Recommended Data Labeling Tools with Weights & Biases Integration

Head of Partnerships at Encord
Weights & Biases (W&B) has become a key platform for machine learning teams, from experiment tracking, to visualisation and data versioning. It allows experiments, metrics, models, and comparisons to all live in one place.
For many teams, labeled data still exists outside that system. Annotations are often created in separate tools and exported manually or stitched into pipelines with custom scripts. However, to achieve a clear lineage between model performance and the dataset version used, Weights & Biases is integrated with data labeling tools, like Encord.
As teams grow, adding more annotators, supporting additional data modalities, or iterating more frequently, finding a tool natively integrated with Weights & Biases becomes even more important. Increasingly, ML teams are realizing the importance of labeling tools that integrate directly with Weights & Biases, ensuring that labeled datasets are automatically versioned, traceable, and aligned with experiments.
What an Integration with Weights & Biases Actually Looks Like
At a basic level, some teams simply export labels as CSV, JSON, or COCO files and upload them manually to W&B. While this approach might work in the early stages, it fails to scale and often results in lost lineage between annotations and experiments.
Native integrations, by contrast, enable a direct and automated flow of labeled data into Weights & Biases Artifacts. Instead of relying on periodic exports or custom scripts, updated labels are continuously packaged and versioned so each change results in a new dataset Artifact that can be referenced by downstream training runs.
While the underlying label ontology typically remains stable, any updates to annotations are captured in the data that’s pushed to Weights & Biases. The key distinction is not schema transformation, but operational reliability: native integrations remove the coordination, maintenance, and failure modes that come with custom pipelines. For teams using Weights & Biases as the backbone of experimentation, this kind of managed, versioned data flow is the only approach that scales without adding ongoing engineering overhead.
Why Dataset Versioning Matters as Much as Model Versioning
W&B makes it easy to ask questions like “Which model performed best?” However, without versioned datasets, it is difficult to determine which labels were actually used for a given training run. Labeled data is never static. Corrections are made, edge cases are scoped, and schemas evolve over time. Without proper dataset versioning, teams end up comparing results that are not truly comparable, undermining trust in metrics and model performance.
Having the right labeling tool integrated with W&B ensures that every experiment can be traced back to the exact version of the dataset used. This alignment is critical not only for reproducibility but also for diagnosing model regression, improving data quality, and iterating at scale.
Recommended Data Labeling Tools with W&B Integration
Some organizations attempt to build internal labeling platforms, usually at an early stage or for highly specialized data. While this offers theoretical control, it’s rarely sustainable long-term. Reviewer interfaces, schema evolution, approval workflows, and audit trails are all complex to build and maintain. Integrating these systems with W&B in a robust way adds yet another layer of engineering overhead, and internal teams quickly become a scaling constraint.
Encord
Encord focuses on large-scale labeling and dataset management with an emphasis on quality and automation. Its native W&B integration enables labels in Encord to automatically sync into W&B as versioned Artifacts. This creates a seamless pipeline where updates to labeled data are immediately reflected in training workflows, without the need for manual exports or scripts.
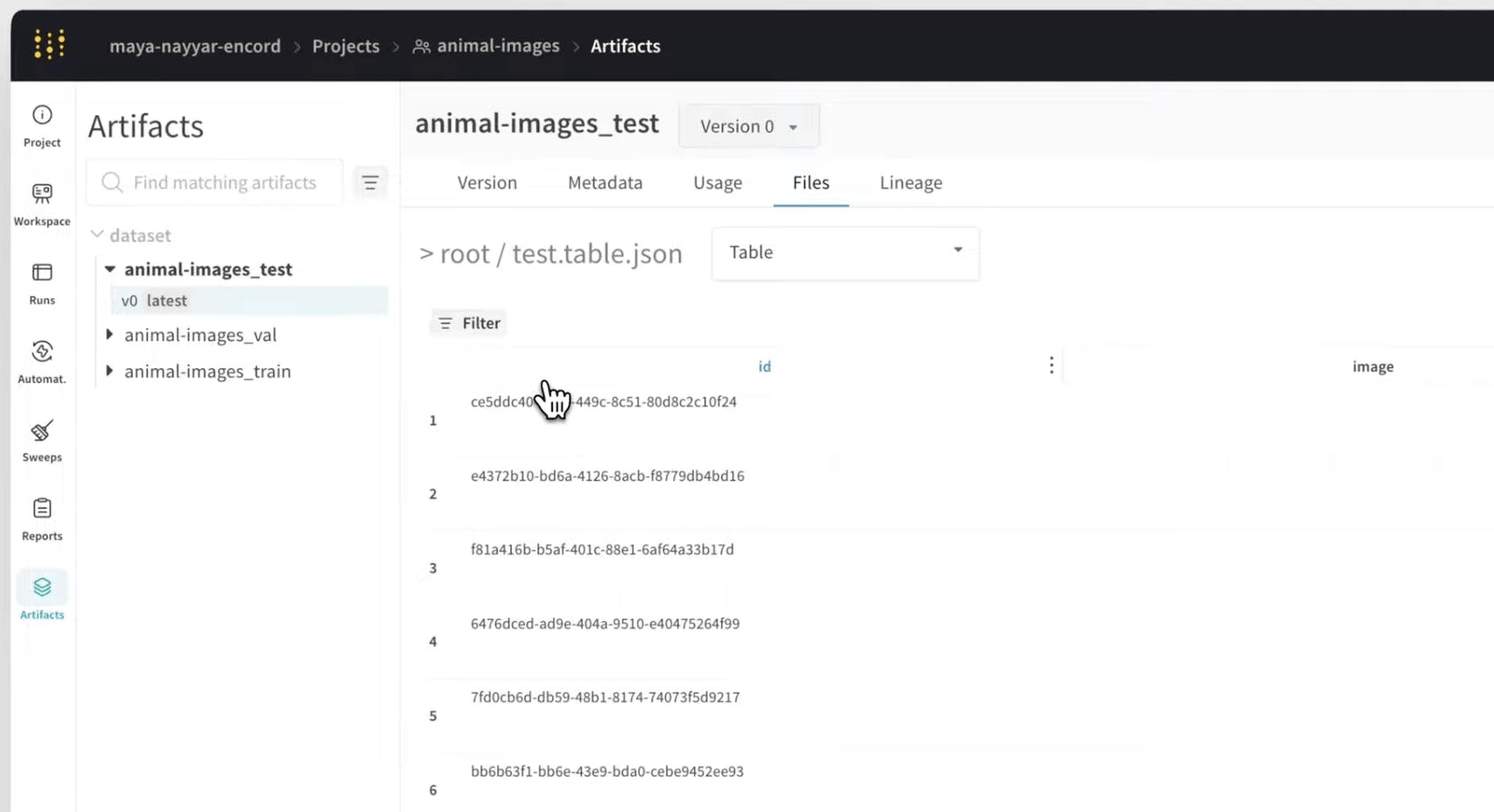
Access auto synced ground truth labels on Weights and Biases
Prodigy
Prodigy is a popular annotation tool for NLP and computer vision, especially for research-driven teams. It integrates directly with W&B by allowing Prodigy-labeled datasets to be logged into W&B Tables, where teams can explore examples, analyze labels, and connect datasets to model runs. This setup is particularly useful for rapid, iterative annotation workflows where understanding data quality is critical.
Kili AutoML (by Kili Technology)
Kili combines data labeling with AutoML workflows. Its integration with W&B allows models trained through Kili’s AutoML pipelines to report metrics, parameters, and results directly into W&B dashboards.
Which is the best?
Encord stands out for its native integration with Weights & Biases. Once connected, annotations in Encord are automatically packaged and pushed to W&B as versioned Artifacts. Each update creates a traceable dataset version that can be referenced directly in training runs, sweeps, and evaluations. This setup eliminates manual exports, reduces the risk of label drift, and ensures that every model iteration is trained on the most current ground truth.
Encord’s integration also supports multimodal data, including images, video, text, and GenAI evaluations. It maintains full lineage between annotations and experiments while requiring minimal engineering overhead. For teams practicing data-centric AI, this approach removes guesswork about whether models are training on the right data. For a deeper dive into the integration, see Encord × Weights & Biases: How to Keep Your Training Data in Lockstep with Ground Truth.
Some teams adopt a more flexible, script-based approach with open-source or generic annotation tools. These pipelines offer control over data formatting and can work well in teams with strong MLOps support. However, they often become cumbersome as annotation schemas evolve or workflows grow, introducing the risk and requiring ongoing engineering attention.
How W&B-Integrated Labeling Tools Transform Workflows
When a labeling tool is fully integrated with W&B, several workflows improve dramatically. Teams can be confident that training runs always use the latest labels, eliminating uncertainty about dataset currency. Debugging performance issues becomes far simpler, as results can be traced back to the exact dataset version and any changes in labels. Even human evaluations for GenAI models can be managed in the labeling platform and logged to W&B, allowing qualitative feedback and metrics to be analyzed side by side.
Choosing the Right Tool for Your Team
Selecting the right tool depends on your team’s scale, resources, and compliance needs. Early-stage teams with simpler pipelines may find script-based integrations sufficient. Scaling ML teams benefit from native dataset versioning and automatic syncing, which reduces operational risk and accelerates iteration. Enterprise and regulated organizations often require auditability, approval workflows, and strict lineage, making native integrations with versioned datasets essential.
Native integrations with labeling tools like Encord ensure that labeled data remains aligned with every model experiment. Teams that invest in these integrations can iterate faster, debug more effectively, and maintain confidence in the results of every training run.
For those looking to explore how automatic dataset syncing works in practice, the Encord × Weights & Biases integration provides a complete solution for keeping labeled data and experiments in lockstep.