How to Track and Version Labeled Datasets with Weights & Biases and Encord

Head of Partnerships at Encord
Keeping labeled datasets versioned and in sync with model iterations is a challenge scaling AI teams face when building reliable ML systems. Labels change, schemas evolve, and iterations multiply. However, many teams still rely on manual exports or scripts to manage training data.
In this guide, we’ll walk through how to track and version labeled datasets using Weights & Biases and Encord, and why connecting annotation workflows directly is critical for modern ML and teams.
Why Dataset Versioning Matters for ML Teams
When a model underperforms, it is often due to the data they are trained on. Most models will produce unreliable results if the underlying labels are inconsistent, outdated, or misaligned with the task or the environments in which it is deployed in the real world.
Without proper dataset tracking and versioning, ML teams quickly encounter a range of problems. Teams might inadvertently train on inconsistent labels, leading to degraded performance over time.
Past iterations can become difficult to reproduce, making it hard to answer simple questions like, “Did this model actually improve?”
Even subtle shifts in labeling, or label drift, can creep in across iterations, creating inconsistencies. And when multiple versions of a dataset exist without clear lineage, it can be impossible to know which dataset version produced a particular result.
This is where a systematic approach to dataset management becomes critical. Weights & Biases excels at experiment tracking and artifact versioning, giving teams a clear view of what data, code, and parameters were used in each run.
Encord, on the other hand, provides a structured, high-quality platform for creating, reviewing, and managing labeled data. When these systems are connected, the process of manually tracking dataset versions becomes automatic. Each annotation update is captured, versioned, and tied directly to experiments, ensuring that training pipelines always operate on the correct, up-to-date ground truth.
Without proper dataset tracking and versioning, teams run into problems like:
- Training on stale or inconsistent labels
- Inability to reproduce past experiments
- Silent label drift across model iterations
- Confusion about which dataset version produced a given result
Weights & Biases solves experiment tracking and artifact versioning, while Encord specializes in creating and managing high-quality labeled data. When these two systems are connected, dataset versioning becomes automatic instead of manual.
The Challenge: Manual Dataset Handoffs Don’t Scale
In many organizations, dataset management still relies on a series of manual handoffs. Traditionally, dataset management looks something like this:
- Annotate data in a labeling tool
- Export labels as files
- Transform or clean them
- Upload them into a training pipeline
This process may work when projects are small, but it quickly breaks down as teams scale. Each handoff introduces risk: files can be misplaced, outdated labels can be uploaded by mistake, or subtle changes can go untracked. Over time, these small errors accumulate, undermining reproducibility, slowing iteration, and eroding trust in the model.
A more robust approach involves closing the loop between annotation and experiment tracking. By connecting Encord and Weights & Biases, teams eliminate the need for manual file transfers and ad-hoc scripts. Updates made in Encord flow automatically into Weights & Biases as versioned artifacts, ensuring that models are always trained on the correct data, experiments are fully reproducible, and data teams can focus on quality. In short, the integration transforms dataset versioning from a manual process into a reliable, automatic part of the ML workflow.
How Encord and Weights & Biases Work Together
The Encord + Weights & Biases integration creates a direct, managed data flow between labeled data and model training.
Here’s how it works at a high level:
- Encord remains the source of truth for annotations and labels
- Annotation updates in Encord are automatically pushed to Weights & Biases
- Each update is stored as a versioned Artifact in Weights & Biases
- Training runs, evaluations, and sweeps reference those Artifacts directly
Tracking Labeled Datasets with Weights & Biases Artifacts
Weights & Biases Artifacts are designed to version and track datasets, models, and other assets used in ML workflows.
With Encord connected:
- Every label update becomes a new Artifact version
- Metadata (schema, timestamps, annotation state) is preserved
- You can trace exactly which dataset version fed each experiment
- Rollbacks and comparisons are built in
This makes dataset lineage as clear as model lineage.
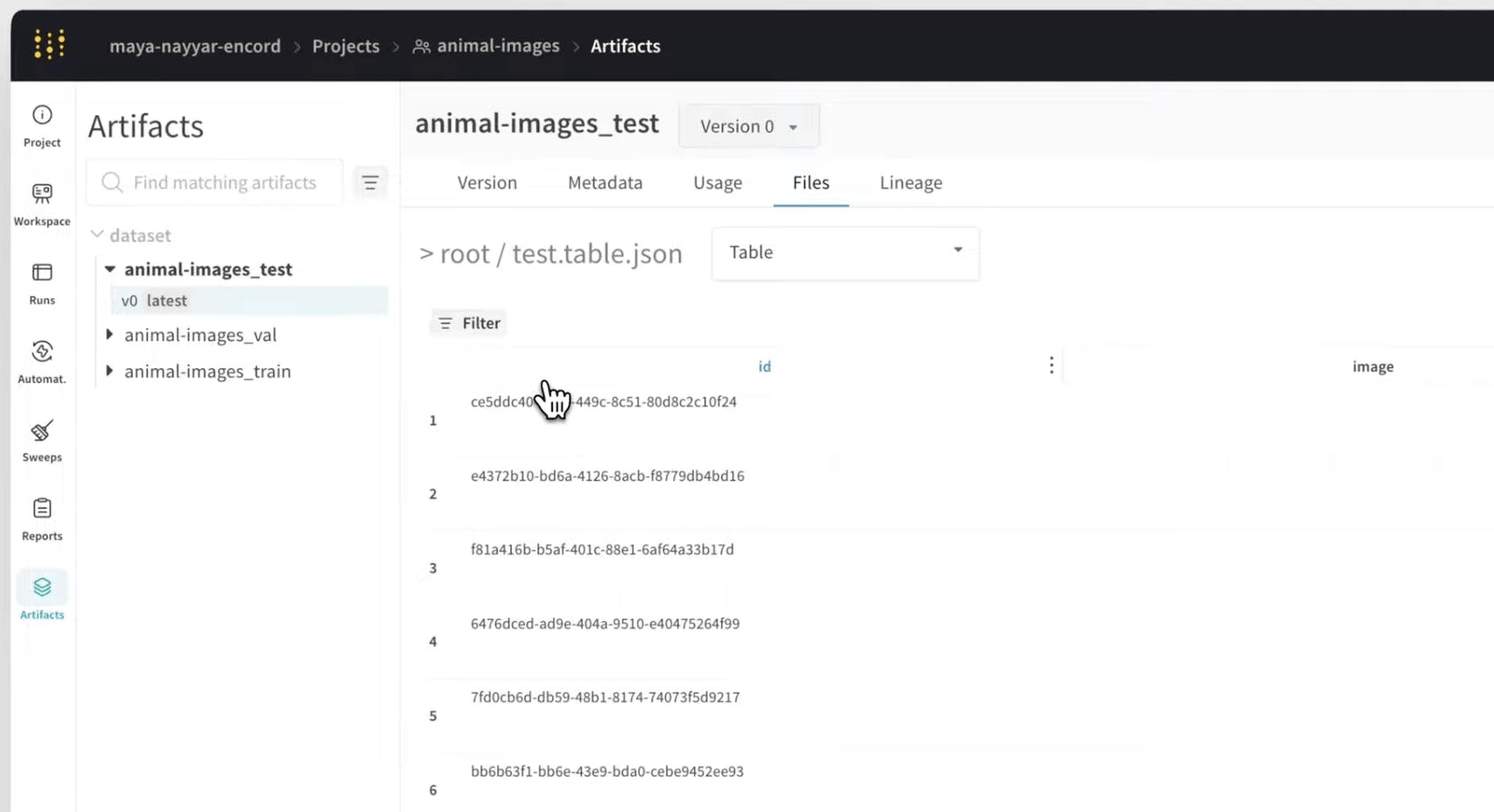
Access auto synced ground truth labels on Weights and Biases
Step-by-Step: Versioning Labeled Data Automatically
Once the integration is set up, dataset versioning happens continuously:
- Connect Encord to a Weights & Biases workspace
- Select the annotation project, with related dataset and ontology, you want to sync
- As annotations are created or edited in Encord:
- Encord packages the updated data
- Versions it automatically
- Pushes it to Weights & Biases as an Artifact
- Training pipelines point directly to those Artifacts
Benefits of Dataset Tracking with Encord + Weights & Biases
One of the biggest advantages of connecting Encord and Weights & Biases is that your models always train on the most up-to-date labels. As labels are created in Encord, they flow automatically into Weights & Biases, ensuring that every experiment reflects the current ground truth. This reduces the risk of label drift and eliminates poor iterations caused by outdated data.
Versioned datasets also bring full reproducibility to ML workflows. Each run in Weights & Biases is tied to a specific version of the labeled dataset, so audits, regressions, and comparisons become straightforward. Teams can trace a model’s performance back to the exact labels it was trained on, eliminating ambiguity and making it easier to reproduce or debug past experiments. This transparency is especially critical for regulated industries or large organizations.
By automating dataset versioning, teams can iterate on models faster. When new labels or corrections are made in Encord, they immediately become available for training runs in Weights & Biases without additional engineering effort. Data updates no longer require manual exports, transformations, or pipeline adjustments, streamlining and accelerating iteration.
Another key benefit is clear ownership across teams. With Encord handling annotation, review, and data quality, and Weights & Biases focusing on experiments, metrics, and monitoring, each tool plays to its strengths. Teams avoid duplicating work or creating ad-hoc processes, and stakeholders from data scientists to product managers can trust that data and model workflows are aligned.
Finally, this setup makes data-centric debugging practical. When model performance dips, the first question is often whether the data has changed. With versioned datasets, teams can inspect exactly which labels were used for a given run, compare different dataset versions side by side, and identify missing edge cases or inconsistencies. Fixes are made in Encord, then automatically synced back to Weights & Biases. This closes the loop between analyzing model failures and improving the underlying data, creating a more robust, iterative ML process.
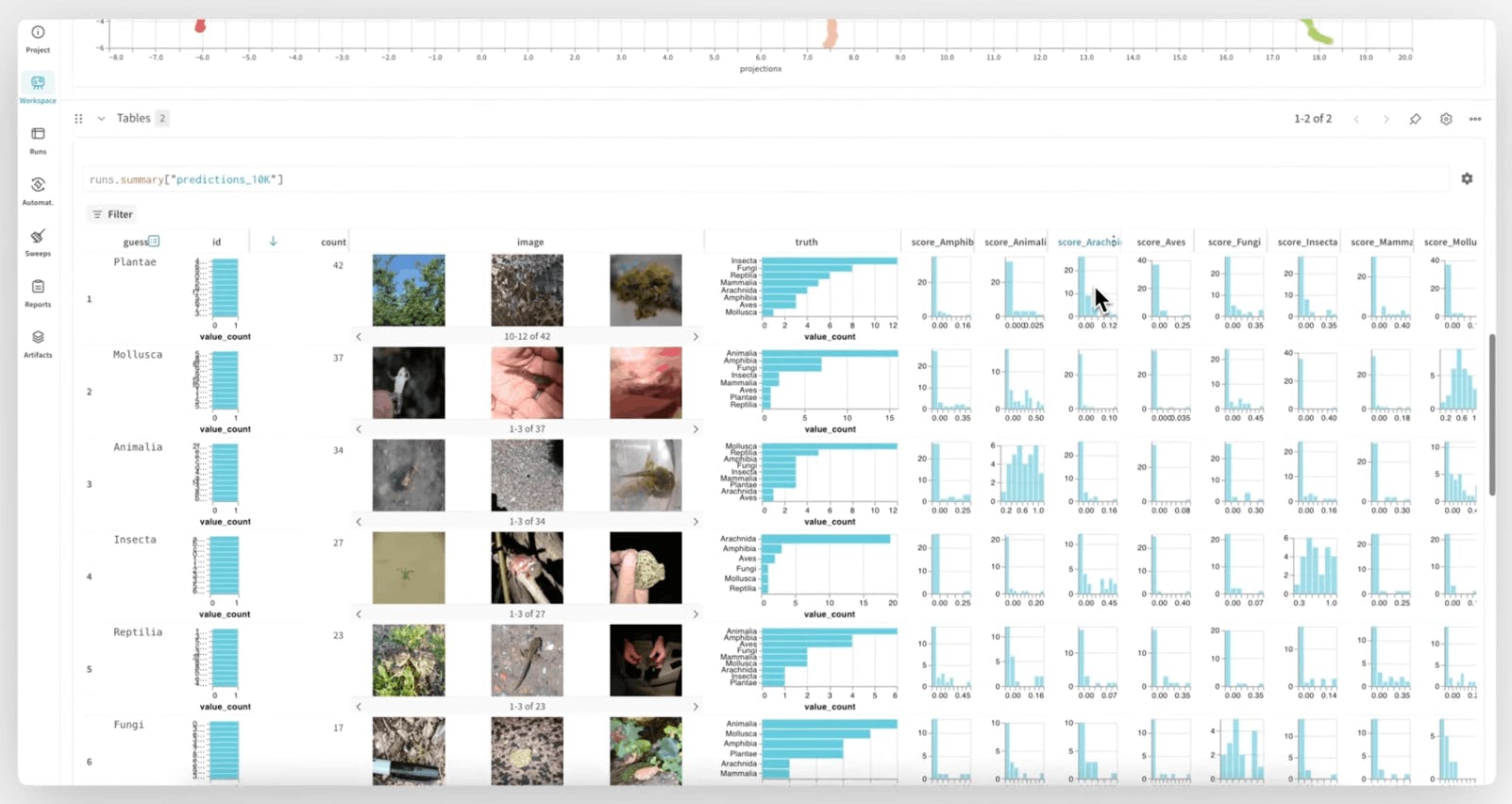
Optimise model training in Weights & Biases
Scaling ML systems demands the same rigor for data as for the models themselves.
By combining Encord for annotation and data quality with Weights & Biases for artifact tracking and experimentation, teams can:
- Eliminate manual dataset management
- Track labeled data automatically
- Reproduce results with confidence
- Iterate faster with fewer surprises