Text2Cinemagraph: Synthesizing Artistic Cinemagraphs

Step into the captivating world of cinemagraphs, in which elements of a visual come to life with fluid motion.
Crafting cinemagraphs has traditionally been a laborious process involving video capture, frame stabilization, and manual selection of animated and static regions.
But what if there was a revolutionary method that brings cinemagraph creation to a whole new level of simplicity and creativity? Let’s delve into this exciting research.
Introducing Text2Cinemagraph - this groundbreaking method leverages the concept of twin image synthesis to generate seamless and visually captivating cinemagraphs from user-provided text prompts. Text2Cinemagraph not only breathes life into realistic scenes but also allows creators to explore imaginative realms, weaving together various artistic styles and otherworldly visions.

Text Prompt: ‘a large waterfall falling from hills during sunset in the style of Leonid Afremov’.
Before diving into the details of Text2Cinemagraph, let’s discuss text-based synthetic cinemagraphs.
Text-based Synthetic Cinemagraphs
Cinemagraphs are visuals where certain elements exhibit continuous motion while the rest remain static. Traditionally, creating cinemagraphs has involved capturing videos or images with a camera and using semi-automated methods to produce seamless looping videos. This process requires considerable user effort and involves capturing suitable footage, stabilizing frames, selecting animated and static regions, and specifying motion directions.
Text-based cinemagraph synthesis expedites this process. The method generates cinemagraphs from a user-provided text prompt, allowing creators to specify various artistic styles and imaginative visual elements. The generated cinemagraphs can depict realistic scenes as well as creative or otherworldly compositions.
There are two approaches for generating synthetic cinemagraphs:
Text-to-Image Models
One method is to generate an artistic image using a text-to-image model and subsequently animate it. However, this approach faces challenges as existing single-image animation techniques struggle to predict meaningful motions for artistic inputs. This is primarily due to their training on real video datasets. Creating a large-scale dataset of artistic looping videos, however, is impractical due to the complexity of producing individual cinemagraphs and the wide variety of artistic styles involved.

Text-to-Video Models
An alternative approach is to use text-to-video models for generating synthetic cinemagraphs. Unlike the previous method of first generating an artistic image and then animating it, text-to-video models directly create videos based on the provided text prompts.
However, experiments have revealed that these text-to-video methods often introduce noticeable temporal flickering artifacts in static regions and fail to produce the desired semi-periodic motions required for cinemagraphs. These issues arise due to the challenges of accurately predicting continuous and seamless motions solely from text descriptions.
Text2Cinemagraph aims to overcome these limitations and enhance motion prediction by leveraging the concept of twin image synthesis.
Text2Cinemagraph: Synthesizing Artistic Cinemagraphs from Text
Text2Cinemagraph presents a fully-automated approach to generating cinemagraphs from text descriptions. The research paper, authored by Aniruddha Mahapatra and Jun-Yan Zhu from CMU and Aliaksandr Siarohin, Hsin-Ying Lee, and Sergey Tulyakov from Snap Research, introduces an innovative method that overcomes the difficulties of interpreting imaginary elements and artistic styles in the prompts to generate cinemagraphs.

Synthesizing Artistic Cinemagraphs from Text
Text2Cinemagraph achieves a seamless transfer of motion from a realistic image to an artistic one by synthesizing a pair of images. The process generates a visually appealing cinemagraph that brings the text description to life with fluid and mesmerizing motion. Text2Cinemagraph not only outperforms existing approaches but also offers extensions for animating existing paintings and controlling motion directions using text commands.

Text Prompt: “a large river in a futuristic world, large buildings, cyberpunk style”
Text2Cinemagraph: Core Design
The core design of Text2Cinemagraph contains 3 elements: twin image generation, mask-guided optical flow prediction, and video generation.
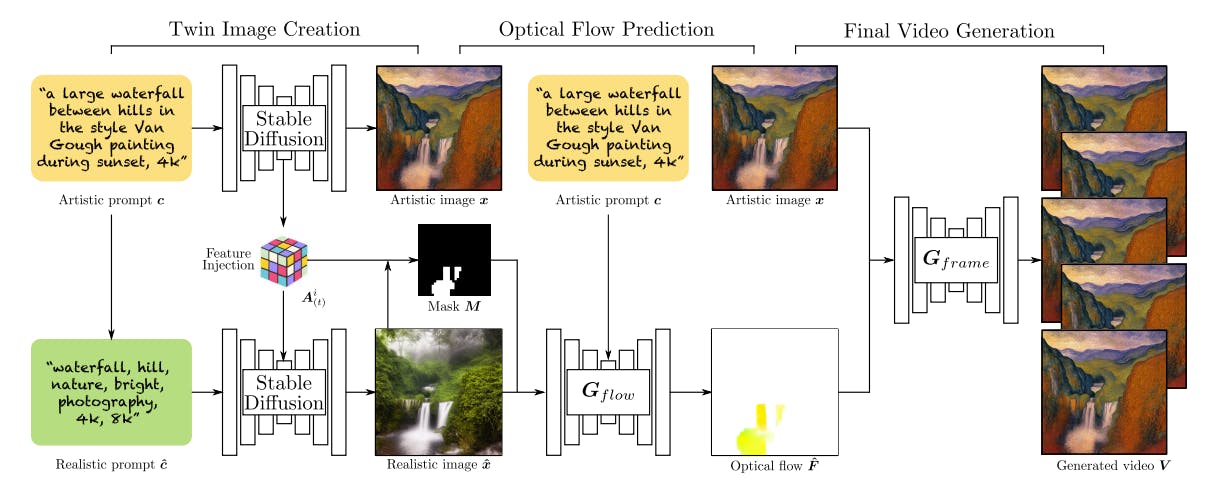
Synthesizing Artistic Cinemagraphs from Text
Twin Image Generation
The twin image generation method involves creating an artistic image from the input text prompt using Stable Diffusion and generating a corresponding realistic counterpart with a similar semantic layout. This is achieved by injecting self-attention maps and residual block features into the UNet module during the degeneration process, ensuring meaningful correspondence between the twin images.
This step lays the foundation for accurate motion prediction in the next step.
Mask-Guided Flow Prediction
Text2Cinemagraph uses a mask-guided approach to define the regions to animate in the image. The flow prediction model uses a pre-trained segmentation model which is trained on real images, ODISE, and user-specified region names, to predict the binary mask. The model is refined using self-attention maps from the diffusion model.
Using this mask as a guide, the flow prediction model generates the optical flow for the realistic image. The flow prediction model is conditioned not only on the mask but also on the CLIP embedding of the input text prompt. This allows the model to incorporate class information from the text, such as “waterfall” or “river,” to determine the natural direction in the predicted flow.
This method effectively addresses the challenges of the boundaries of static regions and ensures smoother animation.
Flow-Guided Video Generation
After predicting the optical flow for the realistic image, it is transferred to animate the artistic image. This transfer is possible because of the similar semantic layout between the real and the artistic image.
Now, to generate the cinemagraph, each frame is generated separately. For the looping effect, the artistic image serves as both the first and last frame. Euler integration of the predicted optical flow is performed to obtain the cumulative flows in forward and backward directions.
Surprisingly, despite being trained on real-domain videos, the model can animate the artistic image without modification. This is achieved by essentially in painting small holes in the feature space generated during symmetric splatting, with surrounding textures providing repetitive patterns.
Text2Cinemagraph: Results
The training of Text2Cinemagraph involves two domains: Real Domain and Artistic Domain. The real domain includes a dataset of real-life videos with ground-truth optical flow, while the artistic domain generates artistic images from different captions generated using BLIP.
 💡The PyTorch implementation of Text2Cinemagraph can be found here.
💡The PyTorch implementation of Text2Cinemagraph can be found here. The models are trained with UNet backbones and cross-attention layers. Text2Cinemagraph outperforms recent methods in both domains, demonstrating its effectiveness in generating high-quality cinemagraphs from text prompts.
Real Domain Results

Text prompt: ‘a large river flowing in front of a mountain in the style of starry nights painting’.
In the real domain, Text2Cinemagraph outperforms baselines in both qualitative and quantitative evaluations. This method predicts more plausible flows, covering entire dynamic regions like rivers.
Synthesizing Artistic Cinemagraphs from Text
Quantitatively, this method achieves significantly lower FVD scores, closely matching the fidelity of ground-truth videos. Hence, Text2Cinemagraph excels in generating high-quality cinemagraphs from real-world videos.
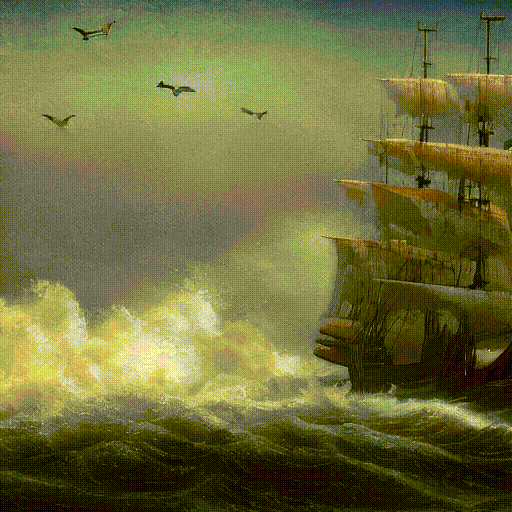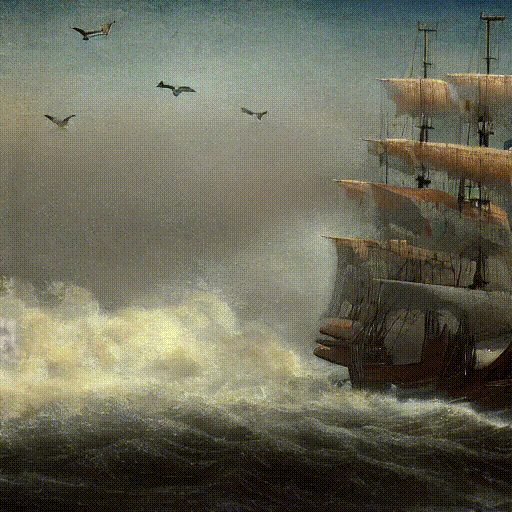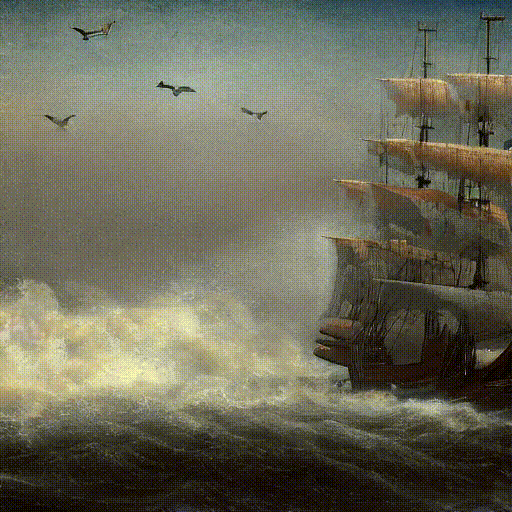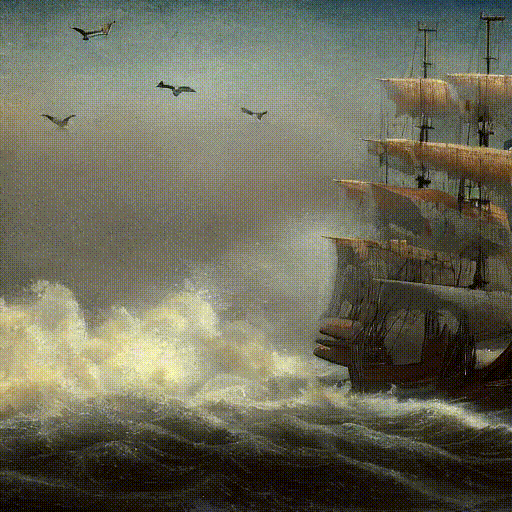
Text Prompt: ‘Pirate ships in turbulent ocean, ancient photo, brown tint’.
Artistic Domain Results

Synthesizing Artistic Cinemagraphs from Text
In the Artistic Domain, Text2Cinemagraph excels in qualitative comparison. It predicts cleaner flows, focusing accurately on desired regions, while baselines produce inaccurate flows with artifacts.
Other text-to-video methods struggle to capture details or preserve temporal consistency. Text2Cinemagraph generates higher-quality cinemagraphs with smooth motion, overcoming limitations of other approaches and showcasing its ability to bring artistic visions to life.
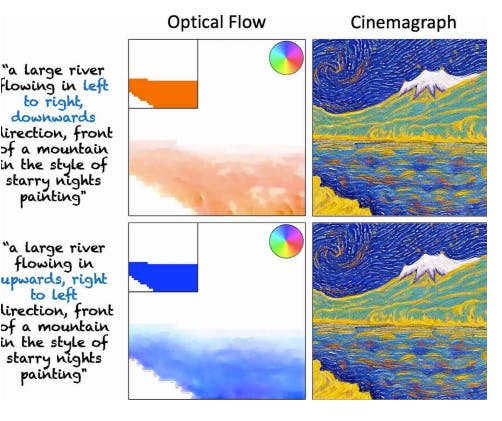
Text-Guided Direction Control
This method also allows you to provide text-guided direction control for cinemagraph generation. This allows the manipulation of the direction of the movements in the cinemagraph according to the text prompt.
Text Prompt: “a large river flowing in left to right, downwards direction in front of a mountain in the style of starry nights painting”.

Text Prompt: “a large river flowing in upwards, right to left direction> in front of a mountain in the style of starry nights painting”
Text2Cinemagraph: Limitations
Text2Cinemagraph has some limitations:
- Artistic and realistic images may not always correspond to the input text, leading to missing dynamic regions in the generated images.
- Structural alterations in the artistic image can occur, even though it shares self-attention maps with the realistic image.
- The pre-trained segmentation model (e.g., ODISE) might struggle with complex natural images, leading to imperfect segmentation and unusual movements in the generated cinemagraphs.
- Optical flow prediction may fail for images with unusual compositions and complex fluid dynamics.
- Significant changes in flow direction, like repeated zig-zag movement of water, may be challenging for the optical flow model to predict accurately.
Text2Cinemagraph: Key Takeaways
- Text2Cinemagraph generates captivating cinemagraphs from text descriptions, offering a fully automated solution for cinemagraph creation.
- Concept behind Text2Cinemagraph: It uses twin image synthesis, transferring motion from realistic images to artistic ones for seamless animations.
- Text2Cinemagraph excels in generating high-quality cinemagraphs for real and artistic domains. It also enables text-guided direction control for manipulating movement based on text prompts.
Read More
Read more on other recent releases:
Frequently asked questions
Encord includes a curation feature that allows users to identify and select interesting frames or phases within lengthy surgical videos. This feature is useful for enhancing the annotation process, although it may not always be necessary depending on the project specifics.
Encord allows users to import and curate text data sets, such as the IMDb text reviews from Hugging Face, by providing a streamlined process for loading files, adding metadata, and generating embeddings. This enables efficient project management and labeling workflows.
Encord provides tools that assist in the curation process by identifying interesting moments in video data. This feature is particularly beneficial for users needing to sift through hours of footage to find relevant content, streamlining the data annotation workflow.
Encord's interpolation functionality is designed to work across multiple frames. Users can manually annotate two frames and then use the interpolation feature to map the changes between those frames, creating a linear progression of labels across the selected frames.
Encord's go-to-market strategy emphasizes building brand awareness and establishing meaningful partnerships. The company aims to connect with clients and partners to demonstrate the value of its annotation platform, particularly in the video and AI training spaces.
Encord offers an intuitive user interface that simplifies the labeling process, reducing the time spent navigating cumbersome menus. This user-friendly design helps annotators focus on their work, leading to higher quality data and faster output.
Encord offers features that streamline the management of annotation hours across multiple agencies, allowing for better oversight and coordination. This is particularly useful for complex projects that require contributions from various teams.
Encord enables users to link annotations with historical field reports, ensuring that image data is contextualized with specific narratives from field engineers, thus enhancing the reliability and usefulness of the annotated data.
Yes, Encord's platform is designed to streamline the labeling process, allowing users to handle multiple queues without the need for task duplication. This reduces the risk of errors, such as dropped frames or unreadable content.
Encord accommodates both in-house teams and outsourced annotators, allowing for flexibility as project teams may change over time. This adaptability ensures that you can scale your annotation efforts based on project demands.