Alternatives
Encord vs. Dataloop
Encord is the reliable Dataloop alternative for teams building production-grade AI systems. Encord is the end-to-end data development platform for multimodal teams.
Announcing our Series C with $110M in total funding. Read more →.
Alternatives
Encord is the reliable Dataloop alternative for teams building production-grade AI systems. Encord is the end-to-end data development platform for multimodal teams.
Trusted by leading AI teams










Evaluating Dataloop alternatives? Leading AI teams focus on: platform stability that scales with data volume growth, intuitive and user-friendly annotation interface that supports multimodalities in seamless workflows, and consolidated data infrastructure unifying data curation, annotation, and model evaluation without the complexity overhead.
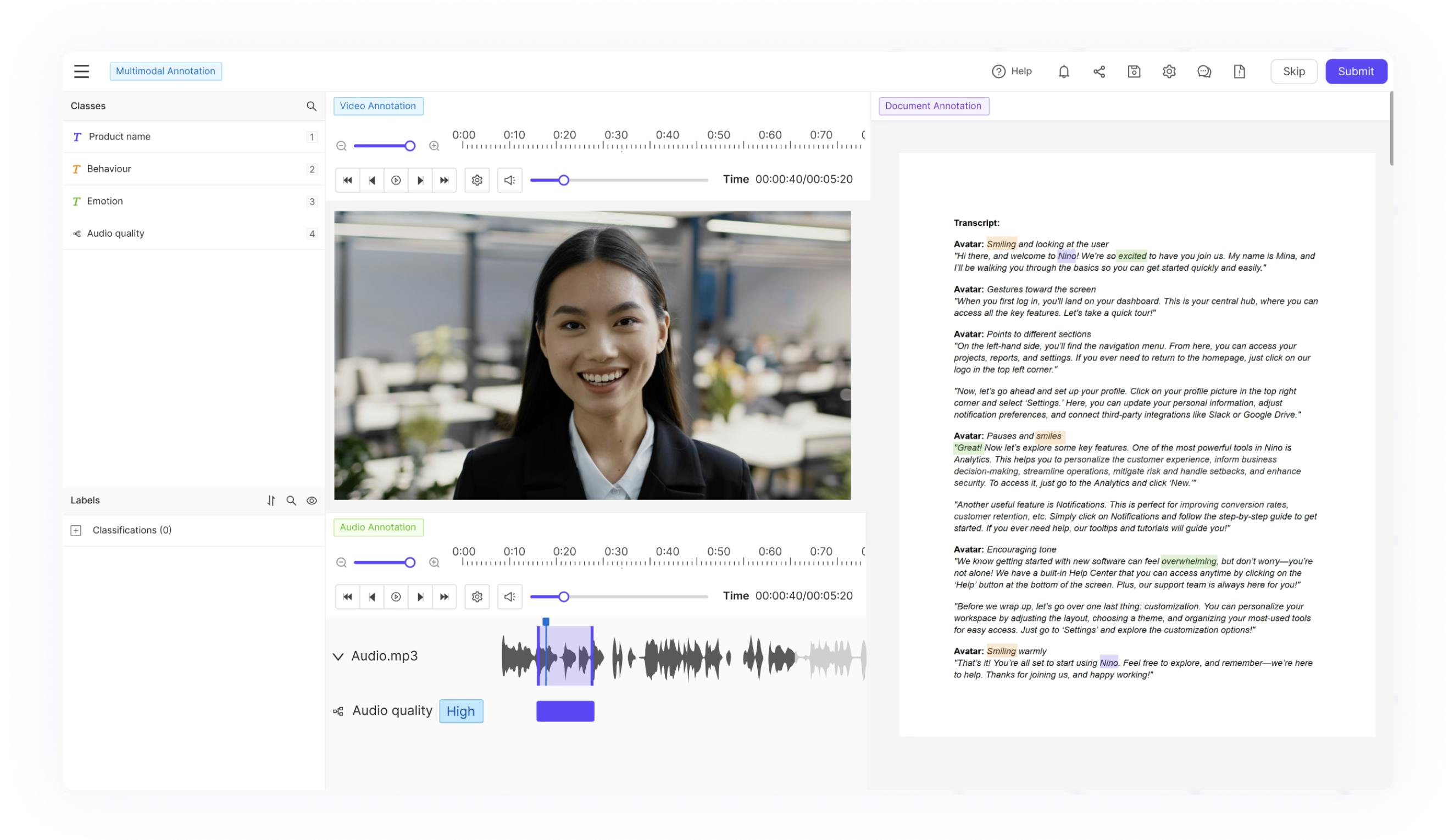
Advanced multimodal annotation features for the most complex AI projects
Encord’s multimodal labeling editor supports various modalities—images, video, LiDAR, 3D point clouds, DICOM, audio, and text—with intuitive interface, advanced nested ontologies. Handle complex computer vision projects with our advanced video annotation tools, including native video rendering, precise frame-by-frame analysis, and seamless object tracking. Unlike platforms that struggle with stability at scale, Encord maintains consistent performance even as your data volumes scale to millions of data points.
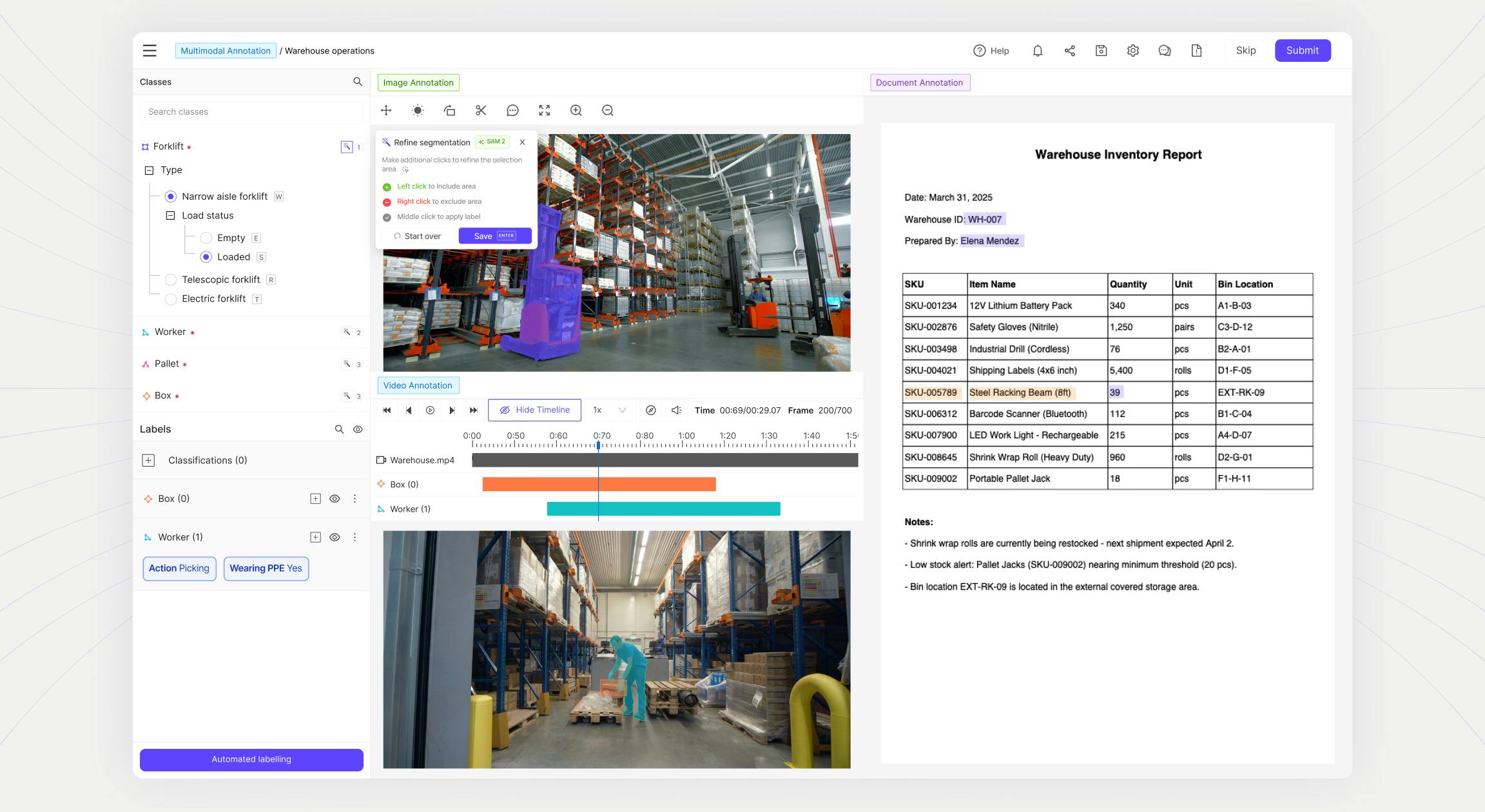
Consolidated data platform built for reliability
Encord focuses on helping leading AI teams address challenges at the data layer. Eliminate the need to build fragmented data management infrastructure. Our platform unifies data curation, annotation, and model evaluation capabilities in a single, stable platform that integrates seamlessly with your existing MLOps stack.
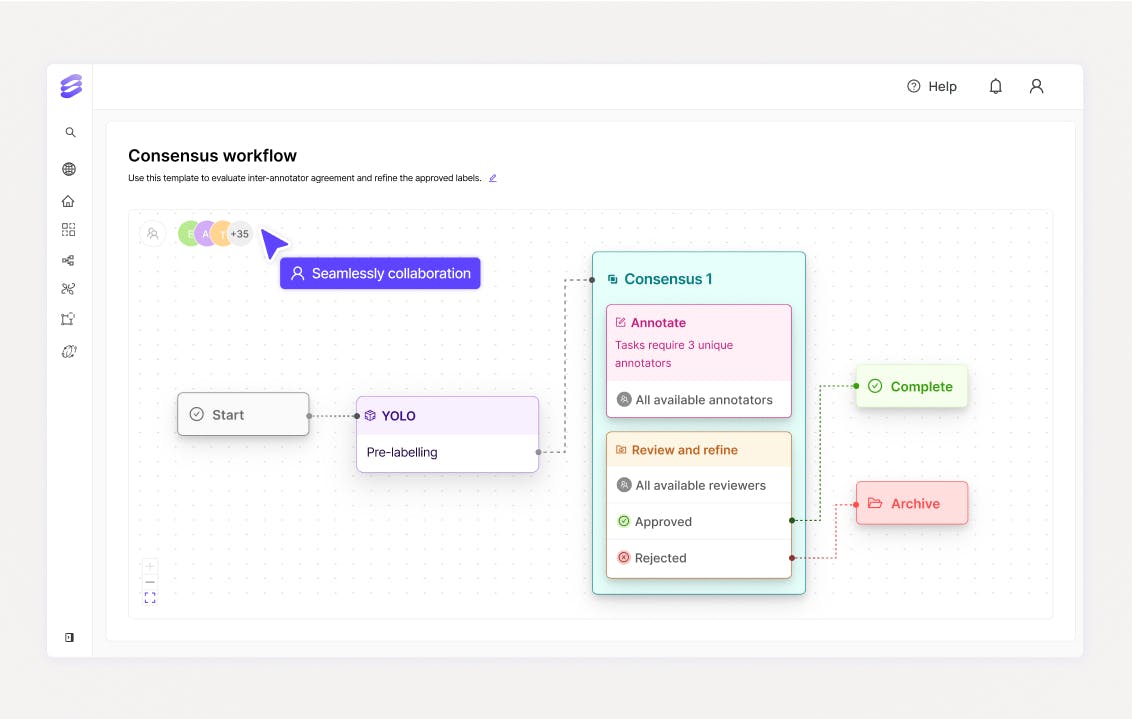
Customizable workflows with QA/QC and Data Agents
Accelerate your data pipelines with Encord's advanced workflow orchestration and Data Agents. Orchestrate bulk data labeling and integrate SOTA or custom AI models with Data Agents for automated pre-labeling, quality control, and data classification and more. Configure HITL and QA/QC processes such as consensus to ensure data quality and label accuracy.
KEY FEATURES


Annotation and RLHF
Native multimodal support (image, video, audio, LiDAR, DICOM, documents, text)
Limited
Advanced video annotation with native rendering and object tracking
Limited
Intuitive annotation interface
Complex ontology and classification structures
AI-assisted labeling with SOTA models (SAM2, YOLO, GPT-4)
Platform stability with large data volumes (1M+ data points)
Limited
Data management and curation
Complete platform for data curation, management, and annotation
Model testing and evaluation
Data Agents for AI model integration into workflows
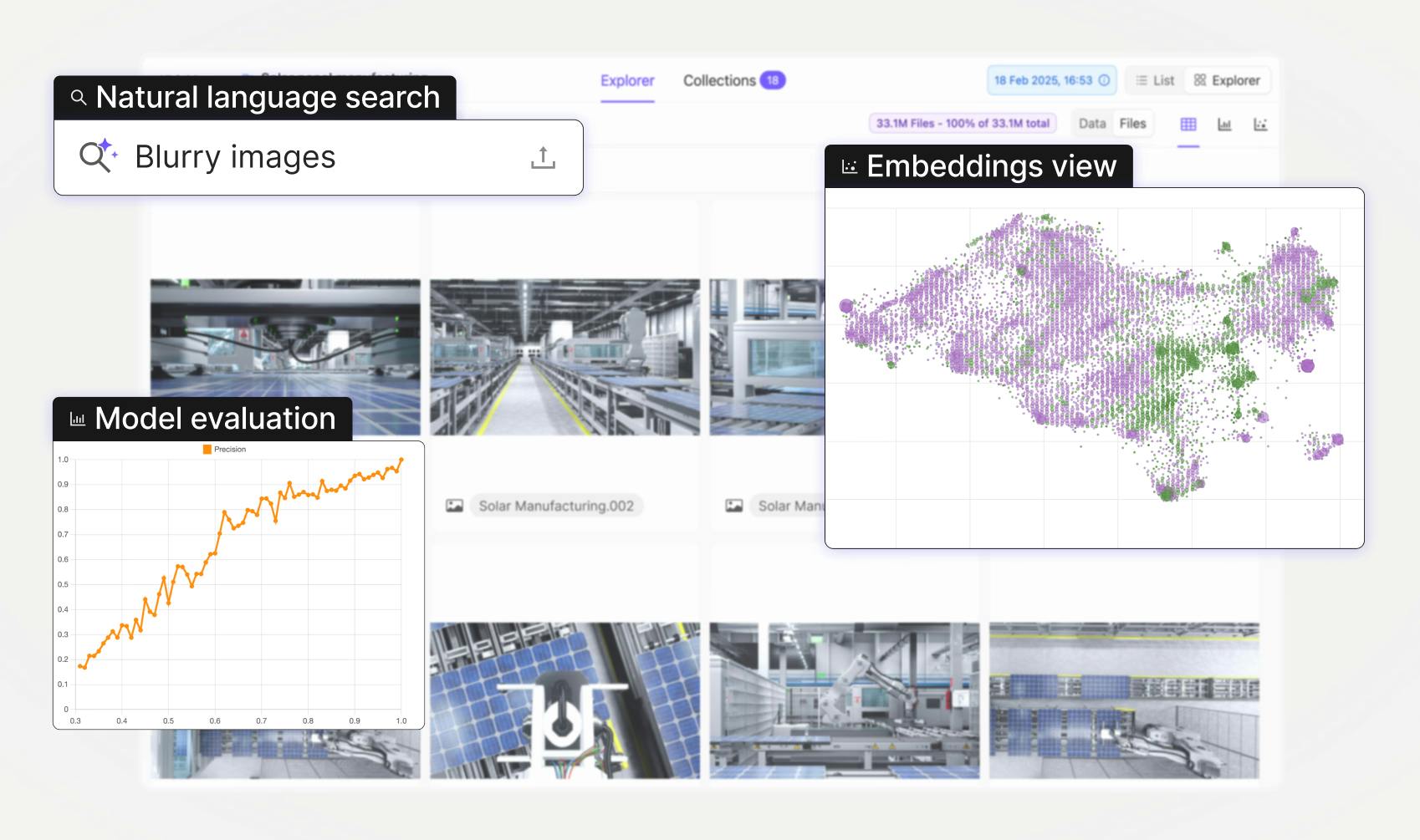
Data curation with classification, advanced filtering, natural language search across petabytes of datasets
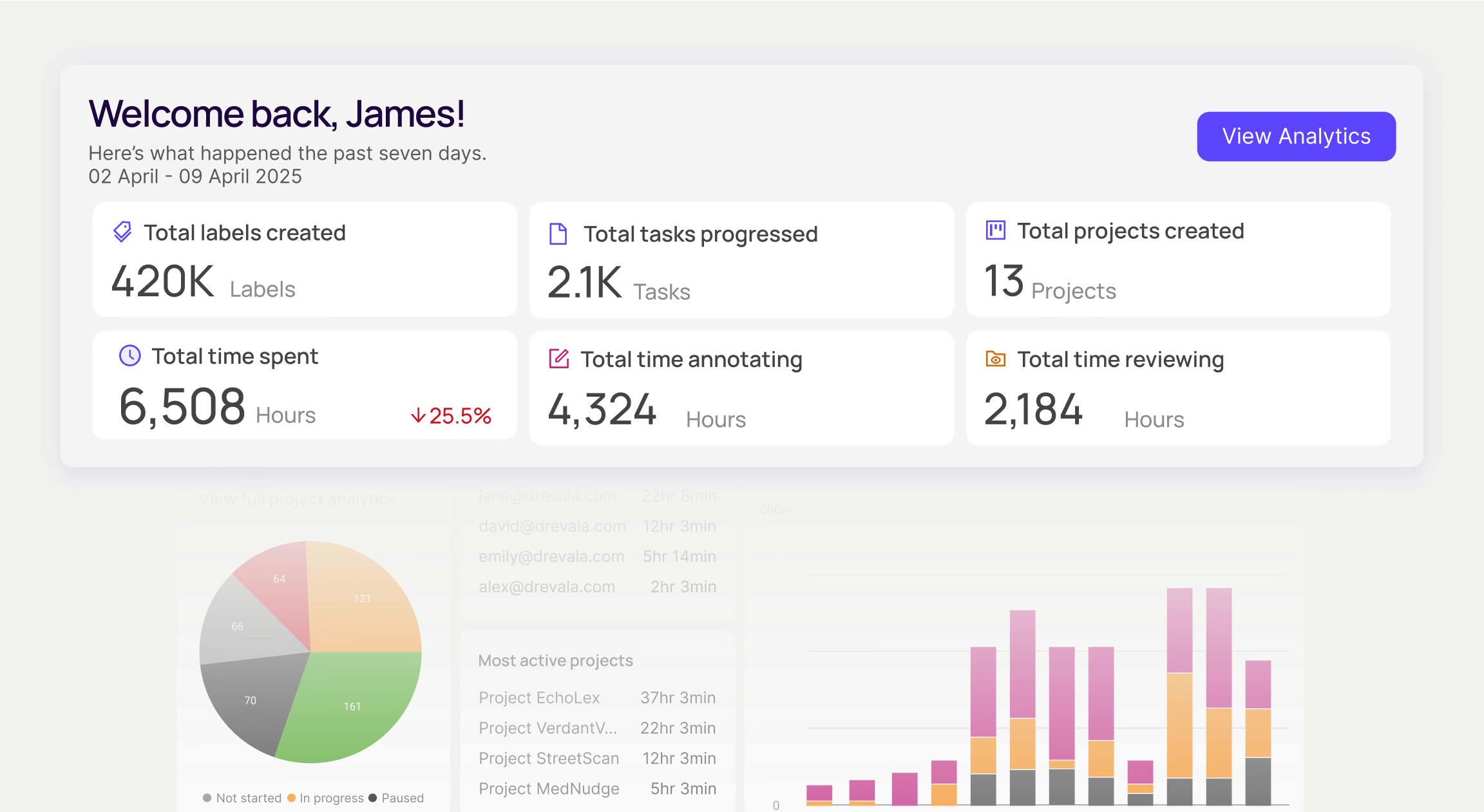
Enhanced team productivity and annotation quality with robust analytics
Supercharge team productivity with organization and individual level performance analytics to understand throughput, identify bottlenecks, and optimize annotation processes. Implement advanced quality control workflows with consensus-based review processes. Track metrics to ensure consistent labeling standards, improving efficiency and data quality.

API/SDK for programmatic access to Encord
Leverage our comprehensive Python SDK and REST API to access Encord platform capabilities programmatically. Automate data ingestion, manage annotation workflows, datasets, and projects, as well as integrating quality control processes directly into your existing MLOps pipelines.

Enterprise-grade security and compliance
Protect sensitive data with Encord's comprehensive security framework, including SOC2 Type II certification, HIPAA compliance, and GDPR adherence. Our platform provides detailed audit trails, role-based access controls, and encryption protocols. Deploy in your preferred environment—cloud, VPC, or on-premises—while maintaining full security compliance.
Case studies

We now have an integrated, one-stop solution where we can manage our data and also understand our model performance to create feedback mechanisms to improve data and models.

Encord made it very easy to centrally keep track of annotations, including who had made them and who had reviewed them. It also has this great interpolation tool which was especially useful.

It’s always about balancing speed and quality. A lot of platforms prioritize speed over quality or quality over speed. Encord speeds up annotation while still allowing for strong quality control.

Encord’s robust support system has been remarkable. Whenever questions or issues come up, they are always supportive and helpful. This ensures that our workflows remain uninterrupted.

We went through a bunch of vendors and one of the things that stood out about Encord was the video first support, which other vendors do not have.

Getting started with Encord and integrating it into our workflow was really fast. The thing that I find the most valuable is the flexibility of how we can integrate the Encord pipeline into our own pipeline.

Encord Index is a high-performance system for our AI data, enabling us to sort and search at any level of complexity.

Before using Encord, it was challenging to see all the data, projects, and annotations in one place. Now, with Encord I feel like we have a much clearer understanding of everything that's happening.
We now have an integrated, one-stop solution where we can manage our data and also understand our model performance to create feedback mechanisms to improve data and models.
Encord made it very easy to centrally keep track of annotations, including who had made them and who had reviewed them. It also has this great interpolation tool which was especially useful.
It’s always about balancing speed and quality. A lot of platforms prioritize speed over quality or quality over speed. Encord speeds up annotation while still allowing for strong quality control.
Encord’s robust support system has been remarkable. Whenever questions or issues come up, they are always supportive and helpful. This ensures that our workflows remain uninterrupted.
We went through a bunch of vendors and one of the things that stood out about Encord was the video first support, which other vendors do not have.
Getting started with Encord and integrating it into our workflow was really fast. The thing that I find the most valuable is the flexibility of how we can integrate the Encord pipeline into our own pipeline.
Encord Index is a high-performance system for our AI data, enabling us to sort and search at any level of complexity.
Before using Encord, it was challenging to see all the data, projects, and annotations in one place. Now, with Encord I feel like we have a much clearer understanding of everything that's happening.
Encord provides native video rendering with advanced object tracking, no downsampling, and precise frame-by-frame analysis. This enables significantly faster and more accurate video annotation while maintaining the highest quality for your computer vision projects. Roboflow primarily works by extracting frames from videos, which lacks the temporal understanding and efficiency of Encord's approach.
Yes. Encord offers support for LiDAR point clouds with native 3D visualization, annotation tools, and sensor fusion capabilities. This makes Encord essential for teams developing autonomous vehicle AI, robotics, and other Physical AI applications.
Encord is built for consistent performance at scale. Unlike platforms that experience stability issues with large datasets, our infrastructure maintains reliable performance even with millions of data points. Teams report seamless experiences scaling from pilot projects to production volumes without the platform reliability concerns that can derail development timelines.
Encord provides more flexible data structuring capabilities. With Encord, you can create complex hierarchical classification structures with unlimited depth and implement dynamic attributes that evolve throughout videos. This powerful capability enables sophisticated annotation schemas that match the complexity of real-world computer vision applications.
Encord provides robust API/SDK options, featuring a comprehensive Python API and SDK that allows developers to programmatically access all platform functionalities. This enables seamless integration with existing MLOps toolstacks and custom workflows.
Encord provides true data curation capabilities rather than basic data management. Our platform includes advanced filtering, embedding-based similarity search, automated quality metrics, and visual data exploration tools that help you identify the most valuable data for model training. Unlike platforms that present data management complexity as a feature, we focus on making data operations straightforward and reliable.
No. Encord makes migration straightforward with dedicated tools and support from our expert team, allowing you to quickly benefit from our more advanced and comprehensive platform capabilities.
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord's Data Development platform accelerates every step of taking your model into production.