Top RLHF Tools

Remember when Google’s AlphaGo beat the world’s number one Go Champion, Ke Jie, in a three-part match? That was a significant breakthrough for artificial intelligence (AI), proving how powerful AI can be in solving highly complex problems and surpassing human capabilities.
The driving force behind AlphaGo’s success was reinforcement learning (RL), an AI sub-domain that enables models to harness uncertainty using a trial-and-error approach, allowing them to perform optimally in various scenarios.
While RL improves AI systems in several domains, such as robotics, gaming, finance, etc., they do not perform well in situations requiring more nuanced approaches to problem-solving. For instance, optimizing responses from Large Language Models (LLMs) is complex due to the multiple ground truths for a particular user prompt. Defining a single reward function is challenging and requires human input to help the model understand the most appropriate response.
That’s where reinforcement learning with human feedback (RLHF) comes into play! It uses human preference information for AI model training to provide more context-specific and accurate output.
In this article, you will:
- Explore RLHF in detail
- Learn about the benefits and challenges of RLHF
- Introduce a list of top RLHF tools you can use to implement RLHF systems efficiently
How Does Reinforcement Learning From Human Feedback (RLHF) Work?
RLHF involves three steps to train a machine learning model. These include model pre-training, reward model training, and fine-tuning. Let’s discuss them below.
Pre-Training
The first stage in RLHF is to pre-train a model on extensive data to ensure it learns general patterns for performing several tasks. For example, in the context of large language models (LLMs), OpenAI developed InstructGPT using a lighter pre-trained GPT-3 with only 1.3 billion parameters instead of the complete 175 billion parameters from the original model. The resulting model performs better on use cases where following user instructions is required.
Similarly, Anthropic pre-trained transformer-based language models with 10 to 52 billion parameters work great for several natural language processing (NLP) tasks, such as summarization and Python code generation.
There is no single rule for selecting a suitable initial model for RLHF. However, you can consider multiple factors, like resource capacity, task requirements, data volume, variety, etc., to make the correct choice.
For example, you can select the GPT-3 model to create a virtual chatbot for your website. GPT-3 understands human language patterns well due to its pretraining on a massive text corpus. Fine-tuning it for downstream tasks will not consume much computational resources and will not require considerable annotated data due to its zero-shot learning capabilities.
Training a Reward Model
The next step is to develop a reward model that understands human preferences and assigns appropriate scores to different model outputs. The idea is to have another model - a reward function - that considers human values and assigns a rank to the model's initial prediction.
These ranks serve as reward signals for the model. A good rank tells the model that the prediction was desirable, while a negative rank suppresses any further occurrences. These signals are used to fine-tune the initial model for better performance. The illustration below shows this mechanism.
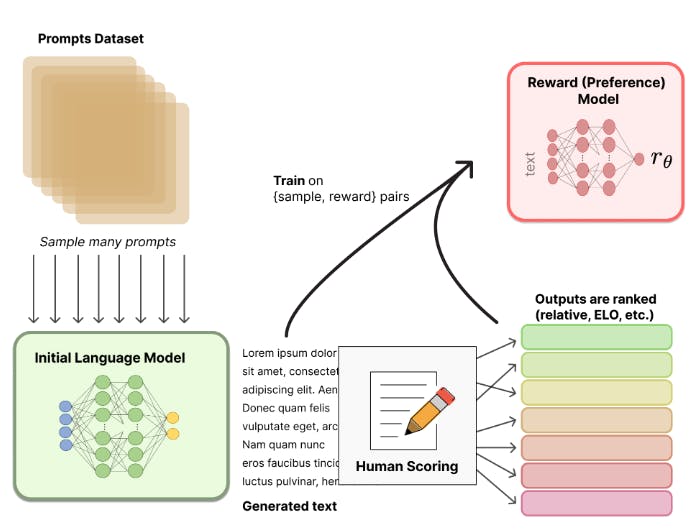
For example, multiple LLMs can generate different text sequences for the same prompt. Human annotators can rank the different sequences according to standard criteria, such as the level of toxicity, harmfulness, hallucination, etc. RLHF platforms can help streamline the process by computing numerical scores for each output based on human preferences.
You can train a separate reward model using the samples containing the generated texts and the corresponding human preference scores.
RL Fine-Tuning
The final step is to use a suitable RL algorithm to fine-tune an initial model’s copy to generate appropriate predictions that align with human preferences. You can freeze a certain number of layers of the copy and only update the parameters of the remaining layers for faster training.
The workflow begins with the frozen model - called the policy - generating a particular output. The reward model developed in the previous stage processes this output to compute a reward score. An RL algorithm uses the reward score to update the policy parameters accordingly.
For RL fine-tuning, you can use RL algorithms like proximal policy optimization (PPO) asynchronous advantageous actor-critic (A3C) algorithm, and Q-learning.
For example, in PPO, the reward model generates a preference score for the policy’s output. Also, it compares the initial model’s and the policy’s output probability distributions based on Kullback-Leibler (KL) divergence to assess how far the policy’s prediction space is from the original model. PPO penalizes policy outputs that drift further from the original model’s prediction.
The diagram below illustrates the Proximal Policy Optimization (PPO) Algorithm: It uses the preference score and penalty to update the policy’s parameters. This way, PPO constrains the policy from producing entirely non-sensical outputs.
Benefits of Reinforcement Learning From Human Feedback (RLHF)
The system described above is a typical RLHF training process, and it suggests that human input plays a crucial role in reward model training. Here are some of the significant benefits that RLHF has over traditional learning procedures -
Reduced Bias
RLHF models learn from diverse human feedback. The procedure prevents bias as the model understands human preferences better than a traditional model. However, Ensuring that human feedback comes from a varied and representative group is crucial, as non-diverse feedback can inadvertently introduce new biases.
Faster Learning
Models that only use automated RL algorithms can take considerable time to learn the optimal policy. With RLHF, quality and consistent human feedback accelerate the learning process by guiding the algorithm in the correct direction. The system can quickly develop a suitable policy for the desired action in a specific state.
Improved Task-Specific Performance
RLHF allows users to guide the model to output responses more suited to the task. It allows the model to learn to filter out irrelevant outputs and generate desirable results. For example, in a text-generation task, RLHF can help the model learn to prioritize relevant and coherent responses.
Safety
One significant issue in the Generative AI space is the model’s tendency to disregard how harmful or offensive the output can be. For instance, text-generation models can produce inappropriate content with high accuracy scores based on automated metrics. With RLHF, human feedback prevents a model from generating such output by increasing the model’s safety. However, the safety measure depends on the feedback providers' understanding and definition of what is harmful or offensive. So, the feedback must be context-specific and respect the available guidelines that tell what an inappropriate response entails.
Challenges of Reinforcement Learning From Human Feedback (RLHF)
While RLHF has many advantages, it still faces certain problems that can prevent you from efficiently implementing an RLHF system. Below are a few challenges you must overcome to build a robust RLHF model.
Scalability
RLHF requires human annotators to fill in their preferences for multiple outputs manually. This is time-consuming and demands domain experts if the output contains technical content. Implementing large-scale RLHF systems can be prohibitively expensive and may hurt feedback quality and consistency.
One possible solution is to use crowd-sourcing platforms to parallelize the feedback process, introduce semi-automated annotation pipelines to reduce reliance on manual effort or generate synthetic feedback using generative models to speed up the process.
Human Bias
While RLHF reduces overfitting by including human preferences in the training data, it is still vulnerable to several cognitive biases, such as anchoring, confirmation, and salience bias. For example, information bias can lead humans to label an output with additional but irrelevant information as “better” than a shorter but more precise answer.
These issues can be mitigated by selecting a diverse pool of evaluators, setting clear guidelines for providing feedback, or combining feedback from humans and other LLMs with automated scores like BLEU or ROUGE to compute a more objective performance metric.
Optimizing for Feedback
Instead of optimizing for the actual task, an RLHF system can produce a model that generates output only to satisfy humans and ignore its true objective. You can overcome this problem by balancing the optimization process to incorporate human feedback and the primary task’s objectives.
Using a hybrid reward structure, where you define task-related rewards and those related to human feedback, is helpful. You can assign different weights to the different types of reward scores to ensure the final model doesn’t overfit human feedback.
While mitigation strategies help deal with RLHF challenges, a robust tool can also streamline your RLFH pipelines. Let’s look at a few factors you should consider when selecting the right RLHF tool.
Factors to Consider Before Selecting the Right RLHF Tool
Choosing the right RLHF tool can be overwhelming. You must consider several factors before investing in an RLHF platform that suits your needs. The list below highlights some critical factors for making the correct decision.
Human-in-the-Loop-Control
You'll need to see whether the tool you're looking for has enough features to allow quick human intervention when things go wrong. It should also enable human annotators with different domain expertise to collaborate efficiently and provide timely feedback to the annotation process. Moreover, the feedback interface must be intuitive to minimize the learning curve and maximize efficiency. It should allow customizable control levels for annotators with varying expertise and facilitate efficient collaboration across domains.
Variety and Suitability of RL Algorithms
While Proximal Policy Optimization (PPO) is a popular RL algorithm, other algorithms can also benefit depending on the task. The tool should have algorithms that match your specific requirements for building an effective RL or RLHF system.
Scalability
As mentioned earlier, scaling RLHF systems is challenging due to the need for human annotators. An RLHF platform containing collaboration tools, cloud-based integration, batch processing, features to build automated pipelines for data processes, quality assurance, and task allocation can help scale your RLHF infrastructure significantly. Also, the platform must provide sufficient domain experts and customer support on demand for scalability.
Cost
You must consider the costs of installing, operating, and maintaining the tool against your budgetary resources. These costs can include platform licensing or subscription fees, data acquisition costs, costs to train the workforce, and the cost of installing appropriate hardware, such as GPUs, to run complex RLHF processes. Also, the expenses can increase as you scale your models, meaning you must choose a platform that provides the required functionality and flexibility to handle large data volume and variety.
Customization and Integration
Adaptability is key in RLHF systems, enabling the model to perform well in dynamic environments. The optimal choice is a tool with high customization options for tailoring the reward models according to your needs. Also, it should integrate seamlessly with your existing ML stack to minimize downtime.
Data Privacy
Since RLHF can involve humans accessing personal data for annotation, an RLHF tool must have appropriate data privacy and security protocols. For example, robust access management features and audit trail logging can help prevent data breaches and compliance issues. It must comply with international data privacy regulations like GDPR and CCPA while providing robust data encryption and a secure data storage facility.
Let’s now discuss the different tools available for implementing RLHF.
Top Tools for Reinforcement Learning From Human Feedback (RLHF)
Although implementing RLHF is challenging, a high-quality RLHF tool can help you through the difficulties by providing appropriate features to develop an RLHF system. Below is a list of the most popular RLHF tools in the market, ranked based on functionality, ease-of-use, scalability, and cost.
Encord RLHF
Encord RLHF lets you build robust RLHF workflows by offering collaborative features to optimize LLMs and vision-language models (VLMs) through human feedback.

Benefits and key features
- Encord RLHF enables you to build powerful chatbots that generate helpful and trustworthy responses.
- The platform lets you moderate content by building LLMs that align with human feedback to flag misinformation, hate speech, and spam.
- You can quickly benchmark, rank, select, recognize named entities, and classify outputs to validate the LLMs' and VLMs' performances.
- The platform also lets you prioritize, label, and curate high-quality data with specialized workforces with expertise in RLHF and evaluation.
- It also comes with high-end security protocols and easy integration capabilities.
Best for
- Sophisticated teams looking to build scalable RLHF workflows for large language models or vision language models.
Pricing
- Book a demo for an appropriate quotation.
Appen RLHF
Appen RLHF platform helps build LLM products by providing high-quality, domain-specific data annotation and collection features. Its RLHF module benefits from a curated crowd of diverse human annotators with a wide range of expertise and educational backgrounds.
Benefits and key features
- You can benefit from Appen’s specialists for providing feedback.
- The tool features robust quality controls to detect gibberish content and duplication.
- It supports multi-modal data annotation.
- It provides real-world simulation environments related to your niche.
Best for
- Teams who want to create a powerful LLM application for various use cases.
Pricing
- Pricing information is unavailable
Scale
Scale is an AI platform that allows the optimization of LLMs through RLHF.
Benefits and key features
- It helps you build chatbots, code-generators, and content-creating solutions.
- It has an intuitive user interface for providing feedback.
- It provides collaborative features to help labelers understand task requirements when giving feedback.
Best for
- Teams searching for a robust labeling platform that supports human input.
Pricing
- Pricing information is unavailable
Surge AI
Surge AI’s RLHF platform powers Anthropic AI’s LLM tool called Claude. Surge AI offers various modeling capabilities for building language models, such as summarization, copywriting, and behavior cloning.
Benefits and key features
- It lets you build InstructGPT-style models.
- Features safety protocols like SOC 2 compliance.
- Offers easy integration through API and Software Development Kit (SDK).
Best for
- Teams who want to develop multi-purpose chatbots and generative tools.
Pricing
- Pricing information is unavailable
Toloka AI
Toloka is a crowd-sourced labeling platform that offers RLHF workflows for fine-tuning LLMs. The platform was a critical factor in the BigCode project – an open scientific collaboration for responsible development and use of LLMs, where it helped in data preparation by labeling 14 categories of sensitive personal data.
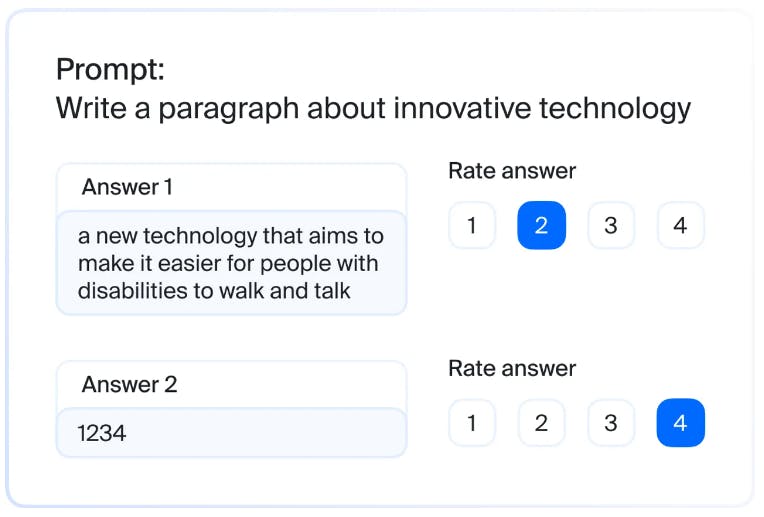
Benefits and key features
- It has an extensive expert community that can provide labeling support 24/7.
- It comes with ISO-27001 certification.
- It offers re-training and evaluation features to assess LLM performance.
Best for
- Teams who wish to kick-start RLHF projects in technical domains, such as linguistics or medicine.
Pricing
- Pricing information is unavailable
TRL and TRLX
Transformers Reinforcement Learning (TRL) is an open-source framework by Hugging Face for training models based on the transformer architecture using RLHF. This framework is superseded by TRLX from Carper AI, an advanced distributed training framework that supports large-scale RLHF systems.
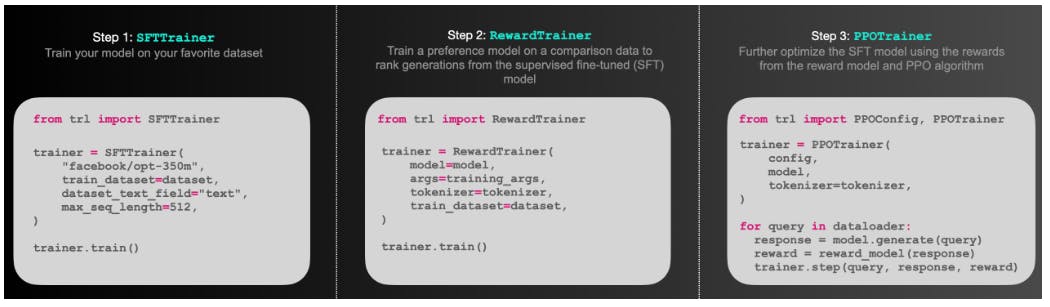
Benefits and key features
- TRL only features the PPO RL algorithm, while TRLX consists of PPO and Implicit Language Q-Learning (ILQL).
- TRLX can support LLMs with up to 33 billion parameters.
Best for
- Teams who want to work on large-scale transformer-based language model development can use TRLX.
Pricing
- The tool is open-source.
RL4LMs
Reinforcement Learning (RL) for Language Models (LM) (RL4LMs) is an open-source RLHF library that offers many on-policy RL algorithms and actor-critic policies with customizable building blocks for training transformer-based language models.
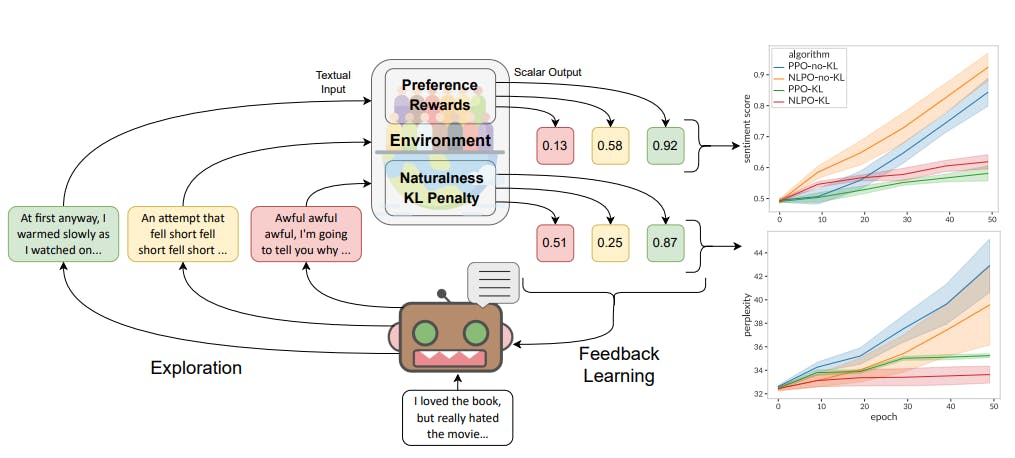
Benefits and key features
- On-policy RL algorithms include PPO, Advantage Actor-Critic (A2C), Trust-Region Policy Optimization (TRPO), and Natural Language Policy Optimization (NLPO).
- It supports 20+ lexical, semantic, and task-specific metrics that can be used to optimize reward functions.
- It works well for several tasks, such as summarization, generative common-sense reasoning, and machine translation.
Best for
- Teams who want to build LLM models where the massive action space and defining a reward function are complex. For instance, LLMs for generating long-form stories or having open-ended conversations can benefit from the RL4LMs library.
Pricing
- RL4LMs is open-source.
Reinforcement Learning From Human Feedback: Key Takeaways
RLHF is an active research area with many nuances and complexities. However, the following are key points you must remember about RLHF.
- RLHF components: RLHF systems involve a pre-trained model, a reward model, and a reinforcement learning algorithm that fine-tunes the pre-trained model with respect to the reward model.
- Reward function: RLHF improves the traditional RL system by incorporating human feedback in the reward function.
- Fine-tuning: RL models can be fine-tuned using various algorithms. Proximal Policy Optimization (PPO) is the most popular policy-gradient-based algorithm for finding the optimal policy.
- Enhanced learning: RLHF can enhance the learning process by allowing the RL model to quickly find an optimal policy through reward scores based on human feedback.
- Scalability challenge: Scaling an RLHF algorithm is challenging since it requires manual input from human annotators. Finding human resources with relevant skills and domain expertise is difficult and also carries the possibility of human error during the feedback process. Possible solutions include crowdsourcing feedback, batch processing, automated scoring methods, and tools that support cloud-based integration with robust collaboration tools.
- RLHF platforms: Effective RLHF platforms can help mitigate such challenges by providing robust collaborative and safety features. Some popular platforms include Encord RLHF, Scale, and Toloka.
Frequently asked questions
RLHF helps enhance model training by including human feedback as an additional factor to optimize model output.
Traditional RL finds optimal policy through trial and error without human guidance. In contrast, RLHF accelerates the learning process by learning from human feedback.
You can implement RLHF by letting human annotators rank multiple outputs from different models. You can then train a reward model on these rankings with corresponding outputs. The reward model will learn to generate a score that you can use to train your initial model.
RLHF speeds up the learning process and ensures AI model safety, as humans can directly verify the output’s relevance and accuracy.
ChatGPT, InstructGPT, Deepmind’s Sparrow, and Google Bard are some RLHF-based models.
Since RLHF uses human feedback, implementing RLHF systems at scale is challenging as expert human annotators can be lacking.
In language models, RLHF involves humans annotating various responses from multiple language models to indicate which response is more appropriate. A separate reward model can use this information to learn a reward function.
Yes. GPT 3.5 uses RLHF as it allows you to like or dislike a response. The feedback helps in improving the model’s responses.
Encord prioritizes the user experience by continuously developing features that enhance usability for those on the ground. This commitment ensures that the tools provided are not only functional but also tailored to meet the needs of users in real-world applications.
Encord stands out with its advanced functionalities, including robust traceability features essential for FDA workflows. Clients often transition to Encord from lower-end tools due to these added capabilities that enhance their labeling and annotation processes.