Google’s Video Gaming Companion: Scalable Instructable Multiworld Agent [SIMA]

How do you train an AI agent to be a generalist? Google DeepMind’s latest AI agent, SIMA, short for Scalable Instructable Multiworld Agent, helps us understand precisely how.
Both NVIDIA and DeepMind have been focused on controlling one multi-world agent. The idea is that if you can develop one agent that can generalize across different domains (for example, different video games), it would probably be quite useful in the real world—for piloting a robot, learning from a physical environment, etc.
In this article, you will learn about:
- What SIMA is and how it interacts with the environment in real-time using a generic human-like interface.
- Different methods for training an AI agent.
- SIMA’s training process, including the environments, data, models, and evaluation methods.
- How SIMA generalizes knowledge across tasks and environments with really impressive zero-shot capabilities.
- How useful they are as embodied AI agents.
DeepMind’s Gaming Legacy: Alpha Go to Scalable Instructable Multiworld Agent (SIMA)
DeepMind has consistently been at the forefront of advancing artificial intelligence (AI) through gaming. This tradition dates back to its groundbreaking success with AlphaGo, famous for beating the world’s best Go players.
To understand how the team arrived at SIMA, let’s explore the evolution from DeepMind's early work on reinforcement learning in Atari video games to Scalable Instructable Multiworld Agent (SIMA), focusing on… wait for it… Goat Simulator 3, with some of the funniest game actions .
The evolution shows how models go from mastering structured board games to navigating complex, rich, interactive 3D simulations and virtual environments.
First off… Atari games.
Reinforcement Learning on Atari Video Games
DeepMind's first attempt at using AI in games was a huge success when applied to Atari games using deep reinforcement learning (RL). The goal was to get the highest scores in several classic games using only pixel data and game scores. These games provided a diverse platform for testing and improving RL algorithms, which learn optimal behaviors through trial and error, guided by rewards.
In this situation, DeepMind's algorithms (the popular AlphaGo, MuZero, and AlphaGo Zero) could master several Atari games, often doing better than humans. This work showed how RL can solve difficult, dynamic, and visually varied problems. It also set a new standard in AI by showing how AI agents can learn and adapt to new environments without having much pre-programmed information.
DeepMind's deep Q-network (DQN) was key to this success. It combined deep neural networks with a Q-learning framework to process high-dimensional sensory input and learn successful strategies directly from raw pixels.
This approach enabled AI to understand and interact meaningfully with the gaming environment, paving the way for more sophisticated AI applications in gaming and beyond.
Scalable Instructable Multiworld Agent (SIMA) on Goat Simulator 3
SIMA builds on its predecessors. The AI agent can move around and interact in a wide range of 3D virtual worlds, not just the 2D worlds of Atari games.
SIMA is built to understand and follow natural language instructions within these environments. This is a first step toward creating general AI that can understand the world and its complexities.
SIMA learned from different gaming environments, and one interesting one is Goat Simulator 3. If you have played this game before, you will surely know how unpredictable and chaotic the actions are.
It is uniquely challenging due to its open-ended gameplay and humorous, physics-defying mechanics. This, of course, is different from the structured world of Go and other Atari games!
To teach SIMA how to operate in Goat Simulator 3, the researchers had to collect a lot of human gameplay from which it could learn. The gameplay included simple navigation to follow specific actions in open-ended language instructions (e.g., “jump the fence”).
This process checks the agent's ability to understand and follow directions and adapt to an environment where nothing is ever the same.
Agent Training Methods
DeepMind's technical report discusses new ways to train AI agents that use the complexity of simulated environments to help them learn and adapt. These methods are crucial for creating agents like those in the SIMA project that can interact intelligently with various 3D environments.
AI Agent Simulator-based Training
The method uses reinforcement learning—agents learn the best way to execute a task by trying things out and seeing what works best, with help from reward signals in their environment. In this context, the game environment serves as both the playground and the teacher. Here are the components of this training approach:
- Reinforcement Learning: The core of this method is an algorithm that adjusts the agent's policy based on the rewards it receives for its actions. The agent learns to connect actions with results, which helps it improve its plan to maximize cumulative rewards.
- Reward Signals: These signals guide the agent's learning process within game environments. They can be explicit, like points scored in a game, or more nuanced, reflecting progress toward a game's objective or successful interaction within the environment.
- Environment Flexibility: This training method is flexible because you can use in any setting that provides useful feedback. The agent learns by engaging directly with the environment, navigating a maze, solving puzzles, or interacting with dynamic elements.
- Examples: Using RL in places like Atari games, where the agent learns different strategies for each game, shows how well this method works. This can also be seen when training agents in more complicated situations, like those in Goat Simulator 3, where the AI must adapt to and understand complex situations with nuance.
Traditional Simulator-based Agent Training
This method involves unsupervised learning, where the agent explores the environment and learns its dynamics without explicit instruction or reinforcement. The goal is for the agent to develop an intuitive understanding of the rules and mechanics governing the environment. The techniques in this approach are:
- Unsupervised Model: By interacting with the environment without predefined objectives or rewards, the agent builds a model of the world that reflects its inherent rules and structures. This model helps agents predict outcomes and plan actions, even in unfamiliar scenarios.
- Learn the Rules Intuitively: The agent notices patterns and regularities in its surroundings by observing and interacting with them. This is the same as "learning the rules of the game." This process helps the agent gain a deep, unconscious understanding that shapes how they act and what they choose to do in the future.
- Less Need for Annotation: One big benefit of this method is that it does not require as much detailed annotation or guidance. The agent learns from experiences, so it does not need large datasets with labels or manual instructions.
- Example: Scenarios where agents must infer objectives or navigate environments with sparse or delayed feedback. For example, an agent might learn to identify edible vs. poisonous items in a survival game or deduce the mechanics of object interaction within a physics-driven simulation.
Scalable Instructable Multiworld Agent (SIMA) Training Process
SIMA's training approach includes several key components, detailed as follows:
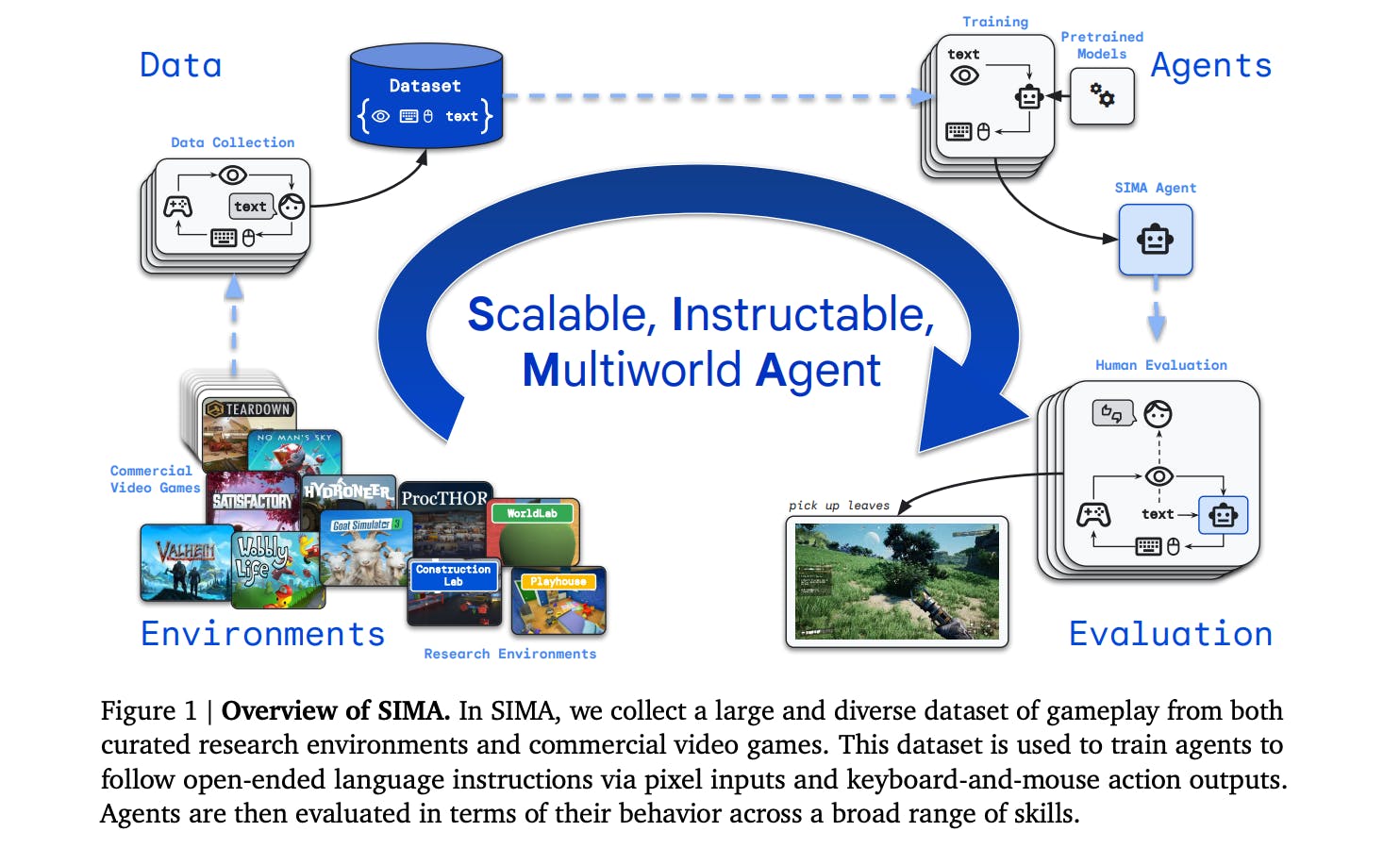
Scaling Instructable Agents Across Many Simulated Worlds
Environment
SIMA's training leverages diverse 3D environments, ranging from commercial video games to bespoke research simulations. It was important to the researchers that these environments offer a range of challenges and chances to learn so that agents could become more flexible and generalize to various settings and situations.
Key requirements of these environments include:
- Diversity: Using open-world games and controlled research environments ensures that agents encounter various scenarios, from dynamic, unpredictable game worlds to more structured, task-focused settings.
- Rich Interactions: The researchers chose the environments because they allowed agents to interact with different objects, characters, and terrain features in many ways, helping them learn a wide range of skills.
- Realism and Complexity: Some environments have physics and graphics close to reality. This lets agents learn in situations similar to how complicated things are in the real world.
Two environments that meet these requirements are:
- Commercial Video Games: The researchers trained the agents on games, including Goat Simulator 3, Hydroneer, No Man’s Sky, Satisfactory, Teardown, Valheim, and Wobbly Life.
- Research Environments: These are more controlled environments, such as Controled Labs and procedurally-generated rooms with realistic contents (ProcTHOR).

SIMA is capable of performing many actions from language-instructed tasks.
Data
An extensive and varied set of gameplay data from various environments forms the basis of SIMA's training. This dataset includes:
- Multimodal Inputs: The multimodal data includes visual observations, spoken instructions, and the actions taken by human players that match. This gives agents a lot of information to learn from.
- Human Gameplay: The dataset ensures that agents learn from nuanced, contextually appropriate behavior by capturing gameplay and interaction sequences from human players.
- Annotated Instructions: Language instructions are paired with game sequences to give agents clear examples of using natural language to guide them in doing tasks.

Agents
SIMA agents are designed to interpret language instructions and execute relevant actions within 3D virtual environments. Key aspects of their design include:
- Language-Driven Generality: Agents are taught to follow instructions that use open-ended language. This lets them change their actions based on verbal cues to complete many tasks.
- Human-Like Interaction: The agents work with a standard interface that looks and feels like a person's. It takes in text and images and responds to keyboard and mouse commands like a person would.
- Pre-trained Models: SIMA uses pre-trained models, like video models, to process textual and visual data. These models were mostly trained using instruction-conditioned behavioral cloning (see this note) and classifier-free guidance. This makes it easier for the agents to understand complicated instructions and their surroundings.
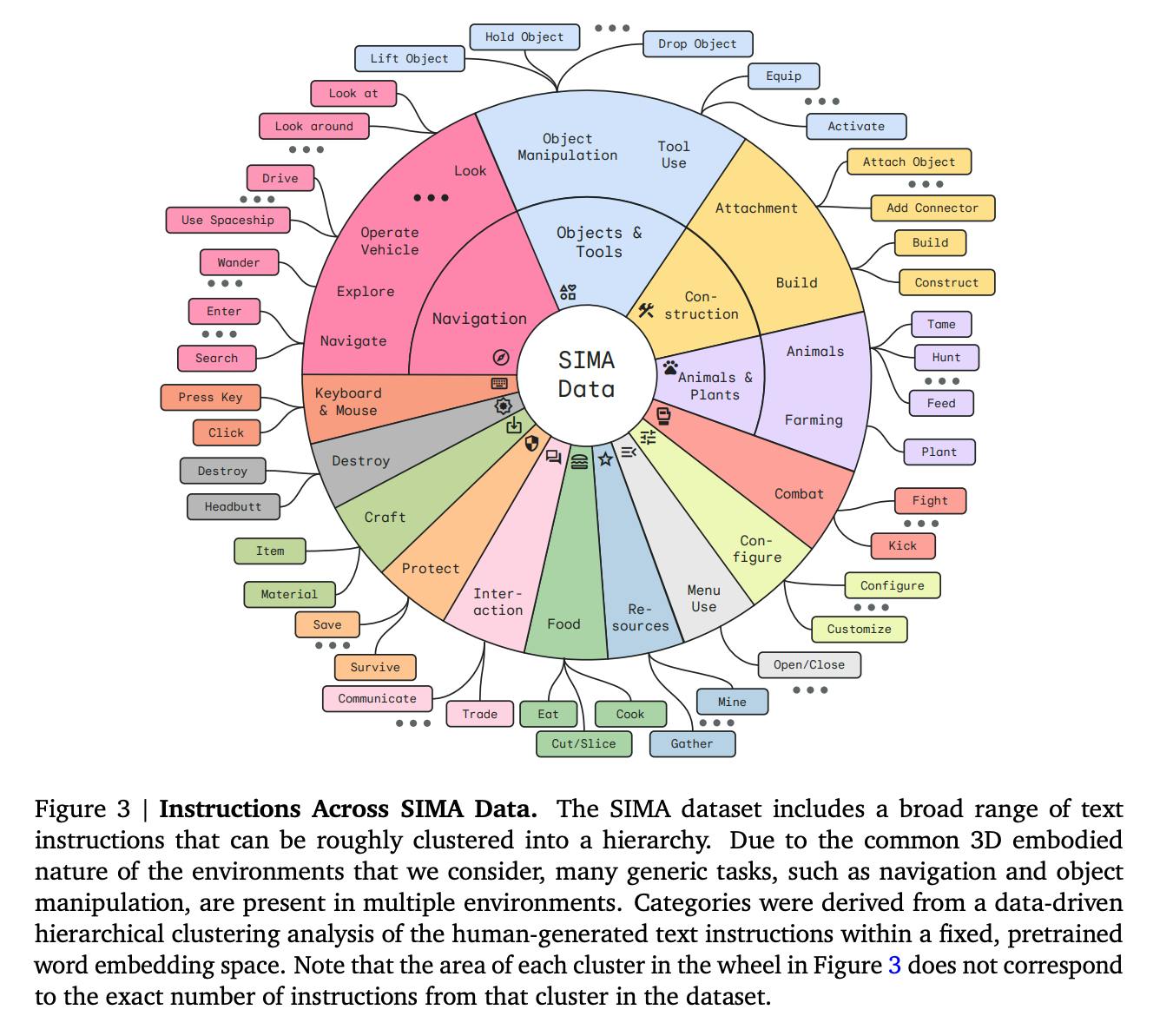
Evaluation Methods
Assessing the performance of SIMA agents involves a variety of evaluation methods tailored to the different environments and tasks:
- Ground-truth Evaluation: In research environments, clear success criteria are set for each task, so it is easy to judge an agent's performance by whether certain goals are met.
- Human Judgments: When the tasks are more open-ended or subjective, human evaluators watch how the agents act and give feedback on how well they can follow directions and reach their goals while acting like humans.
- Automated Metrics: In some cases, particularly within commercial games, automated metrics such as in-game scores or task completion indicators provide quantitative measures of agent success.
- Optical Character Recognition (OCR): Applied in commercial video games where task completion might not be as straightforward to assess. OCR is used to detect on-screen text indicating task completion.
- Action Log-probabilities and Static Visual Input Tests: These are more simplistic methods assessing the agent's ability to predict actions based on held-out data or to respond to static visual inputs with correct actions.
SIMA Agent Features
Scalable Instructable Multiworld Agent (SIMA) incorporates sophisticated features that enable it to interact effectively within various simulated 3D environments. These features are integral to its design, allowing it to understand and execute various natural language instructions and perform many actions across different virtual settings.
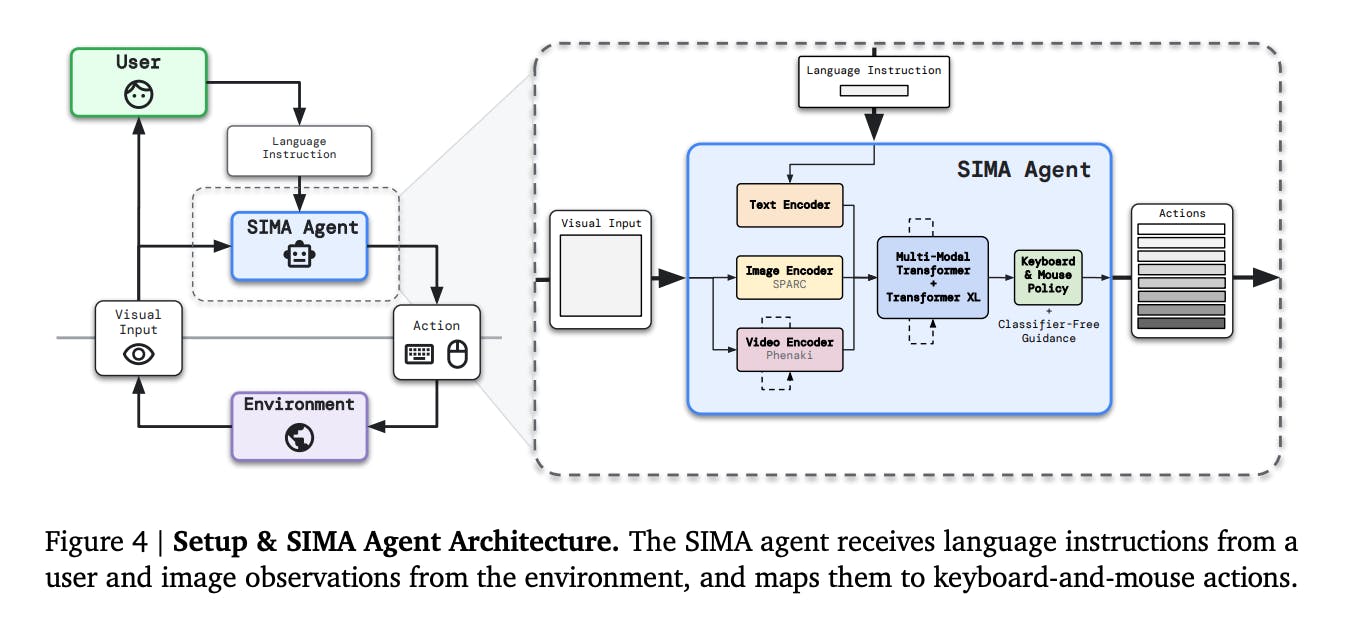
SIMA agent receives instructions from a user and image observations from the environment
Here's a breakdown of these crucial features:
Multi-environment Transfer
A key feature of SIMA is that it can use the knowledge and skills it has gained in one environment to perform well in another without starting from scratch each time. This ability to transfer between environments is very important for the agent's flexibility and efficiency; it lets it use what it has learned in a wide range of situations instead of just one.
For instance, if the agent learns the concept of 'opening a door' in one game, it can apply this knowledge when encountering a door in another unrelated game. The agent's sophisticated perception and action systems facilitate mapping shared concepts by abstracting underlying similarities in interactions across environments and accelerating its adaptation.
Understands Natural Language instructions
SIMA is engineered to understand a wide range of language instructions, interpreting them within the context of its current environment and objectives. This comprehension extends to complex commands and instruction sequences, enabling SIMA to engage in sophisticated interactions and complete intricate tasks in accordance with human-like language inputs.
Performs 600+ Actions
Due to the variety of its training environments and the difficulty of the tasks it can handle, SIMA can perform more than 600 different actions. Thanks to its large action repertoire, it can respond correctly to various situations and instructions, which shows how well it has learned to adapt.
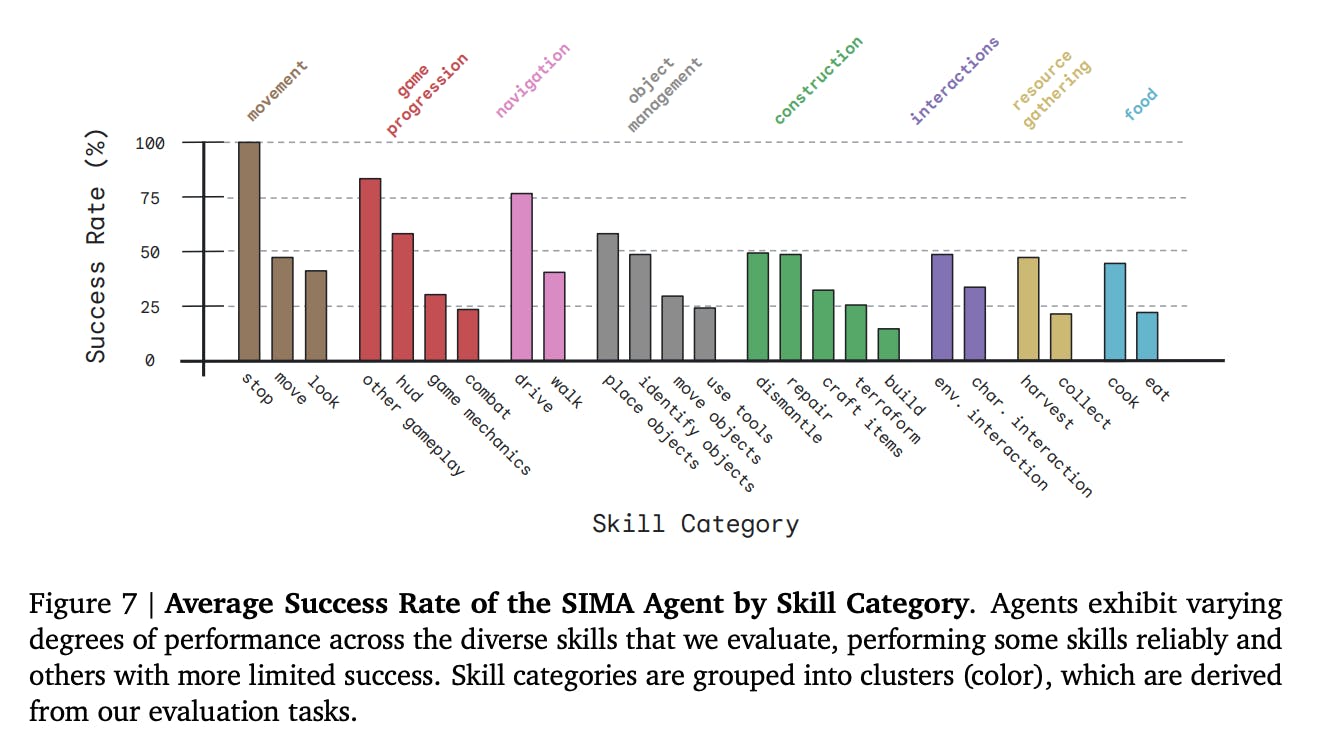
Average success rate of the SIMA Agent by skill category
From basic movements and interactions to more intricate and context-specific actions, SIMA's broad range of capabilities enables it to tackle diverse challenges and objectives.
Generalization
Rather than mastering a single task or environment, SIMA is developed to generalize its learning and problem-solving capabilities across contexts. This generalization ensures that the agent can apply its learned skills and knowledge to new, unseen challenges, adapting its strategies based on prior experiences and the specific demands of each new setting.
Results Highlighting SIMA's Generalization Ability
DeepMind's SIMA demonstrates impressive generalization capabilities across various environments, as showcased through several key findings:
- Zero-Shot Learning Abilities: SIMA effectively applies learned skills to new, unseen environments without additional training, which indicates robust internalized knowledge and skill transferability.
- No Pre-Training Ablation: Removing pre-trained components affects SIMA's performance, emphasizing the importance of pre-training for generalization. Despite this, some generalization capacity persists, highlighting the robustness of SIMA's core architecture.
- Language Ablation: Taking out natural language inputs worsens task performance. This shows how important language comprehension is to SIMA's ability to work in diverse environments.
- Environment-Specialized Performance: SIMA matches or outperforms environment-specialized agents, showcasing its broader applicability and efficient learning across different virtual worlds.
Ethical AI Guidelines
DeepMind's commitment to ethical AI practices is evident in developing and training SIMA. As part of these ethical guidelines, the AI should only be trained in carefully chosen environments that encourage good values and behavior. Here are the key guidelines they used to avoid violent content:
- Content Curation: In aligning with ethical AI practices, SIMA's training explicitly avoids video games or environments that feature violent actions or themes. This careful curation ensures that the agent is not exposed to, nor does it learn from, any content that could be considered harmful or contrary to societal norms and values.
- Promotes Positive Interaction: The training focused on problem-solving, navigation, and constructive interaction, choosing environments without violence. This created an AI agent that can be used in many positive situations.
- Risk Mitigation: This approach also serves as a risk mitigation strategy, reducing the potential for the AI to develop or replicate aggressive behaviors, which is crucial for maintaining trust and safety in AI deployments.
- Modeling Safe and Respectful Behaviors: The training program reinforces safe and respectful behaviors and decisions in the agent, ensuring that their actions align with the principles of avoiding harm and promoting well-being.
SIMA's training on nonviolent content shows how important it is to ensure that AI research and development align with societal values and that we only create AI that is helpful, safe, and respectful of human rights.
Challenges of Developing SIMA
The DeepMind SIMA research team faced many difficult problems when developing the agent. These problems arise when training AI agents in different and changing 3D environments, and they show how difficult it is to use AI in situations similar to the complicated and unpredictable real world.
Real-time Environments Not Designed for Agents
- Unpredictable Dynamics: Many real-time environments SIMA is trained in, especially commercial video games, are inherently unpredictable and not specifically designed for AI agents. These environments are crafted for human players and feature nuances and dynamics that can be challenging for AI to navigate and understand.
- Complex Interactions: The multifaceted interaction possibilities within these environments add another layer of complexity. Agents must learn how to handle various possible events and outcomes, which can change from one moment to the next, just like in real life.
Evaluation Without API Access to Environment States
- Limited Information: Evaluating SIMA's performance without API access means the agent cannot rely on explicit environment states or underlying game mechanics that would typically be available to developers. This limitation necessitates reliance on visual and textual cues alone, which mirrors the human gameplay experience but introduces significant challenges in interpreting and responding to the environment accurately.
- Assessment Accuracy: The lack of direct environment state access complicates the evaluation process, making it harder to ascertain whether the AI has successfully understood and executed a given task, particularly in complex or ambiguous situations.
SIMA’s Current Limitations
Although the Scalable Instructable Multiworld Agent (SIMA) has made significant progress, it still has some problems worth mentioning. These constraints highlight areas for future research and development to improve AI agents' capabilities and applications in complex environments.
Limited Environmental Availability
- Diversity of Games: SIMA was trained and tested on four research-based 3D simulations and seven commercial video games. This shows that the model can work in various settings but is still not very broad, considering all the different game types and settings. Adding more types of environments could help test and improve the agent's ability to adapt to new ones.
- Breadth of 3D Simulations: The four 3D simulations provide controlled settings to test specific agent capabilities. However, increasing the number and diversity of these simulations could offer more nuanced insights into the agent's adaptability and learning efficiency across varied contexts.
Restricted Data Pipeline Scalability
- The current data pipeline, crucial for training SIMA through behavioral cloning, might not be scalable or diverse enough to cover the full spectrum of potential interactions and scenarios an agent could encounter. Improving the scalability and diversity of the data pipeline would be essential for training more robust and versatile AI agents.
Short Action Horizon
- Action Duration: SIMA's training has primarily focused on short-horizon tasks, generally capped at around 10 seconds. This limitation restricts the agent's ability to learn and execute longer and potentially more complex sequences of actions, which are common in real-world scenarios or more intricate game levels.
Reliability and Performance
- Agent Reliability: Although SIMA has shown promise in following instructions and performing actions across various environments, it is often unreliable compared to human performance. The agent's inconsistency in accurately interpreting and executing instructions poses challenges for its deployment in scenarios requiring high precision or critical decision-making.
- Comparison with Human Performance: Some tasks made for SIMA are naturally hard and require advanced problem-solving and strategic planning, but the agent still does not follow instructions as well as a human would. This shows how hard the environments are and how high the bar was set for the agent since even skilled human players do not get perfect scores on these tasks.
Addressing these limitations will be crucial for the next stages of SIMA's development. To make the field of AI agents that can navigate and interact in complex, changing virtual worlds even better, we must improve environmental diversity, data pipeline scalability, action horizon, and overall reliability.
Key Takeaways: Google’s Video Gaming Companion—Scalable Instructable Multiworld Agent (SIMA).
Here are the key ideas from this article:
- SIMA interacts with the environment in real-time using a generic human-like interface. It receives image observations and language instructions as inputs and generates keyboard and mouse actions as outputs.
- SIMA is trained on a dataset of video games, including Satisfactory, No Man's Sky, Goat Simulator 3, and Valheim.
- The researchers evaluated SIMA’s ability to perform basic skills in these games, such as driving, placing objects, and using tools. On average, SIMA's performance is around 50%, but it is far from perfect.
- The researchers believe that training AI agents on a broad variety of video games is an effective way to make progress in general AI.
These results support SIMA's strong generalization skills and show that it can work well in various situations and tasks. It is a big step forward in developing AI agents with strong, flexible, and transferable skill sets because it shows strong zero-shot learning abilities and resilience against ablation impacts.
Frequently asked questions
SIMA dynamically adapts its strategies using reinforcement learning and behavioral cloning. When faced with changing gameplay scenarios, the AI analyzes the current state, interprets the natural language instructions, and modifies its approach based on training. It uses the knowledge it has acquired from diverse environments to anticipate possible changes and adapt its actions accordingly. Continuous feedback from the environment allows the AI to learn from its successes and mistakes, refining its strategy to deal with new or evolving gameplay challenges over time.
Currently, SIMA does not possess the capability to sense or react to player emotions directly. Its design focuses on interpreting and following natural language instructions within 3D environments, not including emotional recognition or response mechanisms. However, the AI's performance can indirectly influence player emotions through its actions, which can be designed to be cooperative, competitive, or neutral based on the given context and objectives.
In multiplayer settings, several ethical considerations are paramount to ensuring fairness, safety, and enjoyable experiences for all players.
These include:
- Non-Exploitative Behavior: SIMA is programmed to avoid exploitative behavior that could give it an unfair advantage or detract from the gameplay experience for human players.
- Respect for Player Autonomy: The AI is designed to respect player choices and autonomy, ensuring that it does not unduly influence or interfere with human decision-making processes.
- Privacy and Data Security: In settings where player data or interactions could be observed or recorded, stringent measures are in place to protect privacy and ensure data security, adhering to relevant laws and ethical guidelines.
- Transparency: Players in multiplayer environments should be informed about the presence of AI agents like SIMA, understanding their role and capabilities within the game.
- Bias and Fairness: Special attention is given to prevent bias in SIMA's behavior, ensuring it treats all players equitably and contributes to a fair gaming environment.