How To Use Encord’s Bitmask Brush Tool

Product Manager at Encord
In machine learning, precise image annotation is crucial for training accurate and reliable models. Encord's Bitmask brush tool revolutionizes the annotation process by allowing interactive and fine-grained selection of regions of interest within images. Designed to cater to the needs of machine learning practitioners, this comprehensive guide will walk you through the ins and outs of utilizing Encord's Bitmask brush tool, empowering you to create precise and highly accurate annotations within the Encord platform.
What is the bit mask brush?
A bit mask brush allows you to interactively define regions or areas of interest within an image by "brushing" over them. As you paint or brush over the image, the bit mask brush assigns specific ‘bits’ or values to the corresponding pixels or regions you select. These bits represent the labels or categories associated with the selected areas.
 Accessing brush tool: Click on 🖌️ or press ‘f’
Accessing brush tool: Click on 🖌️ or press ‘f’ 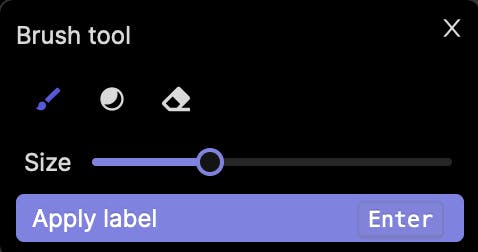
For example, if you are labeling outlines of blood vessels in an image, you can use a bit of mask brush to brush over the pixels corresponding to the vessel’s boundaries. The bit mask brush would assign a specific value or bit pattern to those pixels, indicating that they belong to the vessel class or category.
Similarly, if you are labeling topologically separate regions belonging to the same frame classification, you can use a bitmask brush to assign different bit patterns or values to the regions you select. This allows you to differentiate between regions or segments within the same frame category.
Using the Bitmask Brush
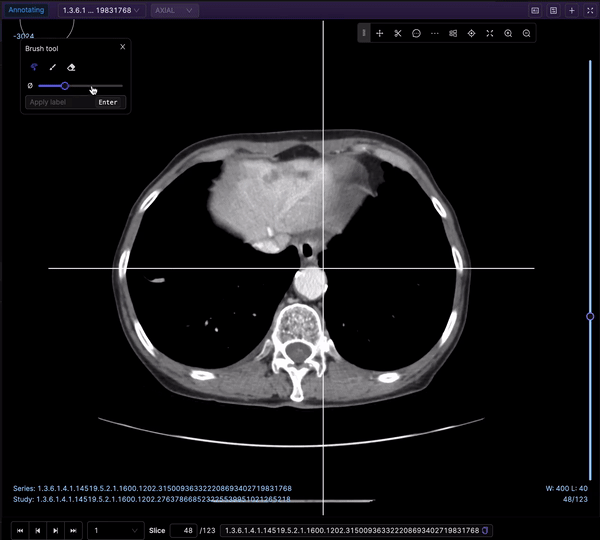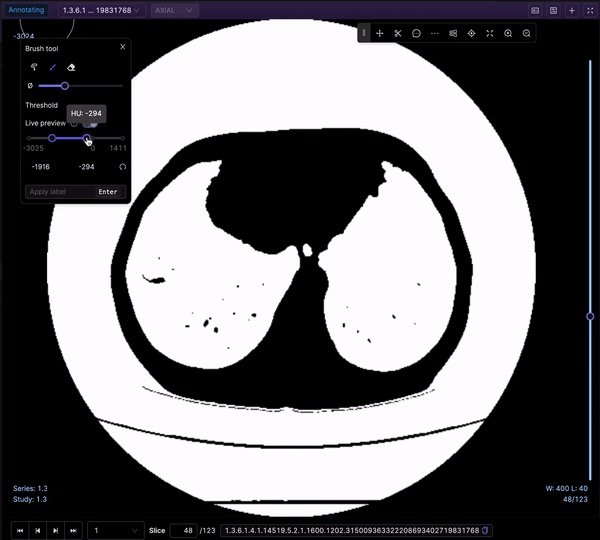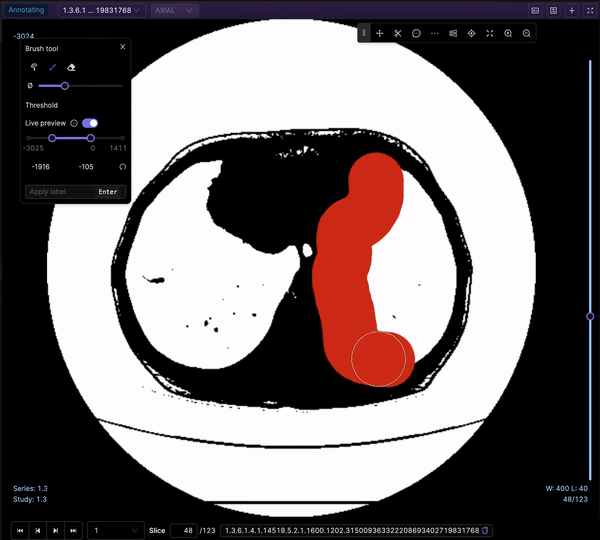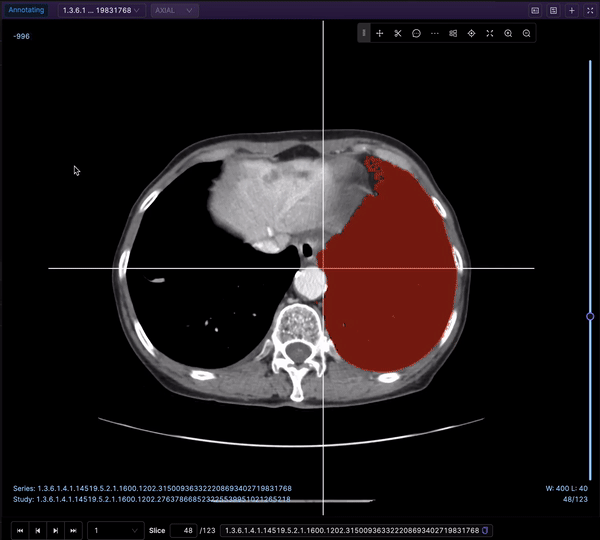
The Bitmask brush is a powerful tool for creating annotations or labels by selecting specific regions within an image, providing flexibility and control over the labeling process. Let’s explore its key functionalities:
Selection and Size Adjustment
When the Bitmask annotation type is selected, the brush tool is automatically chosen by default. You can access it by clicking the brush icon or pressing the 'f' key, and you are able to adjust the brush size using a convenient slider. This enables you to tailor the brush size to the level of detail needed for your annotations.
Annotation Creation
Once you have adjusted the brush size, you can begin annotating your image by selecting the desired areas. As you brush over the regions, the Bitmask brush assigns specific bit patterns or values to the corresponding pixels, indicating their association with the selected labels or categories.
Apply Label
Once your annotation is complete, you can apply the label by clicking the "Apply label" button or pressing the Enter key, finalizing the annotation and incorporating it into the labeling or annotation process.
💡To use the bitmap masks, the ontology should contain the Bitmask annotation type. Eraser
The Eraser tool provides the ability to erase parts or the entirety of your bitmask selection. This can be useful if you need to refine or modify your annotations before applying the final label. You can access the Eraser tool by clicking the eraser icon or pressing the 'h' key on your keyboard while the popup window is open.
Accessing eraser tool: Click on eraser icon or press ‘h’ Threshold Brush
The Threshold brush, specific to DICOM images, offers additional functionality by enabling you to set an intensity value threshold for your labels. The preview toggle allows you to visualize which parts of the image correspond to your set threshold, helping you determine the areas that will be labeled when covered by the Threshold brush.
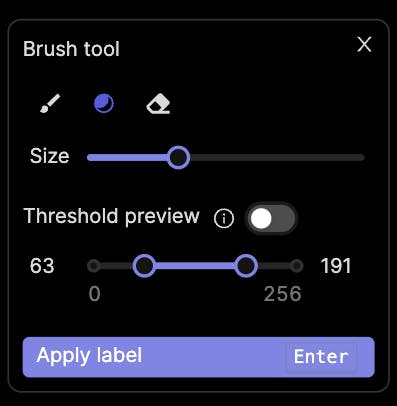
To access the Threshold brush, click the corresponding icon or press the 'g' key while the popup window is open. Adjust the brush size and the range of intensity values using the sliders in the popup.
Accessing threshold tool: Click on the corresponding icon or press ‘g’ With the Encord Bitmask SDK
The Encord Bitmask SDK empowers you to effortlessly generate, modify, and analyze annotations within the Encord platform, leveraging the vast capabilities of Python's comprehensive libraries and tools to their fullest extent.
Find more details in the bitmask documentation. To conclude, Encord’s Bitmask brush tool, equipped with its diverse range of features, offers an intuitive and flexible solution for creating annotations within the Encord platform. Harnessing the power of the Bitmask brush and the Encord Bitmask SDK, you can elevate your annotation workflow to achieve precise and reliable results.

Recommended Articles
Frequently asked questions
To create binary attributes in Encord, you can use the attribute configuration options when setting up your bounding boxes. While direct binary checkbox options may not be available, you can create attributes that function similarly, allowing you to specify whether a feature is present or not.
User feedback indicates that while the new hotkey feature for filtering offers a quicker way to apply filters, some users prefer the previous layout where filters were more visible and easily listed. Preferences may vary, but the new system aims to cater to different workflows.
The percentage router in Encord's workflows allows users to sample a specific percentage of data for tasks such as quality assurance or evaluation. This feature lets you adjust the percentages as needed, enabling you to effectively manage how data is distributed for review.
Encord can handle both 16-bit and 8-bit images. If you have 16-bit images, it's essential to clarify whether normalization to 8-bit is needed, as Encord can process both formats efficiently. This allows for flexibility in how image data is prepared for analysis.
Encord includes role-based access control, allowing administrators to assign specific permission levels to users based on their roles. This ensures that only authorized personnel can access sensitive data or perform certain actions within the platform.
Users can adjust the windowing settings in Encord by accessing the additional controls during annotation. This feature allows for granular adjustments to both the window width and window level, aiding in precise data visualization and annotation.
Yes, Encord provides granular user access control, allowing administrators to assign specific roles to users, such as annotators and reviewers. This structure helps to manage the annotation workflow effectively and ensures accountability.
The SDK in Encord serves as an API that allows users to programmatically interact with the platform. It enables users to write scripts that can handle various tasks, including data analysis and integration with external algorithms.
Yes, Encord seamlessly integrates with existing databases and tools. All features within the platform are programmatically accessible via our API and SDK, allowing for easy integration into your current workflows.
Encord does not natively provide a feature to directly export overlaps of surfaces with a single button. However, users can access annotation locations that allow them to compute overlaps through custom scripts.