Label and curate video data 6x faster
Accelerate precise video data annotations without frame rate errors to build production-ready models faster using high-quality labeled videos.
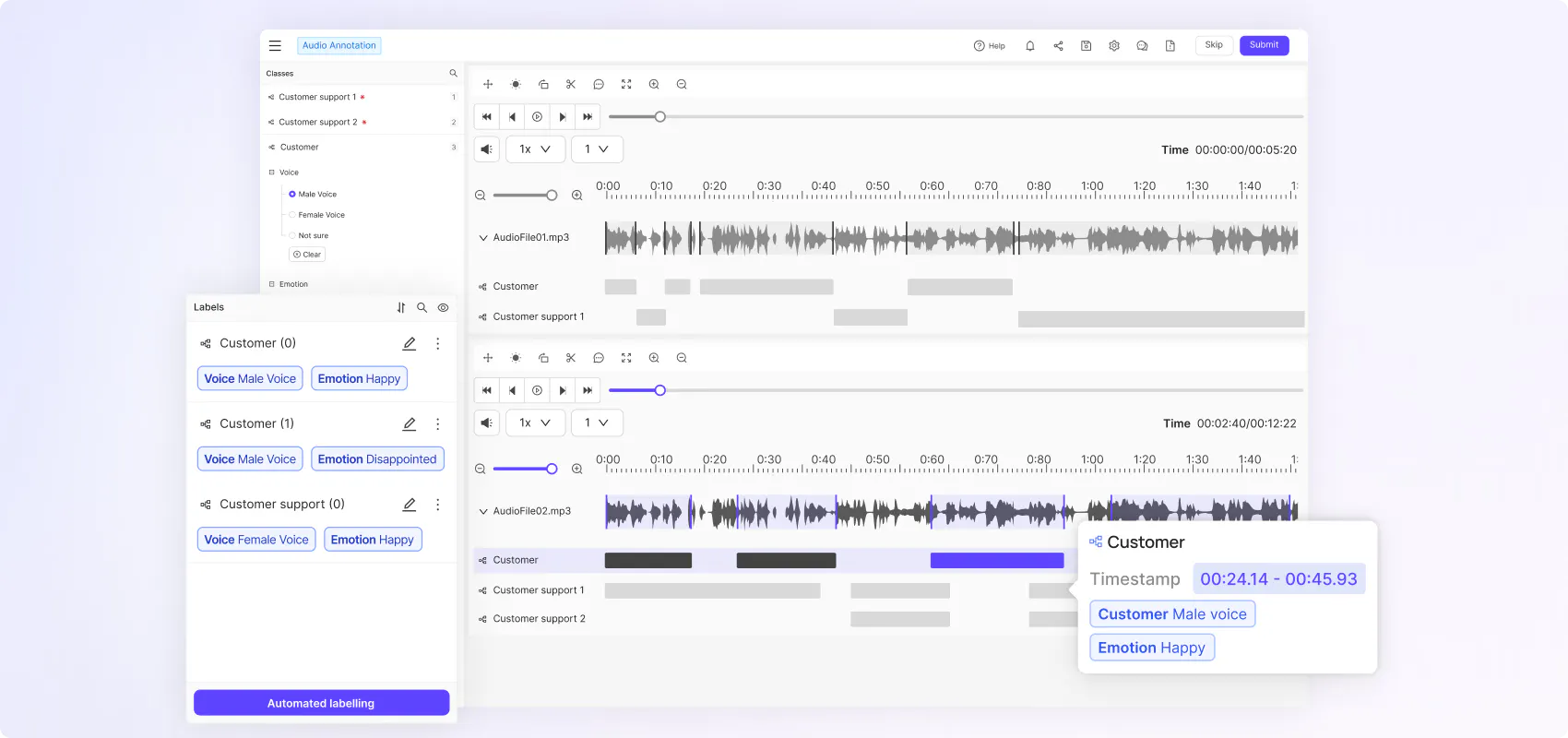
Achieve high quality video annotation with granular tooling
Use precision automated object tracking and segmentation as well as polygons, polylines, bounding boxes and more to quickly annotate full-length videos across MP4, avi, mov, and WebM file formats.
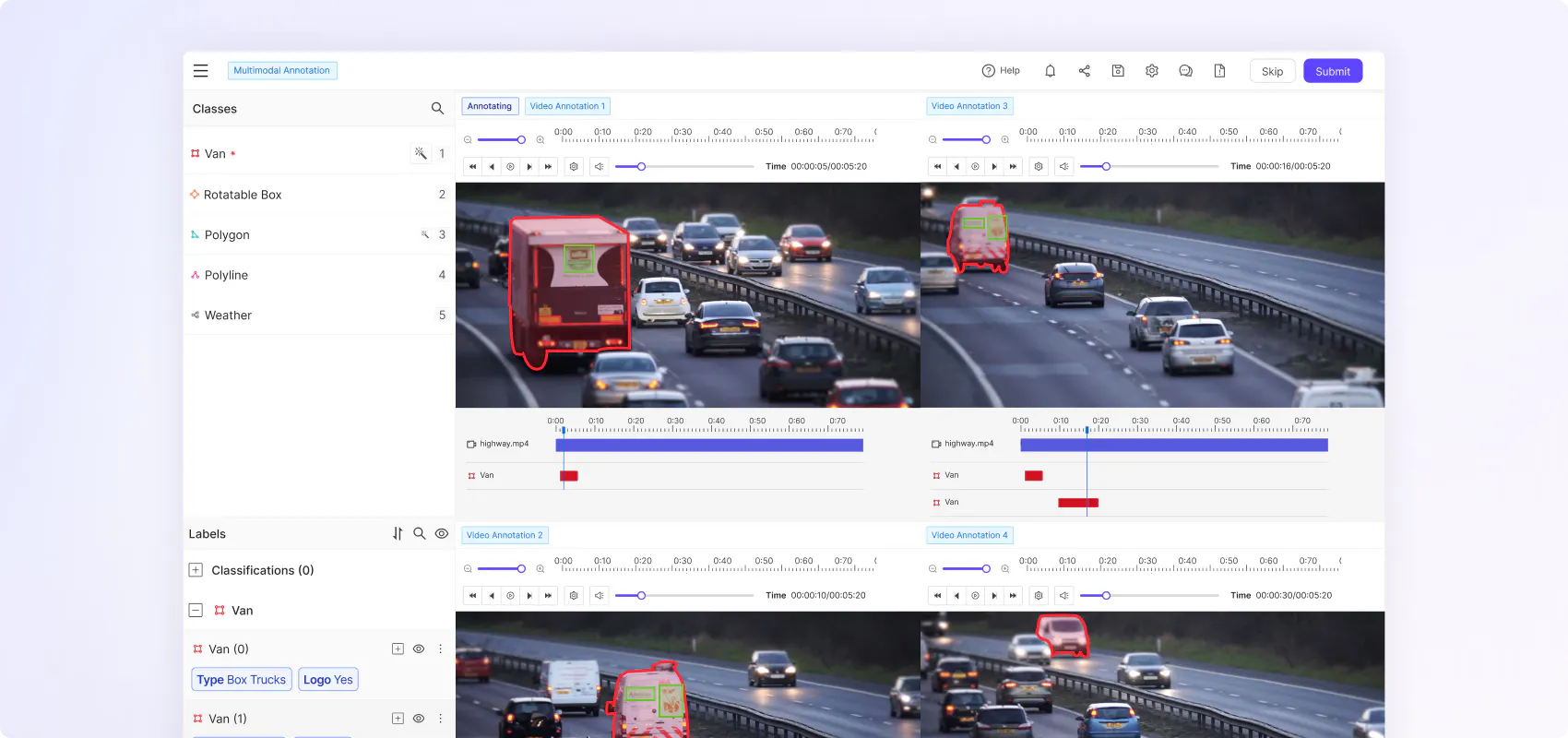
“Setting up our labeling process with our previous solution took nearly two months and required extensive support. With Encord, we were operational in just two weeks, and then we went on vacation and got back, and the data was good.”

Rammohan Adabala
Principal Product Manager
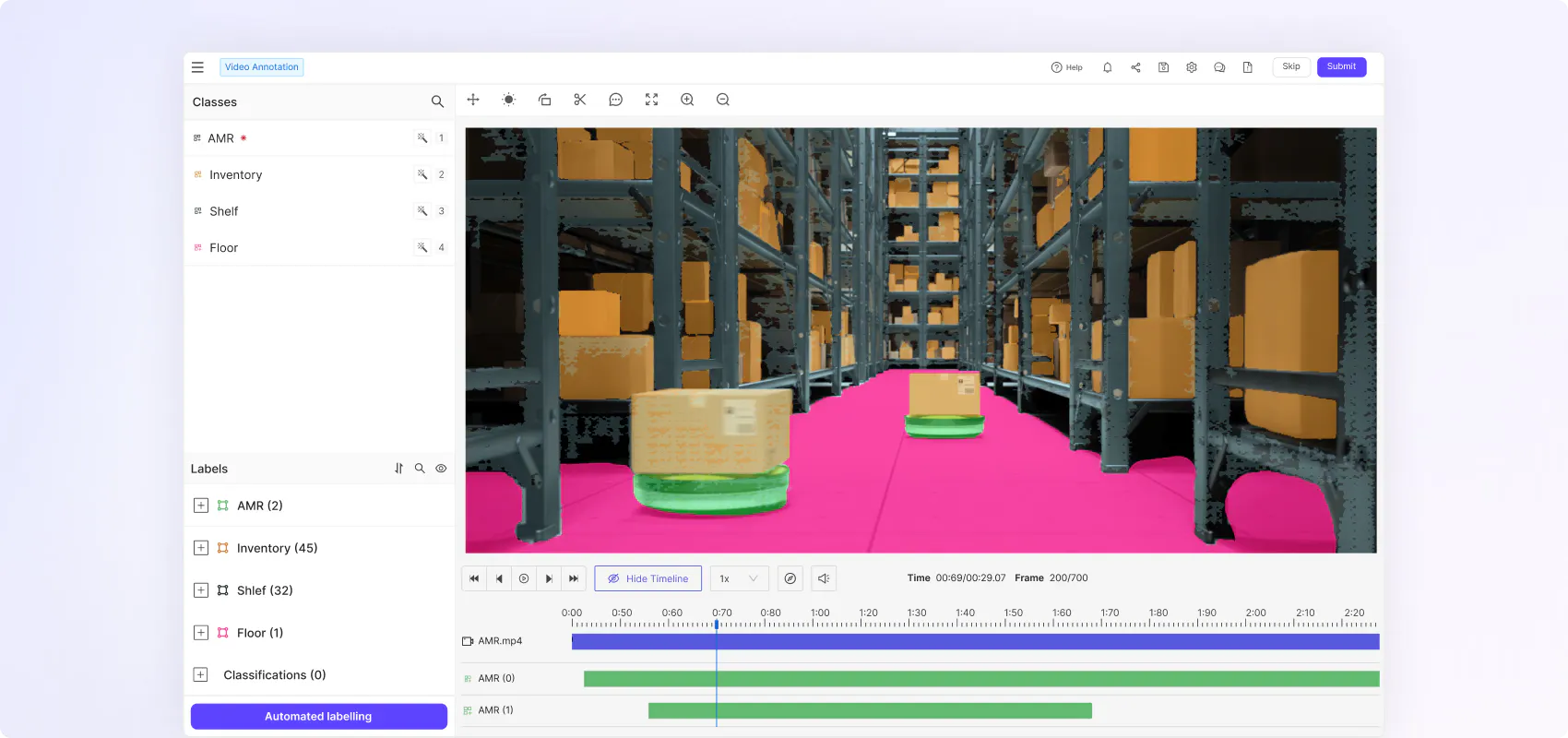
Boost annotation efficiency and accuracy with native video rendering

Native rendering for seamless frame synchronization
Preserve temporal context to improve annotation quality and speed. Native video rendering uses 80% less storage boosting data pipeline efficiency.
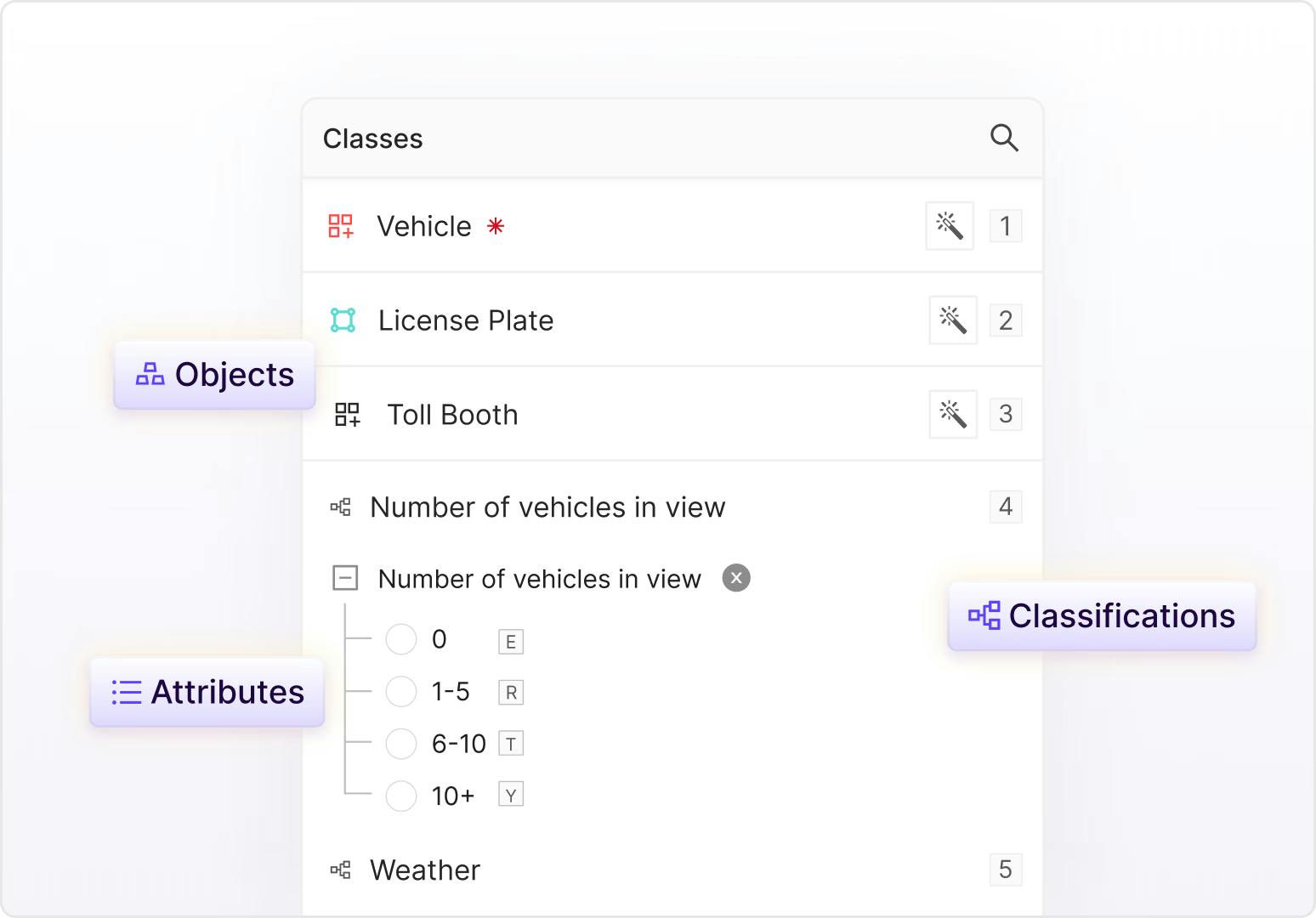
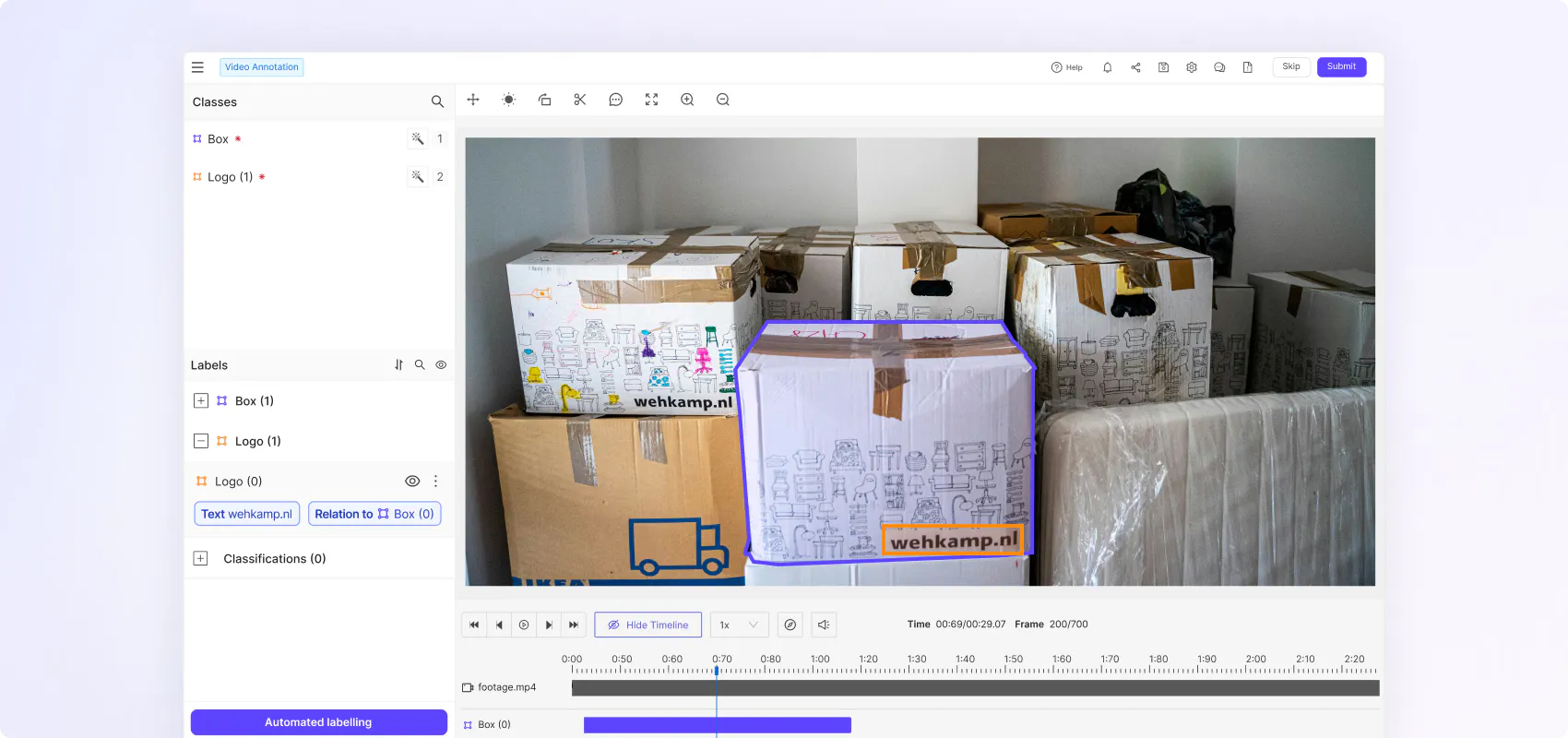
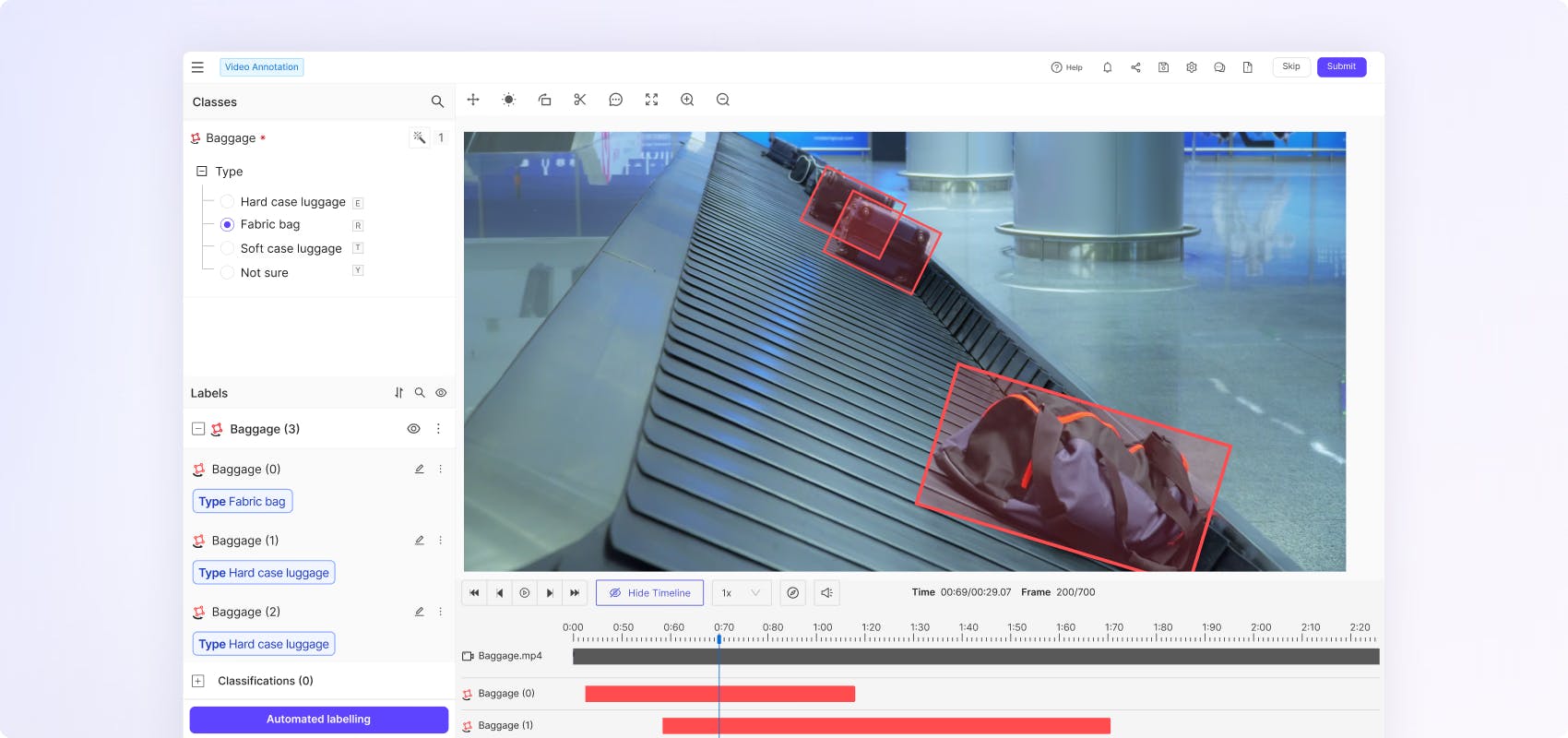
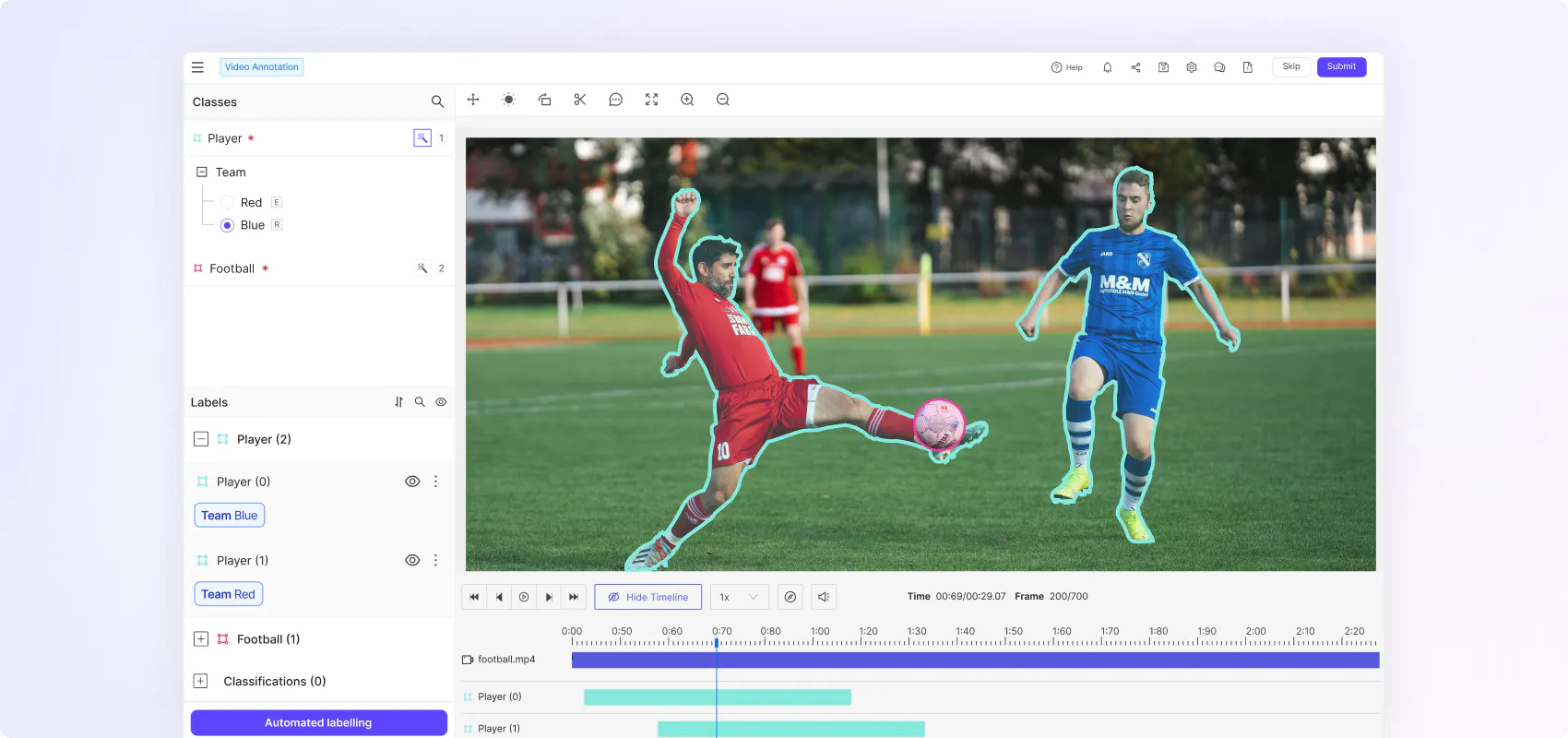
Flexible ontologies for every use case
Create nested classifications with static, dynamic and relation attributes to capture real world scenarios in the granular detail and temporally evolving object behaviour.
Improve label quality and speed with AI-assisted video labeling
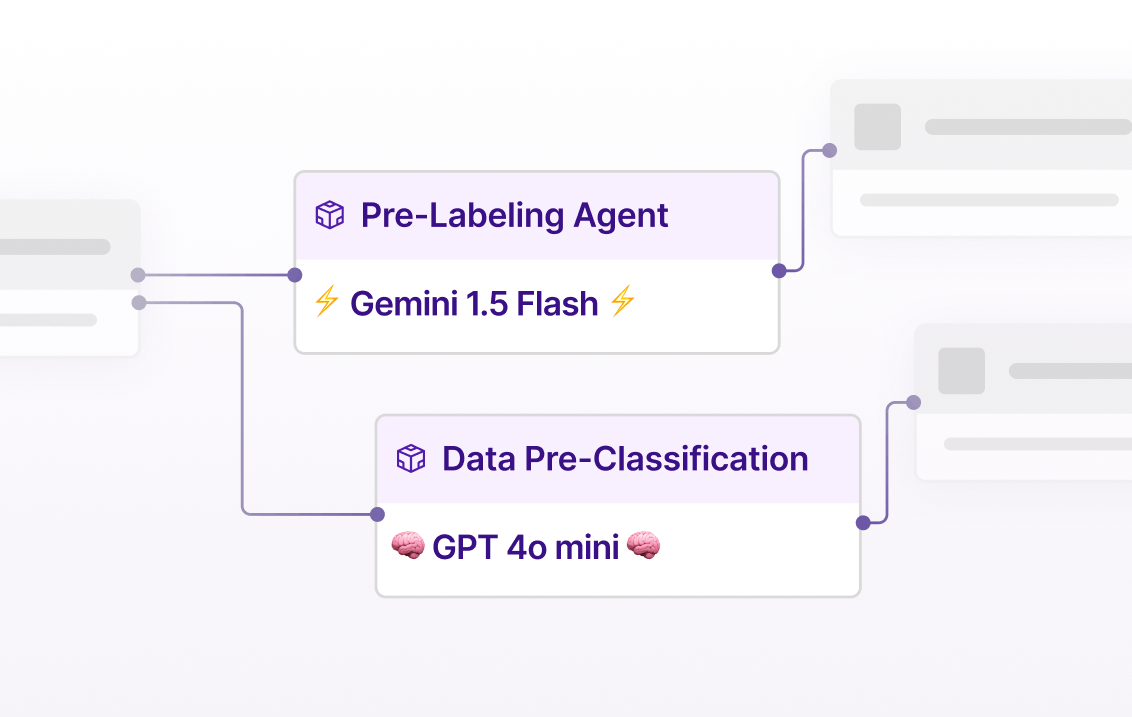
Customizable workflows for AI-assisted labeling
Integrate SOTA models or your own models directly into your data workflows to automate any data action such as reviews, pre-labeling, data classification, filtering and more.
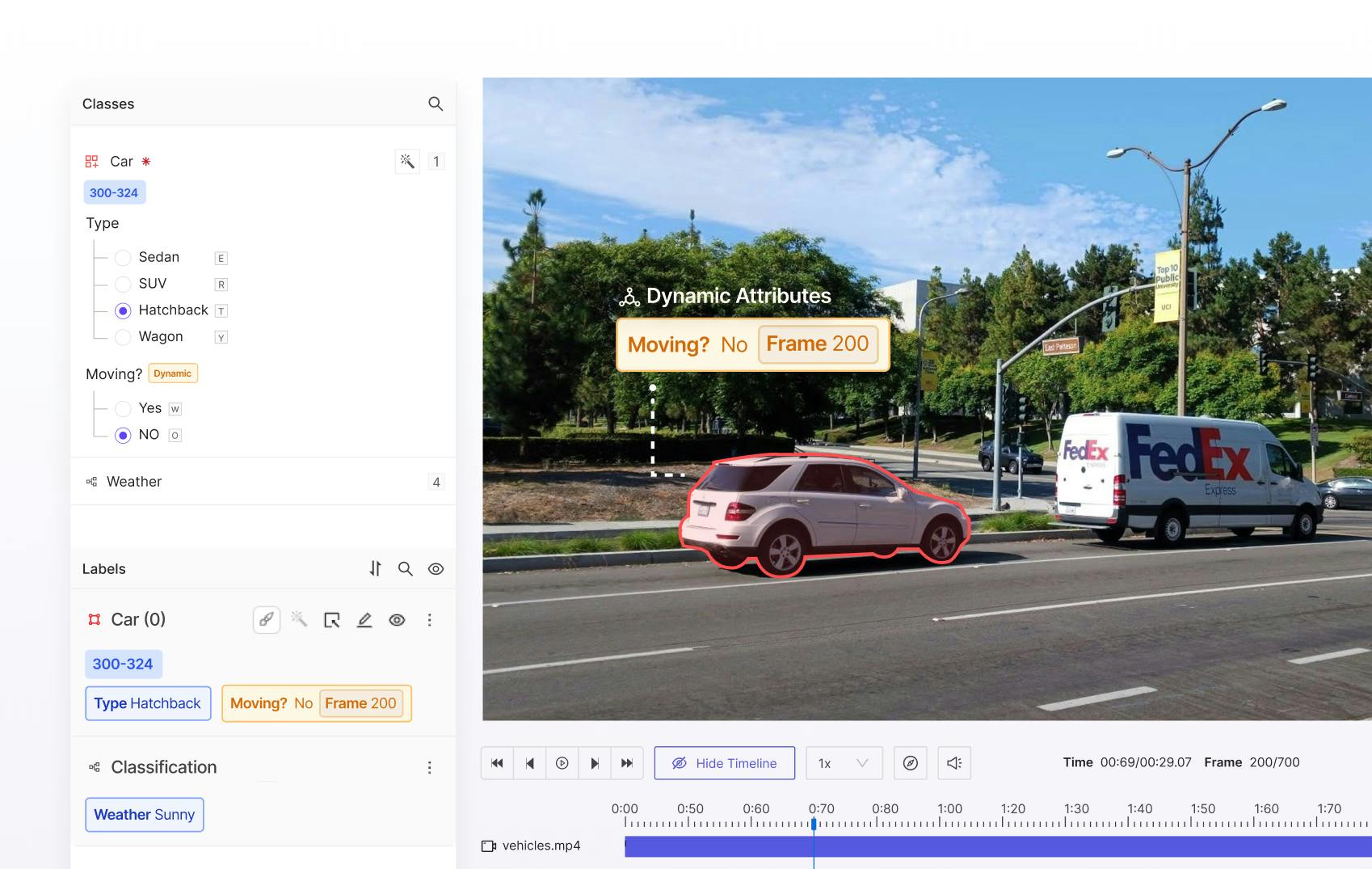
Video native AI-assisted labeling with SAM 3
Access SAM 3 natively within Encord for model-assisted labeling to achieve faster and more accurate mask prediction and object tracking.
Instantly manage and curate millions of video files and frames
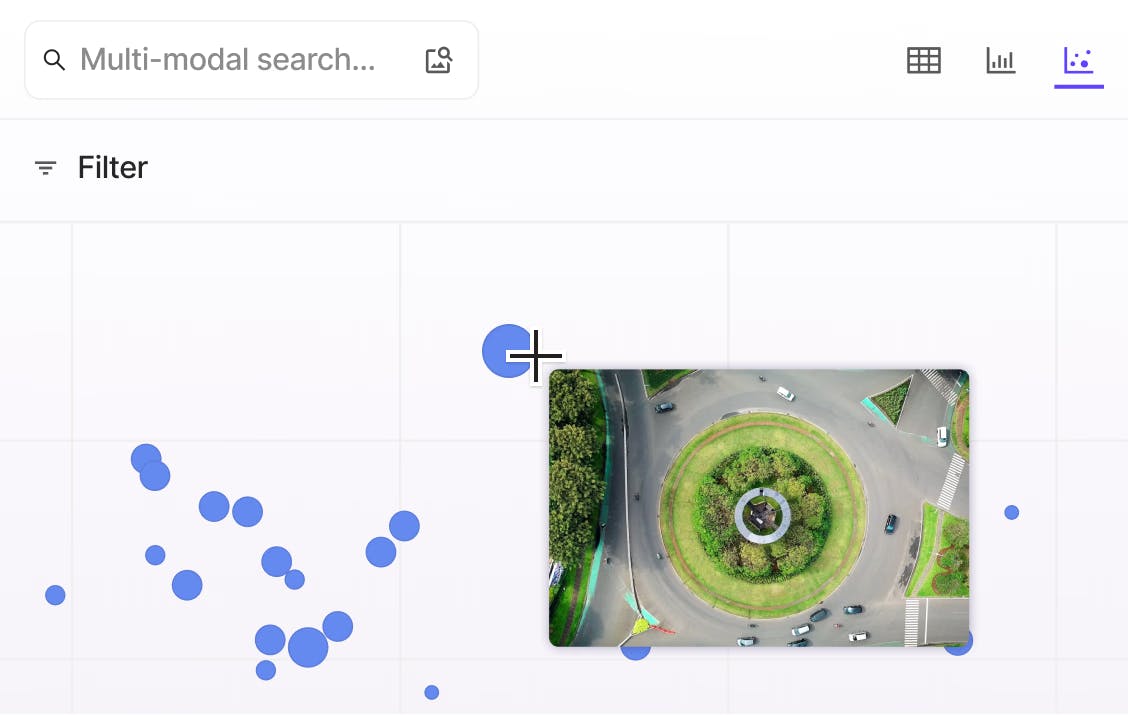
Manage millions of video files with ease
Explore and curate billions of video frames at scale with granular filtering, sort and search using quality metrics, custom metadata, and natural language queries.
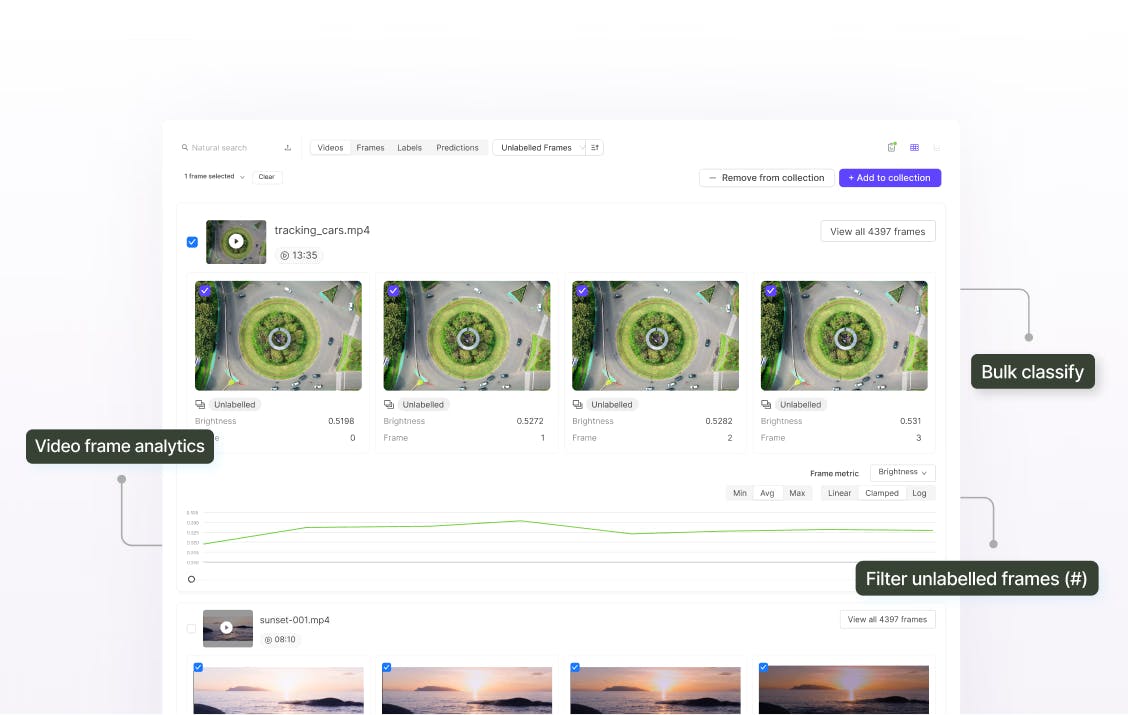
Curate video files using quality metrics
Explore videos temporally by embeddings-based quality metrics to find the most valuable data for labeling and create diverse training datasets.
You're in good company
Encord is used by 300+ frontier AI teams to deploy production-ready AI models.
Enterprise-grade.
Built for scale.
Designed for reliable AI.
Built for scale.
Designed for reliable AI.
API/SDK-first. Zero data migration. Your data stays in your cloud.
Visit trust centre


Frequently asked questions
It’s an AI-assisted platform designed for high-quality video labeling. It accelerates precise annotations without frame rate errors, enabling faster training of production-ready models.
Encord uses native video rendering to preserve temporal context, prevent frame-splitting issues, and reduce storage usage by up to 80%, boosting both speed and data pipeline efficiency.
Encord supports multi-view annotation, object tracking, related objects, rotatable bounding boxes, semantic segmentation, panoptic segmentation, and audio annotation.
Yes. With native SAM 3 integration, you can achieve faster and more accurate mask prediction and object tracking. Workflows allow automation of reviews, pre-labeling, classification, and filtering.

Get the data right
300+ of the best AI teams in the world use Encord. Join them.