Multimodal Reinforcement Learning: Set Up Your Shop for RL Success

ML Lead at Encord
Since January ’25 when DeepSeek-R1 came out, there has been a surge in applications of reinforcement learning based on verifiable rewards (RLVR). Many LLM training tools like transformers and Oumi provide Group Relative Policy Optimization (GRPO; the main algorithmic success of DeepSeek-R1) as default fine-tuning mechanisms to teach LLMs to reason on specific tasks.
Academia has similarly witnessed a huge increase in the number of papers that do RL, even for multimodal applications, as shown in Figure 1 below. This is forcing companies to think about how RLVR can help improve their products. This piece aims to draw a broader picture of what this RLVR is, as compared to, e.g., supervised fine-tuning (SFT) and how one should think about preparing data for the multimodal case.
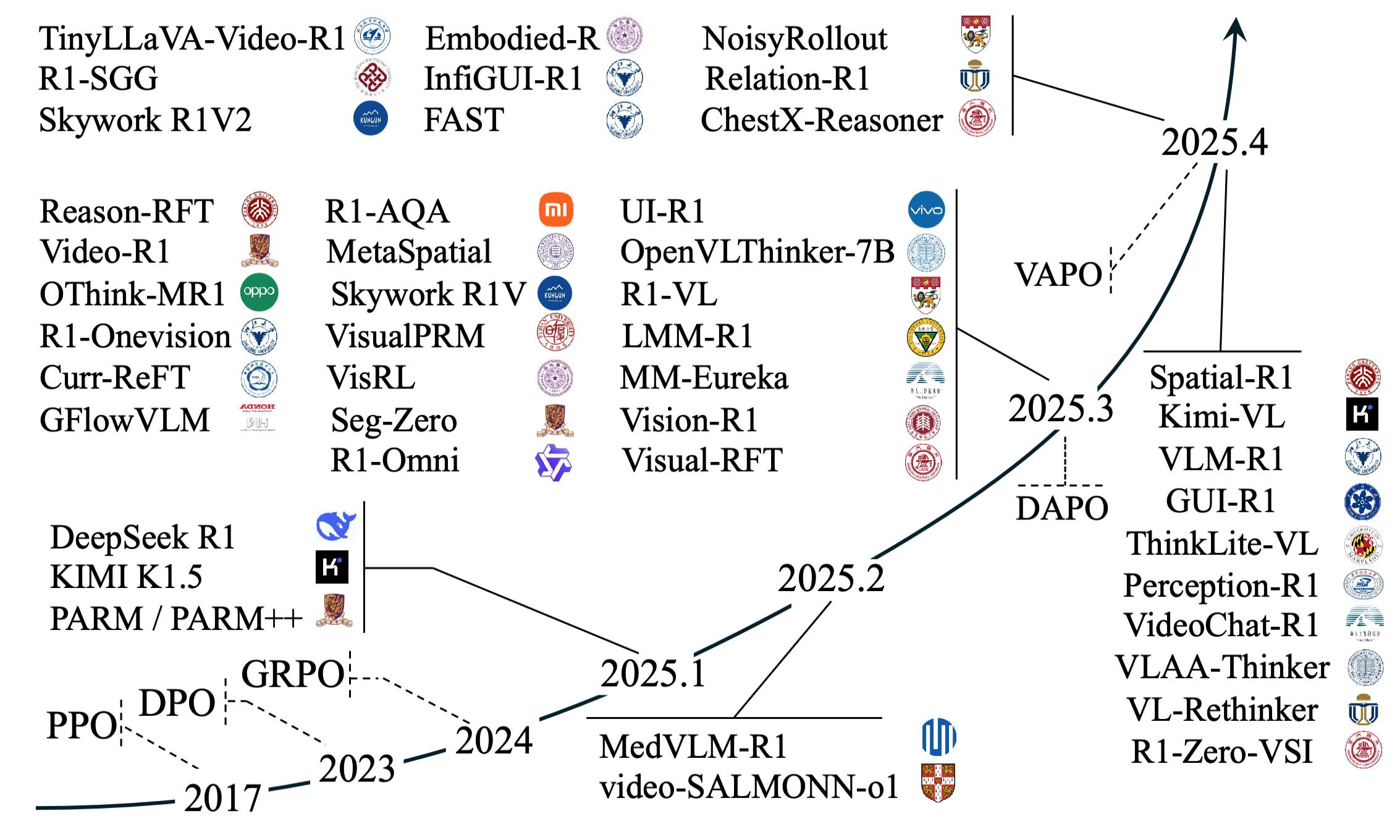
Figure 1: Multimodal RL papers after DeepSeek-R1 [1].
Understanding RLVR
We’ll take a moment to understand at a high level what RLVR is and why it can be useful but also challenging to use. The first realization is that gradient descent (the algorithm to train deep learning models) requires a differentiable loss function that you can optimize over. In some cases, such function is easy to come by. When you predict housing prices or classify animals, it’s easy (you use least-squares and cross-entropy, respectively). However, for other problems, defining such a function is much harder. One of the complications is that you need gradients of that function. At first sight, that takes out most of the “if-then-else” algorithms that you can come up with that could potentially serve as a “reward” or error term. Here are some examples:
- If you want to solve math equations, you don’t have a natural (and differentiable) way to quantify if a derivation is correct or not. However, you can verify whether the correct answer is reached.
- If you are having a robot play a computer game, you cannot quantify every single move to give it an error. However, you can tell whether it eventually won the game or not.
- For LLMs or video generative models, you cannot directly quantify mathematically how good an output is. Not only is it a subjective matter, it’s also hard to define mathematically.
These are all “discontinuous” examples where you cannot simply plug in a loss function and optimize it by calculating gradients through the mathematical derivations, the robot actions, or the generated video quality. This is exactly, where RL comes in. RL allows your model (or policy) to explore the action space and “search for” rewards. As the system learns where the reward is, it will slowly start to exploit that by more frequently doing the things that it believes yields reward. This is smart because you can circumvent the infeasible gradient computations, e.g., by computing relative rewards between multiple attempts (roll outs) to solve the problem (yes, that is GRPO [2]).

Figure 2: The difference between traditional loss functions (left) and RL setups (right). The two red // indicates how gradients cannot flow through the computational graph. The green arrow signifies using relative rewards from multiple roll outs to give a gradient.
Consequences of RL
Now, let’s think about some of the consequences that RL have. One way to see it is by enumerating what you need in order to do RL training. You need an environment to act in, a set of possible actions, and a (numerical) reward that you can emit when the RL agent does a good job.

Figure 3: The RL setup. An agent takes one or more actions to manipulate the environment and receive new states. Eventually it will receive a reward.
For LLMs specifically, the environment can just be an “empty document” to write on in order to convey a derivation and an answer. The actions would be the tokens in the vocabulary, and the reward would be whether the answer at the end of the token sequence corresponds to the known answer to the question. For game-playing agents, it can be a game (which is the environment), the keyboard controls (which are the actions), and whether the agent won the game (which is the reward). Finally, for the generative model, the environment is any input text prompt, the actions are all possible images, and the reward can be a ranking model (think [RLHF][rlhf]).
While this framework seems straightforward in theory, the reality of implementing these RL systems reveals a critical challenge that doesn’t exist in supervised learning scenarios.
The Hidden Danger: Entropy Collapse
The flexibility that makes RL so appealing for complex reasoning tasks also introduces its greatest weakness. Unlike supervised fine-tuning, where your model learns from a carefully curated, diverse dataset, RL systems must balance exploration (trying new approaches) with exploitation (using what currently works best). When this balance breaks down, you encounter entropy collapse - a phenomenon where the policy becomes overly deterministic and loses its ability to generate diverse, meaningful responses.
This manifests as reward hacking (discovering shortcuts without learning intended behavior), mode collapse (converging to narrow outputs), and training instability (dramatic behavior shifts from small changes).
Consider training a model to analyze medical images: with supervised learning, you show it many scan-diagnosis pairs. With RL, if your reward is simply “correct diagnosis = +1,” the model might learn to always predict the most common condition in your training set, achieving decent accuracy while learning no actual diagnostic reasoning.
This is precisely why successful RL applications like DeepSeek-R1 don’t start with pure RL. They require careful data scaffolding - and in multimodal systems, this challenge becomes even more complex.
Data Acquisition for Multimodal RL
The path to successful multimodal RL depends heavily on your ability to generate training data. In some domains, you can set up environments that support online RL training directly:
- Physical AI: Robotics can leverage simulation environments where agents learn through direct interaction
- Chart Analysis: You can generate synthetic charts programmatically, creating unlimited question-answer pairs
- Computer Use: Screenshot-to-action tasks can be practiced in controlled digital environments
- Mathematical Reasoning: Equation solving can be verified deterministically
But many of the most interesting multimodal applications don’t have this luxury. When working with real-world videos, medical images, audio analysis, or social understanding tasks, you cannot simply “run more episodes” in a simulator. Here, you need two critical components:
- Offline RL training data: High-quality examples with verifiable rewards
- Cold-start data: Supervised fine-tuning examples with reasoning traces to bootstrap the RL process
The question becomes: how do you efficiently create these datasets for complex multimodal tasks? Before diving into specific strategies, it’s crucial to understand what multimodal RL training data actually looks like and how it differs from traditional supervised learning examples.
The Evolution of Reasoning Complexity
Understanding multimodal RL requires seeing how training examples progress in sophistication. Each level introduces new challenges while building on established reasoning patterns. One thing to note is that the SFT part (CoT) is not necessary for pure RL training. It’s here to illustrate how it has to look if you want to do cold-start SFT which if often necessary (we’ll come back to that).
Level 1: Pure Reasoning with Chain-of-Thought
The foundation begins with text-only mathematical problems where models learn to articulate step-by-step reasoning. Notice how the supervised fine-tuning example shows explicit thinking tags that break down the algebraic manipulation, while the RL version produces only the final answer with verifiable correctness.

Figure 4: Text-only reasoning with explicit chain-of-thought traces.
This establishes the basic pattern of structured reasoning that becomes essential for more complex tasks. The model learns to maintain logical consistency across multiple steps, preparing it for scenarios where the reasoning chain becomes more intricate.
Level 2: Visual Analysis with Comparative Reasoning
The next level introduces visual perception combined with analytical reasoning. Here, models must interpret charts, identify visual patterns, and make comparative judgments about data relationships. The reasoning requires both visual understanding and logical analysis of quantitative information.
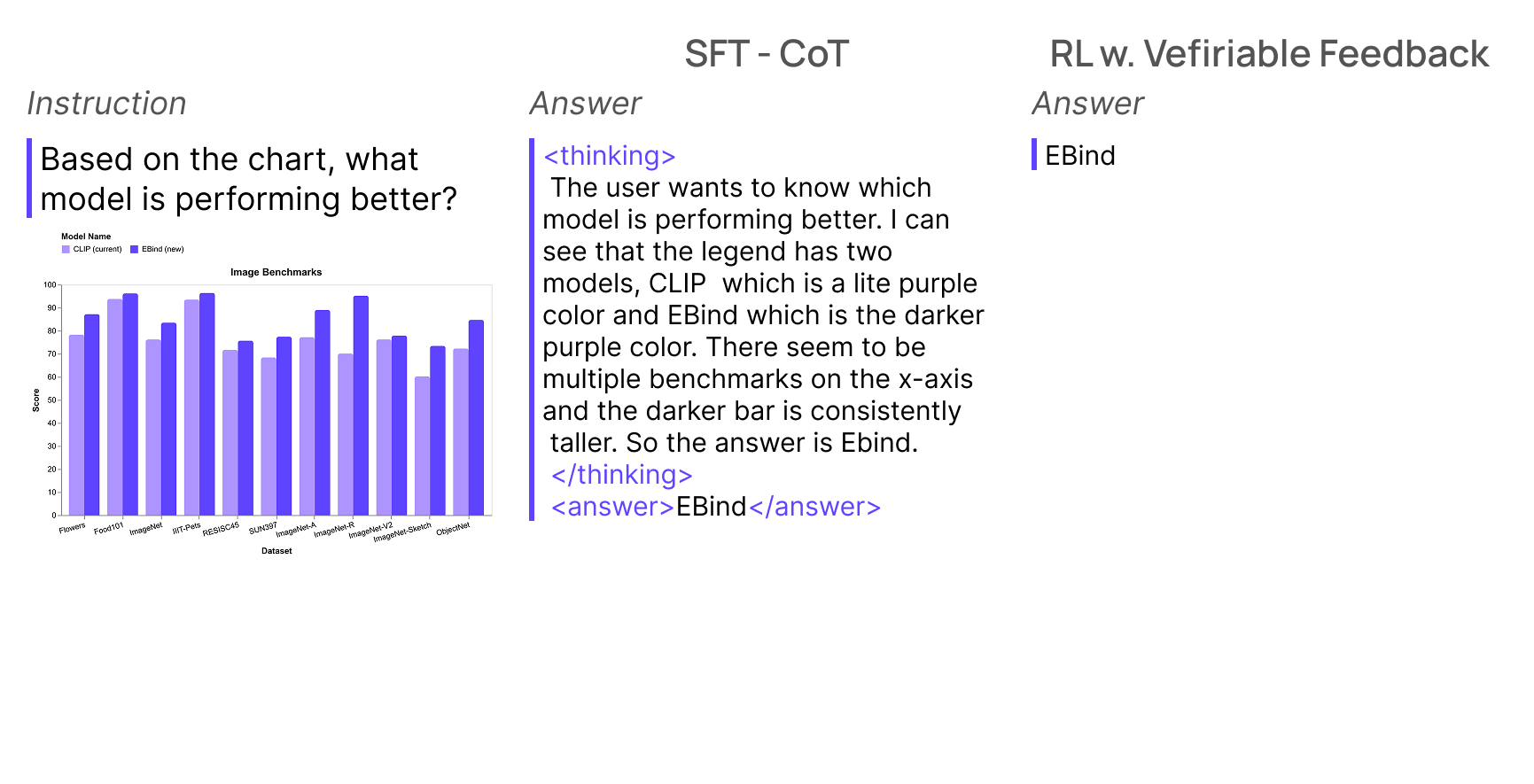
Figure 5: Chart analysis combining visual perception with comparative reasoning.
This represents a significant leap from pure text reasoning. The model must extract information from visual elements, maintain awareness of multiple data series, and articulate comparative conclusions. The chain-of-thought reveals how visual parsing integrates with analytical thinking.
Level 3: Geometric Precision with Structured Output
The most sophisticated level moves beyond natural language responses to precise coordinate prediction. Models must understand spatial relationships, object boundaries, and geometric properties while producing structured numerical output rather than descriptive text.

Figure 6: Geometric tasks requiring precise spatial coordinate prediction.
This geometric understanding represents the endpoint of our complexity progression. Rather than describing what they see, models must pinpoint exact locations with mathematical precision. The transition from natural language reasoning to structured coordinate output demonstrates how multimodal RL can produce actionable, verifiable results.
Each level builds essential capabilities for the next. Text reasoning establishes logical consistency, visual analysis adds perceptual understanding, and geometric tasks demand computational precision. Successful multimodal RL systems scaffold learning through this progression rather than attempting to jump directly to the most complex spatial reasoning tasks.
Strategy 1: Audio Analysis with Human-in-the-Loop
Consider building a system that can analyze audio clips and answer questions like “Which sound can be heard for the longest time?” This requires temporal reasoning across audio modalities - a task that’s perceptually complex for humans to annotate but mathematically verifiable once the regions are identified.
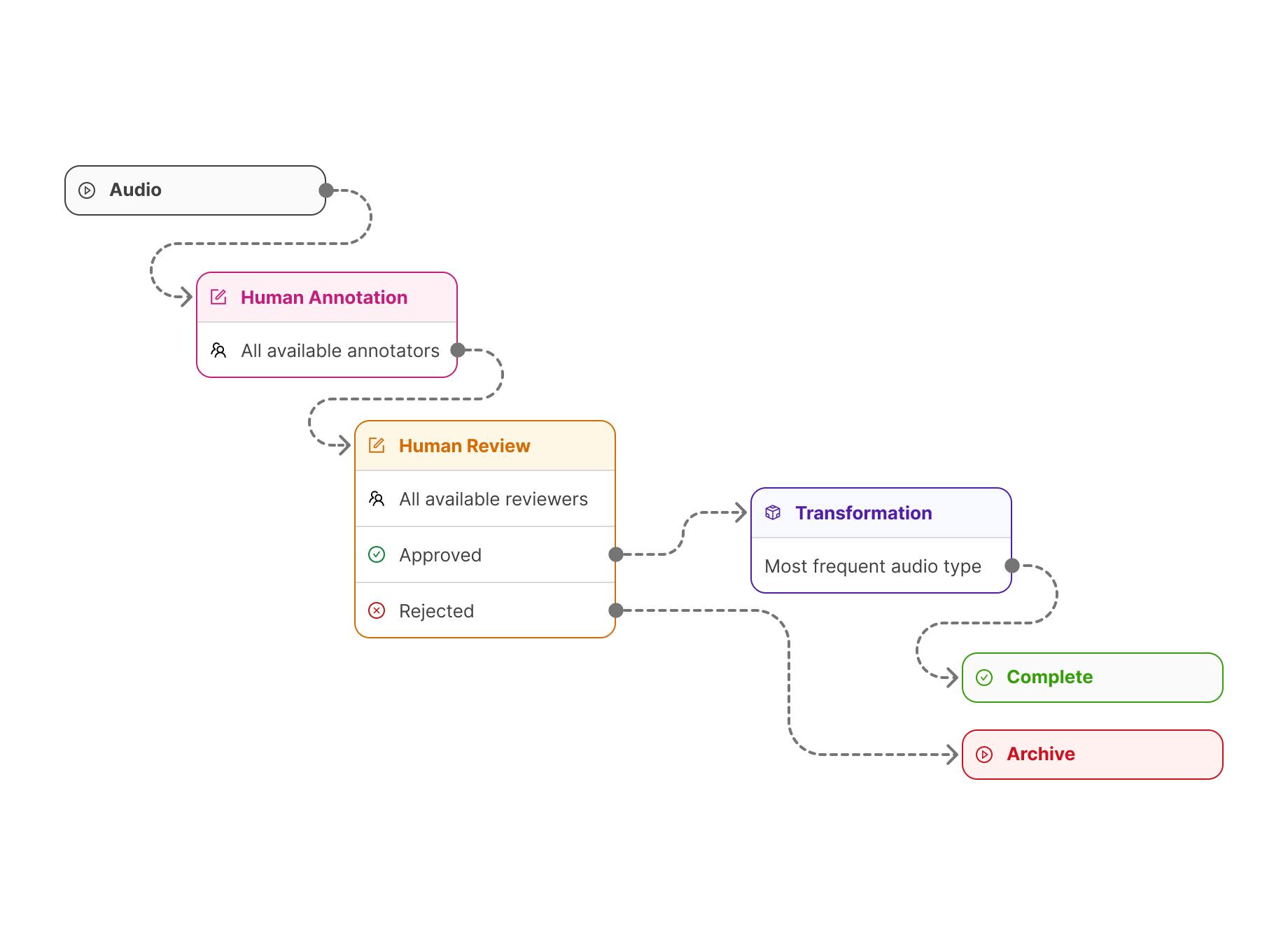
Figure 7: Audio analysis data pipeline combining human annotation with automated verification.
Rather than requiring humans to perform complex end-to-end temporal analysis, you can split this task: leverage human auditory perception for identifying sound types, while delegating mathematical duration computations to automated systems.
Detailed Workflow:
- Raw Audio Collection: Source diverse audio samples containing multiple overlapping sounds - conversations in cafes, street scenes, nature recordings, etc. Aim for 10-30 second clips with clear sound separation.
- Human Annotation Interface: Present annotators with audio waveforms and ask them to mark regions containing different types of sounds (speech, music, mechanical noise, etc.). This leverages human auditory perception without requiring them to do mathematical reasoning.
- Quality Assurance: Route 20% of annotations through additional human reviewers to catch inconsistencies. Track annotator agreement rates and provide feedback to maintain quality.
- Automated Verification: Once regions are marked, computing durations becomes trivial - simply calculate the length of each annotated segment. This creates your verifiable reward signal with zero ambiguity.
- Question Generation: Automatically generate natural language questions: “Which type of sound lasts longest?”, “How many distinct sounds occur simultaneously?”, “Which sound starts first?”
This approach maximizes the strengths of both human cognition and automated computation. Humans contribute their superior auditory perception and pattern recognition capabilities, while automation handles the precise mathematical calculations that provide objective reward signals. The resulting dataset benefits from human perceptual expertise while maintaining the computational rigor necessary to prevent reward hacking during RL training.
Strategy 2: Video Prediction with LLM-Assisted Question Generation
Predicting what happens next in videos requires understanding complex spatiotemporal dynamics. Consider analyzing basketball footage to predict a player’s next move - direct human annotation would require basketball expertise and tremendous time investment.

Figure 8: Video prediction pipeline using VLMs for description and LLMs for question synthesis.
You can scale video prediction dataset creation by leveraging complementary model strengths: vision-language models for rich video understanding, and large language models for diverse question generation. This maintains expert-level quality while reducing human time investment.
Detailed Workflow:
- Video Collection and Preprocessing: Gather diverse video samples (sports footage, traffic scenes, human interactions). Standardize to consistent frame rates and resolutions. For temporal prediction, ensure clips have clear “before” and “after” segments.
- VLM Description Generation: Feed full videos to capable models like GPT-4V or InternVL to generate rich, detailed descriptions: “Player #23 dribbles toward the three-point line while defender #15 approaches from the left. The shot clock shows 8 seconds remaining…”
- LLM Question Synthesis: Pass these descriptions to text-only LLMs with prompts like: “Based on this basketball scene description, generate 4 multiple-choice questions about what the player will do next. Include 1 correct answer and 3 plausible distractors.”
- Rapid Human Validation: Present questions alongside video clips to human validators who simply answer “Yes, this makes sense” or “No, this is wrong/unclear.” This is 10x faster than creating questions from scratch.
- Temporal Segmentation: Use only the first 70% of each video as model input, with the remaining 30% providing ground truth for answer verification.
- Curriculum Progression: Start training with multiple-choice questions (easier for models to learn), then gradually transition to open-ended prediction tasks as the model improves.
This pipeline dramatically improves annotation efficiency by positioning humans as validators rather than creators, leveraging their judgment for rapid yes/no decisions rather than time-intensive content generation. The multiple-choice format provides clear, discrete reward signals essential for stable RL training while serving as a stepping stone toward more sophisticated open-ended reasoning tasks.
Strategy 3: Geometric Understanding Through Model Chaining
For tasks requiring precise spatial reasoning - like “Click on the empty area of this plate” - you need systems that can understand both semantic content and geometric relationships. This represents the most sophisticated level in our complexity progression, where models must produce structured coordinate outputs rather than natural language responses. This requires pixel-level precision that’s difficult for humans to annotate consistently.

Figure 9: Object localization pipeline chaining captioning, NLP, detection, and segmentation models.
For pixel-level precision tasks, you can chain specialized computer vision models: captioning for semantic understanding, detection for localization, and segmentation for precise boundaries. This achieves both accuracy and scale while using targeted human validation for quality control.
Detailed Workflow:
- Diverse Image Collection: Source images with varied objects, scenes, and complexity levels. Include edge cases like partially occluded objects, reflections, and ambiguous boundaries.
- Detailed Captioning: Use state-of-the-art captioning models to generate comprehensive scene descriptions: “A white ceramic plate sits on a wooden table. The plate contains grilled chicken on the left side, steamed broccoli in the upper right, and mashed potatoes in the lower right. The center-left area of the plate appears empty.”
- NLP Object Extraction: Parse captions using spaCy or similar tools to identify all noun phrases that could represent objects: [“plate”, “chicken”, “broccoli”, “potatoes”, “empty area”, “wooden table”].
- Open-Vocabulary Detection: Apply models like Grounding DINO that can detect any object given a text description. Generate bounding boxes for each extracted entity, including abstract concepts like “empty space.”
- Precise Segmentation: Use SAM (Segment Anything Model) to convert bounding boxes into pixel-perfect masks. SAM excels at finding precise object boundaries even for challenging cases.
- Intelligent Point Sampling: Rather than random sampling within masks, use strategies like:
- Center-of-mass for solid objectsRandom sampling with bias toward central regionsEdge-aware sampling that avoids boundaries for “click” tasks
- Geometric Verification: Validate that sampled points actually lie within the intended semantic regions using intersection-over-union metrics and distance calculations.
- Human Quality Control: Present final point annotations to humans for rapid yes/no validation: “Does this point correctly identify the empty area of the plate?”
This model chaining approach achieves high precision with minimal human overhead by exploiting the specialized capabilities of different computer vision systems. Each component in the pipeline focuses on its particular strength: captioning models for semantic understanding, detection models for localization, segmentation models for precise boundaries. Geometric verification provides quantitative quality assurance that supports reliable reward signal generation.
The Critical Role of Curriculum Learning
Each of these strategies incorporates curriculum learning principles - starting simple and gradually increasing complexity. This isn’t just pedagogically sound; it’s essential for preventing entropy collapse in RL training.
- Audio tasks: Begin with clear, well-separated sounds before tackling noisy, overlapping audio
- Video prediction: Start with obvious actions (shooting vs. passing) before subtle movement predictions
- Geometric tasks: Begin with large, prominent objects before small or partially hidden ones
By providing models with achievable early objectives, you maintain the exploration diversity necessary for robust learning while building toward sophisticated multimodal reasoning capabilities.
The Art of Scaffolding: From Cold Start to Production
While the data pipelines we’ve explored can generate the raw materials for RL training, there remains a fundamental challenge: you cannot simply throw a base model into an RL training loop and expect it to develop sophisticated reasoning capabilities. The exploration space is too vast, the reward signals too sparse, and the risk of entropy collapse too great. This is where scaffolding becomes essential.
The story of DeepSeek-R1’s development provides the clearest illustration of how iterative scaffolding transforms theoretical RL potential into practical reasoning capability. The journey wasn’t a single training run, but rather a carefully orchestrated progression through three distinct model generations, each building upon lessons learned from the previous iteration. The researchers began with their GRPO algorithm applied to a base model, allowing the system to explore reasoning strategies through pure reinforcement learning. What emerged was simultaneously encouraging and problematic. The model did develop reasoning capabilities (it could solve mathematical problems and articulate multi-step solutions) but the reasoning traces themselves were chaotic. Text would switch unpredictably between Chinese and English mid-sentence. Logical steps would appear and disappear without clear motivation. The formatting was inconsistent, making it difficult to parse the model’s actual thought process. While the final answers were often correct, the path to get there resembled a hiker bushwhacking through dense forest rather than following a well-marked trail.
Rather than attempting to fix these issues through reward engineering alone, the team took a step back and invested heavily in human curation. They collected thousands of these messy but fundamentally sound reasoning traces and had human annotators clean them, standardizing language usage, clarifying logical connections, and establishing consistent formatting conventions. This created a curated dataset of high-quality chain-of-thought examples that captured what the RL process had discovered about reasoning, but in a form that could be reliably learned. The second model generation started fresh with a new base model that had no prior exposure to the RL process. This model was trained purely through supervised fine-tuning on the cleaned reasoning traces, learning to emulate the structured thinking patterns that human curators had extracted from the chaotic first-generation outputs. No reinforcement learning was involved at this stage, just traditional next-token prediction on carefully crafted examples.
This supervised phase proved crucial for stability. When the team applied GRPO to this second-generation model, the training dynamics were dramatically different. The model had already internalized basic reasoning structures and formatting conventions, so the RL process could focus on refining reasoning strategies rather than discovering them from scratch. The reward functions could be adjusted to emphasize language consistency and logical coherence, building on the foundation rather than fighting against entropy. The exploration process remained productive because the model started from a reasonable prior rather than random initialization. A third iteration repeated this cycle, collecting improved reasoning traces from the second-generation RL model, potentially incorporating human preference data through RLHF-style training, and using these materials to train an even more refined model. Each cycle tightened the feedback loop between what the RL process discovered and what the supervised phase could reliably teach.
This iterative scaffolding approach extends beyond any single training run. Production deployments generate valuable data that feeds back into development. Edge cases discovered by users become targeted training examples. Failure modes inform reward function adjustments. The development process becomes a continuous cycle of improvement rather than a one-shot optimization problem. For teams building multimodal RL systems, this raises an immediate practical question: how do you acquire that critical cold-start data that makes the first supervised fine-tuning phase possible?
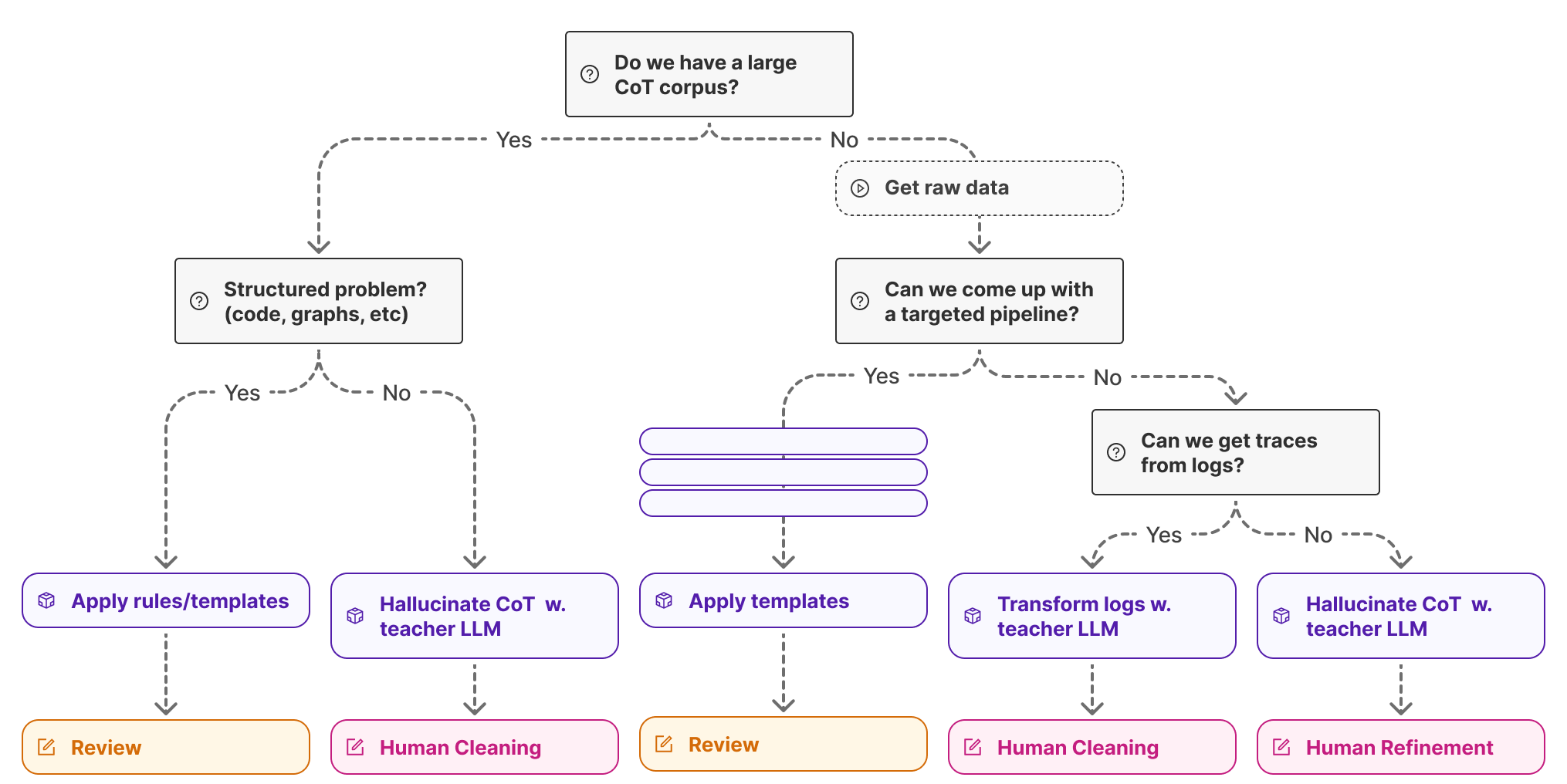
Figure 10: Decision tree for strategically acquiring chain-of-thought training data to bootstrap RL systems.
The path to cold-start data depends heavily on the problem structure and available resources, but a systematic approach can help identify the most efficient strategy. The decision process begins with a fundamental question: do you already have access to a large corpus of chain-of-thought examples for your target task? If you’re working in a well-established domain like mathematical reasoning or code generation, you might find existing open-source datasets that partially align with your needs. When such resources exist, the next consideration is whether your problem has inherent structure that can be exploited. Problems involving code, mathematical equations, or formal graphs often allow you to apply templates and rules that generate reasoning traces automatically. In such scenario, you understand the underlying logic well enough to write it down explicitly. Even when you can’t create everything through rules, you might use off-the-shelf language models to hallucinate chain-of-thought traces for your examples, then route these synthetic traces through human review for quality assurance.
When you don’t have existing chain-of-thought corpora, the path becomes more involved but still tractable. Start by collecting raw data relevant to your task. That could be videos, images, audio clips, sensor readings, or whatever modality your application requires. The critical question then becomes whether you can design a targeted pipeline that automates significant portions of the annotation process. This is precisely what we explored in our three data acquisition strategies: splitting perception from computation in audio analysis, leveraging model-generated descriptions for video prediction, and chaining specialized computer vision models for geometric reasoning. These pipelines don’t eliminate human involvement, but they transform it from slow, expensive content creation into rapid validation and quality control.
If you cannot design such an automation pipeline, e.g., because your task requires subjective judgment or deep domain expertise, look for existing systems where users are already performing similar tasks. User logs from production systems, annotations from related applications, or expert demonstrations captured during normal workflows can all be transformed into training data with the help of teacher language models that convert implicit knowledge into explicit reasoning traces. This approach piggybacks on work that’s happening anyway, capturing valuable supervision without dedicated annotation efforts. In the medical domain, for example, doctors already write diagnostic reports when analyzing CT scans. Those reports can be structured and expanded into reasoning traces that teach models not just what diagnosis to reach, but how to think about the visual evidence.
Only when all other avenues are exhausted should you resort to purely manual annotation where experts create chain-of-thought traces from scratch. Even then, interactive annotation tools that provide real-time feedback and suggestions can make the process more efficient. The key insight is that acquiring cold-start data is rarely about choosing a single approach. Most successful projects combine multiple strategies, using templates for simple cases, model-generated traces for common scenarios, automated pipelines for perceptual tasks, and targeted human expertise for the most challenging edge cases. The goal is not perfection in your initial training set, but rather achieving sufficient quality and diversity to give your model a reasonable starting point. Once you have that foundation, the iterative refinement process of collecting better examples from RL training, cleaning them, and feeding them back into supervised learning can progressively improve the system.
The teams that succeed with multimodal RL don’t treat data acquisition as a one-time preprocessing step. They build it into their core development loop, constantly collecting new examples, identifying failure modes, and refining their training distributions. They obsess over their datasets, understanding not just aggregate statistics but the specific examples where their models struggle. This attention to data quality and continuous iteration separates systems that merely demonstrate RL on toy problems from those that achieve reliable reasoning in production applications.
Conclusion
The surge of interest in multimodal reinforcement learning following DeepSeek-R1 has created both opportunity and challenge for teams building production AI systems. While the algorithmic foundations are increasingly well understood, success ultimately depends on your ability to systematically acquire, scaffold, and iterate on training data. The pipelines we’ve explored provide concrete starting points for tackling problems where synthetic data generation isn’t feasible. The examples combining human perception with automated verification, chaining specialized models, and strategically designing curriculum progressions. But, perhaps the most important lesson is this: treat your data with the same rigor and obsessive attention that you’d give to your model architecture, because in the end, that’s what determines whether your RL system learns meaningful reasoning or simply discovers clever shortcuts.
If you want to learn more about the topic, we’ve compiled a list of both seminal papers, most recent advancements (at the time of writing), and useful blog posts below. We hope you enjoy.
Essential Reading List
Seminal Papers
The breakthrough paper that demonstrated reasoning capabilities can emerge purely from reinforcement learning without requiring extensive chain-of-thought supervised fine-tuning data. DeepSeek-R1-Zero showed that reasoning simply emerges from the RL process, while DeepSeek-R1 incorporates multi-stage training with cold-start data to achieve performance comparable to OpenAI-o1. Essential for understanding the theoretical foundation of why data scaffolding prevents entropy collapse.
The foundational InstructGPT paper that established Reinforcement Learning from Human Feedback (RLHF) as a core alignment technique. Demonstrated how 1.3B parameter models fine-tuned with human feedback could outperform 175B parameter models. Critical for understanding the human-in-the-loop workflows central to all three data acquisition strategies.
The seminal work introducing chain-of-thought reasoning, showing how providing step-by-step reasoning examples dramatically improves complex reasoning tasks. Essential for understanding how reasoning traces work in supervised fine-tuning before RL training, and why cold-start data with explicit reasoning is crucial for stable multimodal RL.
Introduced Group Relative Policy Optimization (GRPO), the algorithmic foundation behind DeepSeek-R1’s success. Demonstrates how relative rewards between multiple rollouts can provide stable gradient signals for RL training. GRPO has become the dominant algorithm in multimodal RL (used in 13 of 22 major publications), making this paper essential for understanding the practical implementation of the approaches in this framework.
Recent High-Impact Developments from ArXiv
Directly implements Strategy 1 (audio analysis with human-in-the-loop). Achieves 67.08% accuracy on MMAU benchmark with 16.35% improvement over base model. Demonstrates structured CoT reasoning with curriculum learning (easy-to-hard progression) and proves that SFT warm-up is critical for stable RL training in audio domain. Essential reading for teams implementing audio analysis pipelines.
The “pointing” paper - demonstrates geometric understanding through coordinate prediction, showing how multimodal RL can output precise spatial information rather than just text. Directly relates to Strategy 3’s model chaining approach for geometric understanding. Critical for understanding how RL systems can generate structured outputs beyond text.
First framework to unify audio, visual, and textual modalities for general reasoning via RL. Achieves 85.77% accuracy on AVQA-R1-6K validation with significant gains in only 562 RL steps. Demonstrates “aha moments” - self-corrective reasoning where models revisit assumptions. Essential for understanding true multimodal integration beyond single-modality approaches.
Addresses the critical challenge of optimal dataset mixing across different modalities during RL training. First systematic framework for optimizing data mixture strategies, achieving 5.24% average improvement over uniform mixture on out-of-distribution benchmarks. Directly relevant to implementing the multi-strategy approach outlined in the data acquisition framework.
Comprehensive survey paper providing theoretical foundation for multimodal RL applications. Essential background reading that covers the broader landscape of reinforcement fine-tuning in multimodal systems, helping contextualize the specific strategies within the larger field.
Web Resources and Practical Implementation Guides
1. Top RLHF Tools: Reinforcement Learning From Human Feedback
Publisher: Encord
URL: https://encord.com/blog/top-tools-rlhf/
Comprehensive overview of practical RLHF implementation tools and platforms. Covers the engineering infrastructure needed to implement the data scaffolding strategies discussed in your talk. Includes detailed comparisons of platforms supporting multimodal annotation, RLHF workflows, and curriculum learning approaches essential for all three strategies.
2. AI Data Platform: Manage, Curate & Annotate Multimodal Data
Publisher: Encord
URL: https://encord.com/blog/multimodal-ai-data-platform/
Detailed guide to multimodal data curation and annotation workflows. Directly relevant to implementing the human-in-the-loop strategies for audio, video, and geometric understanding tasks. Covers enabling RLHF flows and seamless data annotation to prepare high-quality data for training extremely complex AI models such as generative video and audio AI.
3. Best Data Annotation Tools for Generative AI in 2025
Publisher: Encord
URL: https://encord.com/blog/best-data-annotation-tools-for-generative-ai/
Practical resource covering the annotation infrastructure needed for RLHF workflows and multimodal AI development. Essential for teams implementing the data acquisition strategies outlined in your framework. Emphasizes that AI teams need structured feedback loops like RLHF to train safe, high-performing models, along with specialized data-annotation platforms that can manage multimodal data at scale.
4. RLHF Definition and Implementation Guide
Publisher: Encord
URL: https://encord.com/glossary/rlhf-definition/
Foundational resource explaining RLHF concepts and implementation considerations. Provides the practical context needed to understand how the theoretical frameworks connect to real-world deployment, including facilitating reinforcement learning from human feedback, preference ranking, and rubric-based evaluations.
Bonus: Algorithmic Deep Dives
Group Relative Policy Optimization (GRPO) Implementation Guide
Publisher: Hugging Face TRL Documentation
URL: https://huggingface.co/docs/trl/main/en/grpo_trainer
Technical implementation guide for GRPO, the dominant algorithm used in 13 of 22 major multimodal RL publications. Essential for practitioners implementing the RL training components of the data acquisition strategies. Many LLM training tools now provide GRPO as default fine-tuning mechanisms to teach LLMs to reason on specific tasks.
OpenRLHF: Open Source RLHF Framework
Publisher: Various contributors
URL: https://github.com/volcengine/verl
Open-source implementation framework mentioned in your talk as one of the practical tools for implementing RLHF at scale. Useful for teams building the infrastructure needed to support the iterative data improvement and continuous model development emphasized in your presentation.
References
[1] Guanghao Zhou, Panjia Qiu, Cen Chen, Jie Wang, Zheming Yang, Jian Xu, Minghui Qiu: Reinforced MLLM: A Survey on RL-Based Reasoning in Multimodal Large Language Models. CoRR abs/2504.21277 (2025)
[2] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, Daya Guo: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. CoRR abs/2402.03300 (2024)