Top 9 Audio Annotation Tools

Head of Forward Deployed Engineering at Encord
In recent years, multimodal AI has revolutionized how machines process and understand the world by integrating diverse data types like text, images, and audio. This approach allows for more nuanced, context-aware interactions, enhancing high-quality AI applications across industries.
From automating audiobook production to improving virtual assistants like Alexa, audio plays a critical role in developing accurate training data. As we explore the top 10 audio annotation tools, we'll see how advanced annotation services are driving innovation in digital collaboration, content creation, and accessibility, shaping the future of AI technologies.
What is Audio Annotation?
Audio annotation is the process of labeling and structuring audio data so it can be used to train and evaluate machine learning models. It typically includes time-aligned transcriptions, speaker tags, and sound event labels. These annotations support applications such as speech recognition, audio search, and multimodal AI systems.
Let’s explore the top 9 audio annotation software in the industry.
Top 9 Audio Annotation Tools
Tools Comparison Guide at a Glance
| Tools | Annotation Type | Manual vs AI-Assisted | Collaboration | Multimodal Support |
| Encord | Transcription, sound event, speaker labels | AI-assisted + manual | Yes | Yes (audio, images, video) |
| Audino | Segment-level manual labels | Manual | Basic | No |
| ELAN | Time-aligned multilayer annotation | Manual | Yes | Yes (audio + video) |
| Rev AI | Transcription, diarization | AI-assisted | Limited | No |
| Anvil | Timeline-based multimodal annotation | Manual | Yes | Yes |
| Labellerr | Automated + manual audio tagging | AI-assisted | Yes | No |
| Prodigy | Automated + manual audio tagging | AI-assisted | Yes | No |
| Prodigy | Model-in-loop active learning | AI-assisted | Limited | Yes (text & audio) |
| Diffgram | Audio + other modalities | AI-assisted + manual | Yes | Yes |
| TapeWrite | Interactive enriched audio | Manual | Yes | No |
Encord
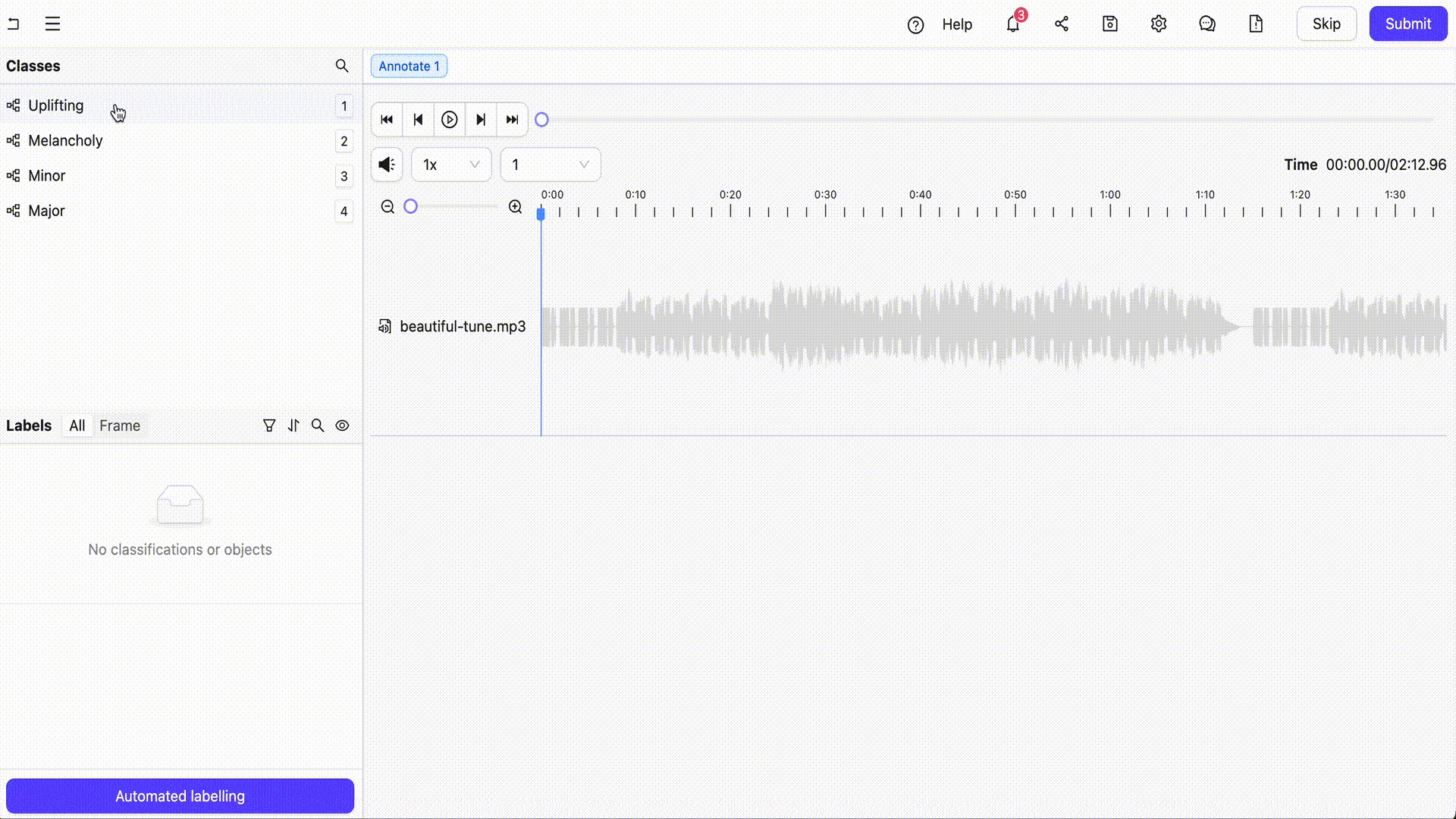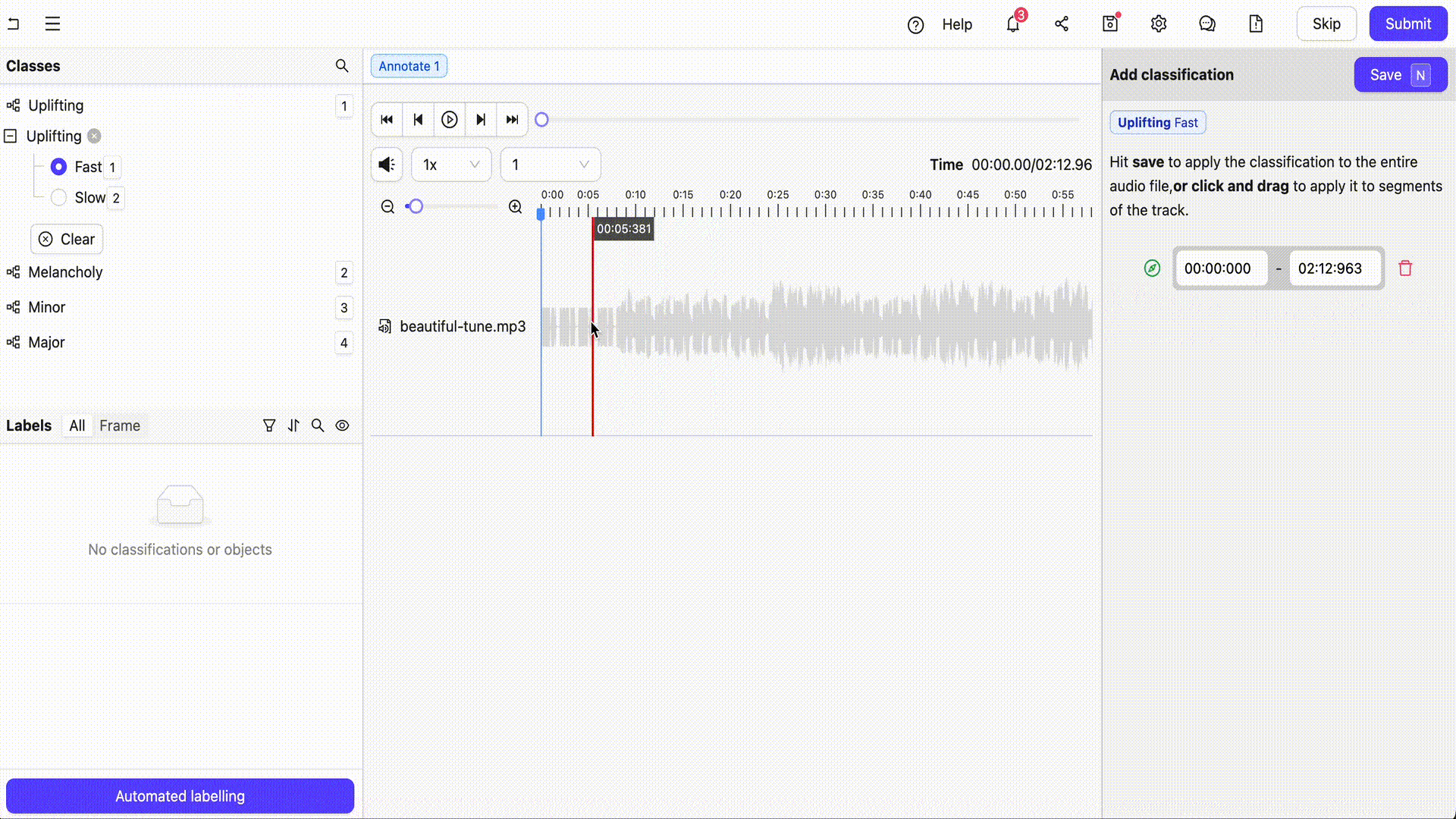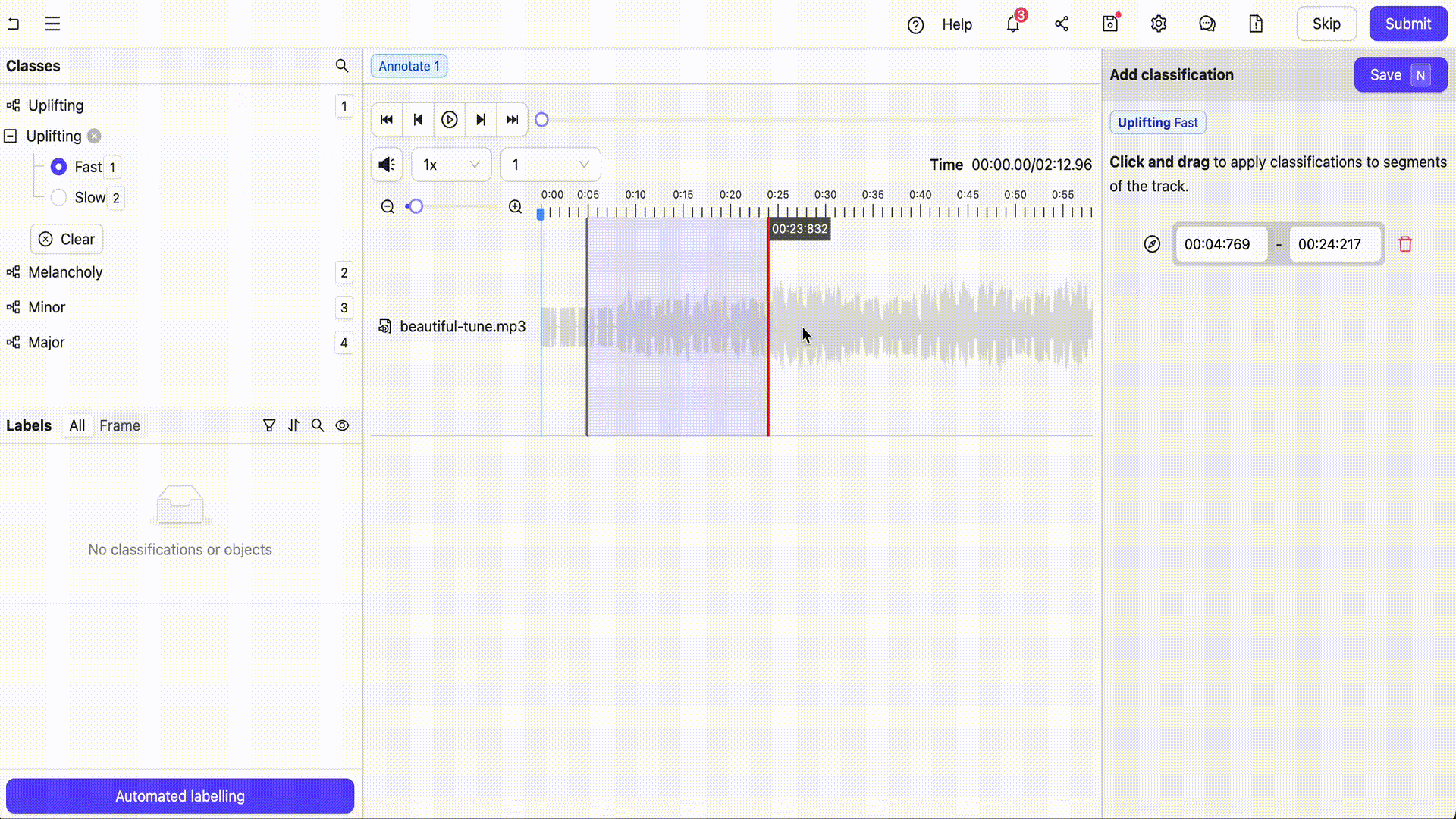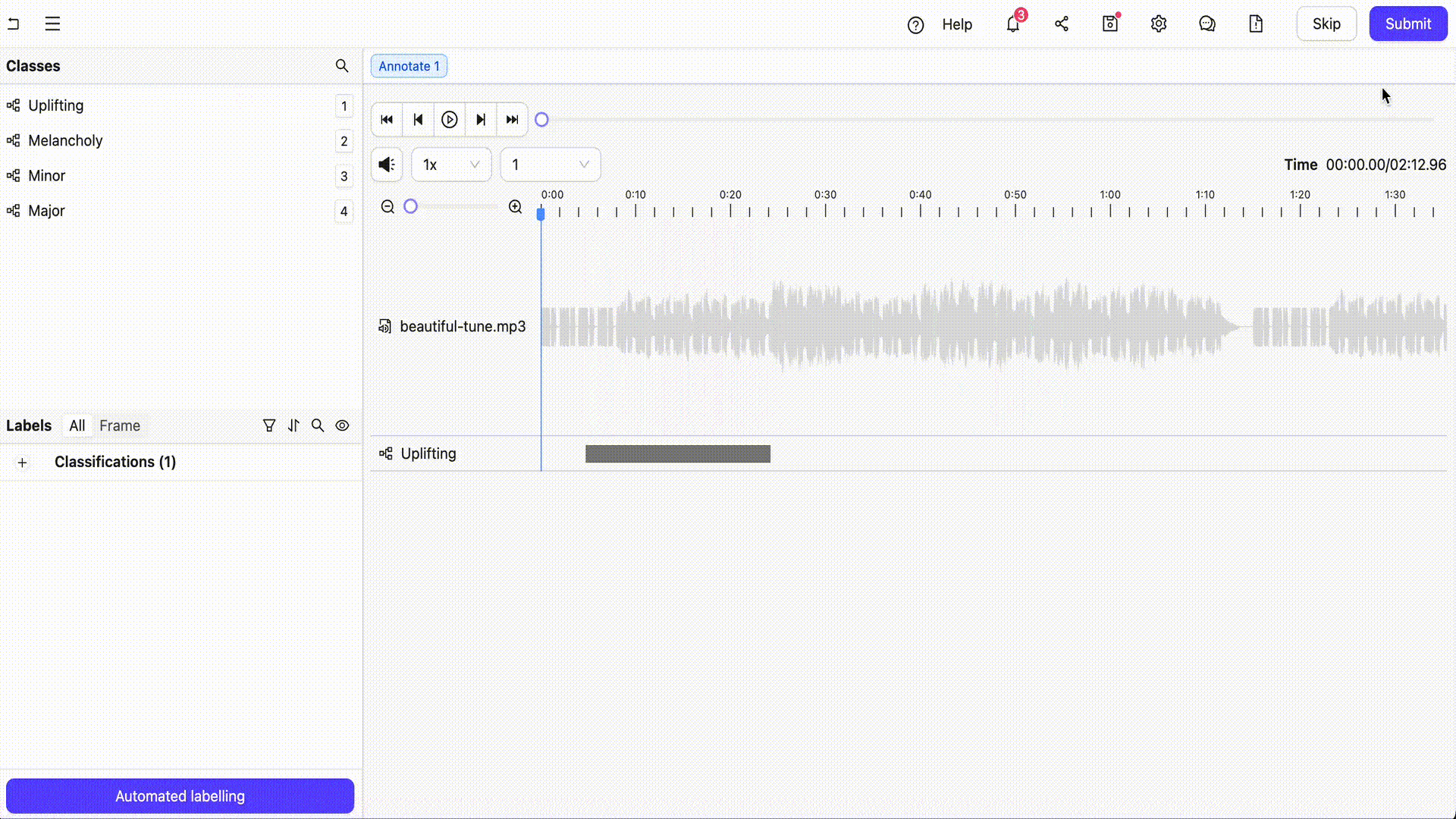
Overview
Encord is a comprehensive multimodal AI data platform that enables the efficient management, curation and annotation of large-scale unstructured datasets including audio files, videos, images, text, documents and more. Encord supports a number of audio annotation use cases such as speech recognition, emotion detection, sound event detection and whole audio file classification. Teams can also undertake multimodal annotation such as analyzing and labeling text and images alongside audio files.
Key Features
- Flexible Classification: Allows for precise classification of multiple attributes within a single audio file down to the millisecond.
- Overlapping Annotations: Supports layered annotations, enabling the labeling of multiple sound events or speakers simultaneously.
- Collaboration Tools: Facilitates team collaboration with features like real-time progress tracking, change logs, and review workflows.
- Efficient Editing: Provides tools for revising annotations based on specific time ranges or classification types.
- AI-Assisted Annotation: Integrates AI-driven tools to assist with pre-labeling and quality control, improving the speed and accuracy of annotations.
Strength
The platform’s support for complex, multilayered annotations, real-time collaboration, and AI-driven annotation automation, along with its ability to handle various file types like WAV and an intuitive UI with precise timestamps, makes Encord a flexible, scalable solution for AI teams of all sizes preparing audio data for AI model development.
Audino
Overview
Audino is an open-source tool that focuses on the manual annotation of audio datasets, offering users the flexibility to label audio at the segment level. Designed for simplicity, Audino is a great choice for smaller teams or projects requiring detailed, manual audio annotations.
Key Features
- Segment-Level Annotation: Allows users to annotate specific segments of an audio file with detailed precision.
- Open-Source: Completely free to use, with customizable features based on project needs.
- User-Friendly Interface: Provides a simple, intuitive interface for manual labeling.
- Multilingual Support: Enables annotation of speech data in multiple languages.
Strength
The combination of a straightforward interface and segment-level precision makes Audino an excellent choice for research-focused projects or teams with a smaller scope that require detailed control over audio annotations.
ELAN (EDICO LINGUISTIC ANNOTATOR)

Overview
ELAN is a free tool developed by the Max Planck Institute for Psycholinguistics, designed for linguistic research and multimodal annotation. It enables the annotation of both audio and video files and is often used for analyzing speech, gestures, and other forms of communication.
Key Features
- Multilayered Annotation: Supports multiple layers of annotations within audio and video files.
- Time-Linked Annotations: Allows users to annotate specific time points and durations with precision.
- Open-Source: Free and highly customizable for research purposes.
- Multimodal Data Support: Handles both audio and video, ideal for linguistic and psychological research.
Strength
The ability to handle complex, multilayered annotations in both audio and video files makes ELAN a robust tool for academic research, particularly in the fields of linguistics and communication.
Rev AI

Overview
Rev AI is a leading speech-to-text API that provides real-time transcription and audio processing functionalities. It is commonly used for automating transcription tasks and analyzing voice data for a range of industries, from media to customer service.
Key Features
- Real-Time Transcription: Provides fast, accurate transcription of audio data into text.
- Multilingual Support: Supports transcription in multiple languages, enhancing its global usability.
- Speaker Diarization: Identifies and labels different speakers within an audio file.
- Custom Vocabulary: Allows users to upload specific vocabularies to improve transcription accuracy for industry-specific terms.
Strength
Its ability to handle complex audio tasks like speaker diarization make Rev AI a go-to solution for companies needing reliable, scalable transcription services.
Anvil

Overview
Anvil is an open-source tool designed for multimodal annotation, enabling the labeling of both audio and video data. Its flexibility makes it particularly useful for projects that involve analyzing communication through both speech and visual cues.
Key Features
- Timeline-Based Annotation: Users can annotate multiple layers of audio and video data simultaneously.
- Multimodal Support: Combines audio annotations with gestures, facial expressions, and other visual elements.
- Customizable: Users can create their own coding schemes for specific research needs.
- Open-Source: Free to use and ideal for academic research.
Strength
Anvil is widely used in psychology and linguistics for analyzing multimodal communication, such as synchronizing speech with gestures or body language.
Labellerr

Overview
Labellerr is an AI-driven platform designed for collaborative audio annotation. Its automation features make it ideal for teams handling large volumes of data, particularly in industries that require high accuracy and speed.
Key Features
- AI-Driven Automation: Automates part of the annotation process to increase speed and reduce manual labor.
- Quality Control: Built-in tools to ensure high accuracy in annotations.
- Collaboration Tools: Supports team collaboration on large-scale annotation projects.
- Scalability: Easily handles large datasets, making it ideal for enterprises.
Strength
Labellerr’s AI-driven automation and scalability make it a strong choice for enterprises that require fast and accurate labeling of large datasets, reducing manual effort and improving efficiency.
TapeWrite
Overview
TapeWrite is a platform for creating interactive audio content, enabling users to enhance audio files with embedded links, images, and multimedia elements. It’s an innovative tool designed for content creators, educators, and podcasters.
Key Features
- Interactive Audio: Embeds links, images, and multimedia content directly into audio files.
- User-Friendly Interface: Simple, intuitive interface designed for ease of use.
- Multimedia Integration: Combines audio with visual content to create an enriched listening experience.
- Cloud-Based: Fully cloud-based, allowing for easy sharing and collaboration.
Strength
TapeWrite is ideal for content creators, educators, and podcasters looking to add interactive elements to their audio files to engage their audience. TapeWrite’s ability to turn audio files into interactive content makes it a unique tool in the market, offering a creative solution for enhancing learning and entertainment experiences.
Prodigy

Overview
Prodigy is an annotation tool that focuses on active learning, allowing users to annotate data while training machine learning algorithms. It is primarily used for NLP tasks but also supports audio annotation, making it versatile for machine learning projects.
Key Features
- Customizable Workflows: Allows users to tailor workflows to their specific needs.
- Cross-Modal Support: Handles both text and audio annotations.
- Efficient Model Training: Reduces the need for large datasets by focusing on the most uncertain or informative data points.
Strength
Prodigy is used by developers working on NLP and speech recognition projects, where real-time model training during the annotation process is beneficial for improving accuracy and efficiency.
Diffgram

Overview
Diffgram is an open-source data labeling tool designed for large-scale machine learning projects. It supports the annotation of audio, video, and image datasets, with features that integrate directly into machine learning pipelines.
Key Features
- Open-Source: Fully open-source and customizable for specific project needs.
- Real-Time Collaboration: Supports team collaboration with real-time progress tracking.
- Version Control: Built-in version control for managing large datasets.
- Automation Integration: Allows for the integration of automation tools to speed up the annotation process.
Strength
Its open-source nature and strong integration with machine learning workflows make Diffgram an excellent choice for teams needing a customizable, scalable solution for annotating audio and other data types.
Why Audio Annotation Tools Are Essential
Audio annotation tools are vital for a broad range of tasks, from training machine learning models for speech recognition to improving virtual assistants' accuracy. As voice-driven technologies like Amazon Alexa, Google Assistant, and voice search apps grow, the demand for accurately labeled audio recordings has surged. Well-annotated audio is essential for:
- Speech Recognition: Training models to accurately understand and transcribe human speech.
- Natural Language Processing (NLP): Enabling machines to process and interpret human languages.
- Emotion and Sentiment Analysis: Identifying emotions in speech for applications like customer service and marketing.
- Audio Classification: Categorizing sounds or speech patterns for various use cases.
- Language Identification: Detecting and labeling different languages or dialects in audio datasets.
- Accessibility: Enhancing automated transcription and captioning for improved accessibility.
The right audio annotation tool is critical for efficiently handling annotation tasks like audio transcription and classification. Choosing the best tool depends on your project’s scale, complexity, and specific requirements.
Key Evaluation Criteria for Audio Annotation Tools
When selecting an audio annotation tool, consider these factors:
- Accuracy and Precision: Ensure the tool delivers high accuracy in detecting and labeling audio events or speech.
- User Interface: A user-friendly interface improves workflow efficiency.
- Scalability: The tool should scale with the size of your dataset.
- Integration Capabilities: Choose a tool that integrates seamlessly with your existing software stack.
- Cost and Pricing Models: Consider both upfront costs and long-term subscription models.
- Collaboration Features: For large teams, the ability to collaborate in real-time may be necessary.
- Automation and AI Features: Automation can save time by automatically annotating simpler tasks, while AI models assist in more complex tasks like emotion detection or speaker diarization.
Key Takeaways: Top 9 Audio Annotation Tools
Choosing the right audio annotation tool is essential for ensuring accurate and efficient labeling of audio data. Each tool offers unique features tailored to different needs. Encord excels in AI-assisted annotations and collaboration, making it perfect for teams working with complex audio datasets. Audino and Anvil provide valuable solutions for detailed, manual annotations, particularly in research and academia. Labellerr and Prodigy offer AI-driven automation for faster, large-scale projects, while TapeWrite enhances audio content with interactive features. Diffgram and SuperAnnotate stand out for their scalability and multimodal support, making them ideal for enterprise-level projects.
Selecting the best tool comes down to balancing your project’s scale, the complexity of the audio data, and your team’s workflow. As the demand for voice-driven applications and services grows, these tools will continue to play a critical role in shaping the future of AI and machine learning, providing the foundation for smarter, more intuitive technologies.
Frequently Asked Questions
What should I look for in an audio annotation tool?
Look for support for time-aligned labeling, transcription, and sound event tagging, along with review and QA workflows to maintain consistency. Teams should also check collaboration features, export formats, and whether the tool supports model-assisted labeling to speed up large audio datasets.
What features does Encord offer for audio annotation projects?
Encord supports audio annotation with time-based labeling, transcription, and sound event tagging workflows across common audio formats. Teams can run collaborative projects with built-in review and QA stages, model-assisted labeling, and dataset quality controls. The platform also supports multimodal workflows, so audio can be annotated alongside image, video, and text data when needed.
Explore More Audio annotation Resources:
Product Demo:
Learning Guides:
- Guide to Audio Annotation
- How to scale audio annotation
- Introduction to audio annotation
- Audio file classifications
- Guide to speaker recognition
Technical Documentation:
Industry & Use Case:
Frequently asked questions
Encord provides advanced annotation tools that streamline the process of labeling audio data, making it easier for teams to prepare datasets for training machine learning models. Our platform supports various audio tasks, including speaker identification and audio segmentation, which can significantly enhance the efficiency of your workflows.
Encord provides a robust platform for audio annotation, designed to enhance the efficiency and accuracy of labeling audio data. Key features include the ability to handle diverse audio formats, support for collaborative annotation, and tools for quality control, ensuring that annotations meet the specific needs of your project.
Encord provides scalable solutions for large-scale audio annotation projects, enabling teams to efficiently manage and annotate extensive datasets. The platform's collaborative features streamline workflows, allowing multiple annotators to work simultaneously while maintaining high standards of quality and consistency.
Encord provides a high-quality annotation platform specifically designed to handle audio and text data, making it particularly beneficial for medical applications. Our features allow for precise speech-to-text transcription and structured documentation, ensuring that medical data is accurately captured and organized.
Encord provides robust tools for curating audio data at scale, allowing users to effectively sanitize their audio datasets. This involves preprocessing steps such as annotation and fine-tuning to enhance model performance, particularly in addressing issues like background noise and overlapping speech.
Encord offers a comprehensive annotation solution that involves human input for tasks such as audio transcription. This is particularly useful in specialized fields like medical transcription, where high accuracy and specific domain knowledge are essential for effective model training.
Encord is built to support teams working with audio data in various languages. The platform can handle random segments of files across different languages, making it easier for users to manage multilingual audio labeling projects without compromising on quality or efficiency.
Encord offers a straightforward interface for audio glitch labeling, allowing users to tag specific audio regions like sibilance, clipping artifacts, and background noise. Users can also adjust playback speed and utilize hotkeys for efficient labeling.
Encord supports integration with data storage solutions such as S3, allowing users to easily upload audio files for annotation. This integration streamlines the workflow by enabling seamless data management and access during the annotation process.
Encord is designed to integrate seamlessly with existing tools and platforms, such as seabed and weight and bias, allowing teams to enhance their data annotation and model training processes without disrupting their current workflows.