Mask-RCNN vs. Personalized-SAM: Comparing Two Object Segmentation Models

Let's take a moment to talk about one of the coolest things in AI right now: object segmentation. Simply put, object segmentation is about making sense of a picture by splitting it into its core parts and figuring out what's what. It’s kind of like solving a jigsaw puzzle, but instead of fitting pieces together, our AI is identifying and labeling things like cats, cars, trees, you name it!
The practical implications of successful object segmentation are profound, spanning diverse industries and applications - from autonomous vehicles distinguishing between pedestrians and road infrastructure to medical imaging software that identifies and isolates tumors in a patient's scan to surveillance systems that track individuals or objects of interest. Each of these cases hinges on the capability to segment and identify objects within a broader context precisely; as a result, precise detection provides a granular understanding that fuels informed decisions and actions. Object segmentation is the secret sauce that makes this possible.
Yet, as powerful as object segmentation is, it comes with its challenges. Conventionally, segmentation models require vast quantities of annotated data to perform at an optimal level. The task of labeling and annotating images can be labor-intensive, time-consuming, and often requires subject matter expertise, which can be a barrier to entry for many projects.
At Encord, we utilize micro-models to speed up the segmentation process of computer vision projects. Users only label a few images from their dataset, and Encord micro-models learn the visual patterns of these labels by training on them. The trained micro-model is used to label the unlabeled images in the dataset, thereby automating the annotation process.
As new foundational vision models such as DINO, CLIP, and Segment Anything Model emerge, the performance of these micro-models also increases.
So we have decided to put two object segmentation models to the test to see how well they handle few-shot learning. We challenge these models to generate predictions for unlabeled images based on training a Mask-RCNN with 10 images and a recently proposed Personalized-SAM with 1 image, pushing the boundaries of what few-shot learning can achieve.
Segment Anything Model (SAM)
Personalized-SAM uses the Segment Anything Model (SAM) architecture under the hood. Let’s dive into how SAM works.
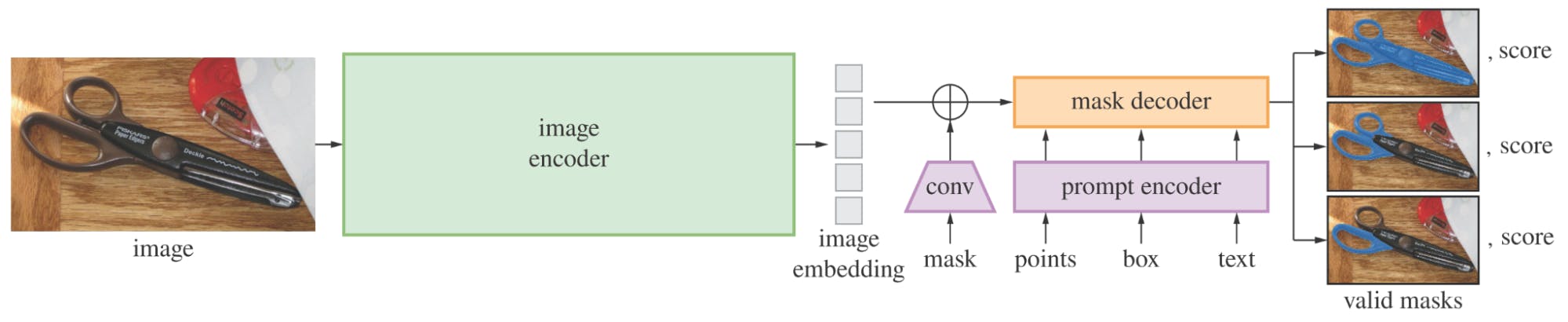
The Segment Anything Model (SAM) is a new AI model from Meta AI that can "cut out" any object, in any image, with a provided input prompt. SAM is a promptable segmentation system with zero-shot generalization to unfamiliar objects and images, without the need for additional training. So basically, SAM takes two inputs, an image and a prompt, and outputs a mask that is in relation to the prompt. The below figure shows the main blocks of the SAM architecture:
Personalize Segment Anything Model with One Shot
The image is passed through an image encoder which is a vision transformer model; this block is also the largest block of all SAM architecture. The image encoder outputs a 2D embedding (this being 2D is important here, as we will see later in Personalized-SAM). The prompt encoder processes the prompt, which can be points, boxes, masks, and texts. Finally, 2D image embedding and prompt embedding is fed to the mask decoder, which will output the final predicted masks. As there is a visual hierarchy of objects in images, SAM can output three different masks for the provided prompt.
There are two main drawbacks of the SAM architecture:
- For each new image, a human is needed for the prompting.
- The segmented region is agnostic to the class; therefore, the class should be specified for each generated mask.
Now, let’s move on to the Personalized-SAM to see how these issues are addressed.
Personalized-SAM (Per-SAM)
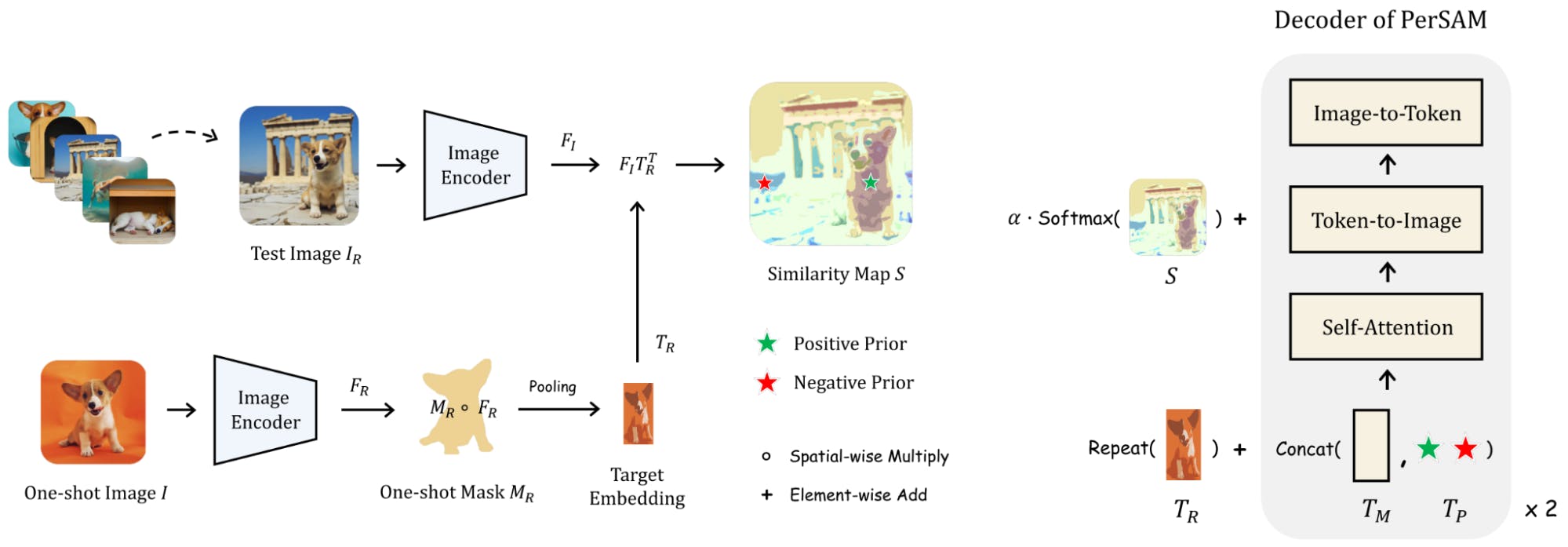
Personalized SAM (Per-SAM) is a training-free Personalization approach for SAM. The proposed approach works by first localizing the target concept in the image using a location prior, and then using a combination of target-guided attention, target-semantic prompting, and cascaded post-refinement to segment the target concept. Then, it uses a combination of target-guided attention, target-semantic prompting, and cascaded post-refinement to segment the target concept.
Personalize Segment Anything Model with One Shot
Learning the target embedding
First, the user provides an image and mask of the target concept (object). Then the image is processed through the image encoder block of the SAM architecture. Remember what the image encoder’s output was? Yes, it’s a 2D embedding! Now, one needs to find where the mask of the target object corresponds to in this 2D embedding space, as these embeddings will be the representation of our target concept. Since the spatial resolution is decreased in 2D embeddings, the mask should also be downscaled to that size. Then, the average of the vectors at locations that correspond to the downscaled mask should be obtained. Finally, we have a fixed embedding (or representation) for the target concept, which we will utilize in the next step.
Getting a similarity map to generate prompts
Now it is time for the inference on a new image. Per-SAM first processes it through the SAM image encoder to obtain a 2D embedding. The next step is crucial: finding the similarity between each location in the 2D embedding, and the target embedding that we obtained in the first step. The authors of Per-SAM use Cosine distance to calculate the similarity map. Once the similarity map is obtained, points for prompts can be generated for the prompt decoder. The maximum similarity location is determined as the positive point, and the minimum similarity location is determined as the negative point.
So, now we have a prompt for the desired class for the new image. Can you guess what is next? We just need to apply the classic SAM process to get the mask. The image and prompts are given to the model and a segmentation mask is generated.
In the Per-SAM paper, the authors also use the similarity map as a semantic prompt. Moreover, they consecutively obtain new prompts (bounding box and segmented region) from the generated mask and refine the final predicted mask, which improves the overall result.
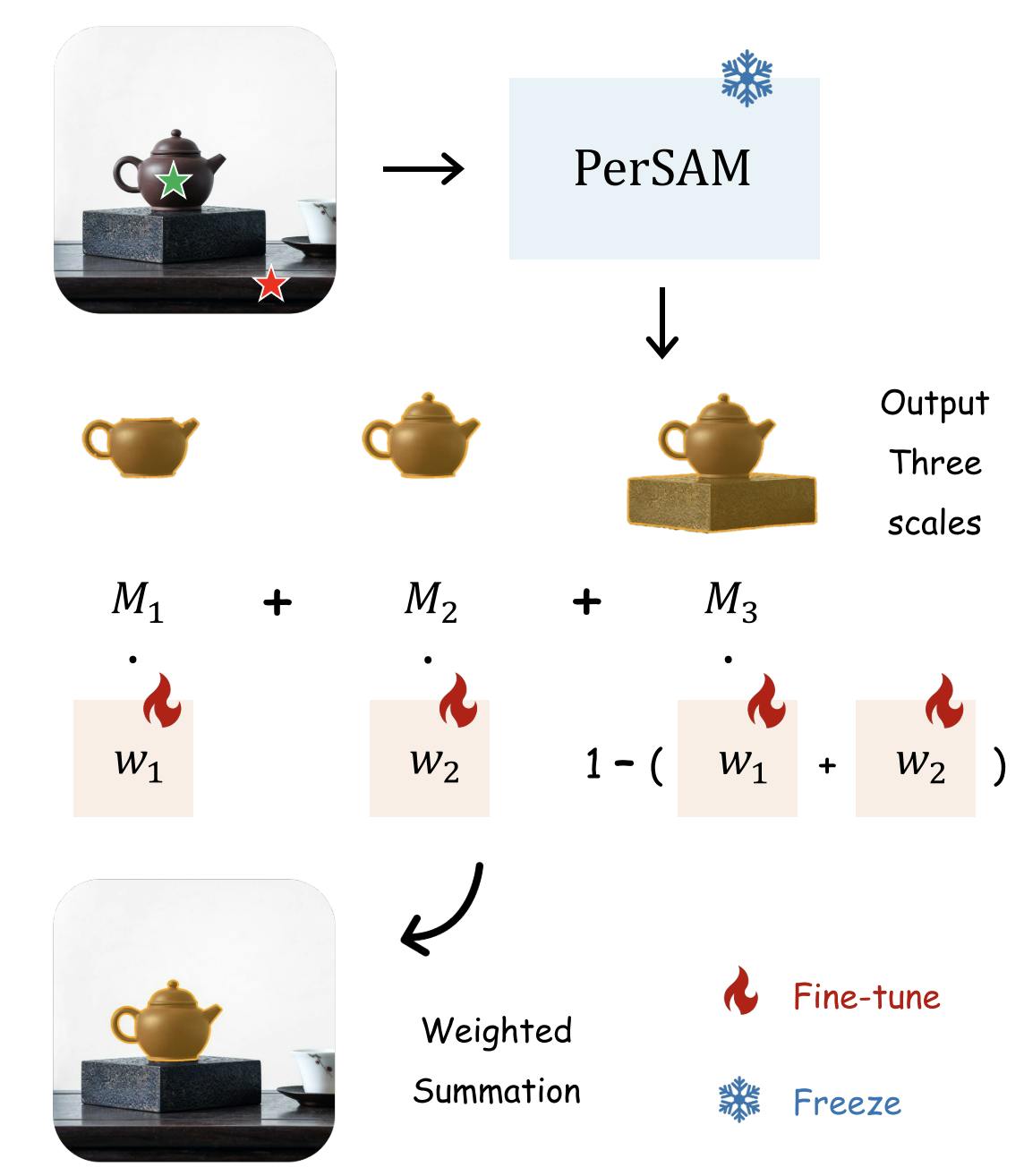
Fine-tuning the Per-SAM
Personalize Segment Anything Model with One Shot
In most of the images, objects have a conceptual hierarchy, which is already discussed in the SAM paper; therefore, SAM outputs 3 different masks when the prompt is ambiguous (especially for the point prompts). The authors of the Per-SAM propose another light layer, consisting of only 2 weights, on top of the SAM architecture to weigh the proposed masks. The entire SAM is frozen, and the generated masks are weighted with the learnable parameters, which results in rapid (under 10 seconds) training. The reported results show that when fine-tuning is applied, the final performance result is significantly improved.
Per-SAM vs. Mask R-CNN: Comparison
Mask R-CNN (Mask Region-based Convolutional Neural Network) is a flexible and powerful framework for object instance segmentation, which is also one of the many deep learning models in Encord Apollo. Unlike SAM architecture, Mask R-CNN only accepts images as input and class annotations as output. Although it emerged a long time ago, it is still a very powerful model and is widely used in lots of applications and research papers as a baseline model. Therefore, comparing the Per-SAM against Mask R-CNN would be a sensible choice.
Benchmark Dataset: DeepFashion-MultiModal
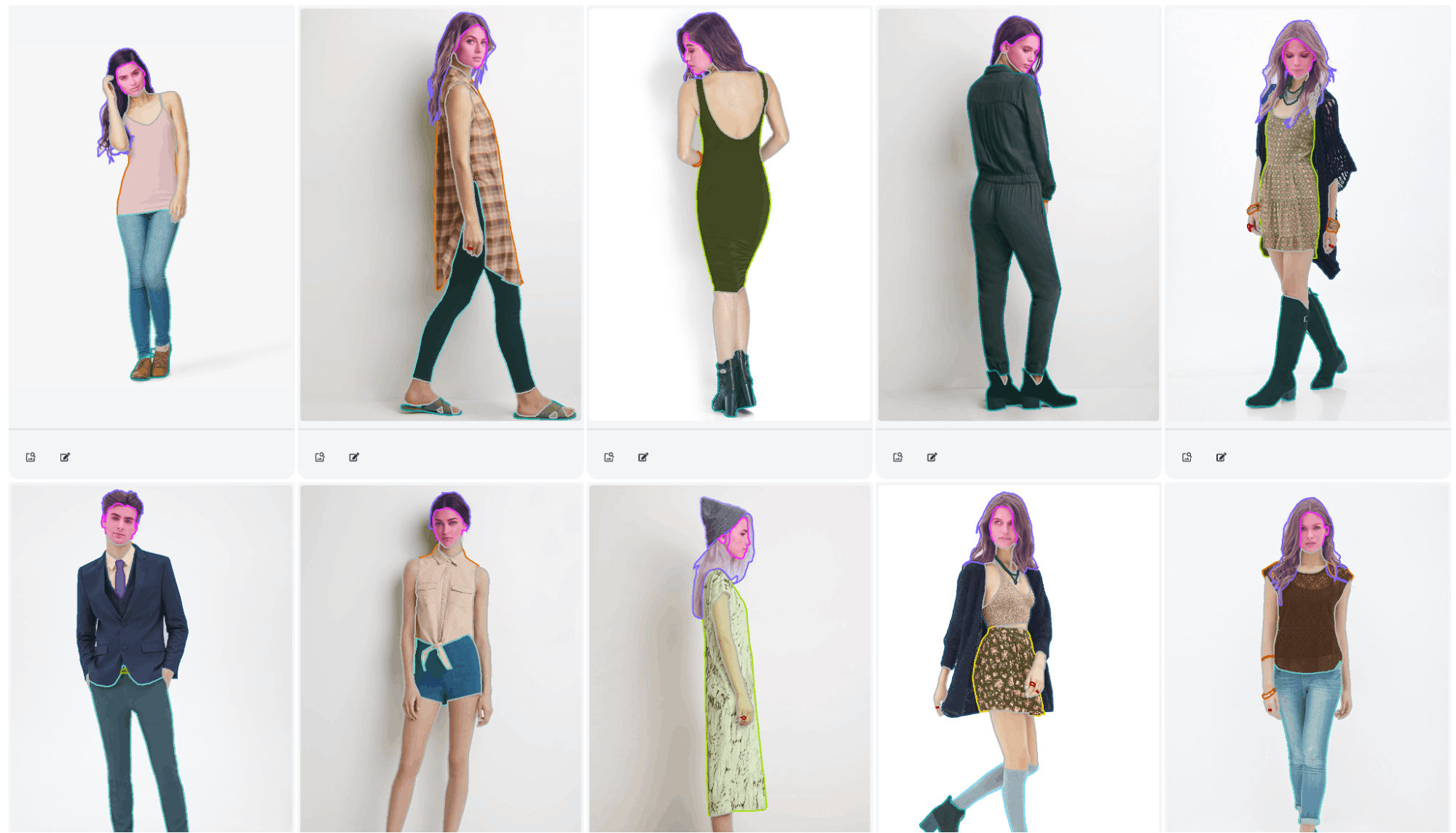
In this benchmark, we will use the DeepFashion-MutiModal dataset, which is a comprehensive collection of images created to facilitate a variety of tasks within the field of clothing and fashion analysis. It contains 44,096 high-resolution human images, including 12,701 full-body human images. All full-body images are manually annotated for 24 classes. The dataset also has key points, dense pose and textual description annotations.

An image and its mask annotations
The dataset is uploaded to Encord Active and here are more sample images and their annotations as seen in Encord Active platform:
First, we have created a training set (10 images) and a test (inference) set (300 images) on the Encord platform. Encord platform provides two important features for this benchmark:
- We can visualize the images and labels easily.
- We can import predictions to the Encord Active platform which calculates the model performance.
We have trained a MaskRCNN model on the training set using Encord Apollo. For the Per-SAM architecture, we have only used the first image in the training set. For the sake of simplicity, only ‘top’ type of class is used for this evaluation. The trained Mask-RCNN model and Per-SAM models are compared on the test images.
Here is the benchmark table:
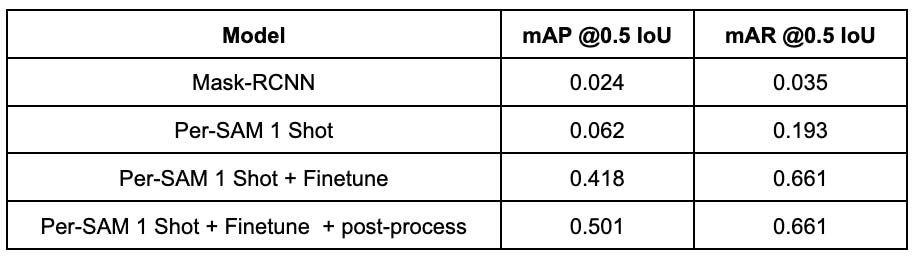
Experiment results indicate that training-free Per-SAM outperforms the Mask-RCNN model, which shows the strong capability and clever approach of this new foundational model. Mask-RCNN and Per-SAM-1 shot performances are quite low which shows the difficulty of the dataset. When Per-SAM is trained on the image to weigh the masks, its performance is significantly improved. With fine tuning, Per-SAM learns the concept of the target object which results in a dramatic decrease in false positives and an increase in true positives. As a final step, we applied a post-processing step that removes the very small objects (if the object area to total area is less than 0.1%) in Per-SAM predictions. Which significantly reduced the false positives and resulted in a boost in the mAP score.
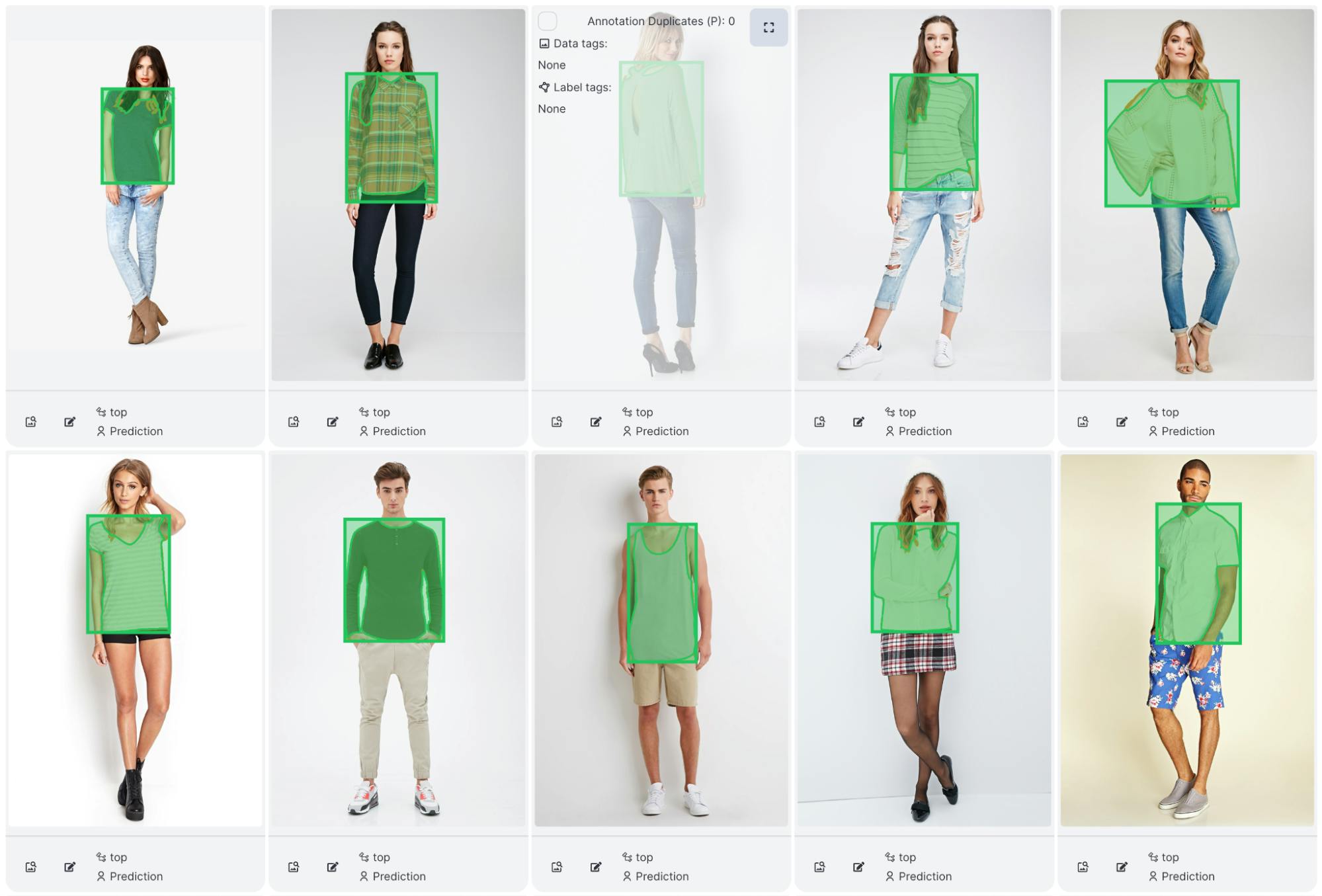
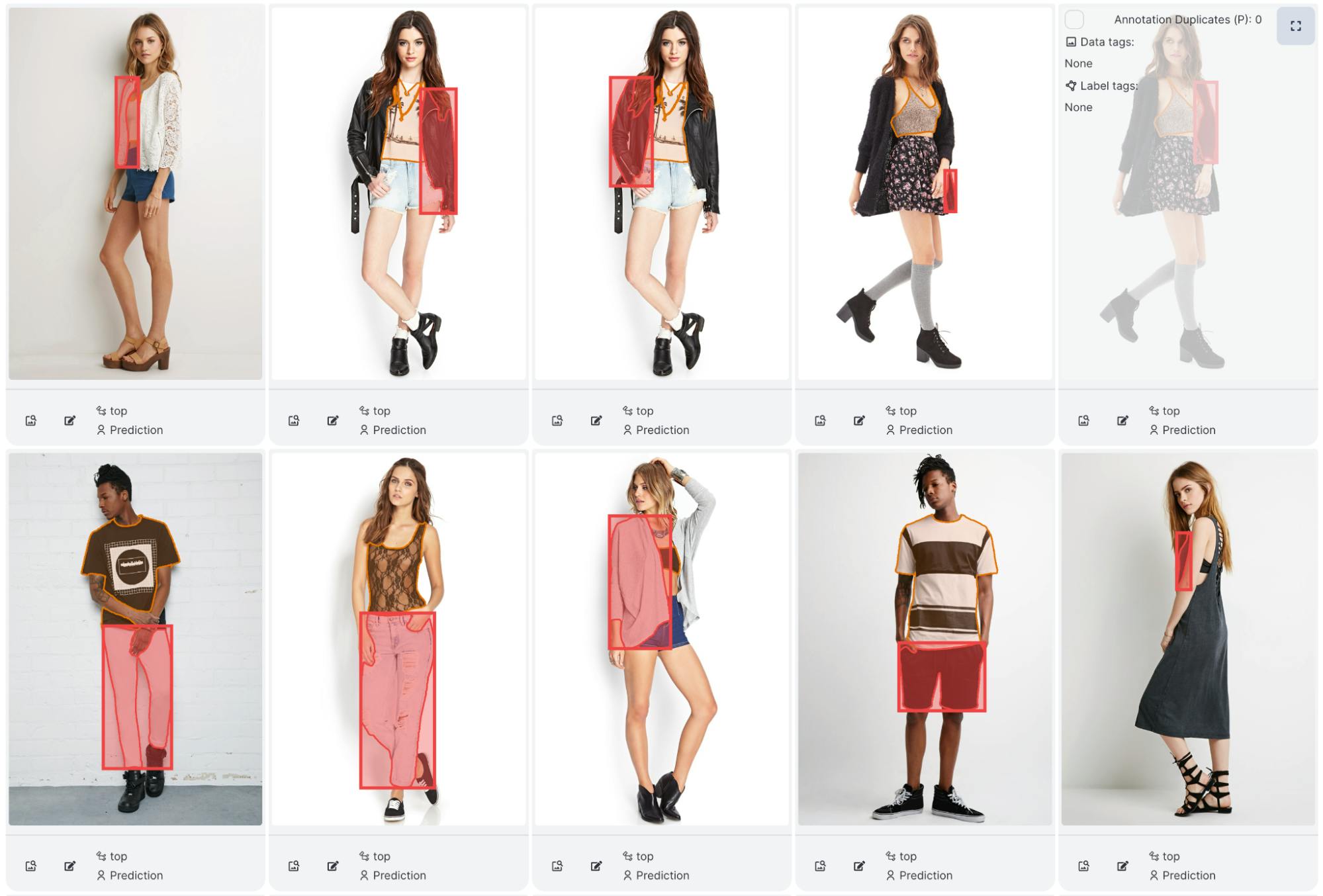
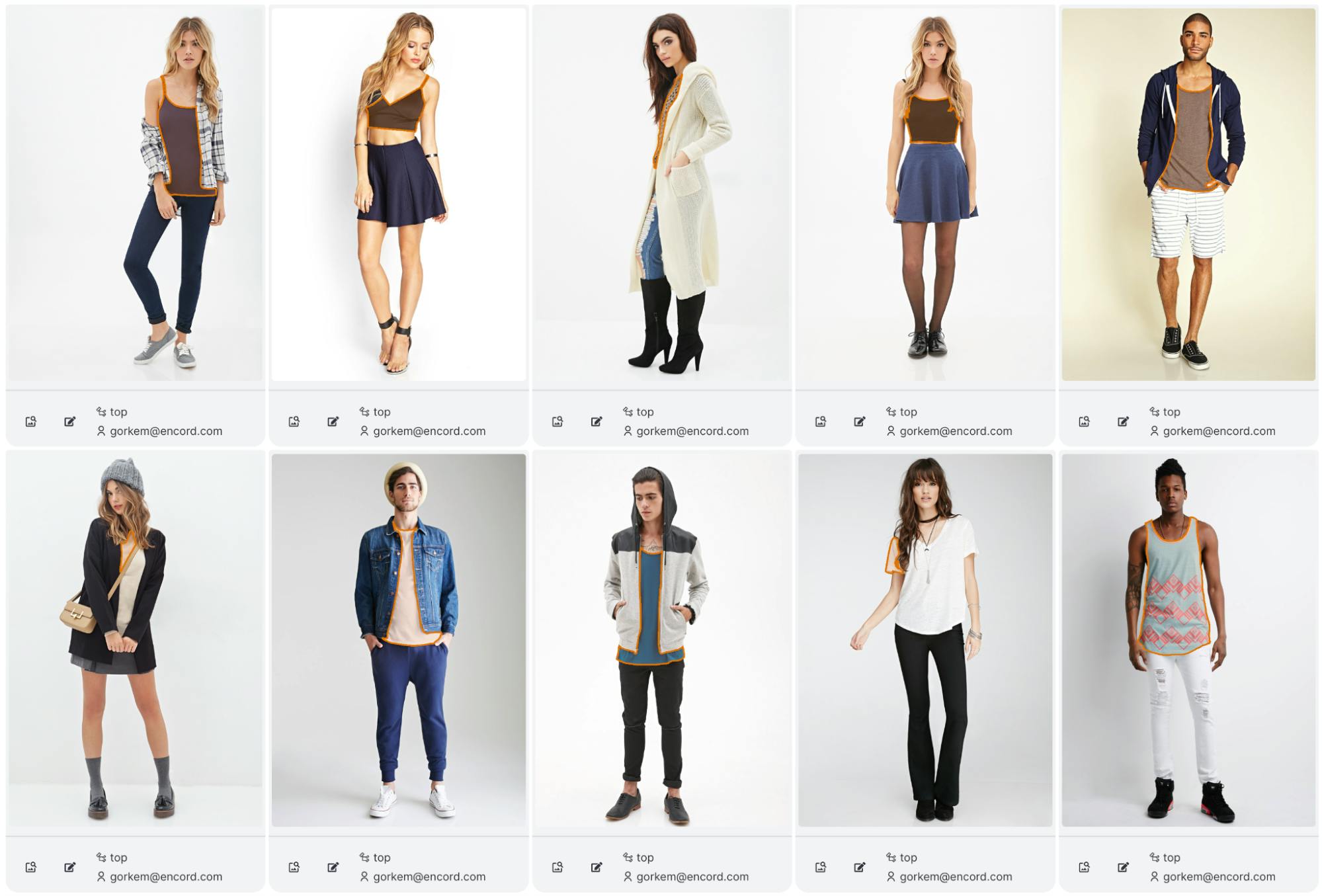
When we examine the individual image results, we see that Per-SAM performs fairly well on most objects. Here are the true positives, false positives and false negatives:
True Positives
False Positives
False Negatives
Conclusion
The experimental results show that new foundational models are very powerful regarding few-shot learning capabilities. Since their learning capacity is much more advanced than previous architectures and they are trained with millions of images (SAM is trained with over 11 million images with more than 1 billion masks), they can quickly learn new classes from a few images.
While the introduction of SAM was a milestone for computer vision, Per-SAM shows that there are many areas to explore on top of the SAM that will open new and more effective solutions. In Encord, we are constantly exploring new research and integrating them into the Encord platform to ease the annotation processes of our users.
