represents a significant stride forward in large-scale multilingual vision-language models, with the goal of advancing multimodal research.
Qwen-VL has demonstrated its superiority over comparable artificial intelligence models across various benchmarks, facilitating multilingual complex conversations, multi-image interleaved conversations, grounding in Chinese, and fine-grained recognition.
Looking ahead, the focus is on further enhancing Qwen-VL's capabilities in several key dimensions:
- Multi-modal Generation
The team plans to integrate Qwen-VL with more modalities, including speech and video. By expanding its scope to encompass these modalities, Qwen-VL will enhance its ability to understand and generate content across a wider range of inputs. - Multi-Modal Generation
This generative AI model will be further developed to excel in multi-modal generation, particularly in generating high-fidelity images and fluent speech. By enhancing its ability to generate content across multiple modalities with high fidelity and fluency, Qwen-VL will advance the state-of-the-art in multimodal AI systems. - Augmentation of Model Size and Training Data
Efforts are underway to scale up the model size, training data, and resolution of Qwen-VL. This enhancement aims to enable Qwen-VL to handle more complex and intricate relationships within multimodal data, leading to more nuanced and comprehensive understanding and generation of content.
Frequently asked questions
Qwen-VL integrates bounding box, image, and text inputs through its visual receptor architecture, which includes a visual encoder and a position-aware adapter. This allows the model to process image features alongside textual inputs, enabling seamless integration of visual and textual information.
Qwen-VL utilizes the Vision Transformer (ViT) architecture for its visual encoder, initialized with pre-trained weights from Openclip's ViT-bigG. In the code the 4.3.1.0 is preferred.
Qwen-VL stands out an open-source large vision language model with advanced visual reasoning capabilities, fine-grained visual understanding, and superior performance across various benchmarks. Its comprehensive training pipeline and multilingual support further along with it being open sourced distinguish it from other vision-language models.
No they do not support streaming yet.
Yes, Qwen-VL has demonstrated practical applications in various case studies, including image recognition, image captioning, question answering, dialogue systems, and multimodal understanding tasks. Its capabilities have been showcased across multiple domains, highlighting its versatility and effectiveness in real-world scenarios.
Encord is designed to handle a variety of use cases, including visual language modeling (VLM) and traditional perception tasks. The platform's annotation editor allows for flexible labeling scenarios, accommodating diverse data types and annotation requirements, which can be tailored to specific project needs.
Yes, Encord is designed to support innovative applications such as vision language models and large language models. This capability allows teams to explore advanced functionalities that leverage both visual and textual data, enhancing the overall utility of their computer vision solutions.
Encord includes advanced model-assisted annotation capabilities that streamline the annotation process. This feature allows users to leverage machine learning models to assist in generating annotations, making the overall workflow more efficient and reducing the manual effort required.
Encord streamlines the machine learning pipeline by integrating data collection, curation, workflow management, and model evaluation into a single platform. This holistic approach reduces the complexity of the pipeline, ultimately enhancing scalability and improving model performance.
Encord supports users in deploying models on edge devices by allowing them to use pre-trained models for initial labeling and fine-tuning based on a smaller dataset. This ensures that users can efficiently deploy models without the need for extensive computational resources.
Encord offers a range of tools specifically designed for managing Visual Language Action (VLA) workflows. These tools help in organizing and annotating vast amounts of footage, ensuring that teams can efficiently work on their VLA models and improve their training datasets.
Yes, Encord is designed to scale seamlessly, accommodating millions of images for annotation. The platform's robust infrastructure ensures that users can handle large datasets without compromising on performance or quality, making it suitable for extensive projects.
Encord provides the necessary tools and data annotation services that facilitate the training of VLA models. By offering high-quality annotations and a user-friendly platform, Encord helps organizations streamline their model development processes.
Encord utilizes vision language models to enhance product recognition capabilities, allowing the system to understand and describe items beyond typical product classifications. This extends the platform's adaptability for various user needs.
Encord has its own dedicated infrastructure for training machine learning models, enabling users to develop and refine their segmentation capabilities tailored to specific environmental applications.