Meta AI’s Ilama 3: The Most Awaited Intelligent AI-Assistant

Meta has released Llama 3 pre-trained and instruction-fine-tuned language models with 8 billion (8B) and 70 billion (70B) parameters. These models have new features, like better reasoning, coding, and math-solving capabilities. They set a new state-of-the-art (SoTA) for models of their sizes that are open-source and you can use. This release builds upon the company's commitment to accessible, SoTA models.
Llama 3 technology stands out because it focuses on capabilities that are tuned to specific instructions. This shows that Meta is serious about making helpful, safe AI systems that align with what users want.
The Llama 3 family of models utilizes over 400 TFLOPS per GPU when trained on 16,000 GPUs simultaneously. The training runs were performed on two custom-built 24,000 GPU clusters.
In this article, you will learn:
- What we know so far about the underlying Llama 3 architecture (surprisingly, it’s not a Mixture of Experts; MoE).
- Key capabilities of the multi-parameter model.
- Key differentiators from Llama 2 and other models.
- The performance on benchmarks against other SoTA models.
- Potential applications and use cases.
- How you can test it out and plug it into your application now.
Here’s the TL;DR if you are pressed for time:
- Llama 3 models come in both pre-trained and instruction-following variants.
- Llama 3 promises increased responsiveness and accuracy in following complex instructions, which could lead to smoother user experiences with AI systems.
- The model release includes 8B, 70B, and 400B+ parameters, which allow for flexibility in resource management and potential scalability.
- It integrates with search engines like Google and Bing to draw on up-to-date, real-time information and augment its responses.
- It uses a new tokenizer with a vocabulary of 128k tokens. This enables it to encode language much more efficiently. It offers notably improved token efficiency—despite the larger 8B model, Llama 3 maintains inference efficiency on par with Llama 2 7B.
Understanding the Model Architecture
In addition, training the model was three times more efficient than Llama 2. In this section, you will learn the architectural components of Llama 3 that make it this efficient:
Model Architecture with Improved Tokinzer Efficiency
Like many SoTA LLMs, Llama 3 uses a Transformer-based architecture. This architecture allows efficient parallelization during training and inference, making it well-suited for large-scale models. Here are the key insights:
- Efficiency Focus: Adopting a standard decoder-only Transformer architecture prioritizes computational efficiency during inference (i.e., generating text).
- Vocabulary Optimization: The 128K token vocabulary offers significantly improved encoding efficiency compared to Llama 2. This means the model can represent more diverse language patterns with fewer parameters, potentially boosting performance without increasing model size.
- Fine-Tuning the Attention Mechanism: Grouped query attention (GQA) aims to improve inference (text generation) for the 8B and 70B parameter models. This technique could improve speed without sacrificing quality.
- Long Sequence Handling: Training on 8,192 token sequences focuses on processing longer text inputs. This is essential for handling complex documents, conversations, or code where context extends beyond short passages.
- Document Boundary Awareness: Using a mask during self-attention prevents information leakage across document boundaries. This is vital for tasks like summarizing or reasoning over multiple documents, where maintaining clear distinctions is crucial.
Pretraining Data Composition
Llama 3 was trained on over 15 trillion tokens. The pretraining dataset is more than seven times larger than Llama 2's. Here are the key insights on the pretraining data:
- Massive Dataset Scale: The 15T+ token dataset is a massive increase over Llama 2, implying gains in model generalization and the ability to handle more nuanced language patterns.
- Code Emphasis: The dataset contains four times more code samples, which improves the model’s coding abilities.
- Multilingual Preparation: Over 5% more non-English data than used to train Llama 2 for future multilingual applications exist. Though performance in non-English languages will likely differ initially.
- Quality Control Rigor: The team developed data filtering pipelines to build high-quality training data. They used heuristic filters, NSFW removal, deduplication, and classifiers to ensure model integrity and reduce potential biases.
- Data Mixing Experimentation: The emphasis on experimentation with varying data mixes highlights the importance of finding an optimal balance for diverse downstream use cases. This suggests Meta understands that the model will excel in different areas based on its training composition.

Scaling Up Pre-training
Training LLMs remains computationally expensive, even with the most efficient implementations. Training Llama 3 demanded more than better scaling laws and infrastructure; it required efficient strategies (scaling up pre-training) to achieve highly effective training time across 16,000 GPUs. Here are key insights on scaling training:
- Scaling Laws as Guides: Meta leans heavily on scaling laws to determine optimal data mixes and resource allocation during training. These laws aren't foolproof but likely enable more informed decision-making about model development.
- Continued Improvement with Massive Data: The 8B and 70B models show significant log-linear improvement up to 15T tokens. This suggests that even large models can benefit from more data, defying the notion of diminishing returns within the dataset sizes explored.
- Parallelization Techniques: Combining data, model, and pipeline parallelisms allowed them to efficiently train on up to 16K GPUs simultaneously.
- Reliability and Fault Tolerance: The automated error detection, hardware reliability focus, and scalable storage enhancements emphasize the practical realities of training huge models. 95%+ effective training time is remarkable!
The most important thing to remember is that bigger models can do the same work with less computation. However, smaller models are still better because they are better at generating responses quickly. This makes choosing the right model size for the job even more important.
Instruction Fine Tuning
Meta's blog mentioned Llama 3 is fine-tuned in instructions-following. This likely involved specific fine-tuning techniques on datasets designed to improve the model's ability to understand and execute complex instructions. Here are key insights:
- Hybrid Finetuning Approach: Meta combines several techniques for instruction-tuning—supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct policy optimization (DPO). This multi-pronged strategy suggests flexibility and tailoring to specific use cases.
- Data as the Differentiator: The emphasis is on the quality of prompts and preference rankings as prime drivers of aligned model performance. This highlights the involvement of fine-tuning techniques and data curation.
- Human-in-the-Loop: Multiple rounds of quality assurance on human annotations remind us that human feedback remains vital for aligning and refining these complex models.
- Reasoning and Coding Benefits: PPO and DPO with preference ranking data significantly boosted Llama 3's performance on reasoning and coding tasks. This underscores the power of these techniques in specific domains.
- Answer Selection Fine-Tuning: Intriguingly, models can sometimes 'understand' the correct answer but struggle with selection. Preference ranking training directly addresses this, teaching the model to discriminate between output possibilities.
Functional Capabilities of Llama 3
Meta's Llama 3 advancements in pretraining and instruction-focused fine-tuning offer potential across a wide range of natural language processing (NLP) and code-related tasks. Let's explore some potential functional areas:
Conversational Interactions
- Asking for Advice: Llama 3 can provide guidance or suggestions for a problem scenario due to its instruction-following focus. Its ability to draw on knowledge from its training data could offer a variety of perspectives or solutions.
- Brainstorming: Llama 3's creativity and language generation capabilities could make it a helpful brainstorming partner. It can generate lists of ideas, suggest alternative viewpoints, or create out-of-the-box concept combinations to stimulate further thought.
Text Analysis and Manipulation
- Classification: With appropriate fine-tuning, Llama 3 classifies text, code, or other data into predefined categories. Its ability to identify patterns from both its pretraining data and specific classification training could make it effective in such tasks.
- Closed Question Answering: Llama 3's access to real-time search results and large-scale knowledge base from its pretraining improve its potential for factual question answering. Closed-ended questions yield accurate and concise responses.
- Extraction: Llama 3 extracts specific information from larger text documents or code bases. Fine-tuning might identify named entities, key phrases, or relevant relationships.
Code-Related
- Coding: Meta's attention to code within the training data suggests Llama 3 possesses coding capability. It could generate code snippets, assist with debugging, or explain existing code.
Creative and Analytical
- Creative Writing: Llama 3's generative abilities open possibilities for creative text formats, such as poems, stories, or scripts. Users might provide prompts, outlines, or stylistic guidelines to shape the output.
- Extraction: Llama 3 extracts specific information from larger text documents or code bases. Fine-tuning might identify named entities, key phrases, or relevant relationships.
- Inhabiting a Character/Persona: Though not explicitly stated, Llama 3's generative and knowledge-accessing capabilities indicate the potential for adopting specific personas or character voices. This could be entertaining or useful for simulating specific conversational styles.
- Open Question-Answering: Answering complex, open-ended questions thoroughly and accurately could be more challenging. However, its reasoning skills and access to external knowledge might offer insightful and nuanced responses.
- Reasoning: The emphasis on preference-ranking-based fine-tuning suggests advancements in reasoning. Llama 3 can analyze arguments, explain logical steps, or solve multi-part problems.
- Rewriting: Llama 3 could help rephrase text for clarity, alter the tone, or change writing styles. You must carefully define their rewriting goals for the most successful results.
- Summarization: Llama 3's ability to process long input sequences and fine-tuned understanding of instructions position it well for text summarization. It might condense articles, reports, or meeting transcripts into key points.
Model Evaluation Performance Benchmarking (Comparison: Gemma, Gemini, and Claude 3)
The team evaluated the models' performance on standard benchmarks and tried to find the best way to make them work in real-life situations. They created a brand-new, high-quality set of human evaluations to do this.
This test set has 1,800 questions that cover 12 main use cases: asking for help, coming up with ideas, sorting, answering closed questions, coding, creative writing, extraction, taking on the role of a character or persona, answering open questions, reasoning, rewriting, and summarizing.
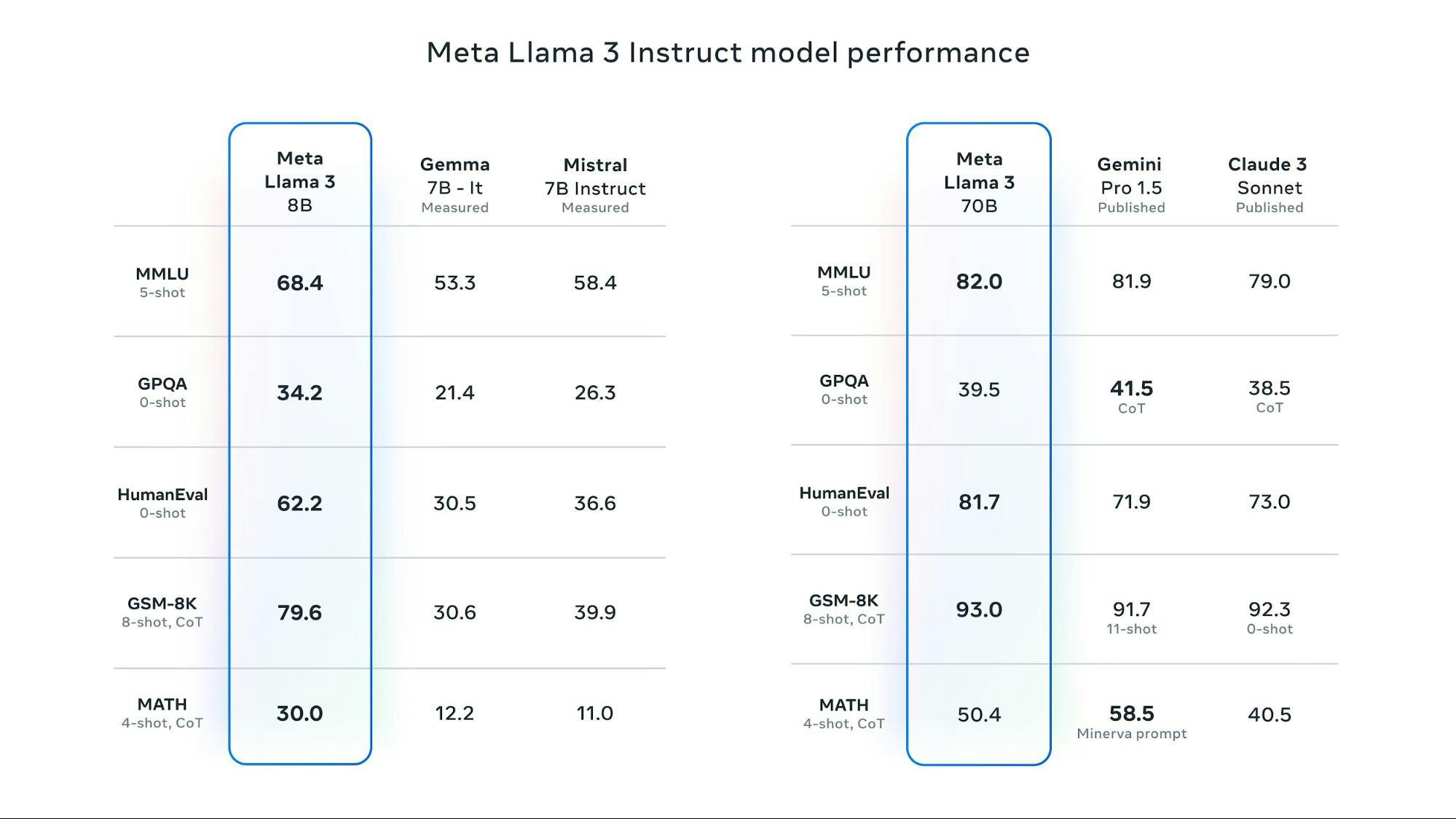
Llama 3 70B broadly outperforms Gemini Pro 1.5 and Claude 3 Sonnet. It is a bit behind on MATH, which Gemini Pro 1.5 seems better at. But it is small enough to host at scale without breaking the bank.
Here’s the performance benchmark for the instruction-following model:
Meta Llama 3 Instruct model performance.
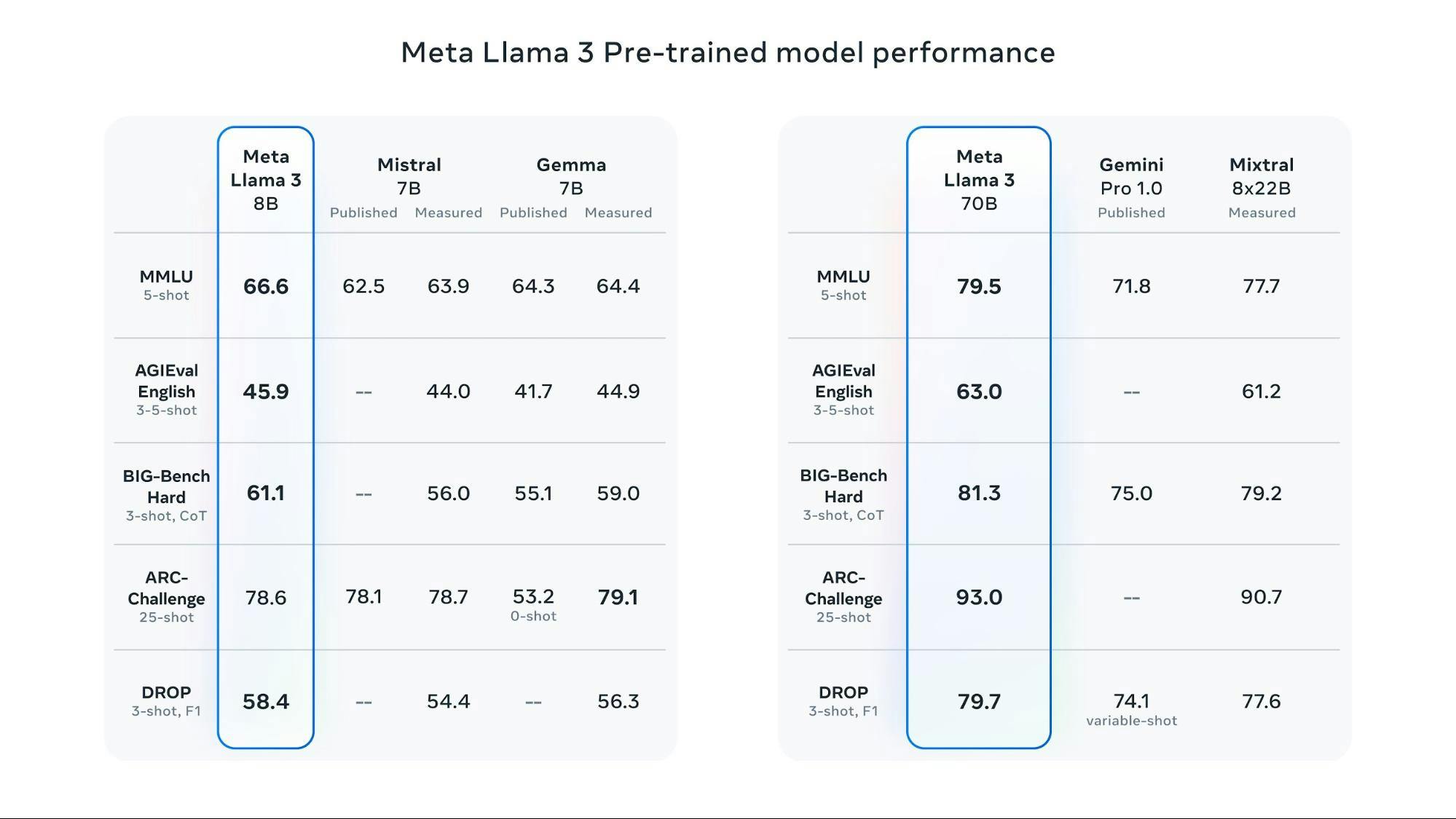
Meta Llama 3 Pre-trained model performance.
Let’s look at some of these benchmarks.
MMLU (Knowledge Benchmark)
The MMLU benchmark assesses a model's ability to understand and answer questions that require factual and common-sense knowledge.
The 8B model achieves a score of 66.6, outperforming the published Mistral 7B (63.9) and measured Gemma 7B (64.4) models.
The 70B model achieves an impressive score of 79.5, outperforming the published Gemini Pro 1.0 (71.8) and measured Mistral 8x22B (77.7) models.
The high scores suggest Llama 3 can effectively access and process information from the real world through search engine results, complementing the knowledge gained from its massive training dataset.
AGIEval
The AGIEval measures performance on various English-language tasks, including question-answering, summarization, and sentiment analysis.
In a 3-shot setting, the 8B model scores 45.9, slightly higher than the published Gemma 7B (44.0) but lower than the measured version (44.9).
The 70B model's score of 63.0 outperforms the measured Mistral 8x22B (61.2).
ARC (Skill Acquisition Benchmark)
The ARC benchmark assesses a model's ability to reason and acquire new skills.
In a 3-shot setting with a score of 78.6, the 8B model performs better than the published Gemma 7B (78.7) but slightly worse than the measured version (79.1).
The 70B model achieves a remarkable score of 93.0, significantly higher than the measured Mistral 8x22B (90.7).
The high scores suggest Llama 3 has explicitly been enhanced for these capabilities through preference-ranking techniques during fine-tuning.
DROP (Model Reasoning Benchmark)
This benchmark focuses on a model's ability to perform logical reasoning tasks based on textual information, often involving numerical reasoning.
In a 3-shot setting, Llama 8B scores 58.4 F1, higher than the published Gemma 7B (54.4) but lower than the measured version (56.3).
With a score of 79.7 (variable-shot), the Llama 70B model outperforms both the published Gemini Pro 1.0 (74.1) and the measured Mistral 8x22B (77.6).
While DROP can be challenging for LLMs, Llama 3's performance suggests it can effectively handle some numerical reasoning tasks.
Overall, the test results show that Meta's Llama 3 models, especially the bigger 70B version, do better than other SoTA models on various tasks related to language understanding and reasoning.
Responsible AI
In addition to Llama 3, the team released new Meta Llama trust & safety tools featuring Llama Guard 2, Code Shield, and Cybersec Eval 2—plus an updated Responsible Use Guide & Getting Started Guide, new recipes, and more. We will learn some of the approaches Meta used to test and secure Llama 3 against adversarial attacks.
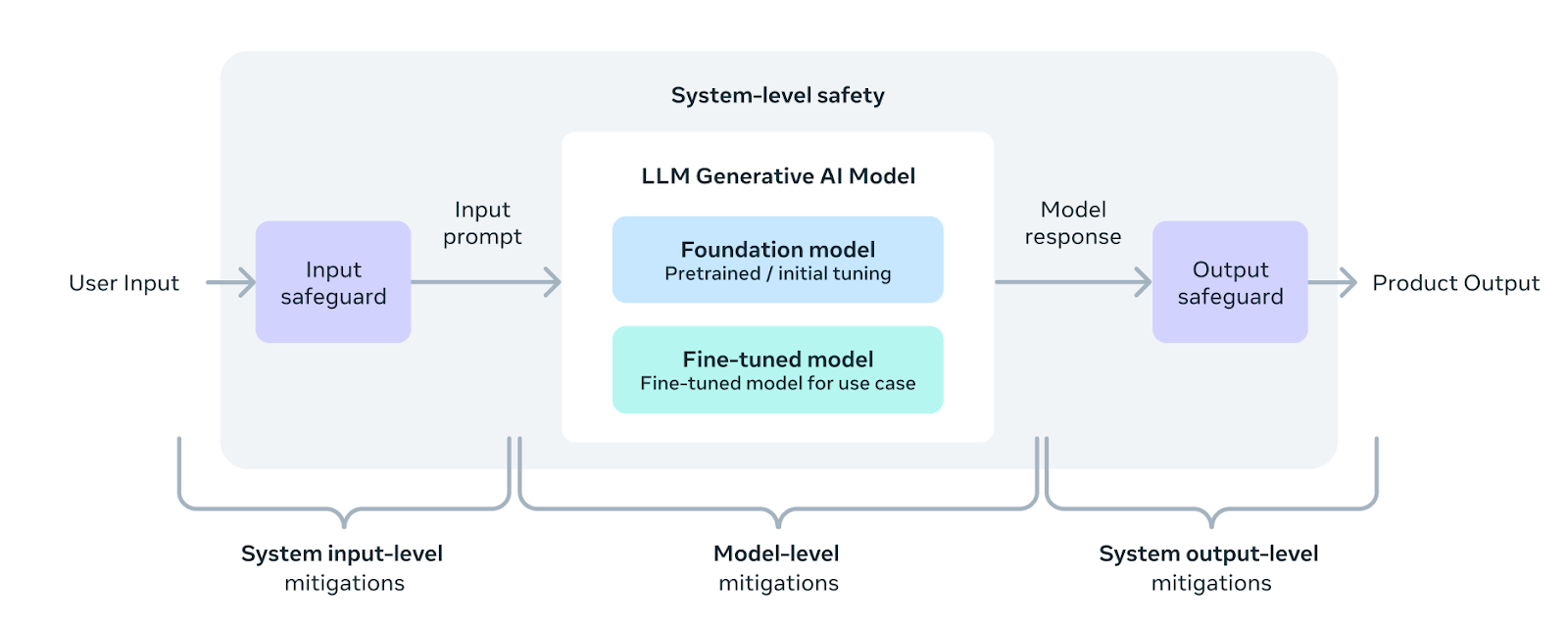
A system-level approach to responsibility in Llama 3.
System-level Approach
- Responsible Development of LLMs: Meta emphasizes a holistic view of responsibility, going beyond just the core model to encompass the entire system within which an LLM operates.
- Responsible Deployment of LLMs: Developers building applications with Llama 3 are seen as sharing responsibility for ethical use. Meta aims to provide tools and guidance to facilitate this.
- Instruction Fine-tuning: Fine-tuning with an emphasis on safety plays a crucial role in aligning the model with responsible use guidelines and minimizing potential harms.
Red Teaming Approach
- Human Experts: Involvement of human experts in the red teaming process suggests an understanding that automated methods alone may not catch all the nuances of potential misuse.
- Automation Methods: These methods are vital for scaling the testing process and generating a wide range of adversarial prompts to stress-test the model.
- Adversarial Prompt Generation: The focus on adversarial prompts highlights Meta's proactive approach to identifying potential vulnerabilities and safety concerns before wider deployment.
Trust and Safety Tools
- Llama Guard 2, Code Shield, and CyberSec Eval 2: Development of specialized tools demonstrates a focus on mitigating specific risks:
- - Llama Guard 2: Proactive prompt and output safety filtering aligns with industry-standard taxonomies for easier adoption.
- - Code Shield: Addresses security vulnerabilities unique to LLMs with code generation capabilities.
- - CyberSecEval 2: Focuses on assessing and mitigating cybersecurity-related risks associated with LLMs.

Llama 3 Trust and Safety Tools.
Responsible Use Guide (RUG)
- Responsible Development with LLMs: Updated guidance reinforces Meta's commitment to providing developers with resources for ethical application building.
- Content Moderation APIs: Explicitly recommending the use of external content moderation tools suggests a multi-pronged approach to safety. Developers are encouraged to utilize existing infrastructure to complement Meta's own efforts.
You can find more of these updates on the Llama website.
Llama 3: Model Availability
Meta's commitment to open-sourcing Llama 3 expands its accessibility and potential for broader impact. The model is expected to be available across various platforms, making it accessible to researchers, developers, and businesses of varying sizes.
Cloud Providers
Major cloud providers are partnering with Meta to offer Llama 3 integration, making it widely accessible:
- AWS, Databricks, Google Cloud, and Microsoft Azure: These platforms provide scalable infrastructure, tools, and pre-configured environments that simplify model deployment and experimentation.
- NVIDIA NIM and Snowflake: NVIDIA also provides services for deploying and using Llama 3.
Model API Providers
- Hugging Face: These platforms are popular for model sharing and experimentation. Llama 3 is already available as a GGUF version and other platform variations.
- Ollama: The Ollama community has also integrated the model's different parameters and variations into its library, which has over 15k downloads.
Llama 3: What’s Next?
Meta's announcements reveal an exciting and ambitious future for the Llama 3 series of LLMs. Some of the main areas of focus point to a model with a lot more capabilities and reach:
Scaling and Expansion
- Larger Models: Meta is currently developing larger Llama 3 models in the 400B+ parameter range, suggesting its ambition to push the boundaries of LLM capabilities further.
- Multimodality: Planned features include the ability to process and generate text and other modalities, such as images and audio. This could greatly expand the use cases of Llama 3.
- Multilingualism: The goal to make Llama 3 conversant in multiple languages aligns with Meta's global focus, opening up possibilities for cross-lingual interactions and applications.
- Longer Context Window: Increasing the amount of text the model can process at once would enable Llama 3 to handle more complex tasks, improving its understanding of extended conversations, intricate documents, and large codebases.
- Enhanced Capabilities: An overall emphasis on improving capabilities hints at potential advancements in reasoning, problem-solving, and coding that may exceed the impressive performance of currently released models.
Research Transparency
- Research Paper: Meta plans to publish a detailed research paper after completing the training process for larger Llama 3 models. This commitment to transparency and knowledge-sharing aligns with their open-source philosophy.
Focus on Accessibility and Real-World Impact
- Wider Platform Availability: Collaboration with cloud providers, hardware companies, and hosting platforms seeks to make the model readily accessible across various resources. This focus could encourage wider experimentation and adoption for various use cases.
- Open-Source Commitment: Meta encourages community involvement and seeks accelerated development progress, underscoring its belief that open-source drives innovation and safety.

Want to experience Llama 3 right now? Starting today, our latest models have been integrated into Meta AI, which is now rolling out to even more countries, available across our family of apps, and having a new home on the web.
{{light_callout_open}} See the model card here
Experience it on meta.ai
Llama 3: Key Takeaways
Awesome! Llama 3 is already a game-changer for the open-source community. Let’s summarize the key takeaways for Llama 3, focusing on its significance and potential impact on the LLM landscape:
- Breakthrough in Performance: Meta's claim that Llama 3 sets a new standard for 8B and 70B parameter models suggests a big improvement in LLM's abilities in those size ranges.
- Focus on Accessibility: Llama 3's open-sourcing, wide platform availability, and partnerships with major technology providers make it a powerful tool accessible to a much wider range of individuals and organizations than similar models.
- Real-World Emphasis: Meta's use of custom human evaluation sets and focus on diverse use cases indicates they actively work to make Llama 3 perform well in situations beyond theoretical benchmarks.
- Ambitious Trajectory: Ongoing training of larger models, exploration of multimodality, and multilingual development showcase Meta's ambition to continuously push the boundaries of what LLMs can do.
- Emphasis on Instruction-Following: Llama 3's refinement in accurately following complex instructions could make it particularly useful for creating more user-friendly and adaptable AI systems.