Meta Training Inference Accelerator (MTIA) Explained

Product Manager at Encord
Meta AI unveils new AI chip MTIA
The metaverse is dead; long live AI–
In the ever-evolving landscape of artificial intelligence, Meta and Mark Zuckerberg have maybe once again raised the bar with their new AI chip, “Meta Training and Inference Accelerator,” or MTIA.
The MTIA Chip shows marginal improvements in efficiency for simple low- and medium-complexity inference applications. While it currently lags behind GPUs for complex tasks. Meta is, however, planning to match GPU performance through software optimization later down the line.
. MTIA is Meta’s first in-house silicon chip, which was announced on the 18th of May during the AI Infra @ Scale event.
 “AI Workloads are growing at a pace of a thousand x every 2 years”
“AI Workloads are growing at a pace of a thousand x every 2 years”- Alexis Bjorlin, VP of Engineering/infrastructure.
Innovation is at the heart of Meta's mission, and their latest offering, MTIA, is a testament to that commitment. Metaverse was perhaps a big mistake, but maybe AI can help revive it. Building AI infrastructure feels, in the current macroeconomic environment, like the right choice for Meta.
In this explainer, you will learn:
- What is an AI Chip, and how do they differ from normal chips?
- What is MTIA, why was it built, and what is the chip's architecture?
- The performance of MTIA
- Other notable Meta announcements and advancements.
Let’s dive in!

Introduction to AI Chips
In the ever-evolving landscape of artificial intelligence, computational power, and efficiency is as critical as ever. As companies, especially BigAI (OpenAI, Google, Meta, etc.), push the boundaries of what AI models can do, the need for specialized hardware to efficiently run these complex computations is clear. Enter the realm of AI chips.
What is an AI Accelerator?
An AI accelerator (or AI chip), is a class of microprocessors or computer systems on a chip (SoC) designed explicitly to accelerate AI workloads. Unlike traditional processors that are designed for a broad range of tasks, AI chips are tailored to the specific computational and power requirements of AI algorithms and tasks, such as training deep learning models or making real-time inferences from trained models.
AI chips are built to handle the unique computational requirements of AI applications, including high volumes of matrix multiplications and concurrent calculations. They are equipped with specialized architectures that optimize data processing for AI workloads, reducing latency and boosting overall performance. In essence, AI chips help turn the potential of AI into a reality by providing the necessary computational power to handle complex AI tasks efficiently and effectively.
Examples of AI chips include Google's Tensor Processing Units (TPUs) and NVIDIA's A100 Tensor Core GPU. These chips perform the kind of parallel computations common in AI workloads, such as matrix multiplications and convolutions, which are used extensively in deep learning models.

NVIDIA A100, the $10,000 chip powering the AI race. Image from NVIDIA
Elsewhere Amazon provides its AWS customers with proprietary chips for training (Trainium) and for inference (Inferentia), and Microsoft is said to be collaborating with AMD to develop their own AI chip called Athena, aiming to enhance their in-house AI capabilities after the Investment in OpenAI. Apple has also added AI acceleration into its own M1 chips, and Tesla and Elon Musk are following along with the Tesla D1 AI chip!
How is an AI Chip different from a normal chip?
While conventional CPUs and GPUs have been the workhorses of early ML computation, they're not always the most efficient tools for the job.
- Traditional CPUs: A versatile chip, but not well-suited to the high degree of parallelism that AI computations require.
- GPUs: Were initially designed for rendering graphics, but their design allowed for a higher degree of parallel computation and has powered ML computation in the last decade. However, they still carry legacy features intended for graphics processing, not all of which are useful for AI.
AI chips, on the other hand, are purpose-built to handle AI workloads. They are architected to perform a high volume of concurrent operations, often using lower-precision arithmetic. It is typically sufficient for AI workloads and allows for more computations per watt of power by minimizing memory pressure and bringing the data closer to the computation. Furthermore, many AI chips are designed with specific hardware features for accelerating AI-related tasks.
For instance, Google's TPUs have a large matrix multiplication unit at their core, enabling them to perform the kind of computations prevalent in deep learning at high speed.
What is the Meta Training Inference Accelerator (MTIA) Chip
MTIA is designed by Meta to handle their AI workloads more efficiently. The chip is a custom Application-Specific Integrated Circuit (ASIC) built to improve the efficiency of Meta's recommendation systems.
💡Tip: Content understanding, Facebook Feeds, generative AI, and ads ranking all rely on deep learning recommendation models (DLRMs), and these models demand high memory and computational resources. 
The MTIA Chip on a sample test board. Source
Benefits and Purpose of MTIA
MTIA was built as a response to the realization that GPUs were not always the optimal solution for running Meta's specific recommendation workloads at the required efficiency levels.
The MTIA chip is part of a full-stack solution that includes silicon, PyTorch, and recommendation models; all co-designed to offer a wholly optimized ranking system for Meta’s customers.
MTIA Specs
The first-generation MTIA ASIC was designed in 2020 specifically for Meta's internal workloads. The chip was fabricated using the TSMC 7nmœ process and runs at 800 MHz, providing 102.4 TOPS at INT8 precision and 51.2 TFLOPS at 16-bit floating-point precision. It also features a thermal design power (TDP) of 25 W.

The architecture of MTIA
As an introduction, we will cover four of the key components. There are a lot more too it and we recommend you to check out the full post and video if interested.
- Processing Elements
- Memory Hierarchy
- Interconnects
- Power and Thermal Management
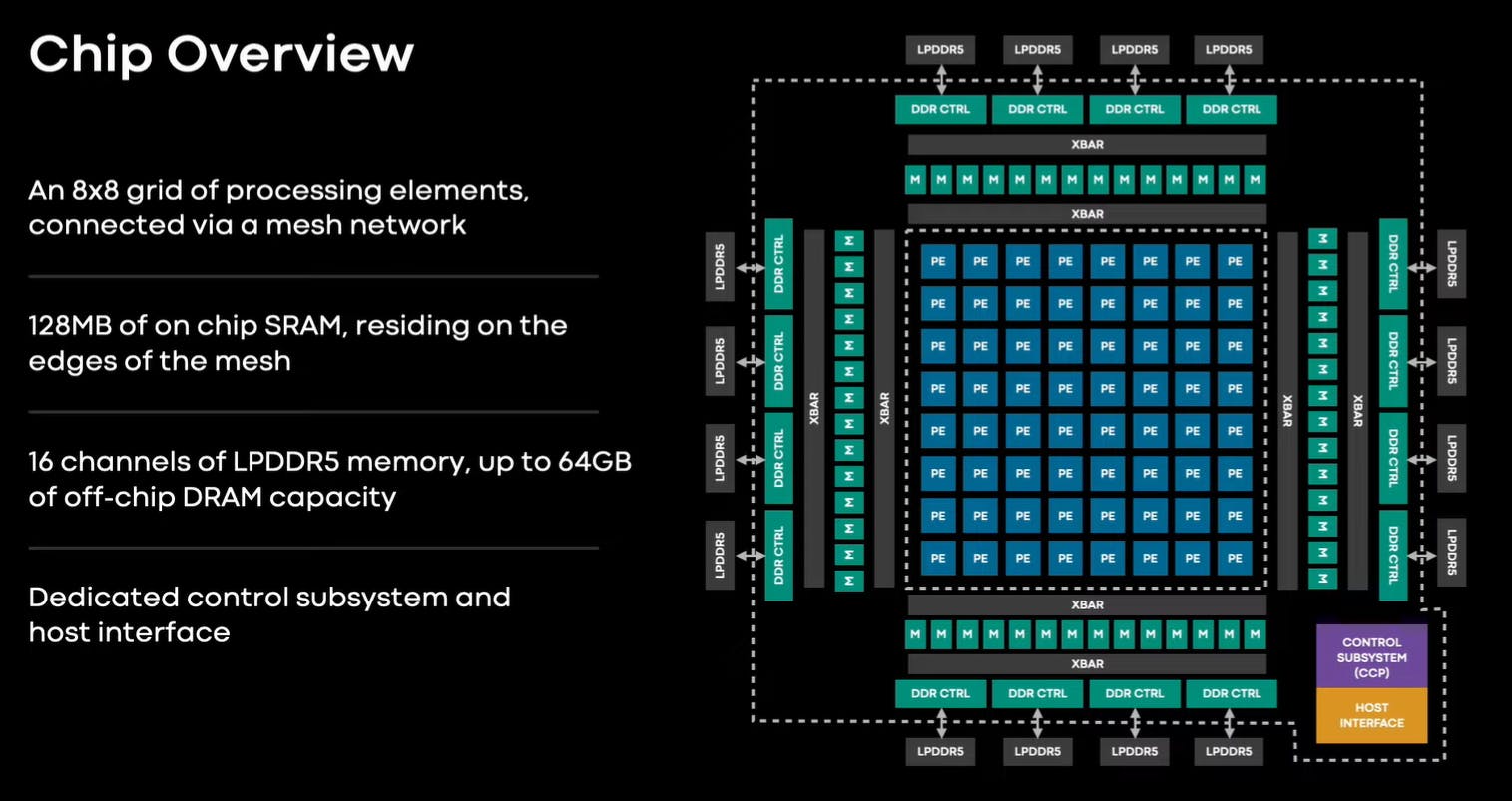
Processing Elements
The processing elements (PEs) are the core computational components of an inference accelerator. The accelerator configuration comprises a grid consisting of 64 PEs arranged in an 8x8 pattern.
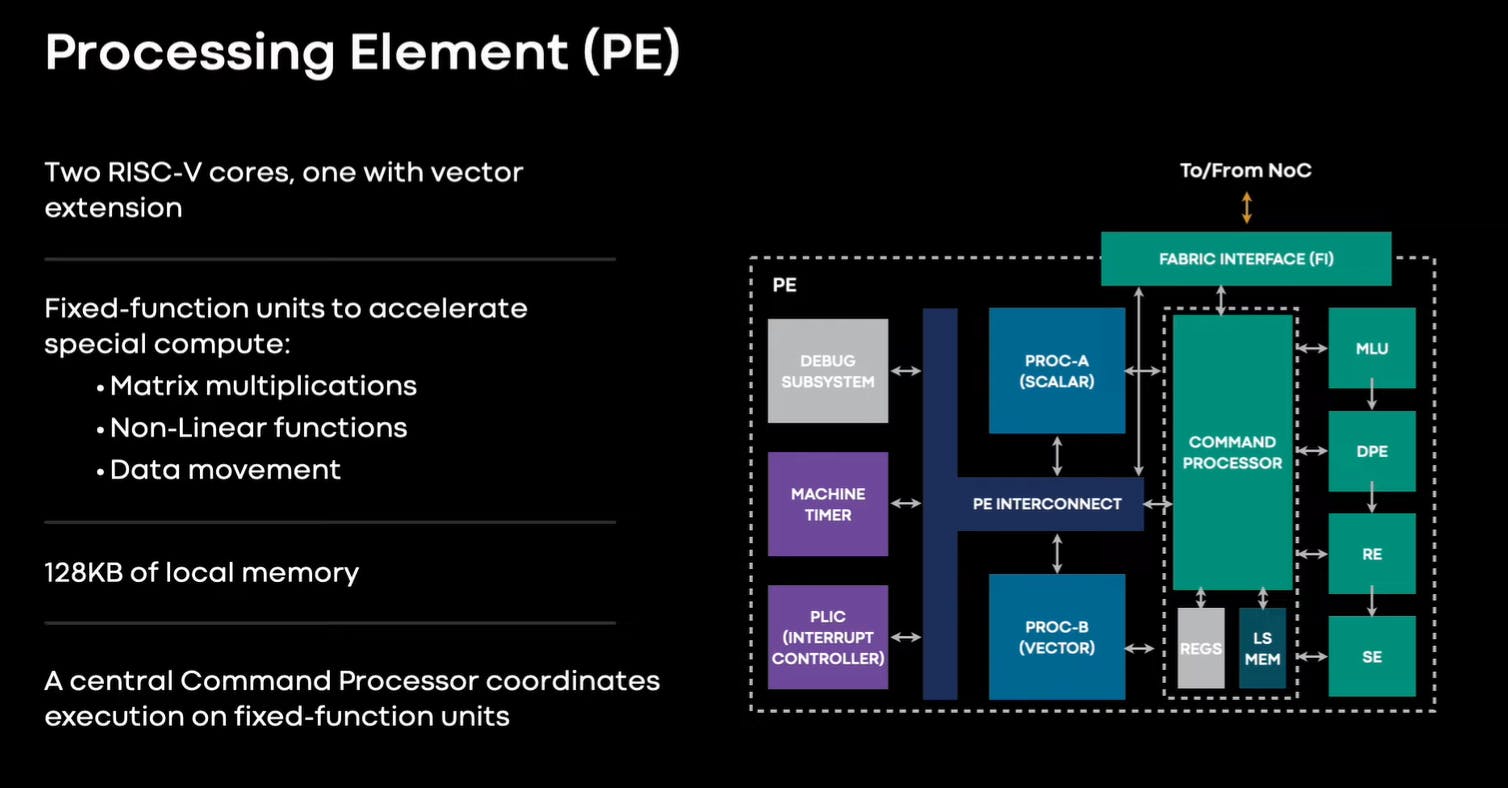
Every PE in the accelerator has two processor cores, one of which is equipped with a vector extension. The PEs include a set of fixed-function units optimized for crucial operations like matrix multiplication, accumulation, data movement, and nonlinear function calculation.
The processor cores are based on the RISC-V open instruction set architecture (ISA) but are extensively customized to efficiently handle the required compute and control tasks.
Memory Hierarchy
The MTIA uses on-chip and off-chip memory resources to store intermediate data, weights, activations, and other data during inference.
- On-chip memory (SRAM) is typically faster and is likely used for storing frequently accessed data.
- off-chip memory (DRAM) would provide additional storage capacity.
The off-chip memory of the MTIA utilizes LPDDR5 (Low Power Double Data Rate 5) technology. This choice of memory enables fast data access and can scale up to 128 GB, providing ample storage capacity for large-scale AI models and data.
The on-chip memory of the accelerator includes a 128 MB of on-chip SRAM (Static Random Access Memory) shared among all the PEs.
Unlike DRAM, SRAM is a type of volatile memory that retains data as long as power is supplied to the system. SRAM is typically faster and more expensive than DRAM but requires more physical space per bit of storage.
Interconnects
Interconnects provide the communication infrastructure within the accelerator, allowing different components to exchange data and instructions. The MTIA uses a mesh network to interconnect the PEs and the memory blocks.
The mesh network architecture provides multiple communication paths, allowing for parallel data transfers and minimizing potential bottlenecks. It allows for flexible data movement and synchronization between the PEs and memory resources.
Power and Thermal Management
Inference accelerators require power and thermal management mechanisms to ensure their stable operation. The MTIA has a thermal design power (TDP) of 25 W, which suggests that the design and cooling mechanisms of the accelerator are optimized to handle a power consumption of up to 25 watts without exceeding temperature limits.
The Performance of MTIA
The performance of MTIA is compared based on its end-to-end performance of running five different DLRMs (Deep Learning Recommendation Systems), representing low to high-complexity workloads.
The MTIA achieves near PERF/W (floating-point operations per watt) with GPUs and exceeds the PERF/W of NNPI. Roofline modeling indicates that there is still room for improvement.
MTIA achieves three times PERF/W on low-complexity models and trails behind GPUs on high-complexity models.
Meta promised during the release to continue improving MTIA for high-complexity models by optimizing the software stack of MTIA.
More information on the model’s performance will be announced with the paper release later in June. 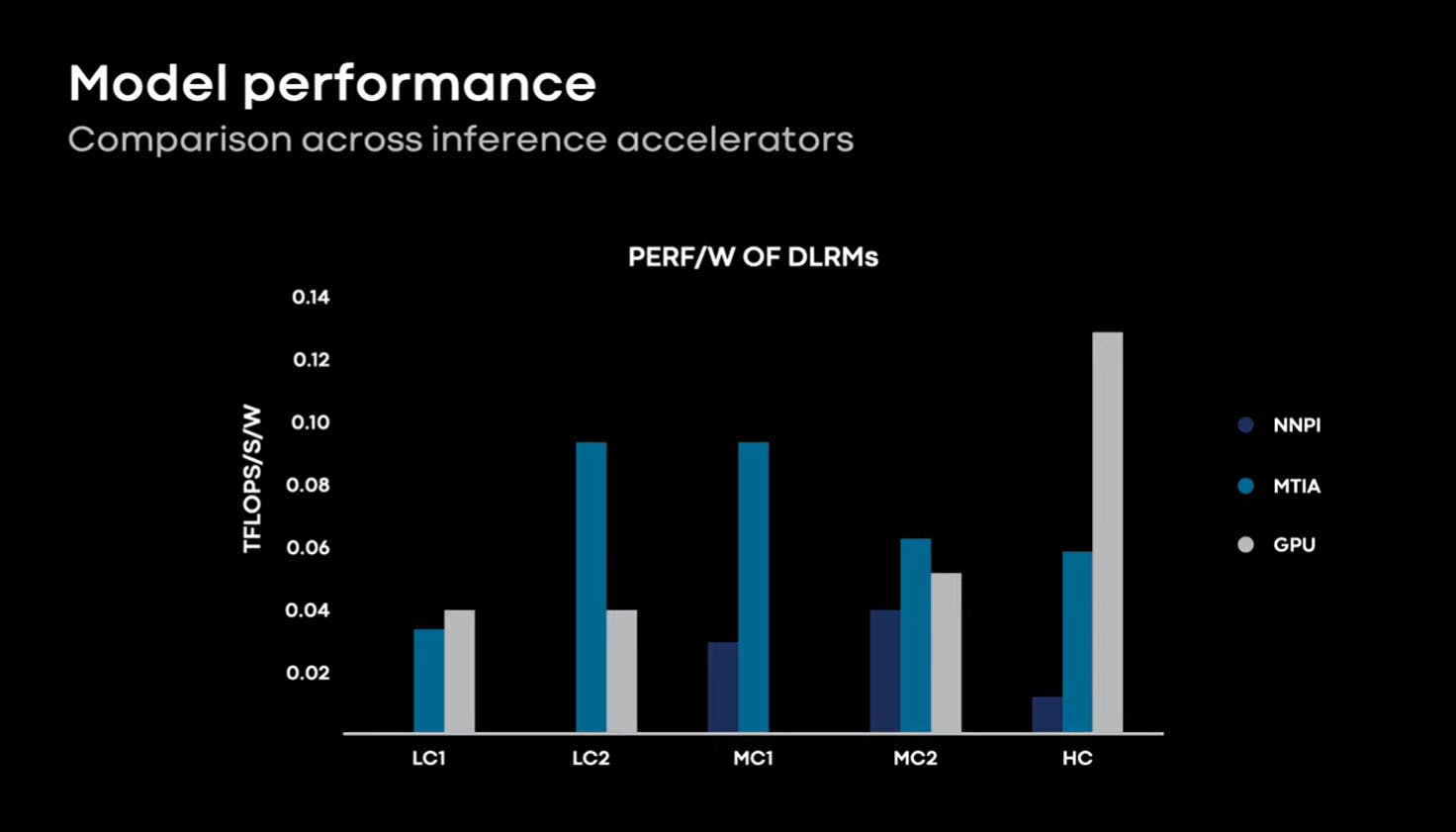
Other Notable Announcements
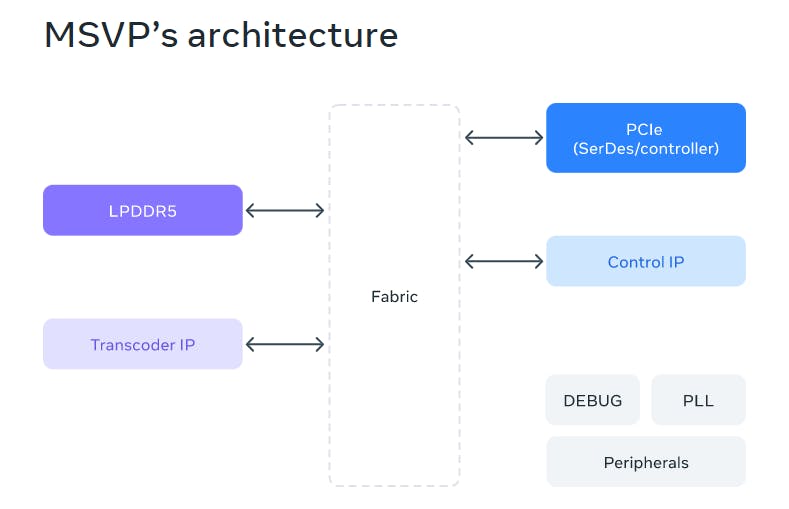
Meta Scalable Video Processor (MSVP)
MSVP is a new, advanced ASIC for video transcoding. It is specifically tailored to address the processing demands of Meta’s expanding Video-On-Demand (VOD) and live-streaming workloads. MSVP offers programmability and scalability, enabling efficient support for both VOD’s high-quality transcoding requirements and the low latency and accelerated processing demands of live-streaming. By incorporating the hardware acceleration capabilities of MSVP, you can:
- Enhance video quality and compression efficiency
- Ensure stability, reliability, and scalability
- Reduce compute and storage requirements
- Reduce bits at the same quality or increase quality at the same bit rate.
To know more about MSVP, you can read all about it on Meta’s blog.
Research Super Cluster (RSC)
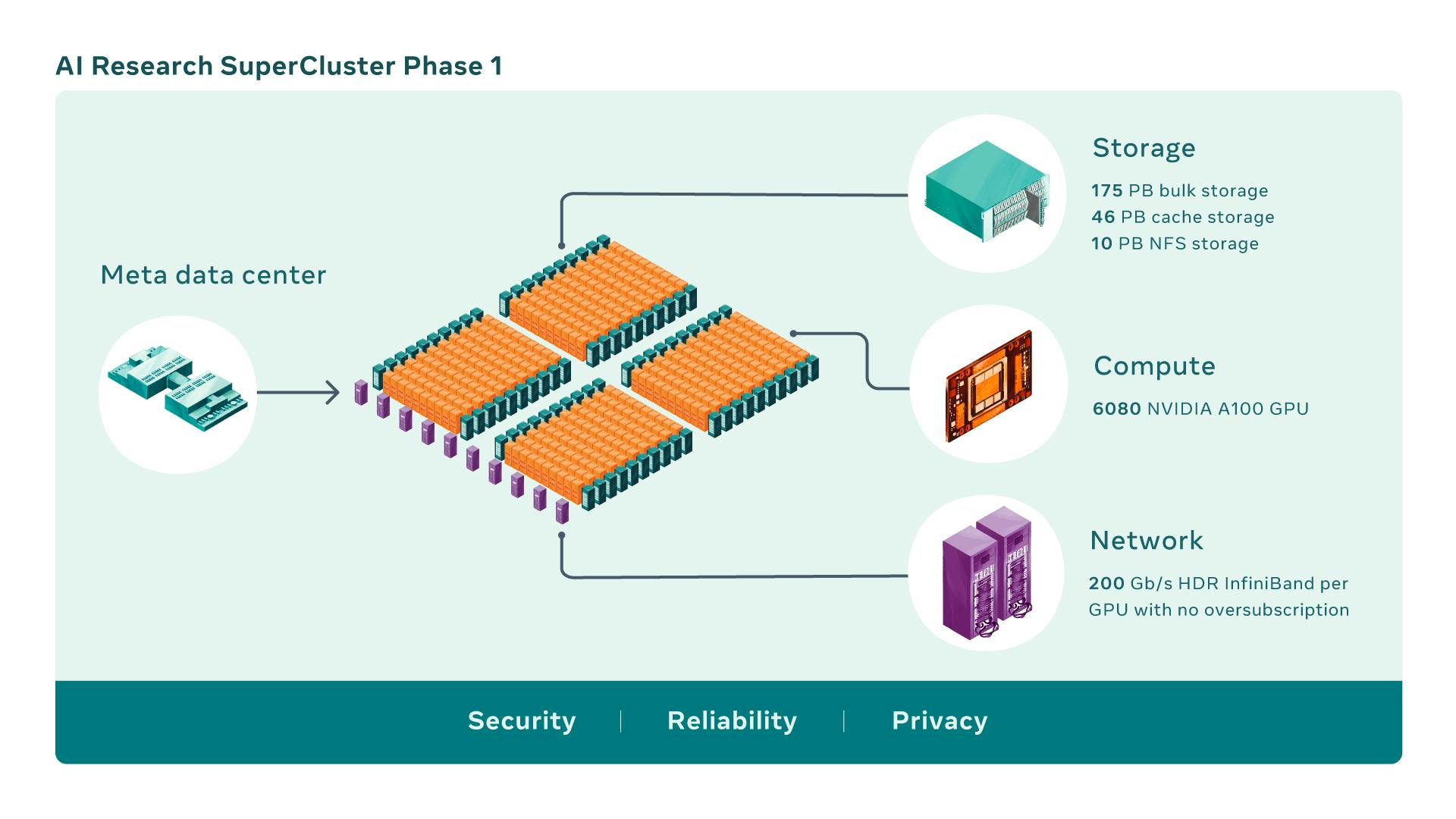
Meta’s RSC is among the most high-performing AI supercomputers (data centers) globally. It was specifically designed for training the next generation of large AI models (such as LLaMA).
Its purpose is to fuel advancements in augmented reality tools, content understanding systems, real-time translation technology, and other related applications. With an impressive configuration of 16,000 GPUs, the RSC possesses significant computational power. Accessible across the three-level CIos network fabric, all the GPUs provide unrestricted bandwidth to each of the 2,000 training systems. You can read more about the RSCs on Meta’s blog.
Meta’s History of Releasing Open-Source AI Tools
Meta has been on an incredible run of successful AI releases over the past two months.
Segment Anything Model
MetaAI's Segment Anything Model 2 (SAM 2) has changed image and video segmentation for the future by applying foundation models traditionally used in natural language processing.

SAM 2 leverages prompt engineering to accommodate various segmentation challenges. This model empowers users to choose an object for segmentation through interactive prompts, including bounding boxes, key points, grids, or text.
In situations where there is uncertainty regarding the object to be segmented, SAM 2 has the ability to generate multiple valid masks.
SAM 2 has great potential to reduce labeling costs, providing a much-awaited solution for AI-assisted labeling, and improving labeling speed by orders of magnitude.
DINOV2
DINOv2 An advanced self-supervised learning technique that learns visual representations from images without relying on labeled data. Unlike supervised learning models, DINOv2 doesn't require large amounts of labeled data for training.

The DINOv2 process involves two stages: pretraining and fine-tuning. During pretraining, the DINO model learns useful visual representations from a large dataset of unlabeled images. In the fine-tuning stage, the pre-trained DINO model is adapted to a task-specific dataset, such as image classification or object detection.
💡Learn more about DINOv2, how it was trained, and how to use it.ImageBind
ImageBind, developed by Meta AI's FAIR Lab and released on GitHub, introduces a novel approach to learning a joint embedding space across six different modalities: text, image/video, audio, depth (3D), thermal (heatmap), and IMU. By integrating information from these modalities, ImageBind enables AI systems to process and analyze data more comprehensively, resulting in a more humanistic understanding of the information at hand.

The ImageBind architecture incorporates separate encoders for each modality, along with modality-specific linear projection heads, to obtain fixed-dimensional embeddings. The architecture comprises three main components:
- modality-specific encoders,
- a cross-model attention module, and
- a joint embedding space.
While the specific details of the framework have not been released yet, the research paper provides insights into the proposed architecture.
💡Learn more about ImageBind and its multimodal capabilities.Overall, ImageBind's ability to handle multiple modalities and create a unified representation space opens up new possibilities for advanced AI systems, enhancing their understanding of diverse data and enabling more accurate predictions and results.
Conclusion
Even though it can feel like a virtual reality, sometimes it isn’t, the AI race is on, and Meta is back with powerful new AI infrastructure.
Meta's release of the MTIA, along with its history of open-source contributions, demonstrates the company's commitment to advancing the field of AI research and development. Meta is clearly committed to driving forward innovation in AI. Whether it's the MTIA, the Segment Anything model, DinoV2, or ImageBind, each of these contributions plays a part in expanding our understanding and capabilities in AI.
The release of their first AI chip, MTIA, is a significant development. It further fuels the AI hardware race and contributes to the evolution of hardware designed specifically for AI applications.
If you’re dying to hear more about the Meta’s new custom chip, they will present a paper on the chip at the International Symposium on Computer Architecture conference in Orlando, Florida, in June 17 - 21 with the title "MTIA: First Generation Silicon Targeting Meta's Recommendation System.