DINOv3 Explained: Scaling Self-Supervised Vision Transformers

DINOv3 is Meta AI’s third generation of open-source self-supervised vision foundation models. It is a 7-billion parameter Vision Transformer trained on 1.7 billion images without labels. The model provides high-quality global and dense features. This can be applied to tasks such as image classification, semantic segmentation, depth estimation, and object tracking.
The significance of DINOv3 lies in three factors: scale, stability, and versatility. It introduces new algorithms to stabilize dense features and releases a family of distilled variants. This way, DINOv3 establishes itself as a general-purpose vision backbone. It reduces reliance on labeled datasets and offers reusable representations that perform well across domains.
What’s New in DINOv3?
Large Scale Training
DINOv3 is trained at a scale that sets it apart from earlier versions. The largest model has 7 billion parameters and was trained on 1.7 billion images, all without human labels. This scale allows the machine learning model to learn visual representations that generalize across a wide range of downstream tasks.
The training relies on Vision Transformers (ViTs), which scale effectively with larger datasets and longer training runs. Unlike earlier DINO versions that were limited by instability in dense feature learning, DINOv3 introduces state-of-the-art mechanisms such as Gram Anchoring to maintain stable training at scale.

Source: DINOv3
Gram Anchoring
In computer vision (CV), dense features refer to patch-level representations that preserve fine-grained details across the entire image. These are essential for tasks like segmentation, depth estimation, and object tracking, where pixel- or region-level accuracy matters. Unlike global features, which summarize an image into a single embedding for classification, dense features must stay consistent and discriminative across long training runs.

High-resolution dense features of the image. Source: DINOv3.
A key challenge in scaling DINOv3 was that while global representations kept improving, dense features degraded over time. Patches that should remain distinct started to collapse into similar embeddings, hurting performance on dense prediction tasks.
To address this, the DINOv3 team introduced Gram Anchoring, a regularization technique that stabilizes dense features during long training. The idea is simple: instead of directly constraining individual patch features, Gram Anchoring works on the Gram matrix, which encodes pairwise similarities between patches. The student model’s Gram matrix is encouraged to stay close to that of an earlier, more stable teacher network (the “Gram teacher”).
This approach allows local features to evolve freely, as long as their relative structure remains consistent. Applied after ~1M iterations, Gram Anchoring quickly “repairs” degraded local features and significantly improves dense-task benchmarks like segmentation and depth estimation, while global performance remains strong.

Qualitative effect of gram anchoring. Source: DINOv3.
The image above shows how dense features improve with gram anchoring. Without it (middle row), features are scattered and noisy. With anchoring (bottom row), they become sharper and more consistent, making objects like flowers, birds, and food stand out more clearly.
Universal Frozen Backbone
DINOv3 is trained as a multi-purpose frozen backbone, meaning the core model is kept fixed after pretraining. This universal representation works across a wide range of tasks like detection, segmentation, and retrieval without retraining from scratch.
The idea is simple: if the backbone is strong and general enough, downstream models can plug into it with minimal fine-tuning, saving compute and preserving stability.
Post-hoc Adaptability
Even though the backbone stays frozen, DINOv3 enables post-hoc adaptation through lightweight modules. Instead of retraining the full model, researchers can add task-specific heads like linear probes or adapters that specialize the features for new problems. This flexibility makes it easier to apply DINOv3 across domains from natural images to medical or satellite data without redoing the heavy pretraining.
Distilled Variants
To make DINOv3 more accessible, the Meta AI research team also trained distilled variants. These are smaller student models distilled from the large backbone, keeping much of the performance while reducing size and latency. This opens the door to real-world use cases like robotics or mobile applications where compute is limited but high-quality representations are still needed.
How Dinov3 Works
At its core, DINOv3 learns dense visual features in a fully self-supervised way. Instead of relying on labeled data, it uses a teacher–student training setup:
- The teacher model provides target representations.
- The student model learns to match them using multiple augmented views of the same image.
This approach encourages the model to capture rich, invariant features that remain consistent across transformations like cropping, color shifts, or blurs. Over time, the student becomes a strong encoder that produces representations useful for downstream tasks.

Training pipeline: curated unlabeled data → large-scale SSL pretraining → Gram anchoring → high-res refinement → distillation into multiple sizes. Source: DINOv3: Self-supervised learning for vision at unprecedented scale.
Once pretrained, DINOv3 acts as a universal visual encoder. During inference, images are passed through the backbone ViT to produce dense feature maps. These representations can then be:
- Adapted directly for tasks like retrieval or clustering.
- Fine-tuned with lightweight heads for segmentation, detection, or classification.
- Transferred across domains with minimal supervision, since the features are invariant and robust.

Inference pipeline: input → frozen DINOv3 → shared features → lightweight adapters → task-specific outputs. Source: DINOv3: Self-supervised learning for vision at unprecedented scale.
How DINOv3 Compares to Previous Models
DINOv3 builds on earlier self-supervised methods like MoCo, BYOL, and DINOv2 but pushes three key improvements:
- Dense patch-level learning: Unlike global embedding models, it supervises at the patch level, enabling strong performance on dense tasks like segmentation.
- Scalability: Trained with larger Vision Transformers on billions of images, achieving robustness across diverse domains.
- Universality: Produces features competitive with supervised models, reducing reliance on labeled data.
In benchmarks, DINOv3 consistently narrows or surpasses the performance gap between supervised and self-supervised approaches making it one of the most general-purpose visual encoders available today.
DINOv3 Benchmark Performance
DINOv3 consistently matches or surpasses supervised methods across standard vision benchmarks.
ImageNet Classification
Without seeing a single human-provided label, DINOv3 reaches top-1 accuracy comparable to fully supervised baselines. This is significant because ImageNet has traditionally been the gold standard for supervised learning.
Segmentation and Dense Prediction
Thanks to patch-level alignment, DINOv3 excels at tasks like semantic segmentation (ADE20K) and object detection (COCO). Earlier SSL models often struggled here, but dense supervision helps DINOv3 preserve fine-grained details.
Transfer Learning Across Domains
Features pretrained with DINOv3 adapt effectively to very different domains such as medical imaging or satellite data where labeled datasets are scarce. This shows that the model has truly learned universal visual features rather than overfitting to natural images.
Scaling Trends
As the backbone size grows (ViT-S → ViT-B → ViT-L → ViT-H), downstream performance scales smoothly. Larger DINOv3 models deliver gains in both accuracy and robustness, reinforcing the value of large-scale pretraining.
Why this matters:
DINOv3 isn’t just a research milestone, it’s a practical backbone replacement. Instead of relying on separate models like ResNet for classification, YOLO for detection, or Mask R-CNN for segmentation, you can use a single self-supervised backbone,i.e., DINOv3 with task-specific heads. This unification means you only need to maintain one backbone across pipelines.
In practice, this also opens up new workflows. If you store backbone features from your production environment, you can quickly re-scan past data to find relevant samples for retraining or validation without running full inference pipelines again.

Source: DINOv3: Self-supervised learning for vision at unprecedented scale.
DINOv3 Real-World Applications
DINOv3 is already being deployed in diverse, high-impact domains.
- World Resources Institute (WRI): WRI uses DINO to measure tree canopy heights from satellite imagery. This helps track global reforestation progress and provides civil society groups with accurate, scalable tools for monitoring environmental change without the need for massive annotated datasets.
- NASA Jet Propulsion Laboratory (JPL): NASA JPL integrates DINO into Mars exploration robots, enabling them to handle multiple vision tasks like terrain mapping and object recognition with minimal compute resources. This makes autonomous navigation more reliable in extreme environments where human intervention is impossible.
These use cases highlight DINO’s versatility: it can adapt to domains with scarce labels like satellite imagery or resource-constrained settings like space robotics, proving its value as a universal vision foundation model.
DINOv3 Access and Availability
Meta has made DINOv3 openly available to the research community, releasing pretrained weights, documentation, and training details. The models can be accessed directly through:
Implementation Walk-through: Segmentation Tracking with DINOv3
One of the most practical ways to use DINOv3 is in segmentation tracking, i.e., following objects frame by frame in video streams. This is particularly useful in robotics, environmental monitoring, and medical imaging.
Annotate Training Data with Encord
Start by creating your video annotation dataset using Encord’s video-native platform. The Label Editor supports frame-level bitmask annotations, object tracking, interpolation, and timeline navigation making annotation fast, consistent, and precise.
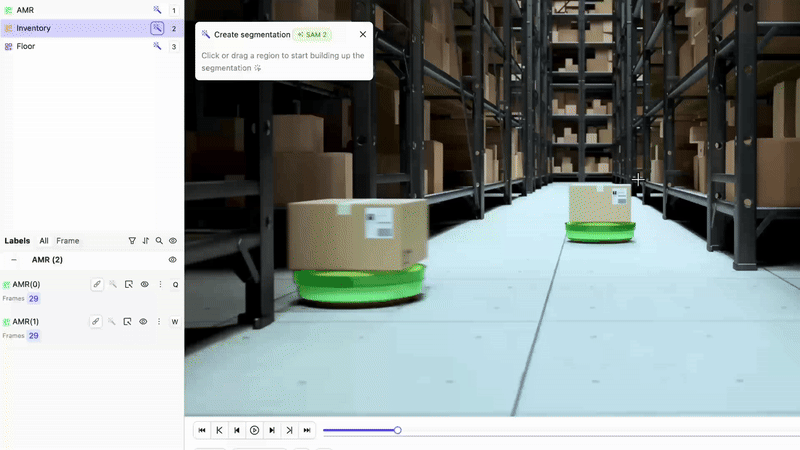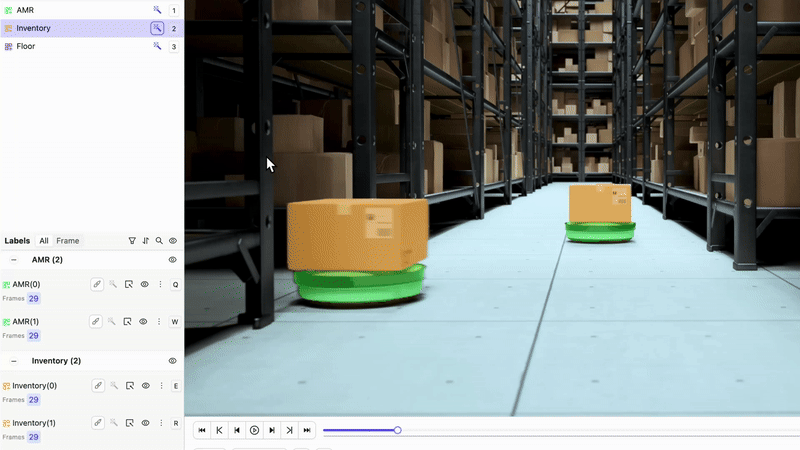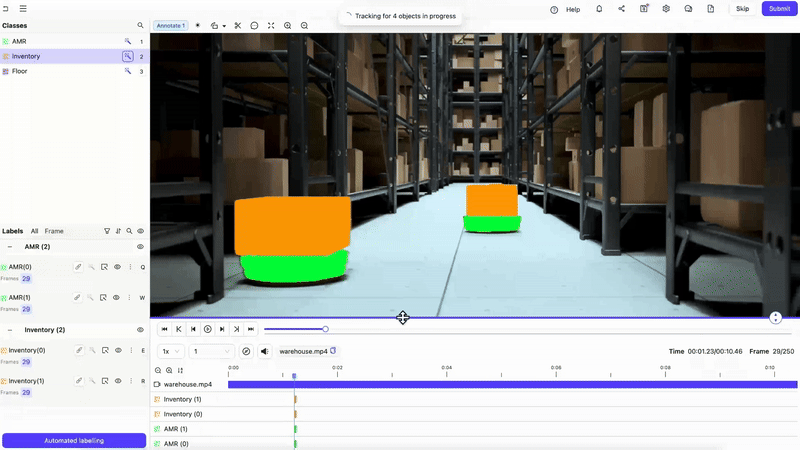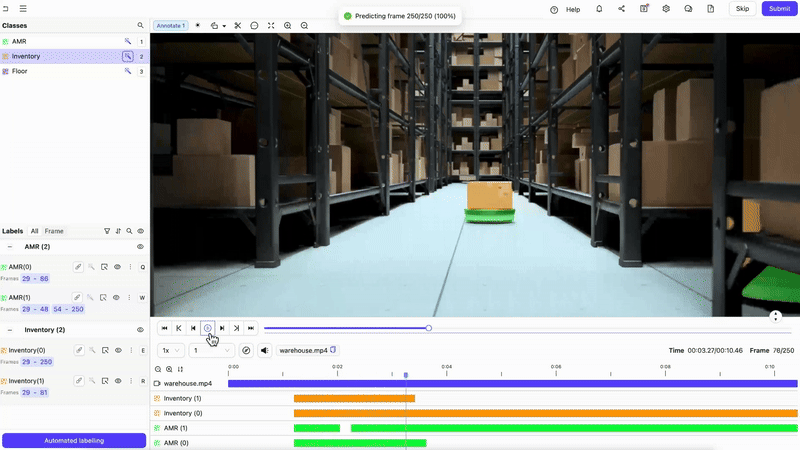
Load a Pretrained Model
Start with pretrained DINOv3 weights, which already capture strong visual representations.
import torch
model = torch.hub.load('facebookresearch/dinov3', 'dinov3_vitl')
model.eval()Preprocess Input Frames
Prepare video frames with the same normalization pipeline used in training.
from torchvision import transforms
transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
Extract Dense Patch Frames
Request dense outputs to get per-patch embeddings, not just a global vector.
with torch.no_grad():
features = model(input_tensor, return_dense=True) # shape: (patches × dim)Propagate Segmentation Masks Over Time
Define segmentation labels on one frame, then use feature-wise similarity to propagate and refine them across later frames. This works even when objects move or lighting changes.
Visualize and Evaluate
Overlay the propagated masks onto video frames to assess tracking coherence and segmentation quality.
DINOv3 Limitations
While DINOv3 pushes self-supervised vision forward, it can still faces few challenges:
- Domain Sensitivity: DINOv3 is trained primarily on natural images e.g., ImageNet-scale data. Performance may drop in specialized domains like medical imaging, remote sensing, or industrial inspection without domain adaptation.
- Annotation Propagation Drift: In segmentation tracking tasks, mask propagation can accumulate errors over long sequences since it relies on feature similarity rather than explicit temporal modeling.
DINO v3: Key Takeaway
- DINOv3 scales vision transformers to billions of parameters and diverse image sizes without supervision.
- Strong performance across tasks: segmentation, tracking, retrieval, and more with minimal task-specific tuning.
- Accessible resources: pretrained models, code, and tutorials available via Meta’s GitHub.
Frequently asked questions
DINOv3 is a self-supervised learning method for computer vision that uses self-distillation to train large neural networks without labeled training data. It learns robust image features that transfer well to downstream tasks like segmentation, tracking, and classification.
Unlike supervised models that rely on large amounts of annotated training data, DINOv3 learns image features without labels. Using self-attention and optimization techniques such as cross-entropy loss and exponential moving average, it achieves state-of-the-art results comparable to supervised baselines on ImageNet.
Gram Anchoring is a regularization technique introduced in DINOv3 to stabilize training of very large Vision Transformers. It penalizes deviations in Gram matrices between teacher and student networks, helping prevent feature collapse and ensuring richer representations.
Data augmentations create multiple image views, forcing the model to learn invariant features. Large batch sizes improve stability and generalization when scaling up models and training on billions of parameters.
Yes. DINOv3 features transfer effectively to segmentation, object tracking, retrieval, and clustering. Even simple k-NN evaluation on embeddings shows strong class separability, confirming robustness beyond classification.
DINOv3 integrates well with ViTs and ConvNeXt, producing embeddings that outperform many supervised baselines. It achieves state-of-the-art performance on standard computer vision benchmarks without labeled training data.
Encord streamlines the data annotation process by consolidating various tools and features into a single platform. This integration reduces inefficiencies caused by using multiple tools and enables users to manage data cleaning, curation, annotation, and model evaluation all in one place.
Encord is equipped to handle 3D annotations, particularly for cone beam computed tomography (CBCT) and other 3D imaging modalities. This capability allows teams to accurately annotate and analyze 3D volumes, which is essential for developing AI-based features in medical software.
Encord provides intuitive navigation features for complex scenes, such as the ability to pivot and explore data in different views. Users can hover over objects to see reprojected views and navigate through multiple frames, making it easier to annotate dynamic environments.
Encord features advanced annotation tools that enable users to label and track objects over time within lidar datasets. Users can modify positions, sizes, and orientations of bounding boxes, allowing for precise tracking of vehicles or vegetation across multiple frames.
Encord utilizes the latest advancements in model fine-tuning, such as leveraging dense task approaches like Dino V3, to improve segmentation outcomes. This results in more accurate detection of wood defects, enhancing the model's performance in specialized tasks.
Encord provides tools designed specifically for lidar data processing and semantic segmentation. These features enable users to label objects with precision and accuracy, allowing for better model training and improved performance in real-world applications.
Encord utilizes advanced segmentation models to identify various environmental elements that indicate biodiversity levels. The platform offers both one-size-fits-all habitat mapping and tailored assessments for specific habitat types, such as peatlands.
Encord supports various types of sensor data, including thermal camera inputs. The platform facilitates sensor fusion, allowing users to sync data and accurately measure object depth, thus streamlining the labeling process for complex datasets.
Encord has the capability to separate objects from backgrounds in 3D point clouds, allowing for differentiated coloration. This feature aids in the clear identification and labeling of objects within the annotation process.
Yes, Encord provides a 3D render view for annotations. Users can load their anatomical structures and explore how labels appear in a three-dimensional space, enhancing the visualization of complex datasets.