Medical Image Segmentation: A Complete Guide

Product Manager at Encord
Medical image segmentation is used to extract regions of interest (ROIs) from medical images and videos. When training computer vision models for healthcare use cases, you can use image segmentation as a time and cost-effective approach to labeling and annotation to improve accuracy and outputs.
Segmentation in medical imaging is a powerful way of identifying objects, segmenting pixels, grouping them, and using this approach to labeling to train computer vision models.
In this guide, we’ll explore medical image segmentation, its role in healthcare computer vision projects, applications, and how to implement medical image segmentation.

What is Medical Image Segmentation?
Computer vision models rely on large training datasets used to train the algorithmic models (CV, AI, ML, etc.) to achieve high-precision medical diagnostics.
An integral part of this process is annotating and labeling the images or videos in a dataset. One method for this is image segmentation, which this article will explore in more detail.
Medical image segmentation involves the extraction of regions of interest (ROIs) from medical images, such as DICOM and NIfTI images, CT (Computed Tomography) scans, X-Rays, and Magnetic Resonance Imaging (MRI) files.
There are numerous ways to approach segmentation, from traditional methods that have been around for decades to new deep-learning techniques.
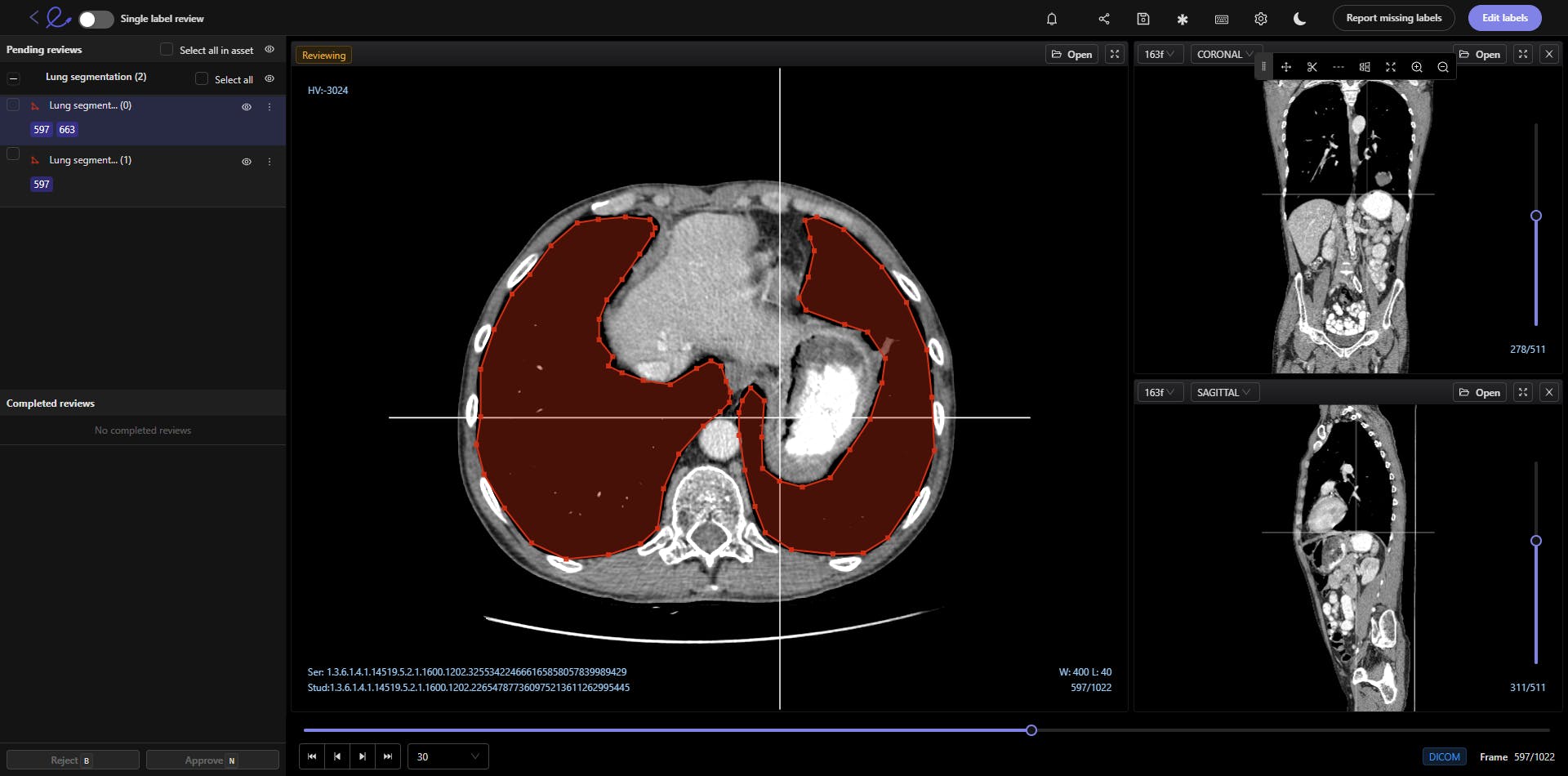
Naturally, everything in the medical profession needs to be implemented with precision, care, and accuracy. Any mistakes in the diagnosis or AI model-building stage could have significant consequences for patients, treatment plans, and healthcare providers.
This guide is for medical machine learning (ML), data operations (DataOps), and annotation teams and leaders wanting to learn more about how they can apply image segmentation for their computer vision projects.
 Read more: Encord’s guide to medical imaging experiments and best practices for machine learning and computer vision.
Read more: Encord’s guide to medical imaging experiments and best practices for machine learning and computer vision. Why is Medical Image Segmentation used In Healthcare Computer Vision Models?
Healthcare organizations, medical data operations, and ML teams can use medical image segmentation for dozens of computer vision use cases, including the following:
Radiology
Radiology is a medical field that generates an enormous amount of images (X-ray, mammography, CT, PET, and MRI), and healthcare organizations are increasingly turning to AI-based models to provide more accurate diagnoses at scale.
Training those models to spot what medical professionals can sometimes miss, or identify health issues more accurately, involves labeling and annotating vast datasets. Image segmentation is one way to achieve more accurate labels so that models can go into production faster, producing the results that healthcare organizations need.
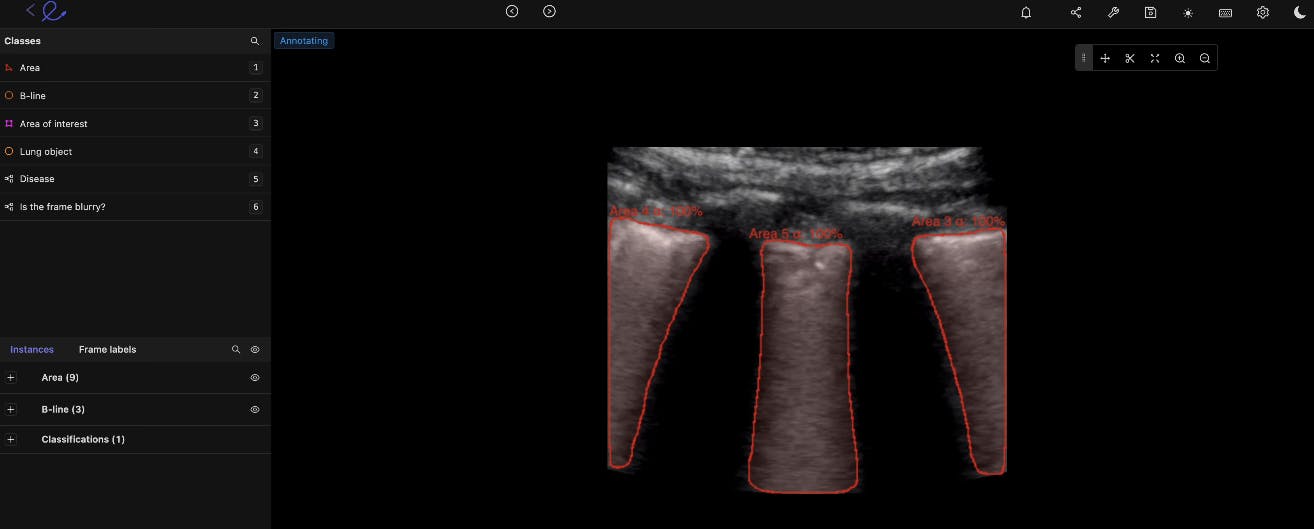
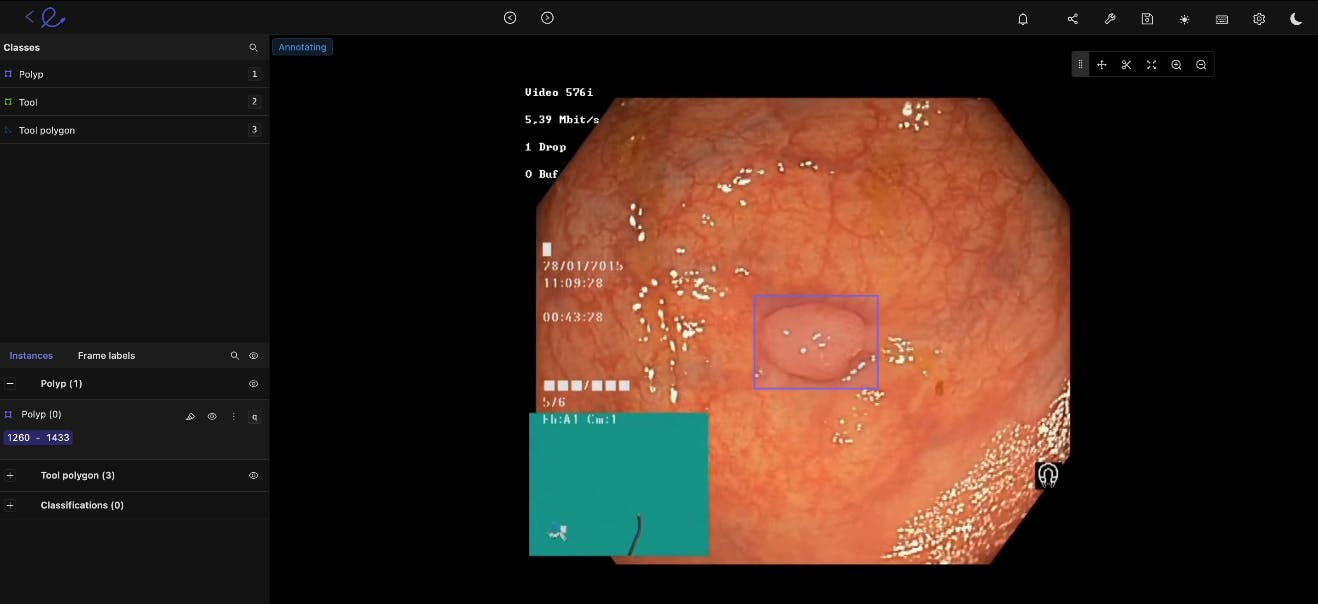
Gastroenterology
We can say the same about gastroenterology (GI) model development. Machine learning and computer vision models can be trained to more accurately identify cancerous polyps, ulcers, IBS, and other conditions at scale. Especially when it comes to outliers and edge cases that even the most skilled doctors and practice specialists can sometimes miss.
Histology
Medical image annotation is equally useful for histology, especially when AI models can accurately apply widely-used staining protocols (including hematoxylin and eosin stain (H&E), KI67, and HER2). Image segmentation helps medical ML teams train algorithmic models, implement labeling at scale, and generate more accurate histology diagnoses from image-based datasets.
Ultrasound
Image segmentation can help medical professionals more accurately label ultrasound images to identify gallbladder stones, fetal deformation, and other insights.
Cancer Detection
When cancerous cells are more difficult to detect, or the results from scans are unclear, computer vision models can play a role in the diagnosis process. Image segmentation techniques can be used to train computer vision models to screen for the most common cancers automatically, medical teams can make improvements in detection and treatment plans.
Looking for a dataset to start training a computer vision model on? Here are the top 10 free, open-source healthcare datasets. Different Ways to Apply Medical Image Segmentation In Practice
In this section, we’ll briefly cover 8 types of segmentation modes you can use for medical imaging. Here we’ll give you more details on the following types of image segmentation methods:
- Instance segmentation
- Semantic segmentation
- Panoptic segmentation
- Thresholding
- Region-based segmentation
- Edge-based segmentation
- Clustering segmentation
- Foundation Model segmentation
For more information, check out our in-depth image segmentation guide for computer vision that also includes a number of deep learning techniques and networks.

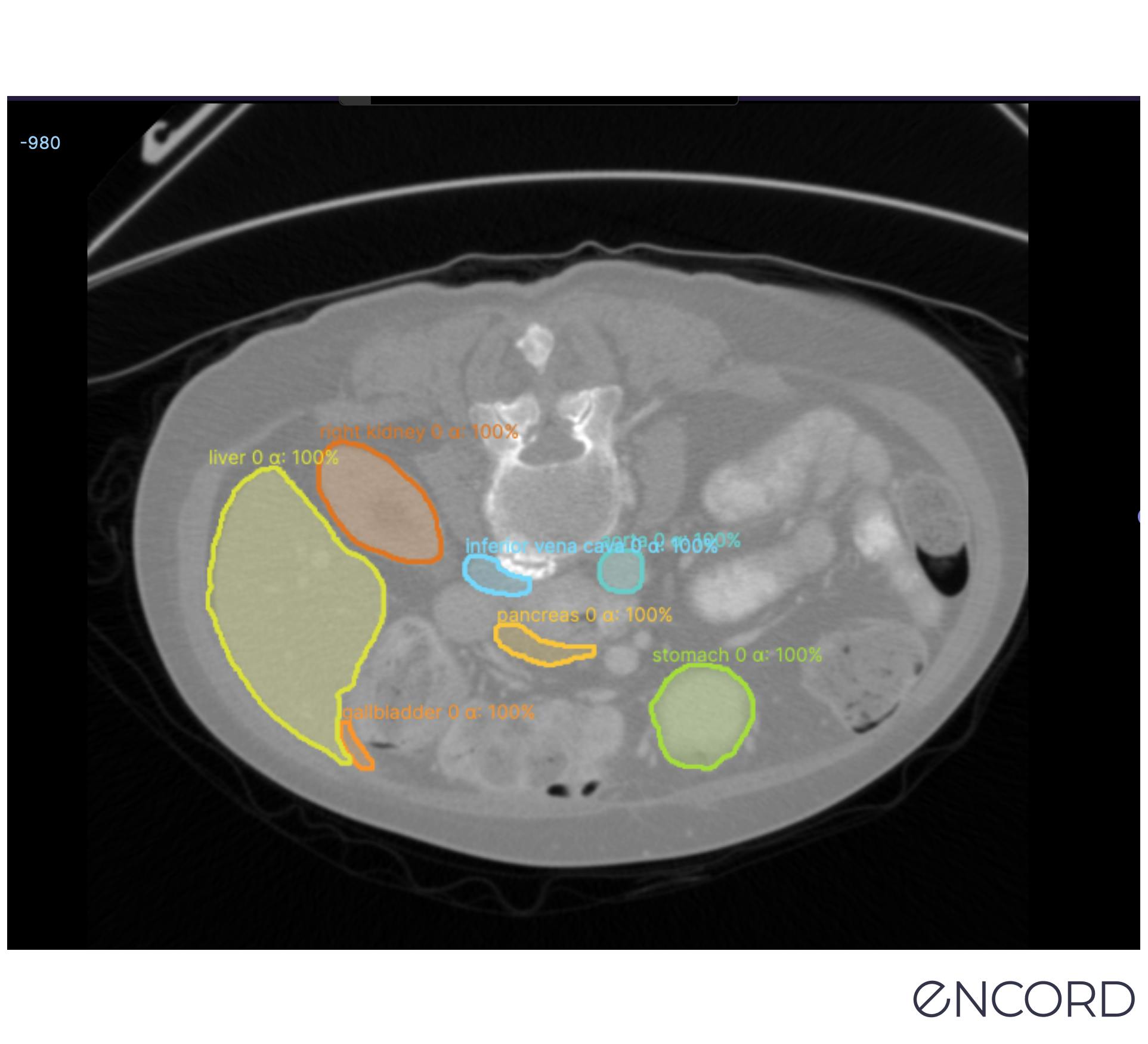
Instance segmentation
Similar to object detection, instance segmentation involves detecting, labeling, and segmenting every object in an image. This way, you’re segmenting an object’s boundaries, and whether you’re doing this manually or AI-enabled, overlapping objects can be separated too. It’s a useful approach when individual objects need to be identified and tracked.
Semantic Segmentation
Semantic segmentation is the act of labeling every pixel in an image. This will provide a densely labeled image, and then an AI-assisted labeling tool can take these inputs and generate a segmentation map where pixel values (0,1,...255) are transformed into class labels (0,1,...n).
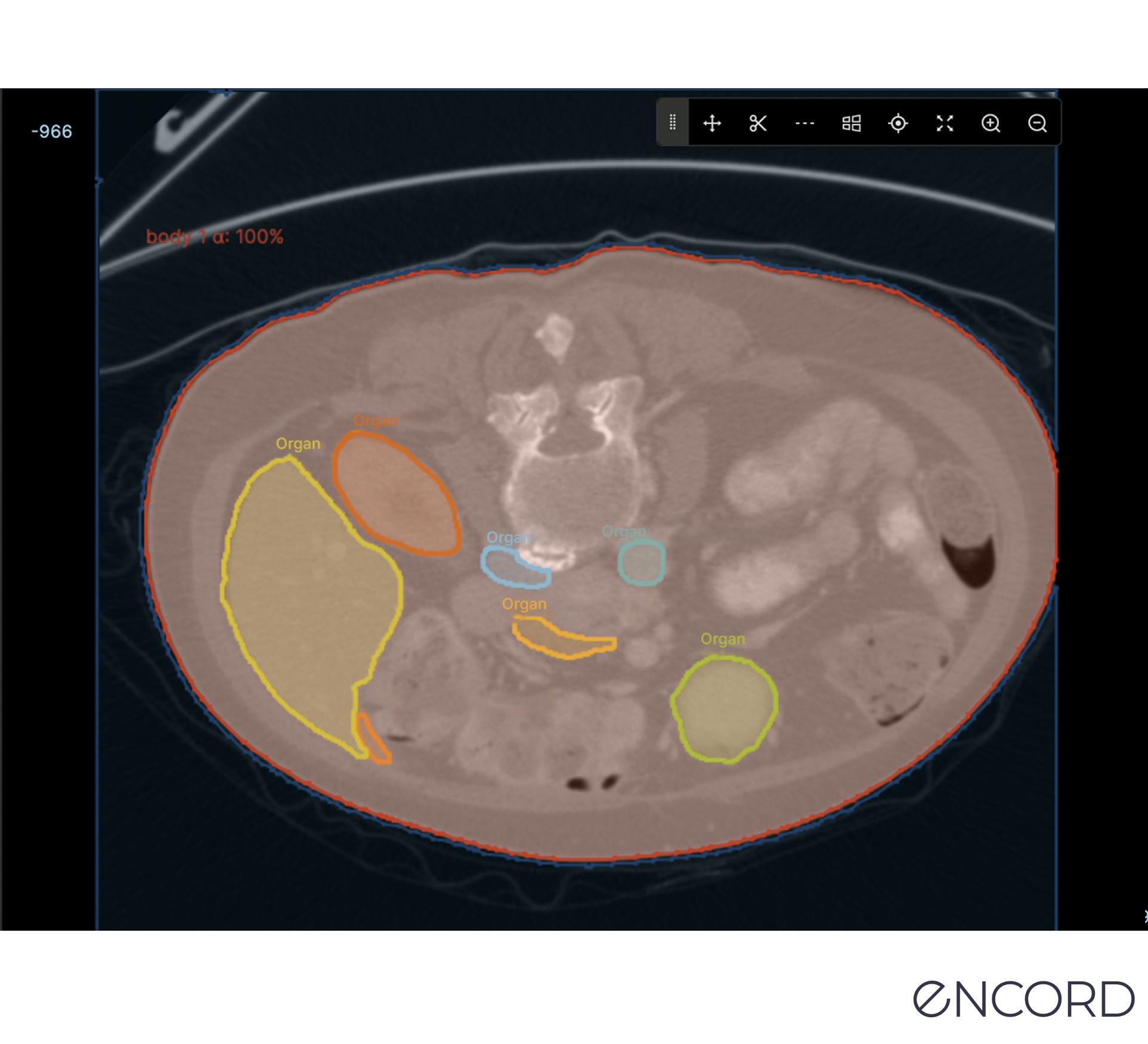
Panoptic Segmentation
Panoptic is a mix of the two approaches outlined above, semantic and instance. Every pixel is applied a class label to identify every object in an image. This method provides an enormous amount of granularity and can be useful in medical imaging for computer vision where attention to detail is mission-critical.
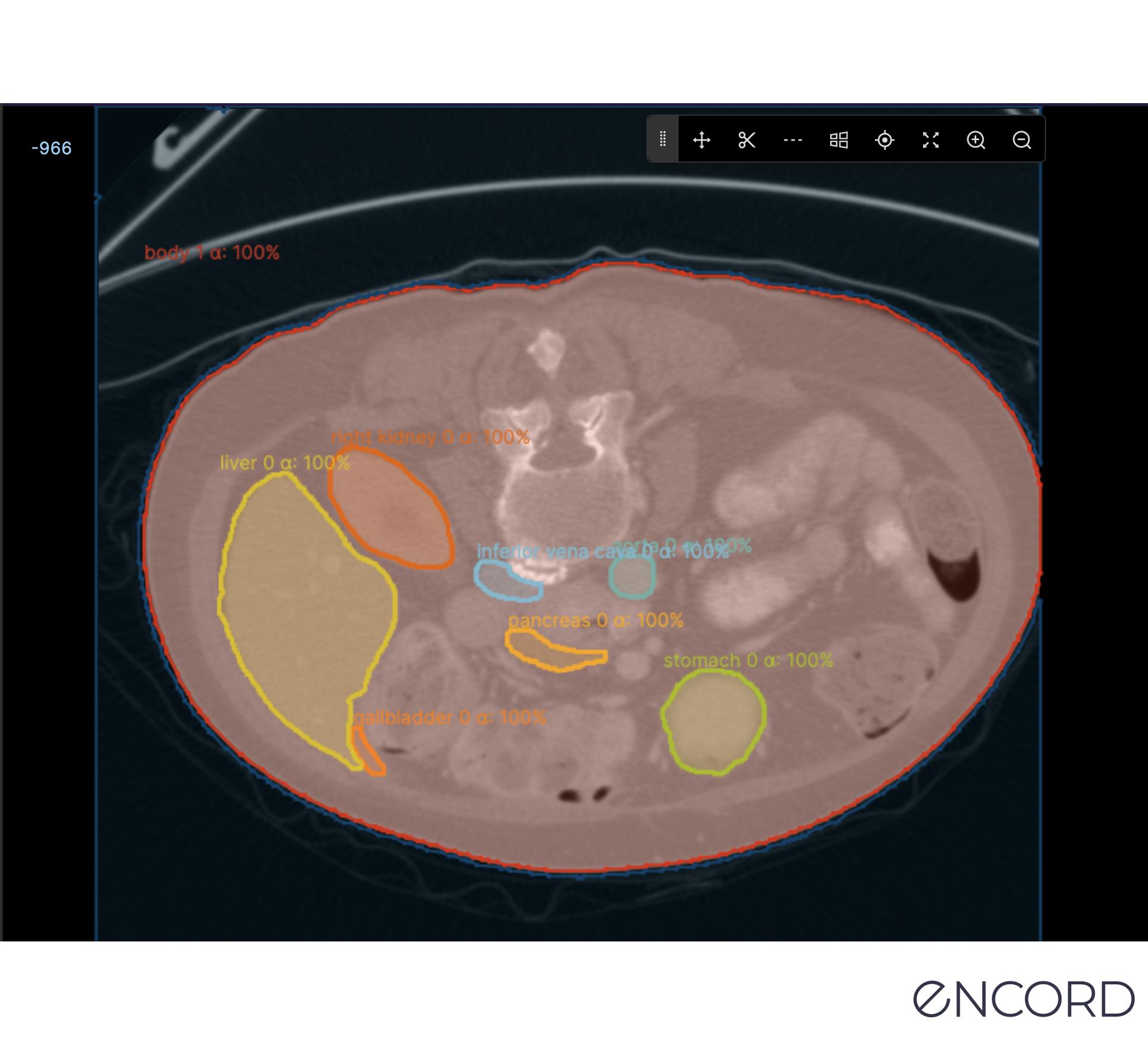
Thresholding Segmentation
Thresholding is a fairly simple image segmentation method whereby pixels are divided into classes using a histogram intensity that’s aligned to a fixed value or threshold.
When images are low-noise, threshold values can stay constant. Whereas in noisy images, a dynamic approach for setting the threshold is more effective.
In most cases, a greyscale image is divided into two segments based on their relationship to the threshold value. Two of the most common approaches to thresholding are global and adaptive.
Global thresholding for image segmentation divides images into foreground and background regions, with a threshold value to separate the two.
Adaptive thresholding divides the foreground and background using locally-applied threshold values that are contingent on image characteristics.
Region-based Segmentation
Region-based segmentation divides images into regions with similar criteria, such as color, texture, or intensity, using a method that involves grouping pixels. With this data, regions or clusters are then split or merged until a level of segmentation is achieved.
Annotators and AI-based tools can do this using a common split and merge technique or graph-based segmentation.
Edge-based Segmentation
Edge-based segmentation is used to identify and separate the edges of an image from the background. AI tools can be applied to detect changes in intensity or color values and use this to mark the boundaries of objects in images.
One method is the Canny edge detection approach, whereby a Gaussian filter is applied, applying non-maximum suppression to thin the edges and using hysteresis thresholding to remove weak edges.
Another method, known as Sobel, involves computing the gradient magnitude and direction of an image using a Sobel operator, which is a convolution kernel that extracts horizontal and vertical edge information separately.
Clustering Segmentation
Clustering is a popular technique that involves grouping pixels into clusters based on similarities, with each cluster representing a segment. Different methods can be used, such as K-mean clustering, mean-shift clustering, hierarchical clustering, and fuzzy clustering.
Visual Foundation Model Segmentation: (SAM) Segment Anything Model
Meta’s Visual Foundation Model (VFM), called the Segment Anything Model (SAM), is a powerful open-source VFM with auto-segmentation workflows, and it’s live in Encord!
It’s considered the first foundation model for image segmentation, developed using the largest image segmentation known, with over 1 billion segmentation masks. Medical image annotation teams can train it to respond with a segmentation mask for any prompt.
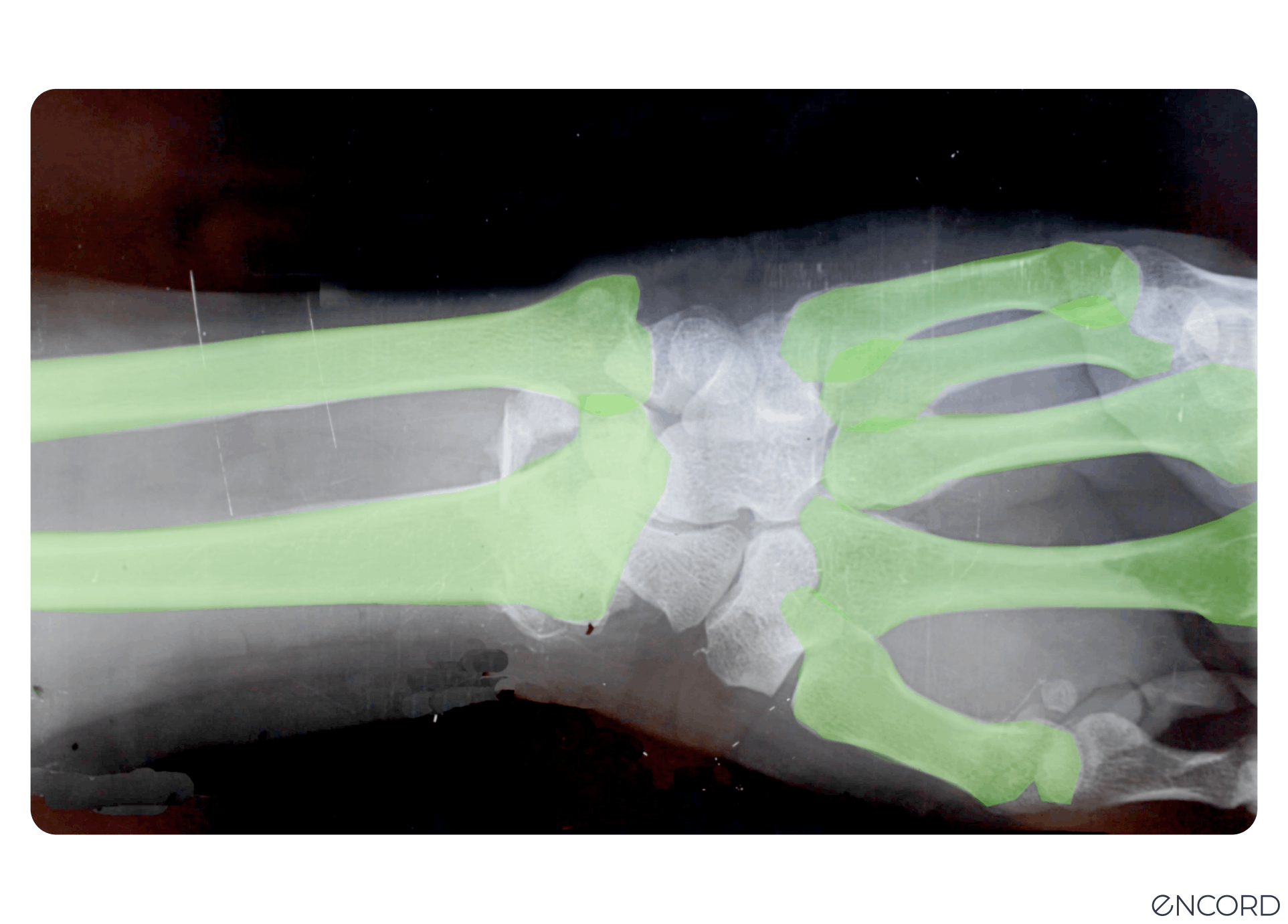
Prompts can be asking for anything from foreground/background points, a rough box or mask, freeform text, or general information indicating what to segment in an image.
How to Implement Medical Image Segmentation for Healthcare Computer Vision with Encord
With an AI-powered annotation platform, such as Encord, you can apply medical image segmentation more effectively, ensuring seamless collaboration between annotation teams, medical professionals, and machine learning engineers.
At Encord, we have developed our medical imaging dataset annotation software in collaboration with data operations, machine learning, and AI leaders across the medical industry – this has enabled us to build a powerful, automated image annotation suite, allowing for fully auditable data and powerful labeling protocols.
A few of the successes achieved by the medical teams we work with:
- Stanford Medicine cut experiment duration time from 21 to 4 days while processing 3x the number of images in 1 platform rather than 3
- King’s College London achieved a 6.4x average increase in labeling efficiency for GI videos, automating 97% of the labels and allowing their annotators to spend time on value-add tasks
- Memorial Sloan Kettering Cancer Center built 1000, 100% auditable custom label configurations for its pulmonary thrombosis projects
- Floy, an AI company that helps radiologists detect critical incidental findings in medical images, reduces CT & MRI Annotation time with AI-assisted labeling
- RapidAI reduced MRI and CT Annotation time by 70% using Encord for AI-assisted labeling.
Ready to automate and improve the quality, speed, and accuracy of your medical imaging segmentation?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
- Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
- Join our Discord channel to chat and connect.
Frequently asked questions
Encord offers a robust infrastructure that empowers physicians to leverage their own data for AI applications. With tools for image segmentation and object detection, Encord enables doctors to create custom models tailored to their specific needs without requiring extensive machine learning expertise.
Encord offers tools specifically designed for segmentation tasks, allowing users to efficiently segment structures like lung nodules and vertebral bodies in CT images. The platform streamlines the annotation process, making it easier to manage large datasets and improve accuracy.
Encord provides advanced AI capabilities that enhance the speed and accuracy of segmentation processes. By leveraging Encord's platform, users can achieve high-quality segmentations more quickly, allowing for improved surgical preparation and efficiency in complex procedures.
Encord offers advanced algorithms for automated segmentation in medical imaging, which are crucial for enhancing the accuracy of clinical trials. These features leverage machine learning to improve the efficiency and effectiveness of image analysis.
Encord specializes in annotating various types of medical imaging, including DICOM and MRI formats. This versatility allows teams to work with a wide range of medical data, making it suitable for diverse applications in healthcare.