
Customer Stories
Trusted by 300+ leading AI teams
 4.8/5
4.8/5

All customer stories

How Thoro Cut Model Deployment to One Week and Increased Labeling Speed by 50% with Encord
Introducing Customer: Thoro Thoro is building an indoor autonomy stack for a broad range of mobile robots, with a primary focus on material handling in logistics and manufacturing environments, as well as industrial floor cleaning. For material handling, the company’s core vision is simple but ambitious: enable robots to move any pallet, anywhere. Safety sits at the heart of everything Thoro builds, with the ongoing goal of achieving independent safety certification for all its robots, allowing them to operate reliably around both trained and untrained people. Problem: A Demanding Deployment Environment and a Fragile Data Pipeline Thoro’s most challenging deployment environments are large U.S. warehouses, up to 800,000 square feet, with no permanent racking. The only fixed landmarks are I-beams spaced roughly 30 feet apart, while the internal layout of pallets changes frequently. This makes reliable navigation exceptionally difficult: robots must distinguish real aisles from temporary pallet storage areas with virtually no persistent spatial reference points. Compounding this challenge was the team’s data and annotation infrastructure. Before Encord, Thoro managed all annotations manually using an open-source tool hosted on a local server. This setup created three major friction points: First, because it was locally hosted, remote team members could not label data outside the office. Second, dataset visibility was limited—the team could only see whether data was labeled, with no way to track progress or inspect pipeline flow. Third, there was no automation: no auto-labeling, no automated data ingestion, and no mature pipeline to move data from robot to model. Everything had to be manually uploaded and downloaded. As Chris Dunkers from Thoro put it: "We could only see if data was labeled or not labeled. Tracking its progress through a project wasn’t really easy. And labeling from anywhere… that was one of the big things that drove us to look elsewhere." Solution: A Cloud-Native Pipeline from Robot to Model Thoro partnered with Encord to replace its fragmented, locally hosted setup with a fully cloud-based, automated data pipeline. Data now flows from the robot into AWS, into Encord for labeling and quality review, and back out through Python training scripts before the updated model is deployed onto the robot. The team primarily works with stereo image data (color images paired with aligned depth images), focusing on keypoint labeling and tracking for pallets across image sets. Encord’s project and ontology tools provide a live view of data flow at every stage. One particularly valuable capability is the ability to add new ontology items and immediately reopen existing datasets to label only the new element, with full visibility into relabeling progress. For model evaluation and experiment tracking, the team uses Weights & Biases alongside their Encord workflow. Implementation: Operational Within a Week Thoro’s onboarding experience was smooth from the start. The team ran a one-week trial and was fully operational by the end. Connecting to their existing AWS infrastructure worked on the first attempt, and Encord’s support team provided fast, high-quality responses throughout. "The support has been phenomenal. Questions answered in about 20 minutes. And integrating with AWS just worked the first time I tried it." Results: 50% Faster Labeling, One-Week Deployment Cycles, and New Customers Unlocked Since adopting Encord, Thoro has significantly increased the speed at which it can respond to real-world model failures, a critical capability in live warehouse environments. The team estimates they are at least 50% faster compared to earlier stages of the project, with each team member labeling or quality-controlling roughly twice as many images as before. The primary driver of this improvement has been the integrated auto-labeler, which performs a highly effective first pass on incoming data. Model deployment timelines have shrunk to approximately one week: collect data on Monday, deploy an updated model by Friday. The team targets around 3,000 new images added within that window, a pace they are already achieving. Beyond throughput, Encord’s pipeline visibility gave Thoro the operational insight needed to identify bottlenecks and optimize workflows. When one team member was labeling significantly faster than others, project insights helped surface and scale that workflow across the team. The speed advantage has also unlocked new commercial opportunities. When Thoro deployed robots at a new customer site and encountered plastic-wrapped pallets, an edge case the existing model couldn’t handle, the team collected data, processed it through Encord, and deployed an updated model within three weeks.

Archetype AI Doubles Annotation Speed With Encord
Introducing Customer: Archetype AI Archetype AI is building the first developer platform for Physical AI — powered by Newton, a foundation model trained on real-world sensor data. The platform enables enterprises to build and deploy custom AI applications for the physical world through simple APIs and no-code tools. With deep multimodal sensor fusion, Newton delivers rich, accurate insights across industries — from predictive maintenance to human behavior understanding. They're working with global leaders like Mercedes-Benz, NTT Data, and SLB, and backed by Venrock, Amazon, and Bezos Expeditions. Before Encord Prior to adopting Encord, Archetype AI managed data curation and annotation through a combination of internally developed tools and third-party platforms. A key limitation was the lack of native video support within their primary annotation tool. Without the ability to annotate directly on video, annotators were forced to label frame by frame — an inefficient and labor-intensive process that significantly hindered throughput. Object tracking capabilities were similarly constrained, leading to inconsistent performance and difficulty in maintaining continuity across frames. As the scale and complexity of the data increased, maintaining label accuracy was difficult due to limited visibility in the annotation interface, and the overall user experience lacked the flexibility required for managing high-volume video datasets. These inefficiencies created friction throughout the pipeline, delaying project timelines and impacting the quality of data used for model development. Recognizing the need for a more robust and purpose-built solution, the team began evaluating platforms capable of supporting scalable, high-performance video and multimodal annotation workflows. The Encord Solution Since adopting Encord, the team has achieved a 70% increase in overall productivity. Most significantly, annotation speed has doubled, allowing the team to work far more efficiently than with previous tooling. This improvement is driven by Encord’s fast and intuitive annotation tools, powerful features like trackers and bulk operations, and most importantly, the flexibility of Encord's SDK, which enabled the team to build custom ETL pipelines for seamless data ingestion and annotation retrieval. Tasks that previously required manual upload/download steps and browser-heavy interactions are now fully streamlined. Together, these capabilities have drastically streamlined Archetype AI’s end-to-end labeling workflow. Encord’s intuitive interface has streamlined project setup and management. It’s now easier for them to design workflows, assign and review tasks, and maintain full visibility across active projects. Labeling accuracy has also improved, leading to tangible gains in model performance, highlighting the impact of having the right data labeled correctly from the start. The platform made it easy for the team to experiment with new annotation methodologies and iterate quickly, without being constrained by tooling limitations. This flexibility introduced a new level of agility, enabling the team to adapt and innovate faster across their data pipeline. Collectively, these benefits have resulted in substantial time savings, improved model outcomes, and a more scalable and adaptable approach to handling complex multimodal data.

Standard AI Powers Video Processing 5x Faster
Introducing Customer: Standard AI Retailers today face some of the toughest challenges in physical stores — from tracking shopper behavior to optimizing promotions and in-store media. Standard AI solves these challenges by equipping retailers and CPG brands with AI-powered computer vision technology that unlocks real-time insights on promotions, media impact, new product launches, and more. The VISION platform turns data into actionable insights, helping retailers drive sales, improve store performance, and gain deeper visibility into the shopper journey. Standard AI is equipping brick-and-mortar stores and their suppliers with real-time in-store analytics, all while maintaining a privacy-first approach. Helmed by an executive team that spans firms like Mars, Sara Lee, Oracle, NASA, and Adobe, Standard AI is at the forefront of applying artificial intelligence and computer vision to physical retail spaces. The data challenge: lower quality, longer time to value At its core, Standard AI’s business is based on its ability to extract meaningful insights from millions of hours of video footage from store’s security cameras. For the ML team, access to high-quality and enriched video data was an extremely cumbersome, time-consuming process that relied on multiple internal and agency hand-off points, lengthy quality control review cycles, and fragmented point solutions. In several instances, custom scripts were needed to glue these workflows together. The ML team spent more time managing fragile data pipelines than focusing on model performance. The product and ML teams also wanted to find a way to streamline the data curation and annotation processes and spend more time evaluating and fine-tuning their models to continue improving performance. This wasn’t possible due to limitations of Standard AI’s existing tooling, which offered limited debugging, quality control, and statistical insights. From a business perspective, Standard AI understood that the way of managing their AI data pipeline wouldn’t scale or support the rapid innovation needed to meet customer demands. Standard AI’s Product and ML team defined strict requirements for their updated approach: Native support for large-scale video processing (including fish eye lens) with support for other modalities A unified platform for curation, labeling, and evaluation Robust API and SDK support Ability to automate labeling tasks with HITL A simplified user experience for non-technical users The solution: easy access to pixel-perfect video data to build production-grade AI Native video processing — With prior approaches, the Standard AI team spent long cycles manually uploading videos to other platforms and faced significant conversion issues. With Encord’s native video support and API, the Standard AI team is now able to upload and process millions of video files 5x faster. Unified data management platform for AI — Standard AI shifted from relying on outsourced labelers, open-source tooling, and niche labeling platforms to Encord, a unified platform that streamlines data curation and annotation at enterprise scale. Robust API and SDK support — The API integration for data upload is intuitive, enabling rapid implementation. and programmatic data annotation at speed with the Encord SDK. Granular ontologies — Standard AI was able to rapidly refine complex hierarchical ontologies in response to evolving project insights, continuously enhancing data labeling precision. AI-assisted labeling with HITL — Standard AI benefited from automated labeling functions paired with human-in-the-loop reviews to ensure label accuracy whilst speeding up labeling pipelines. Seamlessly scalable across the organization — The ML team has democratized access, enabling all team members to add, annotate, and utilize enriched data for their specific tasks. This distributed approach accelerates company-wide progress by eliminating bottlenecks previously created by specialized tooling gatekeepers. Benefits: Standard AI built production-ready models faster and at lower cost Since moving to Encord, Standard AI has seen a drastic improvement in productivity across its product and ML teams, significant cost savings, improved data quality, and faster time-to-model improvement. Key benefits: Saved $600k a year Process millions of video files 5x faster with Encord’s native video platform 99.4% faster project initiation

Pickle Robot Sped Up Model Iteration Cycles by 60%
Introducing: Pickle Robot Pickle Robot, a Cambridge, MA-based Physical AI innovator, is revolutionizing the logistics industry with cutting-edge applications of hardware, AI, and data. Focused first on optimizing truck unloading and loading, Pickle Robot streamlines one of the most physically demanding tasks in warehousing. Historically, the process of unloading non-palletized goods from trailers relied heavily on manual labor, resulting in fatigue and inefficiencies and prone to high worker safety risks. To address these challenges, a team of MIT graduates came together to form Pickle Robot. They developed a sophisticated solution that uses advanced AI algorithms trained on highly accurate images and videos to automate the unloading of up to 1,500 packages per hour with its green mobile manipulation robots. The purpose-built solution combines custom AI/ML, highly contextualized data, and off-the-shelf hardware and sensors, significantly reducing the time, effort, and risk in an often overlooked part of the supply chain that warehouses spend over $100 Billion a year to do. Today, they are helping their customers like UPS, Ryobi Tools, and Randa Apparel & Accessories unload millions of pounds of packages monthly. The data challenge To build fast and precise robotic systems, Pickle Robot needed to think about the end-to-end experience while facing hurdles across hardware and AI models. Specifically on the model front, Pickle Robot recognized the need for a robust AI system capable of handling diverse cargo. This led the team to implement a unique combination of sensors and machine learning models to identify different types of packages and manipulate various goods accurately. The integration of these technologies enhanced operational efficiency and minimized errors and downtime. Achieving success required a robust data engine and rich images with precise annotations. Prior to Encord, Pickle Robot used data annotation services from other providers. It relied on an outsourced labeling team to conduct the labeling within the software's limitations and the skills of the outsourced labelers. Challenges included: Poor labels—overlapping polygons, or, more often than not, a significant number of packages were submitted with incomplete labels. Excessive auditing cycles—the legacy approach was error-prone. The lean team of AI and ML engineers spent up to 20+ minutes on auditing tasks per cycle, with high rejection rates. Complex semantic segmentation ontologies were infeasible, which inhibited the robot's ability to accurately understand its operating environment. Platform unreliability limited the efficacy of automated workflows and reduced the time available for model development. Accuracy in training data is critical when your business depends on the accuracy and efficiency of the robotics system's performance. Utilising Encord for consolidated data curation & annotation To address these challenges, Pickle Robot made a strategic decision to partner with Encord. With Encord, Pickle Robot gained a platform that does data curation, annotation, and provides robust analytics and model evaluation functionality, with full integration to Pickle Robot's Google Cloud Platform based data engine infrastructure. The Encord platform enables data management and discoverability capabilities, granular annotation features (bounding boxes, polylines, key points, bitmasks, and polygons), nested ontologies, collaborative workflows, AI-assisted labeling with HITL, and comprehensive data curation functionality required to run efficient data pipelines. "For our AI initiatives, rapid iteration is critical. Encord and our ML infrastructure allow us to prototype learning tasks efficiently. The composability of Encord enables us to merge diverse data sources, facilitating extensive experimentation. With a well-integrated SDK, it's a matter of a few lines of code to achieve seamless integration and functionality." - Matt Pearce, Applied ML, Pickle Robot Benefits: Pickle Robot increased precision by 15% and iterated models 60% faster Since Pickle Robot partnered with Encord, Pickle Robot has seen a drastic improvement in the AI and ML engineers’ productivity, improved precision in task execution, and faster time-to-model improvement. Key benefits: Achieving reliable data pipelines for model training and evaluation 60% faster 30% improvement in annotation accuracy Faster and more comprehensive audit and review cycles Increased observability of real-time data distributions, allowing for rapid domain drift corrections. 15% Improvement in robotic grasping accuracy with better training data

OnsiteIQ Achieves 5x Faster Data Throughput and Streamlines Their AI Infrastructure
OnsiteIQ, a construction intelligence platform using computer vision for safety and quality inspections, migrated their data workflows to Encord after overhauling their AI infrastructure. This enabled them to become operational 4x faster and achieve 5x data throughput with their existing team. "Encord integrates seamlessly into our entire AI infrastructure," says Evgeny Nuger, Principal Engineer at OnsiteIQ. "By implementing Encord within our redesigned ML infrastructure, we've established an efficient end-to-end workflow from data sampling through to model training." Platform Migration + Key Results OnsiteIQ faced significant limitations with their previous annotation platform, struggling with poor usability and underperforming automation capabilities that hindered their workflow efficiency. After evaluating several vendors, the team chose Encord for its advanced features and intuitive interface, particularly the SAM 2 integration for automated labeling workflows. The results: 5x improvement in data throughput – with corresponding decrease in labeling costs through advanced automation features 75% reduction in time to value – implementation time decreased from 2 months to just 2 weeks Real-time annotation analytics – simplified team management through Encord's monitoring dashboard Superior Automation and Intuitive User Experience The automation capabilities paired with the UX of Encord's platform were decisive factors in OnsiteIQ's selection: Despite offering sophisticated organization with distinct layers for datasets, projects, ontologies, and files, the team found Encord's platform surprisingly intuitive, effectively balancing complexity with usability. Evgeny notes, "The UX on Encord's platform was way more clear as to how everything comes together." Accelerated Time to Value The implementation timeline also improved dramatically. The team saw a 4x acceleration in their time to value, reducing time to value from 2 months to just 2 weeks: Improved Team Management OnsiteIQ now utilizes Encord's built-in analytics to optimize their operations: The fully integrated system has improved operational efficiency for OnsiteIQ. The company is now actively using the data generated through Encord for deploying models into production.


Zeitview Improves Recall by 12% and Doubles Data Throughput Using Encord
Zeitview, a provider of advanced inspection solutions for the energy and infrastructure sectors, significantly improved performance of their rooftop penetration detection model by focusing on high quality data delivery. We spoke with Jonathan Lwowski, Head of AI/ML, and Conor Wallace, Machine Learning Engineer, to understand how leveraging Encord helped improve data quality, tightened their feedback loop, and accelerated the deployment of machine learning models into production. Key results Initial training data for Zeitview's rooftop penetration detection models suffered from quality issues. The first dataset was labeled by 15 external contractors using a third-party tool, resulting in inconsistent annotations and suboptimal model performance. Zeitview improved data quality using the Encord platform: Moved from external contractors to a smaller, specialized 5-person internal labeling team Implemented robust QA workflows for systematic quality control Relabeled problematic data while simultaneously expanding the dataset These changes yielded meaningful results: 3.67% boost in precision 12.33% boost in recall 2x increase in dataset size and throughput Reduced team size by ⅓ The recall improvement is particularly significant for Zeitview's inspection use case, representing a meaningful enhancement in detection reliability. How did Zeitview achieve these results? Encord's platform enabled several workflow improvements: Consolidate labeling and QA operations within a single environment Implemented structured QA/QC workflows that integrated MLEs directly into the feedback loop Leveraged image similarity search to quickly curate high-quality datasets As Jonathan notes, human labeling data can be expensive and time-consuming if not done efficiently: Intelligent data curation For complex projects with no reference data – like rooftop penetrations – Zeitview now leverages image similarity search and image quality metrics to curate high-quality datasets. This approach allows the team to rapidly identify edge cases and ensure diverse training datasets. Automated QA Zeitview moved from spreadsheet-based feedback to a three-round QA workflow built within Encord, integrating ML engineers directly into the review process. As label accuracy improves, they are able to gradually reduce human oversight. Active learning Zeitview is preparing to use Encord Active to close the loop between model predictions and data curation. The goal: trigger automated retraining when failed predictions are detected, ensuring continuous model improvement. Summary Zeitview integrated Encord’s platform to centralize their data operations and automate key parts of the annotation and feedback workflow, enabling greater efficiency and consistency across teams. With Encord, Zeitview has established a foundation for trustworthy, production-ready datasets and continuous model improvement - delivering faster iteration cycles, higher label quality, and more accurate inspection models.

Yutori achieved 2-3x faster task completion with lower inference costs
Key Stats Thousands of weekly trajectory evaluations with 20+ evolving error categories Systematic head-to-head model comparisons across hundreds of trajectory pairs weekly to quantify performance gains Yutori Navigator outperforms Gemini 2.5 and Claude 4.5 by 10-20 percentage points on real-world web tasks Yutori is reimagining how people interact with the web. Founded in 2024 by former Meta AI leaders Devi Parikh, Dhruv Batra and Abhishek Das, the San Francisco startup builds autonomous web agents that reliably execute complex tasks – from booking reservations to researching products and making purchases. In November 2025, Yutori launched Navigator, a web agent that operates a real browser to autonomously complete web tasks. Navigator outperforms Gemini 2.5, Claude 4.0 and 4.5, and OpenAI's Operator by 10-20 percentage points in accuracy while being 2-3x faster. The Challenge: Foundation Models Can't Navigate the Real Web Foundation models struggle with dynamic interfaces, multi-step workflows, ambiguous user intent, and the need to reason about both what to do and how to do it. "Models aren't ready yet to deliver this out of the box," Devi explained. "In sequential decision making problems, errors compound at each step. We need to push on modeling capabilities to complete complex workflows on the web with high reliability. To this end, it is critical for data that models are trained on to be high quality. It's the starting point for where model capabilities will come from." Yutori faced critical data challenges. Supervised fine-tuning requires high quality human-annotated trajectories. Every action an annotator takes on the web while completing a specified task – including any exploration and backtracking – needs to be accurately recorded while keeping the annotation interface simple. Trajectory evaluation can’t be fully automated yet across the entire diversity of tasks. Incorrect actions or subgoals along the way may still lead to successful outcomes. That needs to be appropriately accounted for. While quality is most important, throughput of data annotation also needs to be reasonable to make fast progress. How Encord Built a Scalable Data Pipeline for Yutori We partnered with Yutori to develop data infrastructure spanning the agent development lifecycle. High-Quality Training Data We created a tailored pipeline for supervised fine-tuning: Human-annotated trajectories Iterative quality control with strict standards enforced by both teams Large-Scale Evaluation As Yutori's customer base grew, evaluating agent performance at scale became critical. We worked together to build a comprehensive evaluation framework: Custom error taxonomy: We iteratively developed 20+ error types capturing action prediction, model reasoning and infra errors. Error categories evolved weekly as Yutori identified new model behaviors. We trained our team to adapt quickly while maintaining quality. Massive scale: We conducted thousands of trajectory evaluations per week, evolving from task outcome evaluation to detailed error categorization of both the process and outcome of the agentic trace. Model evaluations: Beyond single trajectory and Online Mind2Web evaluations, we conduct systematic head-to-head comparisons for hundreds of trajectory pairs weekly where different models attempt identical prompts. Our framework has captured signals across multiple performance dimensions - identifying improvement areas and quantifying Navigator's gains over Claude 4.5 and Gemini 2.5. Model-in-the-loop: We balanced human expertise with AI efficiency. Over time, human annotators provided the correct action labels only when models made mistakes. The Result: Yutori Navigator Sets a New Standard The partnership enabled Yutori to launch Navigator as the highest-performing web agent available: 10-20 percentage points higher in accuracy than Gemini 2.5, Claude 4.0 and 4.5, and OpenAI's Operator 2-3x faster task completion with lower inference costs Uniformly preferred by users in head-to-head evaluations Yutori agents completing autonomous tasks (Videos courtesy of Yutori) You can try Yutori’s product Scouts or build on their state-of-the-art web agentic tech via their API. What This Means for Agentic AI As agentic AI expands into web browsing, coding assistants, and customer service, evaluating performance in production becomes critical. Our work with Yutori demonstrates what frontier AI teams need: Flexible data infrastructure that adapts to key experimental needs as model capabilities evolve Custom workflows for each development phase Quality and quantity of training data Human-model collaboration balancing automation with nuanced understanding Structured evaluation frameworks capturing fine-grained signals If you're building agentic AI that needs to work reliably in the real world, your data pipeline quality will determine whether your agents deliver on their promise.
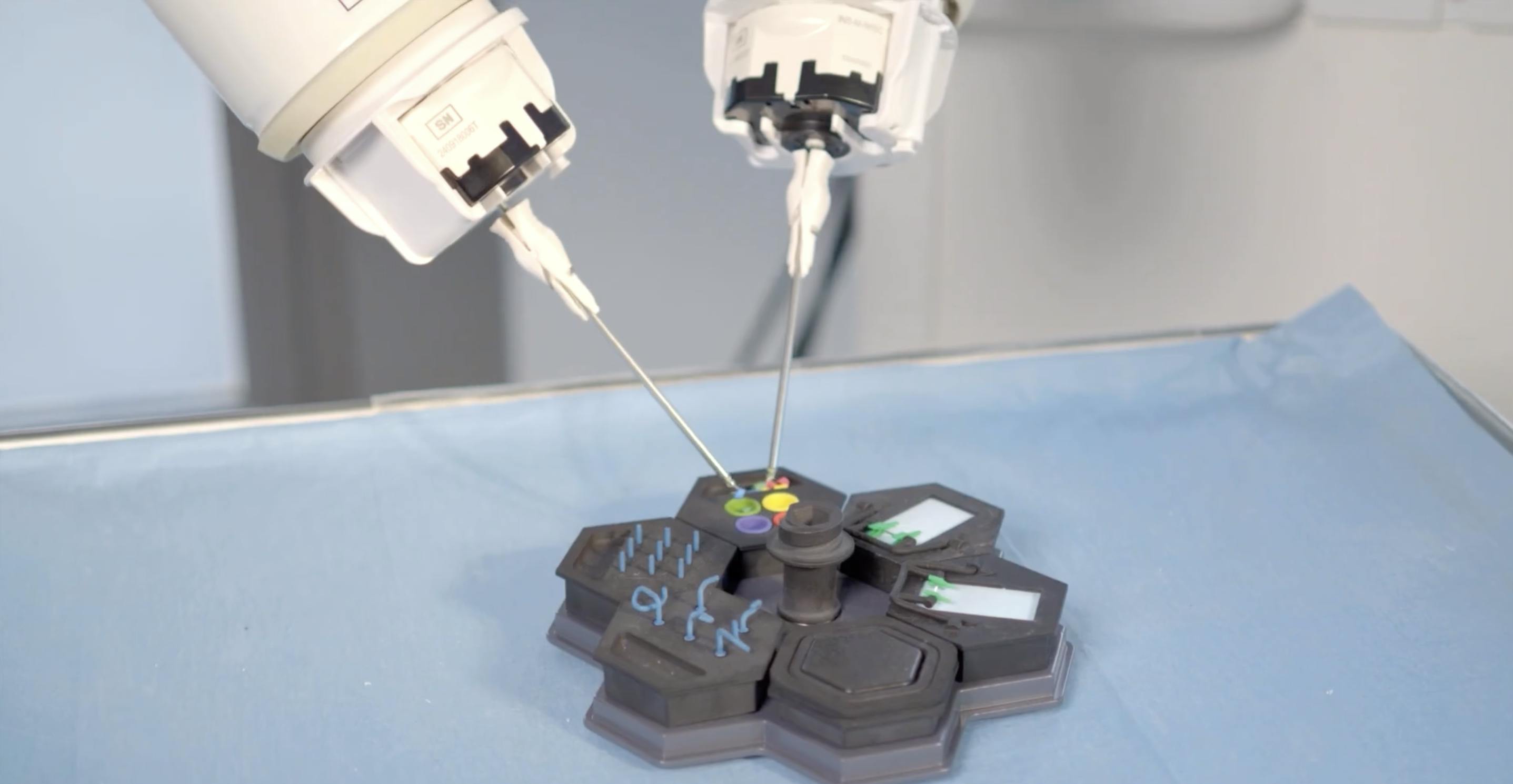

How MMI Accelerates Digital Surgery Innovation with Encord
The Challenge: Scaling Computer Vision for Robotic Microsurgery MMI is building the future of digital and robotic microsurgery. Their work sits at the intersection of robotics, computer vision, and AI, supporting surgeons who operate at an extremely small scale where precision, tremor reduction, and motion control are critical. To power these systems, MMI relies on large volumes of high-quality annotated video data. But microsurgical data presents unique challenges: it comes from multiple sources, requires extreme precision, and must be curated and validated carefully to ensure stable model performance across environments. As their computer vision efforts scaled, manual data handling and annotation became a bottleneck. Engineers needed to focus on model optimisation, testing, and innovation, not spending disproportionate time curating datasets, reviewing annotations, or managing fragmented workflows. MMI needed a solution that could: Scale annotation and review efficiently Support complex video-based computer vision workflows Integrate tightly with their existing AI pipelines Improve dataset consistency and model stability Reduce the time from hypothesis to model validation The Solution: Encord as the Backbone of MMI’s Data & Annotation Workflow MMI adopted Encord as a core part of their computer vision and data operations, using it across annotation, review, data curation, and automation. With Encord, the team gained access to: An external annotation workforce, allowing engineers to prioritise model innovation over manual labeling Workflow automation and model-assisted labeling, accelerating annotation and review cycles Systematic review policies and targeted relabeling, improving dataset consistency and edge-case handling Encord Index, enabling efficient browsing, categorisation, and reuse of large-scale surgical video data SDK integrations, allowing seamless export into MMI’s internal training pipelines Engineers across roles, from senior CV engineers to PhD researchers and interns, use Encord daily to review annotations, visualise edge cases, automate parts of the workflow, and move faster from experimentation to validation. The Results: Faster Iteration, Better Data, More Focus on Innovation By integrating Encord into their AI-driven workflows, MMI significantly improved both operational efficiency and model quality. Annotation and review cycles became faster and more consistent, allowing the team to iterate on multiple model versions more quickly. Improved dataset quality translated directly into more stable model performance across different test environments. Most importantly, Encord freed up valuable engineering time. Instead of manually handling data, MMI’s team can focus on what matters most: advancing the state of the art in digital surgery, developing assistive and autonomous capabilities, and delivering better outcomes for surgeons and patients. As MMI continues to expand its digital surgery platforms, including first-in-human deployments, Encord remains a critical partner in enabling scalable, reliable, and high-quality computer vision development.

Finding a Reliable Ecosystem to Scale Model Development
Introducing Customer: Voxel Voxel is a global leader in workplace safety, empowering worksites by providing them with the data they need to protect workers and gain insight into workplace activities. Their mission is to protect the people who power our world. We spoke with Anurag Kanungo, the co-founder and CTO, about why he decided to transition to Encord to manage their machine learning pipeline and computer vision projects. Problem: Operational Challenges in Data Accessibility and Model Scalability As Voxel grew, they encountered several challenges that hampered their ability to deliver on their mission effectively. The initial approach to data gathering and analysis wasn't sufficient for scale, leading to difficulties in finding relevant data and a lack of dataset diversity. The frequent changes in work environments, such as uniform updates, posed challenges in accurately updating models with new, unseen data. Also, addressing model edge cases and efficiently scaling the data labeling and analysis process became a prominent issue. Initially, Voxel trained pipelines using open-source tooling for object detection in videos. While sufficient on a small scale, as Voxel grew and required more complexity, the limitations of these tools became evident. Among others, they faced challenges with the user interface, backend data management, interpolation issues, and label exports. Despite being a good starting point, these tools proved inadequate for scaling operations effectively. “…as we started growing and adding more customers and more people using the tool there were certainly a bunch of challenges that came in, like our previous OS labeling tool kept running out of disk, so we had to start doing maintenance ourselves. We had to start editing the code and diverging from the main branch, which we really didn’t want to do…because we wanted to focus on our product.” - Anurag Kanungo As Voxel scaled, they sought a more robust solution that had critical features such as video support and image classification. Solution: Transitioning to Encord for Scalable and Efficient Video Analysis The decision to transition to Encord marked a significant turning point for Voxel. Encord's video-first approach addressed their need for robust video support, while its innovative features, such as image group classification, stood out. Moreover, Encord's exceptional support and technical design resonated with Voxel's needs, offering a seamless and efficient solution that aligned perfectly with their vision for enhancing workplace safety. "We went through a bunch of vendors and one of the things that stood out about Encord was the video first support, which other vendors do not have. Specifically understanding how the video works behind the scenes: the encoding, the frame indexes and square pixel ratios."- Anurag Kanungo Results: Impact of Encord on Voxel’s Operations One of the key requirements for Voxel was the ability to integrate their existing data pipelines into a new solution, which Encord was able to provide seamlessly. This enabled their team to continue to focus on their end solution without being preoccupied with the handover. Voxel were impressed by the robustness of the platform, enabling them to utilise many of the advanced features enabling them to address the safety issues and ergonomic concerns more effectively, aligning with their overarching mission to reduce workplace risks and ensure a safer environment for all workers Overall, the adoption of Encord has significantly aided Voxel's approach to workplace safety and efficiency. The platform's integration and its capabilities have empowered Voxel to address safety concerns and optimize operations effectively. With Encord's ongoing support, Voxel is well-equipped to navigate future challenges and drive innovation in workplace safety, setting new standards for operational excellence.
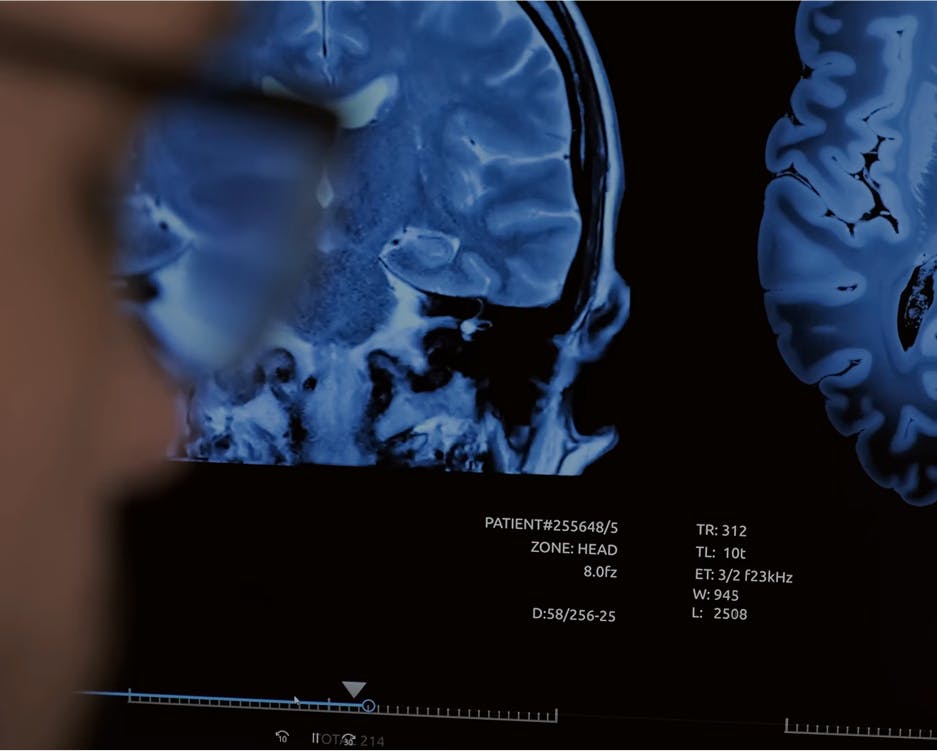
How Floy Reduced CT & MRI Annotation Time by 50%
Floy develops AI that helps radiologists detect critical incidental findings in medical images. Floy partners with radiologists who use their medical expertise to annotate data used for training diagnostic models. When other annotation tools didn’t provide the flexibility or speed that radiologists need, Floy turned to Encord to improve its medical-imaging annotation process. Introducing Customer: Floy Floy’s technology scans radiological images to detect abnormalities, providing a second pair of eyes for radiologists. Radiologists have to interpret and make diagnoses from complex images, such as X-rays, CT scans, and MRIs. They are highly skilled medical professionals, but they’re also human, and their diagnoses are vulnerable to human error. Radiologists can make perceptual errors, in which they overlook abnormality, and interpretive errors in which they identify an abnormality but draw the wrong conclusions. Because radiologists have a tremendous workload – sometimes hundreds of images a day – perceptual errors account for 80 percent of diagnostic radiology errors. Floy’s AI helps solve the perceptual error problem for inpatient and outpatient radiologists. After radiologists complete reading of scans, they use Floy’s product to screen for abnormalities – such as tumors or metastasis – in spinal scans. The AI will alert the doctors to abnormal patterns that may have been overlooked by the human eye, requesting that they double check the scan before making a declarative diagnosis. Problem: Unreliable and Inflexible Tools for Radiologists Developing high-quality medical AI products depends on having high-quality training data. Having processes in place for obtaining consistent, high-quality annotations is of great importance. Floy tried working with open source labeling tools for medical images, but they didn’t have an option for building efficient workflows or sharing data across a team of radiologists. Floy’s radiologists had to download images locally, annotate them using the open source tool, and re-uploaded the image segmentations back to Floy. This unscalable, cumbersome process wasted radiologists’ precious time, decreasing productivity and increasing the likelihood of errors. The off-the-shelf annotation platforms Floy tried contained cloud-based features and allowed users to structure workflows, but they didn’t have specialized annotation features when labeling DICOM images. Radiologists couldn’t annotate seamlessly in these platforms without encountering issues, and some of these tools had bugs which caused image labels to shift location, meaning the radiologists had to redo hours of work. Floy needed a training data tool that enabled high-quality labeling as well as efficient workflow structuring and labeling. The company also needed a tool that made key employees happy. “Radiologists are highly specialized, well educated doctors. Radiological annotators have a separate and rare skill: the ability to interpret medical images and perform accurate segmentation,” explains Leander Märkisch, Co-Founder and Managing Director of Floy. “This skillset makes them hard to find. With inefficient data labeling processes, we have to find and employ more of them to develop our product. With cumbersome products that cause frustration, we run the risk of losing talented annotators.” Image annotation is also the most time consuming and expensive part of product development for medical AI, so labeling efficiency is key for keeping costs down. Solution: DICOM Image Specialization and Quality Control Features Looking for a tool that enabled DICOM image annotation and improved workflows for radiologists, Floy turned to Encord’s collaborative data labeling platform. Encord’s DICOM annotation tool can render 20,000+ pixel intensities as opposed to existing tools that manage just 256. Created specifically for medical image labeling, the technology perfectly fits Floy’s annotation needs. Annotating DICOM images in Encord with windowing pre-set set to 'bone' For data privacy reasons, Floy needed to work with a German cloud provider. Encord built out integrations with Open Telekom so that Floy could store patient data on local servers while still streaming it quickly into Encord’s platform for annotation. Encord’s user-friendly platform enables radiologists to move quickly from image slice to image slice, and it creates a workflow that prioritizes images by order of importance. It also allows reviewers and annotators to collaborate so that annotators can leave notes for reviewers, and reviewers can provide annotators with modified labels and feedback, helping them to improve. Using Encord’s quality assessment tool, Floy’s team has visibility into the entire annotation and review process. Not only does this tool help ensure that labels are of the highest possible quality, it also provides Floy’s team with insights about the annotators themselves. For instance, if one annotator produces consistently low-quality labels, Floy’s team can have them retrained. They can also see whether an annotator performs better on certain scan types and then adjust their annotation tasks according to their strengths. Annotator management dashboard in Encord Results: Higher-quality Data in Less Labeling Time With Encord, Floy has built a scalable workflow process that results in high-quality annotated data that feeds back into its models. Using Encord’s platform, Floy’s annotation team has labeled 5,100 scans, each containing between about 16 to 200 images, or a total of approximately 60,000 images. Equally important, Floy’s annotators are very happy when using the product. The time it takes for them to label images has reduced by approximately 50 percent for CT scans and 20 percent for MRI scans. Encord’s platform also facilitates new types of collaboration beyond those between annotators and reviewers. “Our ML engineers and product managers also use the platform,” says Märkisch. “Because everyone has visibility into the training data pipeline, our conversations have changed. We no longer have to ask annotators for general updates about the labeling process. We can instead use our insights about the annotation process to have discussions about product development timeline and make better business decisions.” Floy and Encord’s teams have benefited from close collaboration. The two companies solve problems together in real time. When Floy has provided feedback about the product from radiologists or data engineers, Encord’s team implemented features and improvements based on that feedback. Working with Encord, Floy can be certain that it’s training its models on high-quality data so that it can build great products that serve patients. As the company expands and builds technology that works with new modalities and different body parts, Encord’s platform can help them ramp up their training data processes to develop new products quickly.

How Conxai Increased Labeling Speed by 60% with Encord
CONXAI is building an AI platform for the Architecture, Engineering and Construction industries to contextualise different data and transform them into actionable insights. CONXAI, however, encountered challenges with optimizing datasets, reviewing labels, and managing large volumes of data with their in-house data annotation solution. This is where Encord came in - CONXAI was looking for an end-to-end solution for data management and curation, annotation, and evaluation. Introducing Customer: CONXAI CONXAI’s goal is to help AEC teams perform better by organizing and making sense of the vast amount of data generated during different stages of construction projects. They specialize in making data more useful, especially since a lot of project data often goes unused. Their ultimate aim is to help AEC professionals use AI effectively to improve efficiency and tackle challenges in their projects. We sat down with Markus Kittel, AI Product Development Manager at CONXAI, to discuss his work overseeing the product roadmap, and their exciting plans ahead for the business. Problem: Challenges in Data Curation and Management CONXAI's approach involves working with large unstructured datasets, which leads to challenges in effectively managing and curating project data. Their initial reliance on their in-house solution for data annotation proved to be problematic as the volume of data increased. Like many in-house tools, it was prone to frequent malfunctions, obscured the data it processed, and lacked mechanisms for reviewing annotations. Additionally, scalability was a major concern, as the in-house tool struggled to handle the increasing volume and complexity of project data. Without a reliable and scalable data management system in place, they faced difficulties in optimizing datasets and analyzing data effectively. As a result, CONXAI recognized the pressing need for a comprehensive solution that could streamline its data curation and management processes, enabling it to unlock the full potential of AI-driven insights within the AEC industry. CONXAI were also in need of a solution where data security took precedence, enabling data to remain within CONXAI servers and be accessed via an API or SDK. Solution: Encord Provides a Unified Platform for Data Curation and Management “With other labeling tools, we needed to integrate another tool for data management and exploration capabilities, but Encord combined the two needs and provided a single comprehensive solution, along with excellent customer care and support,” Markus says. To address these challenges, CONXAI explored various annotation tools. They were searching for a single platform that could handle data curation and management seamlessly. Encord's Annotate and Encord Active emerged as the ideal solution, offering a comprehensive platform to streamline CONXAI’s operations. As Markus says “We connect Encord Active with our large dataset and then use metrics to prioritize building a collection of images. This collection is then sent to Encord Annotate for labeling images in preparation for training. And all this without the data leaving our server.” Result: 60% Increase in Labeling Speed With the adoption of Encord into the data pipeline, CONXAI witnessed significant improvements in its data management processes. Encord facilitated the transformation of unstructured data into labeled, training-ready, datasets. The intuitive interface of Encord's Annotate tool simplified the annotation process for CONXAI's team, while also providing robust label review capabilities. Moreover, Encord's Active platform allowed CONXAI to efficiently curate and evaluate their datasets. “The labeling speed of the annotation team improved to almost 60% compared to when using their in-house tool.” - Markus Kittel CONXAI was able to curate over 40k images with Encord Active. They were then able to efficiently evaluate and prioritize these images based on metrics, facilitating streamlined data management and enhanced decision-making processes within their operations. CONXAI were able to contribute to Encord’s product roadmap by identifying that mapping relationships between labels in their ontology would enhance model performance. The Encord team were able to deploy this functionality, resulting in an improved user experience for CONXAI. Overall, using Encord led to enhanced robustness, simplified data pipelines, and a remarkable 60% increase in labeling speed compared to CONXAI's previous in-house tool. This demonstrates how adopting an end-to-end platform with annotation, curation, and evaluation capabilities provides the best solution for computer vision teams.

How Tractable Trained 40+ Annotators with Encord's QA & annotation review
Founded in 2014, Tractable uses AI technology to assist insurance providers in performing visual assessments of damaged assets. The company designs customizable machine learning models to serve insurance providers around the globe. As the complexity of data annotation projects grew, Tractable turned to Encord for a user-friendly platform that allowed for complex ontologies, annotator monitoring, and quality assurance. Introducing Customer: Tractable By analyzing customer images, Tractable quickly facilitates accurate damage appraisal, making the recovery from accidents 10 times faster and enabling people to move through the claims process quickly and efficiently after they’ve had an automobile accident. Tractable also offers products for property assessment, providing the same high-quality experience for incidents that involve property damage and thereby helping people to recover faster after a disaster strikes their home. Beyond accident recovery, Tractable’s technology can assist people throughout the entire lifecycle of owning a car or property. With Tractable, they can perform visual inspections before selling an asset, determine which parts of an asset to salvage or replace, obtain a condition report on a leased asset, and more. By using Tractable, insurance providers can free up employee time for high-value tasks, improve customer experiences, accelerate repairs, and increase recycling– all of which has a positive impact on people and the world they live in. Problem: Performing Quality Assurance When Scaling Up Projects with Complex Ontologies When building their first models for image classification, Tractable’s team designed and used internal tools for data annotation. However, as Tractable grew their product offerings, the annotation tasks became more complicated, and the team needed a training data platform that supported segmentation. Building one in-house would be costly and time consuming. Tractable’s team tried a few third-party platforms, but as the projects scaled and grew in sophistication– moving towards more pixel-level annotations with more complex ontologies– they found that many of these platforms had limitations, especially when it came to quality assurance (QA) functionality. As Tractable began building its property assessment models, the remote annotation team began to grow rapidly and the need for improved data annotation workflows became more urgent. Ensuring the quality of both the data and its labels became increasingly important as annotation tasks grew in complexity and size. “As our ambition grew, we realized that the functionality of many of the tools we were using was quite limited,” says Camilla Gilchrist, Head of Operations at Tractable. “We had a lot of steps in our annotation workflows, with many different pipelines, and the platforms couldn’t handle that complexity. We also had a bottleneck around quality assurance. With image segmentation, you can’t do a quick agreement rate analysis and doing a manual quality assurance check on each piece of data isn’t feasible. We needed a far more efficient way to assess quality.” Tractable needed a training data platform that could incorporate the feedback of expert decision makers in the annotation process and provide QA functionality. Solution: A User-Friendly Training Data Platform with Quality Assurance and Annotator Review Functionality When annotating data for its models, Tractable needs to take into account expertise beyond visual observations. “Think about how motor engineers assess damage on a vehicle,” explains Camilla. “They don’t just look at the car: they open and close the doors, feel the body work, and much more. As much as possible, we incorporate that expertise into our models, which requires determining specific annotation criteria that’s often quite complex. We need an accessible training data platform that allows annotators to break these complex labeling tasks into smaller parts and provides quality assurance and annotation review functionality. Otherwise, annotation tasks quickly become overwhelming, and the risk of mistakes increases.” The higher the granularity of an annotation task, the greater the amount of detailed features that must be labeled in each piece of data. This level of detail increases the need for annotator monitoring and quality assurance. Unlike Tractable’s legacy training data platforms, Encord built out the QA functionality that the company needed, enabling Tractable to unlock the power of using granular annotation techniques at scale. At the same time, Encord’s user-friendly platform provided a level of control that allowed Tractable’s operations professionals to build out ontologies quickly. The other platforms that Tractable had used allowed for custom mixtures of segmentation and frame-level annotation, but they required users to implement these customizations programmatically. SageMaker, for instance, allows for users to create custom UIs and ontologies, but to do so Tractable’s engineering and research teams had to put in a lot of time and effort into delivering the tooling the company needed. Results: Improved Quality Control, Data Governance, and Annotator Training With Encord’s QA and annotation review features, Tractable has been able to train annotators efficiently, monitoring their performance and providing feedback along the way. Their remote annotation team has grown to over 40 people. “Managing QA workflows efficiently and having an overview of the entire annotation process has been so important for our success. The more manual that QA process is, the more the amount of work explodes as the annotation workforce scales,” explains Camilla. “It’s always about balancing speed and quality. A lot of platforms prioritize speed over quality or quality over speed. Encord speeds up annotation while still allowing for strong quality control.” Encord’s API also works with S3 servers as a primary integration, so Tractable can keep customer data on its own servers. Because Tractable operates globally, it has to adhere to different data governance rules depending on the region in which a customer is located. The other tools that Tractable tried didn’t prioritize S3 integrations, so when the API broke, Tractable had to wait for and nudge those platforms to fix it– a less-than-ideal situation for a global company. “Encord’s team has been very hands-on in delivering what we need to succeed,” says Camilla. “A lot of companies promise that level of commitment, but Encord actually delivers it. We receive excellent support. They build out new features quickly based on our feedback. With other platforms, we’ve had to troubleshoot problems on our own– even to the extent that we basically needed to build our own offline tooling to process the data we labeled using them! Encord has worked with us to find a solution for every challenge."