Visual Foundation Models vs. State-of-the-Art: Exploring Zero-Shot Object Segmentation with Grounding-DINO and SAM

In the realm of AI, ChatGPT has gained significant attention for its remarkable conversational competency and reasoning capabilities across diverse domains. However, while ChatGPT excels as a large language model (LLM), it currently lacks the ability to process or generate images from the visual world. This limitation leads us to explore Visual Foundation Models, such as Segment Anything Model (Meta), Stable Diffusion, Visual GPT (Microsoft), and many more which exhibit impressive visual understanding and generation capabilities.
However, it's important to note that these models excel in specific tasks with fixed inputs and outputs. In this exploration of zero-shot object segmentation with Encord Active, we will compare the capabilities of Visual Foundation Models with state-of-the-art (SOTA) techniques to assess their effectiveness and potential in bridging the gap between natural language processing (NLP) and computer vision.

Visual Foundation Models
Visual foundations models are large neural network models that have been trained on massive amounts of high-quality image data to learn the underlying patterns. These models are trained on unlabeled data using self-supervised learning techniques and demonstrate remarkable performance across a wide range of tasks including image segmentation, question-answering, common sense reasoning, and more.
The self-supervised learning process involves training the models to predict missing or masked portions of the input data, such as reconstructing a partially obscured image. By learning from the inherent patterns and structure in the data, these models acquire a generalized understanding of the domain and can apply that knowledge to various tasks.
Visual foundation models are designed to be generic and versatile and are capable of understanding visual data across different domains and contexts. They can be fine-tuned to excel in specific computer vision tasks such as image classification, object detection, semantic segmentation, image captioning, and more.
 💡 Learn more about visual foundation models in the blog Visual Foundation Models (VFMs) Explained
💡 Learn more about visual foundation models in the blog Visual Foundation Models (VFMs) Explained In this article, we will focus on two of the visual foundation models introduced recently.
Grounding DINO
Grounding DINO is an object detector that combines transformer-based detector DINO with grounded pre-training which leverages both visual and text inputs.
In open-set object detection, the task involves creating models that not only have the capability to detect familiar objects encountered during training but also possess the ability to distinguish between known and unknown objects. Additionally, there is a need to potentially detect and locate these unknown objects. This becomes crucial in real-world scenarios where the number of object classes is vast, and obtaining labeled training data for every conceivable object type is impractical.
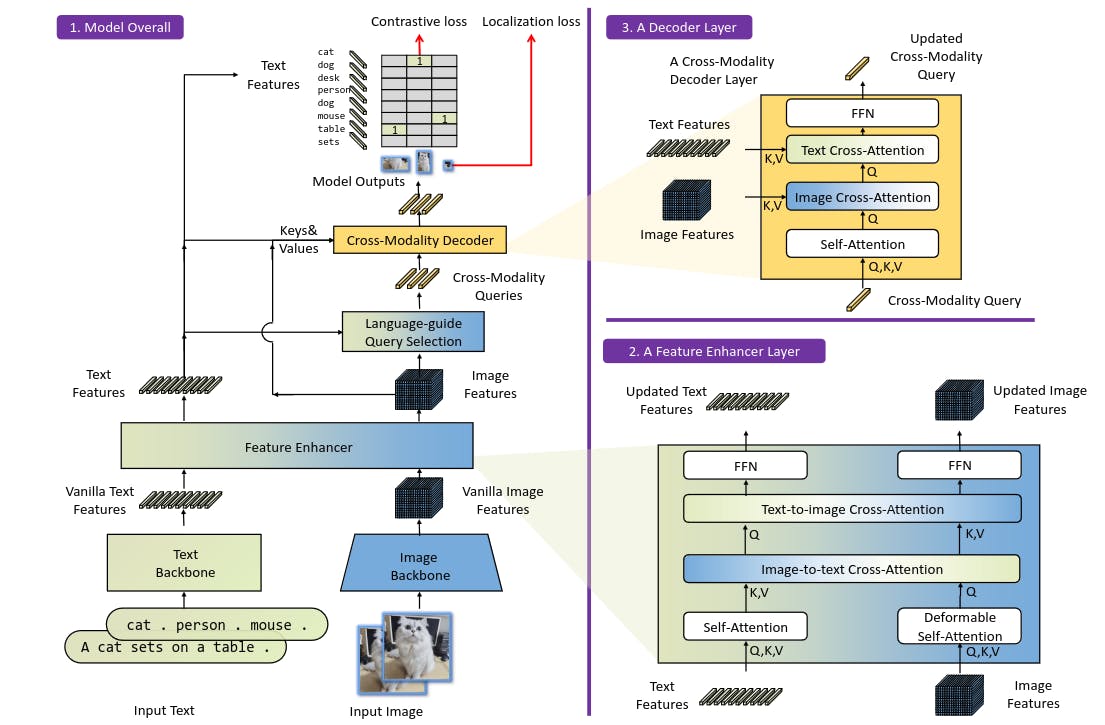
Grounding-DINO is a model that takes input in the form of image-text pairs and outputs 900 object boxes, along with their associated objectness confidence scores. It also provides similarity scores for each word in the input text. The model performs two selection processes: first, it chooses boxes that exceed a certain box threshold, and then it extracts words with similarity scores higher than a specified text threshold for each selected box.

However, obtaining bounding boxes is only one part of the task. Another foundation model called the Segment Anything Model (SAM), from Meta AI, is employed to achieve object segmentation. SAM leverages the bounding box information generated by Grounding-DINO to segment the objects accurately.
Segment Anything Model (SAM)
Segment Anything Model is a state-of-the-art visual foundation model fine-tuned for image segmentation. It focuses on promptable segmentation tasks, using prompt engineering to adapt to diverse downstream tasks.
Read the blog Meta AI's Breakthrough: Segment Anything Model (SAM) Explained to better understand SAM. Large language models like GPT-3 and GPT-4 (from OpenAI) possess remarkable aptitude for zero-shot and few-shot generalization. They can effectively tackle tasks and data distributions that were not encountered during their training process. To achieve this, prompt engineering is often employed, where carefully crafted text prompts the large language model (LLM), enabling it to generate appropriate textual responses for specific tasks. Taking inspiration from ChatGPT, SAM employs prompt engineering for segmentation tasks.
This visual foundation model is trained on the largest high-quality labeled segmentation dataset (SA-1B) with over 1 billion masks on 11 million images. The segment anything model hinges on three components: a promptable segmentation task to enable zero-shot generalization, model architecture, and the large training dataset that powers the segmentation task and the model.

Now, let's examine the performance of these visual foundation models in comparison to traditional computer vision models.
Traditional Computer Vision Models Vs Visual Foundation Models
When comparing traditional computer vision models with visual foundation models, there are notable distinctions in their approaches and performance.
Traditional computer vision models typically rely on handcrafted features and specific algorithms tailored to specific tasks, such as object detection or image classification. These models often require extensive manual feature engineering and fine-tuning to achieve optimal results.
On the other hand, visual foundation models leverage the power of machine learning and large-scale pretraining on diverse image datasets. These models learn representations directly from the data, automatically capturing complex patterns and features. They possess a broader understanding of visual information and can generalize well across different domains and tasks. Visual foundation models also have the advantage of transfer learning, where pre-trained models serve as a starting point for various computer vision tasks, reducing the need for extensive task-specific training.

In terms of performance, baseline visual foundation models have demonstrated remarkable capabilities, often surpassing or rivaling traditional computer vision models on a wide range of tasks, such as object detection, image classification, semantic segmentation, and more. Their ability to leverage pre-trained knowledge, adaptability to new domains, and the availability of large-scale datasets for training contribute to their success.
It is worth noting that the choice between traditional computer vision models and visual foundation models depends on the specific task, available resources, and the trade-off between accuracy and computational requirements. While traditional models may still excel in certain specialized scenarios or resource-constrained environments, visual foundation models have significantly impacted the field of computer vision with their superior performance and versatility.
With the abundance of available models in the field of artificial intelligence, simply selecting a state-of-the-art (SOTA) model for specific tasks does not ensure favorable results. It becomes crucial to thoroughly test and compare different models before building your AI model. In this context, we will compare the performance of baseline visual foundation models and traditional computer vision models specifically for zero-shot instance segmentation.
💡Check out Webinar: Are Visual Foundation Models (VFMs) on par with SOTA? for a detailed analysis. Performance Comparison: Visual Foundation Models (VFMs) vs. Traditional Computer Vision (CV) Models in Zero-Shot Instance Segmentation
Testing Grounding DINO
As mentioned previously, Grounding DINO integrates two AI models: DINO, a semi-supervised vision transformer model, and GLIP (Grounded Image-Language pre-training). The implementation of Grounding DINO is straightforward and has been made open-source, allowing the public to easily access and experiment with it.
The open-source implementation of Grounding DINO can be found on GitHub. The implementation of Grounding DINO is carried out in PyTorch and the pre-trained models are made available.
Testing SAM
As we discussed earlier, SAM is designed with the core concept of enabling the segmentation of any object, as implied by its name, without the need for prior training. It achieves this through zero-shot segmentation, allowing for versatility in handling various objects.
During testing, SAM's performance can be evaluated by providing different types of prompts, including points, text, or bounding boxes. These prompts guide SAM to generate accurate masks and segment the desired objects. SAM employs an image encoder that generates embeddings for the input images, which are then utilized by the prompt encoder to generate the corresponding masks.
The open-source implementation of SAM can be found on GitHub. The GitHub repository of SAM offers a comprehensive set of resources for testing the Segment Anything Model. It includes code for running inference with SAM, convenient links to download the trained model checkpoints, and example notebooks that provide step-by-step guidance on utilizing the model effectively.
Testing Grounding DINO+SAM
The Segment Anything Model (SAM) is not inherently capable of generating inferences without specific prompts. To overcome this limitation, a novel approach was proposed to combine SAM with Grounding DINO. By using the candidate bounding boxes generated by Grounding DINO as prompts, SAM performs segmentation efficiently.
The open-source implementation of Grounding DINO + SAM can be found on GitHub. This integration of Grounding DINO and SAM allows us to leverage the remarkable zero-shot capabilities of both Grounding DINO and SAM, which significantly reduces the reliance on extensive training dataset. By harnessing the strengths of both models, an efficient segmentation model can be built without compromising accuracy or requiring additional data for training.
For the effortless implementation of Grounding DINO, SAM, and Grounded SAM models with Encord Active, a comprehensive Colab notebook is available. This notebook provides a user-friendly interface for quick experimentation with these models. Performance Evaluation of VFMs vs Traditional CV Models
When evaluating the performance of computer vision models, it is beneficial to use popular datasets that are widely utilized for testing vision models. One such dataset is EA-quickstart, which is a subset of COCO datasets containing commonly seen images. Additionally, the evaluation includes the BDD dataset.
To measure the performance, several evaluation metrics are employed, including mean average precision (mAP), mean average recall (mAR), as well as class-based AP, and AR. These metrics provide insights into the accuracy and completeness of instance segmentation.
Colab Notebook of implementation zero-shot image segmentation and performance evaluation with Encord Active. In the comparison between Grounded SAM and Mask R-CNN, a highly efficient computer vision model for instance segmentation, Grounded SAM exhibits impressive performance in terms of mean average recall. This indicates its ability to identify a substantial number of labeled datasets. However, it demonstrates a lower mean average precision, implying the detection of unlabeled objects, which can pose challenges.
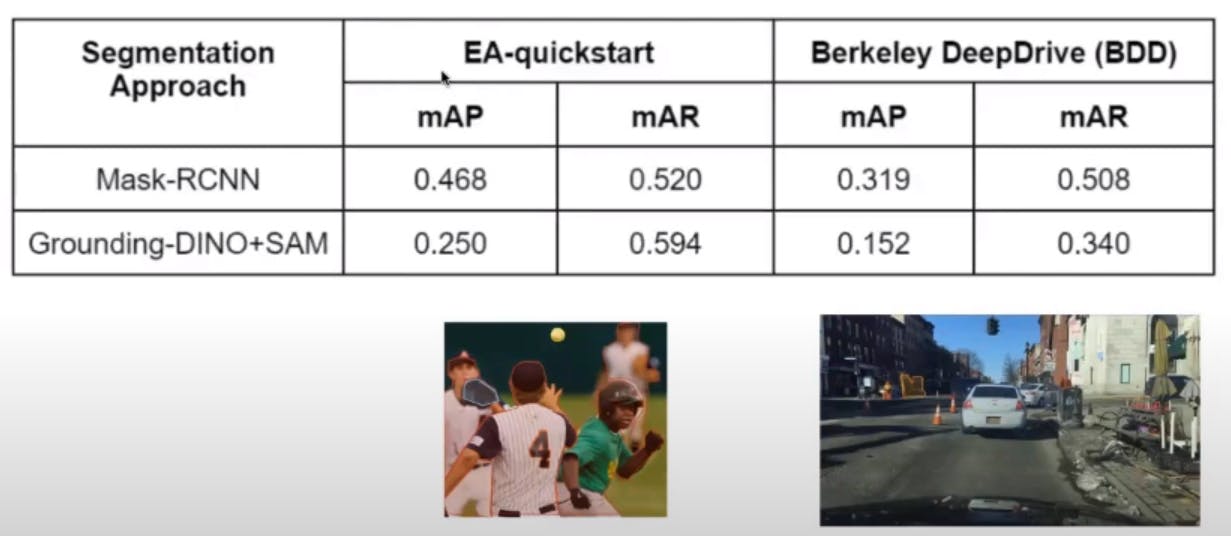
Regarding the BDD dataset, Grounding DINO performs well in identifying common objects like cars. However, it struggles with objects that are frequently encountered, resulting in suboptimal performance.
You can visualize the model’s performance on the Encord Active platform. It gives a clever picture and many analysis metrics for you to examine the model.
To gain a comprehensive understanding of the model's performance, the Encord Active platform provides valuable visualization capabilities. By utilizing this platform, you can obtain a clear picture of the model's performance and access a wide range of analytical metrics.
Encord Active allows you to visualize and analyze various aspects of the model's performance, providing insights into its strengths, weaknesses, and overall effectiveness. The platform offers an array of visualizations that aid in comprehending the model's behavior and identifying potential areas for improvement.

Additionally, the platform provides in-depth analysis metrics, enabling you to delve deeper into the model's performance across different evaluation criteria. These metrics serve as valuable indicators of the model's accuracy, precision, recall, and other relevant factors.

Sign-up for a free trial of Encord: The Data Engine for AI Model Development, used by the world’s pioneering computer vision teams.
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Frequently asked questions
Encord offers a comprehensive annotation platform that combines advanced data visualization, a user-friendly interface for annotators, and robust project management features. Unlike many open-source tools, Encord's solution is designed to handle complex annotation tasks efficiently while accommodating the specific needs of your workflow.
Encord's unique selling proposition lies in its vision-first approach, which sets it apart from other annotation tools that may simply add a GUI to existing solutions. Encord focuses on delivering advanced features tailored for effective machine learning workflows, particularly in the realm of computer vision.
Encord's annotation platform can support a wide range of projects, including those focused on feature detection in satellite data, like the Phantom project. It is also applicable to other domains that require precise labeling and training of models, making it versatile for various industries and applications.
Teams can expect to gain significant value from Encord's platform through enhanced collaboration, streamlined data annotation processes, and improved project outcomes. Our dedicated support team is committed to helping you realize these benefits as you utilize the platform.
Encord provides a range of capabilities including annotation, training modules, and workforce management reporting. These features are designed to facilitate partnerships and help organizations integrate Encord's technology in a way that enhances their service offerings.
Encord includes features designed to enhance project management and collaboration among team members. These tools allow for efficient coordination between annotators and project managers, ensuring clear workflows and timely delivery of high-quality annotations.
Encord helps standardize evaluation pipelines by providing a consistent framework for evaluating models, even when different teams work on diverse projects. This consistency reduces confusion and streamlines collaboration across various evaluation methods.
For setting up projects in Encord, it's essential to organize data into distinct projects that facilitate the annotation flow. Users can access demo projects to familiarize themselves with the platform's features and functionalities.
Absolutely, organizations can conduct a technical evaluation of Encord to assess its fit for their projects. This evaluation helps teams understand the platform's capabilities before making any financial commitments.
Encord's annotation platform is particularly beneficial for projects in robotics and industrial applications, where complex data types need to be integrated and annotated for model training and development.