How to Use GPT-4o to Automate Captioning for VLA Models (and Build a Faster VLA Data Engine)

ML Lead at Encord
Vision-Language-Action (VLA) models are rapidly reshaping how robots perceive the world, plan actions, and complete tasks. But these systems depend on vast quantities of high-quality temporal data. Not just labeled images, but videos paired with rich descriptions of what is happening within the scene. Without consistent captions, VLA models cannot be trained for high-precision real-world applications, like autonomous robotics for example.
For many teams, creating these captions has slowed down their training pipeline. Manually describing actions in videos, sometimes across hundreds or thousands of hours, is slow, expensive, and difficult to standardize across annotators.
This is why our ML team put together this masterclass on automating this process with GPT-4o. You can watch the highlights below or watch the full video here.
By pairing the multimodal reasoning abilities of GPT-4o with a structured workflow inside Encord, teams can now generate temporal captions automatically, reducing the need for dense human labeling. Instead of weeks spent annotating videos, experts can step in where needed to review or refine the output.
In this article, we’ll walk through what Diarmuid and Jim presented in our latest masterclass focusing on how GPT-4o can be used to automate the captioning process for VLA models.
Why Temporal Captions Are So Important for VLA Models
VLAs don’t just need to recognize objects, they need to understand what is happening and how actions progress over time. A model learning to “open a drawer,” for example, must learn far more than what a drawer looks like. It needs to know the sequence of events such as showing the hand approaching, making contact, pulling, adjusting angle, and completing the motion. These steps become the foundation for downstream reasoning and action planning.
Captions, therefore, must be:
- temporally grounded
- sequential
- structured
- and consistent across large datasets
This is exactly the kind of task that overwhelms manual labeling teams. Watching a 30-second clip and describing every meaningful action can take several minutes. Multiply that by tens of thousands of clips, and you quickly run into lengthy timelines.
However, GPT-4o has built-in multimodal understanding, allowing it to process entire video sequences, break them down into steps, and output structured captions aligned to an ontology. When combined with a workflow, such as those that can be built in Encord, it becomes a powerful automation tool.
Using GPT-4o to Generate Captions Inside Encord
The workflow typically begins with ingesting your raw video data. Whether your videos come from robotics experiments, drone footage, or industrial workflows, they can be uploaded directly into Encord.
An ML team then needs to create a step-wise structure. Something like:
- Step 1: The robot arm moves toward the block
- Step 2: It closes its gripper
- and so on
What matters most is that the structure stays consistent; this helps the model output machine-readable JSON and train the model.
With the ontology in place, GPT-4o can then be brought into the loop. Using Encord’s automated editor agent, you can prompt GPT-4o to identify actions and produce captions. A typical prompt might instruct the model to describe only events that are visually observable, avoid speculation, and break the sequence into clear steps. The agent then processes the clip in full and inserts captions directly into your timeline.
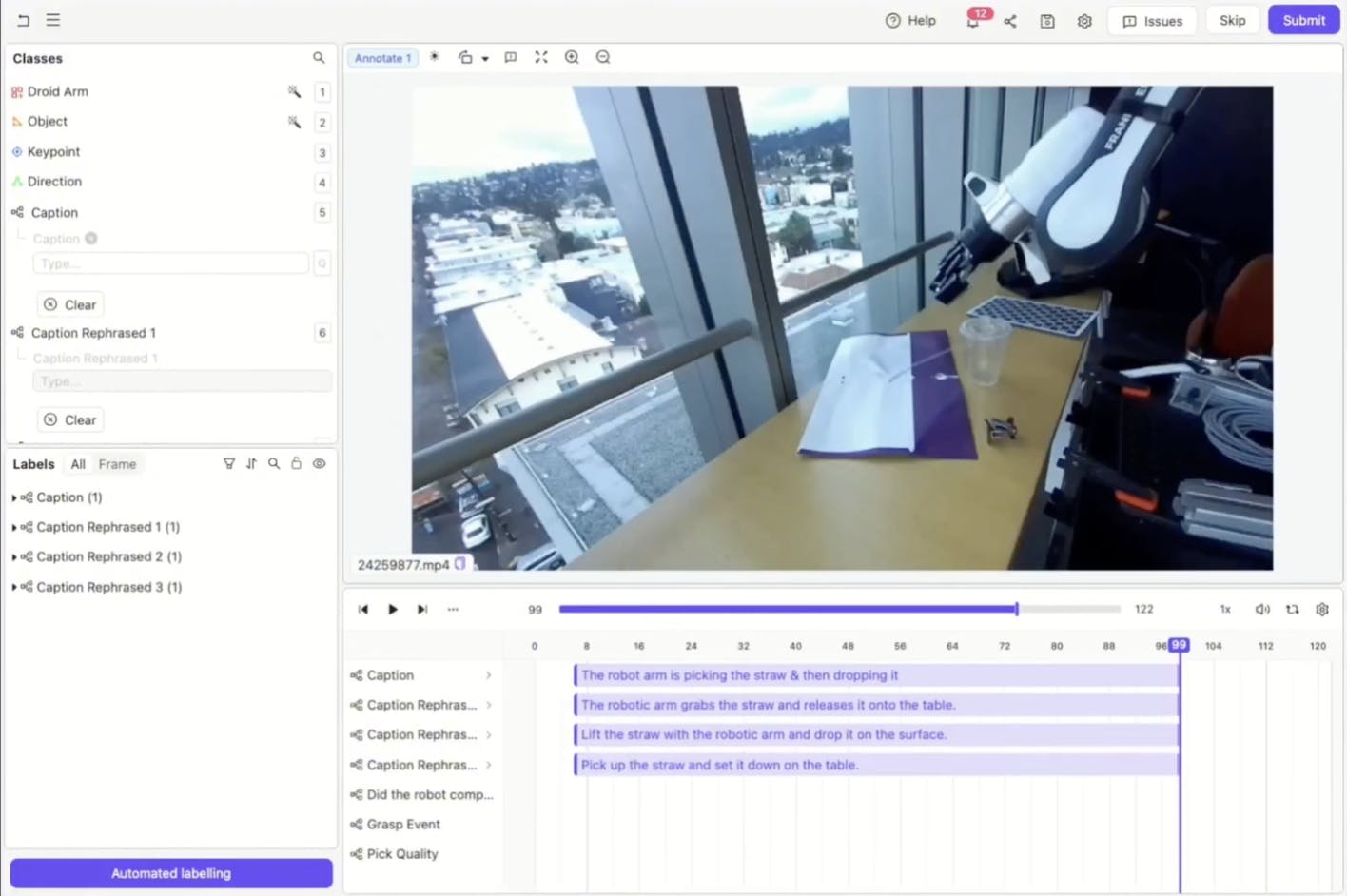
What used to take several annotators hours to complete now takes seconds or minutes.
Automation does not remove the need for human oversight, but rather dramatically reduces it. Instead of writing captions from scratch, reviewers simply skim through the video and make minor adjustments to model-generated steps. .
This hybrid approach vastly speeds up dataset creation, but it also ensures the consistency and accuracy needed for production-grade VLA models.
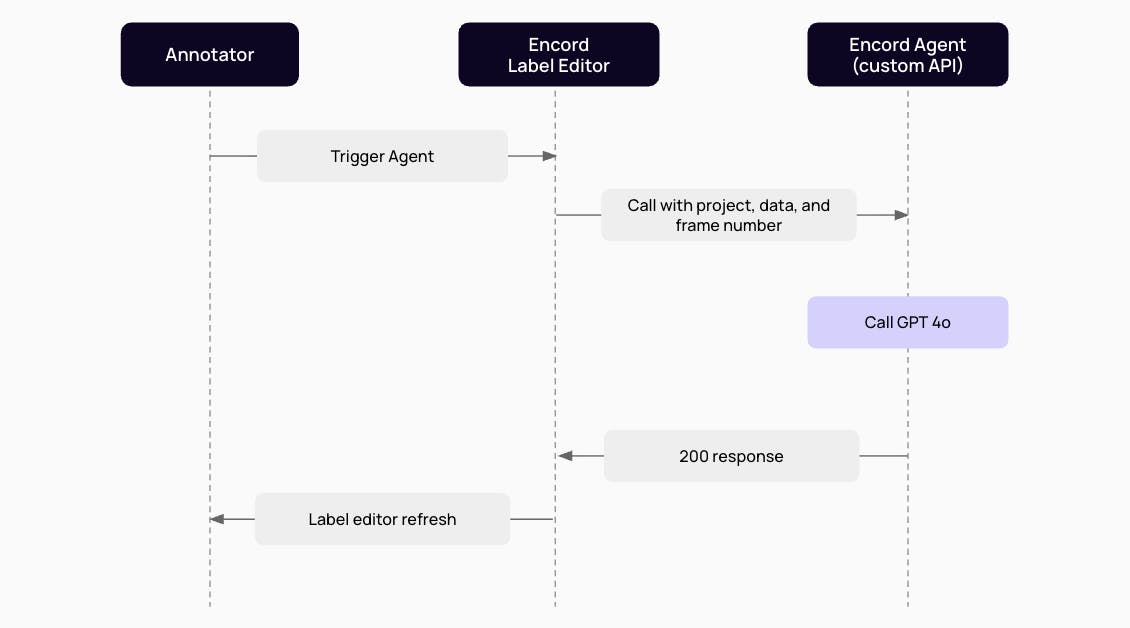
Evaluating Caption Quality and Improving Over Time
One of the biggest advantages of building your captioning pipeline in Encord is the ability to evaluate the results. Teams can measure quality across their dataset, detect inconsistencies, identify outliers, and run structured comparisons between model-generated captions and human reference labels.
This transforms captioning from a one-off manual effort into a continuous improvement loop. Clips that fall below a quality threshold can be re-prompted or re-labeled, and you can iterate on prompts or schema design as your VLA system matures.
Why GPT-4o Works So Well for VLA Data
Not all models are suited for this kind of task, but GPT-4o brings together a combination of capabilities that make it particularly effective:
- It has strong temporal reasoning, meaning it can follow a sequence rather than treating frames independently
- Its multimodal understanding lets it track objects and actions across time
- It handles structured output well, especially when guided by an ontology
- It can be run across large datasets
Where Caption Automation Fits in the Larger VLA Pipeline
Automating captions is not the end goal, but rather it’s a piece of a broader workflow that includes dataset labeling, evaluation, and training. With faster captioning teams can spend more time on the parts that actually drive performance: designing experiments, tuning model architectures, or gathering diverse real-world data.
Teams can collect more video from real-world robotics experiments, create richer evaluation sets, or benchmark their VLA models more frequently. Instead of waiting weeks for new labels, they can update datasets in near-real time.
Captioning has historically been one of the most time-consuming and costly parts of building VLA datasets. GPT-4o fundamentally changes that. With the right prompting strategy and a structured ontology inside Encord, teams can automate the bulk of the captioning workload and reallocate human effort toward quality control rather than manual labeling. The result is faster dataset creation, more iterative robotics development, and better-performing VLA models.