Best Practices for Handling Unstructured Data Efficiently

With more than 5 billion users connected to the internet, a deluge of unstructured data is flooding organizational systems, giving rise to the big data phenomenon. Research shows that modern enterprise data consists of around 80 to 90% unstructured datasets, with the volume growing three times faster than structured data.
Unstructured data—consisting of text, images, audio, video, and other forms of non-tabular data—does not conform to conventional data storage formats. Traditional data management solutions often fail to address the complexities prevalent in unstructured data, causing valuable information loss.
However, as organizations become more reliant on unstructured data for building advanced computer vision (CV) and natural language processing (NLP) models, managing unstructured data becomes a high-priority and strategic goal.
This article will discuss the challenges and best practices for efficiently managing unstructured data. Moreover, we will also discuss popular tools and platforms that assist in handling unstructured data efficiently.
What is Unstructured Data?
Unstructured data encompasses information that does not adhere to a predefined data model or organizational structure. This category includes diverse data types such as text documents, audio clips, images, and videos.
Unlike structured data, which fits neatly into relational database management systems (RDBMS) with its rows and columns, unstructured data presents unique challenges for storage and analysis due to its varied formats and often larger file sizes.
Despite its lack of conventional structure, unstructured data holds immense value, offering rich insights across various domains, from social media sentiment analysis to medical imaging.
The key to unlocking this potential is specialized database systems and advanced data management architectures, such as data lakes or data management and curation tools like Encord Index, which enable efficient storage, indexing, and workflows for processing large, complex multimodal datasets.
Processing unstructured data often involves converting it into a format that machines can understand, such as transforming text into vector embeddings for computational analysis.
Characteristics of unstructured data include:
- Lack of Inherent Data Model: It does not conform to a standard organizational structure, making automated processing more complex.
- Multi-modal Nature: It spans various types of data, including but not limited to text, images, and audio.
- Variable File Sizes: While structured data can be compact, unstructured data files, such as high-definition videos, can be significantly larger.
- Processing Requirements: Unstructured data files require additional processing for machines to understand them. For example, users must convert text files to embeddings before performing any computer operation.
Understanding and managing unstructured data is crucial for utilizing its depth of information, driving insights, and informing decision-making.
The Need to Manage Unstructured Data
With an average of 400 data sources, organizations must have efficient processing pipelines to quickly extract valuable insights. These sources contain rich information that can help management with data analytics and artificial intelligence (AI) use cases.
Below are a few applications and benefits that make unstructured data management necessary.

- Healthcare Breakthroughs: Healthcare professionals can use AI models to diagnose patients using textual medical reports and images to improve patient care. However, building such models requires a robust medical data management and labeling system to store, curate, and annotate medical data files for training and testing.
- Retail Innovations: Sentiment analysis models transform customer feedback into actionable insights, enabling retailers to refine products and services. This process hinges on efficient real-time data storage and preprocessing to ensure data quality (integrity and consistency).
- Securing Sensitive Information: Unstructured data often contains sensitive information, such as personal data, intellectual property, confidential documents, etc. Adequate access management controls are necessary to help prevent such information from falling into the wrong hands. Implementing file access monitoring software allows organizations to track and audit all file access activities, identifying any unauthorized access attempts or suspicious behavior.
- Fostering Collaboration: Managing unstructured data means breaking data silos to facilitate collaboration across teams by establishing shared data repositories for quick access.
- Ensuring Compliance: With increasing concern around data privacy, organizations must ensure efficient, unstructured data management to comply with global data protection regulations.

Structured VS Semi-Structured VS Unstructured Data
Now that we understand unstructured data and why managing it is necessary, let’s briefly discuss how unstructured data differs from semi-structured and structured data.
The comparison will help you determine the appropriate strategies for storing, processing, and analyzing different data types to gain meaningful insights.
Structured Data
Conventional, structured data is usually in the form of tables. These data files have a hierarchy and maintain relationships between different data elements.
These hierarchies and relationships give the data a defined structure, making it easier to read, understand, and process. Structured data often resides in neat spreadsheets or relational database systems.
Semi-structured Data
Semi-structured data falls between structured and unstructured data, with some degree of organization.
While the information is not suitable for storage in relational databases, it has proper linkages and metadata that allow users to convert it into structured information via logical operations.
Standard semi-structured data files include CSVs, XML, and JSON. These file standards are versatile and transformable with no rigid schema, making them popular in modern software apps.
Unstructured Data
Unstructured data does not follow any defined schema and is challenging to manage and store. Customer feedback, social media posts, emails, and videos are primary examples of unstructured data, which includes unstructured text, images, and audio.
This data type holds rich information but requires a complex processing pipeline and information extraction methodologies to reveal actionable insights.
Unstructured Data Challenges
As discussed, organizations have a massive amount of unstructured data that remains unused for any productive purpose due to the complex nature of data objects.
Below, we discuss a few significant challenges to help you understand the issues and strategies to resolve them.
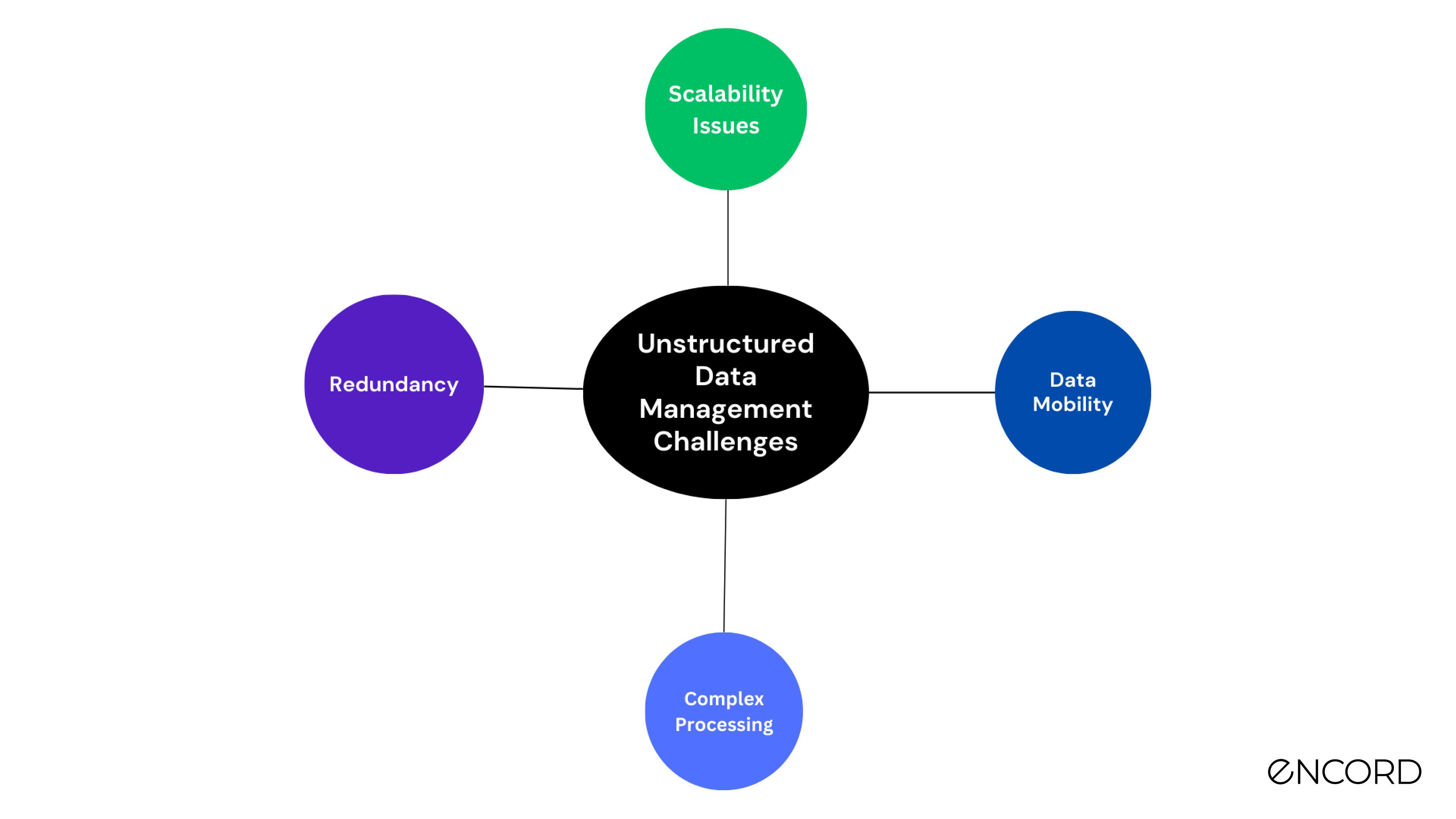
Scalability Issues
With unstructured data growing at an unprecedented rate, organizations face high storage and transformation costs, which prevent them from using it for effective decision-making.
The problem worsens for small enterprises operating on small budgets who cannot afford to build sophisticated in-house data management solutions.
However, a practical solution is to invest in a versatile management solution that scales with organizational needs and has a reasonable price tag.
Data Mobility
With unstructured data having extensive file sizes, moving data from one location to another can be challenging.
It also carries security concerns, as data leakage is possible when transferring large data streams to several servers.
Complex Processing
Multi-modal unstructured data is not directly usable in its raw form. Robust pre-processing pipelines specific to each modality must be converted into a suitable format for model development and analytics.
For example, image documents must pass through optical character recognition (OCR) algorithms to provide relevant information. Similarly, users must convert images and text into embeddings before feeding them to machine learning applications.
In addition, data transformations may cause information loss when converting unstructured data into machine-readable formats.
Solutions involve efficient data compression methods, automated data transformation pipelines, and cloud storage platforms to streamline data management.
Also, human-in-the-loop annotation strategies, ontologies, and the use of novel techniques to provide context around specific data items help mitigate issues associated with information loss.
Redundancy
Unstructured data can suffer from redundancies by residing on multiple storage platforms for use by different team members. Also, the complex nature of these data assets makes tagging and tracking changes to unstructured data challenging.
Modifications in a single location imply updating the dataset across multiple platforms to ensure consistency. However, the process can be highly labor-intensive and error-prone.
A straightforward solution is to develop a centralized storage repository, such as a data warehouse, with a self-service data platform that lets users automatically share updates with metadata describing the details of the changes made. However, the success of this approach hinges on careful data warehouse design, considering factors such as data volume, velocity, variety, and the specific analytical needs of the organization.
Best Practices for Unstructured Data Management
While managing unstructured data can overwhelm organizations, observing a few best practices can help enterprises leverage their full potential efficiently.
The following sections discuss five practical and easy-to-follow strategies to manage unstructured data cost-effectively.

1. Define Requirements and Use Cases
The first step is clearly defining the goals and objectives you want to achieve with unstructured data. Blindly collecting unstructured data from diverse sources will waste resources and create redundancy.
Defining end goals will help you understand the type of data you want to collect, the insights you want to derive, the infrastructure and staff required to handle data storage and processing, and the stakeholders involved.
It will also allow you to create key performance indicators (KPIs) to measure progress and identify areas for optimization.
2. Data Governance
Once you know your goals, it is vital to establish a robust data governance framework to maintain data quality, availability, security, and usability.
The framework should establish procedures for collecting, storing, accessing, using, updating, sharing, and archiving unstructured data across organizational teams to ensure data consistency, integrity, and compliance with regulatory guidelines.
3. Metadata Management
Creating a metadata management system is crucial to the data governance framework. It involves establishing data catalogs, glossaries, metadata tags, and descriptions to help users quickly discover and understand details about specific data assets.
For instance, metadata may include the user's details of who created a particular data asset, version history, categorization, format, context, and reason for creation.
Further, linking domain-specific terms to glossaries will help different teams learn the definitions and meanings of specific data objects to perform data analysis more efficiently.
The process will also involve indexing and tagging data objects for quick searchability. It will let users quickly sort and filter data according to specific criteria.
4. Using Informational Retrieval Systems
After establishing metadata management guidelines within a comprehensive data governance framework, the next step involves implementing them in an informational retrieval (IR) system.
Organizations can store unstructured data with metadata in these IR systems to enhance searchability and discoverability.
They can use modern IR systems with advanced AI algorithms to help users search for specific data items using natural language queries. For instance, a user can fetch particular images by describing the image's content in a natural language query.
5. Use Data Management Tools
While developing governance frameworks, metadata management systems, and IR platforms from scratch is one option, using data management tools is a more cost-effective solution.
The tools have built-in features for governing data assets with collaborative functionality and IR systems to automate data management. Tools like Encord Index provide data curation and data management allowing organizations to efficiently organize, curate, and visualize their datasets. Encord Index enhances workflow efficiency by offering robust tools for data quality assurance, metadata management, and customized workflows, ensuring that data assets are optimized for machine learning applications.

Investing in these tools can save organizations the costs, time, and effort of building an internal management system.
Features to Consider in a Data Management Tool
Although a data management tool can streamline unstructured data management, choosing an appropriate platform that suits your needs and existing infrastructure is crucial.
However, with so many tools in the marking process, selecting the right one is challenging. The following list highlights the essential features you should look for when investing in a data management solution to help you determine the best option.

- Scalability: Look for tools that can easily scale in response to your organization's growth or fluctuating data demands. This includes handling increased data volumes and user numbers without performance degradation.
- Collaboration: Opt for tools that facilitate teamwork by allowing multiple users to work on shared projects efficiently. Features should include tracking progress, providing feedback, and managing permissions.
- User Interface (UI): Choose a platform with a user-friendly, no-code interface that simplifies navigation. Powerful search capabilities and data visualization tools, such as dashboards that effectively summarize unstructured data, are also crucial.
- Integration: Ensure the tool integrates seamlessly with existing cloud platforms, third-party cloud integration tools and supports external plugins to improve functionality and customization.
- Pricing: Consider the total cost of ownership, which includes the initial installation costs and ongoing expenses for maintenance and updates. Evaluate whether the pricing model aligns with your budget and offers good value for the features provided.
Tools for Efficient Unstructured Data Management
Multiple providers offer unstructured data management tools with several features to streamline the management process.
The list below gives an overview of the top five management platforms ranked according to scalability, collaboration, UI, integration, and pricing.
#1. Encord Index
Encord Index is an end-to-end data management and curation product of the Encord platform. It provides features to clean unstructured data, understand it, and select the most relevant data for labeling and analysis.
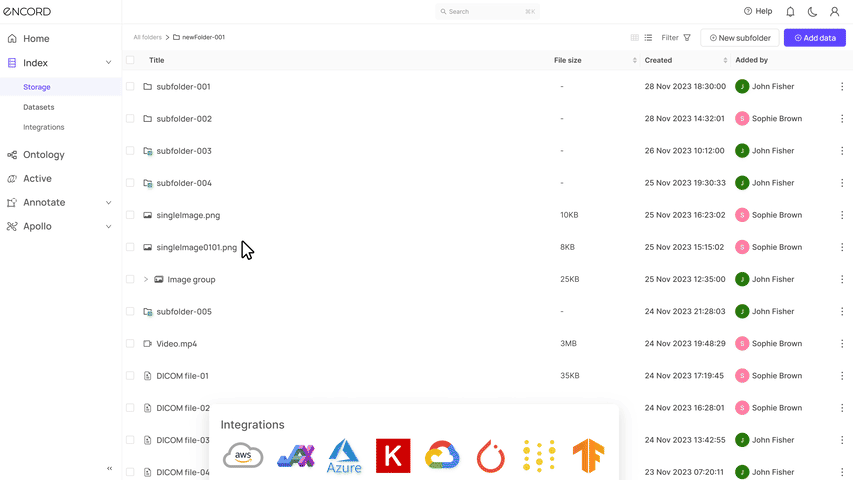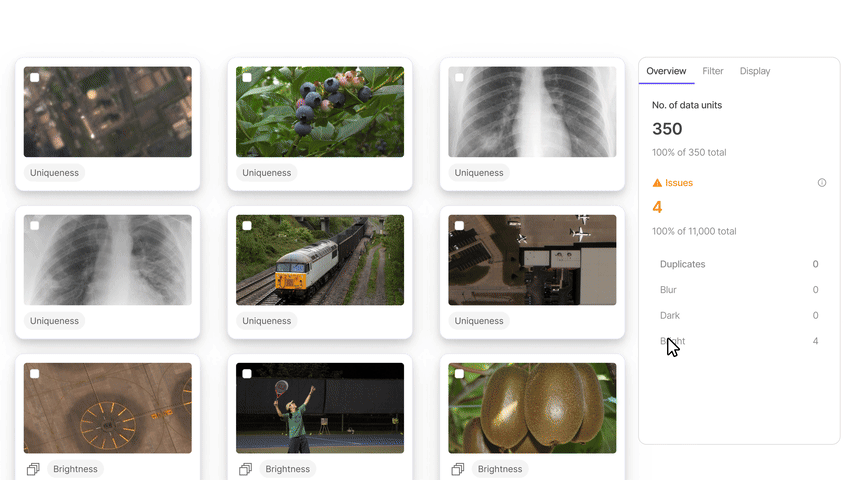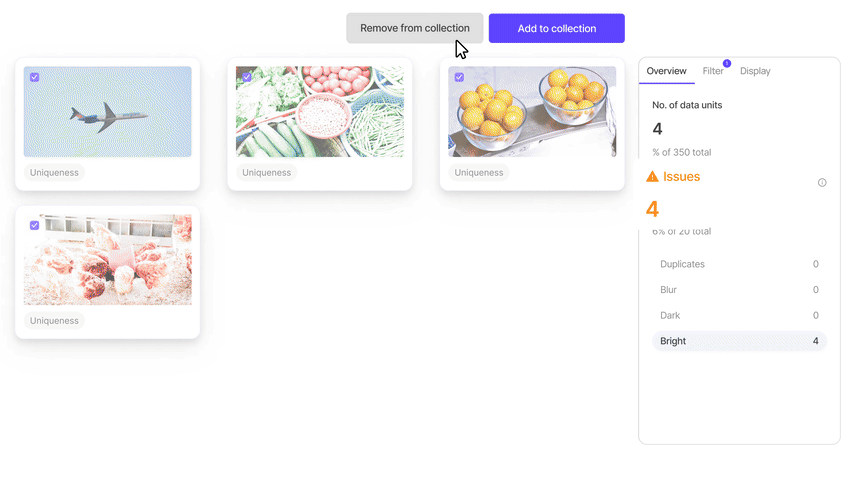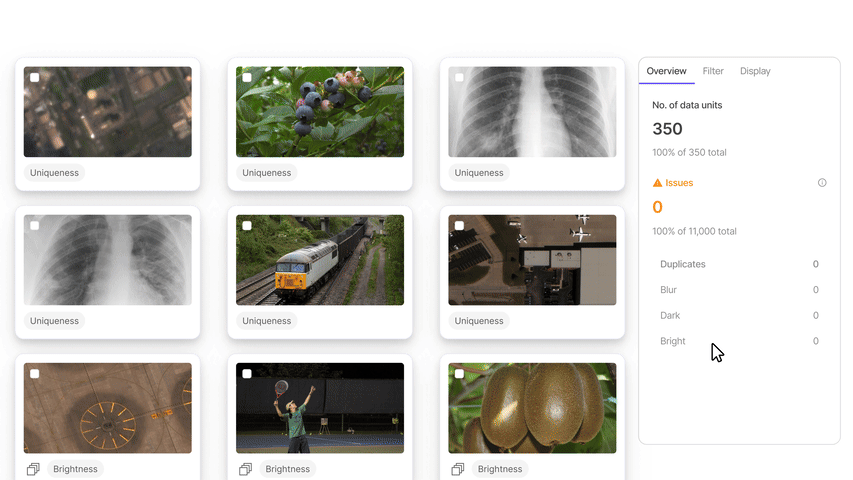
Application
The Encord index allows users to preprocess and search for the most relevant data items for training models.
Key Features
- Scalability: The platform allows you to upload up to 500,000 images (recommended), 100 GB in size, and 5 million labels per project. You can also upload up to 200,000 frames per video (2 hours at 30 frames per second) for each project. See more guidelines for scalability in the documentation.
- Collaboration: To manage tasks at different stages, you can create workflows and assign roles to relevant team members. User roles include admin, team member, reviewer, and annotator.
- User Interface: Encord has an easy-to-use interface and an SDK to manage data. Users also benefit from an intuitive natural language search feature that lets you find data items based on general descriptions in everyday language.
- Integration: Encord integrates with popular cloud storage platforms, such as AWS, Google Cloud, Azure, and Open Telekom Cloud OSS.
Best For
- Small to large enterprises looking for an all-in-one data management and annotation solution.
Pricing
- Encord Annotate has a pay-per-user pricing model with Starter, Team, and Enterprise options.
#2. Apache Hadoop
Apache Hadoop is an open-source software library that offers distributed computing to process large-scale datasets. It uses the Hadoop-distributed file system to access data with high throughput.

Application
Apache Hadoop lets users process extensive datasets with low latency using parallel computing.
Key Features
- Scalability: The platform is highly scalable and can support multiple data storage and processing machines.
- Collaboration: Apache Atlas is a framework within Hadoop that offers collaborative features for efficient data governance.
- Integration: The platform can integrate with any storage and analytics tools.
Best for
- Teams having expert staff with data engineering skills.
Pricing
- The platform is open-source.
#3. Astera
Astera offers ReportMiner, an unstructured data management solution that uses AI to extract relevant insights from documents of all formats.
It features automated pipelines that allow you to schedule extraction jobs to transfer the data to desired analytics or storage solutions.

Application
Astera helps organizations process and analyze textual data through a no-code interface.
Key Features
- Scalability: ReportMiner’s automated data extraction, processing, and mapping capabilities allow users to quickly scale up operations by connecting multiple data sources to the platform for real-time management.
- Collaboration: The platform allows you to add multiple users with robust access management.
- User Interface: Astera offers a no-code interface with data visualization and preview features.
Best For
- Start-ups looking for a cost-effective management solution to process textual documents.
Pricing
- Pricing is not publicly available.
#4. Komprise
Komprise is a highly scalable platform that uses a global file index to help search for data items from massive data repositories. It also has proprietary Transparent Move Technology (TMT) to control and define data movement and access policies.

Application
Komprise simplifies data movement across different organizational systems and breaks down data silos.
Key Features
- Scalability: The Komprise Elastic Grid allows users to connect multiple data storage platforms and have Komprise Observers manage extensive workloads efficiently.
- User Interface: The Global File Index tags and indexes all data objects, providing users with a Google-like search feature.
- Integration: Komprise connects with cloud data storage platforms like AWS, Azure, and Google Cloud.
Best For
- Large-scale enterprises looking for a solution to manage massive amounts of user-generated data.
Pricing
- Pricing is not publicly available.
#5. Azure Stream Analytics
Azure Stream Analytics is a real-time analytics service that lets you create robust pipelines to process streaming data using a no-code editor.
Users can also augment these pipelines with machine-learning functionalities through custom code.

Application
Azure Stream Analytics helps process data in real-time, allowing instant streaming data analysis.
Key Features
- Scalability: Users can run Stream Analytics in the cloud for large-scale data workloads and benefit from Azure Stack’s low-latency analytics capabilities.
- User Interface: The platform’s interface lets users quickly create streaming pipelines connected with edge devices and real-time data ingestion.
- Integration: Azure Stream Analytics integrates with machine learning pipelines for sentiment analysis and anomaly detection.
Best for
- Teams looking for a real-time data analytics solution.
Pricing
- The platform charges based on streaming units.
Case Study
A large e-commerce retailer experienced a sudden boost in online sales, generating extensive data in the form of:
- User reviews on social media platforms.
- Customer support conversations.
- Search queries the customers used to find relevant products on the e-commerce site.
The challenge was to exploit the data to analyze customer feedback and gain insights into customer issues. The retailer also wanted to identify areas for improvement to enhance the e-commerce platform's customer journey.
Resolution Approach
The steps below outline the retailer’s approach to effectively using the vast amounts of unstructured data to help improve operational efficiency.
1. Goal Identification
The retailer defined clear objectives, which included systematically analyzing data from social media, customer support logs, and search queries to identify and address customer pain points. Key performance indicators (KPIs) were established to measure the success of implemented solutions, such as customer satisfaction scores, number of daily customer issues, repeat purchase rates, and churn rates.
2. Data Consolidation
A scalable data lake solution was implemented to consolidate data from multiple sources into a central repository. Access controls were defined to ensure relevant data was accessible to appropriate team members.
3. Data Cataloging and Tagging
Next, the retailer initiated a data cataloging and tagging scheme, which involved establishing metadata for all the data assets.
The purpose was to help data teams quickly discover relevant datasets for different use cases.
4. Data Pipelines and Analysis
The retailer developed automated pipelines to clean, filter, label, and transform unstructured data for data analysis.
This allowed data scientists to efficiently analyze specific data subsets, understand data distributions and relationships, and compute statistical metrics.
5. NLP Models
Next, data scientists used relevant NLP algorithms for sentiment analysis to understand the overall quality of customer feedback across multiple domains in the purchasing journey.
They also integrated the search feature with AI algorithms to fetch the most relevant product items based on a user’s query.
6. Implementation of Fixes
Once the retailer identified the pain points through sentiment analysis and enhanced the search feature, it developed a refined version of the e-commerce site and deployed it in production.
7. Monitoring
The last step involved monitoring the KPIs to ensure the fixes worked. The step involved direct intervention from higher management to collaborate with the data team to identify gaps and conduct root-cause analysis for KPIs that did not reach their targets.
The above highlights how a typical organization can use unstructured data management to optimize performance results.
Results and Impact
- Customer satisfaction scores increased by 25% within three months of implementing the refined e-commerce site.
- Daily customer issues decreased by 40%, indicating a significant reduction in customer pain points.
- Repeat purchase rates improved by 15%, suggesting enhanced customer loyalty and satisfaction.
Inference: Lessons Learned
- Effective data governance, including clear access controls and data cataloging, is crucial for efficient utilization of unstructured data.
- Cross-functional collaboration between data teams, management, and customer-facing teams is essential for identifying and addressing customer pain points.
- Continuous monitoring and iterative improvements based on KPIs are necessary to ensure the long-term success of data-driven solutions.
Unstructured Dataset Management: Key Takeaways
Managing unstructured data is critical to success in the modern digital era. Organizations must quickly find cost-effective management solutions to streamline data processes and optimize their products.
Below are a few key points to remember regarding unstructured data management.
- Unstructured Data Features: Unstructured data has no pre-defined format, large file sizes, and a multi-modal nature.
- The Need for Unstructured Management: Managing unstructured data can allow organizations to analyze the data objects to reveal valuable insights for decision-making.
- Challenges and Best Practices: The primary challenge with unstructured data management is scalability. Solutions and best practices involve identifying goals, implementing governance frameworks, managing metadata, and using management tools for storage, processing, and analysis.
- Best Unstructured Data Management Tools: Encord Index, Apache Hadoop, and Asetra are popular tools for managing large-scale unstructured data.
Frequently asked questions
You can manage unstructured data by storing it in a centralized location, implementing data governance frameworks, and using data management tools to automate data processing.
Apache Hadoop and Encord Index are popular tools for handling unstructured data.
Identify goals you want to achieve from unstructured data, analyze its nature and context, and use appropriate analytics and modeling techniques according to data modality to extract insights.
Data privacy and security concerns call for robust access management controls and tagging systems to track changes and maintain logs.
Mainstream processing methods include optical Character Recognition (OCR), sentiment analysis, image, audio, and text classification.
Natural Language Processing (NLP) is the most useful technique for understanding unstructured data.
NoSQL databases like MongoDB are best for handling unstructured data.
Encord is designed to tackle common data management challenges in machine learning projects, such as handling large data volumes and ensuring data quality. With features that automate data pipelines and facilitate easy access to relevant data, Encord helps teams maintain high standards while efficiently scaling their operations.
Encord offers a platform designed to streamline the management of large datasets, allowing teams to efficiently curate and evaluate data for autonomous vehicle training. With tools tailored to highlight interesting events and anomalies, Encord helps teams focus on critical insights that drive model improvement.
Data curation can be challenging, especially when dealing with large volumes of documents and needing to extract specific insights. Encord addresses these challenges by providing advanced indexing capabilities to help users find relevant data quickly and efficiently, reducing manual effort.
Encord is designed to facilitate data management for machine learning by providing seamless data ingestion and export capabilities. Users can easily manage their datasets and export labeled data for training models, ensuring a streamlined workflow from annotation to application.
Encord focuses on the data operations segment of the machine learning pipeline. While we do not source or host data, nor train models, we provide essential tools for data cleaning, curation, and preparation that are crucial for developing high-performing machine learning models.
Encord simplifies data management by allowing users to utilize metadata for searching through vast datasets at scale. This capability helps quickly locate relevant files for annotation and effectively manage labeling workflows, reducing the time and effort typically involved.
Encord provides robust data ingestion workflows that streamline the entry of various data types into the platform. This ensures that users can effectively manage and preprocess their data for machine learning tasks, enhancing the efficiency of the annotation process.
Encord frequently assists clients in managing unstructured data by offering features that facilitate the cleaning of data and the creation of organized collections. This helps ensure that annotators focus on relevant, high-quality information throughout their tasks.
Encord is designed to handle various types of datasets, including large and complex datasets. The platform supports scalable data management and annotation, making it adaptable for different use cases and industries.
Users can manage data granularity effectively within Encord, allowing for tailored data analysis that meets specific business needs. This ensures that users maintain control over their internal data management.