DataOps Vs MLOps: What's the Difference?

In modern AI-driven applications, Machine Learning Operations (MLOps) and Data Operations (DataOps) help manage machine learning and data-related operations. Their contribution through principles, practices, and tools is vital for scaling up ML and data applications.
Data Operations (DataOps) is an automated approach to streamlining and managing data at scale, so it is helpful for downstream tasks. MLOps and DataOps make collaborating easier for teams, automate tasks, manage large datasets, use sophisticated algorithms, and maintain models continuously. They also let teams focus on experimenting and coming up with new ideas.
But what makes both processes effective for managing data and scaling ML projects?
It is important to note that DevOps practices have influenced both of these practices, and many approaches are borrowed or transferred from them. For instance, at their core, both rely on robust methodology and components that include version control, continuous integration/continuous deployment (CI/CD), monitoring and observability, and model governance.
Furthermore, both practices prioritize automation, collaboration, and streamlining various operations related to ML model development and data engineering and management.
MLOps Methodology
MLOps largely depends on a methodology that optimizes the deployment and management of ML models in production environments. It merges machine learning (ML) with DevOps by adopting best practices from software development and operations to efficiently deploy and maintain models in production environments. You can view this methodology in three ways:
- Problem Definition and Data Acquisition: Identify the problem, gather the data, and design the solution.
- ML training and development: Train and implement proof of concept (PoC) models. Iteratively evaluate, retrain, and improve them to deliver a stable, high-performing model.
- Managing ML operations: Deploy, manage, and monitor models in production. This also involves automating experiments with various models, parameters, and new data.
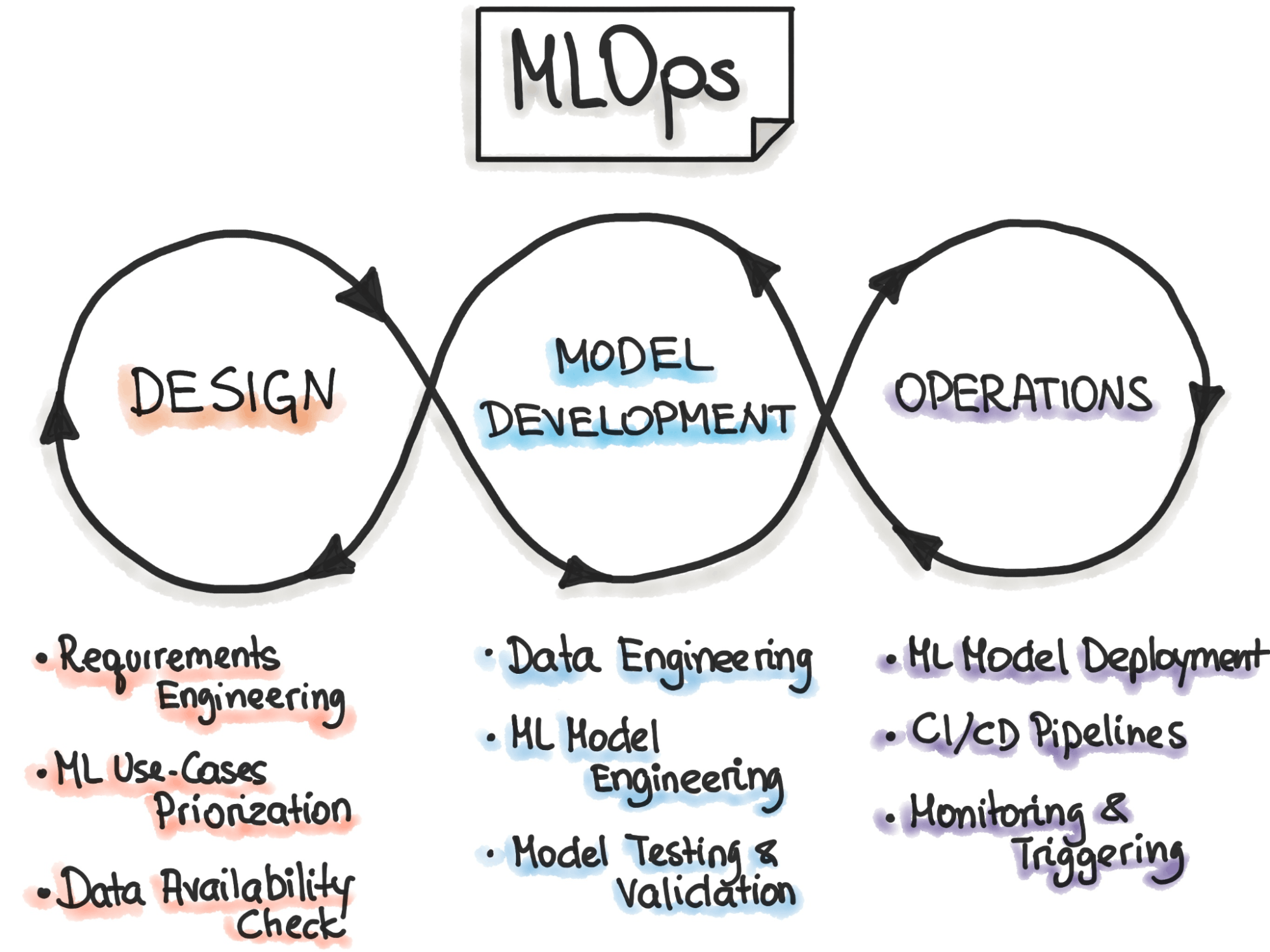
MLOps bridges model development and operations through CI/CD automation, workflow orchestration, collaboration, continuous ML training and evaluation, metadata tracking, monitoring, and feedback loops.
It helps avoid technical debt, ensures reproducibility, complies with governance, scales operations, fosters collaboration, and monitors performance.
ML Lifecycle in MLOps
Another important aspect of MLOps is the ML lifecycle. An ML lifecycle is a set of procedures or methods that enables an ML practitioner to develop, deploy, and continuously maintain ML models in real-world settings.
It generally has four phases:
- Data Collection: This step ensures we collect and prepare data from different sources. Having a dataset from a legitimate source is vital. In addition, ensure that it is well-processed, curated, and ready for training models.
- Model Training: After that, data is well structured, engineered, and used to train ML models. Training is an iterative process to develop an optimal model.
- Deployment: Once trained, we deploy the model in real-world settings, where it can make predictions about new data in real-time.
- Monitoring: After deploying the model, we continuously monitor it to ensure it works well and maintains the expected performance. The monitoring process involves spotting bugs and inconsistencies in the model or changes in data patterns. Monitoring uses performance metrics to track the model's behavior and provide live feedback.
Keeping the above as the building blocks in the ML lifecycle, MLOps emphasizes continuous integration and deployment (CI/CD).
The CI/CD pipeline keeps the lifecycle streamlined and consistent. This allows ML practitioners to innovate and add new features much more quickly. CI/CD involves testing, validating, and deploying models automatically. Technically, it involves:
- Version Control: It keeps track of changes in code, data, and model parts. This allows you to trace the changes made over time. It also allows you to identify errors and bugs, leading to faster improvements.
- Continuous Integration (CI): Automatically validates the codes to detect errors and ensure that the ML applications are production-ready.
- Continuous Delivery (CD): Automates the deployment process of ML models to production environments, ensuring that models are deployed quickly and efficiently.
- Monitoring: This ensures the model and the complete end-to-end pipeline work well.
Now, it is essential to consider the role data plays. An ML model will only perform well if the data is consistent and accurate. For that, we need another set of practices that will allow us to engineer, curate, and analyze data appropriately and efficiently. This is where DataOps comes into the picture, and it is integrated with MLOps.
Integration of MLOps and DataOps
DataOps is a process-oriented practice that ensures, maintains, and improves data quality. It is an essential tool when working with big data because it generally contains many inconsistencies and errors, along with vital information.
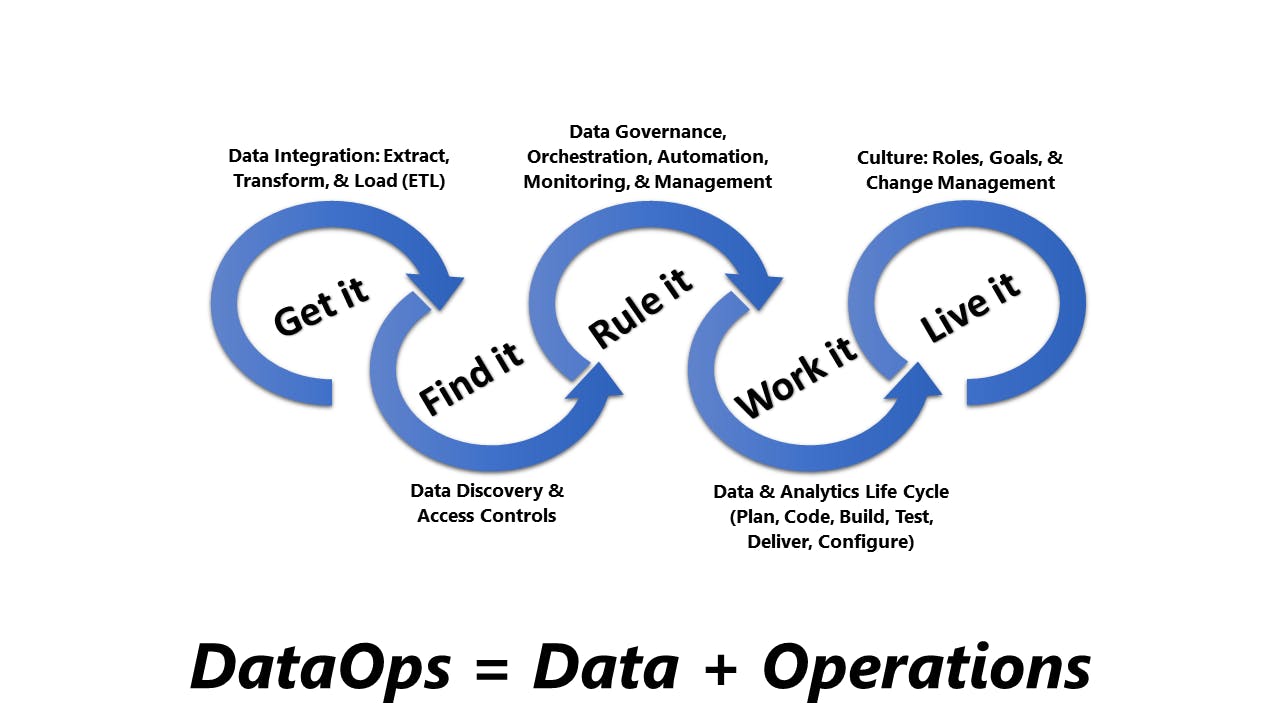
DataOps includes various approaches, such as data engineering services, quality, security, and integration. Along with these approaches, DataOps leverages principles and tools that allow data engineers and teams to curate and process consistent, well-balanced, and high-quality data for downstream tasks like analytics and ML development. The goal is to automate the data life cycle.
It plays a crucial role in upholding the integrity, quality, and security of the data that acts as fuel for data-driven ML models. This ensures cleaner, high-quality data for model training.
DataOps and MLOps share common steps, including data ingestion, preprocessing, model training, model deployment, and model monitoring. The data (pre-)processing part of MLOps focuses on moving data from the source to the ML model.
The following section will discuss seven points highlighting similarities between MLOps and DataOps.
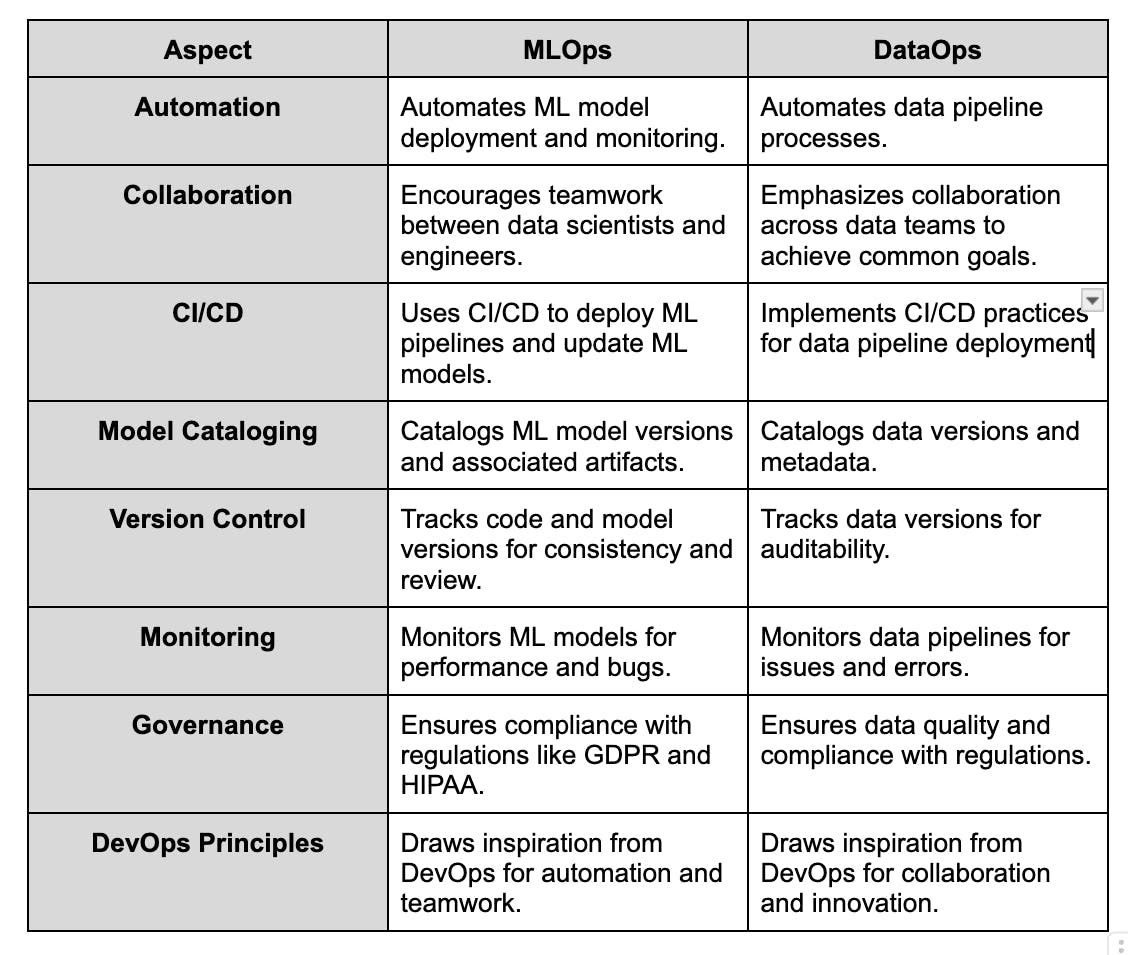
Similarities: MLOps and DataOps
We discussed how MLOps and DataOps have much in common in the previous section. Now, let's dig into some of the shared features they both have:
- Automation: MLOps and DataOps automate processes to execute operations and reduce errors. Automation helps tidy up data pipelines, run ML models, and monitor them once deployed.
- Collaboration: These technologies emphasize the importance of teamwork. They are designed so that data scientists and engineers can collaborate to achieve a common goal.
- CI/CD: They both involve CI/CD practices, which means they like to get things out there quickly and update them easily. This is handy for rapidly spinning up data pipelines and training ML models.
- Model Cataloging and Version Control: MLOps and DataOps keep track of code, metadata, artifacts, etc. They catalog and keep data and ML model versions so everything stays consistent and can be reviewed later.
- Monitoring: DataOps monitors data pipelines, while MLOps monitors ML models. This helps catch bugs early on and ensures everything runs smoothly.
- Governance: Both practices ensure that data is of good quality and safety and that everything follows the rules. This means complying with regulations like GDPR and HIPAA.
- DevOps Principles: Lastly, they draw inspiration from DevOps, which is all about teamwork, automation, and innovation.
The table below shows similarities between both practices in various aspects.
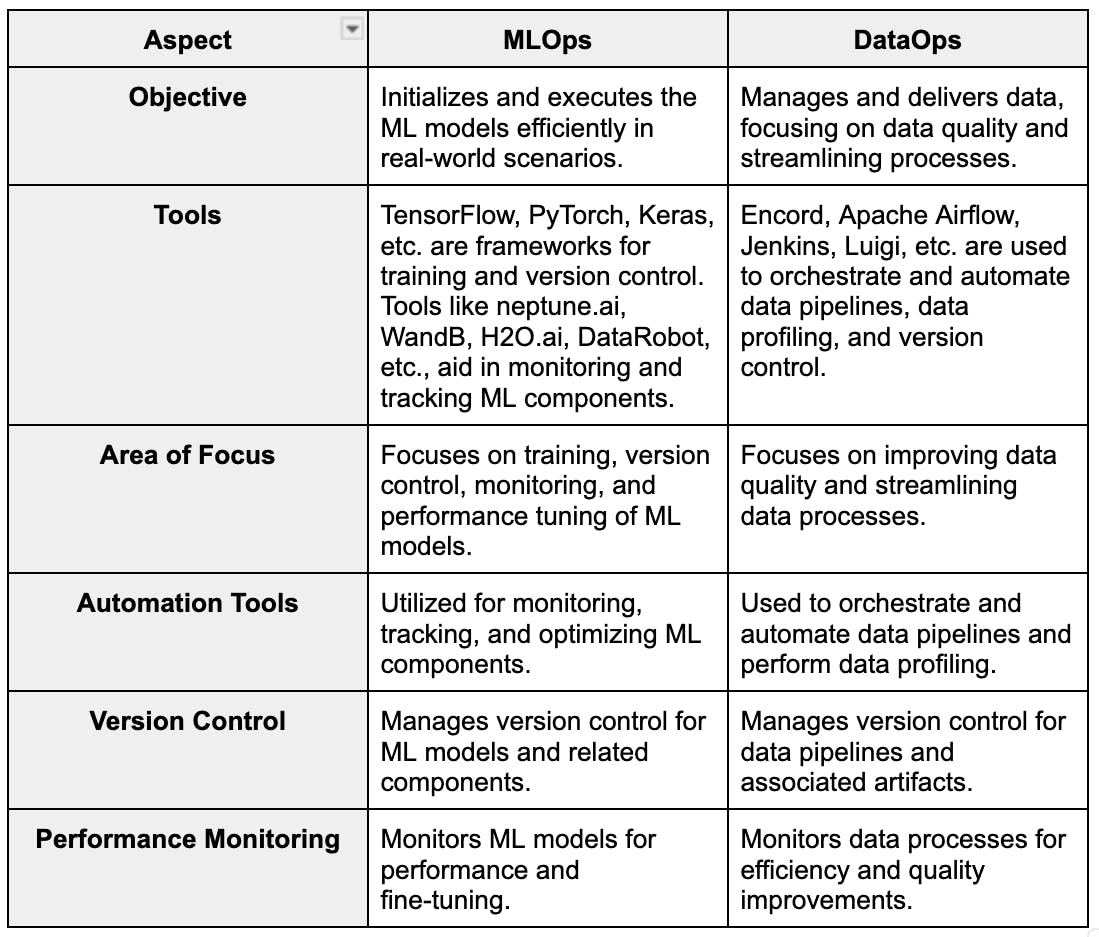
Differentiating MLOps and DataOps
Though these two fields share similar approaches, they each have their objective within the machine learning workflows.
Take DataOps, for instance. It's all about managing and delivering data. This involves improving data quality, streamlining data processes, etc. DataOps tools like Encord, Apache Airflow, Jenkins, Luigi, etc., orchestrate and automate data pipelines, perform data profiling, and check version control.
Now, when it comes to MLOps, it is more about getting the ML models up and running efficiently in the real world. It also involves training, version control, monitoring, and fine-tuning performance. MLOps provides frameworks such as TensorFlow, PyTorch, or Keras to help with that. Automation tools like Neptune.ai, WandB, H2O.ai, DataRobot, etc. allow data scientists and ML engineers to monitor and track every component.
The table below compares the differences between both practices in various aspects.
DataOps vs. MLOps: Which One Should You Choose?
The choice between MLOps and DataOps largely depends on the specific focus and objectives of your project:
Choose MLOps if:
- You are primarily concerned with developing, deploying, and managing production ML models, including overseeing the ML lifecycle.
- Suppose you aim to perform one or all operations, such as efficiently deploying, monitoring, and maintaining ML models, focusing on aspects like version control, continuous integration/deployment, monitoring, and model governance. In that case, you should opt for MLOps.
- You want to streamline the ML lifecycle, automate experiments, ensure reproducibility, and scale operations efficiently.
- You want to scale the ML project. Because the ML lifecycle gets complicated as the size of the project scales up. The size affects how complicated your data processes are, how many models you handle, and how much automation and monitoring you need. For big projects, MLOps gives you a structured way to manage your ML models. This includes controlling versions, monitoring, and making sure they work well. Even with big and complex tasks, MLOps helps keep your models scalable, reproducible, and robust.
Choose DataOps if:
- Your primary focus is collecting, managing, and delivering data within your organization.
- You aim to improve data quality, streamline processes, and optimize data delivery for downstream tasks (production models, business intelligence, analytics, etc.).
- You want to automate data pipelines, improve data quality, and ensure consistent, high-quality data for downstream tasks.
- You are working with big data or if you want to scale up the data streamlining process. Because DataOps focuses on managing data pipelines efficiently, making sure the data is good and easy to operate and access. When working with big data, you need to choose the right tools and ways to handle data input, change, and quality checks. With big data and larger projects, DataOps ensures your data pipelines can scale up, stay reliable, and keep data quality high throughout the process.
DataOps Vs. MLOps: Key Takeaways
In this article, we explored the various aspects of MLOps and dataOps. We studied the similarities and differences, the benefits of integrating both disciplines and which one to choose.
Integrating both can add value to the data and ML projects, as well as teams building data-intensive production ML applications.
Here is a summary of all that we covered in this article comparing DataOps and MLOps.
DataOps:
- Focuses on improving data quality through methodologies like data engineering, quality assurance, and security measures.
- Aims to streamline data operations from end to end.
MLOps, on the other hand:
- Bridges the gap between ML model development and deployment.
- Combines ML with DevOps, which includes designing ML-powered applications, experimentation and development, and ML operation.
- Can be executed in four phases: Data Collection, Model Training, Deployment, and Monitoring.
We also covered the similarities of both MLOps and DataOps, which, in a nutshell:
- Automate operations and create streamlined workflows.
- Focus on collaboration, workflow orchestration, monitoring, and version control.
When it comes to the differences:
- MLOps offers tools for building, deploying, and monitoring ML models.
- DataOps offers tools for data engineering and managing datasets.
Lastly, implementing both disciplines can be challenging due to the complexity of managing the machine learning lifecycle from experimentation to production and governing data quality and security.

Frequently asked questions
No, MLOps represents a specialized branch within the broader DevOps landscape, explicitly tailored for managing machine learning endeavors. In contrast, DataOps is primarily concerned with conventional software development processes.
The difference between DevOps and DataOps lies in their focus areas. DevOps optimize software development pipelines, while DataOps applies similar methodologies to managing data operations pipelines within organizations.
MLOps and AIOps are similar in that they involve managing and optimizing systems operations incorporating ML or AI components. Still, they differ in their focus: MLOps focuses on the end-to-end lifecycle of machine learning models, while AIOps focuses on the broader IT infrastructure landscape to enhance system performance, reliability, and responsiveness.
No, MLOps is a specialized extension of DevOps, explicitly tailored for managing machine learning projects. Both frameworks can coexist harmoniously, offering complementary benefits.
One potential challenge associated with MLOps is that they require specialized expertise and tools to effectively implement and oversee machine learning workflows.
Yes. CI/CD forms integral components of MLOps, facilitating swift and dependable software updates and enhancements.
MLOps and DataOps practices impact the overall efficiency of AI projects in large organizations by streamlining the development and deployment of machine learning models, improving collaboration between teams, and enhancing the scalability and reliability of AI systems.
Encord's annotation platform streamlines the MLOps workflow by providing tools that simplify data labeling, version control, and collaboration among teams. This efficiency is particularly beneficial for organizations looking to implement or redesign their MLOps strategies, as it helps reduce manual overhead and accelerates the model training process.
Encord is designed to streamline various tools and processes used throughout the MLOps stack, allowing teams to consolidate their solutions into a more efficient workflow. By integrating with existing systems, Encord enhances productivity and helps teams manage their data and AI training cycles more effectively.
Encord provides a more comprehensive solution for MLOps automation by integrating multiple functionalities into a single platform. This reduces the complexity of managing separate tools and allows teams to operate more efficiently, ultimately leading to faster deployment and better project outcomes.
MLOps tooling within Encord is significant as it helps manage the complexities of machine learning operations. It addresses inefficiencies that can impact performance and cost, allowing teams to focus on building and deploying models effectively while minimizing operational overhead.
Encord integrates various stages of the MLops pipeline into a single platform, from data acquisition to model training. This consolidation helps teams minimize time spent on managing tools and data transfers, allowing them to focus on building higher quality AI models efficiently.
Encord is designed to streamline the entire MLOps process by integrating various solutions into a cohesive platform. This integration simplifies the iteration and improvement of models, making it easier to handle scaling data volumes efficiently.
Encord provides tailored support for MLOps and data pipelines, facilitating the integration of existing workflows with its platform. This support includes technical guidance and resources to ensure a seamless fit with users' current operations.
Yes, Encord is designed to be a one-stop shop for MLOps tooling, allowing seamless integration with existing systems. This facilitates faster onboarding of customers and enhances collaboration among technical and non-technical team members.
When deciding between on-premise and cloud solutions, factors such as data sensitivity, existing infrastructure investments, and potential network bottlenecks must be considered. Encord can provide insights into both deployment options.
Encord's dataops stack comprises a comprehensive suite of tools designed to streamline the annotation process, manage data efficiently, and support various stages of data utilization, particularly in video and image analysis.