Dataset Distillation: Algorithm, Methods and Applications

As the world becomes more connected through digital platforms and smart devices, a flood of data is straining organizational systems’ ability to comprehend and extract relevant information for sound decision-making. In 2023 alone, users generated 120 zettabytes of data, with reports projecting the volume to approach 181 by 2025.
While artificial intelligence (AI) is helping organizations leverage the power of data to gain valuable insights, the ever-increasing volume and variety of data require more sophisticated AI systems that can process real-time data. However, real-time systems are now more challenging to deploy due to the constant streaming of extensive data points from multiple sources.
While several solutions are emerging to deal with large data volumes, dataset distillation is a promising technique that trains a model on a few synthetic data samples for optimal performance by transferring knowledge of large datasets into a few data points.
This article discusses dataset distillation, its methods, algorithms, and applications in detail to help you understand this new and exciting paradigm for model development.
What is Dataset Distillation?
Dataset distillation is a technique that compresses the knowledge of large-scale datasets into smaller, synthetic datasets, allowing models to be trained with less data while achieving similar performance to models trained on full datasets.
This approach was proposed by Wang et al. (2020), who successfully distilled the 60,000 training images in the MNIST dataset into a smaller set of synthetic images, achieving 94% accuracy on the LeNet architecture.
The idea is based on Geoffrey Hinton's knowledge distillation method, in which a sophisticated teacher model transfers knowledge to a less sophisticated student model.
However, unlike knowledge distillation, which focuses on model complexity, dataset distillation involves reducing the training dataset's size while preserving key features for model training.
A notable example by Wang et al. involved compressing the MNIST dataset into a distilled dataset of ten images, demonstrating that models trained on this reduced dataset achieved similar performance to those trained on the full set. This makes dataset distillation a good option for limited storage or computational resources.
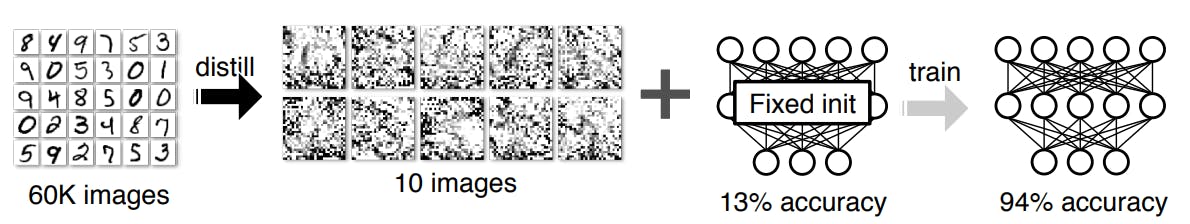
Dataset distillation differs from core-set or instance selection, where a subset of data samples is chosen using heuristics or active learning. While core-set selection also aims to reduce dataset size, it may lead to suboptimal outputs due to its reliance on heuristics, potentially overlooking key patterns.
Dataset distillation, by contrast, creates a smaller dataset that retains critical information, offering a more efficient and reliable approach for model training.
Benefits of Dataset Distillation
The primary advantage of dataset distillation is its ability to encapsulate the knowledge and patterns of a large dataset into a smaller, synthetic one, which dramatically reduces the number of samples required for effective model training. This provides several key benefits:
- Efficient Training: Dataset distillation streamlines the training process, allowing data scientists and model developers to optimize models with fewer training samples. This reduces the computational load and accelerates the training process compared to using the full dataset.
- Cost-effectiveness: The reduced size of distilled data leads to lower storage costs and fewer computational resources during training. This can be especially valuable for organizations with limited resources or those needing scalable solutions.
- Better Security and Privacy: Since distilled datasets are synthetic, they do not contain sensitive or personally identifiable information from the original data. This significantly reduces the risk of data breaches or privacy concerns, providing a safer environment for model training.
- Faster experimentation: The smaller size of distilled datasets allows for rapid experimentation and model testing. Researchers can quickly iterate over different model configurations and test scenarios, speeding up the model development cycle and reducing the time to market.
Dataset Distillation Methods
Multiple algorithms exist to generate synthetic examples from large datasets. Below, we will discuss the four main methods used for distilling data: performance matching, parameter matching, distribution matching, and generative techniques.
- Performance Matching
Performance matching involves optimizing a synthetic dataset so that training a model on this data will give the same performance as training it on a larger dataset. The method by Wang et al. (2020) is an example of performance matching.
- Parameter Matching
Zhao et al. (2021) first introduced the idea of parameter matching for dataset distillation. The method involves training a single network on the original and distilled dataset.
The network optimizes the distilled data by ensuring the training parameters are consistent during the training process.
- Distribution Matching
Distribution matching creates synthetic data with statistical properties similar to those of the original dataset. This method uses metrics like Maximum Mean Discrepancy or Kullback-Leibler (KL) divergence to measure the distance between data distributions and optimize the synthetic data accordingly. By aligning distributions, this method ensures that the synthetic dataset maintains the key statistical patterns of the original data.
- Generative Methods
Generative methods train generative adversarial networks (GANs) to generate synthetic datasets that resemble original data. The technique involves training a generator to get latent factors or embeddings that resemble those of the original dataset.
Additionally, this approach benefits storage and resource efficiency, as users can generate synthetic data on demand from latent factors or embeddings.
Dataset Distillation Algorithm
While the above methods broadly categorize the approaches used for dataset condensation, multiple learning algorithms exist within each approach to obtain distilled data.
Below, we discuss eight algorithms for distilling data and mention the categories to which they belong.
1. Meta-learning-based Method
The meta-learning-based method belongs to the performance-matching category of algorithms. It involves minimizing a loss function, such as cross-entropy, over the pixels between the original and synthetic data samples.
The algorithm uses a bi-level optimization technique. An inner loop uses single-step gradient descent to get a distilled dataset, and the outer loop compares the distilled samples with the original data to compute loss.
It starts by initializing a random set of distilled samples and a learning ratehyperparameter. It also samples a random parameter set from a probability distribution. The parameters represent pixels compared against those of the distilled dataset to minimize loss.

After updating the parameter set using a single gradient-descent step, the algorithm compares the new parameter set with the pixels of the original dataset to compute the validation loss.
The process repeats for multiple training steps and involves backpropagation to update the distilled dataset.
For a linear loss function, Wang et al. (2020) show that the number of distilled data samples should at least equal the number of features for a single sample in the original dataset to obtain the most optimal results.
In computer vision (CV), where features represent each image’s pixels, the research implies that the number of distilled images should equal the number of pixels for a single image.
Zhou et al. (2021) also demonstrate how to improve generalization performance using a Differentiable Siamese Augmentation (DSA) technique. The method applies crop, cutout, flip, scale, rotate, and color jitter transformations to raw data before using it for synthesizing new samples.
2. Kernel Ridge Regression-Based Methods
The meta-learning-based method can be inefficient as it backpropagates errors over the entire training set. It makes the technique difficult to scale since performing the outer loop optimization step requires significant GPU memory.
The alternative is kernel ridge regression (KRR), which performs convex optimization using a non-linear network architecture to avoid the inner loop optimization step. The method uses the neural tangent kernel (NTK) to optimize the distilled dataset.
NTK is an artificial neural network kernel that determines how the network converts input to output vectors. For a wide neural net, the NTK represents a function after convergence, representing how a neural net behaves during training.
Since NTK is a limiting function for wide neural nets, the dataset distilled using NTK is more robust and approximates the original dataset more accurately.
3. Single-step Parameter Matching
In single-step parameter matching—also called gradient matching—a network trains on the distilled and original datasets in a single step. The method matches the resulting gradients after the update step, allowing the distilled data to match the original samples closely.
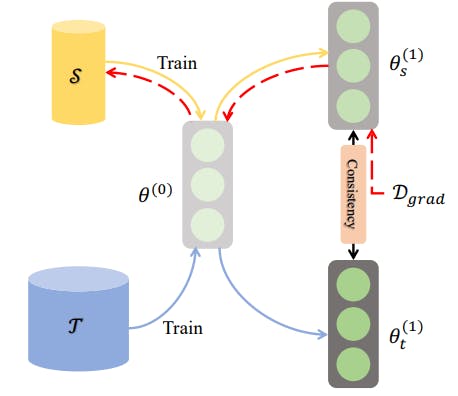
Single-step parameter matching
After updating the distilled dataset after a single training step, the network re-trains on the updated distilled data to re-generate gradients. Using a suitable similarity metric, a loss function computes the distance between the distilled and original dataset gradients.
Lee et al. (2022) improve the method by developing a loss function that learns class-discriminative features. They average the gradients over all classes to measure distance.
A problem that often occurs with gradient matching is that a particular network’s parameters tend to overfit synthetic data due to its small size.
Kim et al. (2022) propose a solution that optimizes using a network trained on the original dataset. The method trains a network on the larger original dataset and then performs gradient matching using synthetic data.
Zhang et al. (2022) also use model augmentations to create a pool of models with weight perturbations. They distill data using multiple models from the pool to obtain a highly generalized synthetic dataset using only a few optimization steps.
4. Multi-step Parameter Matching
Multi-step parameter matching—also called matching training trajectories (MTT)—trains a network on synthetic and original datasets for multiple steps and matches the final parameter sets.
The method is better than single-step parameter matching, which ignores the errors that may accumulate further in the process where the network trains on synthetic data. By minimizing the loss between the end results, MTT ensures consistency throughout the entire training process.
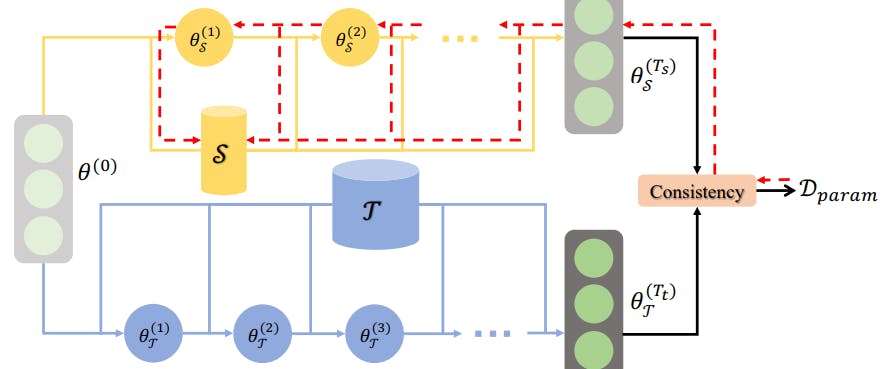
It also includes a normalization step, which improves performance by ensuring the magnitude of the parameters across different neurons during the later training epochs does not affect the similarity computation.
An improvement involves removing parameters that are difficult to match from the loss function if the similarity between the parameters of the original and distilled dataset is below a certain threshold.
5. Single-layer Distribution Matching
Single-layer distribution matching optimizes a distilled dataset by ensuring the embeddings of synthetic and original datasets are close.
The method uses the embeddings generated by the last linear layer before the output layer. It involves minimizing a metric measuring the distance between the embedding distributions.
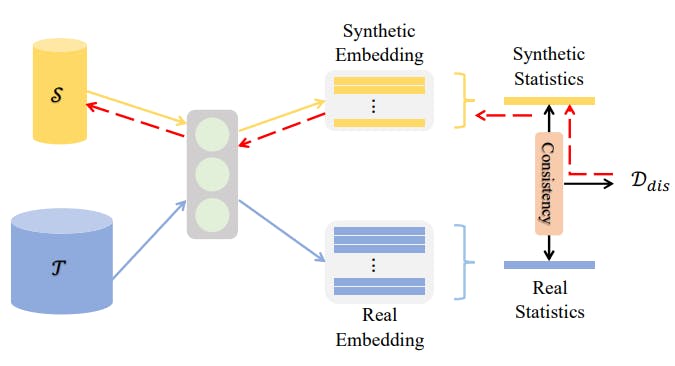
Single-layer Distribution Matching
Using the mean vector of embeddings for each class is a straightforward method for ensuring that synthetic data retains the distributional features of the original dataset.
6. Multi-layer Distribution Matching
Multi-layer distribution matching enhances the single-layer approach by extracting features from real and synthetic data from each layer in a neural network except the last. The objective is to match features in each layer for a more robust representation.
In addition, the technique uses another classifier function to learn discriminative features between different classes. The objective is to maximize the probability of correctly detecting a specific class based on the actual data sample, synthetic sample, and mean class embedding.
The technique combines the discriminative loss and the loss from the distance function to compute an overall loss to update the synthetic dataset.
7. GAN Inversion
Zhao et al. (2022) use GAN inversion to get latent factors from the real dataset and use the latent feature to generate synthetic data samples.
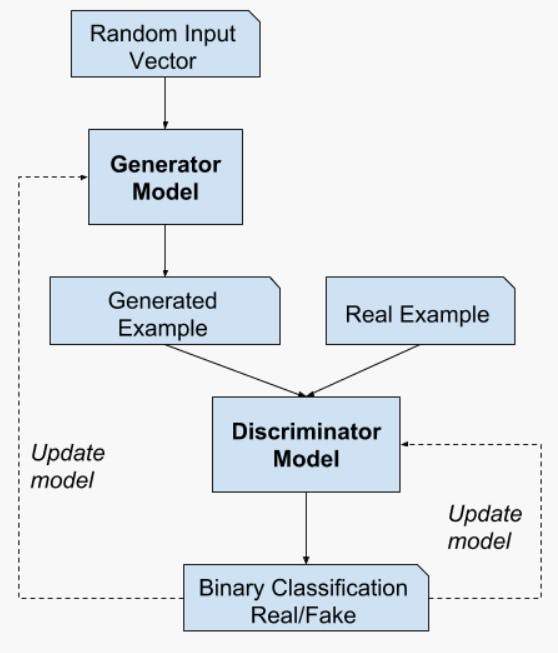
The generator used for GAN inversion is a pre-trained network that the researchers initialize using the latent set representing real images.
Next, a feature extractor network computes the relevant features using real images and synthetic samples created using the generator network.
Optimization involves minimizing the distance between the features of real and synthetic images to train the generator network.
8. Synthetic Data Parameterization
Parameterizing synthetic data helps users store data more efficiently without losing information in the original data. However, a problem arises when users consider storing synthetic data in its raw format.
If storage capacity is limited and the synthetic data size is relatively large, preserving it in its raw format could be less efficient. Also, storing only a few synthetic data samples may result in information loss..
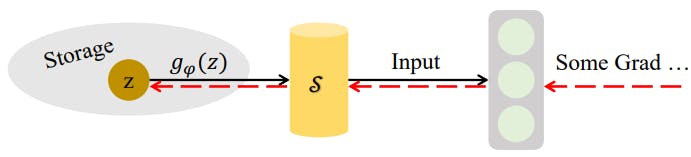
Synthetic Data Parameterization
The solution is to convert a sufficient number of synthetic data samples into latent features using a learnable differentiable function. Once learned, the function can help users re-generate synthetic samples without storing a large synthetic dataset.
Deng et al. (2022) propose Addressing Matrices that learn representative features of all classes in a dataset. A row in the matrix corresponds to the features of a particular class.
Users can extract a class-specific feature from the matrix and learn a mapping function that converts the features into a synthetic sample. They can also store the matrix and the mapping function instead of the actual samples.
Performance Comparison of Data Distillation Methods
Liu et al. (2023) report a comprehensive performance analysis of different data distillation methods against multiple benchmark datasets. The table below reports their results.
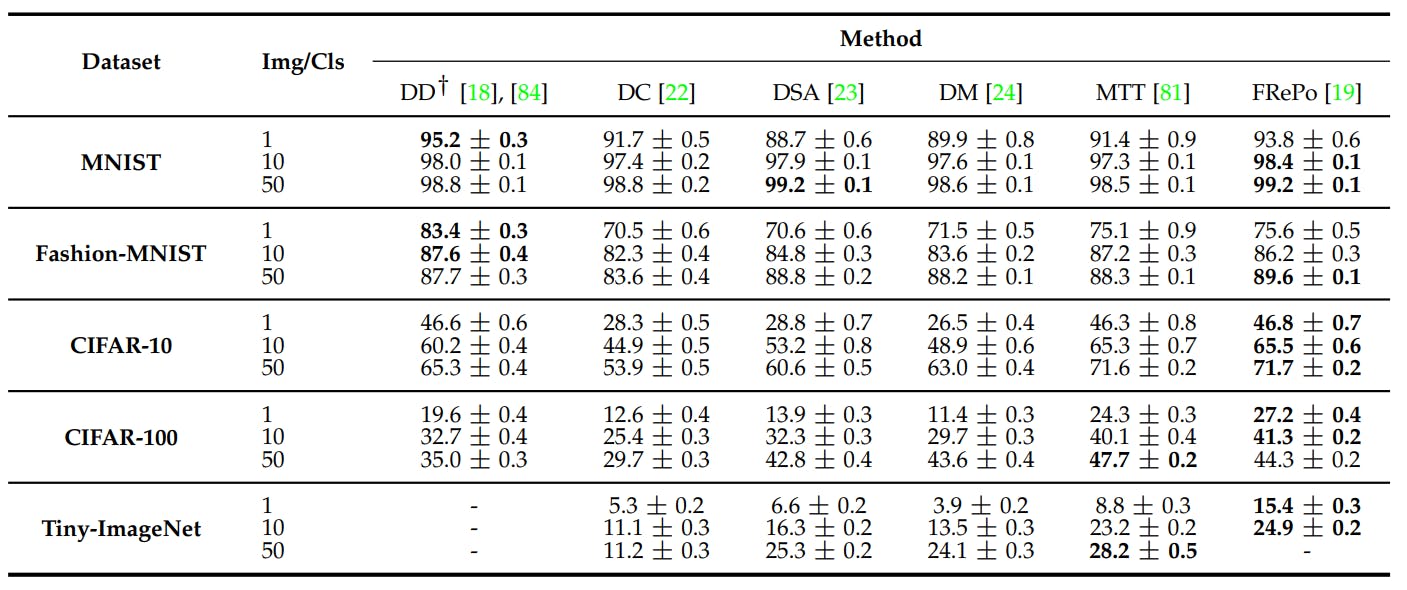
FRePO performs highly on MNIST and Fashion-MNIST and has state-of-the-art performance on CIFAR-10, CIFAR-100, and Tiny-ImageNET.
Dataset Distillation Applications
Since dataset distillation reduces data size for optimal training, the method helps with multiple computationally intensive tasks.
Below, we discuss seven use cases for data distillation, including continual and federated learning, neural architecture search, privacy and robustness, recommender systems, medicine, and fashion.
Continual Learning
Continual learning (CL) trains machine learning models (ML models) incrementally using small batches from a data stream. Unlike traditional supervised learning, the models cannot access previous data while learning patterns from the new dataset.
This leads to catastrophic forgetting, where the model forgets previously learned knowledge. Dataset distillation helps by synthesizing representative samples from previous data.
These distilled samples act as a form of "memory" for the model, often used in techniques like knowledge replay or pseudo-rehearsal. They ensure that past knowledge is retained while training on new information.
Federated Learning
Federated learning trains models on decentralized data sources, like mobile devices. This preserves privacy, but frequent communication of model updates between devices and the central server incurs high bandwidth costs.
Dataset distillation offers a solution by generating smaller synthetic datasets on each device, which represent the essence of the local data. Transmitting these distilled datasets for central model aggregation reduces communication costs while maintaining performance.
Neural Architecture Search (NAS)
NAS is a method to find the most optimal network from a large pool of networks.
This process is computationally expensive, especially with large datasets, as it involves training many candidate architectures.
Dataset distillation provides a faster solution. By training and evaluating models on distilled data, NAS can quickly identify promising architectures before a more comprehensive evaluation of the full dataset.
Privacy and Robustness
Training a network on distilled can help prevent data privacy breaches and make the model robust to adversarial attacks.
Dong et al. (2022) show how data distillation relates to differential privacy and how synthetic data samples are irreversible, making it difficult for attackers to extract real information.
Similarly, Chen et al. (2022) demonstrate that dataset distillation can help generate high-dimensional synthetic data to ensure differential privacy and low computation costs.
Recommender Systems
Recommender systems use massive datasets generated from user activity to offer personalized suggestions in multiple domains, such as retail, entertainment, healthcare, etc.
However, the ever-increasing size of real datasets makes these systems suffer from high latency and security risks.
Dataset distillation provides a cost-effective solution as the system can use a small synthetic dataset to generate accurate recommendations.
Also, distillation can help quickly fine-tune large language models (LLMs) used in modern recommendation frameworks using synthetic data samples instead of the entire dataset.
Medicine
Anonymization is a critical requirement when processing medical datasets. Dataset distillation offers an easy solution by allowing experts to use synthetic medical images that retain the knowledge from the original dataset while ensuring data privacy.
Li et al. (2022) uses performance and parameter matching to create synthetic datasets. They also apply label distillation, which involves using soft labels instead of one-hot vectors for each class.
Fashion
Distilled image samples often have unique, aesthetically pleasing patterns that designers can use on clothing items.
Cazenavette et al. (2022) use data distillation on an image dataset to generate synthetic samples with exotic textures for use in clothing designs.

Similarly, Chen et al. (2022) use dataset distillation to develop a fashion compatibility model that extracts embeddings from designer and user-generated clothing items through convolutional networks.
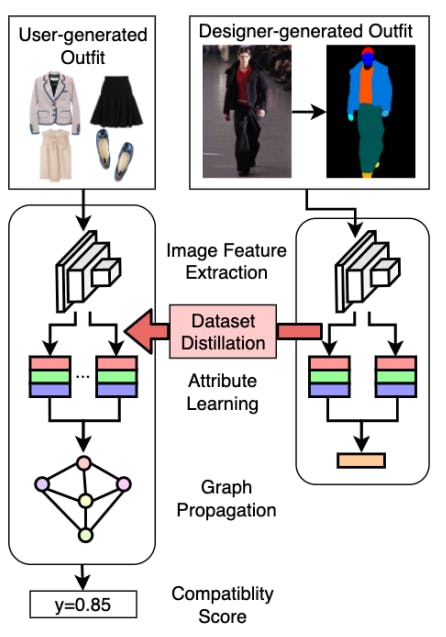
The model learns embeddings from clothing images using uses dataset distillation to obtain relevant features. They also use and employs an attention-based mechanism to measure the compatibility of designer items with user-generated fashion trends.
Dataset Distillation: Key Takeaways
Dataset distillation is an evolving research field with great promise for using AI in multiple industrial domains such as healthcare, retail, and entertainment.
Below are a few key points to remember regarding dataset distillation.
- Data vs. Knowledge Distillation: Dataset distillation maps knowledge in large datasets to small synthetic datasets, while knowledge distillation trains a small student model using a more extensive teacher network.
- Data Distillation Methods: The primary distillation methods involve parameter matching, performance matching, distribution matching, and generative processes.
- Dataset Distillation Algorithms: Current algorithms include meta-based learning, kernel ridge regression, gradient matching, matching training trajectories, single and multi-layer distribution matching, and GAN inversion.
- Dataset Distillation Use Cases: Dataset distillation significantly improves continual and federated learning frameworks, neural architecture search, recommender systems, medical diagnosis, and fashion-related tasks.
Frequently asked questions
Dataset distillation compresses large datasets into smaller synthetic data samples that retain the same knowledge as the original data.
By reducing data size while preserving the knowledge of large datasets, dataset distillation lowers storage costs, improves training efficiency, and provides more security.
Primary challenges include generating synthetic data that performs well on diverse network architectures, finding the optimal compression ratio, and scaling up to solve more complex ML tasks, including segmentation, object detection, and summarization.
No. Dataset distillation involves compressing the knowledge in large datasets into smaller synthetic datasets, while knowledge distillation compresses the knowledge in a large teacher model into a smaller student model.
Performance, parameter, and distribution matching are popular dataset distillation methods.
Yes, Encord is designed to handle complex workflows and supports various data modalities. This flexibility ensures that users can manage larger datasets and incorporate different types of information without needing to switch to another platform, making it a one-stop solution for data management.
Encord offers robust tools designed to streamline dataset management and facilitate smoother experiment runs. These tools help teams analyze experimental results effectively, ensuring that organizations can optimize their machine learning models and enhance overall operational efficiency.
Encord offers improved workflow management capabilities that facilitate the entire data lifecycle—from ingestion to annotation and review. Users can efficiently manage the flow of data, ensuring that the process of sending data to annotators and receiving it back is seamless.
Encord provides best-in-class curation capabilities that allow users to filter datasets through various methods, including metadata search and natural language search. This enables teams to drill down and focus on specific files or videos that are essential for annotation.
Uploading datasets in Encord is straightforward. You can set environment variables to organize your data and ensure it is placed correctly within your project structure. Once uploaded, you can create tasks and start annotating your images using the platform's features.
Encord streamlines data management by providing a comprehensive platform that allows users to efficiently curate, index, and manage their datasets. This eliminates the need for moving data across different platforms and enhances the overall annotation workflow.
Encord supports data ingestion from cloud storage, allowing users to manage annotation projects efficiently. The platform enables the import of various file types, facilitating a smooth transition from data collection to project setup and annotation.
Encord provides a comprehensive platform for dataset curation, allowing teams to create and slice datasets easily. Users can prioritize the most interesting data for annotation and fine-tuning, streamlining the entire dataset creation process.
Yes, Encord can connect to both local data repositories and cloud storage services such as AWS. We utilize signed URLs to access your data without taking physical copies, ensuring a secure and efficient integration.