The Full Guide to Foundation Models

Product Manager at Encord
Foundation models are massive AI-trained models that use huge amounts of data and computational resources to generate anything from text to images. Some of the most popular examples of foundation models include GANs, LLMs, VAEs, & Multimodal, powering well-known tools such as ChatGPT, DALLE-2, Segment Anything, and BERT.
Foundation models are large-scale AI models trained unsupervised on vast amounts of unlabeled data.
The outcome are models that are incredibly versatile and can be deployed for numerous tasks and use cases, such as image classification, object detection, natural language processing, speech-to-text software, and the numerous AI tools that play a role in our everyday lives and work.
Artificial intelligence (AI) models and advances in this field are accelerating at an unprecedented rate. Only recently, a German artistic photographer, Boris Eldagsen, won a prize in the creative category of the Sony World Photography Awards 2023 for his picture, “PSEUDOMNESIA: The Electricia.”
In a press release, the awards sponsor, Sony, described it as “a haunting black-and-white portrait of two women from different generations, reminiscent of the visual language of 1940s family portraits.”
Shortly after winning, Eldagsen rejected the award, admitting the image was AI-generated.
Foundation models aren’t new. But their contribution to generative AI software and algorithms are starting to make a massive impact on the world. Is this image a sign of things to come and the massive potential impact of foundation models and generative AI?


An award-winning AI-generated image: A sign of things to come and the power of foundation models?
(Source)
In this article, we go in-depth on foundation models, covering the following:
- What are foundation models?
- 5 AI principles behind foundation models
- Different types of foundation models (e.g., GANs, LLMs, VAEs, Multimodal, and Computer Vision, etc.)
- Use cases, evolution, and metrics of foundation models;
- And how you can use foundation models in computer vision.
Let’s dive in . . .
What are Foundation Models?
The term “Foundation Models” was coined by The Stanford Institute for Human-Centered Artificial Intelligence's (HAI) Center for Research on Foundation Models (CRFM) in 2021. The CRFM was born out of Stanford’s HAI Center and brought together 175 researchers across 10 Stanford departments.
It’s far from the only academic institution conducting research into foundation models, but as the concept originated here, it’s worth noting the way foundation models were originally described.
CRFM describes foundation models as “any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks.” For more information, their paper, On The Opportunities and Risks of Foundation Models, is worth reading.
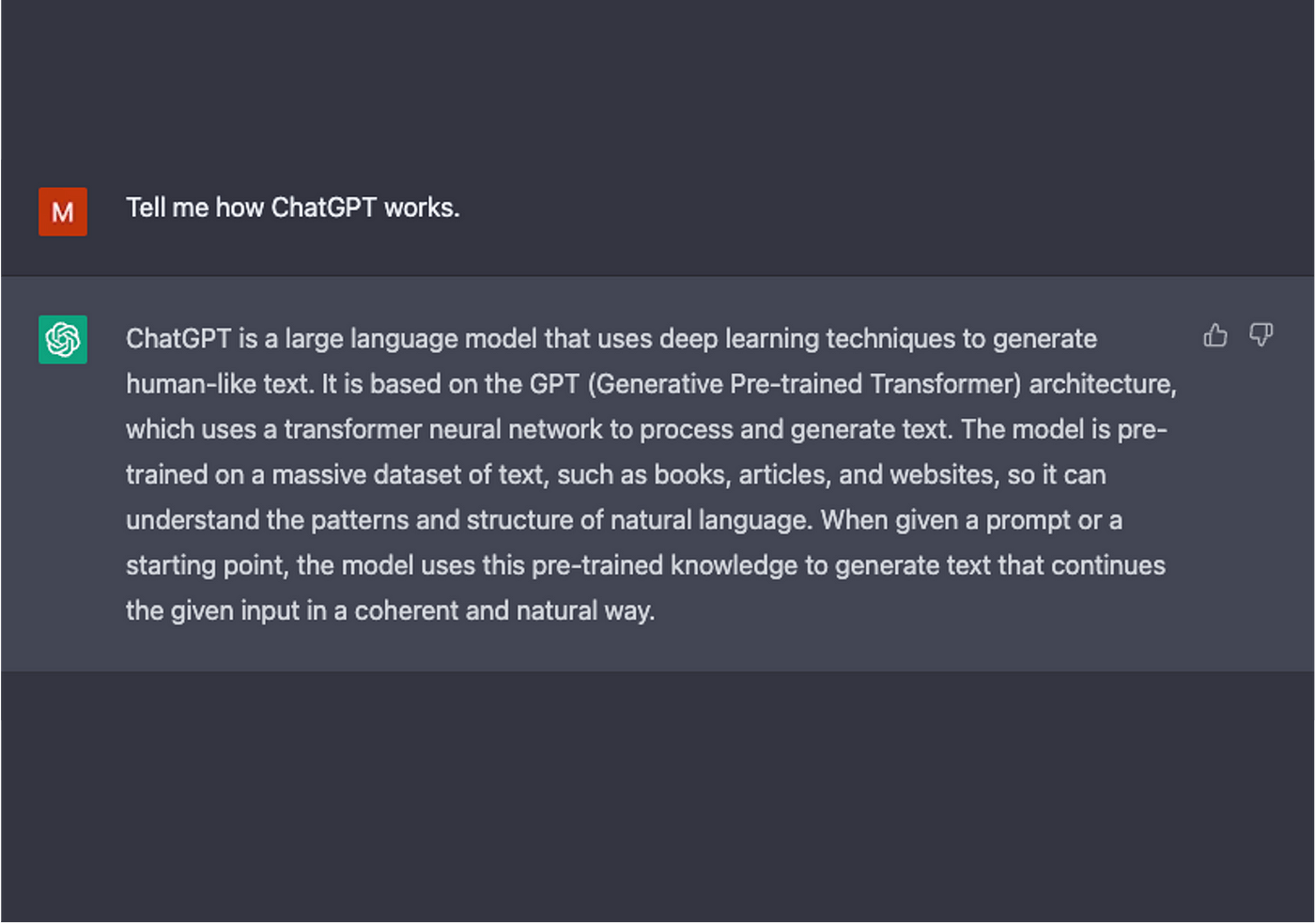
Percy Lang, CRFM’s Director and a Stanford associate professor of computer science, says, “When we hear about GPT-3 or BERT, we’re drawn to their ability to generate text, code, and images, but more fundamentally and invisibly, these models are radically changing how AI systems will be built.”
In other words, GPT-3 (now V4), BERT, and numerous others are examples and types of foundation models in action.
Let’s explore the five core AI principles behind foundation models, use cases, types of AI-based models, and how you can use foundation models for computer vision use cases.
5 AI principles behind foundation models
Here are the five core AI principles that make foundation models possible.
Pre-trained on Vast Amounts of Data
Foundation models, whether they’ve been fine-tuned, or are open or closed, are usually pre-trained on vast amounts of data.
Take GPT-3, for example, it was trained on 500,000 million words, that’s 10 human lifetimes of nonstop reading! It includes 175 billion parameters, 100x more than GPT-3 and 10x more than other comparable LLMs.
That’s A LOT of data and parameters required to make such a vast model work. In practical terms, you need to be very well-funded and resourced to develop foundation models.
Once they’re out in the open, anyone can use them for countless commercial or open-source scenarios and projects. However, the development of these models involves enormous computational processing power, data, and the resources to make it possible.
Self-supervised Learning
In most cases, foundation models operate on self-supervised learning principles. Even with millions or billions of parameters, data and inputs are provided without labels. Models need to learn from the patterns in the data and generate responses/outputs from that.
Overfitting
During the pre-training and parameter development stage, overfitting is an important part of creating foundation models. In the same way that Encord uses overfitting in the development of our computer vision micro-models.
Fine-tuning and Prompt Engineering (Adaptable)
Foundation models are incredibly adaptable. One of the reasons this is possible is the work that goes into fine-tuning them and prompt engineering. Not only during the development and training stages but when a model goes live, prompts enable transfer learning at scale.
The models are continuously improving and learning based on the prompts and inputs from users, making the possibilities for future development even more exciting.
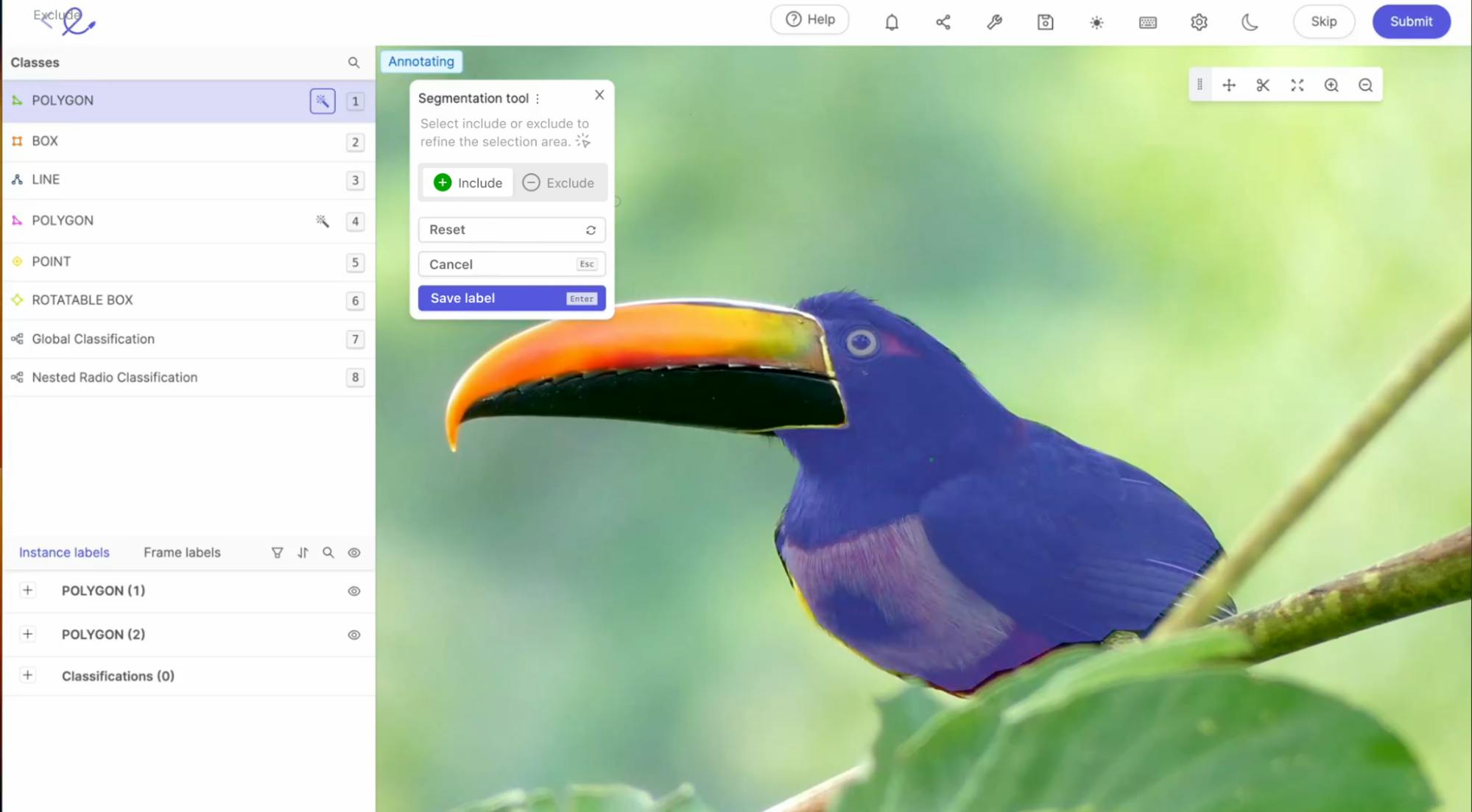
For more information, check out our post on SegGPT: Segmenting everything in context [Explained].
Generalized
Foundation models are generalized in nature. Because the majority of them aren’t trained on anything specific, the data inputs and parameters have to be as generalized as possible to make them effective.
However, the nature of foundation models means they can be applied and adapted to more specific use cases as required. In many ways, making them even more useful for dozens of industries and sectors.
With that in mind, let’s consider the various use cases for foundation models . . .
Use Cases for Foundation Models
There are hundreds of use cases for foundation models, including image generation, natural language processing (NLP), text-to-speech, generative AI applications, and numerous others.
OpenAI’s ChatGPT (including the newest iteration, Version 4), DALL-E 2, and BERT, a Google-developed NLP-based masked-language model, are two of the most widely talked about examples of foundation models.
And yet, as exciting and talked about as these are, there are dozens of other use cases and types of foundation models. Yes, these foundation models capable of generative AI downstream tasks, like creating marketing copy and images, are an excellent demonstration of outputs.
However, data scientists can also train foundation models for more specialized tasks and use cases. Foundation models can be trained on anything from healthcare tasks to self-driving cars and weapons and analyzing satellite imagery.
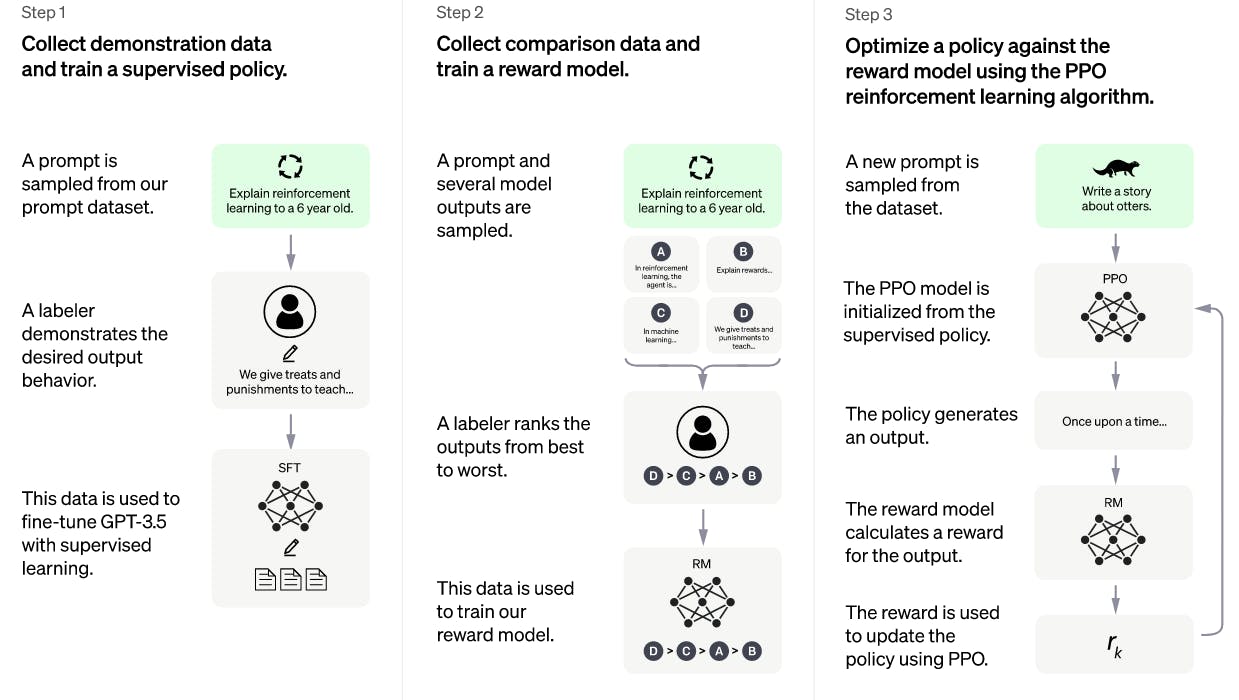
Types of Foundation Models
There are numerous different types of foundation models, including generative adversarial networks (GANs), variational auto-encoders (VAEs), transformer-based large language models (LLMs), and multimodal models.
Of course, there are others, such as variational auto-encoders (VAEs). But for the purposes of this article, we’ll explore GANs, multimodal, LLMs, and computer vision foundation models.
Computer Vision Foundation Models
Computer vision is one of many AI-based models. Dozens of different types of algorithmically-generated models are used in computer vision, and foundation models are one of them.
Examples of Computer Vision Foundation Models
One example of this is Florence, “a computer vision foundation model aiming to learn universal visual-language representations that be adapted to various computer vision tasks, visual question answering, image captioning, video retrieval, among other tasks.”
Florence is pre-trained in image description and labeling, making it ideal for computer vision tasks using an image-text contrastive learning approach.
Multimodal Foundation Models
Multimodal foundation models combine image-text pairs as the inputs and correlate the two different modalities during their pre-training data stage. This proves especially useful when attempting to implement cross-modal learning for tasks, making strong semantic correlations between the data a multimodal model is being trained on.
Examples of Multimodal Foundation Models
An example of a multimodal foundation model in action is Microsoft’s UniLM, “a unified pre-trained language model that reads documents and automatically generates content.”
Microsoft’s Research Asia unit started working on the problem of Document AI (synthesizing, analyzing, summarizing, and correlating vast amounts of text-based data in documents) in 2019. The solution the team came up with combined CV and NLP models to create LayoutLM and UniLM, pre-trained foundation models that specialize in reading documents.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a type of foundation model involving two neural networks that contest and compete against one another in a zero-sum game. One network's gain is the other’s loss. GANs are useful for semi-supervised, supervised, and reinforcement learning. Not all GANs are foundation models; however, there are several that fit into this category.
An American computer scientist, Ian Goodfellow, and his colleagues came up with the concept in 2014.
Examples of GANs
Generative Adversarial Networks (GANs) have numerous use cases, including creating images and photographs, synthetic data creation for computer vision, video game image generation, and even enhancing astronomical images.

Transformer-Based Large Language Models (LLMs)
Transformer-Based Large Language Models (LLMs) are amongst the most widely-known and used foundation models. A transformer is a deep learning model that weighs the significance of every input, including the recursive output data.
A Large Language Model (LLM) is a language model that consists of a neural network with many parameters, trained on billions of text-based inputs, usually through a self-supervised learning approach. Combining an LLM and a transformer gives us transformer-based large language models (LLMs).
And there are numerous examples and use cases, as many of you know and probably already benefit from deploying in various workplace scenarios every day.

Examples of LLMs
Some of the most popular LLMs include OpenAI’s ChatGPT (including the newest iteration, Version 4), DALL-E 2, and BERT (an LLM created by Google).
BERT stands for “Bidirectional Encoder Representations from Transformers” and actually pre-dates the concept of foundation models by several years.
Whereas the “Chat” in OpenAI’s ChatGPT stands for “Generative Pre-trained Transformer.” Microsft was so impressed by ChatGPT-3’s capabilities that it made a significant investment in OpenAI and is now integrating its foundation model technology with its search engine, Bing.
Google is making similar advances, using AI-based LLMs to enhance their search engine with a feature known as Bard. AI is about to shape the future of search as we know it.
As you can see, LLMs (whether transformer-based or not) are making a significant impact on search engines and people’s abilities to use AI to generate text and images with only a small number of prompts.
At Encord, we’re always keen to learn, understand, and use new tools, especially AI-based ones. Here’s what happened when we employed ChatGPT as an ML engineer for a day!
Evaluation Metrics of Foundation Models
Foundation models are evaluated in a number of ways, most of which fall into two categories: intrinsic (a model's performance set against tasks and subtasks) and extrinsic evaluation (how a model performs overall against the final objective).
Different foundation models are measured against performance metrics in different ways; e.g., a generative model will be evaluated on its own basis compared to a predictive model.
On a high-level, here are the most common metrics used to evaluate foundation models:
- Precision: Always worth measuring. How precise or accurate is this foundation model? Precision and accuracy are KPIs that are used across hundreds of algorithmically-generated models.
- F1 Score: Combines precision and recall, as these are complementary metrics, producing a single KPI to measure the outputs of a foundation model.
- Area Under the Curve (AUC): A useful way to evaluate whether a model can separate and capture positive results against specific benchmarks and thresholds.
- Mean Reciprocal Rank (MRR): A way of evaluating how correct or not a response is compared to the query or prompt provided.
- Mean Average Precision (MAP): A metric for evaluating retrieval tasks. MAP calculates the mean precision for each result received and generated.
- Recall-Oriented Understudy for Gisting Evaluation (ROUGE): Measures the recall of a model’s performance, used for evaluating the quality and accuracy of text generated. It’s also useful to check whether a model has “hallucinated”; come up with an answer whereby it’s effectively guessing, producing an inaccurate result.
There are numerous others. However, for ML engineers working on foundation models or using them in conjunction with CV, AI, or deep learning models, these are a few of the most useful evaluation metrics and KPIs.
How to Use Foundation Models in Computer Vision
Although foundation models are more widely used for text-based tasks, they can also be deployed in computer vision. In many ways, foundation models are contributing to advances in computer vision, whether directly or not.
More resources are going into AI model development, and that has a positive knock-on effect on computer vision models and projects.
More directly, there are foundation models specifically created for computer vision, such as Florence. Plus, as we’ve seen, GAN foundation models are useful for creating synthetic data and images for computer vision projects and applications.
Foundation Models Key Takeaways
Foundation models play an important role in contributing to the widescale use and adoption of AI solutions and software in organizations of every size.
With an impressive range of use cases and applications across every sector, we expect that foundation models will encourage the uptake of other AI-based tools.
Foundation models, such as generative AI tools are lowering the barrier to entry for enterprise to start adopting AI tools, such as automated annotation and labeling platforms for computer vision projects.
A lot of what’s being done now wasn’t possible, thanks to AI platforms, demonstrating the kind of ROI organization’s can expect from AI tools.
Ready to scale and make your computer vision model production-ready?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
- Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
- Join the Slack community to chat and connect.
Frequently asked questions
Nested ontologies in Encord allow for the organization of annotation classes in a structured manner, enabling users to define mandatory and optional subcategories. This flexibility helps in managing complex classifications, such as different types of blemishes in materials, without overwhelming the annotation process.
Encord provides a comprehensive platform that consolidates various aspects of model development, from data creation to evaluation and experiment tracking. This allows teams to manage multiple projects in one common workflow, reducing confusion and ensuring consistency across different initiatives.
Encord assists organizations in transitioning to a federated model by providing a robust annotation platform that adapts to diverse operational structures. This support includes tools that enable businesses to maintain autonomy while still benefiting from shared knowledge and best practices.
In Encord, user access and project management are streamlined through an admin portal. Admins can add users to their organization, manage project settings, and control access to specific datasets, ensuring that team members have the appropriate permissions to collaborate effectively.
Yes, Encord is designed to handle flexible annotation schemas and ontologies, allowing users to create and manage structured data that fits their specific project needs. This flexibility is vital for accommodating diverse use cases and ensuring comprehensive data representation.
Encord allows for flexible workforce management by providing tools that can be easily adapted to changing project demands. This flexibility is crucial for companies needing to scale their workforce up and down based on the volume and complexity of model training tasks.
Encord's platform is built around three core pillars: curation, annotation, and model evaluation. These pillars work together to enhance the workflow of AI organizations, enabling them to maximize the value of their data and improve the performance of their models.
Yes, Encord is well-suited for organizations that operate through partnership models. The platform can be tailored to support various commercial structures, allowing partners to leverage Encord’s capabilities while minimizing risk.
No, users can create a master ontology in Encord that can be reused across multiple projects. This approach simplifies the setup process and allows for consistent scoring functions and review flows across different campaigns.