5 Ways to Improve The Quality of Labeled Data

Co-Founder & Co-CEO at Encord
Computer vision models are improving in sophistication, accuracy, speed, and computational power every day. Machine learning teams are training computer vision models to solve problems more effectively, making the quality of labeled data more important than ever.
Poor quality labeled data, or errors and mistakes within image or video-based datasets can cause huge problems for machine learning teams. Regardless of the sector or problem that needs solving, if computer vision algorithms don’t have access to the quality and volume of the data they need they won’t produce the results organizations need.
In this article, we take a closer look at the common errors and quality issues within labeled data, why organizations need to improve the quality of datasets, and five ways you can do that.
Common Data Error and Quality Problems in Computer Vision?
Data scientists spend a lot of time — too much time, many would say — debugging data and adjusting labels in datasets to improve model performance. Or if the labels that have been applied aren’t up to the standard required, part of the dataset needs to go back to annotators to be re-labeled.
Despite annotation automation and AI-assisted labeling tools and software, reducing errors and improving quality in datasets is still time-consuming work. Often, this is done manually, or as close to manual as possible. However, when there are thousands of images and videos in a dataset, sifting through every single one to check for quality and accuracy becomes impossible.
As we’ve covered in this article, the top three causes of errors and quality problems in computer vision datasets are:
- Inaccurate labels;
- Mislabeled images;
- Missing labels (unlabeled data);
- Unbalanced data and corresponding labels (e.g. too many images of the same thing), resulting in data bias, or insufficient data to account for edge cases.
Depending on the quality of the video or image annotation work and AI-supported annotation tools that are used, and the quality control process, you could end up with all three issues throughout your dataset.
Inaccurate labels cause an algorithm to struggle to identify objects in images and videos correctly. Common examples of this include loose bounding boxes or polygons, labels that don’t cover an object, or labels that overlap with other objects in the same image or frame.
Applying the wrong label to an object also causes problems. For example, labeling a “cat” as a “dog” would generate inaccurate predictions once a dataset was fed into a computer vision model. MIT research shows that 3.4% of labels are wrong in best practice datasets. Meaning, there’s an even greater chance there are more inaccurate labels in datasets most organizations use.
Missing labels in a ground truth dataset also contribute to computer vision models producing the wrong predictions and outcomes.
Naturally, the aim of annotation work should be to provide the best, most accurate labels and annotations possible for image and video datasets. According to the relevant use case and problems you are trying to solve.
Why Do You Need To Improve The Quality of Your Datasets?
Improving the quality of a dataset that’s being fed into a machine learning or computer vision model is an ongoing task. Quality can always be improved. Every change made to the annotations and quality of the labels in a dataset should generate a corresponding improvement in the outcomes of your computer vision projects.
For example, when you first give an algorithmic model a training dataset, you might get a 70% accuracy score. Getting that up to 90%+ or even 99% for the production model involves assessing and improving the quality of the labels and annotations.
Here’s what you need from a dataset that should produce the results you’re looking for:
- Accurately labeled and annotated objects within images and videos;
- Data that’s not missing any labels;
- Including labels and annotations that cover data outliers, and every edge case;
- Balanced data that covers the distribution of images and videos in the deployment environment, such as different lighting conditions, times of day, seasons, etc.);
- A continuous data feedback loop, so that data drift issues are reduced, quality keeps increasing, bias reduces, and accuracy improves to ensure that a model can be put into production.
Now let’s consider five ways you can improve the quality of your labeled data.
Five Ways To Improve The Quality of Your Labeled Data
Use Complex Ontological Structures For Your Labels
Machine learning models require high-quality data annotation and labels as a result of your project’s labeling process. Achieving the results you want often involves using complex ontological structures for your labels, providing that's what is required — not simply for the sake of it.
Simplified ontological structures aren’t very helpful for computer vision models. Whereas, when you use more complex ontological structures for the data annotation labeling process, it’s easier to accurately classify, label, and outline the relationship between objects in images and videos.
With clear definitions, applied through the ontological structure, of objects within images and videos, those implementing the data annotation labeling process can produce more accurate labels. In turn, this produces better, more accurate outcomes for production-ready computer vision models.
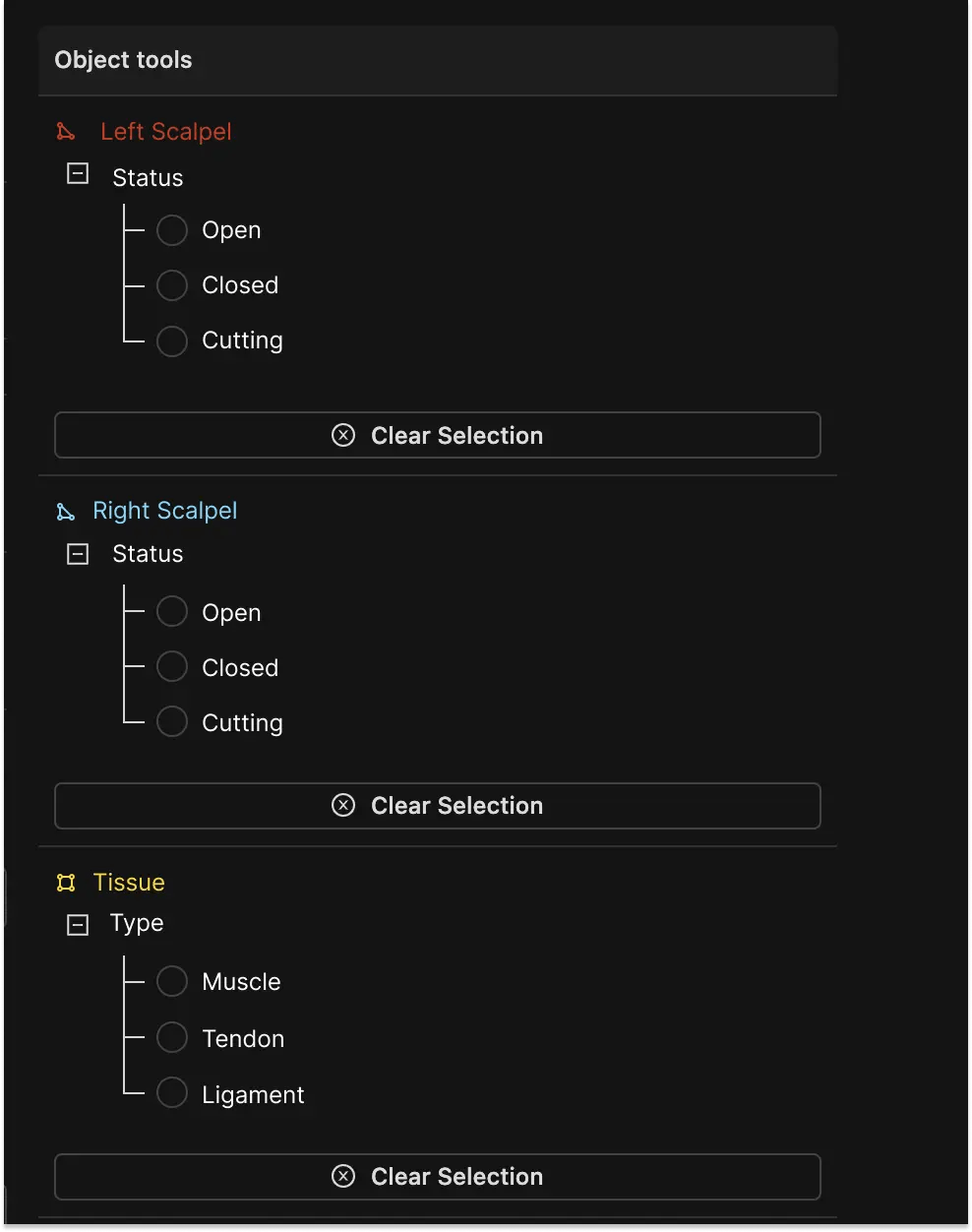
Example of a complex ontology in Encord
AI-Assisted Labeling
A wholly manual data labeling process is a time-consuming and exhausting task. It can cause annotators to make mistakes, burn out (especially when they’re applying the same labels over and over again), and for quality to go down.
One of the best ways to accelerate the timescale it takes to label and annotate a dataset is to use artificial intelligence (AI-assisted) labeling tools. AI-assisted labeling, such as the use of automation workflow tools in the data annotation process is an integral part of creating training datasets.
AI-assisted labeling tools come in all shapes and sizes. From open source out-of-the-box software, to proprietary, premium, AI-based tools, and everything in between. AI solutions save time and money. Efficiency and quality increase when you use AI-assisted tools, producing high-quality datasets more consistently, reducing errors, and improving accuracy.
One such tool is Encord’s micro-models, that are “annotation specific models overtrained to a particular task or particular piece of data.” Encord also comes with a wide range of AI-assisted labeling tools and solutions, and we will cover those in more detail at the end of this article.
Identify Badly Labeled Data
Badly labeled, mislabelled, or data with missing labels will always cause problems for computer vision models.
The best way to avoid any of these issues is to ensure labels are applied accurately during the data annotation process. However, we know that isn’t always possible. Mistakes happen. Especially when a team of outsourced annotators are labeling tens of thousands of images or videos.
Not every annotator is going to do a perfect job every single day. Some will be better than others. Quality will vary, even when annotators have access to AI-assisted labeling tools.
Consequently, to ensure your project gets the highest-quality annotated and labeled datasets possible, you need to implement an expert review workflow and quality assurance system.
An additional way to ensure label and data quality is to use Encord Active, an open-source active learning framework to identify errors and poorly labeled data. Once errors and badly labeled images and videos have been identified, the relevant images or videos (or entire datasets) can be sent back to be re-annotated, or your machine learning team can make the necessary changes before introducing the dataset to the computer vision model.
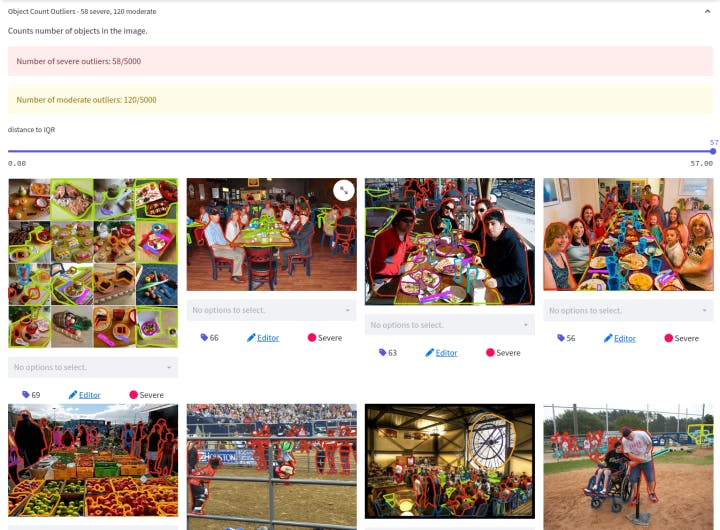
Identifying badly labeled images in Encord Active
Improve Annotator Management
Reducing the number of errors at the quality assurance end of the data pipeline involves improving annotator management throughout the project.
Even when you’re working with an outsourced team in another country, distance, language barriers, and timezones shouldn’t negatively impact your project. Poor management processes will produce poor dataset quality outcomes.
Project leaders need continuous visibility of inputs, outputs, and how individuals on the annotation team are performing. You need to assess the quality of data annotations and labels coming out of the annotation work, so that you can see who’s achieving key performance indicators (KPIs), and who isn’t.
With the right AI-assisted data labeling tools, you should have a project dashboard at your fingertips. Not only should this provide access control, but it should give you a clear overview of how the annotation work is progressing, so that changes can be made during the project. This way, it should be easier to judge the quality of the labels and annotations coming from the annotation team, to ensure the highest quality and accuracy possible.
Use Encord to Improve The Quality of Your Computer Vision Data Labels
Encord is a powerful platform that pioneering AI teams across numerous sectors use to improve the quality, accuracy, and efficiency of computer vision datasets.
Encord comes with everything, from advanced video annotation to an easy-to-use labeling interface, and automated object tracking, interpolation, and AI-assisted labeling. It comes with a dashboard, and a customizable toolkit to equip an annotation and machine learning team to label images and videos, and then implement a production-ready computer vision model.
With Encord, you can find and fix machine learning models and data problems. Reduce the number of errors that come out of an annotation project, and then further refine a dataset to produce the results you need. We are transforming the speed and ways in which businesses are getting their models into production faster.
And there we go, the 5 ways you can improve the quality of your labeled data.

Frequently asked questions
Encord enhances labeling speed by providing tools that automate pre-labeling, allowing users to quickly generate initial predictions. Labelers can then focus on correcting these predictions, significantly reducing the time spent on manual labeling, especially for models addressing unique box requirements.
Encord includes a dedicated workflow setup that addresses QA and QC challenges by allowing teams to create structured processes for reviewing and validating data labels. This feature enhances the reliability of the labeled data, ensuring it meets the necessary standards for effective model training.
Encord offers features designed to streamline the quality control process, enabling teams to discover efficiency gains. By utilizing Encord's platform, users can effectively manage and oversee their annotation workflows, ensuring high-quality outputs while saving time and resources.
Encord helps streamline labeling by allowing teams to control how many annotators review each image, thus improving the quality of annotations. By ensuring that a limited number of trained individuals handle the same images, Encord enhances consistency and quality in data labeling.
Encord offers various methods for data annotation, including automation tools and collaboration features that streamline the annotation process. Quality assurance is enhanced through ongoing reviews and the ability to integrate feedback directly into the annotation workflow.
Encord enhances labeling quality and throughput by utilizing agentic workflows for pre-labeling and connecting these workflows to the labeling pipeline. This iterative process allows domain experts to access data and provide guidance, ultimately improving model performance.
Manual labeling is crucial during the initial stages of model training as it ensures the quality and accuracy of the annotations. Encord allows for efficient manual labeling, which helps in building a robust dataset that can be used for training automated models later on.
Yes, Encord is equipped to facilitate the evaluation of interventions using labeled data. By providing a structured dataset of both positive and negative interventions, users can refine their AI models and enhance decision-making processes within healthcare applications.
Encord enhances data curation through intuitive tools that allow users to easily review and assess their annotated data. This ensures high data quality and enables teams to identify and rectify any potential annotation errors efficiently.
Yes, Encord offers features that facilitate the curation of labeled data. This is particularly beneficial for ensuring high-quality input for training models, which is crucial for effective deployment in physical AI environments.