ADAS Data Annotation Pipelines: Building Scalable, High-Quality Training Data with Encord

Head of Forward Deployed Engineering at Encord
High-performing ADAS and autonomous driving models are only as good as the data they are trained on. As you can imagine, in systems that are deployed in high volatility, safety critical environments, this data pipeline is critical. Pedestrians run into the road, other vehicles can break abruptly on the highway, and adverse weather conditions can impact vision capabilities. All of which ADAS need to understand when motion planning and operating.
Behind every reliable perception system lies a robust data annotation pipeline, capable of handling massive volumes of multi-sensor data while maintaining accuracy, consistency, and scalability. This not only ensures those deploying AVs and ADAS can do so efficiently, but also prevents catastrophic consequences for those operating these vehicles on the road.
This article explores end-to-end ADAS data annotation pipelines, from raw sensor ingestion to QA and continuous improvement, especially how ML engineers can use Encord to build & scale.
Why Data Annotation Is Hard in ADAS
ADAS data annotation is fundamentally more complex than traditional computer vision labeling tasks. The data itself is high-volume and messy, reflecting the real-world environments vehicles must navigate.
Multi-sensor data fusion
One of the biggest challenges is multi-sensor data fusion. ADAS systems typically combine inputs from cameras, LiDAR, and radar. Annotations must remain consistent across all sensors, which significantly increases complexity.
Temporal consistency
Another major challenge is temporal consistency. ADAS models don’t operate on single frames, they reason over sequences. Objects must maintain stable identities across time, with accurate tracking and trajectories. A bounding box that drifts or disappears between frames can degrade the model downstream.
Managing complex label taxonomies
ADAS annotation also requires managing complex label taxonomies. Objects must be categorized not only by class (car, pedestrian, cyclist) but often by sub-class, state, intent, or behavior. Lane markings, traffic signs, drivable space, and free space introduce additional semantic layers.
Safety-critical accuracy thresholds
Finally, the stakes are much higher. Safety-critical accuracy thresholds mean that annotation errors can translate into real-world risk. Unlike other computer vision tasks, ADAS annotation pipelines must meet automotive-grade reliability standards.
Types of ADAS Annotations
A robust ADAS data annotation pipeline supports multiple annotation types, each serving different components of the perception and planning stack. They include:
2D Annotations
2D annotations are typically applied to camera data and form the foundation of many perception models.
Bounding boxes are drawn for detecting vehicles, pedestrians, cyclists, and other objects on the road. To ensure the highest level of accuracy, they must be tightly fitted and consistent across frames to support tracking.
Additionally, semantic segmentation assigns a class label to every pixel in an image. This is commonly used for identifying drivable areas, sidewalks, curbs, vegetation, and obstacles.
Lane markings and traffic sign annotations are also critical for localization, path planning, and rule compliance.
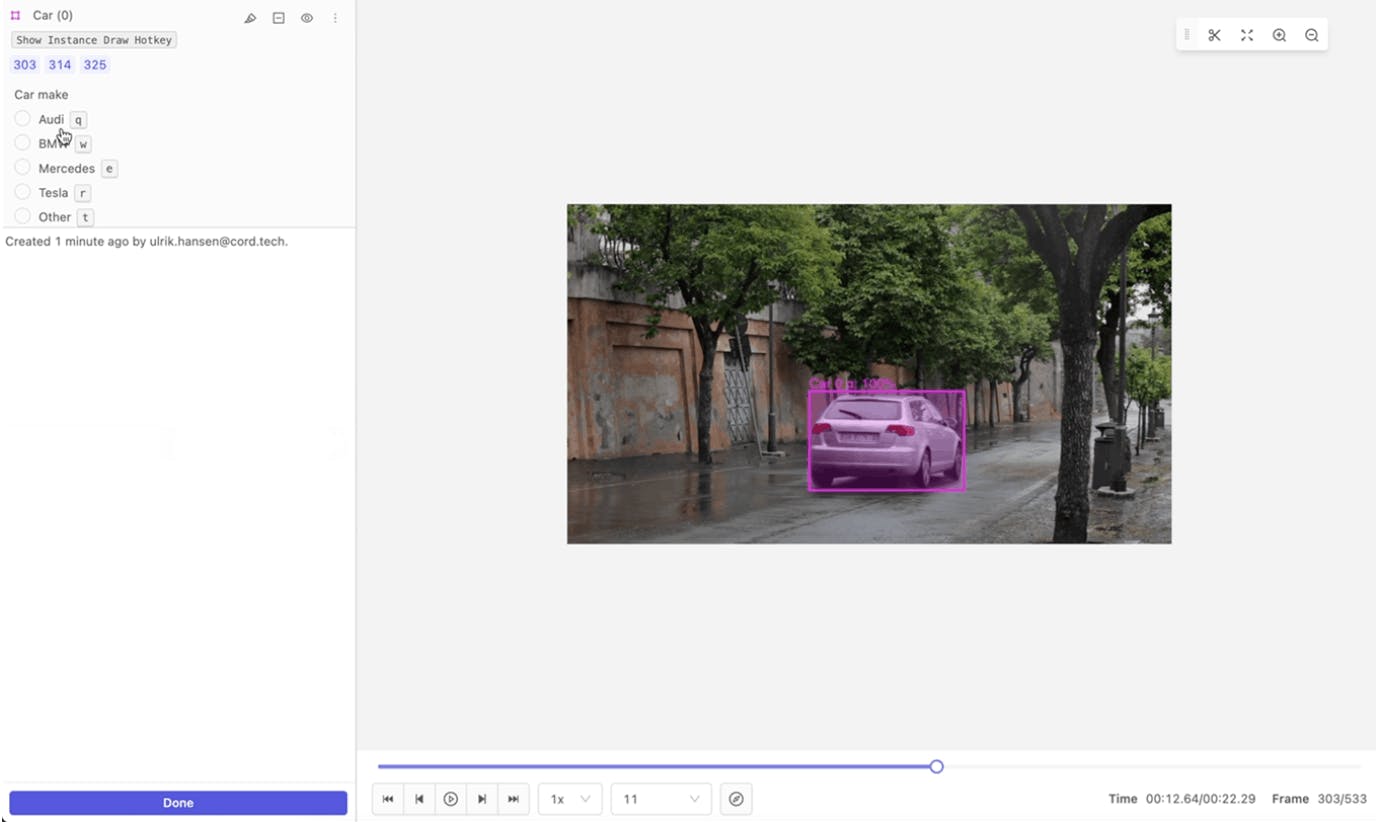
2D Data Annotation in Encord
3D Annotations
3D annotations are essential for understanding depth, scale, and spatial relationships in the environment. They are typically generated using LiDAR data, sometimes fused with camera imagery.
3D bounding boxes capture object dimensions in real-world coordinates, enabling accurate distance and collision estimation.
Object orientation, velocity, and acceleration labels support motion prediction and behavior modeling.
Tracking IDs link objects across frames, allowing models to learn temporal continuity and object permanence.
Temporal Annotations
Temporal annotations focus on how objects and scenes evolve over time rather than static snapshots.
Object trajectories describe paths taken by vehicles and pedestrians across multiple frames, which are crucial for prediction models.
Event labeling captures higher-level behaviors such as lane changes, cut-ins, hard braking, or jaywalking. These annotations are especially valuable for training planning and decision-making systems.
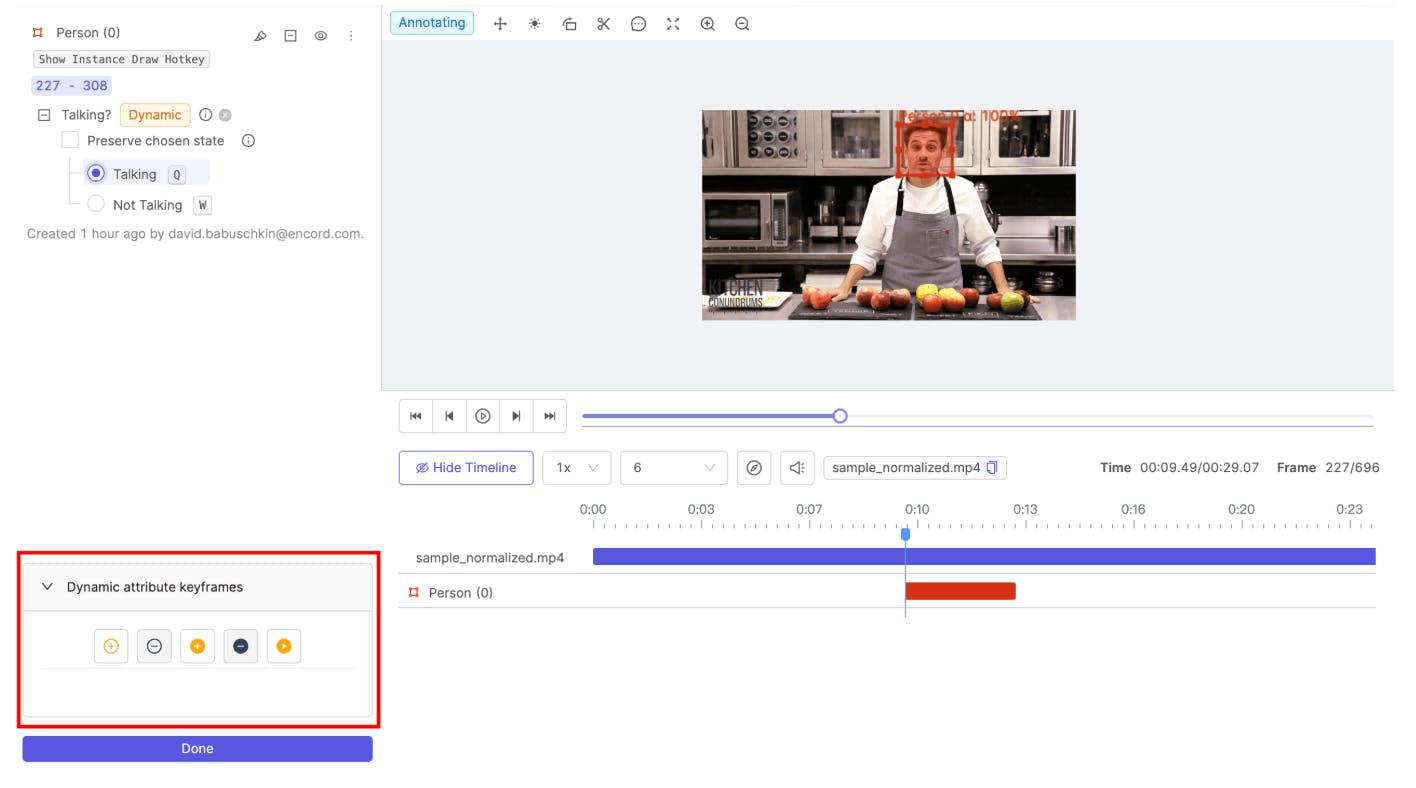
Dynamic Attributes in Encord
Data Ingestion and Preprocessing
Every ADAS data annotation pipeline begins with data ingestion and preprocessing, and mistakes at this stage propagate downstream.
Raw sensor streams must first be synchronized so that camera frames, LiDAR, and radar measurements align in time. Even small timing offsets can cause spatial mismatches that make accurate labeling difficult.
Sensor calibration is equally critical. Intrinsic calibration ensures each sensor’s internal parameters are correct, while extrinsic calibration defines how sensors relate to one another in a shared coordinate frame. Miscalibration leads to systematic label drift and geometry errors.
Coordinate frame alignment transforms all data into a consistent reference, such as the vehicle frame or world frame, enabling cross-sensor annotation and validation.
Finally, data validation and filtering remove corrupted frames, sensor dropouts, or anomalous recordings before annotation begins. High-quality preprocessing dramatically reduces annotation cost and error rates later in the pipeline.
Annotation Tooling and Automation
Modern ADAS data annotation pipelines rely on a mix of manual effort and automation to balance quality, speed, and cost.
Manual Annotation
Fully manual annotation is still used for edge cases and rare scenarios. Human annotators provide high accuracy, but this approach is slow, expensive, and difficult to scale. As a result, manual labeling is typically reserved for validation datasets and complex cases.
Assisted Annotation
Assisted annotation introduces models into the labeling loop. Pre-trained perception models generate initial labels, which human annotators then verify and correct. This approach significantly accelerates throughput while maintaining high quality.
Auto-labeling with human verification is particularly effective for common object classes and well-understood scenarios.
- Interpolation – automatically fills labels between keyframes for many shapes (bounding boxes, polygons, polylines, primitives, keypoints, bitmasks, cuboids, segmentation).
- SAM 2 Segmentation & Tracking – click-based segmentation and forward/backward tracking across frames for supported shapes and modalities.
- SAM 3 (Early Access) – text- or click-prompted detection and tracking of one, multiple, or all objects of a class.
- Object tracking & interpolation controls directly from the Automated labeling drawer and object menus in videos/DICOM.
Active Learning
Active learning prioritizes which data should be annotated based on model uncertainty or error signals. Instead of labeling everything, the pipeline focuses on samples that provide the greatest marginal improvement to model performance.
This strategy dramatically reduces labeling costs while improving coverage of edge cases and failure modes.
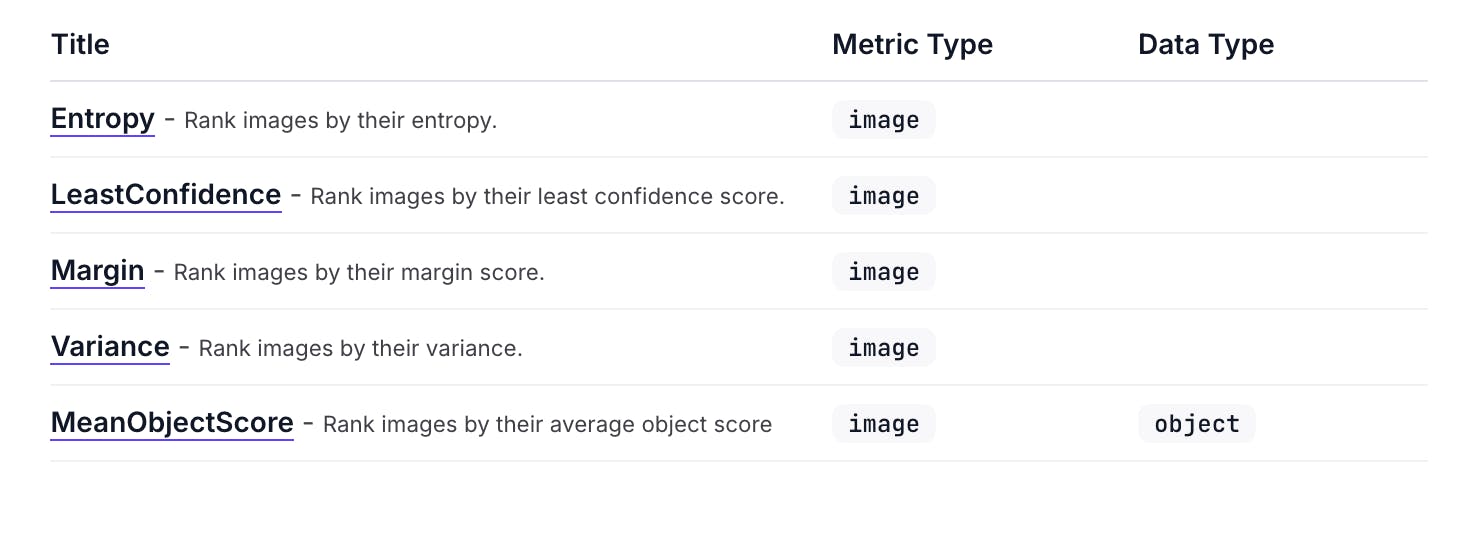
- Use acquisition functions (e.g. Entropy, LeastConfidence, Margin, Variance, MeanObjectScore) to rank samples by model uncertainty and select what to label next. [Model metrics]
- Explore and filter data/labels/predictions, then create Collections of high‑value or problematic samples and send them to Annotate for labeling or relabeling.
- Import predictions, compute model quality metrics, and decompose model performance to find failure modes and guide the next labeling round.
- Iterate through the documented workflows for data curation, label error correction, and model optimization, which are explicitly framed as active learning–style loops.
Quality Assurance and Validation
For ADAS systems, quality assurance is not optional, it is foundational.
Robust QA processes often include multi-pass annotation, where different annotators independently label the same data and discrepancies are resolved.
Statistical sampling ensures that large datasets maintain consistent quality without requiring exhaustive review.
Geometry and consistency checks validate that annotations make physical sense, such as ensuring 3D boxes align with point clouds and remain stable across frames.
Cross-sensor validation compares annotations across camera, LiDAR, and radar to detect mismatches and systematic errors.
Together, these QA strategies help ensure that labeled data meets the reliability standards required for safety-critical deployment.
How to Use Encord for ADAS Data QA and Validation
Encord supports Quality Assurance (QA) and validation mainly through Encord Active plus workflows in Annotate.
1. Label validation & error detection
Encord Active provides Label Quality Metrics to automatically surface likely label issues, such as:
- Label Duplicates
- Missing Objects
- Object Classification Quality
- Occlusion Risk
- Polygon Shape Anomaly
- Relative Area, Width, Sharpness, etc.
These can be accessed in both Explorer (Labels tab + embedding plot) and Analytics → Annotations, where you sort/filter by each metric to find problematic labels.
For videos, there are additional annotation metrics like Broken Track, Inconsistent Class, and Inconsistent Track to detect temporal labeling issues.
2. Data & model quality metrics
Encord Active computes:
- Data/Video Quality Metrics (e.g. brightness, contrast, sharpness) to assess raw data quality.
- Model Quality Metrics / acquisition functions (Entropy, LeastConfidence, Margin, Variance, MeanObjectScore) to identify uncertain or low‑quality model predictions for review.
These metrics are used to rank and filter samples for QA, relabeling, or targeted review.
3. Systematic QA workflows (Active ↔ Annotate)
Typical QA/validation loops:
Data Curation & Label Error Correction:
- Import from Annotate into Active
- Use metrics & exploration to find bad labels
- Create a Collection of problematic items
- Send the Collection to Annotate for relabeling
- Sync updated labels back to Active and re‑check
Model Evaluation & validation:
- Train model on exported labels
- Import predictions into Active
- Use analytics & model metrics to find failure modes
- Curate and relabel targeted data, then retrain and re‑evaluate
4. Project‑level QA in Annotate
On the annotation side, QA is supported by:
- Consensus workflows and Review nodes (including strict review and “Review and refine” modes) to systematically review and approve/reject labels from multiple annotators.
- Annotator Training Projects (including bitmask support) to train and assess annotators on specific label types before or during production work.
5. Active learning style QA
In Active, QA is part of an active learning loop:
- Find label errors that harm model performance
- Automatically decompose model performance to decide where to focus next
- Tag subsets and maintain test sets for ongoing validation
Scaling Annotation for Production
As these systems are deployed and reach full-scale production, annotation pipelines must be designed to scale reliably and efficiently. This is especially critical for enterprise autonomous vehicle companies like Tesla and Waymo, where massive volumes of multi-sensor data must be processed without compromising accuracy or safety.
One key requirement is dataset versioning. As labels evolve and models are retrained, teams need a robust system to track which model was trained on which dataset version, ensuring full reproducibility and traceability. At the same time, label schema evolution introduces additional complexity: as taxonomies change over time, pipelines must support data versioning.
Another challenge is data drift, which occurs when labels shift from frame to frame. However, this can degrade model performance and introduce inconsistencies that propagate into production. To mitigate this, scalable pipelines treat annotations as first-class data assets, capturing lineage, metadata, and full traceability while maintaining cost efficiency across large-scale operations.
Feedback Loops with Model Training
To ensure continuous improvement, high-performing ADAS teams tightly integrate their annotation pipelines with model training workflows. Analysis of model errors directly informs new labeling tasks, highlighting failure cases that require additional data or refined annotations. Similarly, edge cases discovered during deployment trigger targeted data collection and annotation, expanding dataset coverage where it matters most.
Regular dataset refresh cycles ensure that models stay current as environments, vehicle platforms, and sensor configurations evolve, reducing performance decay over time. By coupling annotation, QA, and training in this closed-loop system, organizations transform annotation from a one-time task into a continuous optimization process, reinforcing both data quality and model reliability at scale.
Scalable, high-quality data annotation pipelines are a competitive advantage in ADAS and autonomous driving. As models grow more complex, investment in tooling, automation, and QA will increasingly determine system performance and safety.