Barlow Twins: Self-Supervised Learning

Self-supervised learning (SSL) has emerged as a transformative paradigm in machine learning, particularly in computer vision applications. Unlike traditional supervised learning, where labeled data is a prerequisite, SSL leverages unlabeled data, making it a valuable approach when labeled datasets are scarce. The essence of SSL lies in its ability to process data of lower quality without compromising the ultimate outcomes. This approach mirrors how humans learn to classify objects more closely, extracting patterns and correlations from the data autonomously.
However, a significant challenge in SSL is the potential for trivial, constant solutions. A naive SSL method trivially classifies every example as positive in binary classification, leading to a constant and uninformative solution. This challenge underscores the importance of designing robust algorithms, such as the Barlow Twins, that can effectively leverage the power of SSL while avoiding pitfalls like trivial solutions.
In the subsequent sections, we will delve deeper into the Barlow Twins approach to SSL, a new approach developed by Yann LeCun and the team at Facebook. We will also explore its unique features, benefits, and contribution to the ever-evolving landscape of self-supervised learning in machine learning.
The Barlow Twins Approach
The Barlow Twins method, named in homage to neuroscientist H. Barlow's redundancy-reduction principle, presents a novel approach to self-supervised learning (SSL). This method is particularly significant in computer vision, where SSL has rapidly bridged the performance gap with supervised methods.
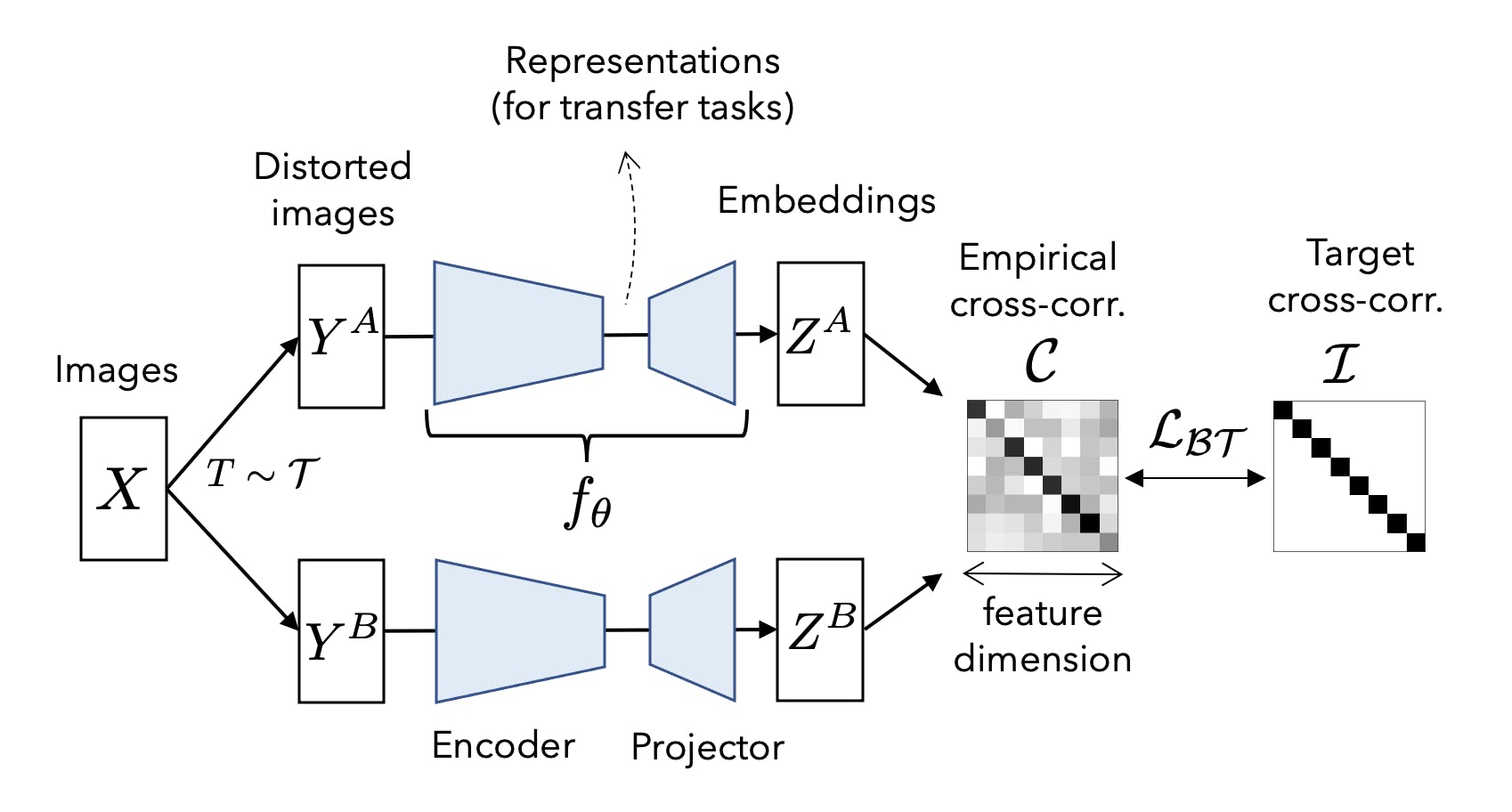
Central to the Barlow Twins approach is its unique objective function, designed to naturally prevent the collapse often observed in other SSL methods. This collapse typically results in trivial, constant solutions, a challenge many SSL algorithms grapple with. The Barlow Twins method addresses this by measuring the cross-correlation matrix between the outputs of two identical neural networks. These networks are fed with distorted versions of a sample, and the objective is to make this matrix as close to the identity matrix as possible.
The role of the cross-correlation matrix is pivotal. By ensuring that the embedding vectors of distorted versions of a sample are similar, the method minimizes redundancy between the components of these vectors. This enhances the quality of the embeddings and ensures that the learned representations are robust and invariant to the applied distortions.
Image Classification with Barlow Twins
Imagine you have many images of cats and dogs, but they must be labeled. You want to train a machine-learning model to distinguish between cats and dogs using this unlabeled dataset.
Here is the Barlow Twins approach:
- Data Augmentation: Create two distorted versions for each image in the dataset. For instance, one version might be a cropped section of the original image, and the other might be the same cropped section but with altered brightness or color.
- Twin Neural Networks: Use two identical neural networks (the "twins"). Feed one distorted version of the image into the first network and the other distorted version into the second network.
- Objective Function: The goal is to make the outputs (embeddings) of the two networks as similar as possible for the same input image, ensuring that the networks recognize the two distorted versions as being of the same class (either cat or dog). At the same time, the Barlow Twins method aims to reduce redundancy in the embeddings. This is achieved by ensuring that the cross-correlation matrix of the embeddings from the two networks is close to an identity matrix. In simpler terms, the method ensures that each embedding component is as independent as possible from the other components.
- Training: The twin networks are trained using the above objective. Over time, the networks learn to produce similar embeddings for distorted versions of the same image and different embeddings for images of different classes (cats vs. dogs).
- Representation Learning: Once trained, you can use one of the twin networks (or both) to extract meaningful representations (embeddings) from new images. These representations can then be used with a simple linear classifier for various tasks, such as classification.
Barlow Twins Loss Function
The primary objective of the Barlow Twins method is to reduce redundancy in the representations learned by neural networks. To achieve this, the method uses two identical neural networks (often called "twins") that process two distorted versions of the same input sample. The goal is to make the outputs (or embeddings) of these networks as similar as possible for the same input while ensuring that the individual components of these embeddings are not redundant.
The Barlow Twins loss function is designed to achieve this objective. It is formulated based on the cross-correlation matrix of the outputs from the two networks.
Cross-Correlation Matrix Calculation:
- Let's say the outputs (embeddings) from the two networks for a batch of samples are Y1 and Y2.
- The cross-correlation matrix C is computed as the matrix product of the centered outputs of the two networks, normalized by the batch size.
Loss Function:
- The diagonal elements of the matrix C represent the correlation of each component with itself. The method aims to make these diagonal elements equal to 1, ensuring that the embeddings from the two networks are similar.
- The off-diagonal elements represent the correlation between different components. The method aims to make these off-diagonal elements equal to 0, ensuring that the components of the embeddings are not redundant.
- The loss is then computed as the sum of the squared differences between the diagonal elements and the squared values of the off-diagonal elements.
The Barlow Twins approach can be applied to more complex datasets and tasks beyond simple image classification. The key idea is to leverage the structure in unlabeled data by ensuring that the learned representations are consistent across distortions and non-redundant.
Redundancy Reduction Principle
Horace Basil Barlow, a renowned British vision scientist, significantly contributed to our understanding of the visual system. One of his most influential concepts was the redundancy reduction principle. Barlow posited that one of the primary computational aims of the visual system is to reduce redundancy, leading to the efficient coding hypothesis4. In simpler terms, while adjacent points in images often have similar brightness levels, the retina minimizes this redundancy, ensuring that the information processed is as concise and non-redundant as possible.
The Barlow Twins method in self-supervised learning draws inspiration from this principle. By reducing redundancy, the Barlow Twins approach aims to create embeddings invariant to distortions and statistically independent across different parts of an image. This ensures that the neural networks, when trained with this method, produce representations that capture the essential features of the data while discarding superfluous information.
In machine learning and computer vision, applying Barlow's redundancy reduction principle through the Barlow Twins method offers a promising avenue for achieving state-of-the-art results in various tasks, from image classification to segmentation.
Key Features of Barlow Twins
Independence from Large Batches
One of the standout features of the Barlow Twins method is its independence from large batches. In deep learning, especially with extensive datasets, large batch sizes are often employed to expedite training. However, this can lead to challenges, including the need for significant GPU memory and potential generalization issues.
The Barlow Twins approach, in contrast, does not necessitate large batches. This independence is particularly advantageous for those without access to extensive computational resources. The method's design, which emphasizes measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, ensures that the embeddings produced are invariant to these distortions. By aiming to make this matrix as close to the identity matrix as possible, the Barlow Twins method effectively minimizes redundancy between the components of the embedding vectors, irrespective of the batch size.
Another noteworthy aspect is the method's resilience to overfitting. Since it doesn't rely on large batches, the risk of the model memorizing the training data, a common pitfall in machine learning, is substantially reduced. This ensures the trained models are more robust and can generalize to unseen data.
The Barlow Twins approach's design, emphasizing redundancy reduction and independence from large batches, sets it apart in self-supervised learning methods. Its unique features make it resource-efficient and ensure its applicability and effectiveness across various tasks and computational settings.
Symmetry in Network Twins
The Barlow Twins approach is distinctive in its utilization of two identical neural networks, often called "twins". This symmetry departs from many other self-supervised learning methods that rely on predictor networks, gradient stopping, or moving averages to achieve their objectives.
The beauty of this symmetric design lies in its simplicity and efficiency. By feeding distorted versions of a sample into these twin networks and then comparing their outputs, the Barlow Twins method ensures that the produced embeddings are invariant to the distortions. This symmetry eliminates the need for additional complexities like predictor networks, often used to map representations from one network to another.
The absence of gradient stopping and moving averages in the Barlow Twins approach means that the training process is more straightforward and less prone to potential pitfalls associated with these techniques. Gradient stopping, for instance, can sometimes hinder the optimization process, leading to suboptimal results.
In essence, the symmetric design of the Barlow Twins method not only simplifies the training process but also enhances the robustness and effectiveness of the learned representations. By focusing on redundancy reduction and leveraging the power of symmetric network twins, the Barlow Twins approach offers a fresh perspective in the ever-evolving landscape of self-supervised learning.
Benefits of High-Dimensional Output Vectors
The Barlow Twins approach has garnered attention for its unique take on self-supervised learning, particularly in its use of high-dimensional output vectors. But why does this matter?
High-dimensional vectors allow for a richer data representation in neural networks. The Barlow Twins method can capture intricate patterns and nuances in the data that might be missed with lower-dimensional representations when using very high-dimensional vectors. This depth of representation is crucial for tasks like image recognition in computer vision, where subtle differences can be the key to accurate classification.
Moreover, the Barlow Twins method leverages these high-dimensional vectors to ensure that the embeddings produced by the twin networks are both similar (due to the distorted versions of a sample) and minimally redundant. This balance between similarity and non-redundancy is achieved through the redundancy reduction principle, inspired by neuroscientist H. Barlow.
To illustrate, imagine describing a complex painting using only a few colors. While you might capture the general theme, many details must be recovered. Now, imagine having a vast palette of colors at your disposal. The richness and depth of your description would be incomparably better. Similarly, high-dimensional vectors offer a richer "palette" for neural networks to represent data.
Using very high-dimensional vectors in the Barlow Twins method allows for a more detailed and nuanced understanding of data, paving the way for more accurate and robust machine learning models.
Performance and Comparisons
The Barlow Twins approach has been a significant leap forward in self-supervised learning, particularly when benchmarked against the ImageNet dataset.13 ImageNet is a large-scale dataset pivotal for computer vision tasks and is a rigorous testing ground for novel algorithms and methodologies.
In semi-supervised classification, especially in scenarios where data is limited, the Barlow Twins method has showcased commendable performance. The method outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime. This is particularly noteworthy as working with limited data often challenges training robust models. With its unique approach to redundancy reduction and high-dimensional output vectors, the Barlow Twins method captures intricate patterns in the data, leading to improved classification results.
Moreover, using a linear classifier head, the Barlow Twins approach aligns with the current state-of-the-art ImageNet classification. It also holds its ground in transfer tasks of classification and object detection.13 These results underscore the potential of the Barlow Twins method in pushing the boundaries of self-supervised learning, especially in computer vision tasks.
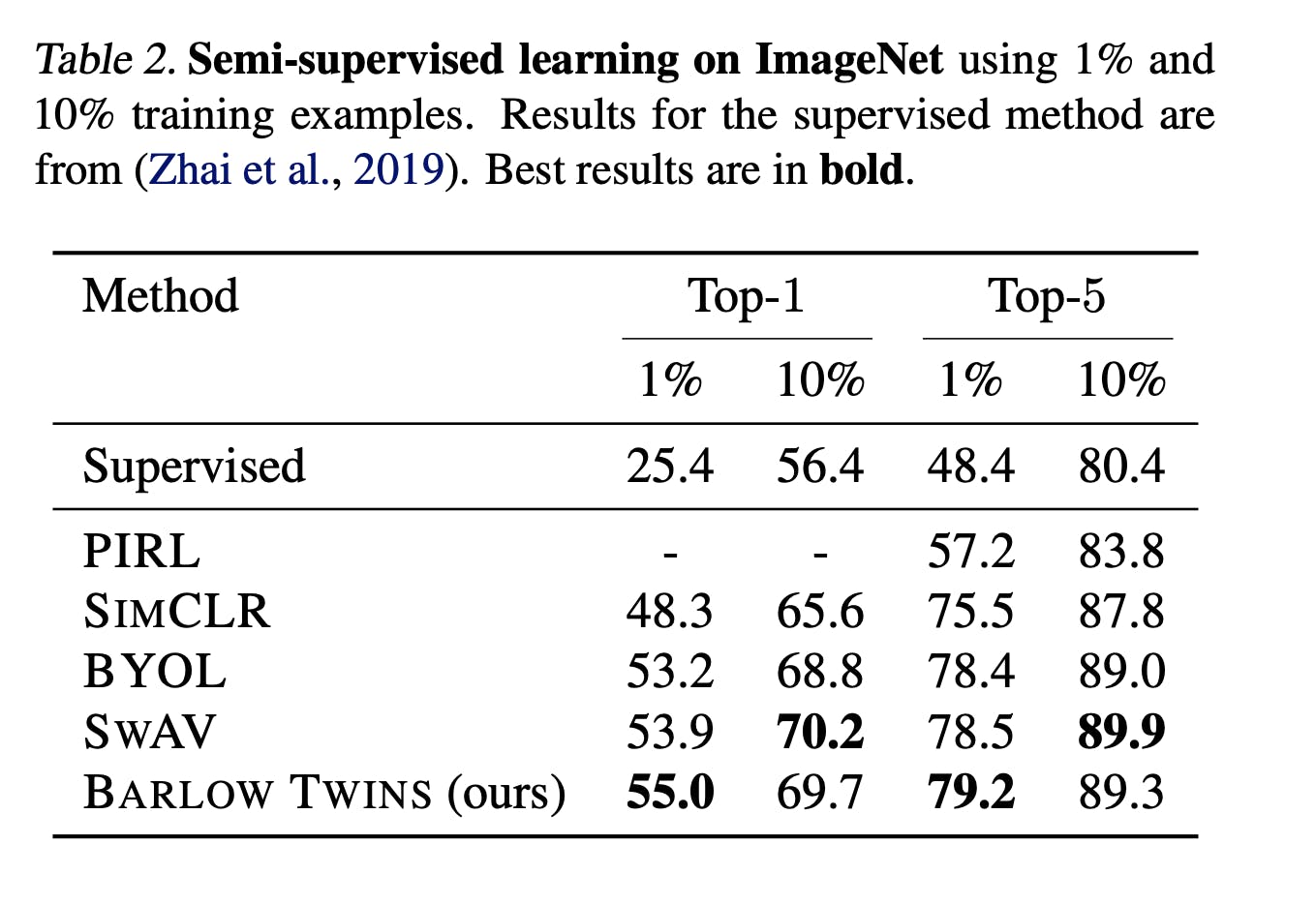
ImageNet numbers for Barlow Twin SSL approach
The Barlow Twins approach to SSL focuses on learning embeddings that remain invariant to input sample distortions. A significant challenge in this domain has been the emergence of trivial, constant solutions. While most contemporary methods have circumvented this issue through meticulous implementation nuances, the Barlow Twins approach introduces an objective function that inherently prevents such collapses.6
The Barlow Twins algorithm exhibits certain features when combined with other SSL methods. For instance, SimCLR and BYOL, two state-of-the-art SSL baselines, rely heavily on negative samples and data augmentations, respectively. In contrast, the Barlow Twins method sidesteps the need for negative samples, focusing instead on minimizing the redundancy between embeddings. This approach, combined with large batches and a tailored learning rate, has been instrumental in its success.
Furthermore, the Barlow Twins algorithm has been tested on the ImageNet dataset, a large-scale computer vision benchmark. The results were compelling. Using a ResNet-50 encoder and a projector network, the Barlow Twins achieved a 67.9% top-1 accuracy after 100 epochs. This performance is particularly noteworthy when considering the algorithm's simplicity and the projector network's absence of batch normalization or ReLU.
It's worth noting that the Barlow Twins' performance and comparisons are actively discussed on various platforms, including GitHub, where developers and researchers share their insights and modifications to the algorithm. As the field of SSL continues to grow, it will be intriguing to see how the Barlow Twins evolve and where they stand across different SSL methods.
Barlow Twins: Key Takeaways
The Importance of Redundancy Reduction
The Barlow Twins method has been recognized for its innovative application of the Redundancy Reduction principle in self-supervised learning (SSL).6 This principle, inspired by neuroscientist H. Barlow, emphasizes the significance of reducing redundant information while retaining essential features. In the context of the Barlow Twins, this means creating embeddings invariant to distortions of the input sample while avoiding trivial constant solutions. The method achieves this by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample and ensuring it remains close to the identity matrix. This intricate balance ensures that the embeddings of distorted versions of a sample are alike, yet the redundancy between the components of these vectors is minimized.
Advantages Over Other SSL Methods
The Barlow Twins approach offers several unique advantages over other SSL methods. One of its standout features is its ability to naturally avoid the collapse of embeddings without needing large batches or asymmetry between the twin networks. This is achieved without using techniques like gradient stopping, predictor networks, or moving averages on weight updates. Furthermore, the method benefits from high-dimensional output vectors, allowing for richer data representation and improved performance in tasks like image recognition.
The future looks promising as SSL narrows the gap with supervised methods, especially in large computer vision benchmarks. With its unique approach and advantages, the Barlow Twins method is poised to play a pivotal role in developing SSL methods. The potential for further research lies in refining the method, exploring its application in diverse domains, and integrating it with other advanced techniques to push the boundaries in SSL.
Frequently asked questions
The Barlow Twins method is an approach in self-supervised learning (SSL) that aims to create embeddings invariant to distortions of the input sample. The method is named after neuroscientist H. Barlow, who proposed the redundancy-reduction principle. In the context of Barlow Twins, this principle is applied to measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample. The objective is to make this matrix as close to the identity matrix as possible, ensuring that the embeddings of distorted versions of a sample are similar while minimizing redundancy between the components of these vectors.
The Barlow Twins method is not strictly a contrastive learning method. While both approaches aim to learn representations by comparing different views of the same data, Barlow Twins focuses on reducing redundancy between the components of the output vectors of two identical networks. It does this by ensuring the cross-correlation matrix of the outputs remains close to the identity matrix.
Both VICReg and Barlow Twins are methods in self-supervised learning, but they have distinct objectives and mechanisms. While Barlow Twins emphasizes reducing redundancy by aligning the cross-correlation matrix of twin network outputs with the identity matrix, VICReg might have different objectives and techniques to achieve its goals. The differences require a detailed comparison of both methods, available in dedicated research papers or comparative studies.
Yes, Encord is equipped to support individual model training projects, including those focused on phase recognition. Users can create and manage separate annotation projects tailored to their specific needs, such as identifying different phases of surgical procedures, ensuring that the models are trained effectively on relevant datasets.