CVPR 2024: Top Artificial Intelligence and Computer Vision Papers Accepted

Summer has arrived, and with it comes the excitement of CVPR season! Over the past year, the field has seen groundbreaking research and innovation. Here are some standout papers that you won't want to miss.
And if you are attending CVPR, be sure to stop by and say hello to Encord👋!
YOLO-WORLD: Real-Time Open-Vocabulary Object Detection
arXiv | Github | Hugging Face | Official Webpage
Authors: Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan
Affiliations: Tencent AI Lab, ARC Lab, Tencent PCG, Huazhong University of Science and Technology
TL;DR
YOLO-WORLD introduces a novel approach to object detection, enabling real-time open-vocabulary detection. This means the model can identify objects from a wide range of categories, including those not seen during training.
Research Highlights
- Open-Vocabulary Object Detection: Traditional object detection models are typically limited to a fixed set of classes known beforehand. YOLO-WORLD overcomes this limitation by using a large-scale vision-language pretraining framework, enabling the model to recognize and detect objects from an open vocabulary, which includes unseen categories.
- Real-Time Performance: The model achieves real-time performance, making it suitable for applications requiring immediate processing and response.
- Large-Scale Vision-Language Pretraining: The model benefits from extensive pretraining on vast datasets containing image-text pairs. This pretraining enables the model to understand the context and semantics of objects, enhancing its ability to generalize to new categories.
- Integration with YOLO Architecture: YOLO-WORLD builds upon the YOLO architecture, introducing modifications that allow for integrating open-vocabulary capabilities without sacrificing speed and accuracy.

YOLO-WORLD: Real-Time Open-Vocabulary Object Detection
SpatialTracker: Tracking Any 2D Pixels in 3D Space
arXiv | Github | Official Webpage
Authors: Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, Xiaowei Zhou
Affiliations: Zhejiang University, UC Berkeley, Ant Group
TL;DR
SpatialTracker is an approach for estimating 3D point trajectories in video sequences. The method efficiently represents 3D content using a triplane representation and leverages as-rigid-as-possible (ARAP) constraints.

SpatialTracker: Tracking Any 2D Pixels in 3D Space
Research Highlights
- 2D-to-3D Tracking: It accurately tracks 2D pixels in 3D space, significantly improving the precision of spatial tracking in various applications such as augmented reality, robotics, and computer vision.
- Real-Time Performance: The model achieves real-time tracking capabilities, making it suitable for time-sensitive applications where quick and accurate tracking is essential.
- High Precision and Robustness: SpatialTracker demonstrates exceptional precision and robustness in diverse and complex environments, including dynamic scenes with occlusions and varying lighting conditions.
DETRs Beat YOLOs on Real-time Object Detection
arXiv | Github | Official Webpage
Authors: Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen
Affiliations: Baidu Inc, Peking University
TL;DR
The Real-Time DEtection TRansformer (RT-DETR), is a real-time end-to-end object detector that addresses the trade-off between speed and accuracy. RT-DETR combines Transformer-based architecture with an efficient hybrid encoder. It outperforms YOLOs and DINO on COCO and Objects365 datasets, achieving high accuracy while maintaining real-time performance.

DETRs Beat YOLOs on Real-time Object Detection
Research Highlights
- Transformer-Based Architecture: DETRs uses a transformer-based architecture, which provides a more comprehensive and context-aware approach to object detection compared to the CNNs used by YOLO models.
- End-to-End Training: It simplifies the object detection pipeline by using end-to-end training, eliminating the need for hand-crafted components and post-processing steps that are typical in YOLO models.
- Improved Handling of Complex Scenes: The attention mechanisms in DETRs enable better handling of complex scenes with multiple objects, occlusions, and varying scales, making them particularly effective in real-world applications where such challenges are common.
DemoFusion: Democratising High-Resolution Image Generation With No $$
arXiv | Github | Hugging Face | Official Webpage
Authors: Ruoyi Du, Dongliang Chang, Timothy M. Hospedales, Yi-Zhe Song, Zhanyu Ma
Affiliations: PRIS, Beijing University of Posts and Telecommunications, Tsinghua University, University of Edinburgh, SketchX, University of Surrey
TL;DR
DemoFusion democratizes high-resolution image generation by providing an accessible, cost-free method that rivals expensive, resource-intensive models. It achieves high-quality results without the need for substantial computational resources or financial investment.

DemoFusion: Democratising High-Resolution Image Generation With No $$$
Research Highlights
- Cost-Free High-Resolution Generation: DemoFusion generates high-resolution images without the need for expensive hardware or computational resources, making advanced image generation accessible to a broader audience.
- Reduced Computation: The model employs innovative techniques to reduce computational requirements while maintaining high image quality, bridging the gap between performance and accessibility.
- Wide Applicability: DemoFusion is versatile and can be applied to various fields, including art, design, and scientific visualization, demonstrating its potential to impact multiple domains positively.
- User-Friendly Implementation: The system is designed to be user-friendly, with straightforward implementation processes that do not require extensive technical expertise, further lowering the barrier to entry for high-resolution image generation.
Polos: Multimodal Metric Learning from Human Feedback for Image Captioning
arXiv | Github | Hugging Face | Official Webpage
Authors: Yuiga Wada , Kanta Kaneda , Daichi Saito , Komei Sugiura
Affiliations: Keio University
TL;DR
Polos uses multimodal metric learning guided by human feedback to enhance image captioning, resulting in more accurate and contextually relevant descriptions. This approach significantly improves the alignment between visual content and textual descriptions.

Polos: Multimodal Metric Learning from Human Feedback for Image Captioning
Research Highlights
- Multimodal Metric Learning: Polos introduces a novel approach to image captioning that utilizes multimodal metric learning, integrating visual and textual information to generate more accurate and contextually appropriate captions.
- Human Feedback Integration: The model incorporates human feedback into the learning process, allowing it to refine and improve caption quality based on real user evaluations and preferences.
- Enhanced Alignment: By aligning visual features with linguistic elements more effectively, Polos produces captions that better capture the nuances and details of the images, improving overall caption quality.
- Applications: This method is applicable to a wide range of scenarios, from automated content creation and social media management to assisting visually impaired individuals by providing detailed image descriptions.
Describing Differences in Image Sets with Natural Language
arXiv | Github | Official Webpage
Authors: Lisa Dunlap, Yuhui Zhang, Xiaohan Wang, Ruiqi Zhong, Trevor Darrell, Jacob Steinhardt, Joseph E. Gonzalez, Serena Yeung-Levy
Affiliations: UC Berkeley, Stanford
TL;DR
This introduces a system that generates natural language descriptions highlighting differences between image sets, enhancing the interpretability and usability of visual data comparisons.

Describing Differences in Image Sets with Natural Language
Research Highlights
- Natural Language Descriptions: The system generates detailed natural language descriptions to articulate the differences between two sets of images, making it easier for users to understand and analyze visual data.
- Automated Comparison: This approach automates the process of comparing image sets, saving time and reducing the need for manual inspection, which is particularly useful for large datasets.
- Context-Aware Analysis: The model employs context-aware analysis to ensure that the descriptions accurately reflect significant differences, providing meaningful insights rather than superficial comparisons.
- Applications: The technology can be applied in various domains such as medical imaging, environmental monitoring, and quality control in manufacturing, where understanding subtle differences between image sets is crucial.
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
arXiv | Github | Official Webpage
Authors: Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent Y. F. Tan, Song Bai
Affiliations: National University of Singapore, ByteDance Inc.
TL;DR
This introduces an interactive image editing system that leverages diffusion models, allowing users to make precise edits to images using point-based interactions, thereby enhancing the editing process while maintaining image quality.

DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Research Highlights
- Diffusion Model Integration: The system integrates diffusion models into the image editing workflow, enabling users to manipulate images effectively while preserving their overall quality and coherence.
- Interactive Point-Based Editing: Users can perform edits by interacting with specific points on the image, providing a more intuitive and precise editing experience compared to traditional methods.
- Real-Time Feedback: DragDiffusion provides real-time feedback, allowing users to instantly see the effects of their edits and make adjustments accordingly, leading to a more efficient editing process.
Now that we've explored some compelling papers to anticipate at CVPR 2024, let's turn our attention to noteworthy datasets and benchmarks.
Datasets and Benchmarks
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models
arXiv | Github | Hugging Face | Official Webpage
Authors: Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, Ying Shan
Affiliations: Tencent AI Lab, City University of Hong Kong, University of Macau, The Chinese University of Hong Kong
TL;DR
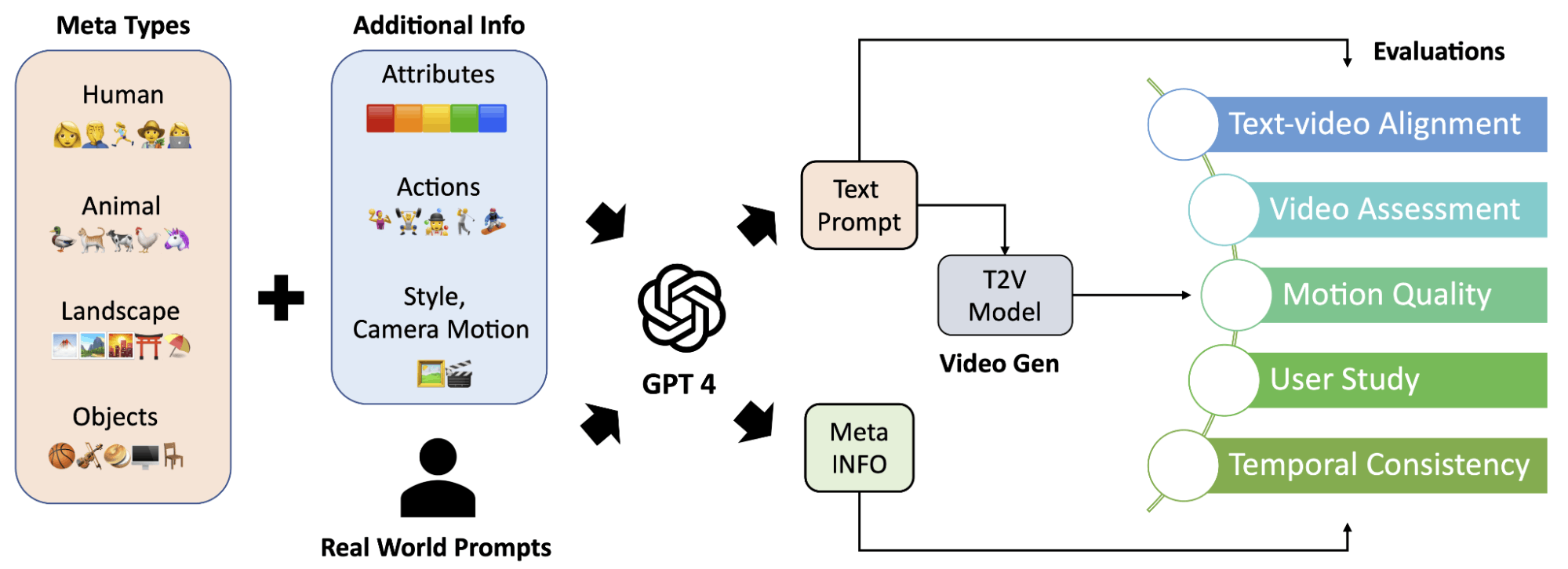
This paper introduces a comprehensive framework for benchmarking and evaluating large video generation models, facilitating rigorous comparisons and assessments of their performance.
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models
Research Highlights
- Comprehensive Evaluation Framework: EvalCrafter provides a robust framework encompassing diverse evaluation metrics, datasets, and evaluation protocols tailored specifically for large video generation models.
- Standardized Benchmarking: The paper establishes standardized benchmarks and evaluation procedures, enabling fair and consistent comparisons across different models and datasets.
- Performance Analysis: EvalCrafter offers in-depth performance analysis, shedding light on the strengths and weaknesses of various video generation models under different conditions and datasets.
360Loc: A Dataset and Benchmark for Omnidirectional Visual Localization with Cross-device Queries
arXiv | Github | Official Webpage
Authors: Huajian Huang, Changkun Liu, Yipeng Zhu, Hui Cheng, Tristan Braud, Sai-Kit Yeung
Affiliations: The Hong Kong University of Science and Technology, Sun Yat-sen University
TL;DR
This paper introduces a novel dataset and benchmark specifically designed for omnidirectional visual localization, accommodating cross-device queries. It offers a comprehensive platform for evaluating localization models across diverse scenarios and devices.

360Loc: A Dataset and Benchmark for Omnidirectional Visual Localization with Cross-device Queries
Research Highlights
- Specialized Dataset Creation: 360Loc creates a specialized dataset tailored for omnidirectional visual localization tasks, addressing the unique challenges posed by spherical imagery.
- Cross-Device Queries: The dataset includes cross-device queries, allowing for robust evaluation of localization models across different types of devices, such as smartphones, cameras, and drones.
- Benchmarking Framework: 360Loc establishes a benchmarking framework comprising diverse evaluation metrics and protocols, ensuring fair and rigorous assessments of localization model performance.
- Application: The dataset and benchmark are designed to reflect real-world scenarios, making them invaluable for assessing the practical effectiveness of localization models in various applications, including augmented reality, navigation, and robotics.
DriveTrack: A Benchmark for Long-Range Point Tracking in Real-World Videos
arXiv | Github | Official Webpage
Authors: Arjun Balasingam, Joseph Chandler, Chenning Li, Zhoutong Zhang, Hari Balakrishnan
Affiliations: MIT CSAIL, Adobe Systems
TL;DR
DriveTrack introduces a benchmark specifically crafted for evaluating long-range point tracking in real-world video sequences, catering to the demands of autonomous driving and surveillance applications.

DriveTrack: A Benchmark for Long-Range Point Tracking in Real-World Videos
Research Highlights
- Tailored Benchmark Creation: This benchmark dataset is tailored for the challenging task of long-range point tracking in real-world video footage, addressing the unique demands of applications such as autonomous driving and surveillance.
- Real-World Scenario Representation: The dataset faithfully represents real-world scenarios encountered in driving and surveillance contexts, encompassing diverse environmental conditions, lighting variations, and camera perspectives.
- Performance Evaluation Framework: DriveTrack provides a comprehensive framework for evaluating point tracking algorithms, including metrics to assess accuracy, robustness, and computational efficiency across long-range sequences.
- Application: The benchmark's focus on real-world applications ensures that evaluated tracking algorithms are well-suited for deployment in critical domains, contributing to advancements in autonomous driving safety, surveillance effectiveness, and video analysis efficiency.
ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
arXiv | Github | Official Webpage
Authors: Chenshuang Zhang, Fei Pan, Junmo Kim, In So Kweon, Chengzhi Mao
Affiliations: KAIST, University of Michigan, McGill University, MILA
TL;DR
ImageNet-D introduces a benchmark for assessing the robustness of neural networks using diffusion-generated synthetic objects, providing a new dimension to the evaluation of model performance under diverse and challenging conditions.

ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
Research Highlights
- Synthetic Object Dataset: ImageNet-D is a dataset comprising diffusion-generated synthetic objects, offering a unique platform for evaluating the robustness of neural networks against synthetic variations.
- Robustness Evaluation: The benchmark focuses on testing neural network robustness, exposing models to a wide range of synthetic distortions and variations to assess their ability to generalize beyond natural images.
- Diverse Challenges: ImageNet-D presents neural networks with diverse and challenging conditions, including variations in shape, texture, and composition, to rigorously evaluate their performance.
- Comprehensive Metrics: The benchmark provides a comprehensive set of evaluation metrics, facilitating detailed analysis of model robustness, accuracy, and adaptability to synthetic objects, thereby enhancing the development of more resilient neural networks.
HouseCat6D - A Large-Scale Multi-Modal Category Level 6D Object Perception Dataset with Household Objects in Realistic Scenarios
arXiv | Dataset | Official Webpage
Authors: HyunJun Jung, Guangyao Zhai, Shun-Cheng Wu, Patrick Ruhkamp, Hannah Schieber, Giulia Rizzoli, Pengyuan Wang, Hongcheng Zhao, Lorenzo Garattoni, Sven Meier, Daniel Roth, Nassir Navab, Benjamin Busam
Affiliations: Technical University of Munich, FAU Erlangen-Nurnberg, University of Padova, Toyota Motor Europe, 3dwe.ai
TL;DR
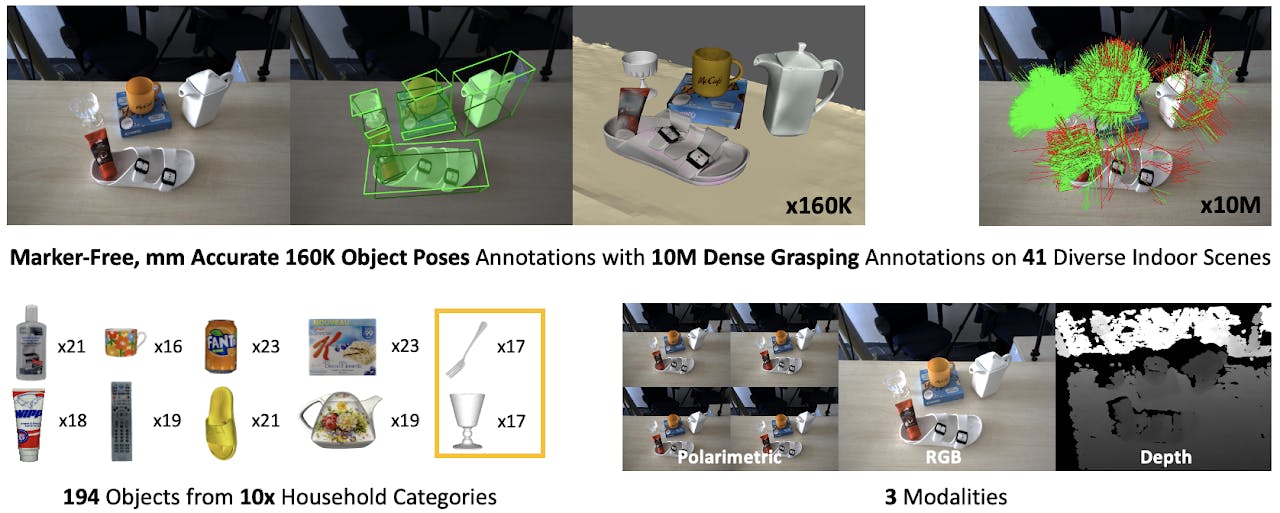
HouseCat6D introduces a comprehensive dataset for category-level 6D object perception, featuring household objects in realistic scenarios and combining multi-modal data to advance research in object recognition and pose estimation.
Research Highlights
- Large-Scale Dataset: This presents an extensive dataset specifically designed for 6D object perception, including a wide variety of household objects captured in realistic settings.
- Multi-Modal Data: The dataset integrates multi-modal data, such as RGB images, depth information, and point clouds, providing a rich resource for developing and evaluating robust 6D object perception algorithms.
- Realistic Scenarios: Objects are presented in realistic household environments, ensuring that the dataset accurately reflects the complexity and diversity of real-world conditions.
- Category-Level Perception: HouseCat6D emphasizes category-level perception, allowing models to generalize across different instances of the same object category, which is crucial for practical applications in home robotics and augmented reality.
- Comprehensive Benchmarking: The dataset includes a comprehensive benchmarking framework with detailed evaluation metrics, enabling researchers to rigorously assess the performance of their models in diverse and challenging scenarios.
Meet Team Encord at CVPR 2024!
I hope this enhances your CVPR experience. If you’re interested in discussing topics from data curation to model evaluation, make sure to connect with Encord at the event.