The Complete Guide to Human Pose Estimation for Computer Vision

Human Pose Estimation (HPE) is a powerful tool when machine learning models are applied to image and video annotation.
Computer vision technology empowers machines to perform highly-complex image and video processing and annotation tasks that imitate what the human eye and mind process in a fraction of a second.
In this article, we outline a complete guide to human pose estimation for machine learning models and video annotation, along with examples of use cases.
What is Human Pose Estimation?
Human Pose Estimation (HPE) and tracking is a computer vision task that’s becoming easier to implement as computational power and resources continue to increase. It takes enormous computational resources and highly-accurate algorithmic models to estimate and track human poses and movements.
Pose estimation involves detecting, associating, and tracking semantic keypoints. Examples of this are keypoints on the human face, such as the corners of the mouth, eyes, and nose. Or elbows and knees. With pose estimation, computer vision machine learning (ML) models let you track, annotate, and estimate movement patterns for humans, animals, and vehicles.

2D Human Pose Estimation
2D human pose estimation estimates the 2D positions, also known as spatial locations of keypoints on a human body in images and videos. Traditional 2D approaches used hand-drawn methods to identify keypoints and extract features.
Early computer vision models reduced the human body to stick figures; think computational rendering of small wooden models that artists use to draw the human body. However, once modern deep machine learning and AI-based algorithms started to tackle the challenges associated with human pose estimation there were significant breakthroughs. We cover more about those models and approaches in more detail in this article.
Examples of 2D Human Pose Estimation
2D pose estimation is still used in video and image analysis of human movement. It’s the underlying theory behind recent advances in ML and AI-based annotation analysis models. 2D human pose estimation is used in healthcare, AI-powered yoga apps, reinforcement learning for robotics, motion capture, augmented reality, athlete pose detection, and so much more.
2D vs 3D Human Pose Estimation
Building on the original 2D approach, 3D human pose estimation predicts and accurately identifies the location of joints and other keypoints in three dimensions (3D). This approach provides extensive 3D structure information for the entire human body. There are numerous applications for 3D pose estimation, such as 3D animation, augmented and virtual reality creation, and action prediction.
Understandably, 3D pose animation is more time-consuming, especially when annotators need to spend more time manually labeling keypoints in 3D. One of the more popular solutions to get around many of the challenges of 3D pose estimation is OpenPose, using neural networks for real-time annotation.
How Does Human Pose Estimation Work?
Pose estimation works when annotators and machine learning algorithms, models, and systems use human poses and orientation and movement to pinpoint and track the location of a person, or multiple people, in an image or video.
In most cases, it’s a two-step framework. First, a bounding box is drawn, and then keypoints are used to identify and estimate the position and movement of joints and other features.
Challenges Of Human Pose Estimation for Machine Learning
Human pose estimation is challenging. We move dynamically, alongside the diversity of clothing, fabric, lighting, arbitrary occlusions, viewing angle, and background. Also, whether there’s more than one person in the video being analyzed, and understanding the dynamic of movement forms between one or more persons or animals.
Pose estimation machine learning algorithms need to be robust enough to account for every possible permutation. Of course, weather and other tracked objects within a video might interact with a person, making human pose estimation even more challenging.
The most common use cases are in sectors where machine learning models are applied to human movement annotation in images and videos. Sports, healthcare, retail, security, intelligence, and military applications are where human pose estimation video and image annotation and tracking are most commonly applied.
Before we get into use cases, let’s take a quick look at the most popular machine learning models deployed in human pose estimation.
Popular Machine Learning Models for Human Pose Estimation
Over the years, dozens of machine learning (ML) algorithmic models have been developed for human pose estimation data sets, including OmniPose, RSN, DarkPose, OpenPose, AlphaPose (RMPE), DeepCut, MediaPipe, and HRNet, alongside several others. New models are evolving all of the time as computational powers and ML/AI algorithms increase in accuracy, as data scientists refine and iterate them constantly.
Before these methods were pioneered, human pose estimation was limited to outlining where a human was in a video or image. It’s taken the advancement of algorithmic models, computational power, and AI-based software solutions to estimate and annotate human body language and movement accurately.
The good news is that it doesn't matter which algorithmic model you normally use with the most powerful and user-friendly machine learning or artificial intelligence (AI) tools. With an AI-based tool such as Encord, any of these models can be applied when annotating and evaluating human pose estimation images and videos.
#1: OmniPose
OmniPose is a single-pass trainable framework for end-to-end multi-person pose estimation. It uses an agile waterfall method with an architecture that leverages multi-scale feature representations that increase accuracy while reducing the need for post-processing.
Contextual information is included, with joint localization using a Gaussian heatmap modulation. OmniPose is designed to achieve state-of-the-art results, especially combined with HRNet (more on that below).
#2: RSN
Residual Steps Network (RSN) is an innovative method that “aggregates features with the same spatial size (Intra-level features) efficiently to obtain delicate local representations, which retain rich low-level spatial information and result in precise keypoint localization.”
This approach uses a Pose Refine Machine (PRM) that balances the trade-off between “local and global representations in output features”, thereby refining keypoint features. RSN won the COCO Keypoint Challenge 2019 and archives state-of-the-art results against the COCO and MPII benchmarks.
#3: DARKPose
DARKPose — Distribution-Aware coordinate Representation of Keypoint (DARK) pose — is a novel approach to improve on traditional heatmaps. DARKPose decodes “predicted heatmaps into the final joint coordinates in the original image space” and implements a “more principled distribution-aware decoding method.” More accurate heatmap distributions are produced, improving human pose estimation model outcomes.
#4: OpenPose
OpenPose is a popular bottom-up machine learning model for real-time multi-person tracking, estimation, and annotation. It’s an open-source algorithm, ideal for detecting face, body, foot, and hand keypoints.
OpenPose is an API that integrates easily with a wide range of CCTV cameras and systems, with a lightweight version ideal for Edge devices.
#5: AlphaPose (RMPE)
Also known as Regional Multi-Person Pose Estimation (RMPE) is a top-down machine learning model for pose estimation annotation. It more accurately detects human poses and movement patterns within bounding boxes. The architecture applies to both single and multi-person poses within images and videos.
#6: DeepCut
DeepCut is another bottom-up approach for detecting multiple people and accurately pinpointing the joints and estimated movement of those joints within an image or video. It was developed for detecting the poses and movement of multiple people and is often used in the sports sector.
#7: MediaPipe
MediaPipe is an open-source “cross-platform, customizable ML solution for live and streaming media”, developed and supported by Google. MediaPipe is a powerful machine learning model designed for face detection, hands, poses, real-time eye tracking, and holistic use. Google provides numerous in-depth use cases on the Google AI and Google Developers Blogs, and even several MediaPipe Meetups happened in 2019 and 2020.
#8: High-Resolution Net (HRNet)
High-Resolution Net (HRNet) is a neural network for pose estimation, created to more accurately find keypoints (human joints) in an image or video. HRNet maintains high-resolution representations for estimating human postures and movements compared to other algorithmic models. Consequently, it’s a useful machine learning model when annotating videos filmed for televised sports games.
MediaPipe vs. OpenPose
Comparing one model against another involves setting up test conditions as accurately and fairly as possible. Hear.ai, a Polish AI/ML educational non-profit, conducted an experiment comparing MediaPipe with OpenPose, testing whether one was better than the other for accurately detecting sign language in a video. You can read about it here.
The accuracy for both was described as “good”, with MediaPipe proving more effective when dealing with blur, objects (hands) in the video changing speed, and overlap/coverage. At some points in the test, OpenPose lost detection completely. Working with OpenPose proved sufficiently challenging — for a number of reasons — that MediaPipe was the clear winner. Other comparisons of the two models come to similar conclusions.
Now let’s take a closer look at how to implement human pose estimation for machine learning video annotation.
How to Implement Human Pose Estimation for Machine Learning Video Annotation
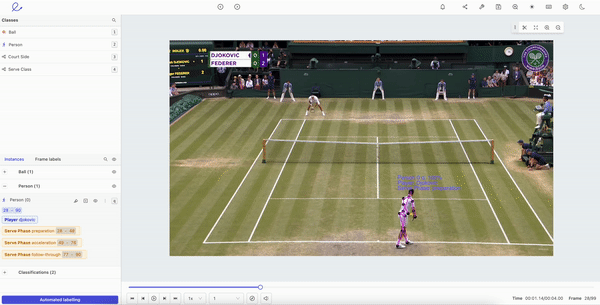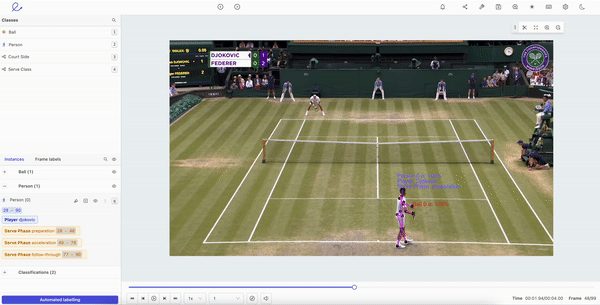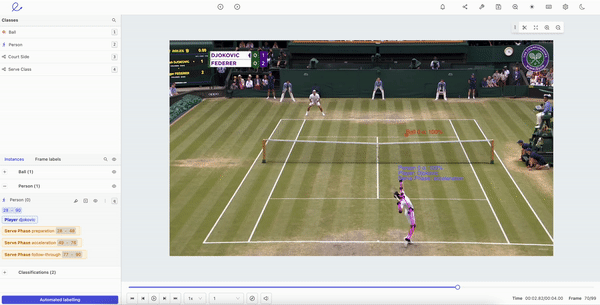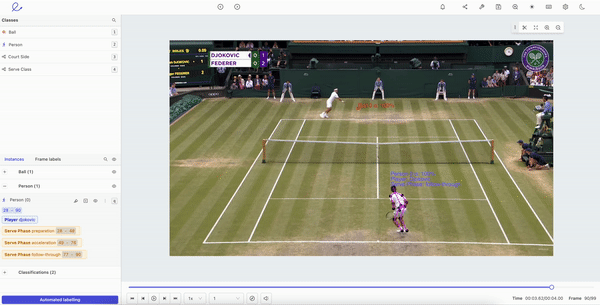
Human Pose Estimation in Encord
Video annotation is challenging enough, with annotators dealing with difficulties such as variable frame rates, ghost frames, frame synchronization issues, and numerous others. To deal with these challenges, you need a video annotation tool that can handle arbitrarily long videos and pre-process videos to reduce frame synchronization issues.
Combine those challenges with the layers associated with human pose estimation — identifying joints, dynamic movement, multiple people, clothes, background, lighting, and weather — and you can see why powerful algorithms and computing power are essential for HPE video annotation.
Consequently, you need a video annotation tool with the following features:
- Easily define object primitives for pose estimation video annotations. For example, annotators can clearly define and draw keypoints wherever they are needed on the human body, such as joints or facial features.
- Define your skeleton template with keypoints in a pose. Once you’ve created a skeleton template, these can be edited and applied to machine learning models. Using Encord’s object tracking features for pose estimation, you can dramatically reduce the manual annotation workload at the start of any project. With a powerful and flexible editing suite, you can reduce the amount of data a model needs while also being able to manually edit labels and keypoints as a project develops.
- Object tracking and pose estimation. With a powerful object-tracking algorithm, the right tool can support a wide range of computer vision modalities. Human movement and body language are accounted for, factoring in all of the inherent challenges of human pose estimation, such as lighting, clothes, background, weather, and tracking multiple people moving in one video.
How to Benchmark Your Pose Estimation Models
One way to benchmark video annotation machine learning models is to use COCO; Common Objects in Context.
“COCO is a large-scale object detection, segmentation, and captioning dataset”, designed for object segmentation, recognition in context, and superpixel object segmentation. It’s an open-source architecture supported by Microsoft, Facebook, and several AI companies.
Researchers and annotators can apply this dataset to detect keypoints in human movement and more accurately differentiate objects in a video in context. Alongside human movement tracking and annotation, COCO also proves useful when analyzing horse racing videos.
Common Mistakes When Doing Human Pose Estimation
Some of the most serious mistakes involve using human pose estimation algorithms and tools on animals. Naturally, animals move in a completely different way to humans, except for those we share the closest amount of DNA with, such as large primates.
However, other more common mistakes involve using the wrong tools. Regardless of the machine learning model being used, with the wrong tool, days or weeks of annotation could be wasted. One or two frame synchronization issues, or needing to break a longer video into shorter ones could cost an annotation team dearly.
Variable frames, ghost frames, or a computer vision tool failing to accurately label key points can negatively impact project outcomes and budgets. Mistakes happen in every video annotation project. As a project leader, minimizing those mistakes with the most effective tool and machine learning model is the best way to achieve the project's goals on schedule and on budget.
Human Pose Estimation Use Cases When Deploying a Machine Learning Video Annotation Tool
Human pose estimation machine learning models and tools are incredibly useful across a wide range of sectors. From sports to healthcare; any sector where staff, stakeholders or annotators need to assess and analyze the impact or expected outcomes of human movement patterns and body language.
HPE machine learning analysis is equally useful in sports analytics, crime-fighting, the military, intelligence, and counter-terrorism. Governments, healthcare organizations, and sports teams regularly use AI and machine learning-based video annotation tools when implementing human pose estimation annotation projects.
Here’s another example of a powerful, life-enhancing use case for machine learning annotation and tracking in the care home sector. It’s an Encord interview with the CTO of Teton AI, a computer vision company designing fall-prevention tools for hospitals and cares homes throughout Denmark. Teton AI used Encord’s SDK to quickly apply the same data for different projects, leveraging Encord’s pose estimation labeling tool to train a much larger model and then apply it in hospitals and care homes.
As you can see, human pose estimation is not without challenges. With the right computer vision, machine learning annotation tool, and algorithmic models, you can overcome those when implementing your next video annotation project.

Frequently asked questions
Encord provides robust annotation tools tailored for autonomous vehicle applications, helping teams manage the complexities of data collection and labeling. Our platform streamlines the process of annotating bounding boxes and tracking information, ensuring that the data is accurately prepared for training models in perception, planning, and control.
Encord provides the capability to utilize up to eight cameras, allowing for multiple viewpoints of the surgical procedure. This is particularly beneficial for manual annotators, as different angles can help disambiguate events and provide a clearer understanding of actions taking place during surgery.
To annotate bounding boxes for jersey numbers in Encord, upload your dataset and create tasks that include the bounding boxes around players. You can then add attributes to each bounding box to specify the jersey number and indicate if it is half occluded or if there is a secondary number present.
Encord facilitates the annotation process by providing tools that streamline data management and curation. Users can either utilize Encord’s internal annotation capabilities or collaborate with external teams to ensure high-quality annotations tailored to specific sports requirements.
Encord's annotation tool is designed to handle multiple camera angles simultaneously, addressing common challenges such as occlusion. Users can perform scene classifications and create bounding boxes efficiently, making it a mature solution for complex annotation tasks.
Encord supports synchronization across multiple camera angles, allowing users to annotate a frame from one camera and infer data for other angles. This unique feature minimizes the annotator's interactions and enhances the efficiency of the annotation process.
Encord offers improved 2D and 3D projection capabilities, ensuring accurate visual alignment between different views. Users can confirm the accuracy of annotations through both bird's eye and 3D point cloud views, addressing common projection discrepancies.
Pose estimation refers to the process of determining the position and orientation of objects in three-dimensional space using depth and RGB images. Encord supports this by providing tools to effectively analyze and annotate data for 3D positioning tasks.
Encord allows users to see synchronized views of the lidar data as they annotate. As users move their cursor in one view, the corresponding position is highlighted in all other views, facilitating a more accurate and intuitive annotation experience.
Encord provides tools to adjust the orientation of vehicles within the annotation editor. Users can manipulate the roll, pitch, and yaw of cuboids, allowing for precise alignment and representation of vehicles in 3D scenes.