9 Best Generative AI Model Validation Tools for Computer Vision

The integrity, diversity, and reliability of the content that AI systems generate depend on generative AI model validation. It involves using tools to test, evaluate, and improve these models. Validation is important for detecting biases, errors, and potential risks in AI-generated outputs and for facilitating their rectification to adhere to ethical and legal guidelines.
The demand for robust generative AI model validation tools is increasing with the adoption of generative AI models. This article presents the top 9 tools for generative AI model validation. These tools help identify and correct discrepancies in generated content to improve model reliability and transparency in AI applications.
The significance of model validation tools cannot be overstated, especially as generative AI continues to become mainstream. These tools are critical to the responsible and sustainable advancement of generative AI because they ensure the quality and integrity of AI-generated content.
Here’s the list of tools we will cover in this article:
- Encord Active
- DeepChecks
- HoneyHive
- Arthur Bench
- Galileo LLM Studio
- TruLens
- Arize
- Weights and Biases
- HumanLoop
Now that we understand the importance of optimizing performance in generative AI models, let's delve into the guidelines or criteria that can help us evaluate different tools and help us achieve these goals.
Compare the Best Generative AI Model Validation Tools
In the sections below, you can compare 9 of best modal validation tools for generative AI.
Encord Active
Encord Active is a data-centric model validation platform that allows you to test your models and deploy into production with confidence. Inspect model predictions and compare to your Ground Truth, surface common issue types and failure environments, and easily communicate errors back to your labeling team in order to validate your labels for better model performance. By emphasizing real data for accuracy and efficiency, Encord Active ensures foundation models are optimized and free from biases, errors, and risks.
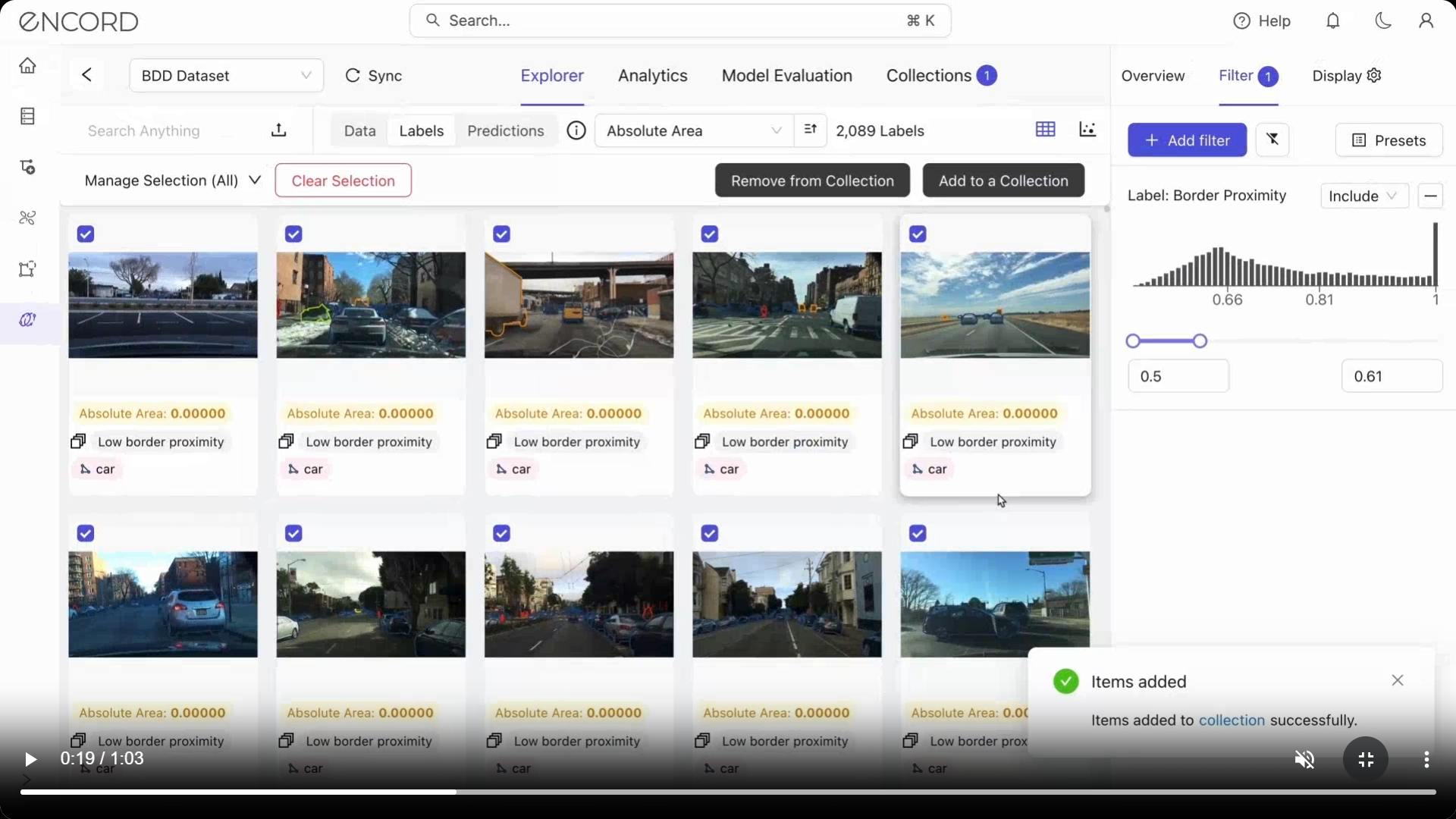
The Model Evaluation & Data Curation Toolkit to Build Better Models
Key Features
Let’s evaluate Encord Active based on the specified criteria:
- Scalability and Performance: Encord Active ensures robust model performance and adaptability as data landscapes evolve.
- Model Evaluation Metrics: The tool provides robust model evaluation capabilities, uncovering failure modes and issues.
- Built-in Metrics to Assess Sample Quality: It automatically surfaces label errors and validates labels for better model performance.
- Interpretability and Explainability: Encord Active offers explainability reports for model decisions.
- Experiment Tracking: While not explicitly mentioned, it likely supports experiment tracking.
- Usage Metrics: Encord Active helps track usage metrics related to data curation and model evaluation.
- Semantic Search: Encord Active is a data-centric AI platform that uses a built-in CLIP to index images from Annotate. The indexing process involves analyzing images and textual data to create a searchable representation that aligns images with potential textual queries. This provides an in-depth analysis of your data quality.Semantic search with Encord Active can be performed in two ways. Either through text-based queries by searching your images with natural language, or through Reference or anchor image by searching your images using a reference or anchor image.
The guide recommends using Encord Annotate to create a project and import the dataset, and Encord Active to search data with natural language.
Best for
- Encord Active is best suited for ML practitioners deploying production-ready AI applications, offering data curation, labeling, model evaluation, and semantic search capabilities all in one.
Pricing
- Encord Active OS is an open-source toolkit for local installation.
- Encord Active Cloud (an advanced and hosted version) has a pay-per-user model. Get started here.
Deepchecks
Deepchecks is an open-source tool designed to support a wide array of language models, including ChatGPT, Falcon, LLaMA, and Cohere.
Key Features and Functionalities
- Scalability and Performance: Deepchecks ensures validation for data and models across various phases, from research to production.
- Model Evaluation Metrics: Deepchecks provides response time and throughput metrics to assess model accuracy and effectiveness.
- Interpretability and Explainability: Deepchecks focuses on making model predictions understandable by associating inputs with consistent outputs.
- Usage Metrics: Deepchecks continuously monitors models and data throughout their lifecycle, customizable based on specific needs.
- Open-Source Synergy: Deepchecks supports both proprietary and open-source models, making it accessible for various use cases.
Best for
- Deepchecks is best suited for NLP practitioners, researchers, and organizations seeking comprehensive validation, monitoring, and continuous improvement of their NLP models and data.
Pricing
The pricing model for Deepchecks is based on the application count, seats, daily estimates and support options. The plans are categorized into Startup, Scale and Dedicated.
HoneyHive
HoneyHive is a platform with a suite of features designed to ensure model accuracy and reliability across text, images, audio, and video outputs. Adhering to NIST's AI Risk Management Framework provides a structured approach to managing risks inherent in non-deterministic AI systems, from development to deployment.
HoneyHive - Evaluation and Observability for AI Applications
Key Features and Functionalities
- Scalability and Performance: HoneyHive enables teams to deploy and continuously improve LLM-powered products, working with any model, framework, or environment.
- Model Evaluation Metrics: It provides evaluation tools for assessing prompts and models, ensuring robust performance across the application lifecycle.
- Built-in Metrics for Sample Quality: HoneyHive includes built-in sample quality assessment, allowing teams to monitor and debug failures in production.
- Interpretability and Explainability: While not explicitly mentioned, HoneyHive’s focus on evaluation and debugging likely involves interpretability and explainability features.
- Experiment Tracking: HoneyHive offers workspaces for prompt templates and model configurations, facilitating versioning and management.
- Usage Metrics: No explicit insights into usage patterns and performance metrics.
Additional Features
- Model Fairness Assessment: Incorporate tools to evaluate model fairness and bias, ensuring ethical and equitable AI outcomes.
- Automated Hyperparameter Tuning: Integrate hyperparameter optimization techniques to fine-tune models automatically.
Best for
- HoneyHive.ai is best suited for small teams building Generative AI applications, providing critical evaluation and observability tools for model performance, debugging, and collaboration.
Pricing
HoneyHive.ai offers a free plan for individual developers.
Arthur Bench
An open-source evaluation tool for comparing LLMs, prompts, and hyperparameters for generative text models, the Arthur Bench open-source tool will enable businesses to evaluate how different LLMs will perform in real-world scenarios so they can make decisions when integrating the latest AI technologies into their operations.
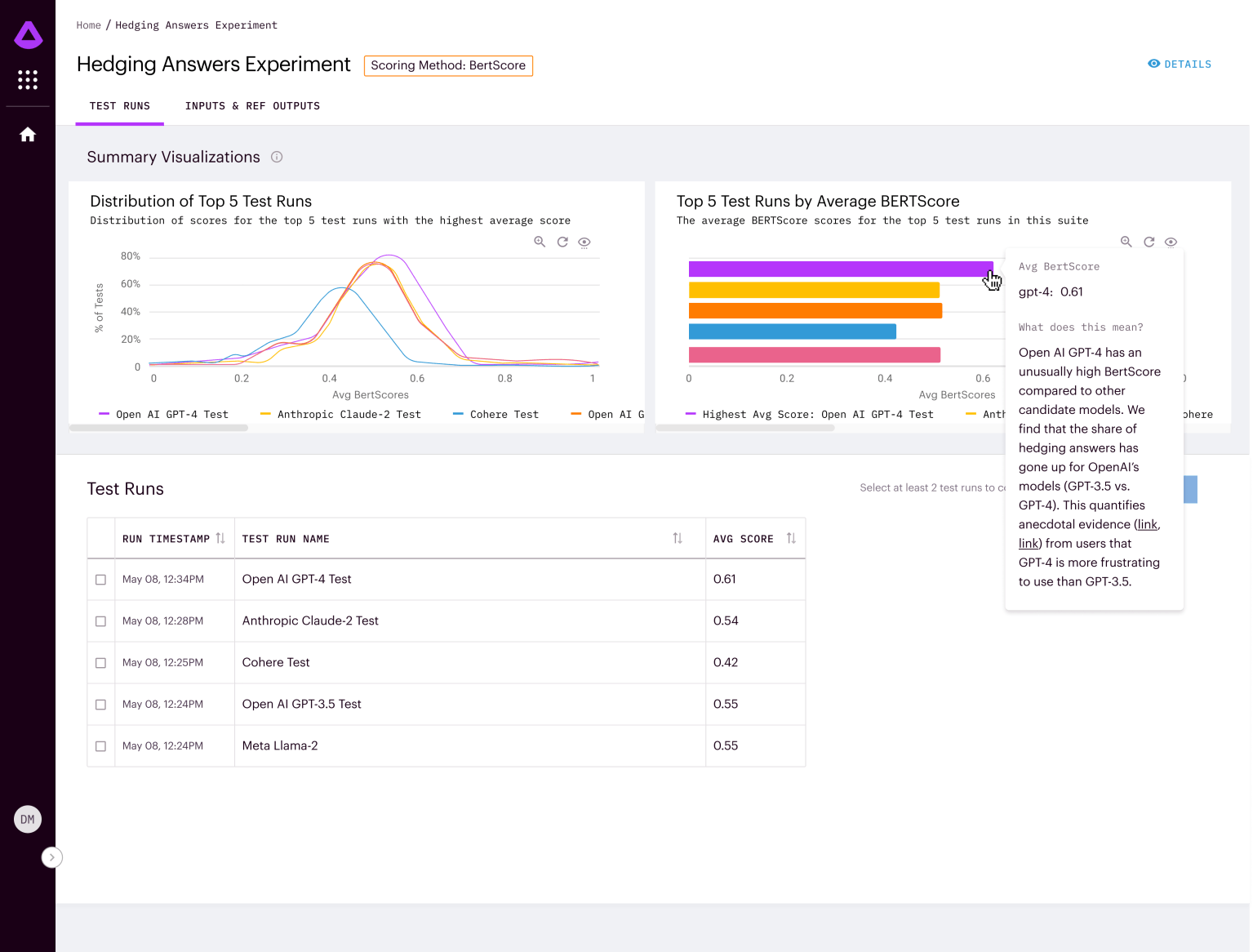
Arthur Bench’s comparison of the hedging tendencies in various LLM responses
Key Features and Functionalities
- Scalability and Performance: Arthur Bench evaluates large language models (LLMs) and allows comparison of different LLM options.
- Model Evaluation Metrics: Bench provides a full suite of scoring metrics, including summarization quality and hallucinations.
- Built-in Metrics to Assess Sample Quality: Arthur Bench offers metrics for assessing accuracy, readability, and other criteria.
- Interpretability and Explainability: Not explicitly mentioned
- Experiment Tracking: Bench allows teams to compare test runs.
- Usage Metrics: Bench is available as both a local version (via GitHub) and a cloud-based SaaS offering, completely open source.
Additional Features
- Customizable Scoring Metrics: Users can create and add their custom scoring metrics.
- Standardized Prompts for Comparison: Bench provides standardized prompts designed for business applications, ensuring fair evaluations.
Best for
- The Arthur Bench tool is best suited for data scientists, machine learning researchers, and teams comparing large language models (LLMs) using standardized prompts and customizable scoring metrics.
Pricing
Arthur Bench is an open-source AI model evaluator, freely available for use and contribution, with opportunities for monetization through team dashboards.
Galileo LLM Studio
Galileo LLM Studio is a platform designed for building production-grade Large Language Model (LLM) applications, providing tools for ensuring that LLM-powered applications meet standards. The tool supports local and cloud testing.
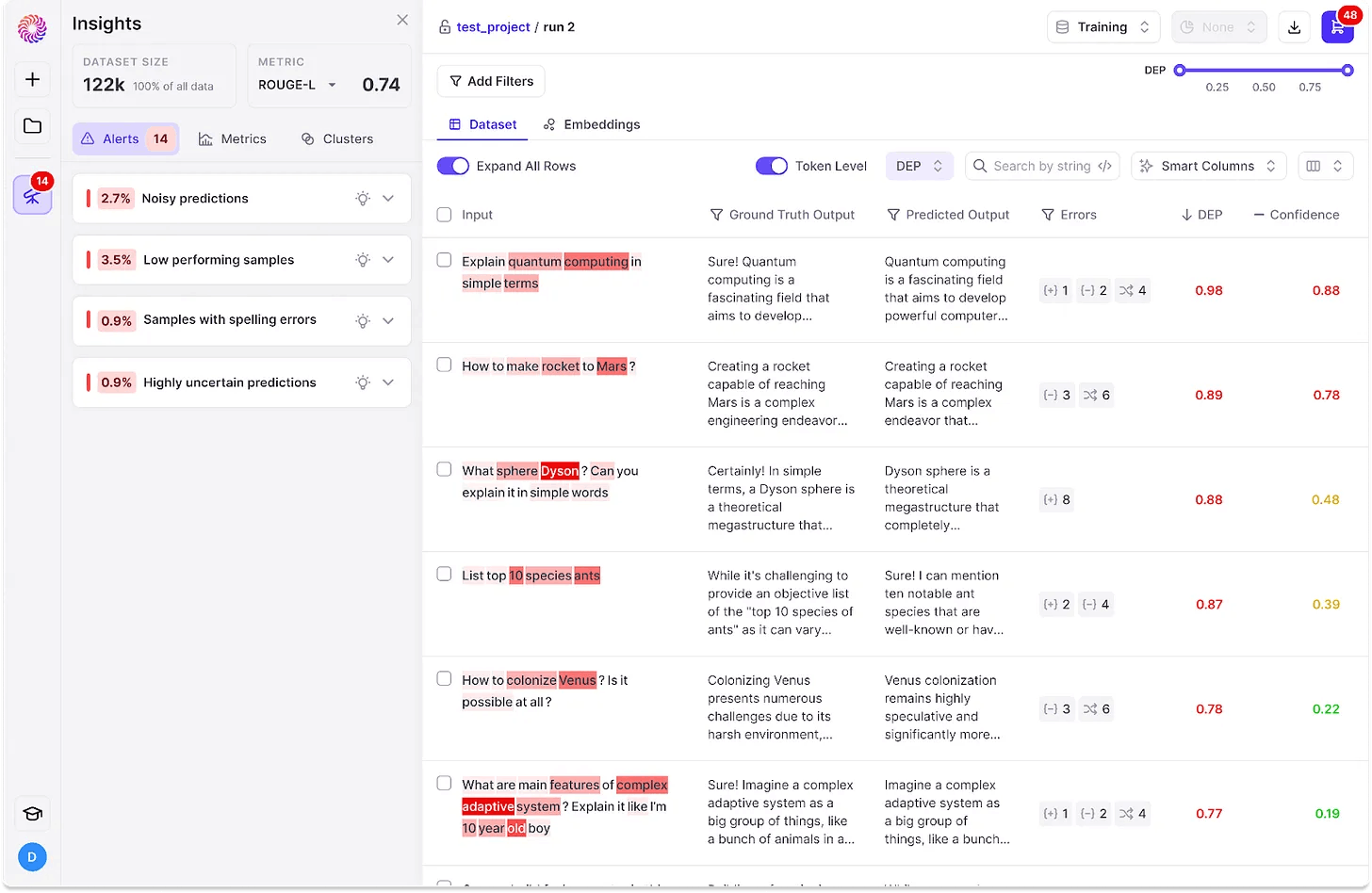
Key Features and Functionalities
- Scalability and Performance: Galileo LLM Studio is a platform for building Large Language Model (LLM) applications.
- Model Evaluation Metrics: Evaluate, part of LLM Studio, offers out-of-the-box evaluation metrics to measure LLM performance and curb unwanted behavior or hallucinations.
- Built-in Metrics to Assess Sample Quality: LLM Studio’s Evaluate module includes metrics to assess sample quality.
- Interpretability and Explainability: Not explicitly mentioned.
- Experiment Tracking: LLM Studio allows prompt building, version tracking, and result collaboration.
- Usage Metrics: LLM Studio’s Observe module monitors productionized LLMs.
Additional Features
Here are some additional features of Galileo LLM Studio:
- Generative AI Studio: Users build, experiment and test prompts to fine-tune model behavior, to improve the relevance and model efficiency by exploring the capabilities of generative AI
- NLP Studio: Galileo supports natural language processing (NLP) tasks, allowing users to analyze language data, develop models, and work on NLP tasks. This integration provides a unified environment for both generative AI and NLP workloads.
Best for
- Galileo LLM Studio, is a specialized platform tailored for individuals working with Large Language Models (LLMs) because it provides necessary tools specifically designed for LLM development, optimization and validation.
Pricing
The pricing model for Galileo GenAI Studio is based on two predominant models:
- Consumption: This pricing model is usually measured per thousand tokens used. It allows users to pay based on their actual usage of the platform.
- Subscription: In this model, pricing is typically measured per user per month. Users pay a fixed subscription fee to access the platform’s features and services.
TruLens
TruLens enables the comparison of generated outputs to desired outcomes to identify discrepancies. Advanced visualization capabilities provide insights into model behavior, strengths, and weaknesses.
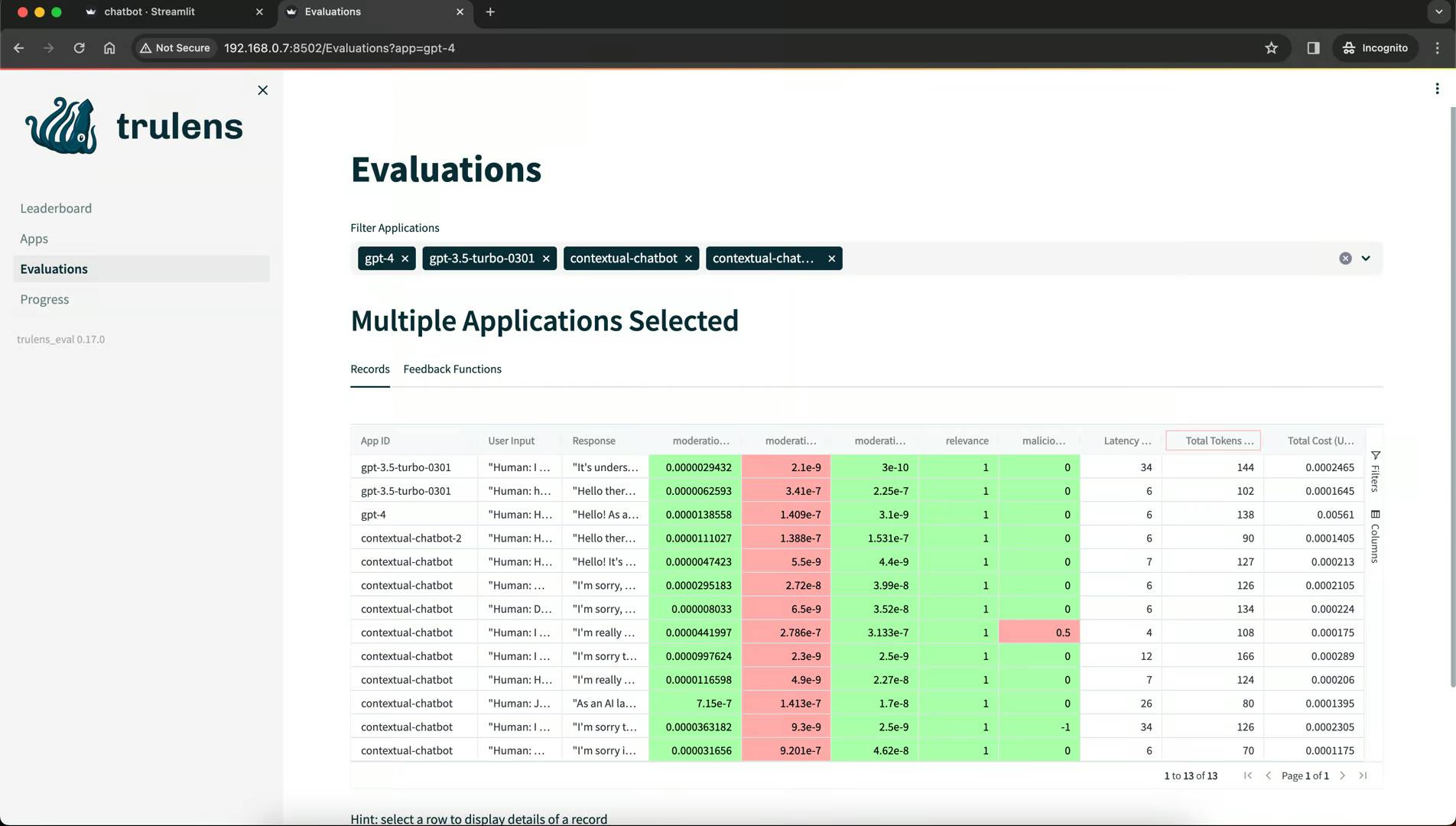
Key Features and Functionalities
- Scalability and Performance: TruLens evaluates large language models (LLMs) and scales up experiment assessment.
- Model Evaluation Metrics: TruLens provides feedback functions to assess LLM app quality, including context relevance, groundedness, and answer relevance.
- Built-in Metrics to Assess Sample Quality: TruLens offers an extensible library of built-in feedback functions for identifying LLM weaknesses.
- Interpretability and Explainability: Not explicitly emphasized
- Experiment Tracking: TruLens allows tracking and comparison of different LLM apps using a metrics leaderboard.
- Usage Metrics: TruLens is versatile for various LLM-based applications, including retrieval augmented generation (RAG), summarization, and co-pilots.
Additional Features
- Customizable Feedback Functions: TruLens allows you to define your custom feedback functions to tailor the evaluation process to your specific LLM application.
- Automated Experiment Iteration: TruLens streamlines the feedback loop by automatically assessing LLM performance, enabling faster iteration and model improvement.
Best for
- TruLens for LLMs is suited for natural language processing (NLP) researchers, and developers who work with large language models (LLMs) and want to rigorously evaluate their LLM-based applications.
Pricing
- TruLens is an open-source model and is thus free and available for download.
Arize
Arize AI is designed for model observability and LLM (Language, Learning, and Modeling) evaluation. It helps monitor and assess machine learning models, track experiments, offer automatic insights, heatmap tracing, cohort analysis, A/B comparisons and ensure model performance and reliability.
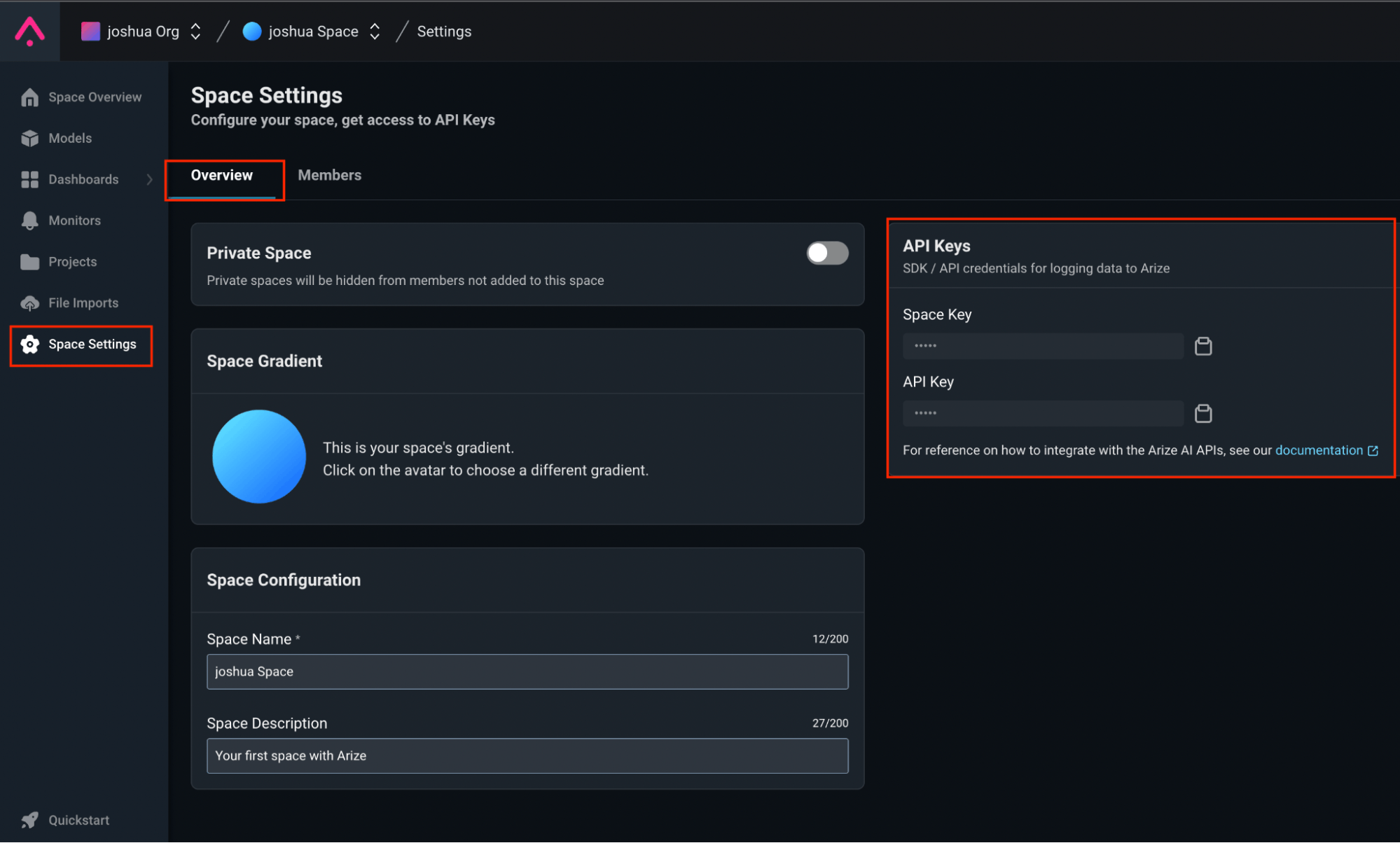
Key Features and Functionalities
- Scalability and Performance: Arize AI handles large-scale deployments and provides real-time monitoring for performance optimization.
- Model Evaluation Metrics: Arize AI offers a comprehensive set of evaluation metrics, including custom-defined ones.
- Sample Quality Assessment: It monitors data drift and concept drift to assess sample quality.
- Interpretability and Explainability: Arize AI supports model interpretability through visualizations.
- Experiment Tracking: Users can track model experiments and compare performance.
- Usage Metrics: Arize AI provides insights into model usage patterns.
Additional Features
- ML Observability: Arize AI surfaces worst-performing slices, monitors embedding drift, and offers dynamic dashboards for model health.
- Task-Based LLM Evaluations: Arize AI evaluates task performance dimensions and troubleshoots LLM traces and spans.
Best for
- Arize AI helps business leaders pinpoint and resolve model issues quickly. Arize AI is for anyone who needs model observability, evaluation, and performance tracking.
Pricing
Arize AI offers three pricing plans:
- Free Plan: Basic features for individuals and small teams.
- Pro Plan: Suitable for small teams, includes more models and enhanced monitoring features.
- Enterprise Plan: Customizable for larger organizations with advanced features, and tailored support.
Weights and Biases
Weights and Biases enables ML professionals to track experiments, visualize performance, and collaborate effectively. Logging metrics, hyperparameters, and training data facilitate comparison and analysis. Using this tool, ML practitioners gain insights, identify improvements, and iterate for better performance.
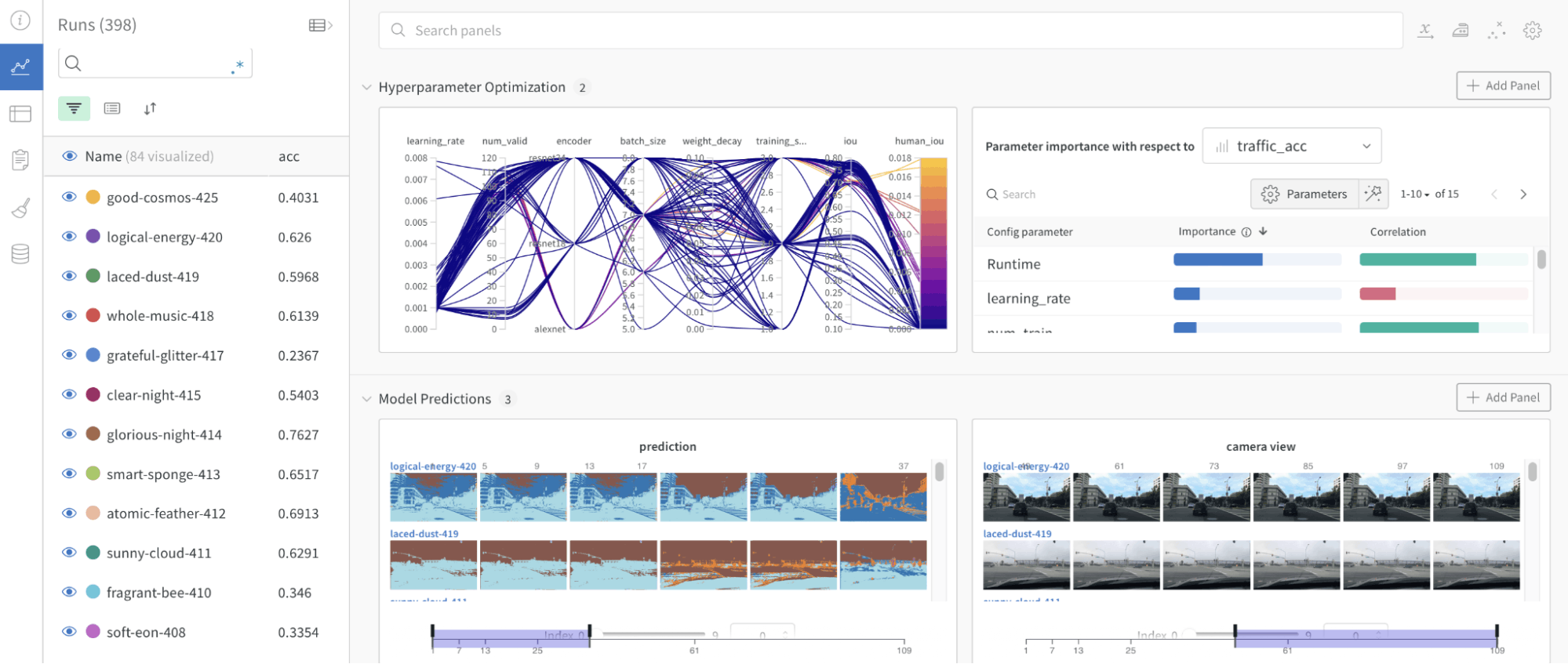
Weights & Biases: The AI Developer Platform
Key Features and Functionalities
- Scalability and Performance: W&B helps AI developers build better models faster by streamlining the entire ML workflow, from tracking experiments to managing datasets and model versions.
- Model Evaluation Metrics: W&B provides a flexible and tokenization-agnostic interface for evaluating auto-regressive language models on various Natural Language Understanding (NLU) tasks, supporting models like GPT-2, T5, Gpt-J, Gpt-Neo, and Flan-T5.
- Built-in Metrics to Assess Sample Quality: While not explicitly mentioned, W&B’s evaluation capabilities likely include metrics to assess sample quality, given its focus on NLU tasks.
- Interpretability and Explainability: W&B does not directly provide interpretability or explainability features, but it integrates with other libraries and tools (such as Fastai) that may offer such capabilities.
- Experiment Tracking: W&B allows experiment tracking, versioning, and visualization with just a few lines of code. It supports various ML frameworks, including PyTorch, TensorFlow, Keras, and Scikit-learn.
- Usage Metrics: W&B monitors CPU and GPU usage in real-time during model training, providing insights into resource utilization.
Additional Features
- Panels: W&B provides visualizations called “panels” to explore logged data and understand relationships between hyperparameters and metrics.
- Custom Charts: W&B enables the creation of custom visualizations for analyzing and interpreting experiment results.
Best for
- Weights & Biases (W&B) is best suited for machine learning practitioners and researchers who need comprehensive experiment tracking, visualization, and resource monitoring for their ML workflows.
Pricing
The Weights & Biases (W&B) AI platform offers the following pricing plans:
- Personal Free: Unlimited experiments, 100 GB storage, and no corporate use allowed.
- Teams: Suitable for teams, includes free tracked hours, additional hours billed separately.
- Enterprise: Custom plans with flexible deployment options, unlimited tracked hours, and dedicated support.
HumanLoop
HumanLoop uses HITL (Human In The Loop), allowing collaboration between human experts and AI systems for accurate and quality outputs. By facilitating iterative validation, models improve with real-time feedback. With expertise from leading AI companies, HumanLoop offers a comprehensive solution for validating generative AI models.
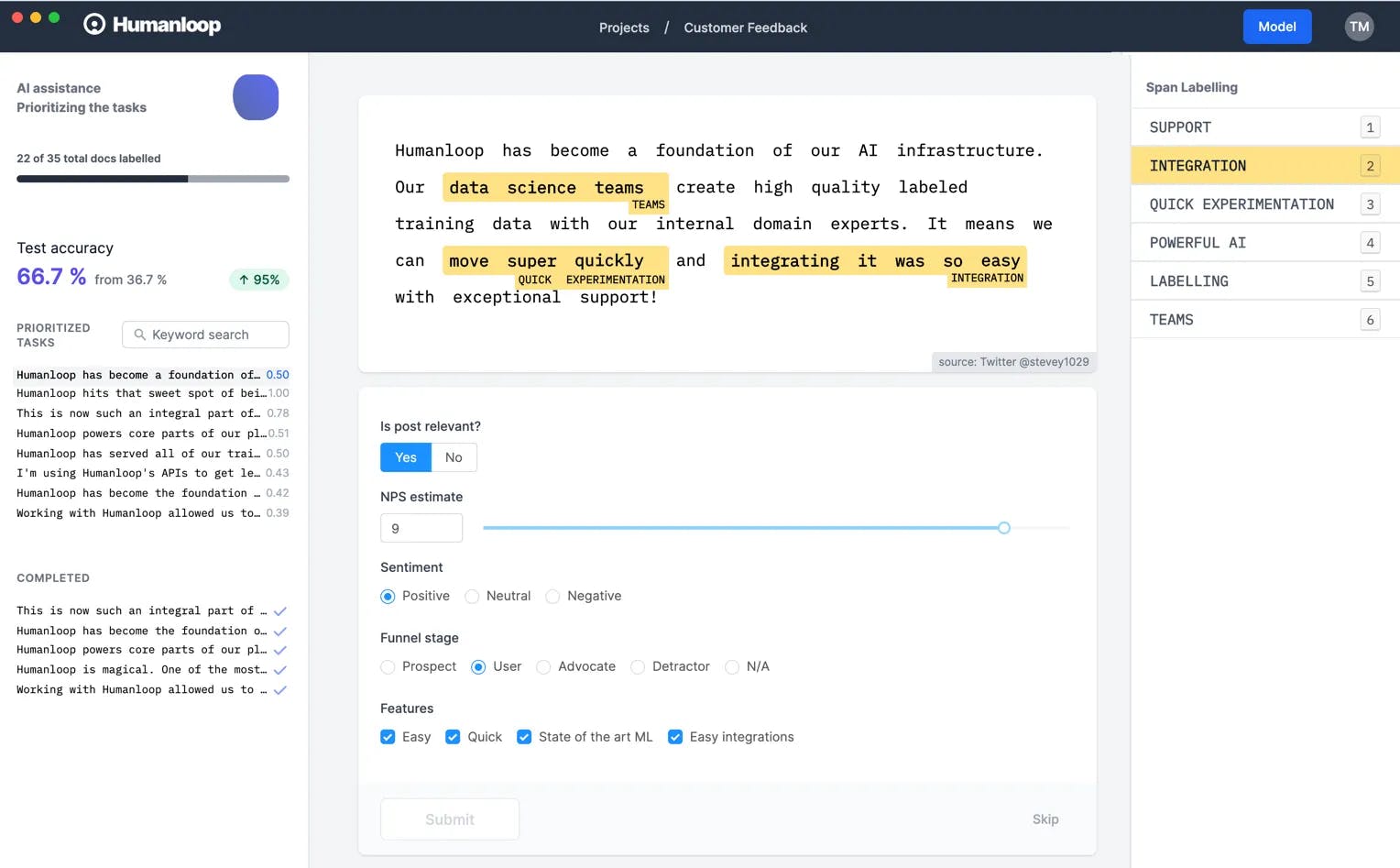
Humanloop: Collaboration and evaluation for LLM applications
Key Features and Functionalities
- Scalability and Performance: Humanloop provides a collaborative playground for managing and iterating on prompts across your organization, ensuring scalability while maintaining performance.
- Model Evaluation Metrics: It offers an evaluation and monitoring suite, allowing you to debug prompts, chains, or agents before deploying them to production.
- Built-in Metrics to Assess Sample Quality: Humanloop enables you to define custom metrics, manage test data, and integrate them into your CI/CD workflows for assessing sample quality.
- Interpretability and Explainability: While Humanloop emphasizes interpretability by allowing you to understand cause and effect, it also ensures explainability by revealing hidden parameters in deep neural networks.
- Experiment Tracking: Humanloop facilitates backtesting changes and confidently updating models, capturing feedback, and running quantitative experiments.
- Usage Metrics: It provides insights into testers’ productivity and application quality, helping you make informed decisions about model selection and parameter tuning.
Additional Features
- Best-in-class Playground: Humanloop helps developers manage and improve prompts across an organization, fostering collaboration and ensuring consistency.
- Data Privacy and Security: Humanloop emphasizes data privacy and security, allowing confident work with private data while complying with regulations.
Best for
- The Humanloop tool is particularly well-suited for organizations and teams that require collaborative AI validation, model evaluation, and experiment tracking, making it an ideal choice for managing and iterating on prompts across different projects.
- Its features cater to both technical and non-technical users, ensuring effective collaboration and informed decision-making in the AI development and evaluation process.
Pricing
- Free Plan allows for Humanloop AI product prototyping for 2 members with 1,000 logs monthly and community support.
- Enterprise Plan includes enterprise-scale deployment features and priority assistance.
Criteria for Evaluating Generative AI Tools
In recent years, generative AI has witnessed significant advancements, with pre-trained models as a cornerstone for many breakthroughs. Evaluating generative AI tools involves comprehensively assessing their quality, robustness, and ethical considerations.
Let’s delve into the key criteria for evaluating the generative AI tools:
- Scalability and Performance: Assess how well the tool handles increased workloads. Can it scale efficiently without compromising performance? Scalability is crucial for widespread adoption.
- Model Evaluation Metrics: Consider relevant metrics such as perplexity, BLEU score, or domain-specific measures. These metrics help quantify the quality of the generated content.
- Support for Different Data Types: Generative AI tools should handle various data types (text, images, videos, etc.). Ensure compatibility with your specific use case.
- Built-in Metrics to Assess Sample Quality: Tools with built-in quality assessment metrics are valuable. These metrics help measure the relevance, coherence, and fluency of the generated content.
- Interpretability and Explainability: Understand how the model makes decisions. Transparent models are easier to trust and debug.
- Experiment Tracking: Effective experiment tracking allows you to manage and compare different model versions. It's essential for iterative improvements.
- Usage Metrics: Understand how real users interact with the model over time. Usage metrics provide insights into adoption, engagement, and user satisfaction.
Remember that generative AI is unique, and traditional evaluation methods may need adaptation. By focusing on these criteria, organizations can fine-tune their generative AI projects and drive successful results both now and in the future.
Generative AI Model Validation Tools: Key Takeaways
- Model validation tools ensure reliable and accurate AI-generated outputs, enhancing user experience, and fostering trust in AI technology.
- Adaptation of these tools to evolving technologies is needed to provide real-time feedback, prioritizing - transparency, accountability, and fairness to address bias and ethical implications in AI-generated content.
- The choice of a tool should consider scalability, performance, model evaluation metrics, sample quality assessment, interpretability, experiment tracking, and usage metrics.
- Generative AI Validation Importance: The pivotal role of generative AI model validation ensures content integrity, diversity, and reliability, emphasizing its significance in adhering to ethical and legal guidelines.
- Top Tools for Model Validation: Different tools are available catering to diverse needs, helping identify and rectify biases, errors, and discrepancies in AI-generated content, essential for model transparency and reliability.
- Criteria for Tool Evaluation: The key criteria for evaluating generative AI tools are focusing on scalability, model evaluation metrics, sample quality assessment, interpretability, and experiment tracking to guide organizations in choosing effective validation solutions.
- Adaptation for Generative AI: Recognizing the uniqueness of generative AI, the article emphasizes the need for adapting traditional evaluation methods. By adhering to outlined criteria, organizations can fine-tune generative AI projects for sustained success, coherence, and reliability.
Frequently asked questions
AI models are validated through techniques like cross-validation, holdout validation, and the use of appropriate metrics to ensure their performance and generalization to new data.
Tools such as Encord Active, DeepChecks, HoneyHive, Arthur Bench, Galileo LLM Studio, TruLens, Arize, Weights and Biases, and HumanLoop are commonly used for model validation, offering functions for cross-validation, metrics calculation, and other validation-related tasks.
AI models are tested using unit testing, integration testing, and end-to-end testing, ensuring the functionality of individual components and the entire system.
Hyperparameter tuning methods like grid search, Bayesian optimization, and ensemble methods, such as combining multiple models, are commonly used for validating models and improving their performance.
Yes, the model validation process can be automated using tools like AutoML (Auto-sklearn, AutoKeras), CI/CD pipelines (Jenkins, Travis CI), and custom validation frameworks, streamlining the validation and deployment workflow.
Encord provides a structured approach to validate summaries generated from medical records by allowing users to compare these summaries against a comprehensive set of source documents. This ensures that the generated summaries reflect accurate and complete information derived from the original medical notes, enhancing reliability in data interpretation.
Encord provides tools for model evaluation that allow users to identify mislabeled or missing data through robust annotation workflows. By leveraging features like data filtering and sorting, users can quickly assess data quality and improve model performance, ensuring a reliable deployment in production environments.
Encord provides robust validation features that help ensure data quality during the annotation process. Users can set up custom validation rules to handle discrepancies, such as minor variations in annotations, allowing for flexibility while maintaining data integrity.
Encord includes powerful label validation tools that help ensure the accuracy and quality of annotations in machine learning projects. These tools allow teams to review and confirm labels, facilitating a smoother workflow and reducing errors in model training.
Encord includes features that enable validation and fine-tuning of models using custom labeled data. This ensures that models perform accurately in unstructured environments, which is crucial for applications such as search and rescue operations.
Encord provides comprehensive features for data annotation and validation, allowing users to efficiently prepare their datasets for training. This includes tools for cleaning and curating data, ensuring high-quality inputs for model training.
Encord consolidates multiple tools into one platform, enabling seamless curation, annotation, and model evaluation. This integration reduces fragmentation and enhances model quality by providing a more efficient way to manage data at scale.
Encord allows users to bring model predictions back into the annotation workflow, enabling identification of failure modes and areas of poor model performance. This feedback loop helps in refining the dataset and improving model outcomes.
Encord includes robust tools for validating annotated data, ensuring that the training data used for AI models meets high quality standards. This capability is crucial for building effective and reliable AI systems.
Yes, Encord allows users to import model predictions and compare them with ground truth data. This feature is essential for evaluating model performance and ensuring high-quality annotations.