Setting Up a Computer Vision Testing Platform

When machine learning (ML) models, especially computer vision (CV) models, move from prototyping to real-world application, they face challenges that can hinder their performance and reliability. Gartner's research reveals a telling statistic: just over half of AI projects make it past the prototype stage into production. This underlines a critical bottleneck—the need for rigorous testing.
Why do so many models fail to make it to real-world applications? At Encord, ML teams tell us that model performance bottlenecks include:
- the complexity of ML models and diverse datasets,
- the need for testing processes that can handle large amounts of data,
- the need for automation to handle repetitive tasks,
- and the need for teams to collaborate to improve ML systems.
This article will teach you the intricacies of setting up a computer vision (CV) testing platform. You will gain insights into the essence of thorough test coverage—vital for the unpredictable nature of CV projects—and learn about managing test cases effectively. You will also learn how collaborative features can be the centerpiece of successful testing and validation.
By the end of the article, you should understand what it takes to set up a CV testing platform.
Challenges Faced by Computer Vision Models in Production
Computer Vision (CV) models in dynamic production environments frequently encounter data that deviates significantly from their training sets—be it through noise, missing values, outliers, seasonal changes, or general unpredictable patterns. These deviations can introduce challenges that compromise model performance and reliability.
Building reliable, production-ready models comes with its own set of challenges. In this section, you will learn why ensuring the reliability of CV models is a complex task.
We are going to look at the following factors:
- Model Complexity: The intricate architecture of CV models can be challenging to tune and optimize for diverse real-world scenarios.
- Hidden Stratification: Variations within classes the model hasn't explicitly trained on can lead to inaccurate predictions.
- Overfitting: A model might perform exceptionally well on the training data but fail to generalize to new, unseen data.
- Model Drift: Changes in real-world data over time can gradually decrease a model's accuracy and applicability.
- Adversarial Attacks: Deliberate attempts to fool models using input data crafted to cause incorrect outputs.
Understanding these challenges is the first step toward building robust, production-ready CV models. Next, we will explore strategies to mitigate these challenges, ensuring your models can withstand the rigors of real-world application. 🚀
Model Complexity
As CV models, particularly visual foundation models (VFMs), visual language models (VLMs), and multimodal AI models, grow in complexity, they often become 'black boxes.' This term refers to the difficulty in understanding how these models make decisions despite their high accuracy.
Because these models have complicated, multi-layered architectures with millions of parameters, it is hard to figure out the reasoning behind their outputs. Confidence in the model's performance can be challenging, mainly when it produces unexpected predictions.
Consider a security surveillance system with advanced visual recognition to spot suspicious activity. This system, powered by a complex visual language model (VLM), is trained on lots of video data encompassing various scenarios from numerous locations and times.
The system can accurately identify threats like unattended bags in public spaces and unusual behavior, but its decision-making process is unclear. Security personnel may struggle to understand why the system flags a person or object as suspicious.
The model may highlight factors like an object's size, shape, or movement patterns, but it is unclear how these factors are synthesized to determine a threat. This opacity raises concerns about the model's trustworthiness and the potential for false positives or negatives.
The lack of interpretability in such CV models is not just an academic issue but has significant real-world consequences. It affects the confidence of those relying on the system for public safety, potentially leading to mistrust or misinterpretation of the alerts generated.
Hidden Stratification
Precision, accuracy, recall, and mean Average Precision (mAP) are commonly used metrics when evaluating the performance of CV models. However, it's important to remember that these metrics may not provide a complete picture of the model's performance. A model could be very accurate when trained on a specific dataset, but if that dataset doesn't represent the real-world scenario, the model may perform poorly.
This dilemma is called hidden stratification. Hidden stratification occurs when the training data doesn't have enough representative examples of certain groups or subgroups.
For instance, a model trained on a dataset of images of primarily Caucasian patients may struggle to accurately diagnose skin cancer in black patients. This could raise serious inclusivity concerns, especially in mission-critical applications.
Overfitting
A model could learn so well from the training data that it cannot make correct predictions on new data, which could lead to wrong predictions on real-world data in production systems.
You have probably encountered this before: You train a model to classify images of cats and dogs with a 1000-image dataset split evenly between the two classes and trained for 100 epochs. The model achieves a high accuracy of 99% on the training data but only manages 70% accuracy on a separate test dataset.
The discrepancy suggests overfitting, as the model has memorized specific details from the training images, like ear shape or fur texture, rather than learning general features that apply to all cats and dogs.
Model Drift
You consider a model “drifting” when its predictive accuracy reduces over time when deployed to production. If you do not build your ML system so that the model can adapt to real-world data changes, it might experience sudden drifts or slow decay over time, depending on how your business patterns change.
One practical example is to consider an autonomous vehicle's pedestrian detection system. Initially trained on extensive datasets covering various scenarios, such a system might still experience model drift due to unforeseen conditions, like new types of urban development or changes in pedestrian behavior over time.
For instance, introducing electric scooters and their widespread use on sidewalks presents new challenges not in the original training data, potentially reducing the system's accuracy in identifying pedestrians.
Adversarial Attacks
Adversarial attacks consist of deliberately crafted inputs that fool models into making incorrect predictions. These attacks threaten ML applications, from large language models (LLMs) to CV systems. While prompt injection is a known method affecting text-based models, CV models face similar vulnerabilities through manipulated images (image perturbation) or objects within their field of view.
A notable demonstration of this was by researchers at the University of California, Berkeley, in 2016. They executed an adversarial attack against a self-driving car system using a simple sticker, misleading the car's vision system into misidentifying the type of vehicle ahead. This manipulation caused the self-driving car to stop unnecessarily, revealing how seemingly innocuous input data changes can impact decision-making in CV applications.
Adversarial attacks are challenging because of their subtlety and precision. Only minor alterations are often needed to deceive an AI system, making detection and prevention particularly challenging.
This underscores the critical importance of rigorously testing ML models to identify and mitigate such vulnerabilities.
You can make CV systems more resistant to these attacks by testing them thoroughly and using adversarial simulation as part of your process for reliable applications.
Testing Computer Vision Models and Applications
Testing CV applications is more complex than testing traditional software applications. This is because the tests only partially depend on the software. Instead, they rely on factors such as the underlying business problem, dataset characteristics, and the models you trained or fine-tuned. Therefore, establishing a standard for testing CV applications can be complex.
Understanding the Computer Vision Testing Platform
A CV test platform forms the backbone of a reliable testing strategy. It comprises an ecosystem of tools and processes that facilitate rigorous and efficient model evaluation. The platform can help teams automate the testing process, monitor test results over time, and rectify issues with their models.
Essential components of a robust CV testing platform include:
- Test Data Management: Involves managing the test data (including versioning and tracing lineage) to mirror real-world scenarios critical for models to understand such conditions. With this component, you can manage the groups and sub-groups (collections) to test your model against before to ensure production readiness.
- Test Reporting: An effective reporting system (dashboards, explorers, visualizations, etc.) is instrumental in communicating test outcomes to stakeholders, providing transparency, and helping to track performance over time.
- Model Monitoring: The platform should also include a component that monitors the model's performance in production, compares it against training performance, and identifies any problems. The monitoring component can track data quality, model metrics, and detect model vulnerabilities to improve the model’s robustness against adversarial attacks.
- Test Automation: Setting up automated testing as part of a continuous integration, delivery, and testing (CI/CD/CT) pipeline allows you to configure how you validate the model behavior. This ensures that models work as expected by using consistent and repeatable tests.
Setting Up Your Computer Vision Testing Platform
Having established what the CV testing platform is and its importance, this section will describe what a good platform setup should look like.
1. Define Test Cases
In ML, test cases are a set of conditions used to evaluate an ML model's performance in varying scenarios and ensure it functions as expected. Defining robust model test cases is crucial for assessing model performance and identifying areas to improve the model’s predictive abilities.
For instance, you trained a model on diverse driving video datasets and parking lot videos. You then used it on a dashcam system to count the number of vehicles while driving and in a parking lot. The successfully trained model performs admirably in Boston with cameras installed on various dashcams and across parking lots.
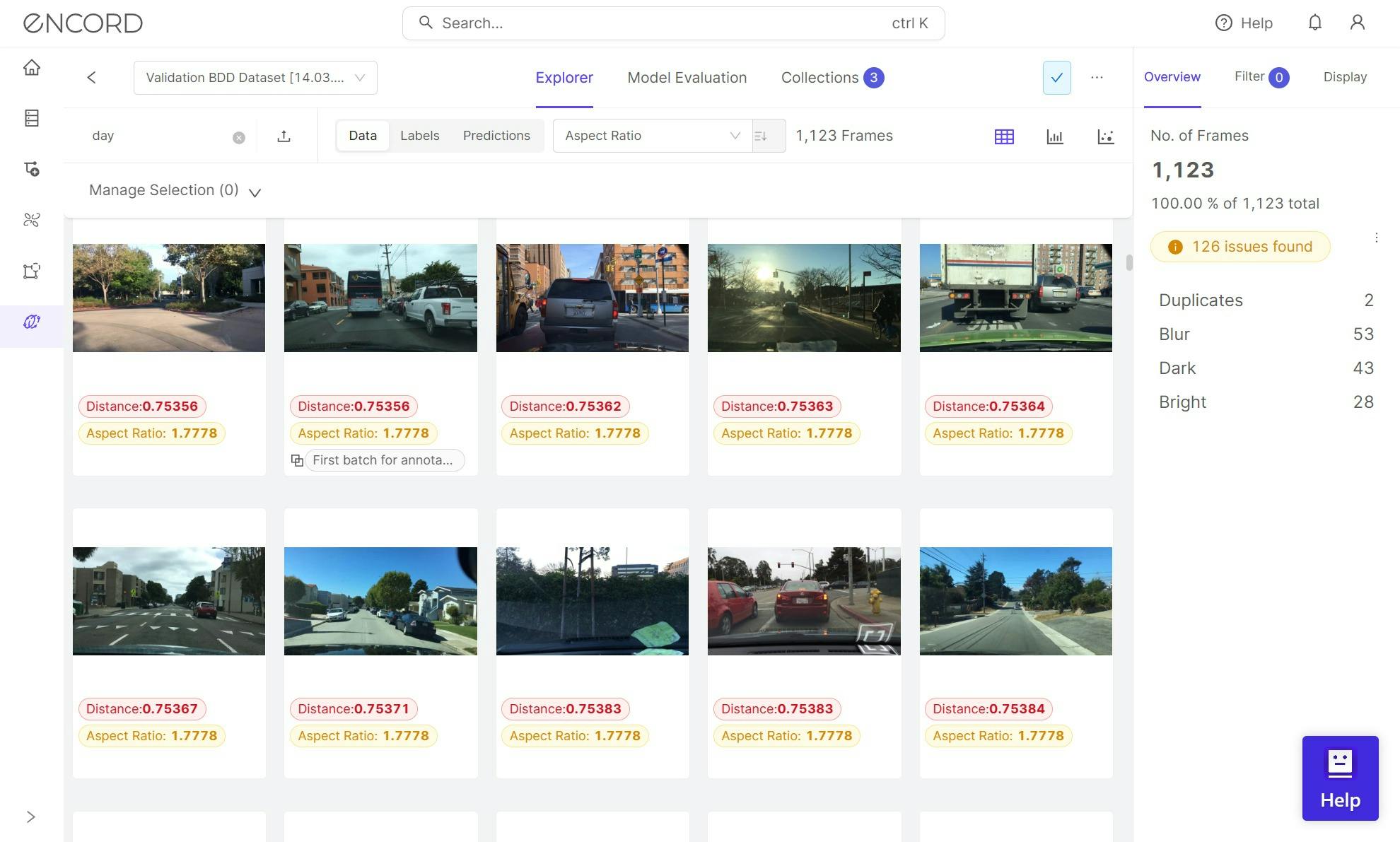
An example of the Berkley Diverse Driving Dataset in Encord Active.
Stakeholders are satisfied with the proof-of-concept and are asking to scale the model to include additional cities. Upon deploying the model in a new area in Boston and another town, maybe Minnesota, new scenarios emerge that you did not consider.
In one parking garage in Boston, camera images are slightly blurred, contrast levels differ, and vehicles are closer to the cameras. In Minnesota, snow is on the ground, the curbside is different, various lines are painted on the parking lot, and new out-of-distribution car models (not in the training data) are present.

Production scenario for the CV model in a Minnesota snowy parking lot (left) and Boston parking house in a dashcam (right).
These scenarios are strange to the model and will harm its performance. That is why you should consider them test cases when testing or validating the model's generalizability.
Defining the test cases should begin with preparing a test case design. A test case design is the process of planning and creating test cases to verify that a model meets its requirements and expected behavior. It involves identifying what aspects of the ML model need to be tested and how to test them.
Steps in test case design
Define test objectives:
Clearly state what the tests are expected to achieve. This starts with identifying failure scenarios, which may include a wide range of factors, such as changing lighting conditions, vehicle types, unique perspectives, or environmental variations, that could impact the model's performance.
For example, in a car parking management system, some of the potential edge cases and outliers could include snow on the parking lot, different types of lines painted on the parking lot, new kinds of cars that weren't in the training data, other lighting conditions at varying times of day, different camera angles, perspectives, or distances to cars, and different weather conditions, such as rain or fog.
By identifying scenarios where the model might fail, you can develop test cases that evaluate the model's ability to handle these scenarios effectively. After defining the test objectives, the next step is selecting test data for each case.
Select test data and specify test inputs:
When selecting input data, consider a diverse range of scenarios and conditions. This ensures that the data is representative of the defined test cases, providing a comprehensive understanding of the system or process being analyzed.
Be sure to include edge cases in your selection, as they can reveal potential issues or limitations that may not be apparent with only typical data.
In the car parking management system above, obtain samples of video images from different locations and parking lot types.
Determine expected ML model outcomes and behaviors:
Specify each test case's expected results or behaviors. This includes defining what the model should predict or what the software should do in response to specific inputs.
Based on the failure mode scenarios of the model in the car parking management system, here are some recommendations:
- The model should achieve a mean Average Precision (mAP) of at least 0.75 for car detection when cars are partially covered or surrounded by snow and in poorly lit parking garages.
- The model's accuracy should be at least 98% for partially snow-covered parking lines.
Create test cases:
Document each test case with inputs, actions, and expected outcomes for clear and effective evaluation.
Execute test cases:
Execute the prepared test cases systematically to evaluate the ML model. Where possible, utilize automated testing to ensure efficiency and consistency. Record the actual outcomes to facilitate a detailed comparison with the expected results.
Analyzing results:
Review the outcomes using established metrics such as precision, recall, and f1-score. Document any deviations and conduct a thorough analysis to uncover the root cause of each discrepancy. Common issues may include model overfitting, data bias, or inadequate training.
Iterative improvement:
Upon identifying any issues, take corrective actions such as adjusting the model's hyperparameters, enriching the dataset with more samples and subsets, or refining the features.
After modifications, re-run the test cases to verify improvements. This iterative process is essential for achieving the desired model performance and reliability.
Keep iterating through this process until the model's performance aligns with the objectives defined in your test cases.
2. Compute Environment
Most CV tests involving complex models and large datasets are computationally intensive. Adequate computing resources are essential for efficient and effective testing. Without these resources, you may encounter scalability issues, an inability to manage large visual test datasets, longer testing times, crashing sessions, insufficient test coverage, and a higher risk of errors.
Strategies for ensuring adequate compute resources for CV testing:
- Resource estimation: Begin assessing the computational load by considering the model's size and complexity, dataset volume, and the number of tests. This will help in estimating the required resources to ensure tests run smoothly.
- Using cloud computing: Use services from cloud providers such as AWS, Azure, or GCP. These platforms provide scalable resources to accommodate varying workloads and requirements.
- Tools like Encord Active—a comprehensive CV testing and evaluation platform—streamline the process by connecting to cloud storage services (e.g., AWS S3, Google Cloud Storage, Azure Blob Storage) to retrieve test data.
- Distributed computing: Use distributed computing frameworks like Apache Spark to distribute CV tests across multiple machines. This can help reduce the time it takes to execute the tests.
- Optimization of tests: Optimize your CV tests by choosing efficient algorithms and data structures to minimize the computational resources required.
ML teams can ensure their models are fully tested and ready for production by carefully planning how to use modern cloud-based solutions and distributed computing.
3. Running Tests and Analyzing Results
For a smooth CV testing process, follow these comprehensive steps:
- Data and code preparation: Transfer the test data and code to the computing environment using secure file transfer methods or uploading directly to a cloud storage service.
- Install dependencies: Install the CV testing framework or tool you have chosen to work with and any additional libraries or tools required for your specific testing scenario.
- Configure the test environment: Set the necessary environment variables and configuration parameters. For example, define database connection strings, store secrets, or specify the path to the dataset and model artifacts.
- Execute tests: Run the tests manually or through an automation framework. Encord Active, for instance, can facilitate test automation by computing quality metrics for models based on the predictions and test data.
- Collect and analyze results: Gather the test outputs and logs, then analyze them to evaluate the model's performance. This includes mAP, Mean Square Error (MSE), and other metrics relevant to the use case and model performance.
4. Automating ML Testing with Continuous Integration, Delivery, and Testing (CI/CD/CT)
Continuous integration, delivery (or deployment), and testing for CV automates the process of building, testing, and deploying the models. This automation is crucial in ensuring that models are reliable and issues are identified and resolved early on.
Steps for a robust CI/CD/CT pipeline in ML:
- Pipeline trigger: Automate the pipeline to trigger upon events like code commits or set it for manual initiation when necessary.
- Code repository cloning: The pipeline should clone the latest version of the codebase into the test environment, ensuring that tests run on the most current iteration.
- Dependency installation: The pipeline must automatically install dependencies specific to the model, such as data processing libraries and frameworks.
- Model training and validation: In addition to training, the pipeline should validate the ML model using a separate dataset to prevent overfitting and ensure that the model generalizes well.
- Model testing: Implement automated tests to evaluate the model's performance on out-of-distribution, unseen data, focusing on the model metrics.
- Model deployment: The pipeline could automatically ship the model upon successful testing. Depending on the pipeline configuration, this may involve a soft deployment to a staging environment or a full deployment to production.
Platforms like GitHub Actions, CircleCI, Jenkins, and Kubeflow offer features that cater to the iterative nature of ML workflows, such as experiment tracking, model versioning, and advanced deployment strategies.
Advantages of CI/CD/CT for computer vision
- Enhanced model quality: Rigorous testing within CI/CT pipelines contributes to high-quality, reliable models in production environments.
- Reduced error risk: Automation minimizes human error, especially during repetitive tasks like testing and deployment.
- Efficiency in development: Automating the build-test-deploy cycle accelerates development and enables rapid iteration.
- Cost-effectiveness: The practices reduce resource waste, translating to lower development costs.
Best practices
By incorporating best practices and being mindful of common pitfalls, you can make your pipeline robust and effective. These practices include:
Ensure your pipeline includes:
- Data and model versioning to track changes over time.
- Comprehensive test suites that mirror real-world data and scenarios.
- Regular updates to the test suite reflect new insights and data.
Pitfalls to avoid:
- Avoid underestimating the complexity of models within the CI pipeline.
- Prevent data leakage between training and validation datasets.
- Ensure that the CI pipeline is equipped to handle large datasets efficiently.
Throughout this article, you have explored the entire workflow for setting up a testing platform. You might have to configure and maintain several different components.
Setting these up might require cross-functional and collaborative development and management efforts. So, most teams we have worked with often prefer using a platform incorporating all these features into one-click or one-deploy configurations. No spinning up servers, using tools that are not interoperable, or maintaining various components.
Enter CV testing platforms!
Using Platforms for Testing Computer Vision Models Over Building One
Various platforms offer tools for testing ML models. Some examples are Encord Active, Kolena, Robust Intelligence, and Etiq.ai. Encord Active, for instance, excels at debugging CV models using data-centric quality metrics to uncover hidden model behaviors.
It provides a suite of features for organizing test data, creating Collections to analyze model performance on specific data segments, and equipping teams to devise comprehensive tests.
With Active Cloud, you can manage test cases and automatically compute metrics for your models through a web-based platform or the Python client SDK (to import model predictions).

Conclusion: Using A Robust Testing Platform
Throughout this article, you have learned that a robust testing platform is vital to developing reliable and highly-performant computer vision models. A well-set-up testing platform ensures comprehensive test coverage, which is crucial for verifying model behavior under diverse and challenging conditions.
Managing your test cases and seamless team collaboration is also essential for addressing issues like hidden stratification—where models perform well on average but poorly on subgroups or slices—overfitting, and model drift over time.
Remember to document the process and results of your accountability tests to inform future testing cycles. Regularly reviewing and refining your test strategy is key to maintaining an effective model development lifecycle.
With the continuous advancements in traditional and foundation ML models over the next few years, we expect the integration of robust testing platforms to become increasingly critical. They will be pivotal in driving the success of LLM and ML applications, ensuring they deliver ongoing value in real-world scenarios.
Your ML team's goal should be clear: to enable the development of CV models that are not only high-performing but also resilient and adaptable to the ever-changing data landscape they encounter.
Frequently asked questions
Testing involves evaluating data quality, using performance metrics, assessing robustness under varied conditions, conducting adversarial tests, and analyzing model interpretability. These strategies ensure accuracy, reliability, and transparency across diverse scenarios.
Machine learning testing focuses on the probabilistic outcomes and data dependency of models, requires assessing complex, 'black box' behaviors, and deals with the continuous evolution and updating of models based on new data.
Prioritize testing based on critical functionality and high-risk areas, focusing on core features and scenarios where failures would have the most significant impact.
Yes, testing varies by industry due to different accuracy, explainability, and regulatory compliance needs, with healthcare prioritizing accuracy and explainability, and e-commerce focusing on user engagement.
Performance metrics alone don't address potential biases, the model's robustness against adversarial inputs, or the need for decision interpretability.
Effective testing requires diverse and representative datasets, automated testing frameworks for continuous evaluation, integration testing within the system, and human-in-the-loop for subjective judgments.
Maintenance costs vary based on model complexity, update frequency, hosting infrastructure, and compliance requirements. More complex and frequently updated models generally incur higher costs.
Encord supports the deployment of computer vision models on various devices through its adaptable annotation platform, which ensures compatibility across different operating systems and environments. This flexibility is crucial for organizations aiming to implement solutions in diverse settings, such as outdoor waste management operations.
Encord offers comprehensive tools for model training and evaluation, including support for various model types like object detection and segmentation. The platform facilitates the assessment of label quality and model performance, enabling users to refine their models based on rich analytics and feedback loops.
Encord is designed to assist teams in moving their computer vision models from experimental phases to production. With a focus on quality annotation, data curation, and model monitoring, Encord ensures that teams have the necessary tools and insights to deploy reliable models confidently.
Using Encord's platform enables visual inspection teams to accelerate their model development processes. With integrated annotation tools and data management features, teams can quickly iterate on their models, improving accuracy and efficiency in identifying defects during manufacturing.
During a demonstration of the Encord platform, users can expect a broad overview of its capabilities, with opportunities to delve into specific features relevant to their needs. The goal is to showcase how Encord can integrate into existing processes and enhance data management.
Encord enables teams to assess model performance by tracking how varying image qualities impact outcomes. Users can leverage tools to analyze results in real-time, helping to identify the effectiveness of different data types and make informed decisions on model adjustments.
Encord supports teams by offering a comprehensive platform that allows for effective testing of machine learning models. This includes validating model outputs and ensuring that they meet the required standards for accuracy and reliability.
Absolutely! Encord encourages potential customers to explore our platform through demonstrations and tailored evaluations. This process allows teams to assess how our features can align with their workflows and meet their specific needs.
No, Encord does not support model training, serving, or inference. The platform focuses exclusively on data preparation, helping users create high-quality pre-labeled data that can be utilized in their own ecosystems for model training.
Absolutely! Encord offers the opportunity for potential customers to conduct a proof of concept. This allows users to test the platform's features and tools to ensure it meets their requirements before making a commitment.