[Masterclass Recap] Building Robust 3D Data Pipelines: From Manual Cuboids to Scalable Workflows

Co-Founder & CEO at Encord
Manual 3D cuboid labeling doesn’t scale.
As point cloud datasets grow in size and complexity, drawing cuboids frame by frame becomes slow and expensive in building production-ready autonomous systems.
In our latest masterclass, Blake Cunningham (Senior Product Manager) and Oliver (Software Engineer) from Encord’s Physical AI team demonstrated how to transition from manual-first labeling to automated, human-in-the-loop (HITL) workflows.
Here’s what we learned.
The Breaking Point of Manual 3D Labeling
Even with sophisticated tools, manual cuboid annotation has inherent limits. In the first masterclass, the team demonstrated how modern 3D tooling enables annotators to create cuboids efficiently, interpolate them across time, adjust ground planes, merge sparse point clouds, and verify objects using synchronized camera views.
These capabilities dramatically improve precision and consistency. However, this is the first step in the data development pipeline. For those using traditional labeling tools, a fundamental bottleneck remains later in the workflow: humans still have to draw every box.
As datasets scale, especially in autonomous driving and robotics, that approach quickly becomes unsustainable. More scenes mean more frames. More frames mean more cuboids. And more cuboids mean exponential increases in time and cost.
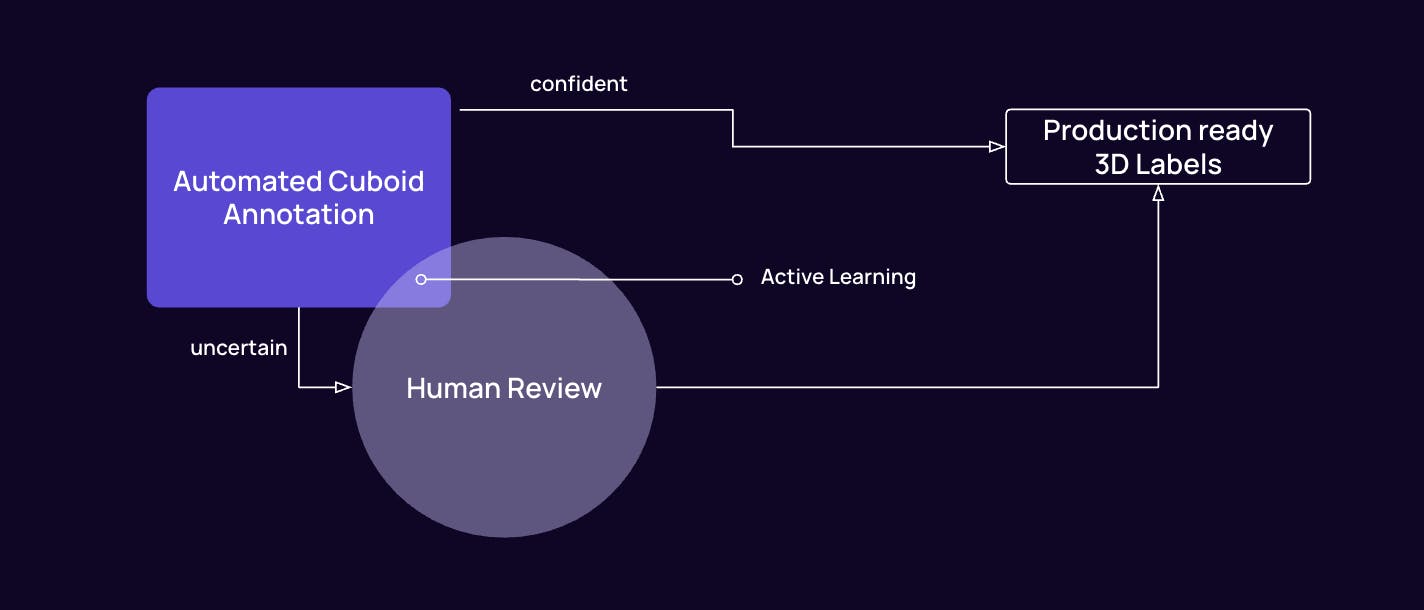
The Shift to Human-in-the-Loop Automation
The central idea of the session was simple but powerful: let models generate cuboids, and let humans ensure they’re correct.
Instead of starting from zero, annotators begin with model-generated 3D bounding boxes. High-confidence detections, like clearly visible vehicles, often require little more than a quick verification. Less certain predictions can be adjusted with precise tools. Missed objects can still be added manually when needed.
This shift transforms the annotator’s role. They move from constructing labels frame by frame to reviewing, refining, and handling edge cases.
In practice, this dramatically accelerates the labeling process. Scenes that once required painstaking manual work can now be completed five to ten times faster without compromising quality.
What Scalable 3D Annotation Looks Like in Practice
During the live demo, we saw how automation integrates directly into the annotation workflow.
Annotators operate within a multi-modal environment where 3D point clouds and synchronized 2D camera feeds are visible simultaneously. This makes verification intuitive. A cuboid can be inspected in 3D space, then instantly cross-checked against camera footage to confirm alignment, orientation, and class.
Temporal navigation is built in. Rather than treating each frame independently, cuboids persist across time. Annotators simply step through the sequence, correcting drift or misalignment only when it appears. This preserves consistency and avoids redundant work.
Visualization modes also play a critical role in speed and clarity. Coloring the point cloud by height or distance helps objects stand out. Image-based coloring (which samples actual camera pixel colors) makes lane markings and road features far easier to identify. Merged point cloud mode aggregates points across time, reconstructing a fuller view of the scene and compensating for sparse LiDAR frames.
These aren’t cosmetic features. They reduce cognitive load and directly accelerate correction workflows.
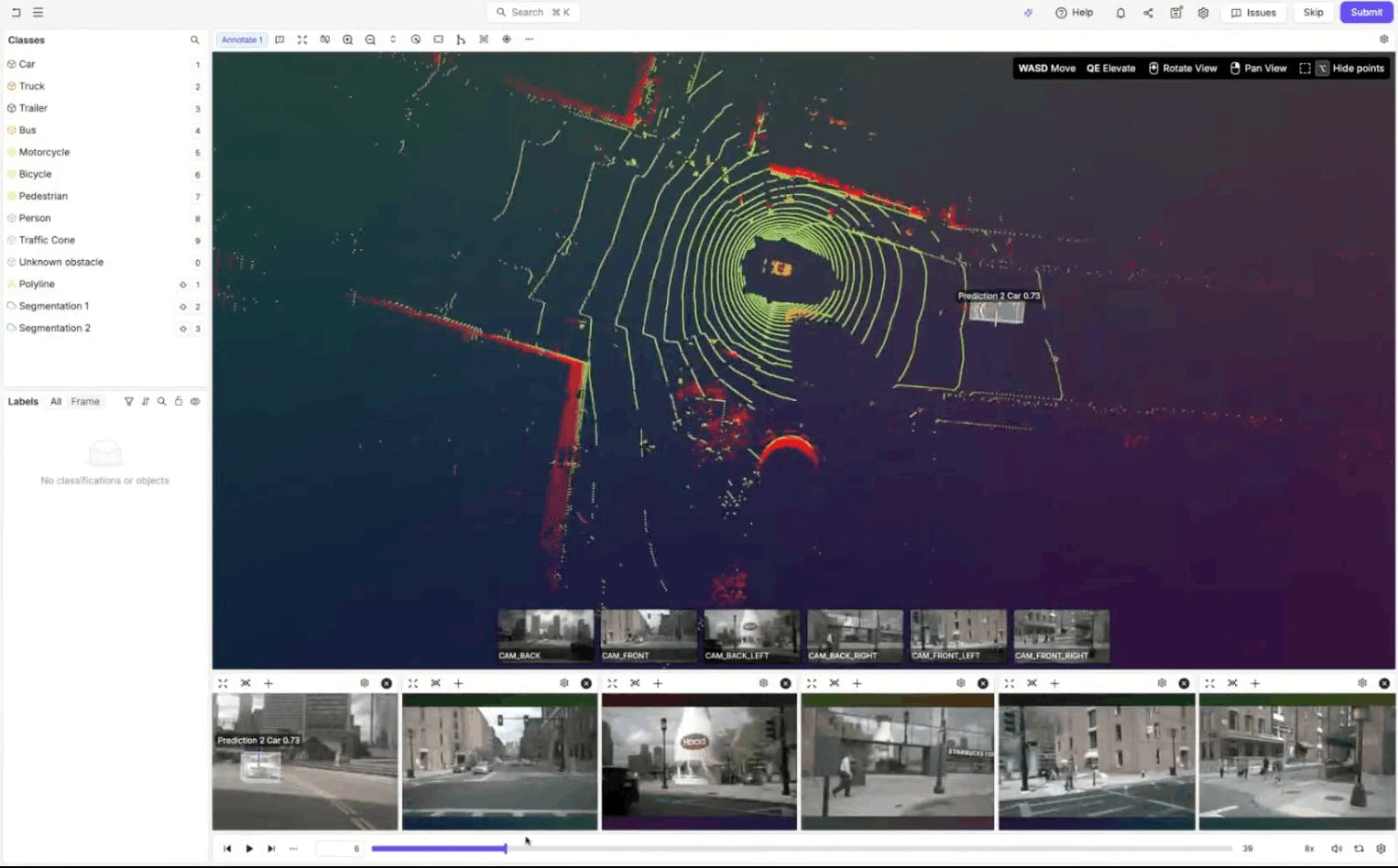
Coloring modes on LiDAR annotation in Encord
From Construction to Validation
One of the most compelling demonstrations showed how dense environments, such as parking lots filled with vehicles, can be handled efficiently.
Rather than manually drawing every cuboid, annotators can bulk-select model predictions and assign classes in a single action. Only the few incorrect or missing cases require intervention.
Even refinement is streamlined. Features like “fit cuboid to points” allow annotators to automatically tighten bounding boxes around point clusters, eliminating the need for tedious fine adjustments.
The workflow becomes less about building labels and more about validating and polishing them.
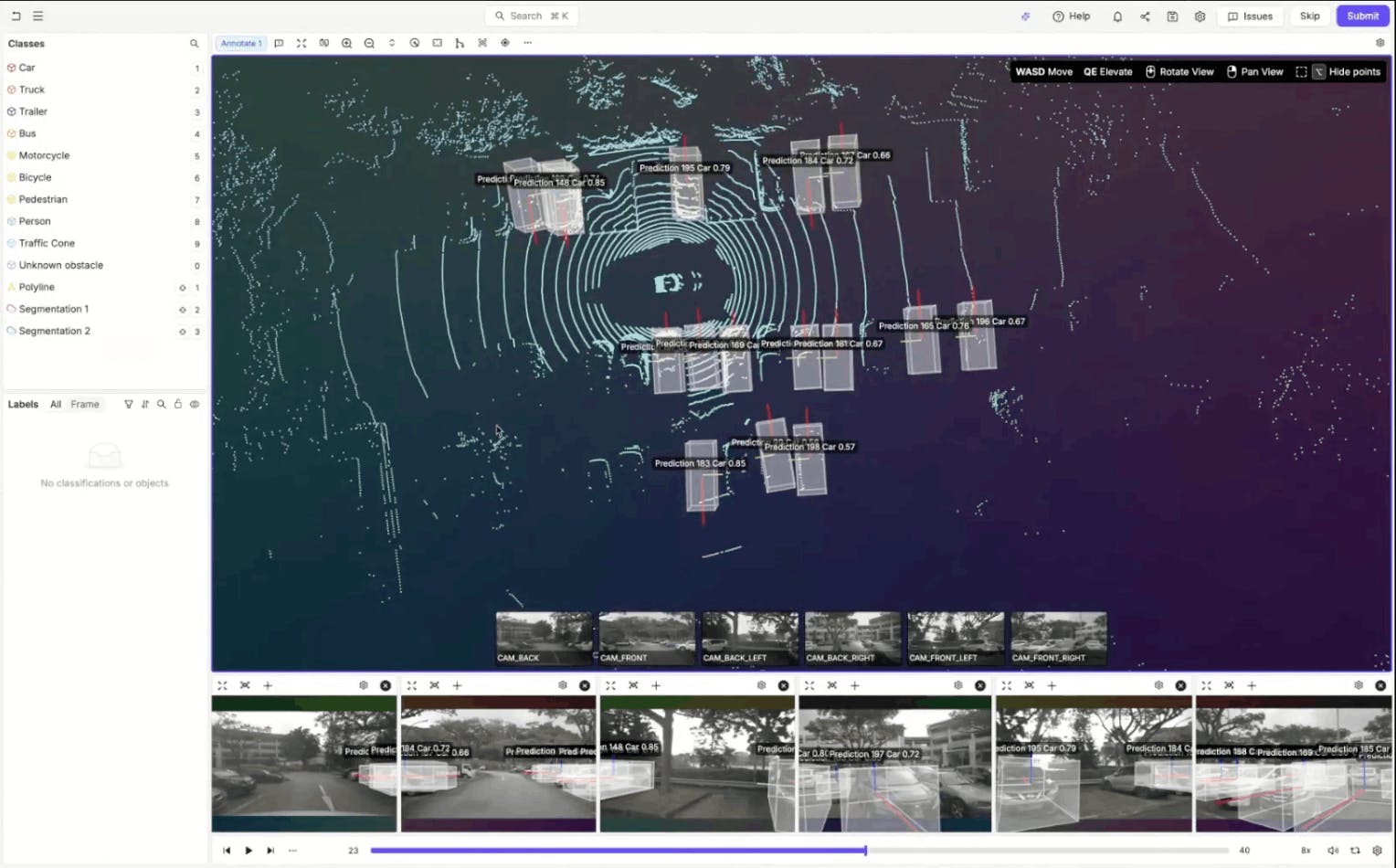
Example of dense parking lot scene in Encord LiDAR annotation interface
Handling Noise and Complexity in 3D Scenes
Audience questions highlighted common real-world challenges, particularly noise in point clouds.
The demo addressed this with a scene slicing tool that allows annotators to isolate spatial regions. By temporarily restricting edits to a selected area, they can segment pedestrians or small objects without accidentally capturing background points aligned in depth.
This is especially valuable in crowded urban scenes, where overlapping point clusters can otherwise complicate segmentation.
The platform also supports more than cuboids. Polylines for lane markings, segmentation masks, and keypoints can all be created within the same 3D environment. Combined with temporal merging, annotators can label extended structures, like road lines, consistently across frames in a single pass.
Why Temporal Context Matters
A recurring theme throughout the session was the importance of time.
Traditional labeling workflows often treat each frame as an isolated task. But autonomous systems don’t operate frame by frame. They operate in continuous sequences.
By leveraging temporal interpolation and persistent objects, annotators maintain consistency across scenes. Instead of recreating labels repeatedly, they adjust only where necessary. This not only improves efficiency but also enhances training data quality by ensuring stable object tracking across time.
The Virtuous Cycle of Better Automation
Perhaps the most powerful takeaway is what happens after annotation.
Corrected cuboids don’t just serve as training data. They feed back into the model, improving future predictions. As models improve, fewer corrections are needed. As fewer corrections are needed, annotation becomes faster. As annotation becomes faster, teams can scale datasets more aggressively.
This creates a virtuous cycle where automation handles the majority of straightforward cases and humans focus on the rare, high-value edge cases that truly improve model robustness.
Over time, the system becomes both faster and more accurate.
The Future of 3D Data Pipelines
For ML engineers building autonomous driving or robotics systems, and for data operations teams managing large-scale 3D labeling efforts, the message is clear: manual-first cuboid workflows are reaching their limits.
Models generate. Humans refine. Data improves. Models improve again.
By moving beyond drawing every cuboid from scratch and embracing human-in-the-loop automation, teams can transform annotation from a bottleneck into a scalable engine for building robust, production-ready 3D AI systems.
If your 3D pipeline still starts with a blank cuboid tool, it may be time to rethink how you scale.