MM1: Apple’s Multimodal Large Language Models (MLLMs)

Introduction to Multimodal AI
Multimodal AI models are a type of artificial intelligence model that can process and generate multiple types of data, such as text, images, and audio. These models are designed to understand the world in a way that is closer to how humans do, by integrating information from different modalities.
Multimodal AI models typically use a combination of different types of AI systems, each designed to process a specific type of data. For example, a multimodal AI model might use a convolutional neural network (CNN) to process visual data, a recurrent neural network (RNN) to process text data, and a transformer model to integrate the information from CNN and RNN.
The outputs of these networks are then combined, often using techniques such as concatenation or attention mechanisms, to produce a final output. This output can be used for a variety of tasks, such as classification, generation, or prediction.
Overview of Multimodal Large Language Models (MLLMs)
Multimodal Large Language Models (MLLMs) are generative AI systems that combine different types of information, such as text, images, videos, audio, and sensory data, to understand and generate human-like language. These models revolutionize the field of natural language processing (NLP) by going beyond text-only models and incorporating a wide range of modalities.
Here's an overview of key aspects of Multimodal Large Language Models:
Architecture
MLLMs typically extend architectures like Transformers, which have proven highly effective in processing sequential data such as text. Transformers consist of attention mechanisms that enable the model to focus on relevant parts of the input data. In MLLMs, additional layers and mechanisms are added to process and incorporate information from other modalities.
Integration of Modalities
MLLMs are designed to handle inputs from multiple modalities simultaneously. For instance, they can analyze both the text and the accompanying image in a captioning task or generate a response based on both text and audio inputs. This integration allows MLLMs to understand and generate content that is richer and more contextually grounded.
Pre-Training
Like their unimodal counterparts, MLLMs are often pre-trained on large datasets using self-supervised learning objectives. Pre-training involves exposing the model to vast amounts of multimodal data, allowing it to learn representations that capture the relationships between different modalities. Pre-training is typically followed by fine-tuning on specific downstream tasks.
State-of-the-Art Models
- CLIP (Contrastive Language-Image Pre-training): Developed by OpenAI, CLIP learns joint representations of images and text by contrasting semantically similar and dissimilar image-text pairs.
- GPT-4: It showcases remarkable capabilities in complex reasoning, advanced coding, and even performs well in multiple academic exams.
- Kosmos-1: Created by Microsoft, this MLLM os trained from scratch on web-scale multimodal corpora, including arbitrary interleaved text and images, image-caption pairs, and text data.
- PaLM-E: Developed by Google, PaLM-E integrates different modalities to enhance language understanding.
Understanding MM1 Models
MM1 represents a significant advancement in the domain of Multimodal Large Language Models (MLLMs), demonstrating state-of-the-art performance in pre-training metrics and competitive results in various multimodal benchmarks. The development of MM1 stems from a meticulous exploration of architecture components and data choices, aiming to distill essential design principles for building effective MLLMs.
MM1 Model Experiments: Key Research Findings
Architecture Components
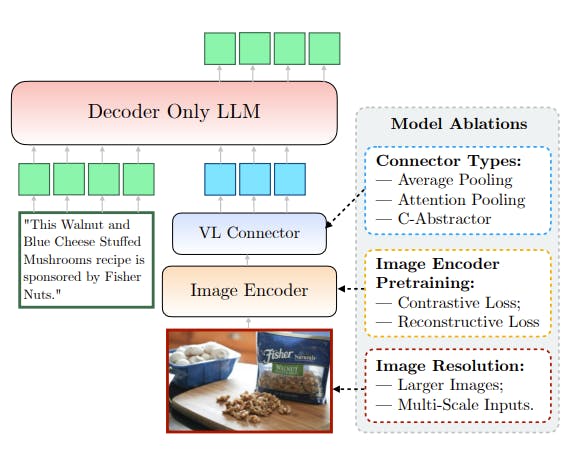
- Image Encoder: The image encoder's design, along with factors such as image resolution and token count, significantly impacts MM1's performance. Through careful ablations, it was observed that optimizing the image encoder contributes substantially to MM1's capabilities.
- Vision-Language Connector: While important, the design of the vision-language connector was found to be of comparatively lesser significance compared to other architectural components. It plays a crucial role in facilitating communication between the visual and textual modalities.
Data Choices
- Pre-training Data: MM1 leverages a diverse mix of image-caption, interleaved image-text, and text-only data for pre-training. This combination proved pivotal in achieving state-of-the-art few-shot results across multiple benchmarks. The study highlights the importance of different types of pre-training data for various tasks, with caption data being particularly impactful for zero-shot performance.
- Supervised Fine-Tuning (SFT): The effectiveness of pre-training data choices was validated through SFT, where capabilities and modeling decisions acquired during pre-training were retained, leading to competitive performance across evaluations and benchmarks.
Performance
- In-Context Learning Abilities: The MM1 model exhibits exceptional in-context learning abilities, particularly in its largest 30 billion parameter configuration. This version of the model can perform multi-step reasoning over multiple images using few-shot “chain-of-thought” prompting.
- Model Scale: MM1's scalability is demonstrated through the exploration of larger LLMs, ranging from 3B to 30B parameters, and the investigation of mixture-of-experts (MoE) models. This scalability contributes to MM1's adaptability to diverse tasks and datasets, further enhancing its performance and applicability.
- Performance: The MM1 models, which include both dense models and mixture-of-experts (MoE) variants, achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks.
Apple MM1 Model’s Features
In-Context Predictions
The Apple MM1 model excels at making predictions within the context of a given input. By considering the surrounding information, it can generate more accurate and contextually relevant responses. For instance, when presented with a partial sentence or incomplete query, the MM1 model can intelligently infer the missing parts and provide meaningful answers.
Multi-Image Reasoning
The MM1 model demonstrates impressive capabilities in reasoning across multiple images. It can analyze and synthesize information from various visual inputs, allowing it to make informed decisions based on a broader context. For example, when evaluating a series of related images (such as frames from a video), the MM1 model can track objects, detect changes, and understand temporal relationships.
Chain-of-Thought Reasoning
One of the standout features of the MM1 model is its ability to maintain a coherent chain of thought. It can follow logical sequences, connect ideas, and provide consistent responses even in complex scenarios. For instance, when engaged in a conversation, the MM1 model remembers previous interactions and ensures continuity by referring back to relevant context.
Few-Shot Learning with Instruction Tuning
The MM1 model leverages few-shot learning techniques, enabling it to learn from a small amount of labeled data. Additionally, it fine-tunes its performance based on specific instructions, adapting to different tasks efficiently. For instance, if provided with only a handful of examples for a new task, the MM1 model can generalize and perform well without extensive training data.
Visual Question Answering (VQA)
The MM1 model can answer questions related to visual content through Visual Question Answering (VQA). Given an image and a question, it generates accurate and context-aware answers, demonstrating its robust understanding of visual information. For example, when asked, “What is the color of the car in the picture?” the MM1 model can analyze the image and provide an appropriate response.
Captioning
When presented with an image, the MM1 model can generate descriptive captions. Its ability to capture relevant details and convey them in natural language makes it valuable for image captioning tasks. For instance, if shown a picture of a serene mountain landscape, the MM1 model might generate a caption like, “Snow-capped peaks against a clear blue sky.”
Key Components of MM1
Transformer Architecture
The transformer architecture serves as the backbone of MM1.
- Self-Attention Mechanism: Transformers use self-attention to process sequences of data. This mechanism allows them to weigh the importance of different elements within a sequence, capturing context and relationships effectively.
- Layer Stacking: Multiple layers of self-attention are stacked to create a deep neural network. Each layer refines the representation of input data.
- Positional Encoding: Transformers incorporate positional information, ensuring they understand the order of elements in a sequence.
Multimodal Pre-Training Data
MM1 benefits from a diverse training dataset:
- Image-Text Pairs: These pairs directly connect visual content (images) with corresponding textual descriptions. The model learns to associate the two modalities.
- Interleaved Documents: Combining images and text coherently allows MM1 to handle multimodal inputs seamlessly.
- Text-Only Data: Ensuring robust language understanding, even when dealing with text alone.
Image Encoder
The image encoder is pivotal for MM1’s performance:
- Feature Extraction: The image encoder processes visual input (images) and extracts relevant features. These features serve as the bridge between the visual and textual modalities.
- Resolution and Token Count: Design choices related to image resolution and token count significantly impact MM1’s ability to handle visual information.
Vision-Language Connector
The vision-language connector facilitates communication between textual and visual representations:
- Cross-Modal Interaction: It enables MM1 to align information from both modalities effectively.
- Joint Embeddings: The connector generates joint embeddings that capture shared semantics.
Ablation Study for MLLMs
Building performant Multimodal Large Language Models (MLLMs) is an empirical process that involves carefully exploring various design decisions related to architecture, data, and training procedures. Here, the authors present a detailed ablation study conducted to identify optimal configurations for constructing a high-performing model, referred to as MM1.
The ablations are performed along three major axes:
MM1 Model Ablations
- Different pre-trained image encoders are investigated, along with various methods of connecting Large Language Models (LLMs) with these encoders.
- The architecture exploration encompasses the examination of the image encoder pre-training objective, image resolution, and the design of the vision-language connector.
MM1 Data Ablations
- Various types of data and their relative mixture weights are considered, including captioned images, interleaved image-text documents, and text-only data.
- The impact of different data sources on zero-shot and few-shot performance across multiple captioning and Visual Question Answering (VQA) tasks is evaluated.
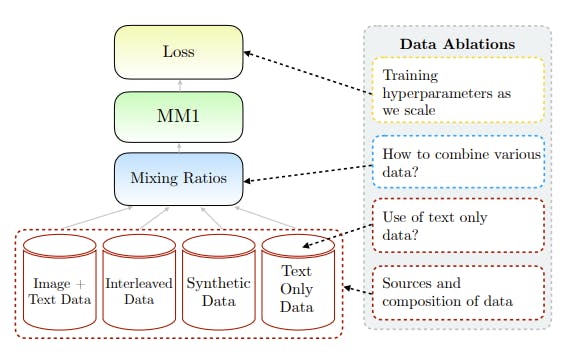
Training Procedure Ablations
- The training procedure is explored, including hyperparameters and which parts of the model to train at different stages.
- Two types of losses are considered: contrastive losses (e.g., CLIP-style models) and reconstructive losses (e.g., AIM), with their effects on downstream performance examined.
Empirical Setup
- A smaller base configuration of the MM1 model is used for ablations, allowing for efficient assessment of model performance.
- The base configuration includes an Image Encoder (ViT-L/14 model trained with CLIP loss on DFN-5B and VeCap-300M datasets), Vision-Language Connector (C-Abstractor with 144 image tokens), Pre-training Data (mix of captioned images, interleaved image-text documents, and text-only data), and a 1.2B transformer decoder-only Language Model.
- Zero-shot and few-shot (4- and 8-shot) performance on various captioning and VQA tasks are used as evaluation metrics.
MM1 Ablation Study: Key Findings
- Image resolution, model size, and training data composition are identified as crucial factors affecting model performance.
- The number of visual tokens and image resolution significantly impact the performance of the Vision-Language Connector, while the type of connector has a minimal effect.
- Interleaved data is crucial for few-shot and text-only performance, while captioning data enhances zero-shot performance.
- Text-only data helps improve few-shot and text-only performance, contributing to better language understanding capabilities.
- Careful mixture of image and text data leads to optimal multimodal performance while retaining strong text performance.
- Synthetic caption data (VeCap) provides a notable boost in few-shot learning performance.
Performance Evaluation of MM1 Models
The performance evaluation of MM1 models encompasses several key aspects, including scaling via Mixture-of-Experts (MoE), supervised fine-tuning (SFT) experiments, impact of image resolution, pre-training effects, and qualitative analysis.
Scaling via Mixture-of-Experts (MoE)
- MM1 explores scaling the dense model by incorporating more experts in the Feed-Forward Network (FFN) layers of the language model.
- Two MoE models are designed: 3B-MoE with 64 experts and 7B-MoE with 32 experts, utilizing top-2 gating and router z-loss terms for training stability.
- The MoE models demonstrate improved performance over their dense counterparts across various benchmarks, indicating the potential of MoE for further scaling.
Supervised Fine-Tuning Experiments
- Supervised Fine-Tuning (SFT) is performed on top of the pre-trained MM1 models using a diverse set of datasets, including instruction-response pairs, academic task-oriented vision-language datasets, and text-only data.
- MM1 models exhibit competitive performance across 12 benchmarks, showing particularly strong results on tasks such as VQAv2, TextVQA, ScienceQA, and newer benchmarks like MMMU and MathVista.
- The models maintain multi-image reasoning capabilities even during SFT, enabling few-shot chain-of-thought reasoning.
Impact of Image Resolution
- Higher image resolution leads to improved performance, supported by methods such as positional embedding interpolation and sub-image decomposition.
- MM1 achieves a relative performance increase of 15% by supporting an image resolution of 1344×1344 compared to a baseline model with an image resolution of 336 pixels.
Pre-Training Effects
- Large-scale multimodal pre-training significantly contributes to the model's performance improvement over time, showcasing the importance of pre-training data quantity.
- MM1 demonstrates strong in-context few-shot learning and multi-image reasoning capabilities, indicating the effectiveness of large-scale pre-training for enhancing model capabilities.
Qualitative Analysis
- Qualitative examples provided in the evaluation offer further insights into MM1's capabilities, including single-image and multi-image reasoning, as well as few-shot prompting scenarios.
- These examples highlight the model's ability to understand and generate contextually relevant responses across various tasks and input modalities.
Apple’s Ethical Guidelines for MM1
- Privacy and Data Security: Apple places utmost importance on user privacy. MM1 models are designed to respect user data and adhere to strict privacy policies. Any data used for training is anonymized and aggregated.
- Bias Mitigation: Apple actively works to reduce biases in MM1 models. Rigorous testing and monitoring are conducted to identify and rectify any biases related to gender, race, or other sensitive attributes.
- Transparency: Apple aims to be transparent about the capabilities and limitations of MM1. Users should have a clear understanding of how the model works and what it can and cannot do.
- Fairness: MM1 is trained on diverse data, but Apple continues to improve fairness by addressing underrepresented groups and ensuring equitable outcomes.
- Safety and Harm Avoidance: MM1 is designed to avoid harmful or unsafe behavior. It refrains from generating content that could cause harm, promote violence, or violate ethical norms.
- Human Oversight: Apple maintains a strong human-in-the-loop approach. MM1 models are continuously monitored, and any problematic outputs are flagged for review.
MM1 MLLM: Key Takeaways
- Multimodal Integration: MM1 combines textual and visual information, achieving impressive performance.
- Ablation Study Insights: Image encoder matters, connector less so. Data mix is crucial.
- Scaling Up MM1: Up to 30 billion parameters, strong pre-training metrics, competitive fine-tuning.
- Ethical Guidelines: Privacy, fairness, safety, and human oversight are priorities.
Frequently asked questions
The MM1 model research leveraged a diverse set of data sources. Specifically, they used a mix of Image-caption pairs, Interleaved image-text documents, Text-only data. This careful combination was crucial for achieving state-of-the-art few-shot results across multiple benchmarks compared to other published pre-training results
To build performant Multimodal Large Language Models (MLLMs) like MM1, it’s essential to judiciously combine different types of data. In MM1’s case, the mixture of image-caption, interleaved image-text, and text-only data played a pivotal role in achieving impressive results.
Yes, the lessons learned during pre-training do indeed transfer to supervised fine-tuning (SFT). After large-scale pre-training, MM1 maintains competitive performance on a range of established multimodal benchmarks.
The research paper does not explicitly delve into environmental considerations for MM1. However, it’s essential to recognize that large-scale models like MM1 consume significant computational resources during training and inference. Researchers and practitioners need to be mindful of the environmental impact when deploying such models.
MM1, with its up-to-30B-parameter family of multimodal models (including dense models and mixture-of-experts variants), achieves state-of-the-art pre-training metrics. After supervised fine-tuning, it remains competitive across various multimodal benchmarks.
The research paper does not explicitly address data privacy and security aspects related to MM1. However, like any large-scale language model, MM1’s deployment should adhere to best practices regarding data privacy, user consent, and secure handling of sensitive information.
Encord provides extensive multimodal annotation capabilities that allow users to annotate various data types, including text and documents, side by side. This customization enables teams to work efficiently on different project types, such as PDFs and emails, enhancing the overall annotation workflow.
Yes, Encord is designed to handle multimodal data, including text, audio, images, and video. This capability allows teams to manage various data types within a single platform, simplifying the annotation process and improving collaboration across different AI teams.
Yes, Encord is equipped to handle multimodal projects, enabling users to work with different data types, including text and audio. This flexibility allows teams to explore and integrate diverse data modalities into their workflows.