Diffusion Transformer (DiT) Models: A Beginner’s Guide

Introduction to Diffusion Models
Diffusion models are a type of generative model that simulates a Markov chain to transition from a simple prior distribution to the data distribution. The process is akin to a particle undergoing Brownian motion, where each step is a small random walk. This is why they are called “diffusion” models.
Diffusion models have been used in various applications such as denoising, super-resolution, and inpainting. One of the key advantages of diffusion models is their ability to generate high-quality samples, which makes them particularly useful in tasks such as image synthesis.
Convolutional U-NET Architecture
The U-Net architecture is a type of convolutional neural network (CNN) that was developed for biomedical image segmentation. The architecture is designed like a U-shape, hence the name U-Net. It consists of a contracting path (encoder) to capture context and a symmetric expanding path (decoder) for precise localization.
The U-Net architecture is unique because it concatenates feature maps from the downsampling path with feature maps from the upsampling path. This allows the network to use information from both the context and localization, enabling it to make more accurate predictions.
Vision Transformers
Vision Transformers (ViT) are a recent development in the field of computer vision that apply transformer models, originally designed for natural language processing tasks, to image classification tasks. Unlike traditional convolutional neural networks (CNNs) that process images in a hierarchical manner.
ViTs treat images as a sequence of patches and capture global dependencies between them. This allows them to model long-range, pixel-level interactions. One of the key advantages of ViTs is their scalability. They can be trained on large datasets and can benefit from larger input image sizes.
Classifier-Free Guidance
Classifier-free guidance refers to the approach of guiding a model’s learning process without the use of explicit classifiers. This can be achieved through methods such as self-supervision, where the model learns to predict certain aspects of the data from other aspects, or through reinforcement learning, where the model learns to perform actions that maximize a reward signal.
Classifier-free guidance can be particularly useful in situations where labeled data is scarce or expensive to obtain. It allows the model to learn useful representations from the data itself, without the need for explicit labels.
Understanding Latent Diffusion Models (LDMs)
Latent Diffusion Models (LDMs) are a type of generative model that learn to generate data by modeling it as a diffusion process. This process begins with a simple prior, such as Gaussian noise, and gradually transforms it into the target distribution through a series of small steps. Each step is guided by a neural network, which is trained to reverse the diffusion process. LDMs have been successful in generating high-quality samples in various domains, including images, text, and audio.
Convolutional U-NET Backbone: Disadvantages
Convolutional U-NETs have been a staple in many computer vision tasks due to their ability to capture local features and maintain spatial resolution. However, they have certain limitations. For one, they often struggle with capturing long-range dependencies and global context in the input data. This is because the receptive field of a convolutional layer is local and finite, and increasing it requires deeper networks and larger filters, which come with their own set of challenges.
Moreover, the convolution operation in U-NETs is translation invariant, which means it treats a feature the same regardless of its position in the image. This can be a disadvantage in tasks where the absolute position of features is important.
Shifting towards Transformer Backbone
Transformers, originally designed for natural language processing tasks, have shown great potential in computer vision tasks. Unlike convolutional networks, transformers can model long-range dependencies without the need for deep networks or large filters. This is because they use self-attention mechanisms, which allow each element in the input to interact with all other elements, regardless of their distance. Moreover, transformers are not translation invariant, which means they can capture the absolute position of features. This is achieved through the use of positional encodings, which add information about the position of each element in the input.
Evolution of Latent Patches
The concept of latent patches evolved from the need to make transformers computationally feasible for high-resolution images. Applying transformers directly to the raw pixels of high-resolution images is computationally expensive because the complexity of self-attention is quadratic in the number of elements. To overcome this, the image is divided into small patches, and transformers are applied to these patches. This significantly reduces the number of elements and hence the computational complexity. This allows transformers to capture both local features within each patch and global context across patches.
Diffusion Transformers (DiT) Vs. Vision Transformers (ViT)
While both DiT and ViT use transformers as their backbone and operate on latent patches, they differ in how they generate images and their specific architectural details.
Diffusion Transformers (DiT)
DiT uses transformers in a latent diffusion process, where a simple prior (like Gaussian noise) is gradually transformed into the target image. This is done by reversing the diffusion process guided by a transformer network. An important aspect of DiT is the concept of diffusion timesteps. These timesteps represent the stages of the diffusion process, and the transformer network is conditioned on the timestep at each stage. This allows the network to generate different features at different stages of the diffusion process. DiT can also be conditioned on ‘class labels’, allowing it to generate images of specific classes.
Vision Transformers (ViT)
ViT uses transformers to directly generate the image in an autoregressive manner, where each patch is generated one after the other, conditioned on the previously generated patches. A key component of ViT is the use of adaptive layer norm layers (adaLN). These layers adaptively scale and shift the features based on the statistics of the current batch, which helps in stabilizing the training and improving the model’s performance. While both approaches have their strengths and weaknesses, they represent two promising directions for leveraging transformers in generative modeling of images. The choice between DiT and ViT would depend on the specific requirements of the task at hand.
For instance, if the task requires generating images of specific classes, DiT might be a better choice due to its ability to condition on class labels. On the other hand, if the task requires generating high-resolution images, ViT might be more suitable due to its use of adaLN layers, which can help in stabilizing the training of large models.
Scalable Diffusion Models with Transformers
Scalable Diffusion Models with Transformers (DiT) leverage the power of transformers to handle complex tasks involving large-scale data. The scalability of these models allows them to maintain or even improve their performance as the size of the input data increases. This makes them particularly suited for tasks such as natural language processing, image recognition, and other applications where the amount of input data can vary greatly.
Here are some of the features of scalable diffusion models:
Gflops - Forward Pass Measurement
Gflops, short for gigaflops, is a unit of measurement that quantifies the performance of a computer’s floating-point operations. In the context of machine learning and neural networks, the forward pass measurement in Gflops is crucial as it provides an estimate of the computational resources required for a single forward pass through the network. This measurement is particularly important when dealing with large-scale networks or data, where computational efficiency can significantly impact the feasibility and speed of model training. Lower Gflops indicates a more efficient network in terms of computational resources, which can be a critical factor in resource-constrained environments or real-time applications.
Network Complexity vs. Sample Quality
The complexity of a neural network is often directly related to the quality of the samples it produces. More complex networks, which may have more layers or more neurons per layer, tend to produce higher quality samples. However, this increased complexity comes at a cost. More complex networks require more computational resources, both in terms of memory and processing power, and they often take longer to train.
Conversely, simpler networks are more computationally efficient and faster to train, but they may not capture the nuances of the data as well, leading to lower quality samples. Striking the right balance between network complexity and sample quality is a key challenge in the design of effective neural networks.
Variational Autoencoder (VAE)’s Latent Space
In a Variational Autoencoder (VAE), the latent space is a lower-dimensional space into which the input data is encoded. This encoding process is a form of dimensionality reduction, where high-dimensional input data is compressed into a lower-dimensional representation. The latent space captures the essential characteristics of the data, and it is from this space that new samples are generated during the decoding process.
The quality of the VAE’s output is largely dependent on how well the latent space captures the underlying structure of the input data. If the latent space is too small or not well-structured, the VAE may not be able to generate high-quality samples. If the latent space is well-structured and of appropriate size, the VAE can generate high-quality samples that accurately reflect the characteristics of the input data.
Scalability of DiT
Scalability is an important feature of Diffusion models with Transformers (DiT). As the size of the input data increases, the model should be able to maintain or improve its performance. This involves efficient use of computational resources and maintaining the quality of the generated samples.
For example, in natural language processing tasks, the size of the input data (i.e., the number of words or sentences) can vary greatly. A scalable DiT model should be able to handle these variations in input size without a significant drop in performance. Furthermore, as the amount of available data continues to grow, the ability of DiT models to scale effectively will become increasingly important.
DiT Scaling Methods
There are two primary methods for scaling DiT models: scaling the model size and scaling the number of tokens.
Scaling Model Size
Scaling the model size involves increasing the complexity of the model, typically by adding more layers or increasing the number of neurons in each layer. This can improve the model’s ability to capture complex patterns in the data, leading to improved performance. However, it also increases the computational resources required to train and run the model. Therefore, it’s important to find a balance between model size and computational efficiency.
Scaling Tokens
Scaling the number of tokens involves increasing the size of the input data that the model can handle. This is particularly relevant for tasks such as natural language processing, where the input data (i.e., text) can vary greatly in length. By scaling the number of tokens, a DiT model can handle longer texts without a significant drop in performance. However, similar to scaling the model size, scaling the number of tokens also increases the computational resources required, so a balance must be found.
Diffusion Transformers Generalized Architecture
Spatial Representations
The model first inputs spatial representations through a network layer, converting spatial inputs into a sequence of tokens. This process allows the model to handle the spatial information present in the image data. It’s a crucial step as it transforms the input data into a format that the transformer can process effectively.
Positional Embeddings
Positional embeddings are a critical component of the transformer architecture. They provide the model with information about the position of each token in the sequence. In DiTs, standard Vision Transformer based positional embeddings are applied to all input tokens. This process helps the model understand the relative positions and relationships between different parts of the image.
DiT Block Design
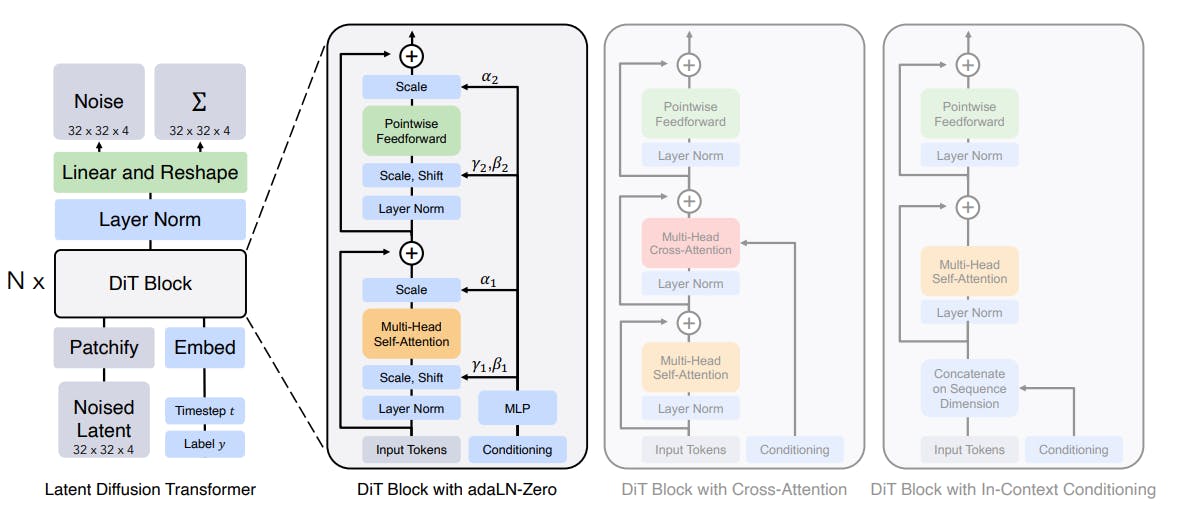
Diffusion Transformer Architecture
In a typical diffusion model, a U-Net convolutional neural network (CNN) learns to estimate the noise to be removed from an image. DiTs replace this U-Net with a transformer. This replacement shows that U-Net’s inductive bias is not necessary for the performance of diffusion models.
Variants of DiT blocks handle conditional information with the following blocks:
- In-context Conditioning
In-context conditioning in DiTs involves the use of adaptive layer normalization (adaLN) to inject conditional information into the model. - Cross-attention Block
The cross-attention in DiTs bridges the interaction between the diffusion network and the image encoder. It mixes two different embedding sequences, allowing the model to capture both local and global information. - Conditioning via Adaptive Layer Norm
An adaptive layer normalization (adaLN) is used to condition the diffusion network on text representations, enabling parameter-efficient adaptation. - Conditioning via Cross-attention
Cross-attention is used to bridge the interaction between the diffusion network and the image encoder. It allows attention layers to adapt their behavior at different stages of the denoising process. - Conditioning via Extra Input Tokens
While there is limited information available on conditioning via extra input tokens in DiTs, it is known that DiTs with higher Gflops—through increased transformer depth/width or increased number of input tokens—consistently have lower FID.
Model Size
DiT models range from 33M to 675M parameters and 0.4 to 119 Gflops. They are borrowed from the ViT literature which found that jointly scaling-up depth and width works well.
Transformer Decoder
The transformer decoder is an architectural upgrade that replaces U-Net with vision transformers (ViT), showing U-Net inductive bias is not necessary for the performance of diffusion models.
Training and Inference
During training, a diffusion model takes an image to which noise has been added, a descriptive embedding, and an embedding of the current time step. The system learns to use descriptive embedding to remove the noise in successive time steps. At inference, it generates an image by starting with pure noise and a descriptive embedding and removing noise iteratively according to that embedding.
Evaluation Metrics
The quality of DiT’s output is evaluated according to Fréchet Interception Distance (FID), which measures how the distribution of a generated version of an image compares to the distribution of the original (lower is better).
FID improves depending on the processing budget. On 256-by-256-pixel ImageNet images, a small DiT with 6 gigaflops of compute achieves 68.4 FID, a large DiT with 80.7 gigaflops achieves 23.3 FID, and the largest DiT with 119 gigaflops achieves 9.62 FID. A latent diffusion model that used a U-Net (104 gigaflops) achieves 10.56 FID.
DiT-XL/2 Models: Trained Versions
The DiT-XL/2 models are a series of generative models released by Meta. These models are trained on the ImageNet dataset, a large visual database designed for use in visual object recognition research. The XL/2 in the name refers to the resolution at which the models are trained, with two versions available: one for 512x512 resolution images and another for 256x256 resolution images.
512x512 Resolution on ImageNet
The DiT-XL/2 model trained on ImageNet at a resolution of 512x512 uses classifier-free guidance scales of 6.0. The training process for this model took 3M steps. This high-resolution model is designed to handle complex images with intricate details.
256x256 Resolution on ImageNet
The DiT-XL/2 model trained on ImageNet at a resolution of 256x256 uses classifier-free guidance scales of 4.0. The training process for this model took 7M steps. This model is optimized for standard resolution images and is more efficient in terms of computational resources.
FID Comparisons of the Two Resolutions
The DiT-XL/2 model trained at 256x256 resolution outperforms all prior diffusion models, achieving a state-of-the-art FID-50K of 2.27. This is a significant improvement over the previous best FID-50K of 3.60 achieved by the LDM (256x256) model. In terms of compute efficiency, the DiT-XL/2 model is also superior, requiring only 119 Gflops compared to the LDM-4 model’s 103 Gflops and ADM-U’s 742 Gflops.
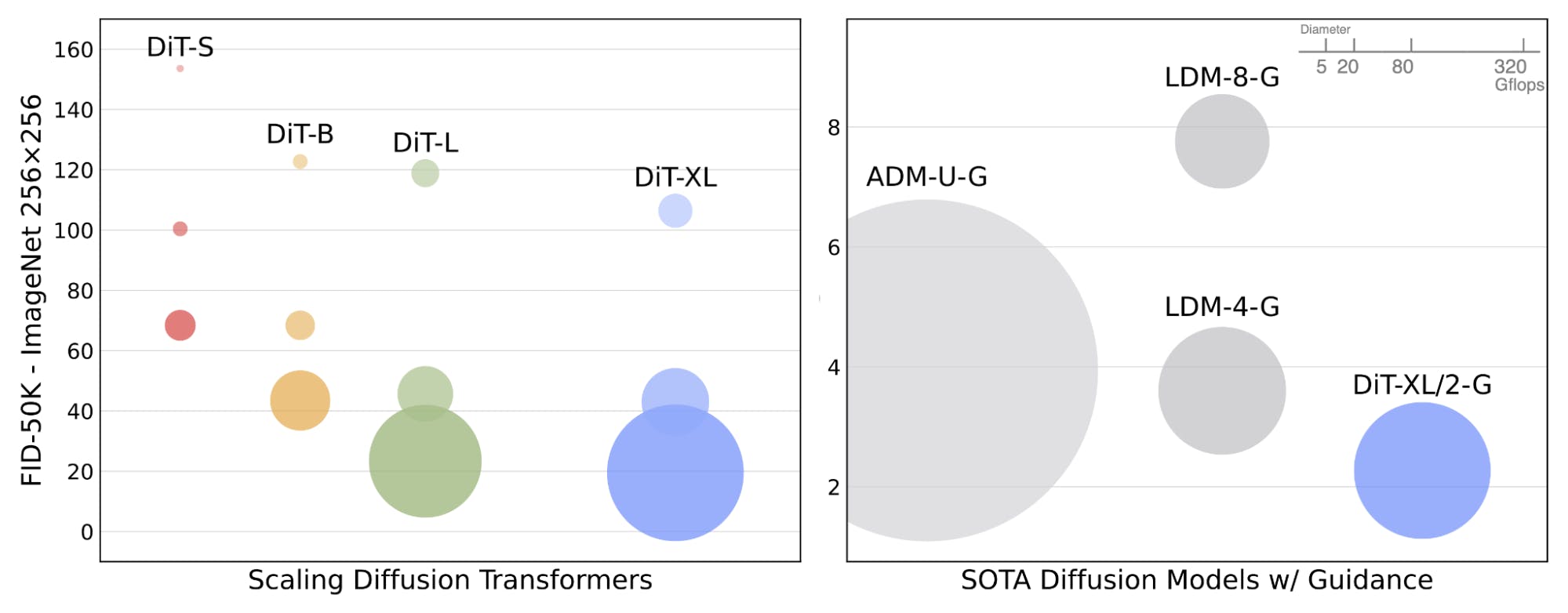
Scalable Diffusion Models with Transformers.
At 512x512 resolution, the DiT-XL/2 model again outperforms all prior diffusion models, improving the previous best FID of 3.85 achieved by ADM-U to 3.04. In terms of compute efficiency, the DiT-XL/2 model requires only 525 Gflops, significantly less than ADM-U’s 2813 Gflops.
Applications of Diffusion Transformer
One of the notable applications of DiT is in image generation. Other applications include text summarizations, chatbots, recommendation engines, language translation, knowledge bases, etc. Let’s look at some notable SOTA models which use diffusion transformer architectures:
OpenAI’s SORA

Video generation models as world simulators
OpenAI’s SORA is an AI model that can create realistic and imaginative scenes from text instructions. SORA is a diffusion model, which generates a video by starting off with one that looks like static noise and gradually transforms it by removing the noise over many steps. It can generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt. SORA is capable of generating entire videos all at once or extending generated videos to make them longer.
Stable Diffusion 3

Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Stable Diffusion 3 (SD3) is an advanced text-to-image generation model developed by Stability AI. SD3 combines a diffusion transformer architecture and flow matching. It generates high-quality images from textual descriptions. SD3 outperforms state-of-the-art text-to-image generation systems such as DALL·E 3, Midjourney v6, and Ideogram v1 in typography and prompt adherence, based on human preference evaluations.
PixArt-ɑ

PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Syntheis
PixArt-α is a Transformer-based Text-to-Image (T2I) diffusion model. Its image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. PixArt-α supports high-resolution image synthesis up to 1024px resolution with low training cost6. It excels in image quality, artistry, and semantic control.
Diffusion Transformer: Key Takeaways
- Class of Diffusion Models: Diffusion Transformers (DiT) are a novel class of diffusion models that leverage the transformer architecture.
- Improved Performance: DiT aims to improve the performance of diffusion models by replacing the commonly used U-Net backbone with a transformer.
- Impressive Scalability: DiT models have demonstrated impressive scalability properties, with higher Gflops consistently having lower Frechet Inception Distance (FID).
- Versatile Applications: DiT has been applied in various fields, including text-to-video models like OpenAI’s SORA, text-to-image generation models like Stable Diffusion 3, and Transformer-based Text-to-Image (T2I) diffusion models like PixArt-α.
Frequently asked questions
DiTs enhance computational efficiency by integrating transformers into diffusion models, capitalizing on best practices across domains.
DiTs offer a fresh paradigm for designing diffusion models, improving image segmentation and classification tasks while reducing data annotation workload.
DiTs’ handling of image artifacts and noise is not explicitly mentioned in the sources. However, image processing techniques generally address these issues.
Diffusion Transformers (DiT) are powerful but demanding. They require significant time and computational resources for training due to their complex denoising process. Despite these challenges, they outperform other models like GANs and VAEs in image generation, making the extra effort worthwhile.
Yes, Diffusion Transformers can process video content. The Video Diffusion Transformer (VDT) and OpenAI’s Sora use transformers in diffusion-based video generation, capturing temporal dependencies and facilitating diverse video generation scenarios.
Ethical considerations for Diffusion Transformers (DiTs) include potential misuse for creating deepfakes or spreading misinformation. They also raise concerns about data privacy and consent, as they can generate realistic synthetic data that could potentially infringe on individuals’ rights.