LLaVA, LLaVA-1.5, and LLaVA-NeXT(1.6) Explained

Microsoft has recently entered the realm of multimodal models with the introduction of LLaVA, a groundbreaking solution that combines a vision encoder and Vicuna to enable visual and language comprehension. LLaVA showcases impressive chat capabilities, rivaling Open AI’s multimodal GPT-4, and sets a new benchmark for state-of-the-art accuracy in Science QA.
The convergence of natural language and computer vision has led to significant advancements in artificial intelligence. While fine-tuning techniques have greatly improved the performance of large language models (LLMs) in handling new tasks, applying these methods to multimodal models remains relatively unexplored.
The research paper "Visual Instruction Tuning" introduces an innovative approach called LLAVA (Large Language and Vision Assistant). It leverages the power of GPT-4, initially designed for text-based tasks, to create a new paradigm of multimodal instruction-following data that seamlessly integrates textual and visual components.
In this blog, we will delve into the evolution of visual instruction tuning and explore the specifics of LLaVA, along with its recent iterations, LLaVA-1.5 and LLaVA-1.6 (or LLaVA-NeXT). By examining these advancements, we can gain valuable insights into the continuous progress of LLMs in AI.
What is Visual Instruction Tuning?
Visual instruction tuning is a technique that involves fine-tuning a large language model (LLM) to understand and execute instructions based on visual cues.
This approach aims to connect language and vision, enabling AI systems to comprehend and act upon human instructions involving both modalities.
For instance, imagine asking a machine learning model to describe an image, perform an action in a virtual environment, or answer questions about a scene in a photograph. Visual instruction tuning equips the model to perform these tasks effectively.
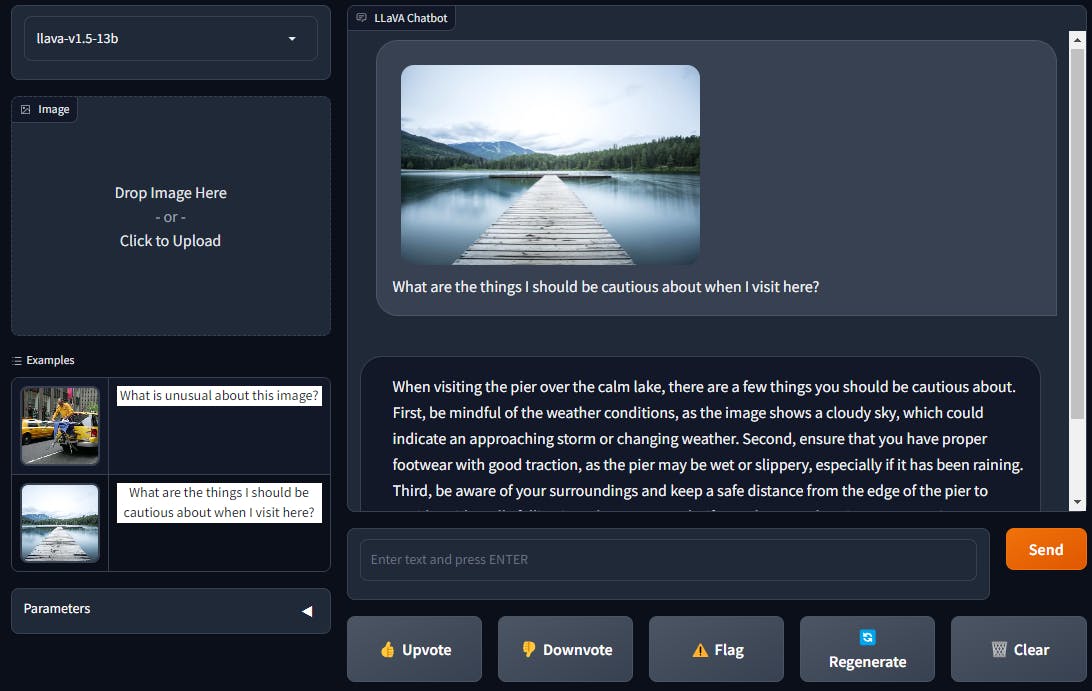
LLaVA vs. LLaVA-1.5
LLaVA
LLaVA, short for Large Language and Vision Assistant, is one of the pioneering multimodal models. Despite being trained on a relatively small dataset, LLaVA showcases exceptional abilities in understanding images and responding to questions about them. Its performance on tasks that demand deep visual comprehension and instruction-following is particularly impressive.
Notably, LLaVA demonstrates behaviors akin to multimodal models like GPT-4, even when presented with unseen images and instructions.
LLaVA Architecture
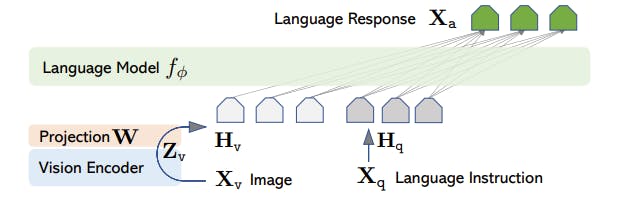
LLaVA utilizes the LLaMA model, which is renowned for its efficacy in open-source language-only instruction-tuning projects. LLaVA relies on the pre-trained CLIP visual encoder ViT-L/14 for visual content processing, which excels in visual comprehension.
The encoder extracts visual features from input images and connects them to language embeddings through a trainable projection matrix. This projection effectively translates visual features into language embedding tokens, thereby bridging the gap between text and images.
LLaVA Training
LLaVA's training encompasses two essential stages that enhance its capacity to comprehend user instructions, understand both language and visual content, and generate accurate responses:
- Pre-training for Feature Alignment: LLaVA aligns visual and language features to ensure compatibility in this initial stage.
- Fine-tuning End-to-End: The second training stage focuses on fine-tuning the entire model. While the visual encoder's weights remain unchanged, both the projection layer's pre-trained weights and the LLM's parameters become subject to adaptation. This fine-tuning can be tailored to different application scenarios, yielding versatile capabilities.
LLaVA-1.5
In LLaVA-1.5, there are two significant improvements. Firstly, adding an MLP vision-language connector enhances the system's capabilities. Secondly, integrating academic task-oriented data further enhances its performance and effectiveness.
MLP Vision-Language Connector
LLaVA-1.5 builds upon the success of MLPs in self-supervised learning and incorporates a design change to enhance its representation power. The transition from a linear projection to a two-layer MLP significantly enhances LLaVA-1.5's multimodal capabilities. This modification has profound implications, enabling the model to effectively understand and interact with both language and visual elements.
Academic Task-Oriented Data
LLaVA-1.5 goes beyond its predecessor by integrating VQA datasets designed for academic tasks. These datasets focus on specific tasks related to VQA, Optical Character Recognition (OCR), and region-level perception. This enhancement equips LLaVA-1.5 to excel in various applications, including text recognition and precise localization of fine-grained visual details.
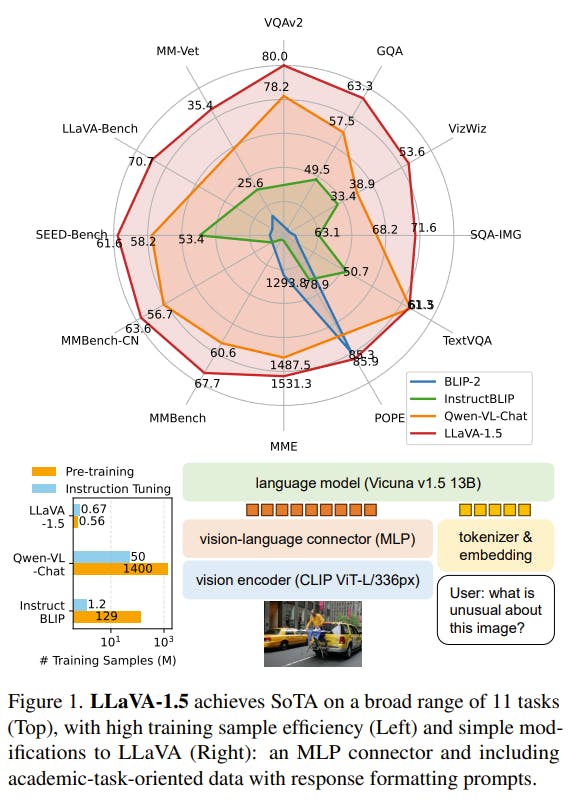
Improved Baselines with Visual Instruction Tuning
The development from LLaVA to LLaVA-1.5 signifies Microsoft’s continuous pursuit to refine and expand the capabilities of large multimodal models. LLaVA-1.5 signifies a significant progression towards developing more sophisticated and adaptable AI assistants, aligning with their commitment to advancing the field of artificial intelligence.
LLaVA 1.6 (LLaVA-NeXT)
In addition to LLaVA 1.5, which uses the Vicuna-1.5 (7B and 13B) LLM backbone, LLaVA 1.6 considers more LLMs, including Mistral-7B and Nous-Hermes-2-Yi-34B. These LLMs possess nice properties, flexible commercial use terms, strong bilingual support, and a larger language model capacity. It allows LLaVA to support a broader spectrum of users and more scenarios in the community. The LLaVA recipe works well with various LLMs and scales up smoothly with the LLM up to 34B.
Here are the performance improvements LLaVA-NeXT has over LLaVA-1.5:
- Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, and 1344x336 resolution.
- Better visual reasoning and zero-shot OCR capability with multimodal document and chart data.
- Improved visual instruction tuning data mixture with a higher diversity of task instructions and optimizing for responses that solicit favorable user feedback.
- Better visual conversation for more scenarios covering different applications. Better world knowledge and logical reasoning.
- Efficient deployment and inference with SGLang.
Along with performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pre-trained connector of LLaVA-1.5 and still uses less than 1 million visual instruction tuning samples. See the updated LLaVA-1.5 technical report for more details.
Comparison with SOTA
Multimodal AI has witnessed significant advancements, and the competition among different models is fierce. Evaluating the performance of LLaVA and LLaVA-1.5 compared to state-of-the-art (SOTA) models offers valuable insights into their capabilities.
LLaVA's ability to fine-tune LLaMA using machine-generated instruction-following data has shown promising results on various benchmarks. In tasks such as ScienceQA, LLaVA achieved an accuracy that closely aligns with the SOTA model's performance. ability to handle out-of-domain questions highlights its proficiency in comprehending visual content and effectively answering questions.
However, LLaVA demonstrates exceptional proficiency in comprehending and adhering to instructions within a conversational context. It's capable of reasoning and responding to queries that align with human intent, outperforming other models like BLIP-2 and OpenFlamingo.

The introduction of LLaVA-1.5 and its potential improvements indicate promising advancements in the field. The collaboration between LLaVA and GPT-4 through model ensembling holds the potential for enhanced accuracy and underscores the collaborative nature of AI model development.
LLaVA-Next (LLaVA 1.6) compares with SoTA methods (GPT-4V, Gemini, and LLaVA 1.5) on benchmarks for instruction-following LMMs. LLaVA-1.6 achieves improved reasoning, OCR, and world knowledge and exceeds Gemini Pro on several benchmarks. See the full result on this page.
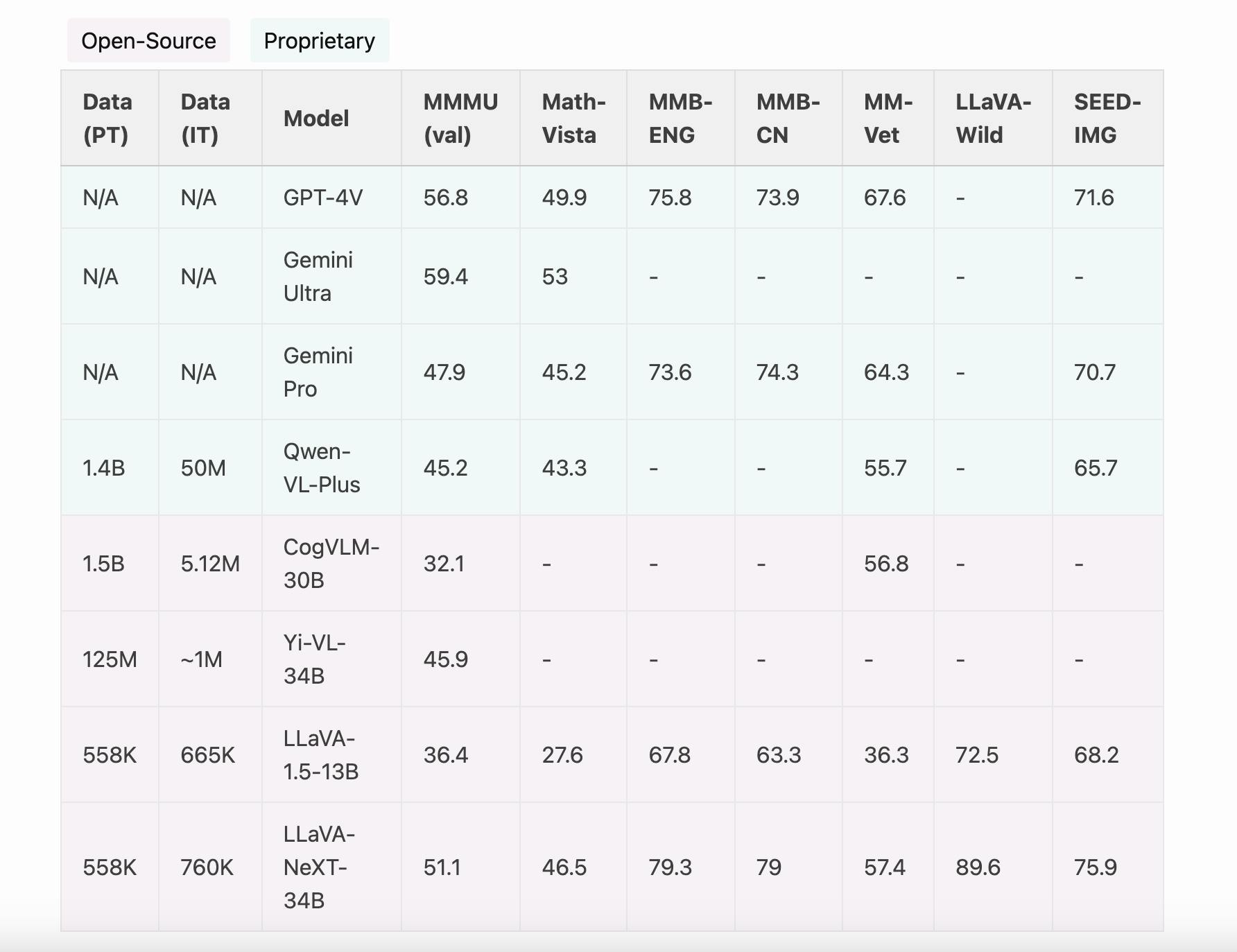
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
Recent Developments
LLaVA-Med
LLaVA-Med, the Large Language and Vision Assistant for BioMedicine, is a groundbreaking multimodal assistant designed specifically for healthcare. This innovative model aims to support biomedical practitioners in pursuing knowledge and insights by effectively addressing open-ended research inquiries related to biomedical images. What sets LLaVA-Med apart is its cost-effective approach, leveraging a comprehensive dataset of biomedical figure-caption pairs sourced from PubMed Central.
Self-guided learning facilitated by GPT-4 excels in capturing the nuances of open-ended conversational semantics and aligning them with the specialized vocabulary of the biomedical domain. Remarkably, LLaVA-Med can be trained in less than 15 hours and exhibits exceptional capabilities in multimodal conversation. This represents a significant advancement in enhancing the comprehension and communication of biomedical images.
LLaVA-Interactive
LLaVA-Interactive is an all-in-one demo that showcases multimodal models' visual interaction and generation capabilities beyond language interaction. This interactive experience, which uses LLaVA, SEEM, and GLIGEN, eloquently illustrates the limitless versatility innate in multimodal models.
Multimodal Foundation Models
Multimodal Foundation Models: From Specialists to General-Purpose Assistants is a comprehensive 118-page survey that explores the evolution and trends in multimodal foundation models. This survey provides insights into the current state of multimodal AI and its potential applications. It is based on the tutorial in CVPR 2023 by Microsoft and the members of the LLaVA project.
Instruction Tuning with GPT-4 Vision
The paper Instruction Tuning with GPT-4 discusses an attempt to use GPT-4 data for LLM self-instruct tuning. This project explores GPT-4's capabilities and potential for enhancing large language models.
While LLaVA represents a significant step forward in the world of large multimodal models, the journey is far from over, and there are promising directions to explore for its future development:
- Data Scale: LLaVA's pre-training data is based on a subset of CC3M, and its fine-tuning data draws from a subset of COCO. One way to enhance its concept coverage, especially with regard to entities and OCR, is to consider pre-training on even larger image-text datasets.
- Integrating with more computer vision models: LLaVA has shown promising results, even approaching the capabilities of the new ChatGPT in some scenarios. To advance further, one interesting avenue is the integration of powerful vision models, such as SAM.
LLaVA: Key Takeaways
- LLaVA Challenges GPT-4: Microsoft's LLaVA is a powerful multimodal model rivaling GPT-4, excelling in chat capabilities and setting new standards for Science QA.
- Visual Instruction Tuning Advances AI: LLaVA's visual instruction tuning enables AI to understand and execute complex instructions involving both text and images.
- LLaVA-1.5 Enhancements: LLaVA-1.5 introduces an MLP vision-language connector and academic task-oriented data, boosting its ability to interact with language and visual content.
- Bridging Language and Vision: LLaVA's architecture combines LLaMA for language tasks and CLIP visual encoder ViT-L/14 for visual understanding, enhancing multimodal interactions.
Frequently asked questions
Encord offers a comprehensive platform that streamlines the data collection and labeling process, allowing users to efficiently manage large datasets. With tools for image classification and annotation, teams can easily organize and prepare data for training AI models, ensuring a scalable solution for growing operations.
Encord allows for the registration of data from various sources such as S3, GCP, and Azure, enabling users to manage large datasets efficiently. Data can be streamed directly from these buckets without needing to upload it to the Encord platform, which is particularly useful for handling extensive data volumes.
Encord provides a role-based access control feature that ensures users have appropriate access to data at each stage of the annotation workflow. This includes the ability to assign specific roles to users, determining who can view or edit data during various phases of the labeling process.
Encord includes advanced workflow capabilities designed for robust quality assurance and task management. Users can split up various annotation tasks for the same video, ensuring that multiple aspects of the content are annotated simultaneously, which enhances productivity.
Encord is designed to accommodate growing annotation needs by streamlining workflows and automating manual tasks. As teams increase in size or complexity, Encord's features help manage larger volumes of data and provide robust review mechanisms to maintain quality.
Encord provides robust text and image annotation capabilities, including support for languages such as Polish and other Eastern European languages. This flexibility allows teams to annotate diverse datasets while ensuring accuracy in various regional contexts.
Encord supports various annotation and curation tasks, including logo detection and captioning. The platform allows for auto-labeling to enhance speed in object detection tasks and provides visualization data curation features to streamline the process.
Yes, Encord provides capabilities to simplify the annotation of data for training large language models. The platform is designed to support complex AI tasks and can help teams efficiently create and manage datasets tailored for LLM applications.
Yes, Encord can manage large images by allowing users to zoom in and out for detailed annotation. The platform supports efficient navigation with shortcuts for zooming and recentering, ensuring that users can easily work with extensive datasets.
Yes, Encord supports a range of languages for annotation tasks, including English, Chinese, Tamil, Malay, Thai, and Vietnamese. This makes our platform versatile for projects that require cultural and linguistic considerations.