Overfitting in Machine Learning: How to Detect and Avoid Overfitting in Computer Vision?

Overfitting occurs when the model memorizes specific patterns in the training images instead of learning general features. Overfit models have extremely high accuracy on the training data but much lower accuracy on testing data, failing to generalize well. Complex models with many parameters are more prone to overfitting, especially with limited training data.
In this blog, we will learn about
- What is the difference between overfitting and underfitting?
- How to find out if the model is overfitting?
- What to do if the model is overfitting?
- and how to use tools like Encord Active to detect and avoid overfitting.
Overfitting Vs Underfitting: Key Differences
- Performance on training data: Overfitting leads to very high training accuracy while underfitting results in low training accuracy.
- Performance on test/validation data: Overfitting causes poor performance on unseen data, while underfitting also performs poorly on test/validation data.
- Model complexity: Overfitting is caused by excessive model complexity while underfitting is due to oversimplified models.
- Generalization: Overfitting models fail to generalize well, while underfit models cannot capture the necessary patterns for generalization.
- Bias-variance trade-off: Overfitting has high variance and low bias, while underfitting has high bias and low variance.
Overfitting and Underfitting: Key Statistical Terminologies
When training a machine learning model you are always trying to strike a balance between capturing the underlying patterns in the data while avoiding overfitting or underfitting. Here is a brief overview of the key statistical concepts which are important to understand for us to improve model performance and generalization.
Data Leakage
Data leakage occurs when information from outside the training data is used to create the model. This can lead to a situation where the model performs exceptionally well on training data but poorly on unseen data. This can happen when data preprocessing steps, such as feature selection or data imputation, are performed using information from the entire dataset, including the test set.
Bias
Bias refers to the error introduced by approximating a real-world problem with a simplified model. A high bias model needs to be more accurate in order to capture the underlying patterns in the data, which leads to underfitting. Addressing bias involves increasing model complexity or using more informative features.
Variance
Variance is a measure of how much the model’s predictions fluctuate for different training datasets. A high variance model is overly complex and sensitive to small fluctuations in the training data and captures noise in the training dataset. This leads to overfitting and the machine learning model performs poorly on unseen data.
Bias-variance tradeoff
The bias-variance tradeoff illustrates the relationship between bias and variance in the model performance. Ideally, you would want to choose a model that both accurately captures the patterns in the training data, but also generalize well to unseen data.
Unfortunately, it is typically impossible to do both simultaneously. High-variance learning methods may be able to represent their training dataset well but are at risk of overfitting to noisy or unrepresented training data. In contrast, algorithms with a high bias typically produce simpler models that don’t tend to overfit but may underfit their training data, failing to capture the patterns in the dataset.
Bias and variance are one of the fundamental concepts of machine learning. If you want to understand better with visualization, watch the video below.
Bootstrap
Bootstrapping is a statistical technique that involves resampling the original dataset with replacement to create multiple subsets or bootstrap samples. These bootstrap samples are then used to train multiple models, allowing for the estimation of model performance metrics, such as bias and variance, as well as confidence intervals for the model's predictions.
K-Fold Cross-Validation
K-Fold Cross-Validation is another resampling technique used to estimate a model's performance and generalization capability. The dataset is partitioned into K equal-sized subsets (folds). The model is trained on K-1 folds and evaluated on the remaining fold. This process is repeated K times, with each fold serving as the validation set once. The final performance metric is calculated as the average across all K iterations.
LOOCV (Leave-One-Out Cross-Validation)
Leave-One-Out Cross-Validation (LOOCV) is a special case of K-Fold Cross-Validation, where K is equal to the number of instances in the dataset. In LOOCV, the model is trained on all instances except one, and the remaining instance is used for validation. This process is repeated for each instance in the dataset, and the performance metric is calculated as the average across all iterations. LOOCV is computationally expensive but can provide a reliable estimate of model performance, especially for small datasets.
Here is an amazing video by Josh Starmer explaining cross-validation. Watch it for more information.
Assessing Model Fit
Residual Analysis
Residuals are the differences between the observed values and the values predicted by the model. Residual analysis involves examining the patterns and distributions of residuals to identify potential issues with the model fit. Ideally, residuals should be randomly distributed and exhibit no discernible patterns or trends. Structured patterns in the residuals may indicate that the model is missing important features or violating underlying assumptions.
Goodness-of-Fit Tests
Goodness-of-fit tests provide a quantitative measure of how well the model's predictions match the observed data. These tests typically involve calculating a test statistic and comparing it to a critical value or p-value to determine the significance of the deviation between the model and the data. Common goodness-of-fit tests include:
The choice of test depends on the assumptions about the data distribution and the type of model being evaluated.
Evaluation Metrics
Evaluation metrics are quantitative measures that summarize the performance of a model on a specific task. Different metrics are appropriate for different types of problems, such as regression, classification, or ranking. Some commonly used evaluation metrics include:
- For regression problems: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), R-squared (R²)
- For classification problems: Accuracy, Precision, Recall, F1-score, Area Under the Receiver Operating Characteristic Curve (AUROC)
Diagnostic Plots
Diagnostics plots, such as residual plots, quantile-quantile (Q-Q) plots, and calibration plots, can provide valuable insights into model fit. These graphical representations can help identify patterns, outliers, and deviations from the expected distributions, complementing the quantitative assessment of model fit.
Causes for Overfitting in Computer Vision
Here are the following causes for overfitting in computer vision:
High Model Complexity Relative to Data Size
One of the primary causes of overfitting is when the model's complexity is disproportionately high compared to the size of the training dataset. Deep neural networks, especially those used in computer vision tasks, often have millions or billions of parameters. If the training data is limited, the model can easily memorize the training examples, including their noise and peculiarities, rather than learning the underlying patterns that generalize well to new data.
Noise Training Data
Image or video datasets, particularly those curated from real-world scenarios, can contain a significant amount of noise, such as variations in lighting, occlusions, or irrelevant background clutter. If the training data is noisy, the model may learn to fit this noise instead of focusing on the relevant features.
Insufficient Regularization
Regularization techniques, such as L1 and L2 regularization, dropout, or early stopping, are essential for preventing overfitting in deep learning models. These techniques introduce constraints or penalties that discourage the model from learning overly complex patterns that are specific to the training data. With proper regularization, models can easily fit, especially when dealing with high-dimensional image data and deep network architectures.
Data Leakage Between Training/Validation Sets
Data leakage occurs when information from the test or validation set is inadvertently used during the training process. This can happen due to improper data partitioning, preprocessing steps that involve the entire dataset, or other unintentional sources of information sharing between the training and evaluation data. Even minor data leakage can lead to overly optimistic performance estimates and a failure to generalize to truly unseen data.
How to Detect an Overfit Model?
Here are some common techniques to detect an overfit model:
Monitoring the Training and Validation/Test Error
- During the training process, track the model’s performance on both the training and validation/test datasets.
- If the training error continues to decrease while the validation/test error starts to increase or plateau, a strong indication of overfitting.
- An overfit model will have a significantly lower training error compared to the validation/test error.

Learning Curves
- Plot learning curves that show the training and validation/test error as a function of the training set size.
- If the training error continues to decrease while the validation/test error remains high or starts to increase as more data is added, it suggests overfitting.
- An overfit model will have a large gap between the training and validation/test error curves.
Cross-Validation
- Perform k-fold cross-validation on the training data to get an estimate of the model's performance on unseen data.
- If the cross-validation error is significantly higher than the training error, it may indicate overfitting.
Regularization
- Apply regularization techniques, such as L1 (Lasso) or L2 (Ridge) regularization, dropout, or early stopping.
- If adding regularization significantly improves the model's performance on the validation/test set while slightly increasing the training error, it suggests that the original model was overfitting.
Model Complexity Analysis
- Examine the model's complexity, such as the number of parameters or the depth of a neural network.
- A highly complex model with a large number of parameters or layers may be more prone to overfitting, especially when the training data is limited.
Visualization
- For certain types of models, like decision trees or neural networks, visualizing the learned representations or decision boundaries can provide insights into overfitting.
- If the model has overly complex decision boundaries or representations that appear to fit the training data too closely, it may be an indication of overfitting.
Ways to Avoid Overfitting in Computer Vision
Data Augmentation
Data augmentation techniques, such as rotation, flipping, scaling, and translation, can be applied to the training dataset to increase its diversity and variability. This helps the model learn more robust features and prevents it from overfitting to specific data points.
Observe and Monitor the Class Distributions of Annotated Samples
During annotation, observe class distributions in the dataset. If certain classes are underrepresented, use active learning to prioritize labeling unlabeled samples from those minority classes. Encord Active can help find similar images or objects to the underrepresented classes, allowing you to prioritize labeling them, thereby reducing data bias.
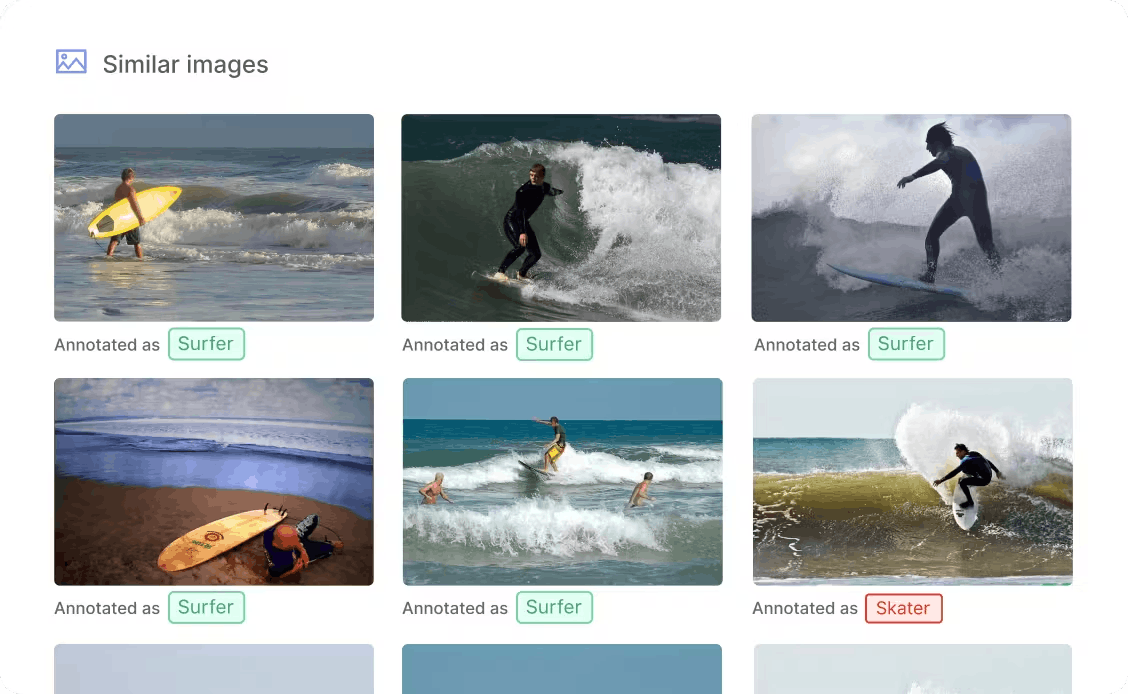
Finding similar images in Encord Active.
Early Stopping
Early stopping is a regularization technique that involves monitoring the model's performance on a validation set during training. If the validation loss stops decreasing or starts to increase, it may indicate that the model is overfitting to the training data. In such cases, the training process can be stopped early to prevent further overfitting.
Dropout
Dropout is another regularization technique that randomly drops (sets to zero) a fraction of the activations in a neural network during training. This helps prevent the model from relying too heavily on any specific set of features and encourages it to learn more robust and distributed representations.
L1 and L2 Regularization
L1 and L2 regularization techniques add a penalty term to the loss function, which discourages the model from having large weights. This helps prevent overfitting by encouraging the model to learn simpler and more generalizable representations.
Transfer Learning
Transfer learning involves using a pre-trained model on a large dataset (e.g., ImageNet) as a starting point for training on a new, smaller dataset. The pre-trained model has already learned useful features, which can help prevent overfitting and improve generalization on the new task.
Ensemble Methods
Ensemble methods, such as bagging (e.g., random forests) and boosting (e.g., AdaBoost), combine multiple models to make predictions. These techniques can help reduce overfitting by averaging out the individual biases and errors of the component models.
Model Evaluation
Regularly monitoring the model's performance on a held-out test set and evaluating its generalization capabilities is essential for detecting and addressing overfitting issues.
Using Encord Active to Reduce Model Overfitting
Encord Active is a comprehensive platform offering features to curate a dataset that can help reduce the model overfitting and evaluate the model’s performance to identify and address any potential issues.
Here are a few of the ways Encord Active can be used to reduce model overfitting:
Evaluating Training Data with Data and Label Quality Metrics
Encord Active allows users to assess the quality of their training data with data quality metrics. It provides metrics such as missing values, data distribution, and outliers. By identifying and addressing data anomalies, practitioners can ensure that their dataset is robust and representative.
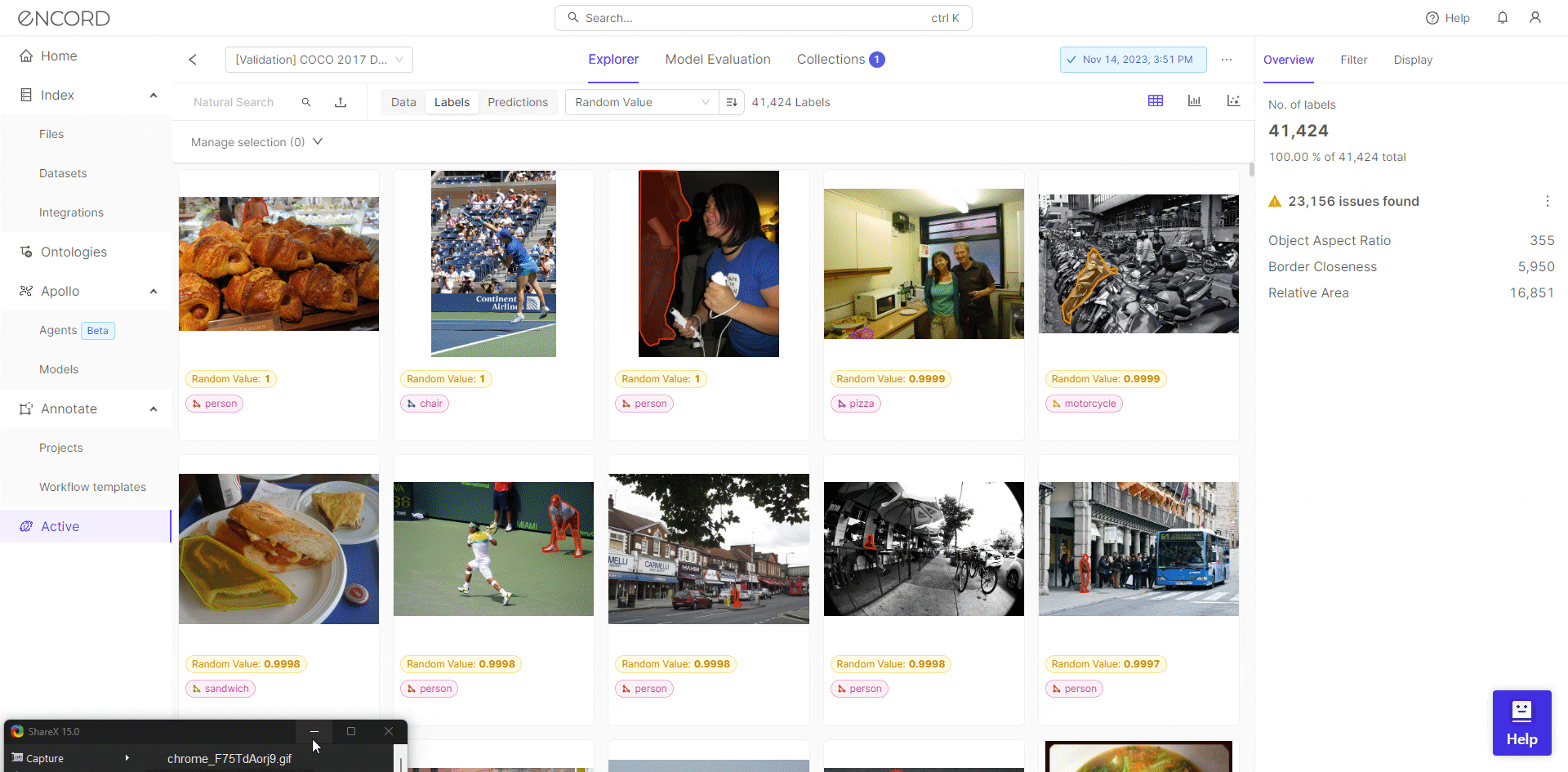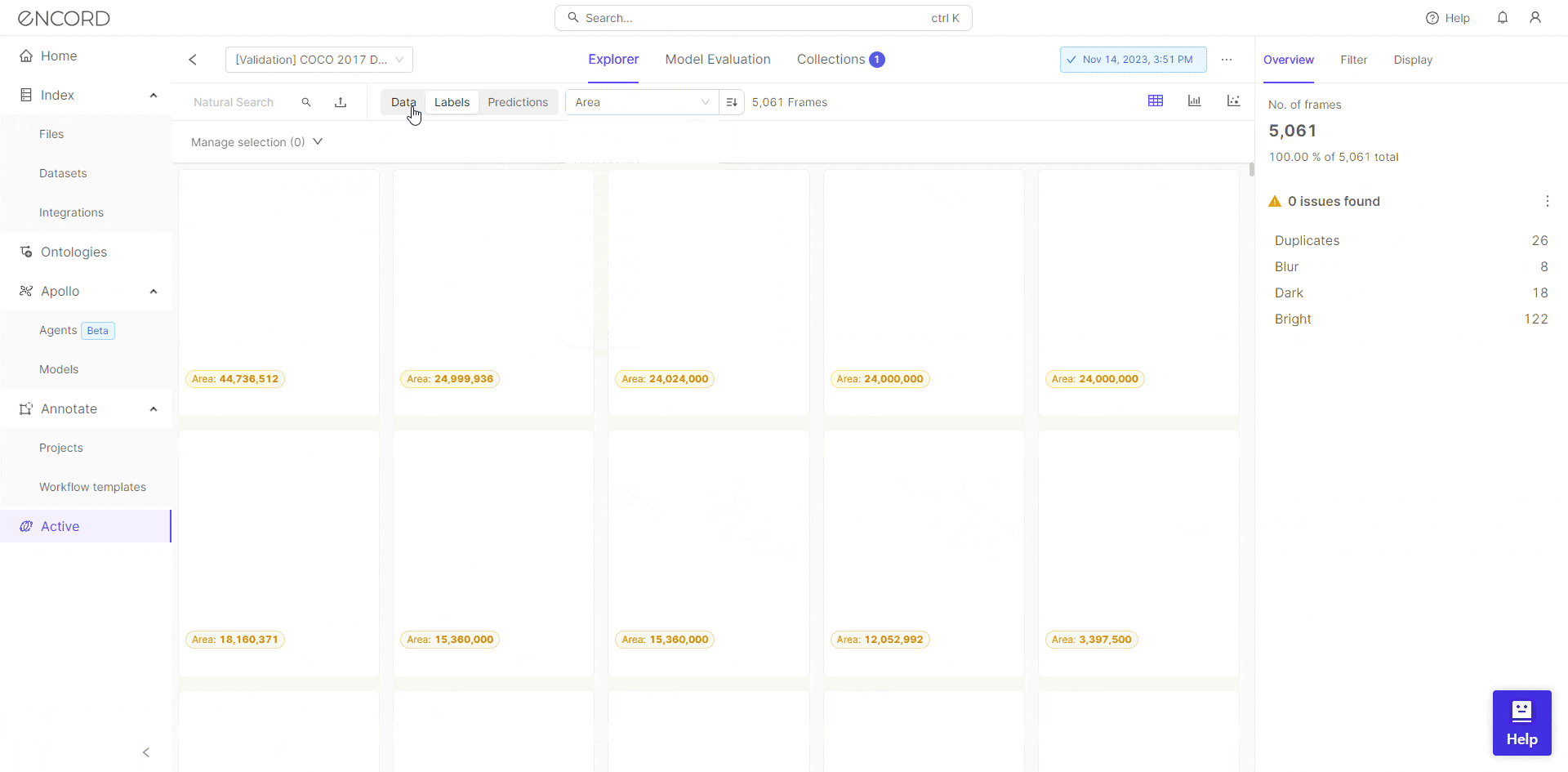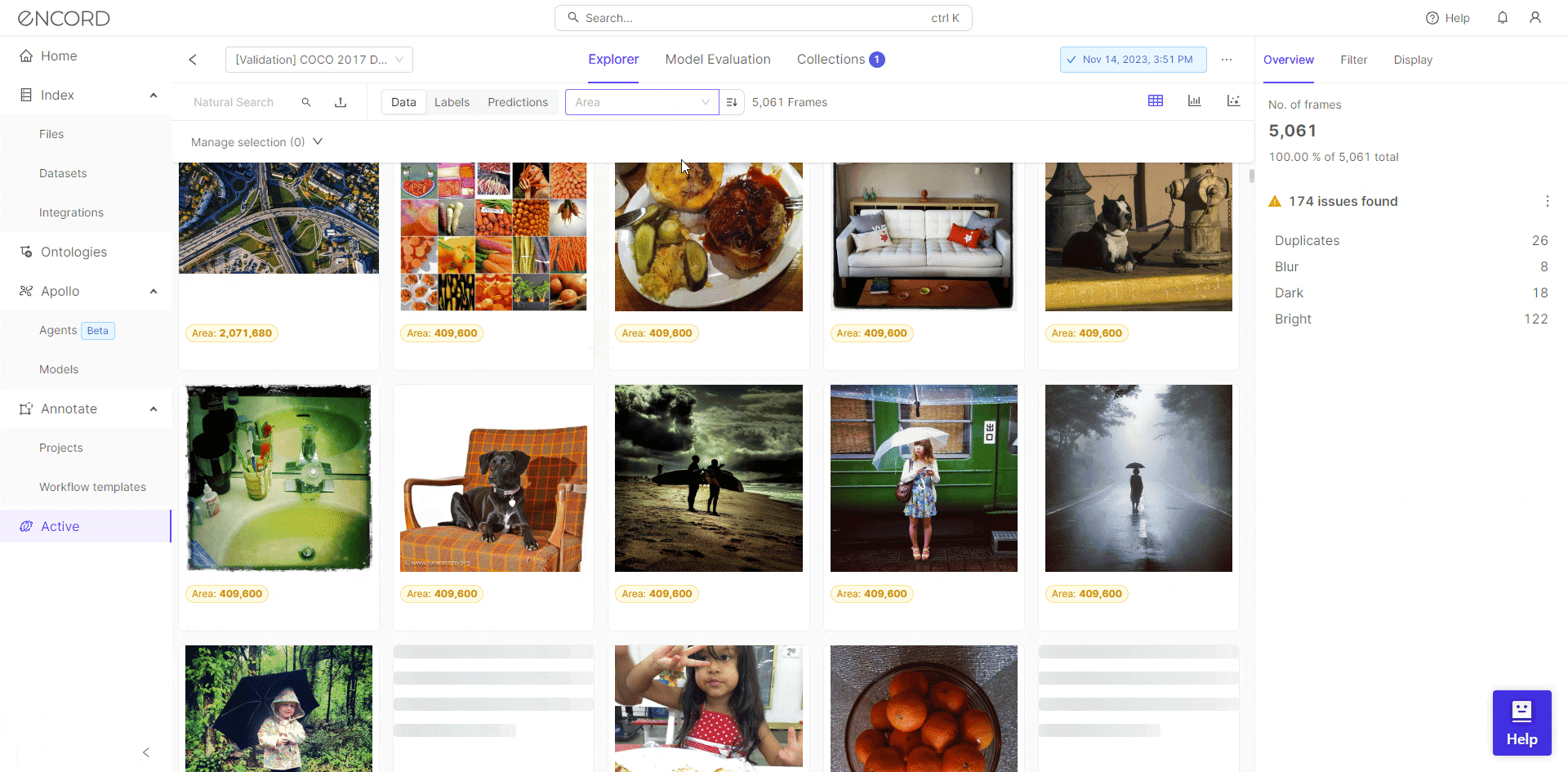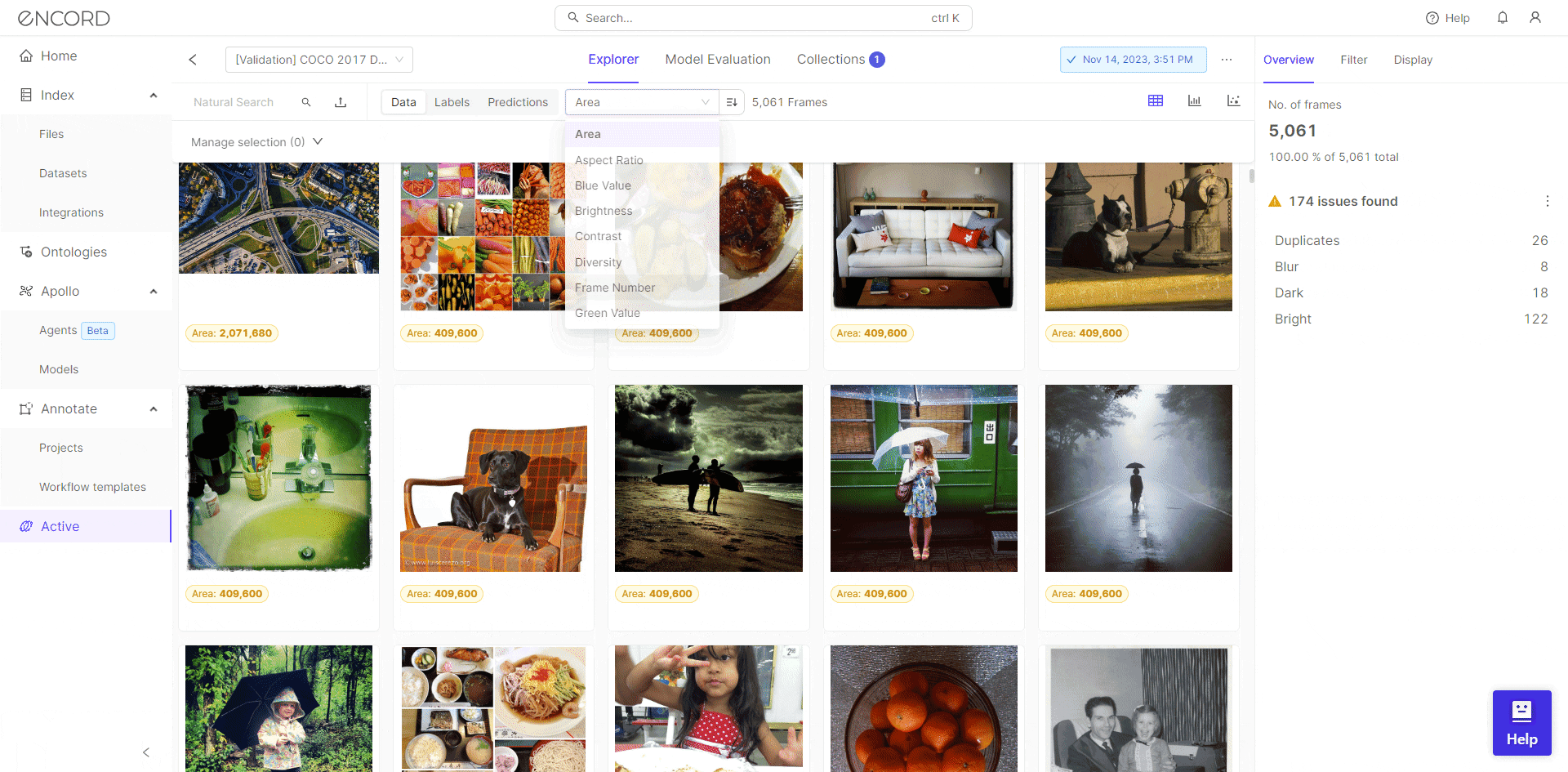
Encord Active also allows you to ensure accurate and consistent labels for your training dataset. The label quality metrics, along with the label consistency checks and label distribution analysis help in finding noise or anomalies which contribute to overfitting.
Evaluating Model Performance with Model Quality Metrics
After training a model, it’s essential to evaluate its performance thoroughly. Encord Active provides a range of model quality metrics, including accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC). These metrics help practitioners understand how well their model generalizes to unseen data and identify the data points which contribute to overfitting.
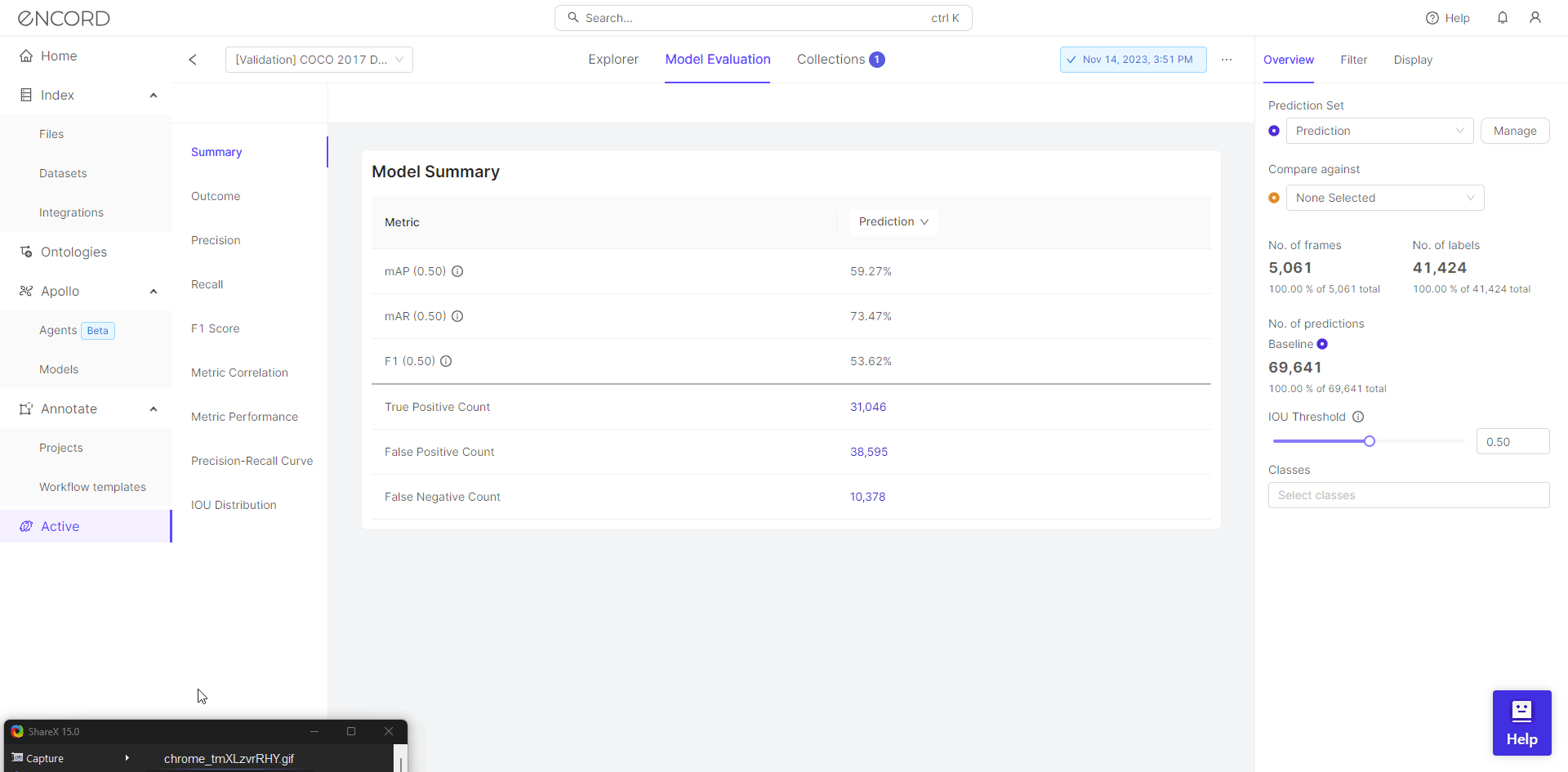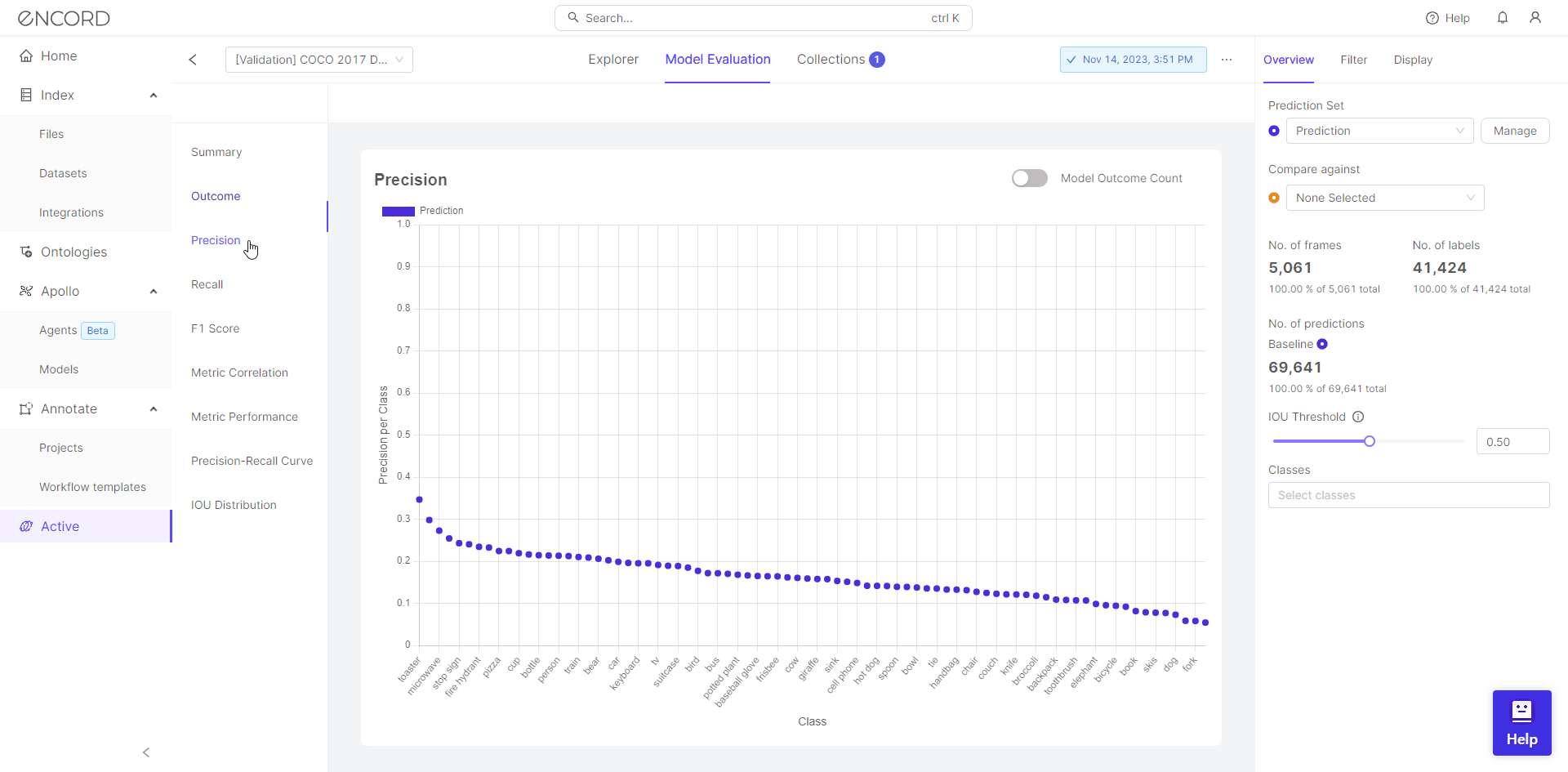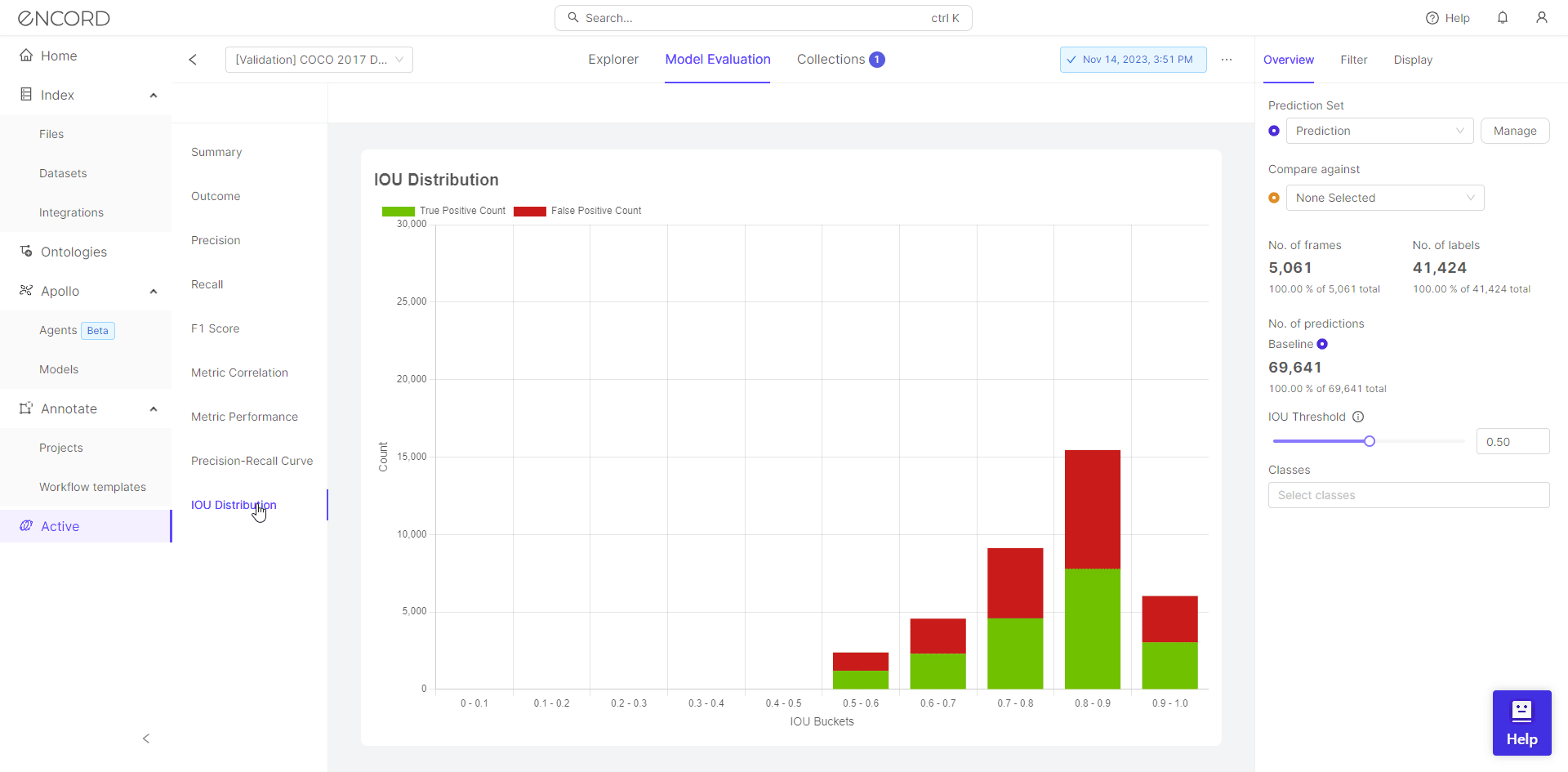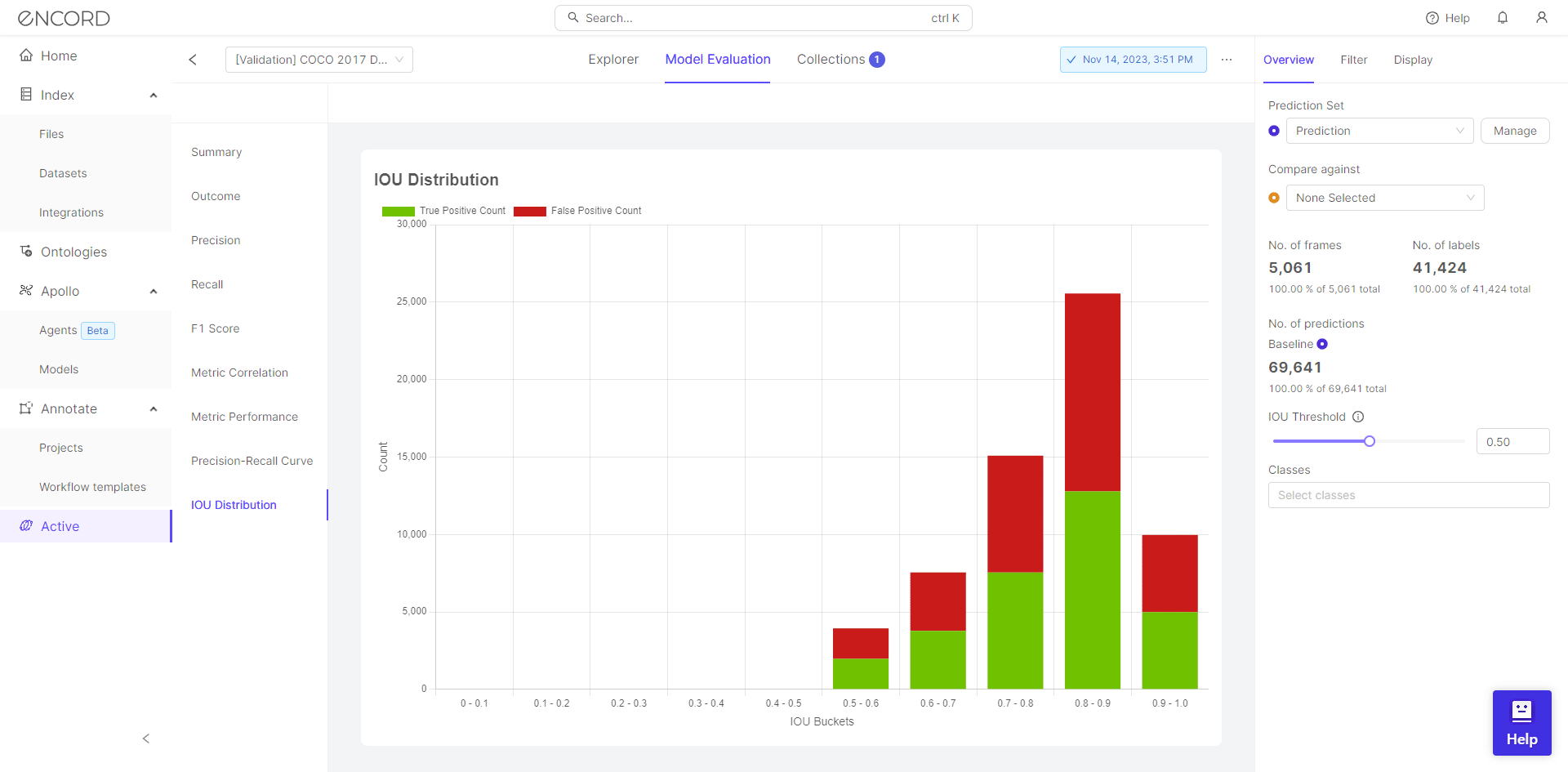
Active Learning Workflow
Overfitting often occurs when models are trained on insufficient or noisy data. Encord Active incorporates active learning techniques, allowing users to iteratively select the most informative samples for labeling. By actively choosing which data points to label, practitioners can improve model performance while minimizing overfitting.
Frequently asked questions
Overfitting is generally undesirable in machine learning as it leads to models that perform well on the training data but fail to generalize to unseen data, defeating the purpose of building a predictive model.
An underfit model is too simple to capture the underlying patterns in the data, resulting in poor performance on both the training and test sets.
Overfitting occurs when a model learns the noise in the training data, while underfitting happens when the model is too simple to learn the underlying patterns.
If a model is overfitting, you can try techniques like regularization, increasing training data size, feature selection, or reducing model complexity.
Overfitting can be addressed through techniques like cross-validation, regularization, early stopping, ensembling, data augmentation, using simpler models or more training data, or use tools like Encord Active.
To prevent overfitting, you can employ regularization techniques, use cross-validation, increase training data size, perform feature selection, and monitor validation performance during training using tools like Encord Active.
Encord focuses on enhancing the human-in-the-loop aspect of machine learning by prioritizing user-friendly annotation tools over low-code ML ops solutions. This approach ensures that technical and non-technical users alike can effectively contribute to the annotation process without complexity, allowing teams to focus on their core needs.
Encord supports the benchmarking of machine learning models by providing a structured environment for comparing new models against established baselines. Users can easily track performance metrics and iterate on their models, ensuring that they achieve state-of-the-art results while also contributing to open science initiatives.
Yes, Encord is designed to integrate seamlessly with machine learning tools. Users can incorporate their machine learning requirements into the annotation process, allowing for a more efficient workflow. This integration helps ensure that the annotated data aligns with the specific needs of the machine learning team.
To maintain high-quality annotations while reducing costs, Encord employs a combination of advanced machine learning techniques and human expertise. The platform is designed to optimize the annotation workflow, enabling teams to achieve efficiency without compromising the quality of their outputs.
Encord offers robust data preprocessing features that facilitate the normalization of data from heterogeneous sources. This includes tools that ensure data safety and efficiency, allowing users to streamline their workflows and reduce the complexities associated with managing diverse data types.
Encord offers innovative approaches to address infrastructure challenges in machine learning, helping teams to overcome limitations related to servers and network complexity. Our platform enables users to explore alternative strategies for managing data and optimizing their ML infrastructure.
Encord provides tools that specifically address the identification of edge cases, which are often rare in datasets. By leveraging our annotation platform, users can ensure that their models are trained on a comprehensive set of data, including edge cases, improving overall model robustness.
Encord's end-to-end ML ops pipelines streamline the entire machine learning workflow, from data management to annotation and model evaluation. This integrated approach reduces inefficiencies and allows teams to focus on core tasks, improving overall productivity and resource allocation.
Yes, Encord can be integrated into existing machine learning pipelines, making it a flexible solution for teams that are developing advanced models. This integration ensures smooth data flow and enhances the overall efficiency of the machine learning workflow.
Encord tackles inefficiencies by offering a unified platform that streamlines data operations within the machine learning pipeline. By consolidating tools and processes, Encord helps teams improve model performance, reduce costs, and enhance scalability.