What is Out-of-Distribution (OOD) Detection?

Imagine teaching a child about animals using only a book on farm animals. Now, what happens when this child encounters a picture of a lion or a penguin? Confusion, right?
In the realm of deep neural networks, there's a similar story unfolding. It's called the closed-world assumption.
Deep within the intricate layers of neural networks, there's a foundational belief we often overlook: the network will only ever meet data it's familiar with, data it was trained on.
The true challenge isn't just about recognizing cows or chickens. It's about understanding the unfamiliar, the unexpected. It's about the lion in a world of farm animals. The real essence? The test data distribution.
The test data should mirror the training data distribution for a machine learning model to perform optimally. However, in real-world scenarios, this is only sometimes the case. This divergence can lead to significant challenges, emphasizing the importance of detecting out-of-distribution (OOD) data.
As we delve deeper, we'll explore the intricacies of OOD detection and its pivotal role in ensuring the robustness and reliability of artificial intelligence systems.
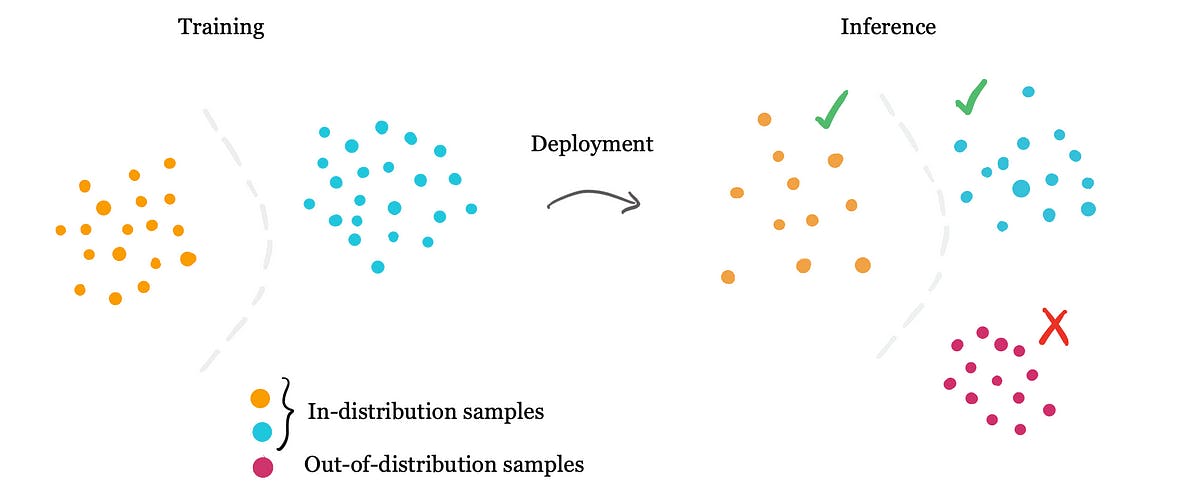
The Importance of OOD Detection
Out-of-Distribution (OOD) detection refers to a model's ability to recognize and appropriately handle data that deviates significantly from its training set.
The closed-world assumption rests on believing that a neural network will predominantly encounter data that mirrors its training set. But in the vast and unpredictable landscape of real-world data, what happens when it stumbles upon these uncharted territories? That's where the significance of OOD detection comes into play.
Real-world Implications of Ignoring OOD
When neural networks confront out-of-distribution (OOD) data, the results can be less than ideal. A significant performance drop in real-world tasks is one of the immediate consequences. Think of it as a seasoned sailor suddenly finding themselves in uncharted waters, unsure how to navigate.
Moreover, the repercussions can be severe in critical domains. For instance, an AI system with OOD brittleness in medicine might misdiagnose a patient, leading to incorrect treatments. Similarly, in home robotics, a robot might misinterpret an object or a command, resulting in unintended actions. The dangers are real, highlighting the importance of detecting and handling OOD data effectively.
The Ideal AI System
Deep neural networks, the backbone of many modern AI systems, are typically trained under the closed-world assumption. This assumption presumes that the test data distribution closely mirrors the training data distribution. However, the real world seldom adheres to such neat confines.
When these networks face unfamiliar, out-of-distribution (OOD) data, their performance can wane dramatically. While such a dip might be tolerable in applications like product recommendations, it becomes a grave concern in critical sectors like medicine and home robotics. Even a minor misstep due to OOD brittleness can lead to catastrophic outcomes.
An ideal AI system should be more adaptable. It should generalize to OOD examples and possess the acumen to flag instances that stretch beyond its understanding. This proactive approach ensures that when the system encounters data, it can't confidently process, it seeks human intervention rather than making a potentially erroneous decision.
Understanding OOD Brittleness
Deep neural networks, the linchpin of many AI systems, are trained with the closed-world assumption. This assumption presumes that the test data distribution closely resembles the training data distribution. However, the real world often defies such neat confines.
When these networks encounter unfamiliar, out-of-distribution (OOD) data, their performance can deteriorate significantly. While such a decline might be tolerable in applications like product recommendations, it becomes a grave concern in critical sectors like medicine and home robotics. Even a minor misstep due to OOD brittleness can lead to catastrophic outcomes.
Why Models Exhibit OOD Brittleness
The brittleness of models, especially deep neural networks, to OOD data is multifaceted. Let's delve deeper into the reasons:
- Model Complexity: Deep neural networks are highly parameterized, allowing them to fit complex patterns in the training data. While this complexity enables them to achieve high accuracy on in-distribution data, it can also make them susceptible to OOD data. The model might respond confidently to OOD inputs, even if they are nonsensical or far from the training distribution.
- Lack of Regularization: Regularization techniques, like dropout or weight decay, can improve a model's generalization. However, models can still overfit the training data if not applied or tuned correctly, making them brittle to OOD inputs.
- Dataset Shift: The data distribution can change over time in real-world applications. This phenomenon, known as dataset shift, can lead to situations where the model encounters OOD data even if it was not present during training.
- Model Assumptions: Many models, especially traditional statistical models, make certain assumptions about the data. If OOD data violate these assumptions, the model's performance can degrade.
- High Dimensionality: The curse of dimensionality can also play a role. Most of the volume in high-dimensional spaces is near the surface, making it easy for OOD data to lie far from the training data, causing models to extrapolate unpredictably.
- Adversarial Inputs: OOD data can sometimes be adversarial, crafted explicitly to deceive the model. Such inputs can exploit the model's vulnerabilities, causing it to make incorrect predictions with high confidence.
- Absence of OOD Training Samples: If a model has never seen examples of OOD data during training, it won't have learned to handle them. This is especially true for supervised learning models, which rely on labeled examples.
- Model's Objective Function: The objective function optimized during training (e.g., cross-entropy loss for classification tasks) might not penalize confident predictions on OOD data. This can lead to overly confident models even when they shouldn't be.
Incorporating techniques to detect and handle OOD data is crucial, especially as AI systems are increasingly deployed in real-world, safety-critical applications.
Types of Generalizations
Models generalize in various ways, each with its implications for OOD detection. Some models might have a broad generalization, making them more adaptable to diverse data but potentially less accurate.
Others might have a narrow focus, excelling in specific tasks, but could be more comfortable when faced with unfamiliar data. Understanding the type of generalization a model employs is crucial for anticipating its behavior with OOD data and implementing appropriate detection mechanisms.
Pre-trained Models vs. Traditional Models
Pre-trained models, like BERT, have gained traction in recent years for their impressive performance across a range of tasks. One reason for their robustness against OOD data is their extensive training on diverse datasets. This broad exposure allows them to recognize and handle a wider range of inputs than traditional models that might be trained on more limited datasets.
For instance, a research paper titled "Using Pre-Training Can Improve Model Robustness and Uncertainty" highlighted that while pre-training might not always enhance performance on traditional classification metrics, it significantly bolsters model robustness and uncertainty estimates. This suggests that the extensive and diverse training data used in pre-training these models equips them with a broader understanding, making them more resilient to OOD data. However, even pre-trained models are not immune to OOD brittleness, emphasizing the need for continuous research and refinement in this domain.

Approaches to Detect OOD Instances
Detecting out-of-distribution (OOD) instances is crucial for ensuring the robustness and reliability of machine learning models, especially deep neural networks. Several approaches have been proposed to address this challenge, each with advantages and nuances. Here, we delve into some of the prominent techniques.
Maximum Softmax Probability
Softmax probabilities can serve as a straightforward metric for OOD detection. Typically, a neural network model would output higher softmax probabilities for in-distribution data and lower probabilities for OOD data. By setting a threshold on these probabilities, one can flag instances below the threshold as potential OOD instances.
Ensembling of Multiple Models
Ensembling involves leveraging multiple models to make predictions. For OOD detection, the idea is that while individual models might be uncertain about an OOD instance, their collective decision can be more reliable. By comparing the outputs of different models, one can identify prediction discrepancies, which can indicate OOD data.
Temperature Scaling
Temperature scaling is a post-processing technique that calibrates the softmax outputs of a model. By adjusting the "temperature" parameter, one can modify the confidence of the model's predictions. Properly calibrated models can provide more accurate uncertainty estimates, aiding OOD detection.
Training a Binary Classification Model as a Calibrator
Another approach is to train a separate binary classification model that acts as a calibrator. This model is trained to distinguish between the in-distribution and OOD data. By feeding the outputs of the primary model into this calibrator, one can obtain a binary decision on whether the instance is in distribution or OOD.
Monte-Carlo Dropout
Dropout is a regularization technique commonly used in neural networks. Monte-Carlo Dropout involves performing dropout at inference time and running the model multiple times. The variance in the model's outputs across these runs can provide an estimate of the model's uncertainty, which can be used to detect OOD instances.
Research in OOD Detection
Deep learning models, particularly neural networks, have performed remarkably in various tasks. However, their vulnerability to out-of-distribution (OOD) data remains a significant concern. Recent research in 2023 has delved deeper into understanding this vulnerability and devising methods to detect OOD instances effectively.
- Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness (Liu et al., 2020): This paper emphasizes the need for AI systems to detect OOD instances beyond their capability and proposes a method for uncertainty estimation.
- Detecting Out-of-Distribution Examples with In-distribution Examples and Gram Matrices (Sastry & Oore, 2019): The study presents a method for detecting OOD examples using in-distribution examples and gram matrices, demonstrating its effectiveness in detecting far-from-distribution OOD examples.
- Energy-based Out-of-distribution Detection (NeurIPS 2020): Proposing a unified framework for OOD detection, this research uses an energy score to detect anomalies.
- Learning Confidence for Out-of-Distribution Detection in Neural Networks (13 Feb 2018): The paper highlights that modern neural networks, despite their power, often fail to recognize when their predictions might be incorrect. The research delves into this aspect, aiming to improve confidence in OOD detection.
Datasets and Benchmark Numbers
In the realm of Out-of-Distribution (OOD) detection, several datasets have emerged as the gold standard for evaluating the performance of various detection methods. Here are some of the most popular datasets and their respective benchmark scores:
- CIFAR-10 and CIFAR-100 are staple datasets in the computer vision community, often used to benchmark OOD detection methods. For instance, the DHM method has been tested on CIFAR-10 and CIFAR-100 and vice versa, showcasing its robustness.
- STL-10: Another dataset in the computer vision domain, the Mixup (Gaussian) method, has been applied here, demonstrating its effectiveness in OOD detection.
- MS-1M vs. IJB-C: This dataset comparison has seen the application of the ResNeXt50 + FSSD method, further emphasizing the importance of robust OOD detection techniques in diverse datasets.
- Fashion-MNIST: A dataset that's become increasingly popular for OOD detection, with methods like PAE showcasing their prowess.
- 20 Newsgroups: This dataset, more textual, has seen the application of the 2-Layered GRU method, highlighting the versatility of OOD detection across different data types.
It's crucial to note that the benchmark scores of methods can vary based on the dataset, emphasizing the need for comprehensive testing across multiple datasets to ensure the robustness of OOD detection methods.

Future Direction
The field of OOD detection is rapidly evolving, with new methodologies and techniques emerging regularly. As AI systems become more integrated into real-world applications, the importance of robust OOD detection will only grow. Future research is likely to focus on:
- Enhanced Generalization: As models become more complex, it will be paramount to ensure they can generalize well to unseen data. This will involve developing techniques that can handle the vast diversity of real-world data.
- Integration with Other AI Domains: OOD detection will likely see integration with other AI domains, like transfer learning, few-shot learning, and more, to create holistic systems that are both robust and adaptable.
- Real-time OOD Detection: Real-time OOD detection will be crucial for applications like autonomous driving or medical diagnostics. Research will focus on making OOD detection methods faster without compromising on accuracy.
- Ethical Considerations: As with all AI advancements, the ethical implications of OOD detection will come to the fore. Ensuring that these systems are fair, transparent, and don't perpetuate biases will be a significant area of focus.
With the pace of advancements in the field, the next few years promise to be exciting for OOD detection, with groundbreaking research and applications on the horizon.
Out-of-Distribution Detection: Key Takeaways
Out-of-distribution (OOD) detection, a pivotal algorithm in the AI landscape, is a cornerstone in modern AI systems.
As AI continues to permeate diverse sectors, from image classification in healthcare to pattern recognition in finance, identifying and handling out-of-distribution samples deviating from the input data the model was trained on becomes paramount.
Here are the pivotal takeaways from our exploration:
- Significance of OOD Detection: AI models, especially convolutional neural networks, are optimized for their training data. When faced with out-of-distribution data, their activations can misfire, and their performance can drastically plummet, leading to unreliable or even hazardous outcomes in real-world applications.
- Model Vulnerability: Despite their prowess and intricate loss function designs, models exhibit OOD brittleness primarily due to their training regimen. Their hyper-fine-tuning can make them less adaptable to unfamiliar inputs, emphasizing the need for novelty detection.
- Diverse Approaches: Researchers are exploring many techniques to enhance OOD detection, from leveraging generative models like variational autoencoders (VAE) to the ensembling of multiple models and from segmentation techniques to validation using Monte-Carlo dropout.
- Research Landscape: 2023 has seen groundbreaking research in OOD detection, with methods like DHM and PAE leading the charge. Platforms like Arxiv and GitHub have been instrumental in disseminating this knowledge. Datasets like CIFAR-10 serve as baselines for evaluating these novel techniques, and international conferences like ICML have been platforms for such discussions.
- Future Trajectory: The AI community, with contributions from researchers like Hendricks, Ren, and Chen, is gearing towards enhanced model generalization, real-time OOD detection using self-supervised and unsupervised techniques, and integrating ethical considerations into OOD methodologies.
In essence, while being a technical challenge, OOD detection is a necessity in ensuring that AI systems, whether they employ classifier systems or delve into outlier detection, remain reliable, safe, and effective in diverse real-world scenarios.
Frequently asked questions
Out-of-distribution (OOD) detection is a crucial algorithm in AI that enables a classifier to discern and manage data markedly deviating from its training set. Rooted in the semantic understanding of data, it ensures that the model can identify when it's presented with out-of-distribution data and take suitable actions. Many researchers have discussed this topic on platforms like Arxiv and GitHub, emphasizing its growing importance in convolutional neural networks and other AI architectures.
While all three mechanisms deal with unexpected data, OOD detection specifically zeroes in on data outside the model's training distribution. Anomaly detection, on the other hand, identifies rare or unusual patterns within the data, often using generative models or likelihood ratios for detection. Outlier detection is another related concept, focusing on distant data points from other observations. The baseline understanding is that while anomalies and outliers are unexpected data points within the in-distribution data, OOD data is entirely outside the known distribution.
An out-of-distribution problem emerges when an AI model encounters data that doesn't resonate with its training set, whether self-supervised, unsupervised, or even fine-tuned. This misalignment can lead to unreliable predictions or outputs. For instance, in a convolutional neural network, the activations might not respond appropriately to OOD data. Researchers like Hendrycks, Ren, and Chen have emphasized the need for robust OOD detection mechanisms, especially when dealing with auroc metrics and normalization techniques in AI systems, as discussed in conferences like ICML.
Encord specializes in damage detection across multiple sectors, including vehicle inspection and manufacturing. Our platform enables clients to identify small, hard-to-detect damages at scale, helping improve the accuracy of their damage detection models.