Microsoft MORA: Multi-Agent Video Generation Framework

Sora, famous for making very realistic and creative scenes from written instructions, set a new standard for creating videos that are up to a minute long and closely match the text descriptions given.
Mora distinguishes itself by incorporating several advanced visual AI agents into a cohesive system. This lets it undertake various video generation tasks, including text-to-video generation, text-conditional image-to-video generation, extending generated videos, video-to-video editing, connecting videos, and simulating digital worlds. Mora can mimic Sora’s capabilities using multiple visual agents, significantly contributing to video generation.
In this article, you will learn:
- Mora's innovative multi-agent framework for video generation.
- The importance of open-source collaboration that Mora enables.
- Mora's approach to complex video generation tasks and instruction fidelity.
- About the challenges in video dataset curation and quality enhancement.
- Mora's novel approach uses multiple specialized AI agents, each handling different aspects of the video generation process. This innovation allows various video generation tasks, showcasing adaptability in creating detailed and dynamic video content from textual descriptions.
- Mora aims to fix the problems with current models like Sora, which is closed-source and does not let anyone else use it or do more research in the field, even though it has amazing text-to-video conversion abilities 📝🎬.
- Unfortunately, Mora still has problems with dataset quality, video fidelity, and ensuring that outputs align with complicated instructions and people's preferences. These problems show where more work needs to be done in the future.
OpenAI Sora’s Closed-Source Nature
The closed-source nature of OpenAI's Sora presents a significant challenge to the academic and research communities interested in video generation technologies. Sora's impressive capabilities in generating realistic and detailed videos from text descriptions have set a new standard in the field.
However, the inability to access its source code or detailed architecture hinders external efforts to replicate or extend its functionalities. This limits researchers from fully understanding or replicating its state-of-the-art performance in video generation.
Here are the key challenges highlighted due to Sora's closed-source nature:
Inaccessibility to Reverse-Engineer
Without access to Sora's source code, algorithms, and detailed methodology, the research community faces substantial obstacles in dissecting and understanding the underlying mechanisms that drive its exceptional performance.
This lack of transparency makes it difficult for other researchers to learn from and build upon Sora's advancements, potentially slowing down the pace of innovation in video generation.
Extensive Training Datasets
Sora's performance is not just the result of sophisticated modeling and algorithms; it also benefits from training on extensive and diverse datasets. But the fact that researchers cannot get their hands on similar datasets makes it very hard to copy or improve Sora's work.
Creating, curating, and maintaining high-quality video datasets requires significant resources, including copyright permissions, data storage, and management capabilities. Sora's closed nature worsens these challenges by not providing insights into compiling the datasets, leaving researchers to navigate these obstacles independently.

Computational Power
Creating and training models like Sora require significant computational resources, often involving large clusters of high-end GPUs or TPUs running for extended periods. Many researchers and institutions cannot afford this much computing power, which makes the gap between open-source projects like Mora and proprietary models like Sora even bigger.
Without comparable computational resources, it becomes challenging to undertake the necessary experimentation—with different architectures and hyperparameters—and training regimes required to achieve similar breakthroughs in video generation technology.
Evolution: Text-to-Video Generation
Over the years, significant advancements in text-to-video generation technology have occurred, with each approach and architecture uniquely contributing to the field's growth.
Here's a summary of these evolutionary stages, as highlighted in the discussion about text-to-video generation in the Mora paper:
GANs (Generative Adversarial Networks)
Early attempts at video generation leveraged GANs, which consist of two competing networks: a generator that creates images or videos that aim to be indistinguishable from real ones, and a discriminator that tries to differentiate between the real and generated outputs.
Despite their success in image generation, GANs faced challenges in video generation due to the added complexity of temporal coherence and higher-dimensional data.
Generative Video Models
Moving beyond GANs, the field saw the development of generative video models designed to produce dynamic sequences. Generating realistic videos frame-by-frame and maintaining temporal consistency is a challenge, unlike in static image generation.
Auto-Regressive Transformers
Auto-regressive transformers were a big step forward because they could generate video sequences frame-by-frame. These models predicted each new frame based on the previously generated frames, introducing a sequential element that mirrors the temporal progression of videos. But this approach often struggled with long-term coherence over longer sequences.
Large-Scale Diffusion Models
Diffusion models, known for their capacity to generate high-quality images, were extended to video generation. These models gradually refine a random noise distribution toward a coherent output. They apply this iterative denoising process to the temporal domain of videos.
Image Diffusion U-Net
Adapting the U-Net architecture for image diffusion models to video content was critical. This approach extended the principles of image generation to videos, using a U-Net that operates over sequences of frames to maintain spatial and temporal coherence.
3D U-Net Structure
The change to a 3D U-Net structure allowed for more nuance in handling video data, considering the extra temporal dimension. This change also made it easier to model time-dependent changes, improving how we generate coherent and dynamic video content.
Latent Diffusion Models (LDMs)
LDMs generate content in a latent space rather than directly in pixel space. This approach reduces computational costs and allows for more efficient handling of high-dimensional video data. LDMs have shown that they can better capture the complex dynamics of video content.
Diffusion Transformers
Diffusion transformers (DiT) combine the strengths of transformers in handling sequential data with the generative capabilities of diffusion models. This results in high-quality video outputs that are visually compelling and temporally consistent.
AI Agents: Advanced Collaborative Multi-agent Structures
The paper highlights the critical role of collaborative, multi-agent structures in developing Mora. It emphasizes their efficacy in handling multimodal tasks and improving video generation capabilities.
Here's a concise overview based on the paper's discussion on AI Agents and their collaborative frameworks:
Multimodal Tasks
Advanced collaborative multi-agent structures address multimodal tasks involving processing and generating complex data across different modes, such as text, images, and videos. These structures help integrate various AI agents, each specialized in handling specific aspects of the video generation process, from understanding textual prompts to creating visually coherent sequences.
Cooperative Agent Framework (Role-Playing)
The cooperative agent framework, characterized by role-playing, is central to the operation of these multi-agent structures. Each agent is assigned a unique role or function in this framework, such as prompt enhancement, image generation, or video editing.
By defining these roles, the framework ensures that an agent with the best skills for each task is in charge of that step in the video generation process, increasing overall efficiency and output quality.
Multi-Agent Collaboration Strategy
The multi-agent collaboration strategy emphasizes the orchestrated interaction between agents to achieve a common goal. In Mora, this strategy involves the sequential and sometimes parallel processing of tasks by various agents.
This collaborative approach allows for the flexible and dynamic generation of video content that aligns with user prompts.
AutoGen (Generic Programming Framework)
A notable example of multi-agent collaboration in practice is AutoGen. This generic programming framework is designed to automate the assembly and coordination of multiple AI agents for a wide range of applications.
Within the context of video generation, AutoGen can streamline the configuration of agents according to the specific requirements of each video generation task to generate complex video content from textual or image-based prompts.

Mora drone to butterfly flythrough shot. | Image Source.
Role of an AI Agent
The paper outlines the architecture involving multiple AI agents, each serving a specific role in the video generation process. Here's a closer look at the role of each AI agent within the framework:
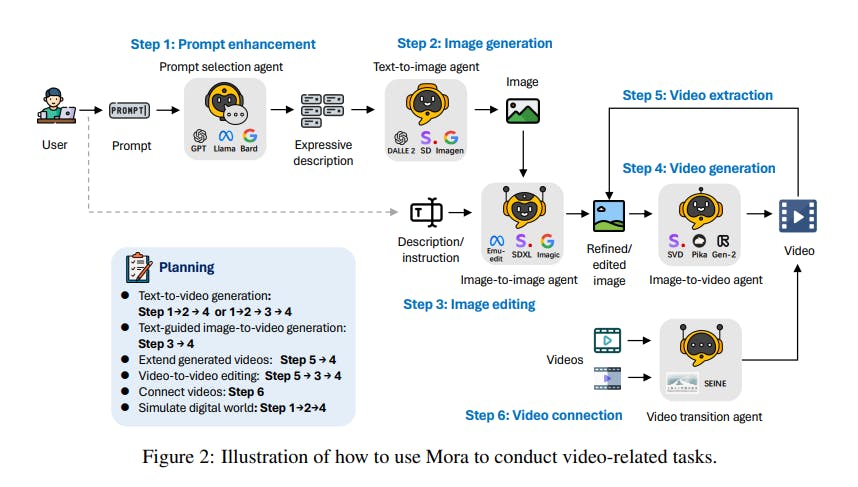
Illustration of how to use Mora to conduct video-related tasks
Prompt Selection and Generation Agent
This agent is tasked with processing and optimizing textual prompts for other agents to process them further. Here are the key techniques used for Mora:
- GPT-4: This agent uses the generative capabilities of GPT-4 to generate high-quality prompts that are detailed and rich in context.
- Prompt Selection: This involves selecting or enhancing textual prompts to ensure they are optimally prepared for the subsequent video generation process. This step is crucial for setting the stage for generating images and videos that closely align with the user's intent.
Text-to-Image Generation Agent
This agent uses a retrained large text-to-image model to convert the prompts into initial images. The retraining process ensures the model is finely tuned to produce high-quality images, laying a strong foundation for the video generation process.
Image-to-Image Generation Agent
This agent specializes in image-to-image generation, taking initial images and editing them based on new prompts or instructions. This ability allows for a high degree of customization and improvement in video creation.
Image-to-Video Generation Agent
This agent transforms static images into dynamic video sequences, extending the visual narrative by generating coherent frames. Here are the core techniques and models:
- Core Components: It incorporates two pre-trained models: GPT-3 for understanding and generating text-based instructions, and Stable Diffusion for translating these instructions into visual content.
- Prompt-to-Prompt Technique: The prompt-to-prompt technique guides the transformation from an initial image to a series of images that form a video sequence.
- Classifier-Free Guidance: Classifier-free guidance is used to improve the fidelity of generated videos to the textual prompts so that the videos remain true to the users' vision.
- Text-to-Video Generation Agent: This role is pivotal in transforming static images into dynamic videos that capture the essence of the provided descriptions.
- Stable Video Diffusion (SVD) and Hierarchical Training Strategy: A model specifically trained to understand and generate video content, using a hierarchical training strategy to improve the quality and coherence of the generated videos.
Video Connection Agent
This agent creates seamless transitions between two distinct video sequences for a coherent narrative flow. Here are the key techniques used:
- Pre-Trained Diffusion-Based T2V Model: This model uses a pre-trained diffusion-based model specialized in text-to-video (T2V) tasks to connect separate video clips into a cohesive narrative.
- Text-Based Control: This method uses textual descriptions to guide the generation of transition videos that seamlessly connect disparate video clips, ensuring logical progression and thematic consistency.
- Image-to-Video Animation and Autoregressive Video Prediction: These capabilities allow the agent to animate still images into video sequences, predict and generate future video frames based on previous sequences, and create extended and coherent video narratives.
Mora’s Video Generation Process
Mora's video-generation method is a complex, multi-step process that uses the unique capabilities of specialized AI agents within its framework. This process allows Mora to tackle various video generation tasks, from creating videos from text descriptions to editing and connecting existing videos.
Here's an overview of how Mora handles each task:
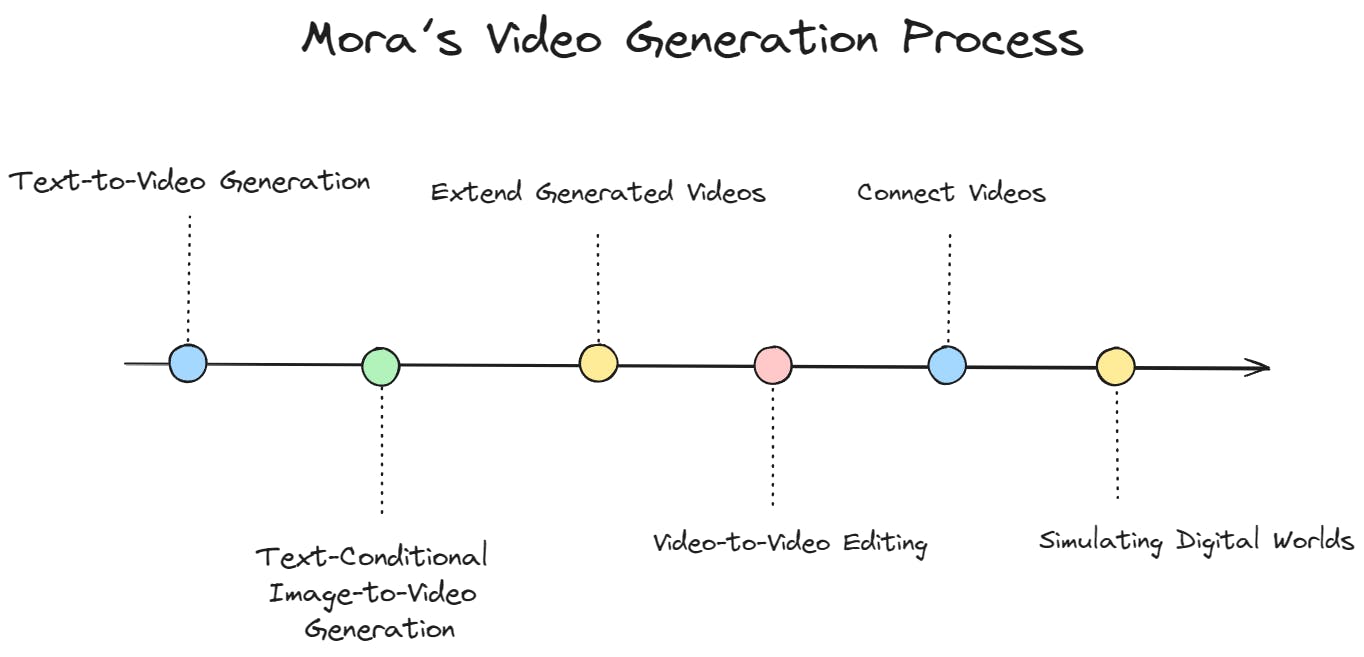
Mora’s video generation process.
Text-to-Video Generation
This task begins with a detailed textual prompt from the user. Then, the Text-to-Image Generation Agent converts the prompts into initial static images. These images serve as the basis for the Image-to-Video Generation Agent, which creates dynamic sequences that encapsulate the essence of the original text and produce a coherent video narrative.
Text-Conditional Image-to-Video Generation
This task combines textual prompts with a specific starting image. Mora first improves the input with the Prompt Selection and Generation Agent, ensuring that the text and image are optimally prepared for video generation.
Then, the Image-to-Video Generation Agent takes over, generating a video that evolves from the initial image and aligns with the textual description.
Extend Generated Videos
To extend an existing video, Mora uses the final frame of the input video as a launchpad. The Image-to-Video Generation Agent crafts additional sequences that logically continue the narrative from the last frame, extending the video while maintaining narrative and visual continuity.
Video-to-Video Editing
In this task, Mora edits existing videos based on new textual prompts. The Image-to-Image Generation Agent first edits the video's initial frame according to the new instructions. Then, the Image-to-Video Generation Agent generates a new video sequence from the edited frame, adding the desired changes to the video content.
Connect Videos
Connecting two videos involves creating a transition between them. Mora uses the Video Connection Agent, which analyzes the first video's final frame and the second's initial frame. It then generates a transition video that smoothly links the two segments into a cohesive narrative flow.
Simulating Digital Worlds
Mora generates video sequences in this task that simulate digital or virtual environments. The process involves appending specific style cues (e.g., "in digital world style") to the textual prompt, guiding the Image-to-Video Generation Agent to create a sequence reflecting the aesthetics of a digital realm.
This can involve stylistically transforming real-world images into digital representations or generating new content within the specified digital style.
Mora: Experimental Setup
As detailed in the paper, the experimental setup for evaluating Mora is comprehensive and methodically designed to assess the framework's performance across various dimensions of video generation. Here's a breakdown of the setup:
Baseline
The baseline for comparison includes existing open-sourced models that showcase competitive performance in video generation tasks. These models include Videocrafter, Show-1, Pika, Gen-2, ModelScope, LaVie-Interpolation, LaVie, and CogVideo.
These models are a reference point for evaluating Mora's advancements and position relative to the current state-of-the-art video generation.
Basic Metrics
The evaluation framework comprises several metrics to quantify Mora's performance across different dimensions of video quality and condition consistency:
Video Quality Measurement
- Object Consistency: Measures the stability of object appearances across video frames.
- Background Consistency: Assesses the uniformity of the background throughout the video.
- Motion Smoothness: Evaluates the fluidity of motion within the video.
- Aesthetic Score: Gauges the artistic and visual appeal of the video.
- Dynamic Degree: Quantifies the video's dynamic action or movement level.
- Imaging Quality: Assesses the overall visual quality of the video, including clarity and resolution.
Video Condition Consistency Metric
- Temporal Style: Measures how consistently the video reflects the temporal aspects (e.g., pacing, progression) described in the textual prompt.
- Appearance Style: Evaluates the adherence of the video's visual style to the descriptions provided in the prompt, ensuring that the generated content matches the intended appearance.
Self-Defined Metrics
- Video-Text Integration (VideoTI): Measures the model’s fidelity to textual instructions by comparing text representations of input images and generated videos.
- Temporal Consistency (TCON): Evaluates the coherence between an original video and its extended version, providing a metric for assessing the integrity of extended video content.
- Temporal Coherence (Tmean): Quantifies the correlation between the intermediate generated and input videos, measuring overall temporal coherence.
- Video Length: This parameter quantifies the duration of the generated video content, indicating the model's capacity for producing videos of varying lengths.
Implementation Details
The experiments use high-performance hardware, specifically TESLA A100 GPUs with substantial VRAM. This setup ensures that Mora and the baseline models are evaluated under conditions allowing them to fully express their video generation capabilities. The choice of hardware reflects the computational intensity of training and evaluating state-of-the-art video generation models.
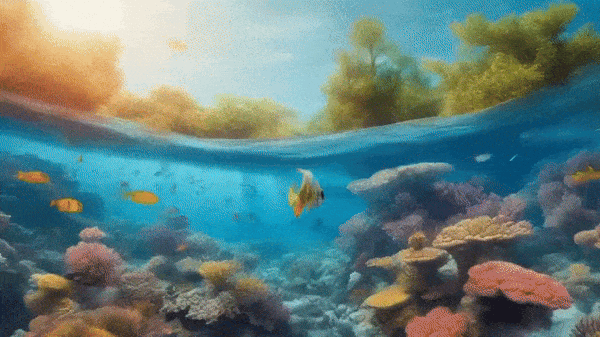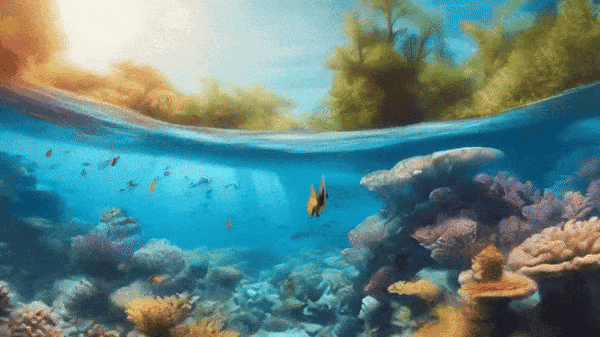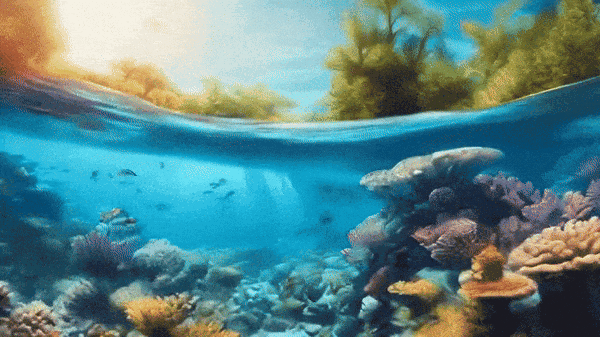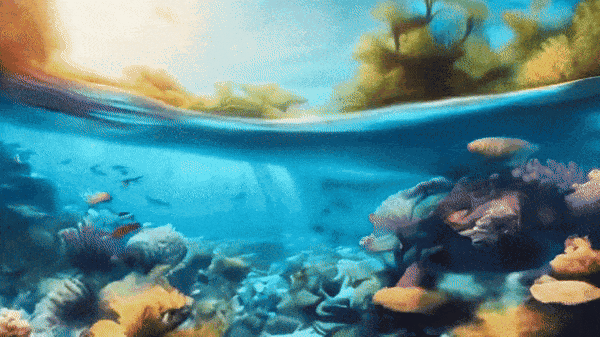
Mora video generation - Fish underwater flythrough
Limitations of Mora
The paper outlines several limitations of the Mora framework. Here's a summary of these key points:
Curating High-Quality Video Datasets
Access to high-quality video datasets is a major challenge for training advanced video generation models like Mora. Copyright restrictions and the sheer volume of data required make it difficult to curate diverse and representative datasets that can train models capable of generating realistic and varied video content.
Quality and Length Gaps
While Mora demonstrates impressive capabilities, it has a noticeable gap in quality and maximum video length compared to state-of-the-art models like Sora. This limitation is particularly evident in tasks requiring the generation of longer videos, where maintaining visual quality and coherence becomes increasingly challenging.

Simulating videos in Mora vs in Sora.
Instruction Following Capability
Mora sometimes struggles to precisely follow complex or detailed instructions, especially when generating videos that require specific actions, movements, or directionality. This limitation suggests that further improvement in understanding and interpreting textual prompts is needed.
Human Visual Preference Alignment
The experimental results may not always align with human visual preferences, particularly in scenarios requiring the generation of realistic human movements or the seamless connection of video segments. This misalignment highlights the need to incorporate a more nuanced understanding of physical laws and human dynamics into the video-generation process.
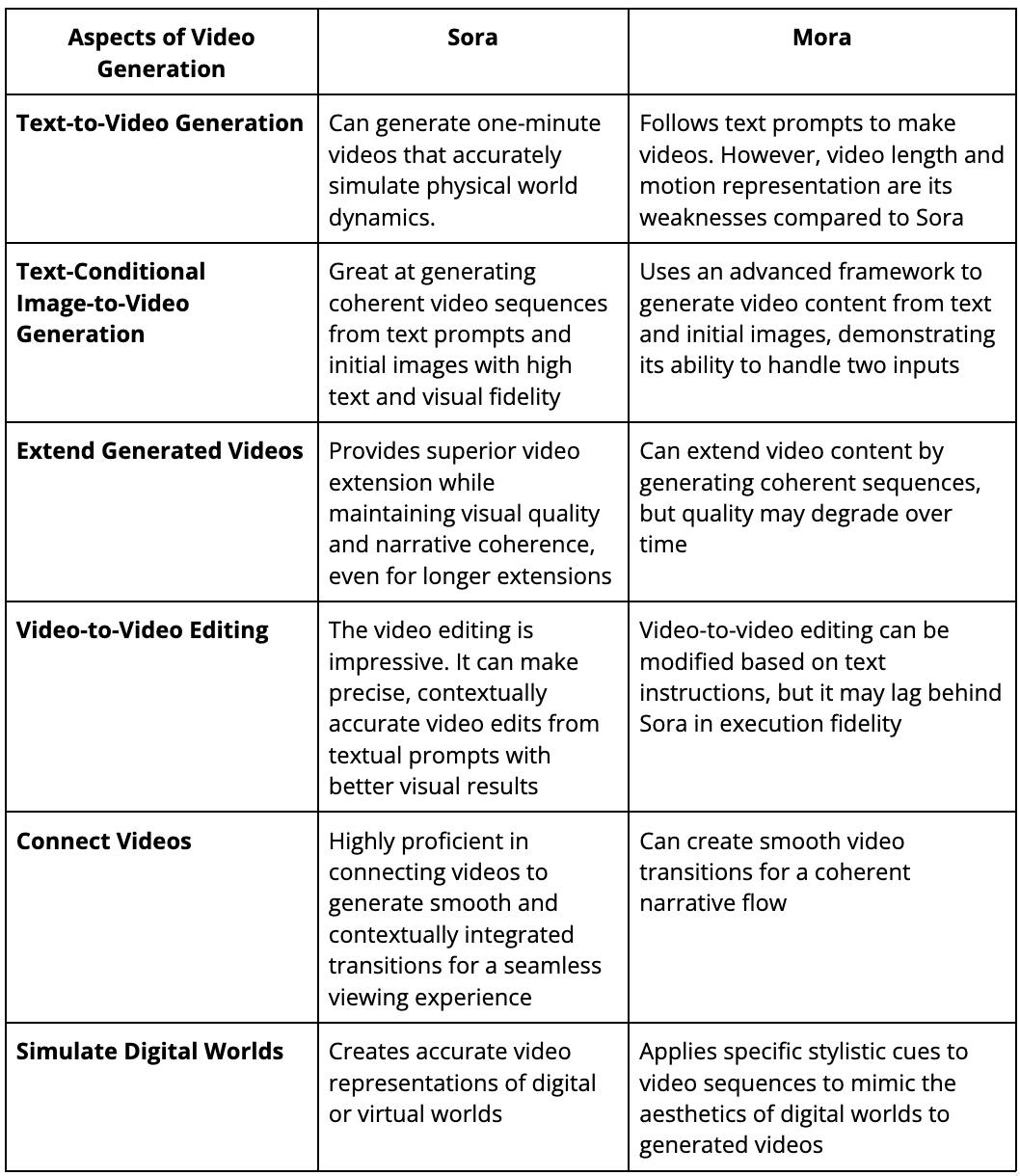
Mora Vs. Sora: Feature Comparisons
The paper compares Mora and OpenAI's Sora across various video generation tasks. Here's a detailed feature comparison based on their capabilities in different aspects of video generation:
Mora Multi-Agent Framework: Key Takeaways
The paper "Mora: Enabling Generalist Video Generation via a Multi-Agent Framework" describes Mora, a new framework that advances video technology. Using a multi-agent approach, Mora is flexible and adaptable across various video generation tasks, from creating detailed scenes to simulating complex digital worlds. Because it is open source, it encourages collaboration, which leads to new ideas, and lets the wider research community add to and improve its features.
Even though Mora has some good qualities, it needs high-quality video datasets, video quality, length gaps, trouble following complicated instructions correctly, and trouble matching outputs to how people like to see things. Finding solutions to these problems is necessary to make Mora work better and be used in more situations.
Continuing to improve and develop Mora could change how we make video content so it is easier for creators and viewers to access and have an impact.
Frequently asked questions
The study doesn't specify particular datasets. Typically, datasets are chosen based on diversity, quality, and relevance to the tasks Mora is designed to perform.
Mora operates through a multi-agent framework. Each agent specializes in a different aspect of video generation, from prompt processing to video synthesis, and collaborates to convert text descriptions into dynamic videos.
While detailed instructions aren't provided in the summary, using Mora likely involves inputting textual prompts into its system. The system processes these through various specialized agents to generate video content.
The experiments were conducted using TESLA A100 GPUs, evaluating Mora’s performance across several metrics like video quality, consistency with the textual prompt, and more, compared against baseline models.
Models like Videocrafter, Show-1, Pika, Gen-2, and Sora are mentioned in the baseline for comparison, showcasing a range of approaches in the text-to-video generation domain.
Mora, with its multi-agent framework, emphasizes flexibility and open-source collaboration, targeting a wide array of video generation tasks. In contrast, Sora is known for its high-quality output and advanced capabilities in generating videos from text, operating as a closed-source model with potentially different underlying technologies.
Closed-source models restrict access to their code and training methodologies, while open-source models are freely available for anyone to use, modify, and distribute.
Yes, Mora is an open-source model, encouraging collaboration and innovation within the AI research community.
Mora's real-time applications could include content creation for media, digital marketing, education, virtual reality environments, and any field requiring dynamic video content generation from text.
Encord addresses the limitations of traditional annotation tools by offering a scalable, efficient platform specifically designed for video annotation. Unlike traditional tools that may struggle with large datasets, Encord provides advanced features for data organization, workflow management, and automated annotation processes, making it a superior choice for teams looking to optimize their annotation efforts.
Encord provides a robust platform for video annotation, catering to various use cases, especially in the realms of AI training models and large language models (LLMs). The platform is designed to enhance the efficiency of video data labeling, making it a valuable tool for organizations looking to leverage video content.
Encord offers specialized tools for video data annotation that cater to medical use cases like colonoscopy and endoscopy. The platform allows teams to efficiently manage and label large volumes of video data, facilitating the training of AI models to recognize and interpret critical visual information effectively.
Encord provides robust video annotation capabilities, allowing users to segment video sections, add descriptive text, and perform video classifications. Unlike some platforms, Encord offers first-class support for various video modalities, simplifying the annotation process and enhancing data usability.
Encord provides a streamlined export process for COCO panoptic, allowing users to export encoded image labels alongside masks and instances. This comprehensive approach minimizes the need for additional tweaking, ensuring a seamless transition from labeling to export.
Yes, users have the flexibility to create their own editor agents in Encord. This allows for the integration of custom models that may be fine-tuned on specific datasets, enhancing performance and tailoring the labeling process to unique project requirements.
Encord is designed to support various data modalities, including text, computer vision, and audio. This versatility ensures that teams can use a single platform to handle multiple types of data, streamlining their workflows and enhancing overall efficiency.
While Encord primarily focuses on image annotation, it does offer capabilities for video annotation as well. However, for users primarily engaged with image projects, the platform provides ample resources and functionalities to meet their needs effectively.
Yes, Encord is particularly well-suited for video annotation projects. Many teams choose Encord for its robust video annotation capabilities, which streamline the process and enhance the quality of results.