Model Drift: Best Practices to Improve ML Model Performance

Machine learning (ML) models can learn, adapt, and improve. But, they are not immune to “wear and tear” like traditional software systems. A recent MIT and Harvard study states that 91% of ML models degrade over time, deduced from experiments conducted on 128 model and dataset pairs.
Production-deployed machine learning models can degrade significantly over time due to data changes or become unreliable due to sudden shifts in real-world data and scenarios.
This phenomenon is known as 'model drift,' and it can present a severe challenge for ML practitioners and businesses.
In this article, we will:
- Discuss the concept of model drift in detail
- Explore the factors that cause model drift and present real-world examples
- Talk about the role of model monitoring in detecting model drift
- Learn the best practices for avoiding model drift and improving your ML models' overall performance
By the end, readers will gain an intuitive understanding of model drift and ways to detect it. It will allow ML practitioners to build robust, long-serving machine learning models for high-profile business use cases.
What is Model Drift in Machine Learning?
Model drift is when a machine learning model's ability to predict the future worsens over time because of changes in the real-world data distribution, which is the range of all possible data values or intervals. These changes can be caused by the statistical properties of the input features or target variables. Simply put, the model’s predictions fail to adapt to evolving conditions.
For instance, during the COVID-19 pandemic, consumer behavior was significantly shifted as people started working from home, leading to a surge in demand for home office and home gym equipment. In such circumstances, machine learning models cannot account for sudden shifts in consumer behavior and experience significant model drift. They would fail to accurately forecast demand, leading to inventory imbalances and potential losses.
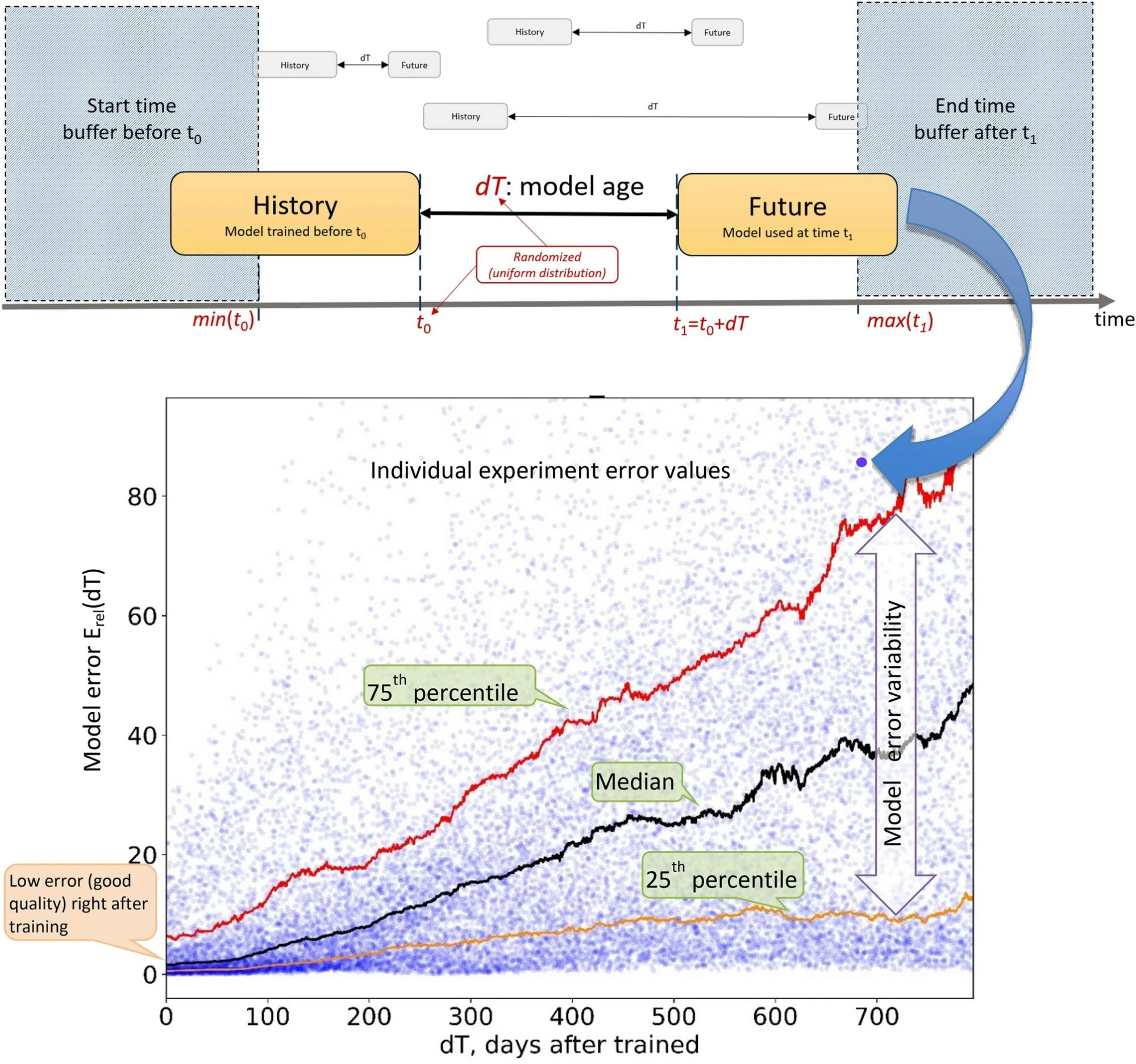
A Model Ageing Chart Based on a Model Degradation Experiment
The chart above illustrates an experiment where the model error variability increases over time. The model shows good quality or low errors right after training, but the errors continue to increase with every passing time interval. Hence, detecting and mitigating model drift is crucial for maintaining the reliability and performance of the models in real-world environments.
Types of Model Drift in Machine Learning
There are three major types of model drift in machine learning, including:
Data Drift
Also known as covariate shift, this type of drift occurs when the source data distribution differs from the target data distribution. It is common with production-deployed ML models. Most of the time, the data distribution during model training differs from the data distribution at production because:
- The training data is not representative of the source population.
- The training data population differs from the target data population.
Concept Drift
This happens when the relationship between the input features and the target variable changes over time. Concept drift does not necessarily depict a change in the input data distribution but rather a drift in the relationship between the dependent and independent variables. It can be due to various hidden, inexplicable factors, for example, seasonality in weather data. Concept drift can be sudden, gradual, recurring, or incremental.
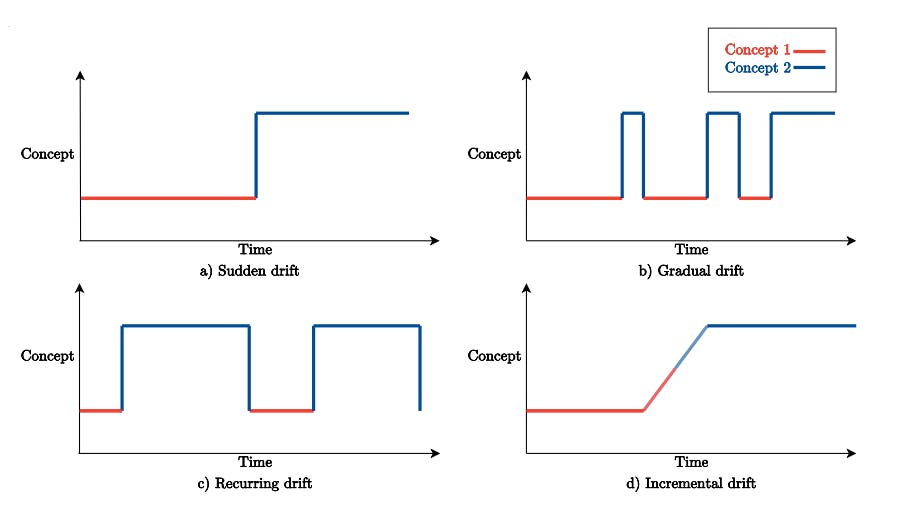
Types of Concept Drift in Machine Learning
Label Drift
This happens when the distribution of the target variable changes over time due to reasons like labeling errors or changes in labeling criteria.
What Is the Cause of Model Drift?
Understanding the root cause of machine learning model drift is vital. Several factors contribute to model drift in ML models, such as:
- Changes in the distribution of real-world data: When the distribution of the present data changes compared to the models’ training data. Since the models' training data contains outdated patterns, the model may not perform well on new data, reducing model accuracy.
- Changes in consumer behavior: When the target audience's behavior changes over time, the model's predictions become less relevant. This can occur due to changes in trends, political decisions, climate change, media hype, etc. For example, if a recommendation system is not updated to account for frequently changing user preferences, the system will generate stale recommendations.
- Model architecture: If a machine learning model is too complex, i.e., has many layers or connections, it can overfit small and unrepresentative training data and perform poorly on real-world data. On the other hand, if the model is too simple, i.e., it has few layers, it can underfit the training data and fail to capture the underlying patterns.
- Data quality issues: Using inaccurate, incomplete, or noisy training data can adversely affect an ML model’s performance.
- Adversarial attacks: Model drift can occur when the model is attacked by malicious actors to manipulate the input data, causing it to make incorrect predictions.
- Model and code changes: New updates or modifications to the model’s codebase can introduce drift if not properly managed.
Prominent Real-World Examples of Model Drift
Model drift deteriorates ML systems deployed across various industries.
Model Drift in Healthcare
Medical machine learning systems are mission-critical, making model drift significantly dangerous. For example, consider an ML system trained for cervical cancer screening. If a new screening method, such as the HPV test, is introduced and integrated into clinical practice, the model has to be updated accordingly, or its performance will deteriorate.
In Berkman Sahiner and Weijie Chen's paper titled Data Drift in Medical Machine Learning: Implications and Potential Remedies, they show that data drift can be a major cause of performance deterioration in medical ML models. They show that in the event of a concept shift leading to data drift, a full overhaul of the model is required because a discrete change, however small, may not produce the desired results.
Model Drift in Finance
Banks use credit risk assessment models when giving out loans to their customers. Sometimes, changes in economic conditions, employment rates, or regulations can affect a customer’s ability to repay loans. If the model is not regularly updated with real-world data, it may fail to identify higher-risk customers, leading to increased loan defaults.
Also, many financial institutions rely on ML models to make high-frequency trading decisions, and it is very common for market dynamics to change in split seconds.
Model Drift in Retail
Today, most retail companies rely on ML models and recommender systems. In fact, the global recommendation engine market is expected to grow from $5.17B in 2023 to $21.57B in 2028. Companies use these systems to determine product prices and suggest products to customers based on their past purchase history, browsing behavior, seasonality patterns, and other factors.
However, if there is a sudden change in consumer behavior, the model may fail to forecast demand accurately. For instance, a retail store wants to use an ML model to predict its customers' purchasing behavior for a new product. They have trained and tested a model thoroughly on historical customer data. But before the product launch, a competitor introduces a similar product, or the market dynamics are disrupted due to external factors, like global inflation. As a result, these events could significantly influence how consumers shop and, in turn, make the ML model unreliable.
Model Drift in Sales and Marketing
Sales and marketing teams tailor their campaigns and strategies using customer segmentation models. If customer behavior shifts or preferences change, the existing segmentation model may no longer accurately represent the customer base. This can lead to ineffective marketing campaigns and reduced sales.
Drawbacks of Model Drift in Machine Learning
Model drift affects various aspects of model performance and deployment. Besides decreased accuracy, it leads to poor customer experience, compliance risks, technical debt, and flawed decision-making.
Model Performance Degradation
When model drift occurs due to changes in consumer behavior, data distribution, and environmental changes, the model's predictions become less accurate, leading to adverse consequences, especially in critical applications such as healthcare, finance, and self-driving cars.
Poor User Experience
Inaccurate predictions can lead to a terrible user experience and cause users to lose trust in the application. This may, in turn, damage the organization's or product's reputation and lead to a loss of customers or business opportunities.
Technical Debt
Model drift introduces technical debt, which accumulates unaddressed issues that make it harder to maintain and improve the model over time. If model drift occurs frequently, data scientists and ML engineers may need to repeatedly retrain or modify the model to maintain its performance, adding to the overall cost and complexity of the system.
How to Detect Model Drift? The Role of Model Monitoring in Machine Learning
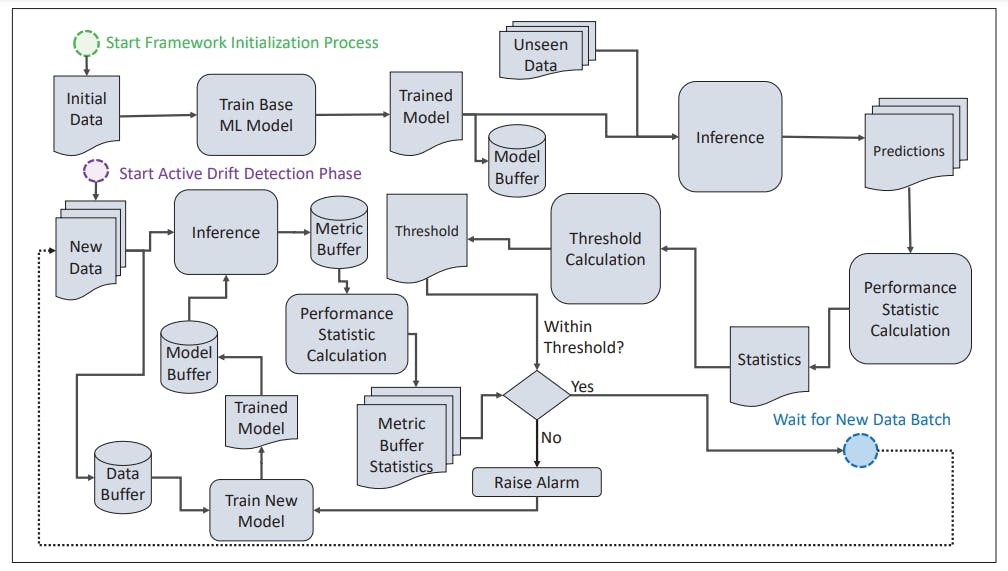
A Generalized Workflow of Model Drift Detection in Machine Learning
What is Model Monitoring in Machine Learning?
Model monitoring is continuously observing and evaluating the performance of machine learning models in the production environment. It plays a crucial role in ensuring that ML models remain accurate and reliable over time, especially in the face of model drift.
It involves logging and tracking the input data, model predictions, metadata, and performance metrics to identify changes affecting the model's accuracy and reliability.
Model monitoring is important for the following reasons:
- Identifying drift: Model monitoring helps to identify model drift in production. It enables you to be in control of your product, detect issues early on, and immediately intervene when action is needed. A robust monitoring system can notify data science teams when the data pipeline breaks, a specific feature is unavailable in production data, or the model becomes stale and must be retrained.
- Improving accuracy: By closely monitoring how the model performs in the production environment, you have insights to remedy various issues, such as model bias, labeling errors, or inefficient data pipelines. Taking corrective actions (such as model retraining or swapping models) upon detecting drift makes each version of your model more precise than the previous version, thus delivering improved business outcomes.
- Creating responsible AI: An important part of building responsible AI is understanding how and why it does what it does. Model monitoring helps with AI explainability by providing insights into the model's decision-making processes and identifying undesirable model behavior.
- Detecting outliers: Model monitoring tools provide automated alerts to help ML teams detect outliers in real time, enabling them to proactively respond before any harm occurs.
How to Detect Model Drift in Machine Learning?
Model drift can be detected using these two model drift detection techniques:
Statistical Tests
Statistical tests primarily involve comparing the predicted values from the ML model to the actual values to understand the performance. They usually vary in how the tests are carried out; let’s discuss a few below:
- Kolmogorov-Smirnov Test (KS Test): The Kolmogorov-Smirnov test compares the cumulative distribution functions (CDFs) of two samples to determine if they are statistically different. It is a non-parametric test that does not assume any specific distribution for the data.
- Kullback-Leibler (KL) Divergence: KL Divergence measures the difference between the model's predicted and actual data distribution. Its sensitivity to outliers and zero probabilities is an important characteristic you should be aware of. In practice, it means that when applying KL Divergence, carefully consider the nature of your data and distributions being compared.
- Jensen-Shannon Divergence (JSD): Jensen-Shannon Divergence measures the similarity between two probability distributions. It is suitable in cases where the underlying data distributions are not easily compared using traditional statistical tests, such as when the distributions are multimodal, complex, or have different shapes. It is less sensitive to outliers than KL Divergence, making it a robust choice for noisy data.
- Chi-Square: The Chi-square is a non-parametric test that measures the categorical data for a model over time. It is commonly used to test for independence between two categorical variables, their goodness-of-fit and homogeneity.
- Population Stability Index: PSI is a statistical measure that quantifies the difference between the distribution of two data ranges. It is a symmetric metric that monitors a variable against a baseline value during machine learning deployments. A value close to zero denotes no or minimal deviation, and a larger value denotes a possible drift in the data trend.
Other statistical tests include the Populations Stability Index, the K-Sample Anderson-Darling Test, and the Wasserstein distance.
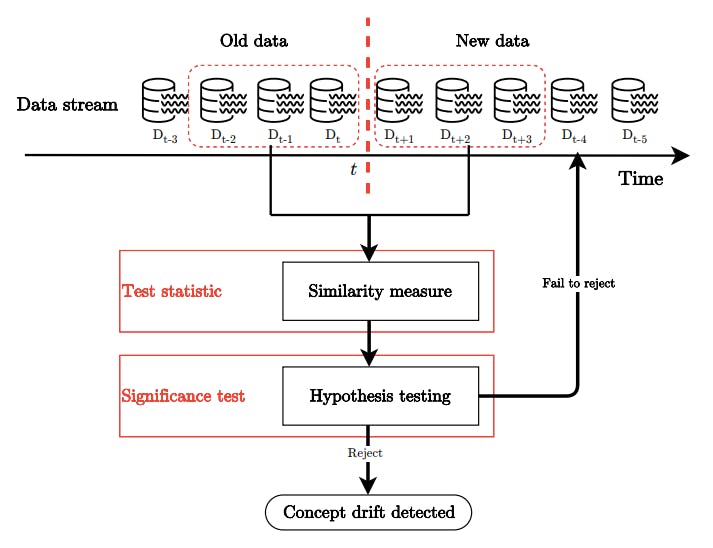
Concept Drift Detection Framework
ML Monitoring Tools
Monitoring tools enable teams to debug models, find and fix data errors, and run automated tests to analyze model errors. They can deliver detailed explainability reports to teams for quick mitigation. Encord Active is a prominent example of a machine learning monitoring tool.
Monitoring Model Drift with Encord Active (EA)
EA is a robust evaluation and monitoring platform that can measure numerous model performance metrics to identify significant data shifts or model deviations. It provides a real-time chart to monitor the distribution of your image metrics or properties over the entire training set and also model quality evaluation metrics.
The following steps will show you how to monitor your model’s predictions when you import a project from Annotate to Active Cloud.
Step 1: Choose a Project
Projects within Encord represent the combination of an ontology, dataset(s), and team member(s) to produce a set of labels. Choose the project containing the datasets you imported from Annotate. This example uses the COCO 2017 dataset imported from Annotate:
Step 2: Import your Model Predictions to Active Cloud
Active provides metrics and analytics to optimize your model's performance. You must import predictions to Active before viewing metrics and analytics on your model performance. You can import them programmatically using an API (see the docs) or the user interface (UI).
In this walkthrough, we imported a set of predictions from a MaskRCNN model trained and evaluated on the COCO 2017 dataset.
Step 3: Explore your Model's Performance Under the Model Evaluation Tab
Navigate to the Model Evaluation tab to see the model performance metrics:
Click on Model Performance to see a dashboard containing the performance metrics peculiar to your model:
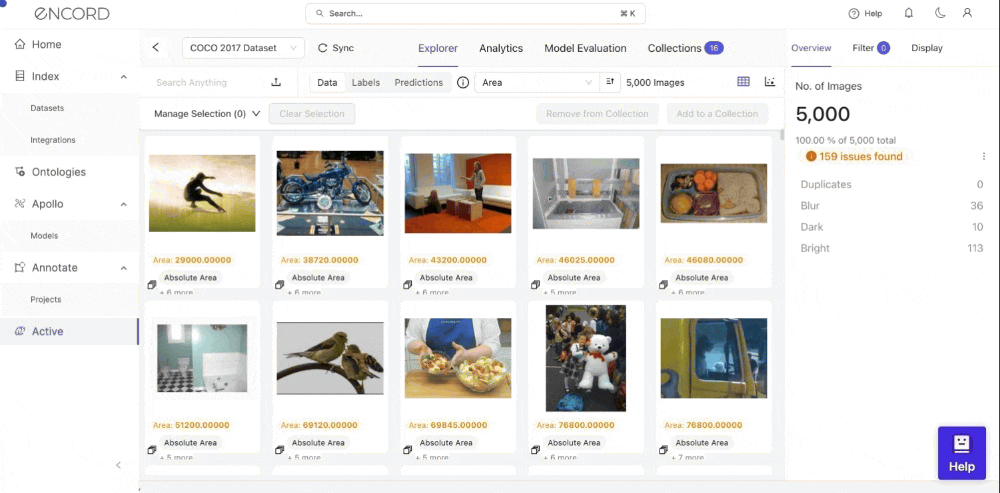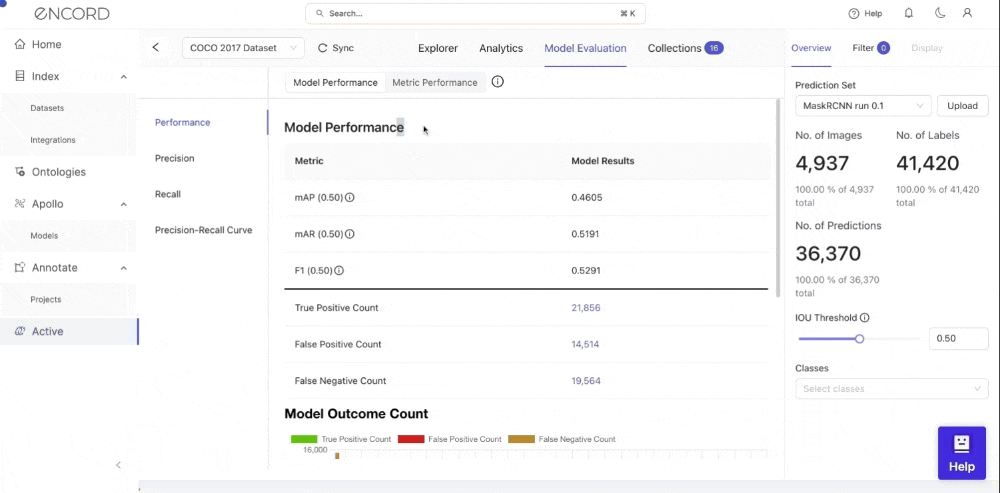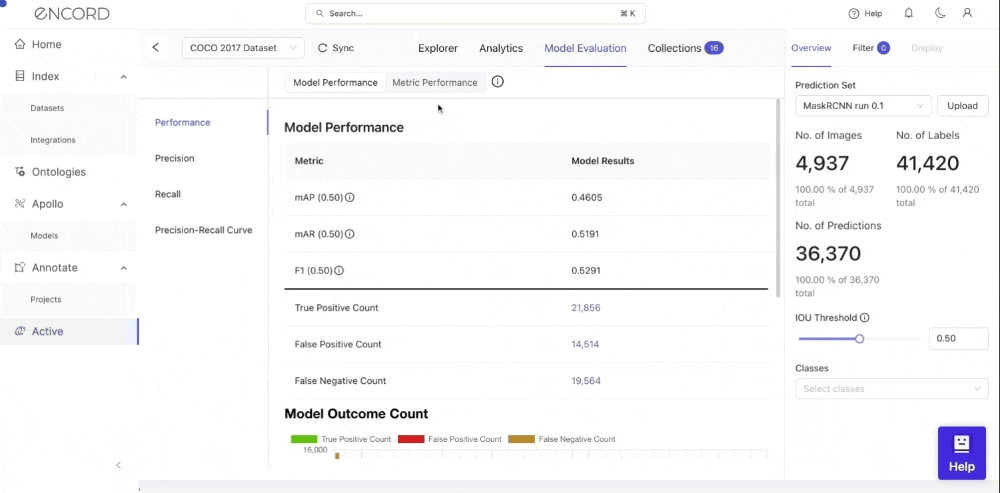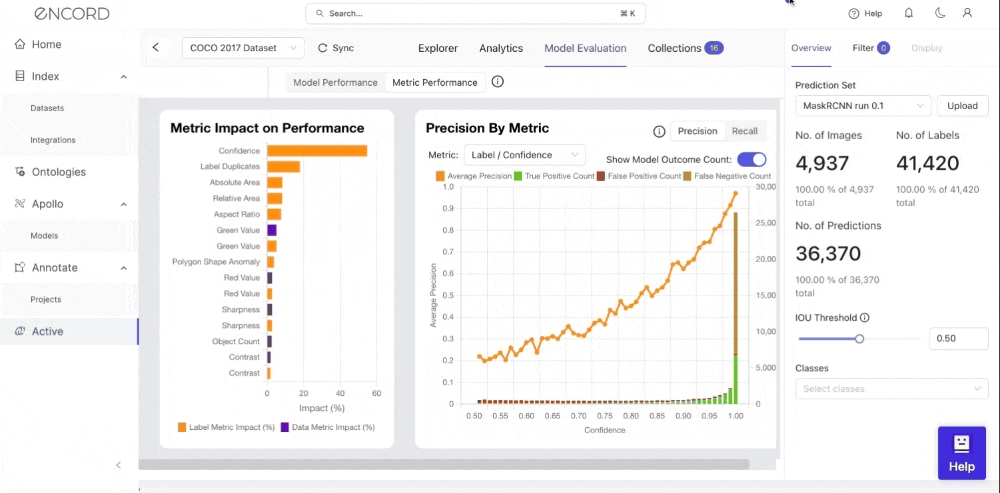
Visualize the important performance metrics (Average-Precision (mAP), Average-Recall (mAR), F1, True Positive Count, False Positive Count, False Negative Count) for your model.
You can also visualize your model’s performance metrics based on different classes and intersection-over-union (IoU) thresholds. Active supports performance metrics for bounding boxes (object detection), polygons (segmentation), polylines, bitmasks, and key points.
Best Practices for Improving Model Performance and Reducing Model Drift
Choosing the Correct Metrics
Different ML models require different evaluation and monitoring metrics to capture their performance accurately. There must be a suitable baseline performance to compare metric values. The chosen metrics must align with the specific goals and characteristics of the model. For instance,
- Classification models are better evaluated using accuracy, precision, and recall metrics.
- Regression models are assessed using MAE, MSE, RMSE, or R-squared.
- Natural language processing models can leverage BLEU, ROUGE, and perplexity metrics.
When choosing your metric, it is important to understand its underlying principles and limitations. For example, a model trained on imbalanced data may exhibit high accuracy values but fail to account for less frequent events. In such cases, metrics like the F1 score or the AUC-ROC curve would provide a more comprehensive assessment.
Metric Monitoring
Continuously tracking the model's performance metrics, such as accuracy, precision, recall, F1 score, and AUC-ROC curve, can help identify any deviations from its expected performance. This can be done using automated monitoring tools or manually reviewing model predictions and performance reports.
Analyzing Data Distribution
Constantly monitor the data distribution of input features and target variables over time to detect any shifts or changes that may indicate model drift. This can be done using statistical tests, anomaly detection algorithms, or data visualization techniques.
Setting Up Data Quality Checks
Accurate data is necessary for good and reliable model performance. Implementing robust data quality checks helps identify and address errors, inconsistencies, or missing values in the data that could impact the model's training and predictions. You can use data visualization techniques and interactive dashboards to track these data quality changes over time.
Leverage Automated Monitoring Tools
Automated monitoring tools provide an easier way to track model performance and data quality across the ML lifecycle. They provide real-time alerts, historical tracking with observability, and logging features to facilitate proactive monitoring and intervention. Automated tools also reduce the team’s overhead costs.
Continuous Retraining and Model Versioning
Periodically retraining models with updated data helps teams adapt to changes in data distribution and maintain optimal performance. Retraining can be done manually or automated using MLOps deployment techniques, which include continuous monitoring, continuous training, and continuous deployment as soon as training is complete.
Model versioning allows for tracking the performance of different model versions and comparing their effectiveness. This enables data scientists to identify the best-performing model and revert to previous versions if necessary.
Human-in-the-Loop Monitoring (HITL)
It is very important to have an iterative review and feedback process conducted by expert human annotators and data scientists (HITL), as it can:
- Help validate the detected model drifts and decide whether they are significant or temporary anomalies.
- Help decide when and how to retrain the model when model drift is detected.

Model Drift: Key Takeaways
Model drift in machine learning can create significant challenges for production-deployed ML systems. However, applying the above mentioned best practices can help mitigate and reduce model drift. Some key points you must remember include:
- Model drift occurs due to changes in training or production data distribution.
- It can also occur due to extensive changes in the system code or architecture.
- Adversarial attacks on ML models can introduce data drift and result in performance degradation.
- Model drift can severely affect critical domains like healthcare, finance, and autonomous driving.
- You can detect model drift by applying statistical tests or automated model ML monitoring tools.
- You must select the right set of metrics to evaluate and monitor an ML system.
- You must set up data quality checks to minimize data drift across training and production workflows.
- Retrain the model after specific intervals to keep it up-to-date with changing environments.
Frequently asked questions
Model drift refers to the degradation of a machine learning model's predictive performance over time due to changes in the data distribution, such as the statistical properties of the input features, the target variables, or how the input features relate to the targets.
Tackling model drift in machine learning involves a combination of strategies, such as using automated monitoring tools for continuous monitoring, data quality checks, data change detection, continuous retraining, human-in-the-loop monitoring, etc.
Model drift can be classified into three main types: Data drift or covariate shift, label drift, and concept drift.
You can monitor a machine learning model by logging and tracking input data, output predictions, and model performance metrics.
ML model monitoring techniques include statistical tests (Kolmogorov-Smirnov, KL Divergence, Jensen-Shannon Divergence, Chi-Square) and the use of ML monitoring tools such as Encord Active, Arize AI, Evidently AI, WhyLabs, and others.
Checking if a machine-learning model performs well involves understanding its baseline performance, selecting the appropriate evaluation metrics, and monitoring its performance over time.
Model drift is the gradual or sudden degradation of a machine learning model's predictive performance over time due to changes in the data distribution. Data drift is a subset of model drift and refers explicitly to changes in the input feature distribution over time.
In autonomous driving systems, model drift can occur due to irregular environmental conditions, changing government road safety policies, or abrupt driving behavior.
Encord benchmarks model performance using extensive datasets and a dedicated ground truth test set. This process not only involves testing on proprietary datasets but also comparing results with public datasets to ensure alignment with state-of-the-art performance as documented in academic literature.
For teams that retrain models frequently, Encord provides automation and efficiency, reducing the time spent on manual annotation and data preparation. This allows teams to focus on refining their models and improving performance, ultimately leading to faster deployment and iteration cycles.
The typical workflow for Encord customers follows the MLops cycle, beginning with data selection for the annotation process. Encord then prepares the data for model training, whether using open-source or proprietary models, and evaluates the model's performance against the prepared data.
Encord enables users to quickly annotate and adapt to changing object variants through its flexible annotation tools. This is particularly beneficial for organizations operating in unpredictable environments, where object appearances can evolve significantly over short periods.
Encord offers support for migrating data from other platforms, including rewriting scripts that point to the previous platform. The migration process can be planned out to ensure a smooth transition, and Encord's team can assist in moving the data and setting up integrations.
It's crucial for teams to evaluate the risks associated with changing annotation tools during peak operational seasons. Encord recommends planning transitions during calmer periods to minimize disruptions and ensure a smooth integration of new tools into existing workflows.
Ramp times for integrating external annotation sources with Encord can vary based on specific project requirements. However, our team is dedicated to working closely with clients to ensure a smooth setup process and timely adaptation to meet project deadlines.
Encord typically starts by offering solutions as a cloud service, allowing users to test functionality. Once satisfied, teams can transition to on-premise models, ensuring that the infrastructure aligns with their operational needs and preferences.
Encord ensures that you receive regular updates on new features through your customer success manager, who will also assist in integrating these features into your workflow for optimal usage.