


Encord Blog
Immerse yourself in vision
Trends, Tech, and beyond

Encord Releases New Physical AI Suite with LiDAR Support
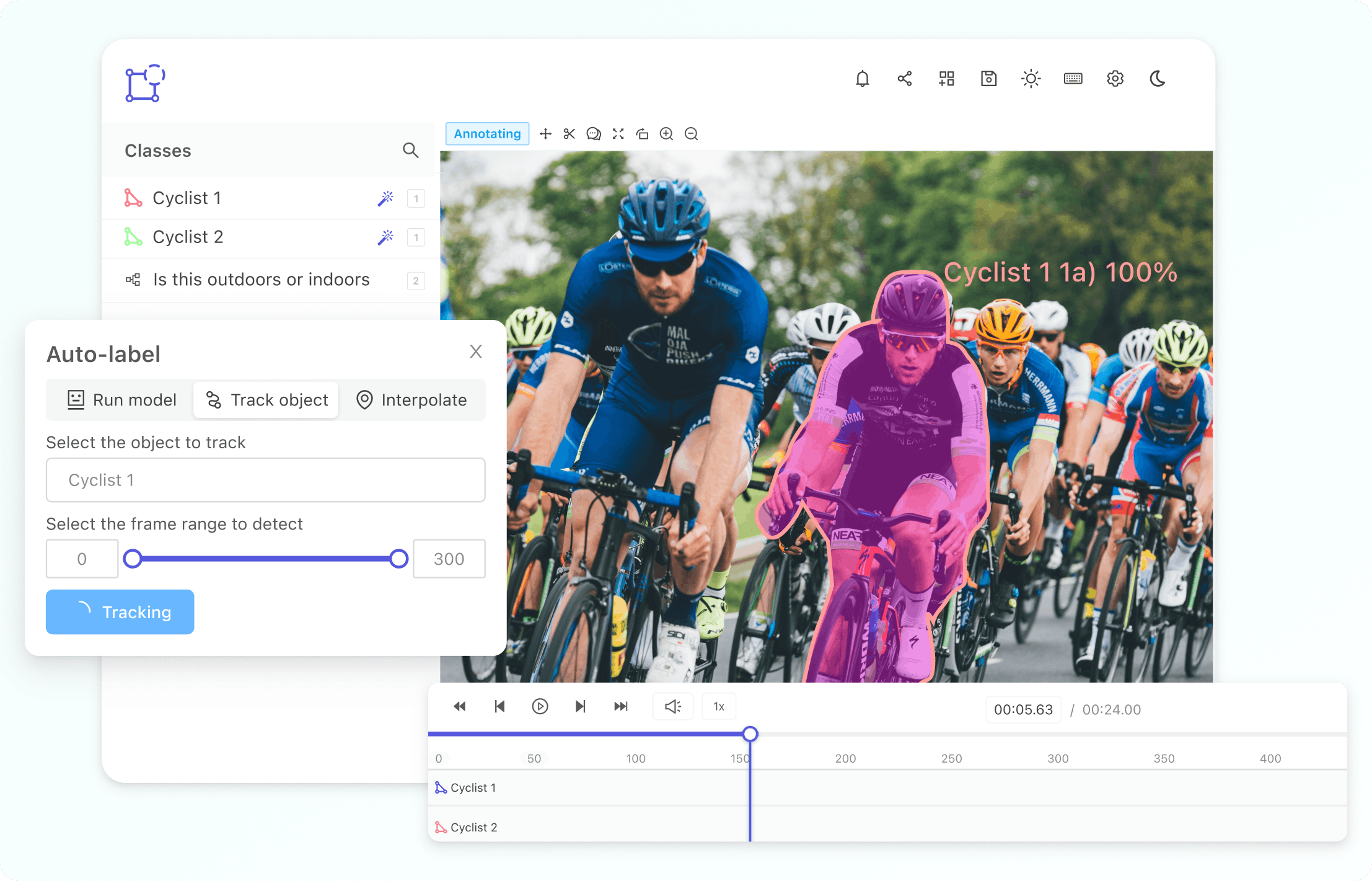
We’re excited to introduce support for 3D, LiDAR and point cloud data. With this latest release, we’ve created the first unified and scalable Physical AI suite, purpose-built for AI teams developing robotic perception, VLA, AV or ADAS systems. With Encord, you can now ingest and visualize raw sensor data (LiDAR, radar, camera, and more), annotate complex 3D and multi-sensor scenes, and identify edge-cases to improve perception systems in real-world conditions at scale. 3D data annotation with multi-sensor view in Encord Why We Built It Anyone building Physical AI systems knows it comes with its difficulties. Ingesting, organizing, searching, and visualizing massive volumes of raw data from various modalities and sensors brings challenges right from the start. Annotating data and evaluating models only compounds the problem. Encord's platform tackles these challenges by integrating critical capabilities into a single, cohesive environment. This enables development teams to accelerate the delivery of advanced autonomous capabilities with higher quality data and better insights, while also improving efficiency and reducing costs. Core Capabilities Scalable & Secure Data Ingestion: Teams can automatically and securely synchronize data from their cloud buckets straight into Encord. The platform seamlessly ingests and intelligently manages high-volume, continuous raw sensor data streams, including LiDAR point clouds, camera imagery, and diverse telemetry, as well as commonly supported industry file formats (such as MCAP). Intelligent Data Curation & Quality Control: The platform provides automated tools for initial data quality checks, cleansing, and intelligent organization. It helps teams identify critical edge cases and structure data for optimal model training, including addressing the 'long-tail' of unique scenarios that are crucial for robust autonomy. Teams can efficiently filter, batch, and select precise data segments for specific annotation and training needs. 3D data visualization and curation in Encord AI-Accelerated & Adaptable Data Labeling: The platform offers AI-assisted labeling capabilities, including automated object tracking and single-shot labeling across scenes, significantly reducing manual effort. It supports a wide array of annotation types and ensures consistent, high-precision labels across different sensor modalities and over time, even as annotation requirements evolve. Comprehensive AI Model Evaluation & Debugging: Gain deep insight into your AI model's performance and behavior. The platform provides sophisticated tools to evaluate model predictions against ground truth, pinpointing specific failure modes and identifying the exact data that led to unexpected outcomes. This capability dramatically shortens iteration cycles, allowing teams to quickly diagnose issues, refine models, and improve AI accuracy for fail-safe applications. Streamlined Workflow Management & Collaboration: Built for large-scale operations, the platform includes robust workflow management tools. Administrators can easily distribute tasks among annotators, track performance, assign QA reviews, and ensure compliance across projects. Its flexible design enables seamless integration with existing engineering tools and cloud infrastructure, optimizing operational efficiency and accelerating time-to-value. Encord offers a powerful, collaborative annotation environment tailored for Physical AI teams that need to streamline data labeling at scale. With built-in automation, real-time collaboration tools, and active learning integration, Encord enables faster iteration on perception models and more efficient dataset refinement, accelerating model development while ensuring high-quality, safety-critical outputs. Implementation Scenarios ADAS & Autonomous Vehicles: Teams building self-driving and advanced driver-assistance systems can use Encord to manage and curate massive, multi-format datasets collected across hundreds or thousands of multi-hour trips. The platform makes it easy to surface high-signal edge cases, refine annotations across 3D, video, and sensor data within complex driving scenes, and leverage automated tools like tracking and segmentation. With Encord, developers can accurately identify objects (pedestrians, obstacles, signs), validate model performance against ground truth in diverse conditions, and efficiently debug vehicle behavior. Robot Vision: Robotics teams can use Encord to build intelligent robots with advanced visual perception, enabling autonomous navigation, object detection, and manipulation in complex environments. The platform streamlines management and curation of massive, multi-sensor datasets (including 3D LiDAR, RGB-D imagery, and sensor fusion within 3D scenes), making it easy to surface edge cases and refine annotations. This helps teams improve how robots perceive and interact with their surroundings, accurately identify objects, and operate reliably in diverse, real-world conditions. Drones: Drone teams use Encord to manage and curate vast multi-sensor datasets — including 3D LiDAR point clouds (LAS), RGB, thermal, and multispectral imagery. The platform streamlines the identification of edge cases and efficient annotation across long aerial sequences, enabling robust object detection, tracking, and autonomous navigation in diverse environments and weather conditions. With Encord, teams can build and validate advanced drone applications for infrastructure inspection, precision agriculture, construction, and environmental monitoring, all while collaborating at scale and ensuring reliable performance Vision Language Action (VLA): With Encord, teams can connect physical objects to language descriptions, enabling the development of foundation models that interpret and act on complex human commands. This capability is critical for next-generation human-robot interaction, where understanding nuanced instructions is essential. For more information on Encord's Physical AI suite, click here.
Jun 12 2025
m
Trending Articles
1
The Step-by-Step Guide to Getting Your AI Models Through FDA Approval
2
Introducing: Upgraded Analytics
3
Introducing: Upgraded Project Analytics
4
18 Best Image Annotation Tools for Computer Vision [Updated 2025]
5
Top 8 Use Cases of Computer Vision in Manufacturing
6
YOLO Object Detection Explained: Evolution, Algorithm, and Applications
7
Active Learning in Machine Learning: Guide & Strategies [2025]
Explore our...
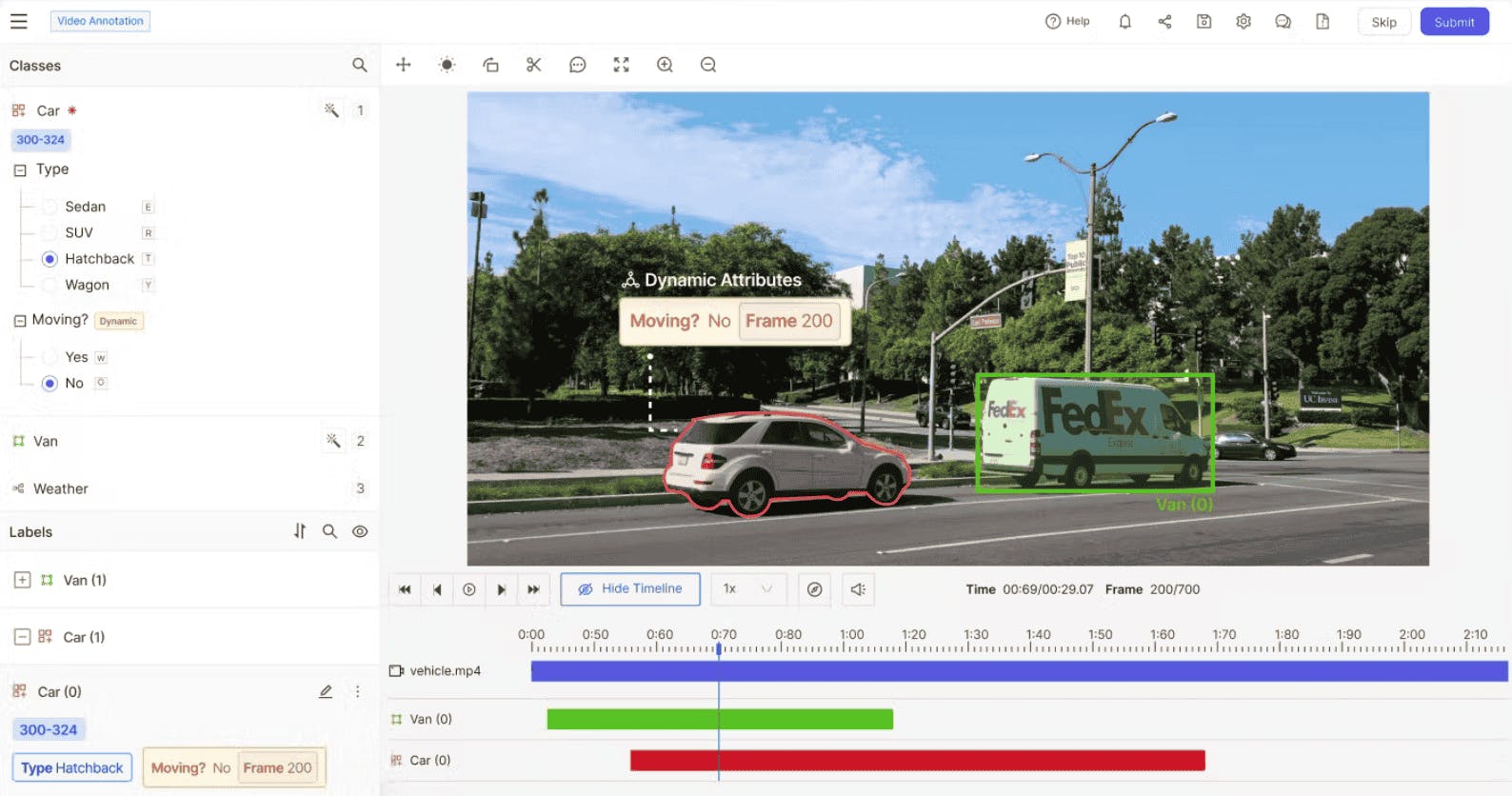
Why Encord Is the Best Choice for Video Annotation: Stop Annotating Frame by Frame
Video annotation isn’t just image annotation at scale. It’s a different challenge that traditional annotation tools cannot support. These frame-based tools weren’t designed for the complexity of video, treating video as a sequence of disconnected images. But this has a direct impact on your model performance and ROI, leading to slow, error-prone, and costly annotation. Encord changes that. Built with native video support, Encord delivers seamless, intelligent annotation workflows that scale. Whether you're working in surgical AI, robotics, or autonomous vehicles, teams choose Encord to annotate faster and at scale to build more accurate models. Keep reading to learn why teams like SDSC, Automotus, and Standard AI rely on Encord to stay ahead. The Problem with Frame-by-Frame Annotation Frame-by-frame annotation is often the case when using open-sourced or annotation tooling that is not video native. These tools break videos down into frames, leaving each frame to be annotated as individual images. However, this has negative consequences on the AI data pipeline. First, it can cause a fragmented workflow. Annotators must work on individual images, losing temporal continuity. Plus, object tracking becomes manual and tedious as each video yields many frames. There is also a higher risk of inconsistency across annotations. This is because when annotating by frame, some frames may be missed due to volume and the level of detail needed. Inconsistent annotations across frames can also arise when proper context is missing. For example, bounding box drift can take place when each bounding box is drawn independently. Objects are likely to change shape and size between the start and end of a video and with manual annotation, boxes may shift, lag behind, or fluctuate. Additionally, a lack of temporal awareness leads to quality degradation. When annotators are not able to understand the relationship between frames over time, this leads to bounding box drift, noisy labels, extra QA effort and most detrimentally, poor model performance. Finally, it can lead to increased time spent and cost incurred. Frame-by-frame annotation is more labor-intensive for both annotators and reviewers, as each video produces thousands of frames. Instead, repeated tasks could be automated with video-native tools. What Makes Encord Different for Video Annotation However, using a video native platform, like Encord, directly mitigates these challenges. A tool that has native video support allows for keyframe interpolation, timeline navigation, and real-time preview. All of which drive greater efficiency and accuracy for developing AI at scale. Built natively for video annotation Within Encord, video is rendered natively, allowing users to annotate and navigate across a timeline. Annotators can directly annotate on full-length videos, not broken up frames. This not only saves time but also mitigates the risk of missed frames and bounding box drift. Video annotation within the platform also supports playback with object persistence across time. And to further improve efficiency across the AI data pipeline, Encord’s real-time collaboration tools can be used on entire video sequences. Advanced object tracking & automation Encord also offers AI-assisted tracking to automatically follow objects through frames once it has been labeled in a single or keyframe. Encord uses SAM2 to predict the place of the bounding box across subsequent frames. This supports re-identification even when objects temporarily disappear (ex: occlusion). This reduces the time spent redrawing objects in each frame and helps maintain temporal consistency. The platform also features interpolation, model-assisted labeling, and active learning. Interpolation is a semi-automated method where the annotator marks an object at key points, and the platform fills in the labels between them by calculating smooth transitions. This leads to massive timesavings and avoids annotator fatigue, without losing accuracy. Additionally, the active learning integration uses a feedback loop that selects frames for human annotation. Encord Active flags frames or video segments where model predictions are low-confidence. Annotators are guided to prioritize these clips. And finally, the model learns from informative samples, not redundant ones. Maintain temporal context Temporal context is critical for accurate video annotation as it relates to how objects and scenes change over time. With temporal labeling built into the UI, users can annotate events, transitions or behaviors, such a person running or car breaking. In Encord, annotators can view and annotate frames in relation to previous and future ones. With this timeline navigation and visualisation, users can view object annotations over a video’s entire duration. This provides more context on where an object appears or changes and it is helpful for labeling intermittent objects. Additionally, this view helps track label persistence across frames, rather than labels that are created per frame. This reduces redundant work and supports smooth object tracking, and avoids annotation drift. Finally, annotators and reviewers can play the full annotated video back to verify consistency across frames. Why Other Platforms Fall Short Summary: Traditional platforms were designed for image annotation and retrofitted for video. Encord was purpose-built for video. The ROI of Using Encord for Video Annotation Seamless, efficient, and intelligent video annotation workflows drive both direct ROI and model accuracy. The investment in a video native annotation tool pays off through: speed, accuracy, and scalability. Faster training & deployment As the platform supports smart interpolation, auto-generated labels, and label persistence across a video timeline, it reduces annotation time significantly. What does this mean for ROI? Faster training data pipelines means faster model development and time to market. By switching to Encord’s video-native platform, the Surgical Data Science Collective (SDSC) accelerated their annotation workflows by 10x while improving precision and reducing error rates from 20% to nearly zero. Encord’s seamless video rendering, Python SDK integration, and automated quality control features like object tracking and label error detection allowed SDSC to annotate complex surgical procedures at scale. Increased model accuracy Frame sync video annotation leads to better data quality through contextual, consistent annotation. This is because no frames are missed with automated video labeling. Additionally, contextual, timeline-based annotation ensures that intermittent objects are detected accurately, such as those that come in and out of the video. Plus, the more accurate the initial annotations are, the fewer QA cycles and rework. Using Encord’s intelligent visual data curation tools, Automotus was able to reduce its dataset size by 25% while increasing model performance by 20%. Encord’s platform enabled Automotus to localize objects more accurately, iterate faster, and optimize performance. Greater ability to scale production Scale is what ensures you dominate the market and competition. With the ability to annotate thousands of video files with collaborative tools, templates, and automation, scaling becomes a simple next step. However, scaling also requires a larger, more in-sync team. Which is why support for multi-user teams, audit trails, and version control are all key features. With Encord, Standard AI transformed its ability to scale video annotation across millions of files, cutting project kick-off times by 99.4%, accelerating video processing by 5x, and saving over $600K annually. By unifying data curation, annotation, and evaluation into a single platform with robust API and SDK support, Standard AI empowered its entire team to collaborate seamlessly and iterate rapidly, leading to production-grade retail intelligence at scale. Key Takewaways Video annotation is not easily scalable using traditional or open-source data annotation tools. The key reason is they break videos into frames, which require tedious, mistake-prone frame-by-frame annotation. However, for deploying precise computer vision models at scale, using a video native platform is key. Encord supports keyframe interpolation, timeline navigation, and real-time preview which drive greater efficiency, accuracy, and ultimately ROI. Encord supports smart interpolation, auto-generated labels, and label persistence, reducing annotation time significantly. Faster training data pipelines means faster model development and time to market. And with frame sync and automated video labeling, higher quality training data can be accelerated without comprising accuracy or model performance. Make the switch to a platform that actually understands video and is built to scale. Book a demo.
Jul 18 2025
5 M
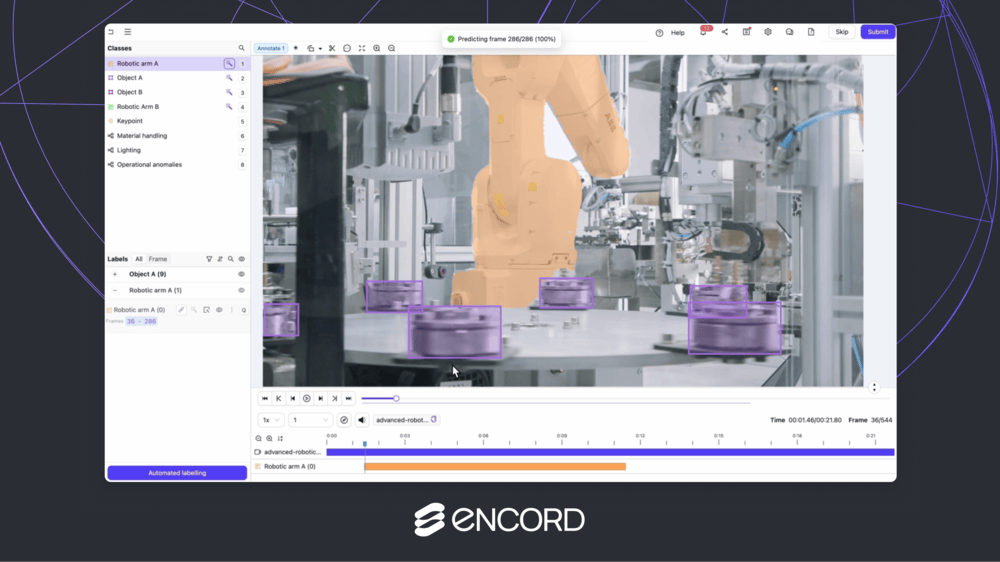
Encord as a Step Up from CVAT + Voxel51: Why Teams Are Making the Switch
When building computer vision models, many machine learning and data ops teams rely on a combination of open-source tools like CVAT and FiftyOne (Voxel51) to manage annotation and data curation. While this setup can work for small-scale projects, it quickly breaks down at scale, creating friction and inefficiencies. CVAT handles manual annotation, while Voxel51 mainly powers dataset visualization and filtering. However, neither tool spans the full AI data development lifecycle, leading to fragmented workflows. As complexity increases, particularly with video, LiDAR, or multimodal data, so do the limitations. In this article, we’ll explore the standard CVAT + Voxel51 workflow, highlight the key bottlenecks teams encounter, and explain why many AI teams are making the switch to Encord — a unified platform designed for scalable, secure, and high-performance data development. Typical Existing Workflow Stack: CVAT + Voxel51 CVAT and V51 make up different parts of the AI data development pipeline – annotation and visualization. Both of these are key drivers of successful AI development so let’s understand how these two tools play a role to support these processes. In large scale AI pipelines, before data can be annotated, it needs to be curated. This includes visualising the data and filtering it in order to exclude outliers, get a deeper understanding of the type of data being worked with, or organising it into relevant segments depending on the project at hand. V51 supports this element of the workflow stack by providing interactive dataset exploration, using filters or similarity search. However, it only supports lightweight image labeling capabilities, with very limited automation. Which leads us to the next part of the AI data workflow. CVAT is used for manual image annotation, such as creating bounding boxes and doing segmentation on visual data. The tool supports a range of annotation types, such as bounding boxes, polygons, polylines, keypoints, and more. It allows for frame-by-frame annotation, tracking, and managing large datasets. However, it does not support frame-based video annotation and only has basic timeline navigation, as it does not natively work with video. However, since neither of these two tools are built to span the entire AI data pipeline, they need to be chained together. Outlining what this stack would look like, raw data would be visualised in Voxel51, to gain deeper understanding of distributions and edge cases. Then it would be loaded into CVAT for annotation. However then the data would need to be re-imported into V51 to evaluate annotation quality. The challenge with this workflow is that it is fragmented. One tool handles curation while the other handles annotation. However, the data then has to be moved between platforms. This can lead to inefficiencies within the data pipeline, especially when developing models at scale or iterating quickly. Additionally, this fragmentation means there is no unified review workflow. Once a model is evaluated, the data then has to be handed off between tools, hindering accuracy improvements at scale. This could mean there is little clarity on version control as there is no central history or audit trail. The CVAT plus V51 workflow is also at the mercy of both tools’ generally sluggish UI. For example, 3D and video are not natively supported and other modalities like audio and text are lacking. Additionally, for industries with high data security standards, because CVAT and V51 are open source, they are not SOC2 compliant and the lack of traceability can pose risks for those dealing with sensitive data. Why Teams Should Choose Encord TL;DR – Top 3 Reasons to Switch: Stop wasting time gluing tools together — unify your stack. Handle video, LiDAR, and multimodal data natively. Scale securely with built-in governance, QA, and automation. Here are the main reasons ML and data ops teams switch from CVAT + FiftyOne to Encord, based on customers we have engaged with: Unify their AI data pipeline Encord serves as the universal data layer for AI teams, covering the entire data pipeline, from curation and annotation to QA and active learning. This eliminates the need to glue together CVAT, V51, and others. With the CVAT plus V51 stack, an additional tool would also need to be used for model evaluation. By unifying their data pipelines, AI teams have been able to achieve faster iteration, less DevOps overhead, and fewer integration failures. For example, Plainsight Technologies, an enterprise vision data company, dramatically reduced the cost and complexity of AI-powered computer vision across many verticals and enterprise use cases, including manufacturing, retail, food service, theft, and more. Native video support For complex use cases that require native video annotation, such as physical AI, autonomous vehicles, and logistics, native video support is key. Encord is built for annotating video directly rather than breaking it into frames that have to be annotated individually. When videos are annotated at the frame level, as if they were a collection of images, there is greater risk of error as frames can be missed. A tool that has native video support allows for keyframe interpolation, timeline navigation, and real-time preview. All of which drive greater efficiency and accuracy for developing AI at scale. Additionally, support for long-form videos (up to 2 hours, 200k+ frames) means that thousands of hours of footage can be annotated. This is often the case for physical AI training. Built-In active learning and labeling Traditional annotation workflows (like CVAT + Voxel51) are heavily manual. Encord, however, provides native active learning and automated pre-labeling for feedback-driven workflows. Instead of labeling every piece of data, Encord helps you prioritize the most high-impact data to label. You can intelligently sample based on embedding similarity, performance metrics, etc. Model integration in Encord allows users to plug in their own models to automate labeling and integrate predictions directly into the annotation workflow. These predictions can be used as initial pre-labels, which annotators only need to verify or correct, dramatically reducing time spent on repetitive tasks. Using pre-labeling to annotate large datasets automatically, then route those to human reviewers for validation reduces manual effort. It also allows for targeting the most impactful data, teams using Encord can reduce annotation costs, speed up model training cycles and increase annotation throughput. Scales with business needs Because Encord is an end to end data platform, data pipelines can scale with business needs and volumes of data. When it comes to increasing volumes of data, it supports millions of images and frames and up to 5M+ labels/project, whereas CVAT supports 250K - 500K. As a dataset grows, many tools (like CVAT or other open-source platforms) begin to lag, freeze, or break entirely. For example, teams risk the UI taking seconds (or minutes) to load a single frame or even crash during long video sessions or when using complex ontologies. However, Encord is purpose-built to handle large-scale datasets efficiently; it also has fast API calls for programmatic access (Python SDK, integrations) that return quickly even when querying huge data volumes. Therefore, your annotators don’t lose time waiting for images or tools to load. And, developers and MLOps teams can run queries or updates programmatically without performance bottlenecks Finally, faster iteration loops mean quicker time to model improvements. A key feature of Encord that allows for scaling model development is that it allows for 100+ annotators working concurrently, without degrading performance. At the same time, model training can run in parallel, leveraging continuously labeled data to update models faster. To keep teams organized and efficient, Encord includes workflow management tools like task assignment, progress tracking, built-in reviewer roles, and automated QA routing, making it easy to manage large, distributed labeling teams without losing oversight or quality control. Comparing CVAT, Voxel 51 & Encord for scaling data development: SOC2-Compliant with Full Traceability CVAT and FiftyOne are powerful tools, but they are not built for enterprise data governance or QA at scale. For example, they lack reviewer approval flows. CVAT, for instance, doesn’t have a built-in way to assign reviewers, approve/reject annotations, or track review status. However, this is key in enterprise settings to ensure high-quality outputs for downstream ML models. Without this, QA is manual, ad hoc, and hard to scale. Additionally, open-source tools aren’t SOC2 compliant and lack enterprise-grade security features. SOC2 is a rigorous standard for data handling, access controls and audit logging. It is essential for ML teams working with regulated data (e.g. healthcare, finance, defense). Therefore, teams might choose to switch to Encord for role-based access controls, SSO integration and SOC2 compliance when working in specific industries. Multimodal & 3D native support When it comes to AI development, multimodal capabilities are crucial across a number of different use cases. For example, in surgical video applications, data is required across video, image and documents for maximum context on not only surgery but also the patient’s medical history. For teams requiring 3D, video or other modalities, a platform that can support multiple allows for more accurate and streamlined workflows. Businesses with complex use cases also require a platform that can handle multi-camera, multi-sensor projects (e.g. LiDAR + RGB). Multiple angles can also be annotated within one frame, providing annotators with additional context without having to switch between tabs to improve efficiency. For example, Archetype’s Newton model uses deep multimodal sensor fusion to deliver rich, accurate insights across industries — from predictive maintenance to human behavior understanding. Using Encord, Archetype achieved a 70% increase in overall productivity. Most significantly, annotation speed has doubled, allowing the team to work far more efficiently than with previous tooling. QA, Review, and Annotation Analytics When it comes to scaling AI data pipelines, having more annotators is step one. However, this requires management and QA, especially if annotation is outsourced. Having built-in review workflows ensures that annotations are correct, especially in cases where annotators need industry-specific knowledge to label successfully. Not only can users build review workflows in Encord but these workflows can be automated using agents. Reviewers can be assigned to certain tasks and leaders can assess annotators’ work through the analytics dashboard. Additionally, label accuracy metrics and consensus scoring are built in, flagging low-consensus annotations for QA. Resolution of discrepancies happen directly in the platform, allowing for quick iteration and maximum accuracy. Most open-source tools like CVAT don’t offer this – you have to build it yourself with scripts or custom QA layers. Encord gives you this out of the box, making quality management and scale possible without reinventing infrastructure. Faster Onboarding and Migration Encord supports direct imports from the most common open-source formats, so teams can migrate quickly without re-labeling or writing custom scripts. This includes but is not limited to: CVAT (XML, JSON) and COCO (JSON). You can upload your existing labels as-is, and Encord will automatically convert them into the internal format with matching ontology and label structure. There is also no need to write scripts or use third-party conversion tools as Encord includes a visual ontology mapping tool (to match your old classes to the new schema) as well as annotation converters that handle anything from bounding boxes to 3D cuboids. It also supports multi-class, multi-object, and nested hierarchies. For example, if you’ve labeled images in YOLO format, you can import that straight into Encord, and continue working immediately. Another key reason using Encord beats the CVAT plus Voxel 51 stack is that it offers dedicated onboarding support (especially for mid-size and enterprise customers) and hands-on help to migrate your data. This reduces friction and helps your team become productive within days. Key Takeaway The combination of CVAT and Voxel51 has served many ML teams well for early-stage experimentation, but it comes with trade-offs: disconnected workflows, limited scalability, and manual QA overhead. As teams grow and use cases become more complex, particularly involving video, 3D, or multi-sensor data, this stack hinders scaling. Encord offers a step-change improvement by unifying annotation, curation, review, and automation in one secure platform, removing the need to use multiple tools, write custom scripts, or manually manage QA processes. Teams switching to Encord can achieve 10–100x improvements in throughput, better model iteration speed, and far less operational complexity. If you're hitting the ceiling of open-source tooling and need an AI data platform that can scale, it's time to consider a switch. Curious how Encord compares for your current stack? Book a demo.
Jul 15 2025
5 M
AI Annotation Platforms with the Best Data Curation (2025)
This guide to AI Annotation Platforms with the Best Data Curation presents the top AI data curation platforms, breaking down their key features and best usage. Machine learning engineers and data practitioners spend most of their time sorting out unstructured data. And after all their effort, they end up with data full of mistakes. But with the help of AI annotation platforms, engineers can train SuperData to produce high-quality, error-free data faster with less manual labor. Why are AI annotation platforms needed for developing AI models? In easy terms, data annotation helps ML algorithms understand your commands. AI annotation platforms train your AI models with clear and accurate data. Since AI can process properly labeled data more efficiently, this leads to increased operational efficiency and reduced costs. It is hard for AI programs to separate one set of data from another. Let's say you fed your ML model with thousands of images of pencils. But that is not enough. You have to label the data (the images), showing which parts of the photos contain the pencils. This helps AI identify how pencils look. If you label the images as 'pens', not 'pencils,' your model will identify those pencils as pens. This is how labeling audio, text, video, images, and all sorts of data can help train AI models. Image 1 - Master Data Annotation in LLMs: A Key to Smarter and Powerful AI! AI annotation platforms prevent the risks of models underperforming or producing biased results. Moreover, curating data with AI platforms helps engineers reduce their manual effort and train AI faster. AI annotation platforms help label data, allowing algorithms to understand and differentiate data accurately What to Look for in a Data Annotation Platform? To select the best AI data annotation platforms, consider these seven key elements. Prioritization Automation: The AI data curation platform should be able to automate the data prioritization tasks, including filtering, sorting, and selecting the most valuable and relevant data from large datasets. It should also offer automation tools (e.g., SAM, GPT-4o) to speed up annotation. Customizable Visualization: The AI should offer customizable visualization in the form of tables, plots, and images. This helps you spot biases, edge cases, and outliers by visualizing data. Model-Assisted Debugging: Look for model-assisted debugging features like confusion matrics. Debugging features help you spot errors like false positives and negatives. Multiple Modality: Look for platforms that can handle various data types and annotation formats, such as text, medical imaging formats, videos, bounding boxes, segmentation, polylines, and key points. User-friendly interface: The platform’s interface should be a simple and configurable UI that is easy to navigate, even for non-technical users. It should also help you design automated workflows and integrate with necessary platforms. Streamlined Workflows: The tool should let you create, edit, and manage labels and annotations. Additionally, it should let you integrate into machine learning pipelines and storage systems like cloud storage, MLOps tools, and APIs. Team Collaboration: Look for features that allow team members to collaborate and share feedback on data curation projects. Modern image labeling tools are essential for building high-quality AI training datasets. They offer advanced annotation features, AI-assisted automation, and robust quality control to efficiently handle large and complex datasets. Top AI Annotation Platforms for Best Data Curation Here are the top 8 data annotation platforms for efficiently and effectively curating data. Encord Image 2 - Encord Encord is a unified, multimodal data platform designed for scalable annotation, curation, and model evaluation. It lets you index, label, and curate petabytes of data. Image 3 - Multimodal Data Annotation Tool & Curation Platform | Encord It supports images, video, text, audio, and DICOM, making it ideal for teams working across computer vision, NLP, and medical AI. Encord also supports various integrations to connect your cloud storage, infrastructure, and MLOps tools. You can even find useful model evaluation tools inside Encord. Special Features Human-in-the-loop labeling use cases Natural language search AI-assisted labeling (SAM-2, GPT-4o, Whisper) Rubric based evolution Seamless cloud integration (AWS, Azure, GCP) Label editor SOC2, HIPAA, and GDPR compliance According to G2: 4.8 out of 5. Most reviewers gave Encord a positive rating for its robust annotation capabilities and ease of use. Some users also praised Encord's collaboration and communication tools. Best for: Generating multimodal labels at scale and curating data with enterprise-grade security. Labellerr Image 4 - Labellerr Labellerr is an AI-powered data labeling platform offering a comprehensive suite for annotating images, videos, text, and more. Its customizable workflows, automation tools, and advanced analytics enable teams to produce high-quality labels at scale rapidly. Labellerr supports collaborative annotation, robust quality control, and seamless integration with popular machine learning frameworks and cloud services. Special Features Automated and model-assisted labeling Customizable annotation workflows and task management Quality assurance with review and feedback loops Collaboration tools for teams and vendors Version control and centralized guideline management Multi-format and multi-data-type support (images, video, text, audio) Real-time analytics and performance dashboards Secure, enterprise-grade deployment According to G2: 4.8 out of 5. Labellerr is highly rated for its ease of use, efficiency, and strong customer support. Users highlight its ability to handle complex projects and automation that reduces manual effort, though some mention occasional performance lags with large files and a desire for improved documentation. Best for: Enterprises and teams needing scalable, collaborative, and automated annotation workflows across diverse data types. 3. Lightly Image 5 - Lightly AI Lightly is a data curation platform designed to optimize machine learning workflows by intelligently selecting the most relevant and diverse data for annotation. Rather than focusing on manual annotation, Lightly uses advanced active learning and self-supervised algorithms to minimize redundant labeling and maximize model performance. Its seamless integration with cloud storage and annotation tools streamlines the entire data pipeline, from raw collection to training-ready datasets and edge deployment. Special Features Smart data selection using active and self-supervised learning Automated data curation for large-scale datasets Integration with existing annotation tools and cloud storage API for workflow automation Data distribution and bias analysis Secure, on-premise or cloud deployment options According to G2: 4.4 out of 5. Users praise Lightly for its intuitive interface, time-saving automation, and ability to reduce labeling costs and effort significantly. Some reviews note a learning curve for advanced features and desire more onboarding resources. Best for: Teams seeking to optimize annotation efficiency, reduce redundant labeling, and accelerate model development, especially for large, complex visual datasets. 4. Keylabs Image 7 - Keylabs Keylabs is an advanced annotation tool and operational management capability that prepares visual data for machine learning. The platform meets the needs of various industries, including aerial, automotive, agriculture, and healthcare. It presents a range of annotation types, including cuboids, bounding boxes, segmentations, lines, multi-lines, named points, and skeleton meshes. Special Features ML-assisted data annotation It can be installed anywhere User roles and permission flexibility Project management Workforce analytics According to G2: 4.8 out of 5. Many users love Keylabs for its unlimited video annotation length, unmatched quality control, and customization capabilities. However, some might find the lack of natural language processing limiting. Best for: Companies looking for a tool for annotating images and videos with higher quality control. 5. CVAT Image 7 - CVAT CVAT helps you annotate images, videos, and 3D files for a range of industries, including drones and aerial, manufacturing, and healthcare and medicine. It supports diverse annotation types such as bounding boxes, polygons, key points, and cuboids, enabling precise labeling for complex computer vision tasks. With AI-assisted features like automatic annotation and interpolation, CVAT significantly speeds up the labeling process while supporting collaborative workflows and integration with popular machine-learning pipelines. Special Features Image Classification Object Detection Semantic and Instance Segmentation Point Clouds / LIDAR 3D Cuboids Video Annotation Skeleton Auto-Annotation Algorithmic Assistance Management & Analytics According to G2: 4.6 out of 5. According to reviewers, it's an easy-to-use AI data annotation tool with many annotation options. However, some felt that the learning curve can be time-consuming. Best for: Training computer vision algorithms. 6. Dataloop Image 8 - Dataloop Dataloop helps you collaborate with other data practitioners and build AI solutions. Here, you will find a large marketplace of models, datasets, ready-made workflow templates, etc. It supports multimodal data annotation, including images, video, audio, text, and LiDAR, and can be integrated with other data tools and cloud platforms. You can also train, evaluate, and deploy ML models. Image 9 - Data Annotation | Dataloop Special Features API call for pipeline design Complete control over data pipelines Marketplace with hundreds of pre-created nodes Real-time human feedback Industry-standard privacy and security According to G2: 4.4 out of 5. Reviewers find this tool highly versatile and scalable, supporting various annotation types. However, some are dissatisfied with its steep learning curve and fewer customization options. Best for: Building AI solutions with easy-to-use and versatile features. 7. Roboflow Image 10 - Roboflow Roboflow lets you build pipelines, curate and label data. Also, train, evaluate, and deploy your computer vision applications. Roboflow Annotate offers an AI-powered image annotation that accelerates labeling with tools like Auto Label and supports various annotation types. It offers seamless collaboration and integrates with Roboflow’s Internal systems, Edge and Cloud Deployment, and Training Frameworks. Special Features Industry-standard open-source libraries Countless industry use cases Enterprise-grade infrastructure and compliance According to G2: 4.8 out of 5. Many reviewers prefer Roboflow for its outstanding UI and customer service. One reviewer stated that the box prompting features have become outdated. Best for: Building computer vision applications using a free, open-source platform. 8. Segments.ai Segments.ai is a multi-sensor data annotation platform that allows simultaneous labeling of 2D images and 3D point clouds, improving dataset quality and efficiency. It offers advanced features like synced tracking IDs, batch mode for labeling dynamic objects, and merged point cloud views for precise annotation of static scenes. With machine learning-assisted tools and customizable workflows, Segments.ai helps teams accelerate labeling while maintaining high accuracy across robotics and autonomous vehicle applications. Special Features 1 click multi-sensor labeling Fuse information from multiple sensors Real-time interpolation ML-powered object tracking Simple object overview Dynamic objects labeling with Batch Mode Auto-labeling with ML models According to G2: 4.6 out of 5. Reviewers positively rated Segments.ai for having many segmentation annotation features. However, some say that finding the multi-sensory annotation requires a bit of a learning curve. Best for: Enterprises wanting faster multi-sensor labeling features. Final Thoughts: Which Data Curation Platform Should You Choose? Choosing the right data curation platform depends on your team’s size, industry, and specific needs. While the mentioned tools offer solid annotation and curation features, basic platforms no longer meet the demands of today’s complex AI projects. So, when your projects demand scalability, top-tier data quality, and seamless collaboration, especially for high-stakes AI applications, Encord outperforms the rest. Its purpose-built platform combines advanced automation, multimodal support, and enterprise-grade security to accelerate workflows without compromising accuracy. Ready to elevate your AI projects with the most scalable and secure data curation platform? Discover how Encord can accelerate your annotation workflows and boost model accuracy today.
Jul 14 2025
5 M
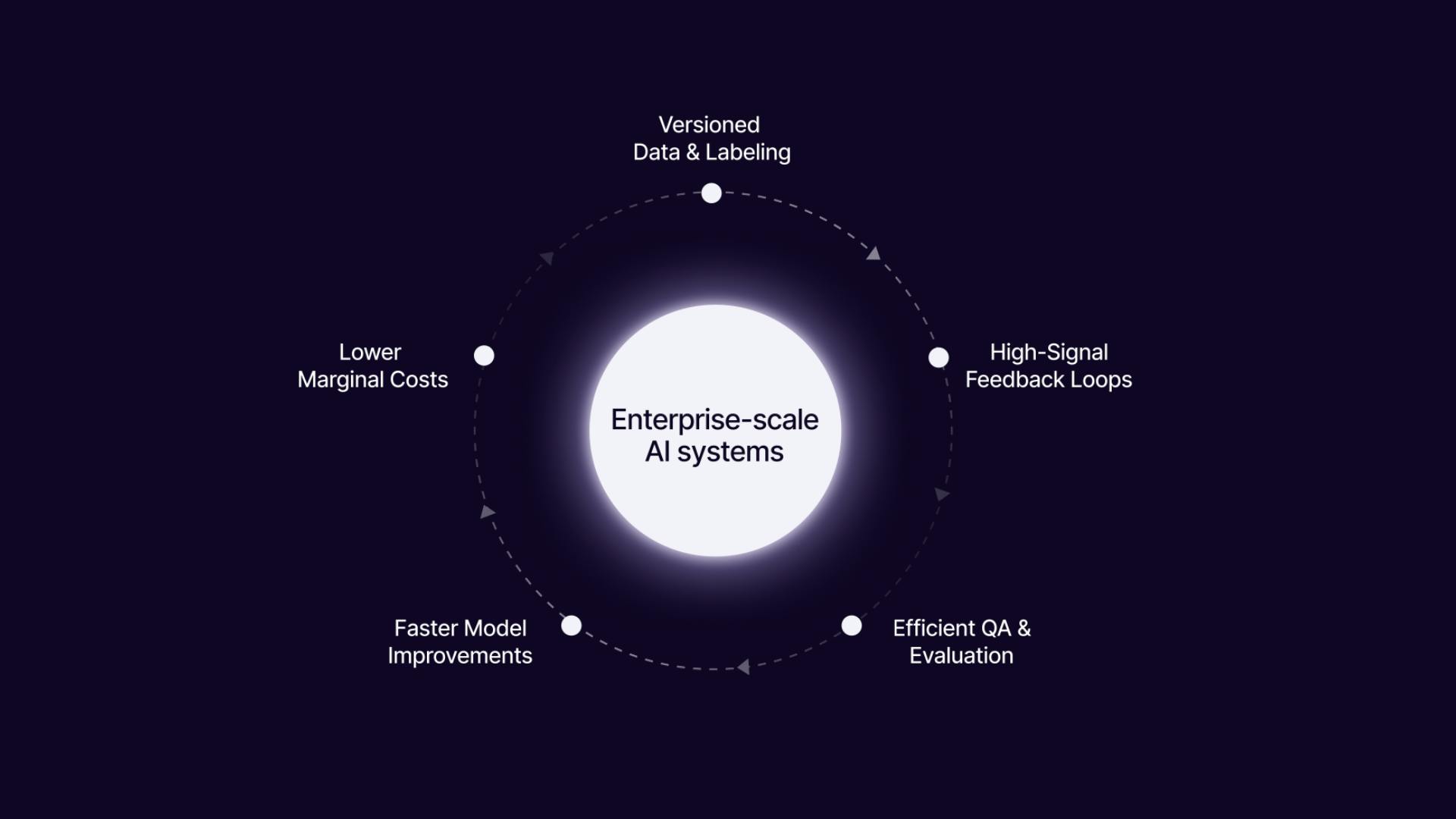
Why Your AI Data Infrastructure Is the Real Competitive Advantage
Introduction: The Hidden Edge in the AI Race This guide to AI data infrastructure breaks down why it’s the real competitive advantage for your AI initiatives, showing how strong pipelines, automation, and feedback loops drive speed, accuracy, and cost efficiency. Artificial intelligence (AI) and machine learning innovation now rely more on data infrastructure than just building smarter models. Leading tech companies like Microsoft, Amazon, Alphabet, and Meta are investing in AI infrastructure. Total capital expansion is projected to grow from $253 billion in 2024 to $1.7 trillion by 2035. That investment signals the actual value is in scalable, performant, and secure data foundations. A MIT Sloan Management Review study found that organizations with high-quality data are three times more likely to gain significant benefits from AI. Managing your AI data infrastructure well and deploying AI with ready AI datasets takes you far beyond your peers in terms of speed, cost, and AI-driven decision-making accuracy. In this article, we will discuss why your AI data infrastructure matters more than model tweaks and how it drives scalability and operational efficiency. We will also go over how feeding enriched data back-to-back into training through feedback loops accelerates model improvements, as well as how infrastructure investments reduce costs and time-to-market. Why Data Ops Is Not Just a Cost—It’s a Strategic Asset An effective way to improve data infrastructure is by adopting DataOps. DataOps is a set of agile, DevOps-inspired practices that streamline end-to-end data workflows, from ingestion to insights. Many leaders view data operations as a sunk cost or a side project to support AI models. This perspective limits their AI strategy. In reality, Data Ops is a strategic asset that drives competitive advantage across your AI initiatives. Treating data like code transforms how teams develop AI systems. When you adopt data-as-code principles, your workflows become: Modular: Data pipelines and workflows are broken down into clear, manageable components. This way, you can swap pipelines or models without having to rebuild your system. Versioned: Just as software engineers version their code, dataset versioning allows you to track changes and maintain full audit trails. Additionally, it helps compare model performance across iterations. Tools like DVC (Data Version Control) enforce version tracking for datasets, just like Git for code. Reusable: Once you codify a pipeline, you can reuse it in AI projects. This reduces duplication of effort and speeds up deployment. The Winning Loop Explained Successful AI initiatives rely on a winning loop that few competitors can replicate. This loop turns data operations from a support function into a strategic growth engine. Here are the loop steps: Capture Live Signals from Real-World Usage Real-world usage generates immediate insights like clicks, transactions, chat logs, and sensor readings. Capture these live signals in real time to align models with actual user behavior. Triage and Enrich Data with Human- and Model-in-the-Loop Workflows Raw captured data is rarely perfect. The data pipeline can use automation features present in tools like Encord. Its active filtering functionality can help filter out, categorize, and pre-process extensive datasets. In addition, human-in-the-loop (HITL) and model-in-the-loop (MITL) workflows further refine this data for quality. Humans resolve edge cases, ambiguities, and context-specific labels, while AI tools streamline scalable enrichment and annotation tasks. This combined approach optimizes data quality while controlling costs. Feed Data Back into Training, Fine-Tuning, and Evaluation Once data is cleaned and enriched, it flows into versioned pipelines for training, fine-tuning, and automated evaluation. DataOps enforces Continuous Integration and Continuous Delivery (CI/CD) for data, automated tests, schema validation, and real-time Quality Assurance (QA) before the data enters production. Fig 1. Continuous Feedback Loop Drives Competitive Advantage Pro Insight: Teams running this loop continuously build compounding value. They don’t just rely on new algorithms to drive results. Instead, their AI systems evolve daily with fresh, relevant data. Meanwhile, competitors who focus only on tweaking models face diminishing returns without a strong data infrastructure to support ongoing learning. Human-in-the-Loop Machine Learning (HITL) Explained Why Competitors Can’t Copy Your Data Flywheel Having a strong data infrastructure built on an efficient DataOps workflow gives your team a lasting edge. It enables faster iteration, better quality control, and domain-specific learning that compounds over time. While competitors may replicate your models, algorithms, AI tools, or frameworks, they cannot recreate your data flywheel. This system captures real-time signals, efficiently enriches the data, and feeds it back into the model pipeline. Fig 2. Data Flywheel and How it Works Datasets as Intellectual Property Treating datasets like intellectual property assets helps you secure a competitive advantage. Companies with high data valuation often have market-to-book ratios 2–3 times higher, reflecting a premium on data quality, ownership, and governance. Internal tools and processes for data versioning, annotation, and lineage are proprietary and provide your organization with a hidden edge. Edge Cases Are Unique to Your Domain Every AI system encounters edge cases, those rare, unexpected scenarios that models struggle with. Only your team understands the full context behind edge-case exceptions, the frequency, and the business impact. Over time, your feedback loops and triage processes effectively capture and resolve these edge cases, empowering you to leverage AI capabilities for deeper domain adaptation. This leads to fine-tuned models deeply aligned with your operations, workflows, and customer interactions. For competitors, if they want to replicate your data, they may require your organizational knowledge and historical context. Real-World Example: A lead data scientist we spoke to expressed the workflow complexity surrounding edge cases and feedback. This extends beyond basic data operations and instead requires knowledge reflected in the company’s datasets, tools, and processes. How Strong Data Infrastructure Reduces Cost and Time-to-Market A well-built AI data infrastructure delivers measurable savings and accelerates deployment. It replaces fragmented, manual efforts with repeatable systems that enable scalable efficiency across teams and projects. Faster Project Onboarding According to a study, organizations using data pipeline automation saw 80% reductions in time to create new pipelines, moving fast from concept to live data. When data pipelines, workflows, and versioning are standardized, new AI initiatives get up and running quickly. Teams don’t waste weeks rebuilding ingestion scripts or annotation processes. Instead, they use existing modular frameworks to start experimentation and model training sooner, aligning with business needs efficiently. Smarter Annotation at Scale Manual data labeling becomes a bottleneck as datasets grow. Having a tool like Encord AI data management in your data stack automates data triage and integrates human-in-the-loop (HTIL) annotation seamlessly. Additionally, it deploys model-in-the-loop pre-labeling to reduce manual effort. This optimized annotation process improves data quality and speeds up training cycles. It ensures your AI applications remain accurate and reliable as workloads increase. Fig 3. Human-in-the-Loop Automation Reuse Models and Datasets Across Products An AI data infrastructure that is versioned and reusable enables teams to use existing datasets and pretrained models for new use cases. This reduces duplication of work, lowers operational costs, and shortens time-to-market for AI-powered features across products. High Marginal Costs Without Infrastructure Without a scalable data infrastructure, every new AI project faces high additional costs. Labeling costs increase linearly with customer growth unless automation is used. QA and feedback pipelines struggle to scale, which causes deployment delays and increased operational risk. This is not sustainable for companies looking to grow AI capabilities throughout their ecosystem. CEO Insight: These needs were validated by a CEO of a firm in the computer vision space, who expressed that scaling past the competition has a high marginal cost. However, there is a competitive advantage in building a data labeling infrastructure. Without it, the cost to support each customer remains high, hurting cost efficiency. The Full Guide to Automated Data Annotation Moving from Prototype to Production-Ready AI Experimentation is easy, but scaling AI to production brings a lot of challenges. Many teams build impressive proof-of-concept models. These models perform well in controlled environments but fail when exposed to real-world requirements such as auditability, consistency, and compliance. Without a strong, end-to-end data infrastructure, moving from prototype to production becomes a bottleneck. To overcome these challenges, teams must adopt repeatable, automated pipelines as the foundation of their infrastructure. Here’s why repeatable pipelines matter: Consistent Quality: Repeatable data pipelines ensure that the same standards are applied across training, validation, and deployment. This consistency is crucial for maintaining model performance when working with diverse and evolving datasets. Regulated Industry Compliance: Industries such as healthcare and finance require traceable and auditable AI systems. Without automated and versioned data workflows, proving compliance becomes manual, slow, and prone to errors. Faster Iteration Cycles: Automated pipelines reduce time spent on repetitive tasks. Engineers can quickly update models, test them with fresh data, and deploy improvements. This agility gives companies a strong competitive edge. Researcher Testimony: This is exactly what was described by a researcher at a firm developing agentic AI. While his team had working models, they did not have repeatable data infrastructure. This put them at a competitive disadvantage. Winning with Data—Not Just Models AI innovation is often framed as a race to build smarter generative AI models. Yet, the true differentiator is how your team uses AI data infrastructure to keep models learning, accurate, and ready for production. A data-focused approach, supported by automated pipelines and strong data management, turns raw datasets into a strategic asset. This boosts AI adoption across industries such as healthcare, finance, and supply chain. Teams that invest in strong AI data infrastructure build a data flywheel. This flywheel becomes an engine of continuous improvement, embedding domain expertise into every cycle. Key advantages of data-centric infrastructure include: Faster Iteration: Automated data pipelines reduce turnaround time for model updates. Teams move from weeks to days in deploying improvements, staying ahead in competitive markets. Higher Model Accuracy: Fresh, high-quality, on-distribution data improves predictive performance. Models stay aligned with evolving user behavior and edge cases unique to your ecosystem. Lower Deployment Costs: Reusable pipelines, versioned datasets, and streamlined labeling reduce infrastructure costs. Teams avoid rebuilding from scratch for each use case, maximizing operational efficiency. Fewer Failures in Production: Repeatable, audited workflows ensure that models work as expected when exposed to real-world demands, regulatory requirements, and customer interactions. Build Your Data-Centric Infrastructure with Encord Encord offers a unified platform to manage, curate, and annotate multimodal datasets. It serves as a direct enabler of robust AI data infrastructure in production settings. Unified Data Management & Curation (Index) Encord handles images, video, audio, and documents within a single environment for in-depth data management, visualization, search, and granular curation. It connects directly to cloud storage, including AWS S3, GCP, Azure, and indexes nested data structures. Fig 4. Manage & Curate Your Data AI-Assisted and Human-in-the-Loop Annotation Automated labeling offloads repetitive tasks, then humans review and correct edge-case outputs. This HTIL workflow boosts annotation accuracy by up to 30% and speeds delivery by 60%, ensuring data quality at scale. Encord Active monitors model performance, surfaces data gaps, finds failure modes, and helps improve your data quality for model retraining loops. Data‑Centric Curation & Dataset Optimization Encord applies intelligent filters to detect corrupt, redundant, or low-value datapoints. Encord index led to a 20% increase in model accuracy and a 35% reduction in dataset size for Automotus. Business Impact & Results Encord users report tangible outcomes, including $600,000 saved annually by Standard AI and a 30% improvement in annotation accuracy at Pickle Robot. Its use of the Index alone cut dataset sizes by 35%, saving on compute and annotation costs. Conclusion AI success at scale comes from data infrastructure. Tech companies are investing to scale their infrastructure because data pipelines, governance, and real-time systems deliver growth, productivity, and long-term profitability. When you treat data as a strategic asset, applying versioning, modular pipelines, and automated workflows, you gain: Faster iteration and deployment, outpacing competitors Higher accuracy and robustness, driven by quality datasets Lower costs and failure rates, thanks to reusable, scalable systems Defensible differentiation, through proprietary feedback loops and domain edge cases If you want a lasting competitive edge, focus on your AI data infrastructure. Scalable pipelines, automated workflows, and strong governance are the foundation your AI strategy needs.
Jul 03 2025
5 M
Best Video Annotation Tools for Healthcare 2025
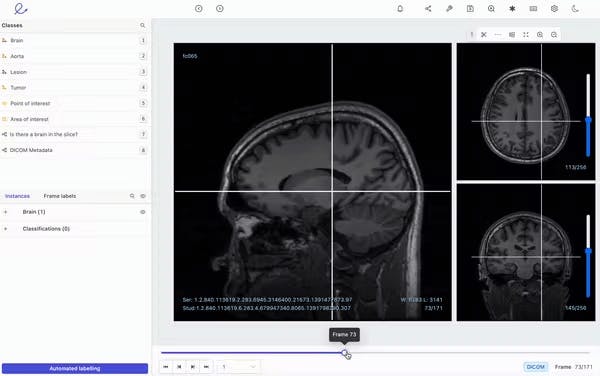
This guide to video annotation tools for healthcare breaks down how AI teams can create quality annotated video datasets for building accurate healthcare computer vision systems. Every year, hospitals add tens of millions of gastrointestinal endoscopy videos to their archives. A single 15-minute procedure produces around 27,000 high-definition frames, creating a large amount of visual data. However, most of this valuable footage remains unused because converting it into reliable AI requires detailed, frame-by-frame data labeling. However, manual labeling is slow and costly, and mistakes can put patient safety at risk. Annotating just 100,000 medical images can cost over $1.6 million and take the effort of 20 people working for a whole year. Therefore, healthcare teams need video-annotation platforms like Encord that do more than draw boxes. These platforms must adhere to medical imaging standards, such as DICOM, and ensure the protection of patient health information. This article will define healthcare AI and the unique demands of video annotation in clinical settings. We will review the best video annotation tools for healthcare, focusing on platforms that create high-quality annotated videos for clinical AI systems. What Is Healthcare AI? Artificial intelligence (AI) in healthcare refers to the use of machine learning models to assist medical decision-making, diagnose diseases, and plan treatments. These models process medical data and give medical professionals important insights. This helps improve health outcomes and deliver better patient care. One of the biggest advances in healthcare AI stems from computer vision. This technology can detect objects in endoscopy videos. It can also identify organs in CT scans, which makes diagnosis faster and more accurate. Fig 1. Computer Vision in Healthcare The Importance of Video Annotation for the Success of Healthcare Model Video annotation is the process of applying descriptive tags, labels, or masks to specific objects in each frame of a video. This process converts raw video into high-quality annotated datasets that serve as the ground truth for training and validating vision models. This approach helps in the following ways: Drives Model Accuracy: Precise annotations ensure computer vision models learn from reliable data. Poor labels lead to unreliable predictions that healthcare cannot afford, and AI models struggle to meet reliability and safety standards. For example, a mislabeled polyp in a colonoscopy video can cause the model to miss a real polyp in future cases. Enables Auditability and Bias Checks: Quality-annotated data provides the foundation for auditability. This helps regulators understand and trace how an AI model arrived at a particular decision. It also helps detect bias, ensuring that AI algorithms do not repeat the existing biases found in the original data. Challenges Unique to Healthcare AI Building AI for healthcare is complex. Unlike general computer vision tasks, medical vision models face strict regulatory, technical, and ethical constraints. Common challenges include: Protected Data: Medical data contains PHI, which is highly sensitive. It is subject to strict global regulations, such as HIPAA and GDPR. Any data annotation platform must handle this information carefully and follow these regulations. High-Stakes Accuracy: A single misprediction can affect treatment, patient safety, and outcomes. This requires high-precision annotations, often needing pixel-level accuracy. Techniques like panoptic or instance segmentation are used to achieve this. Limited Expert Time: Annotating medical videos requires domain experts, such as radiologists, pathologists, or ophthalmologists. Their time is limited, making large-scale annotation slow and expensive. Regulatory Scrutiny: Healthcare AI is subject to regulatory oversight, such as the FDA, when used in diagnostics. Medical AI systems must ensure traceability, bias control, and incorporate human override mechanisms. Annotation platforms must provide transparent workflows, quality control, and complete documentation. These challenges slow AI development and increase risk. Purpose-built video annotation tools, like Encord, help address them by enabling secure labeling and supporting regulatory compliance. Fig 2. Encord's DICOM Annotation Tool Key Features to Look for in Video Annotation Tools for Healthcare When selecting video annotation tools for healthcare, consider key features tailored to the unique needs of medical applications. This ensures high-quality training data and efficient workflows. The list below highlights some crucial features a video annotation tool should have. Support for Medical Image Formats: Look for a video annotation platform that supports standard medical imaging formats, like DICOM and NIfTI. It should also handle 3D and 4D volumetric data to enable annotation across spatial and temporal dimensions. Ability to Handle Large Video Files: Medical videos are often large and high-resolution. Tools should efficiently manage large file sizes and high frame counts without performance degradation to ensure a smooth annotation process. Collaboration Features: Effective annotation requires input from multi-disciplinary healthcare experts. Look for a tool that supports collaborative workflows, allowing teams to coordinate annotation tasks and reviews efficiently. Clinician-Centric User Interface: Look for a tool with a user-friendly interface for medical professionals. Features like intuitive timelines, measurement overlays, and voice annotations for quick feedback can enhance usability by simplifying complex annotation features. Automated and Active Learning Features: AI-assisted and pre-labeling can speed up the annotation process. The human-in-the-loop approach combines the speed of automation with the precision of human quality control, ensuring high-quality datasets for machine learning models. Secure Deployment Options: Medical data demands robust security. Choose tools that provide on-premises, virtual private cloud (VPC), or fully managed cloud solutions to protect sensitive information. Compliance with Healthcare Regulations: Annotation platforms must meet HIPAA and FDA standards to protect patient data and ensure legal compliance throughout the annotation process. Evaluating tools against these features can help in selecting a video annotation platform that aligns with the specific needs of your healthcare AI projects. Top Video Annotation Tools for Healthcare: Overview Top Video Annotation Tools for Healthcare The complexity of medical video data and the need for robust annotation workflows require teams to have platforms that combine automation, collaboration features, and compliance-ready infrastructure. Below is a list of video annotation tools commonly used in medical applications. Encord Encord is a collaborative AI data annotation platform that provides enterprise-grade solutions for complex, regulated AI projects, especially in the healthcare domain. The platform's objective is to accelerate the deployment of medical AI products by allowing the development of high-quality training datasets. Encord Supported Medical Imaging Formats and Video Formats Encord supports standard medical imaging formats, including DICOM and NIfTI. It offers 3D viewing options across sagittal, axial, and coronal planes, with window levels configurable via Hounsfield units, a standard in radiology. Encord also supports various video formats and resolutions. This ensures versatility across a range of medical video sources. Fig 3. Medical Data 3D View in Encord Encord Supported Annotation Types Encord supports various annotation types for detailed medical labeling. These include polygons for irregular shapes, key points for specific anatomical landmarks, and bounding boxes for object detection. It also supports rotatable boxes for objects in different orientations, polylines for linear structures, and classifications for video segments. A valuable feature for medical imaging is its support for Primitives (skeleton templates). These are essential for specialized annotations of template shapes, such as 3D cuboids and rotated bounding boxes, used to capture an object's three-dimensional structure from video. Encord also offers panoptic segmentation, enabling pixel-level labeling of both countable objects and amorphous regions. Fig 4. Encord Pixel-Perfect Labeling Encord AI-Assisted Labeling Capabilities Encord helps automate the annotation workflow through AI-assisted labeling. This includes automated object tracking and interpolation. These techniques intelligently fill in annotations between video frames, reducing the manual effort required across long sequences. Encord also integrates Meta AI’s Segment Anything Model (SAM), allowing instant, pixel-perfect segmentation masks. Moreover, it uses a micro-model approach and Models-in-the-Loop. This allows users to seamlessly integrate their custom models for pre-labeling datasets. Fig 5. Instantly Segment Anything in Encord Learn how to annotations medical data Encord Security and Compliance Encord strictly follows compliance standards, such as HIPAA and GDPR. It uses military-grade encryption, and all your information is encrypted at rest with AES-256. The annotation platform offers flexible deployment options, including VPC and on-premises solutions, to meet the needs of organizations with strict data protection requirements. Continuous security monitoring and multi-layered, role-based access controls are also in place. Supervisely Supervisely is a computer vision platform that focuses on surgical video annotation and DICOM file management. It supports multi-planar labeling across coronal, sagittal, and axial planes, providing a comprehensive view for annotators. Supervisely's video labeling tools enable automatic object tracking, detection, and segmentation on videos by using state-of-the-art (SOTA) neural networks. It integrates advanced models, including Meta AI's SAM, MixFormer, RITM, ClickSeg, and EiSeg. These models allow annotators to provide real-time feedback for correcting model predictions, streamlining the process. Supervisely’s privacy features, such as data encryption and data anonymization, align with healthcare regulations. It supports deployment on all major cloud providers (AWS, GCP, Azure) with flexible configurations. Its user-friendly interface makes it ideal for annotating surgical videos for AI-assisted surgery, surgical robotics, and clinical research. OHIF OHIF is an open-source platform for viewing and annotating medical images, including video data. It supports various medical imaging formats, including DICOM. It uses Cornerstone3D for its strong annotation features, enabling tasks such as surgical video analysis and diagnostic imaging. OHIF features an advanced video viewport for imaging workflows, supporting HTML5 video streams. This enables precise frame-by-frame analysis and longitudinal video annotations. Its web-based interface provides easy access and real-time collaboration among medical professionals, enhancing workflow efficiency. OHIF also introduced AI-powered Labelmap Assist for quickly extending an existing segmentation to the next or previous slice using the Segment Anything (SAM) model. Fig 8. Automatic Labelmap Slice Interpolation Labellerr Labellerr is a video annotation platform known for precision, scalability, and AI integration. It provides tools and solutions for the healthcare and biotechnology sectors. It has a strong focus on reliable data annotation for medical AI applications while adhering to regulations like HIPAA and GDPR. Labellerr offers DICOM annotation tools and supports both 2D and 3D medical image formats, including DICOM and NIfTI. It also works with 2D formats like X-rays and CT scans. The platform handles various types of video data, ensuring broad applicability across different medical video sources. Fig 9. Labeller Bitmask Annotation The platform speeds up the annotation process through its AI assistance and smart feedback loop, leading to 10 times faster labeling. Automated labeling is applied to tasks such as identifying tumors, fractures, and organ structures in medical scans, reducing manual effort and improving accuracy. CVAT CVAT is an open-source image and video annotation tool. Its open-source architecture allows customization. This allows users to adapt it for specific medical imaging files like DICOM or NIfTI, which are not natively supported but can be integrated. CVAT supports a variety of annotation types, including bounding boxes, polygons, and skeletons, with interpolation for efficient labeling of video frames. As an open-source solution, CVAT provides users with a high degree of control over their data and environment. However, self-hosting CVAT in a highly secure, airtight server environment (e.g., without internet access) can present significant challenges. Fig 10. CVAT Video Annotation Kili Technology Kili's video annotation tool supports all common video formats and annotation types. This includes bounding boxes, polygons, and semantic segmentation, suitable for medical videos. Its data management supports help teams manage long videos with over 100,000 frames and multiple objects per frame. The platform’s AI-driven workflows use its Model-in-the-loop feature, which enables users to connect their models and generate pre-annotations. It also enhances segmentation tasks with foundation models such as SAM. Fig 11. Kili's Video Annotation Tool Kili Technology is SOC2 and HIPAA certified, ensuring privacy and protection against bias. It provides secure data storage on its platform or connects to popular cloud providers like Azure, Google, or AWS. The platform also supports Single Sign-On (SSO) for easy and secure access. RedBrick AI RedBrick AI is a SaaS application for medical image viewing and video annotation. It helps healthcare AI teams create quality outcomes datasets. The tool supports all radiology modalities, including X-ray, CT, MRI, and Ultrasound, as well as 2D and 3D formats. Additionally, it supports video formats and medical data formats like DICOM, NRRD, NIfTI, and MP4. RedBrick AI includes an Auto Annotator, an automatic segmentation tool powered by Meta AI's SAM. It helps generate 2D and 3D segmentation masks for hundreds of structures on CT and MR images. Fig 12. RedBrick AI Labeling Its Mask Propagation Tool allows users to annotate a single slice and then propagate that mask across a defined range of slices, making volumetric annotation much faster. RedBrick AI follows HIPAA standards, supporting radiology AI teams in building training datasets for diagnostics. 3D Slicer 3D Slicer is an open-source platform for 3D medical image and video annotation, widely used in research. It supports DICOM, NIfTI, and medical videos, with modules for time-series annotation like surgical procedures. The tool supports DICOM standard interoperability, including 2D, 3D, and 4D images, segmentation objects, and structured reports. It also provides volume rendering, surface rendering, and slice display, enabling medical data to be presented in various ways. Additionally, 3D Slicer integrates AI-assisted annotation tools that can automatically segment anatomical structures using pre-trained or custom models. It supports NVIDIA Clara AI-based automatic segmentation, along with a MONAI plugin for 3D volumes segmentation annotation. Fig 13. 3D Slicer AI-assisted Segmentation Why Encord Stands Out While all the listed tools above offer valuable capabilities for healthcare AI, Encord is particularly noteworthy. Its tailored features directly address the strict demands of medical video. Unlike many general-purpose annotation platforms, Encord is optimized explicitly for medical imaging. It offers native DICOM and NIfTI support, which is essential for managing complex multidimensional data in medical imaging. Encord is an enterprise-grade platform built to manage petabytes of medical data and multiple users without performance degradation. Its project management features make managing complex annotation project pipelines easier. The platform’s powerful tools enable high-throughput video labeling at scale. Encord offers collaboration tools that allow annotators, reviewers, and domain experts to work while maintaining strict access controls. It is SOC 2 Type II, HIPAA, and GDPR compliant, and uses military-grade encryption. This commitment to security ensures confidence in developing AI solutions in regulated healthcare environments. Learn how to automate video annotation Key Takeaways Video labeling tools are important for creating trustworthy healthcare AI systems. They help convert raw video data into quality annotated datasets that power machine learning algorithms for diagnostics, treatment planning, and clinical automation. These tools must handle complex medical imaging formats, support collaboration, and comply with healthcare regulations to ensure safe AI deployment. Below are key points to remember when selecting and using video annotation tools for healthcare AI projects. Best Use Cases for Video Annotation Tools: The most effective video annotation tools in healthcare are used for surgical video analysis, segmentation in radiology, and training models for medical robotics. These use cases demand pixel-level accuracy, expert-driven labeling, and audit-ready documentation. Challenges in Healthcare Annotation: Healthcare video annotation presents challenges. These include managing large-scale datasets, ensuring PHI security, and meeting HIPAA and FDA compliance. Tools must also support 3D and 4D data and streamline annotation workflows. Encord for Healthcare AI: Encord supports various medical imaging formats. Its AI-assisted approach to labeling videos helps teams optimize speed and consistency in producing annotated datasets. Other tools, such as Supervisely, V7, Kili, Labellerr, and RedBrick AI, also offer strong healthcare-focused capabilities. The best choice depends on your data types, project scale, regulatory needs, and workflow priorities.
Jul 02 2025
5 M

Webinar Recap: Build Smarter VLMs, Faster - How to Bootstrap With Existing ML Solutions
In a joint session hosted by our ML Lead Frederik and Neuron’s Head of AI, Doogesh, we pulled back the curtain on what it really takes to turn machine learning (ML), large language models (LLMs), and neuroscience-powered insights into systems that drive measurable ROI. Below are the key takeaways from this insight-packed webinar. How to go from ML models to measurable impact Most companies already use ML in production, but not all of them are extracting business value. This webinar provided a blueprint for bridging that gap: Align model behavior with business goals: Models are only as good as their outcomes. Ensuring alignment with ROI and implementing human-in-the-loop are critical. Unify models into VLMs: Combine Claude, GPT, and proprietary neuroscience models into vertically integrated vision-language systems (VLMs) for performance that scales. Move from suggestion to action: Battle-tested recommendation systems become the foundation for guiding GenAI tools development. Neurons AI: Science-powered ad recommendations Doogesh, Head of AI at Neurons, introduced the audience to how they deliver unlimited AI-driven ad recommendations backed by neuroscience. Here’s how Neurons has used AI to transform advertising performance: Pre-test ads instantly: No more waiting on A/B testing; get results in seconds. Visual Attention Prediction: Eye-tracking and heatmaps predict what grabs users' focus. Optimize messaging and recall: Get early signals on engagement, recall, and cognitive load. Benchmarking across industries: Track performance against industry-specific standards for more accurate insights. How neuroscience powers better ML Through tests like the Visual Memory Game (VMG) and Fast Response Test (FRT), Neurons collects high-quality data on: Memory: Identifying what users remember from fast image streams. Engagement: Reaction speed shows how compelling a visual is. Focus: Area-of-interest (AOI) heatmaps reveal content clarity. Cognitive Load & Demand: EEG and entropy-based metrics quantify complexity. This rich dataset feeds into their CIS score—a single, weighted measure that correlates strongly with ROI. ✅ Key Insight: CIS scores can serve as evaluation metrics in RL setups for autonomous recommendation systems. Industry & segment specificity matters Doogesh emphasized that not all ads, or audiences, are created equal: Different industries and demographics respond to different visual cues Models trained on generalized data underperform unless tuned to specific audience behaviors Benchmarking across segments and geographies helps ensure accurate and trusted recommendations Industry segmentation for benchmarking Annotation of advertisement using image annotation tool, Encord Models trained on generalized data underperform unless tuned to specific audience behaviors. Blueprint for VLM-powered recommendation systems Frederik and Doogesh then provided some a generalized framework for building actionable recommendation engines: Step 1: Build production-grade ML models Let them serve as the foundation for understanding what drives value today. Step 2: Feed insights into a recommender system LLMs act as judges, vibing off human edits, customer feedback, and content scoring systems like CIS. Step 3: Create agentic systems Use data and evaluation pipelines to enable iterative, autonomous systems that learn, act, and improve with minimal human input. “What activities that add value today also generate data for tomorrow’s AI?” From Evaluation to Autonomy As performance benchmarks stabilize, we move closer to autonomous agents that: Generate, evaluate, and adapt creatives Collect real-time feedback like click-through rates Train on their own outputs to self-improve. But this shift hinges on: Strong content scoring systems (like CIS), Reliable evaluation pipelines, and Rich historical data for training. Final Framework: A 3-Step Rocket to ROI 1. Build ML that Works Use neuroscience data and LLMs to create foundational models. 2. Use Models to Guide Recommendations Extract insights, benchmark, and personalize at scale. 3. Turn Recommendations into Agentic Tools Close the loop with systems that act autonomously and improve over time. Closing Thoughts The Encord x Neurons collaboration shows a future where ML systems are no longer siloed black boxes, but value-generating engines deeply embedded into business strategy, backed by science, powered by LLMs, and guided by ROI.
Jul 01 2025
5 M
Scale AI Alternatives: Why AI Teams Choose Encord
On June 12 2025 Meta confirmed a $15 billion investment for a 49 % non-voting stake in Scale AI—and hired CEO Alexandr Wang to run its new “super-intelligence” group. Customers such as Google have already paused work with the platform and Encord is experiencing and influx of customers looking for alternative to Scale. If you need vendor neutrality or faster throughput, now is the ideal moment to benchmark alternatives offering: lower or more predictable unit economics, modern quality-assurance workflows and audit trails, seamless SDK and API integrations, and true multimodal support, including emerging 3D sensors. The best AI teams are moving to Encord because these features matter to them. Encord is the scalable multimodal data engine alternative to Scale Encord’s platform indexes, curates, and annotates petabyte-scale datasets spanning images, video, DICOM, audio, documents, and—as most recently—LiDAR and point-cloud data. The new Physical AI suite unifies 3D, camera, and radar streams inside one labeling workflow, giving robotics and autonomy teams a single pane of glass for perception data. The influx of customers migrating from Scale to Encord are mentioning that these aspects matter the most to them: Encord's LiDAR launch: ingest MCAP or LAS files, visualize multi-sensor scenes, and auto-propagate 3D boxes across sequences. Encord scales from single-GPU prototypes to petabyte deployments without re-architecting. The platform works on-prem, in VPC, or SaaS; SDK covers import → train → export. Encord offers a suite of tools designed to accelerate the creation of training data. Encord's annotation platform is powered by AI-assisted labeling, enabling users to develop high-quality training data and deploy models up to 10 times faster. Encord’s active learning toolkit allows you to evaluate your models, and curate the most valuable data for labeling. See also the detailed Scale vs Encord comparison for pricing and workflow nuances. 📌 Try Encord Free – The Active Learning Platform Trusted by Industry Leaders Encord ML Pipeline & Features State-of-the-art AI-assisted labeling and workflow tooling platform powered by micro-models Perfect for image, video, DICOM, and SAR annotation, labeling, QA workflows, and training computer vision models Native support for a wide range of annotation types, including bounding box, polygon, polyline, instance segmentation, keypoints, classification, and more Easy collaboration, annotator management, and QA workflows to track annotator performance and ensure high-quality labels Utilizes quality metrics to evaluate and improve ML pipeline performance across data collection, labeling, and model training stages Effortlessly search and curate data using natural language search across images, videos, DICOM files, labels, and metadata Auto-detect and resolve dataset biases, errors, and anomalies like outliers, duplication, and labeling mistakes Export, re-label, augment, review, or delete outliers from your dataset Robust security functionality with label audit trails, encryption, and compliance with FDA, CE, and HIPAA regulations Expert data labeling services on-demand for all industries Advanced Python SDK and API access for seamless integration and easy export into JSON and COCO formats Integration and Compatibility Encord offers robust integration capabilities, allowing users to import data from their preferred storage buckets and build pipelines for annotation, validation, model training, and auditing. The platform also supports programmatic automation, ensuring seamless workflows and efficient data operations. Benefits and Customer Feedback Its users have received Encord positively, with many highlighting the platform's efficiency in reducing false acceptance rates and its ability to train models on high-quality datasets. The platform's emphasis on AI-assisted labeling and active learning has been particularly appreciated, ensuring accurate and rapid training data creation. Learn more about how computer vision teams use Encord instead of Scale Vida reduce their model false positive from 6% to 1% Floy reduce CT & MRI annotation times by ~50% Stanford Medicine reduce experiment time by 80% King's College London increase labeling efficiency by 6.4x Tractable go through hyper-growth supported by faster annotation operations As we delve into the best Scale AI alternatives, we'll explore platforms that offer an enhanced user experience, specializing in data labeling, cater to large-scale operations, and can handle many users. From platforms that leverage neural networks to those that focus on transcription, the future of AI is diverse and promising. Find a summary of these tools in the table below: An Overview of Scale AI Scale AI was a provider of data annotation and ML operations solutions, designed to accelerate the development and deployment of machine learning models. It supported a wide range of industries, including autonomous vehicles, e-commerce, and robotics. It is unclear how the company will change post the acquisition. ML Pipeline & Features Supports annotations for images, videos, LiDAR, text, and more, enabling diverse use cases like object detection, sentiment analysis, and 3D mapping. Combines machine learning algorithms with human oversight to reduce annotation time and improve accuracy. Customizable workflows for quality assurance, collaboration, and project tracking. Handles projects of varying complexities, from small datasets to enterprise-level needs, ensuring scalability. Multi-layer quality checks and advanced metrics to ensure dataset reliability and consistency. Real-time insights into labeling performance, dataset health, and model readiness. Integration and Compatibility Scale AI offers robust integrations with major cloud platforms like AWS, Google Cloud, and Azure. Its APIs allow seamless connection to data pipelines and machine learning frameworks, enabling an efficient end-to-end ML workflow. The platform supports JSON, COCO, and other formats for easy data export. Benefits and Customer Feedback Scale AI is praised for its ability to streamline the ML data pipeline, reduce project turnaround times, and maintain high-quality output across large-scale projects. Its customers highlight the platform’s flexibility, scalability, and robust automation features as critical enablers of faster machine learning development. However, its cost and steep learning curve can be challenging for smaller teams. It also may lack flexibility for niche use cases and requires careful integration into existing workflows. iMerit iMerit specializes in providing data annotation solutions, including those for LiDAR, which is crucial for applications like autonomous vehicles and robotics. With a focus on complex data types, iMerit ensures high precision and quality in its annotations, making it a preferred choice for industries that require intricate data labeling. ML Pipeline and Features Expertise in LiDAR data annotation, ensuring accurate and high-quality annotations While Scale AI is known for its broad range of data labeling services, iMerit's strength lies in its specialization in complex data types, most notably LiDAR Robust integration options, allowing seamless connection with various platforms and tools Various tools and platforms for efficient data annotation and management Emphasis on compliance and data protection, ensuring that businesses can trust them with their sensitive data Benefits and Customer Feedback iMerit has garnered positive feedback from its clientele, particularly for its expertise in LiDAR data annotation. Many users have highlighted the platform's precision, efficiency, and quality of annotations. The platform's ability to handle complex data types and provide tailored solutions has been particularly appreciated, making it a go-to solution for industries like autonomous driving and robotics. Refer to the G2 Link for customer feedback on the iMerit platform. Dataloop Dataloop, an AI-driven data management platform, is tailored to streamline the process of generating data for AI. While Scale AI is recognized for its human-centric approach to data labeling, Dataloop differentiates itself with its cloud-based platform, providing flexibility and scalability for organizations of all sizes. ML Pipeline & Features Streamlines administrative tasks efficiently, organizing management and numerical data. Dataloop's object tracking and detection feature stands out, providing users with exceptional data quality Requires a stable and fast internet connection, which might pose challenges in areas with connectivity issues. Integration and Compatibility Dataloop, being a cloud-based platform, offers the advantage of flexibility. However, it also requires a stable and fast internet connection, which might pose challenges in areas with connectivity issues. Despite this, its integration capabilities ensure users can seamlessly connect their data sources and ML models to the platform. Benefits and Customer Feedback Dataloop has received positive feedback from its users. Users have noted the platform's scalability and flexibility, making it suitable for both small projects and larger needs. However, some users have pointed out that the user interface can be challenging to navigate, suggesting the need for tutorials or a more intuitive design. Here is the G2 link for customer reviews on the Dataloop platform. SuperAnnotate SuperAnnotate offers tools to streamline annotation. Their platform is equipped with tools and automation features that enable the creation of accurate training data across multiple data types. SuperAnnotate's offerings include the LLM Editor, Image Editor, Video Editor, Text Editor, LiDAR Editor, and Audio Editor. ML Pipeline & Features Features like data insights, versioning, and a query system to filter and find relevant data Marketplace of over 400 annotation teams that speak 18 languages. This ensures high-quality annotations tailored to specific regional and linguistic requirements Dedicated annotation project managers, ensuring stellar project delivery Annotation tools for different data types, from images and videos to LiDAR and audio Certifications like SOC 2 Type 2, ISO 27001, and HIPAA Data integrations with major cloud platforms like AWS, Azure, and GCP Benefits and Customer Feedback SuperAnnotate has received positive user feedback, with companies like Hinge Health praising the platform's high and consistent quality. Refer to the G2 link for customers' thoughts about the SuperAnnotate platform. Labelbox Labelbox, a leading data labeling platform, is designed to focus on collaboration and automation. It offers a centralized hub where teams can create, manage, and maintain high-quality training data. Labelbox provides tools for image, video, and text annotations. ML Pipeline & Features Labelbox supports data collection to model training Features include MAL (Model Assisted Labeling), which uses pre-trained models to accelerate the labeling process Easy collaboration, allowing multiple team members to work on the same dataset and ensuring annotation consistencyReviewer Workflow feature enables quality assurance by allowing senior team members to review and approve annotations Ontology Manager provides a centralized location to manage labeling instructions, ensuring clarity and consistency API integrations, allowing users to connect their data sources and ML models to the platform Supports integrations with popular cloud storage solutions Integration and Compatibility Labelbox offers API integrations, allowing users to connect their data sources and ML models seamlessly to the platform. This ensures a workflow from data ingestion to model training. The platform also supports integrations with popular cloud storage solutions, ensuring flexibility in data management. Here is the G2 link for customer reviews about the LabelBox platform. Prolific Prolific, a human data platform, accelerates AI development by providing direct access to verified participants for training, alignment, and evaluation data. Prolific's API-first architecture integrates human feedback directly into existing ML tools and workflows. This enables AI researchers and developers to source authentic, high-quality human data for their specific use cases in hours, not weeks. ML Pipeline & Features Support for varied AI alignment and evaluation needs including RLHF, model evaluation, factuality testing and real-world user experience testing 200K+ active participants across 40+ countries and 80+ languages 300+ screeners for precise participant targeting Pre-qualified AI taskers and verified domain experts across fields like STEM, languages, programming Built-in quality controls with ability to screen participants, monitor performance, and build persistent expert pools that improve with your products over time API-first infrastructure along with an intuitive UI Option to use either the self-serve platform or fully managed services Batch data collections and always-on data pipelines for continuous improvement Integration and Compatibility Prolific's API-first architecture integrates with any of your existing ML workflows and tools. The platform supports both batch data collections and always-on data pipelines. Data export is available in standard formats with webhook support for automated data ingestion. As an Encord partner, Prolific provides complementary human intelligence capabilities that enhance annotation workflows. Benefits and Customer Feedback Prolific is valued by AI teams at organizations such as Google, AI2 and Hugging Face for making AI development fast and scalable - dramatically reducing time-to-data from weeks to hours while delivering production-grade data quality. Users particularly appreciate the transparency of knowing exactly who is providing feedback, the ability to precisely target participant demographics and expertise, and the flexibility to scale from small pilots to production-level data collection. The platform excels at tasks requiring genuine human judgment - from model evaluation and bias detection to user experience testing for AI products. Scale Alternatives: Key Takeaways after the acquisition: Meta’s stake introduces potential conflicts of interest; several hyperscalers have paused new Scale AI projects. Encord now leads for scalable multimodal pipelines, adding LiDAR/3D support and active learning to compress annotation cycle times by up to 10 ×. Specialized tools still win in niche domains—iMerit for LiDAR labeling services, V7 for medical imaging—while Labelbox appeals to collaboration-heavy enterprises. Before migrating, pilot two short projects: one “easy” class and one edge-case-heavy class. Measure unit economics, cycle time, and F1 uplift side-by-side. Scale’s interactive platform has been recognized for its excellent automation and streamlined workflows tailored for various use cases. While many platforms in the market are open-source, Scale AI's proposition lies in its focus on machine learning and AI-powered algorithms. The platform offers a range of plugins and tools that provide metrics and insights in real-time. With its robust API integrations, it seamlessly connects with platforms like Amazon, ensuring that artificial intelligence is leveraged to its full potential. In this rapidly evolving domain, optimizing workflows and harnessing the power of natural language processing is paramount. Here are our key takeaways: The AI domain is witnessing a transformative phase with new platforms and tools emerging. As industries seek efficient data labeling and management solutions, platforms like Encord are becoming indispensable. Encord's AI-assisted labeling accelerates the creation of high-quality training data, making it a prime choice in this evolving landscape. One of the standout features of modern AI platforms is the ability to harness AI for faster and more accurate data annotation. Encord excels in this with its AI-powered labeling, enabling users to annotate visual data swiftly and deploy models up to 10 times faster than traditional methods. 📌 Experience AI-assisted labeling, model training, and error detection all in one place. Join the world’s leading computer vision teams and bring your AI projects to production faster. Start Your Free Trial with Encord
Jun 21 2025
8 M
Encord Releases New Physical AI Suite with LiDAR Support
We’re excited to introduce support for 3D, LiDAR and point cloud data. With this latest release, we’ve created the first unified and scalable Physical AI suite, purpose-built for AI teams developing robotic perception, VLA, AV or ADAS systems. With Encord, you can now ingest and visualize raw sensor data (LiDAR, radar, camera, and more), annotate complex 3D and multi-sensor scenes, and identify edge-cases to improve perception systems in real-world conditions at scale. 3D data annotation with multi-sensor view in Encord Why We Built It Anyone building Physical AI systems knows it comes with its difficulties. Ingesting, organizing, searching, and visualizing massive volumes of raw data from various modalities and sensors brings challenges right from the start. Annotating data and evaluating models only compounds the problem. Encord's platform tackles these challenges by integrating critical capabilities into a single, cohesive environment. This enables development teams to accelerate the delivery of advanced autonomous capabilities with higher quality data and better insights, while also improving efficiency and reducing costs. Core Capabilities Scalable & Secure Data Ingestion: Teams can automatically and securely synchronize data from their cloud buckets straight into Encord. The platform seamlessly ingests and intelligently manages high-volume, continuous raw sensor data streams, including LiDAR point clouds, camera imagery, and diverse telemetry, as well as commonly supported industry file formats (such as MCAP). Intelligent Data Curation & Quality Control: The platform provides automated tools for initial data quality checks, cleansing, and intelligent organization. It helps teams identify critical edge cases and structure data for optimal model training, including addressing the 'long-tail' of unique scenarios that are crucial for robust autonomy. Teams can efficiently filter, batch, and select precise data segments for specific annotation and training needs. 3D data visualization and curation in Encord AI-Accelerated & Adaptable Data Labeling: The platform offers AI-assisted labeling capabilities, including automated object tracking and single-shot labeling across scenes, significantly reducing manual effort. It supports a wide array of annotation types and ensures consistent, high-precision labels across different sensor modalities and over time, even as annotation requirements evolve. Comprehensive AI Model Evaluation & Debugging: Gain deep insight into your AI model's performance and behavior. The platform provides sophisticated tools to evaluate model predictions against ground truth, pinpointing specific failure modes and identifying the exact data that led to unexpected outcomes. This capability dramatically shortens iteration cycles, allowing teams to quickly diagnose issues, refine models, and improve AI accuracy for fail-safe applications. Streamlined Workflow Management & Collaboration: Built for large-scale operations, the platform includes robust workflow management tools. Administrators can easily distribute tasks among annotators, track performance, assign QA reviews, and ensure compliance across projects. Its flexible design enables seamless integration with existing engineering tools and cloud infrastructure, optimizing operational efficiency and accelerating time-to-value. Encord offers a powerful, collaborative annotation environment tailored for Physical AI teams that need to streamline data labeling at scale. With built-in automation, real-time collaboration tools, and active learning integration, Encord enables faster iteration on perception models and more efficient dataset refinement, accelerating model development while ensuring high-quality, safety-critical outputs. Implementation Scenarios ADAS & Autonomous Vehicles: Teams building self-driving and advanced driver-assistance systems can use Encord to manage and curate massive, multi-format datasets collected across hundreds or thousands of multi-hour trips. The platform makes it easy to surface high-signal edge cases, refine annotations across 3D, video, and sensor data within complex driving scenes, and leverage automated tools like tracking and segmentation. With Encord, developers can accurately identify objects (pedestrians, obstacles, signs), validate model performance against ground truth in diverse conditions, and efficiently debug vehicle behavior. Robot Vision: Robotics teams can use Encord to build intelligent robots with advanced visual perception, enabling autonomous navigation, object detection, and manipulation in complex environments. The platform streamlines management and curation of massive, multi-sensor datasets (including 3D LiDAR, RGB-D imagery, and sensor fusion within 3D scenes), making it easy to surface edge cases and refine annotations. This helps teams improve how robots perceive and interact with their surroundings, accurately identify objects, and operate reliably in diverse, real-world conditions. Drones: Drone teams use Encord to manage and curate vast multi-sensor datasets — including 3D LiDAR point clouds (LAS), RGB, thermal, and multispectral imagery. The platform streamlines the identification of edge cases and efficient annotation across long aerial sequences, enabling robust object detection, tracking, and autonomous navigation in diverse environments and weather conditions. With Encord, teams can build and validate advanced drone applications for infrastructure inspection, precision agriculture, construction, and environmental monitoring, all while collaborating at scale and ensuring reliable performance Vision Language Action (VLA): With Encord, teams can connect physical objects to language descriptions, enabling the development of foundation models that interpret and act on complex human commands. This capability is critical for next-generation human-robot interaction, where understanding nuanced instructions is essential. For more information on Encord's Physical AI suite, click here.
Jun 12 2025
5 M
Explore our products
Index
Manage & curate your data
Understand and manage your visual data, prioritize data for labeling, and initiate active learning pipelines.
Annotate
Supporting your labeling needs
Super charge your data annotation with AI-powered labeling — including automated interpolation, object detection and ML-based quality control.
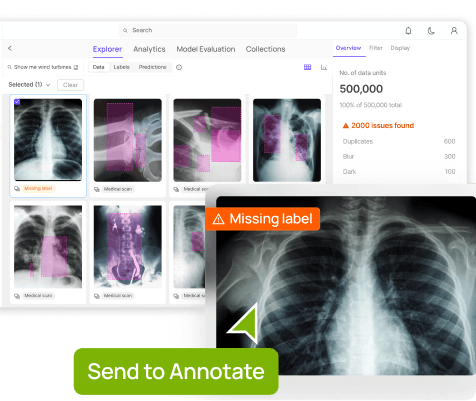
Active
Find & fix data issues with ease
Monitor, troubleshoot, and evaluate the data and labels impacting model performance.


Software To Help You Turn Your Data Into AI
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord Data Engine accelerates every step of taking your model into production.