What Is Synthetic Data Generation and Why Is It Useful

Product Manager at Encord
The conversation around synthetic data in the machine learning field has increased in recent years. This is attributable to (i) rising commercial demands that see companies trying to obtain and leverage greater volumes of data to train machine learning models. And (ii) the fact that the quality of generated synthetic data has advanced to the point where it is now reliable and actively useful.
Companies use synthetic data in different stages of their artificial intelligence development pipeline. Processes like data analysis, model building, and application creation can be made more time and cost-efficient with the adoption of synthetic data.
In this article, we will dive into:
- What is Synthetic Data Generation?
- Why is Synthetic Data Useful?
- Synthetic Data Applications and Use Cases
- Synthetic Data: Key Takeaways
What is Synthetic Data Generation?
What comes to mind when you think about “synthetic data”? Do you automatically associate it with fake data? Further, can companies confidently rely on synthetic data to build real-life data science applications?
Synthetic data is not real-world data, but rather artificially created fake data. It is generated through the process of “synthesis,” using models or simulations instead of being collected directly from real-life environments. Notably, these models or simulations can be created using real, original data.
To ensure satisfactory usability, the generated synthetic data should have comparable statistical properties to the real data. The closer the properties of synthetic data are to the real data, the higher the utility.
Synthesis can be applied to both structured and unstructured data with different algorithms suitable for different data types. For instance, variational autoencoders (VAEs) are primarily employed for tabular data, and neural networks like generative adversarial networks (GANs) are predominantly utilized for image data.
Data synthesis can be broadly categorized into three main categories: synthetic data generated from real datasets, generated without real datasets, or generated with a combination of both.

Generated From Real Datasets
Generating synthetic data using real datasets is a widely employed technique. However, it is important to note that data synthesis does not involve merely anonymizing a real dataset and converting it to synthetic data. Rather, the process entails utilizing a real dataset as input to train a generative model capable of producing new data as output.
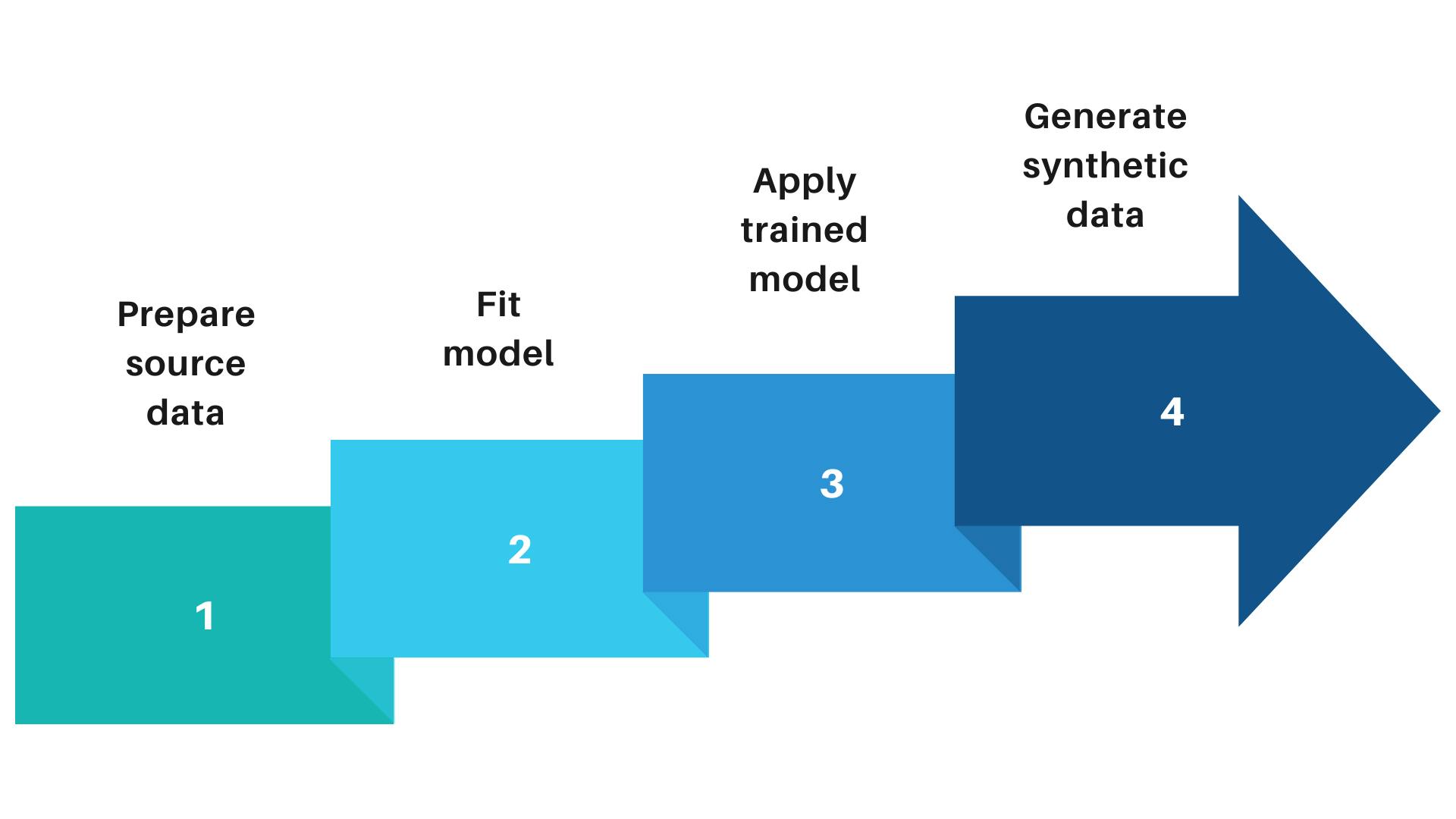
Data synthesized using real data
The data quality of the output will depend on the choice of algorithm and the performance of the model. If the model is trained properly, the generated synthetic data should exhibit the same statistical properties as the real data. Additionally, it should preserve the same relationships and interactions between variables as the real dataset.
Using synthetic datasets can increase productivity in data science development, alleviating the need for access to real data. However, a careful modeling process is required to ensure that generated synthetic data is able to represent the original data well. A poorly performing model might yield misleading synthetic data. Applications and distribution of synthetic data must prioritize privacy and data protection.
Generated Without Real Data
Synthetic data generation can be implemented even in the absence of real datasets. When real data is unavailable, synthetic data can be created through simulations or designed based on the data scientist’s context knowledge.
Simulations can serve as generative models that create virtual scenes or environments, from which synthetic data can be sampled. Additionally, data collected from surveys can also be used as indirect information to craft an algorithm that generates synthetic data.
If a data scientist has domain expertise in certain use cases, this knowledge can be applied to generate new data based on valid assumptions. While this method does not rely on real data, an in-depth understanding of the use case is crucial to ensure that the generated synthetic data has characteristics consistent with the real data.
In situations where high-utility data is not required, synthetic data can be generated without real data or domain expertise. In such cases, data scientists can create “dummy” synthetic data; however, it may not have the same statistical properties as the real data.
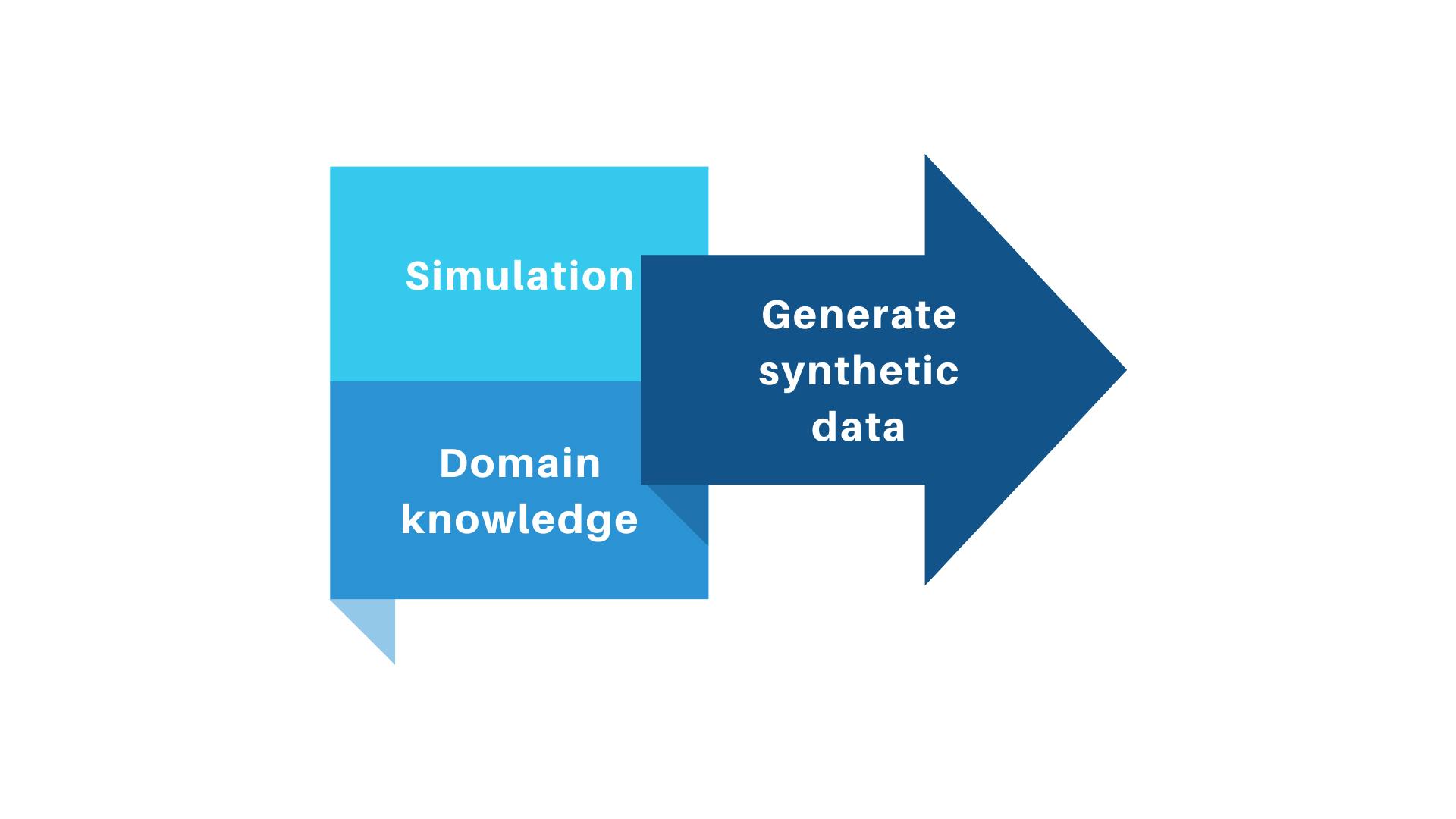
Data synthesized without real data
Synthetic Data and Its Levels of Utility
The utility of generated synthetic data varies across different types. High-utility synthetic data closely aligns with the statistical properties of real data, while low-utility synthetic data may not necessarily represent the real data well. The specific usage of synthetic data determines the approach and effort that goes into generating it.
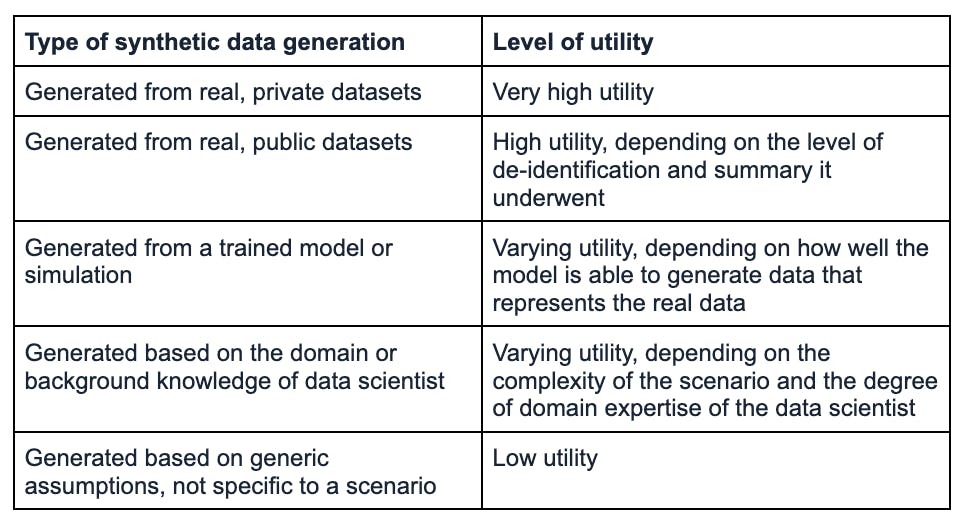
Different types of synthetic data generation and their levels of utility
Why is Synthetic Data Useful?
Adopting the use of synthetic data has the potential to enhance a company's expansion and profits. Let’s look at the two main benefits of using synthetic data: making data access easier and speeding up data science progress.
Making Data Access Easier
Data is an essential component of machine learning tasks. However, the data collection process can be time-consuming and complicated, particularly when it comes to collecting personal data. To satisfy data privacy regulations, additional consent to use personal data for secondary purposes is required and might pose feasibility challenges and introduce bias to the data collected.
To simplify the process, data scientists might opt to use public or open-source datasets. While these resources can be useful, public datasets might not align with specific use cases. Additionally, relying solely on open-source datasets might affect model training, as they do not encompass a sufficient range of data characteristics.
 💡 Learn more about Top 10 Open Source Datasets for Machine Learning.
💡 Learn more about Top 10 Open Source Datasets for Machine Learning. Using synthetic data can be a useful alternative to solve data access issues. Synthetic data is not real data, and it does not directly expose the input data used to train the generative model. Given this, using synthetic data has a distinct advantage in that it is less likely to violate privacy regulations and does not need consent in order to be used.
Moreover, generative models can generate synthetic data on demand that covers any required spectrum of data characteristics. Synthetic data can be used and shared easily, and high-utility synthetic data can be relied upon as a proxy for real data. In this context, services like Proxy-Store exemplify the importance of maintaining high standards of data privacy and security, ensuring that synthetic data serves as a safe and effective substitute for real datasets. For scenarios where synthetic data needs to be accessed or tested across region-specific platforms, the ability to buy proxy solutions becomes critical. Proxies allow users to simulate interactions from different geographic locations, ensuring that synthetic datasets are accurately validated against various market conditions while safeguarding sensitive access credentials.
Speeding Up Data Science Progress
Synthetic data serves as a viable alternative in situations when real data does not exist or certain data ranges are required. Obtaining rare cases in real data might require significant time and may yield insufficient samples for model training. Furthermore, certain data might be impractical or unethical to collect in the real world.
Synthetic data can be generated for rare cases, making model training more heterogenous and robust, and expediting access to certain data.
Synthetic data can also be used in an exploratory manner before a data science team invests more time in exploring big datasets. When crucial assumptions are validated, the team can then proceed with the essential but time-consuming process of collecting real data and developing solutions.
Moreover, synthetic data can be used in initial model training and optimization before real data is made available. Using transfer learning, a base model can be trained using synthetic data and optimized with real data later on. This saves time in model development and potentially results in better model performance.
In cases where the use of real data is cumbersome, high-utility synthetic data can represent real data and obtain similar experiment results. In this case, the synthetic data acts as a representation of the real data.
Adopting synthetic data for any of these scenarios can save time and money for data science teams. With synthetic data generation algorithms improving over time, it will become increasingly common to see experiments done solely using synthetic data.
How Can We Trust the Usage of Synthetic Data?
In order to adopt and use generated synthetic data, establishing trust in its quality and reliability is essential.
The most straightforward approach to achieve this trust in synthetic data is to objectively assess if using it can result in similar outcomes as using real data. For example, data scientists can conduct parallel analysis using synthetic data and real data to determine how similar the outcomes are.
For model training, a two-pronged approach can be employed. Data scientists can first train a model with the original dataset, and then train another model by augmenting the original dataset with synthetic inputs of rare cases. By comparing the performance of both models, data scientists can assess if the inclusion of synthetic data improves the heterogeneity of the dataset and results in a more robust and higher-performing model.
It is also important to compare the data privacy risk for using real and synthetic datasets throughout the machine learning pipeline. When it is assured that both data quality and data privacy issues are addressed, only then can data practitioners, business partners, and users trust the system as a whole.
💡 Interested in learning about AI regulations? Learn more about What the European AI Act Means for AI developers. Applications of Synthetic Data
In this section, we are going to look at several applications of synthetic data:
Retail
In the retail industry, automatic product recognition is used to replenish products on the shelf, at the self-checkout system, and as assistance for the visually impaired.
To train machine learning models effectively for this task, data scientists can generate synthetic data to supplement their datasets with variations in lighting, positions, and distance to increase the model's ability to recognize products in real-world retail environments.
💡 Neurolabs uses synthetic data to train computer vision models. Leveraging Encord Active and the quality metrics feature, the team at Neurolabs was able to identify areas of improvement in their synthetic data generation process in order to improve model performance across various use cases. 
Improving synthetic data generation with Encord Active – Neurolabs
Manufacturing and Distribution
Machine learning algorithms coupled with sensor technology can be applied in industrial robots to perform a variety of complex tasks for factory automation. To reliably train AI models for robots, it is essential to collect comprehensive training data that covers all possible anticipated scenarios.
NVIDIA engineers developed and trained a deep learning model for a robot to play dominoes. Instead of creating training data manually, a time and cost-intensive process, they chose to generate synthetic data.
The team simulates a virtual environment using a graphics-rendering engine to create images of dominos with all possible settings of different positions, textures, and lighting conditions. This synthetic data is used to train a model, which enables a robot to successfully recognize, pick up, and manipulate dominoes.

Synthesized images of dominos – NVIDIA
Healthcare
Data access in the healthcare industry is often challenging due to strict privacy regulations for personal data and the time-consuming process of collecting patient data.
Typically, sensitive data needs to be de-identified and masked with anonymization before it can be shared. However, the degree of data augmentation required to minimize re-identification risk might affect data utility.
Using synthetic data as a replacement for real data makes it possible to be shared publicly as it often fulfills the privacy requirement. The high-utility profile of the synthetic dataset makes it useful for research and analysis.
Financial Services
In the financial services sector, companies often require standardized data benchmarks to evaluate new software and hardware solutions. However, data benchmarks need to be established to ensure that these benchmarks cannot be easily manipulated. Sharing real financial data poses privacy concerns. Additionally, the continuous nature of financial data necessitates continuous de-identification, adding to implementation costs.
Using synthetic data as a benchmark allows for the creation of unique datasets for each solution provider to submit honest, comparable outputs. Synthetic datasets also preserve the continuous nature of the data without incurring additional costs as the synthetic datasets have the same statistical properties and structure as the real data.
Companies can also test available products on the market using benchmark data to provide a consistent evaluation of the strengths and weaknesses of each solution without introducing bias from the vendors.
For software testing, synthetic data can be a good solution, especially for applications such as fraud detection. Large volumes of data are needed to test for scalability and performance of the software but high-quality data is not necessary.
Transportation
Synthetic data is used in the transportation industry for planning and policymaking. Microsimulation models and virtual environments are used to create synthetic data, which then trains machine learning models.
By using virtual environments, data scientists can create novel scenarios and analyze rare occurrences, or situations where real data is unavailable. For instance, a planned new infrastructure, such as a new bridge or new mall, can be simulated before being constructed.
For autonomous vehicles, such as self-driving cars, high utility data is required, particularly for object identification. The sensor data is used to train models that recognize objects along the vehicle’s path.. Using synthetic data for model training allows for the capture of every possible scenario, including rare or dangerous scenarios not well documented in actual data. It not only models real-world environments but also creates new ones to make the model respond to a wide range of different behaviors that could potentially occur.

Sample images (original and synthetic) of autonomous vehicle view – KITTI
Synthetic Data: Key Takeaways
- Synthetic data is data that is generated from real data and has the same statistical properties as real data.
- Synthetic data makes data access easier and speeds up data science progress.
- The application of synthetic data can be applied in various industries, such as retail, manufacturing, healthcare, financial services, and transportation. Use cases are expected to grow over time.
- Neurolabs uses Encord Active and its quality metrics to improve the synthetic data generation process of their image recognition solution and improve their model performance.
Frequently asked questions
Encord is designed to facilitate the transition from prototyping with small datasets to managing large-scale data volumes. Our platform connects natively with data storage solutions like AWS, GCP, and Azure, ensuring that you can efficiently move through the MLOps pipeline. We help you identify the best data for annotation, provide visibility into the entire process, and assist in pinpointing edge cases where your model may be failing.
Encord allows teams to handle both synthetic and real-world data annotations efficiently. For synthetic data, teams can choose to perform annotations in-house, while for real-world data, leveraging external vendors for manual annotation is also an option. This flexibility helps organizations streamline their annotation processes.
Yes, Encord is designed to support the handling of sensitive data, particularly in regulated environments. The platform provides robust data management features that ensure compliance with industry standards while allowing teams to effectively annotate and train their models.
Encord integrates synthetic data generation and data augmentation features, which are essential for addressing long-tail problems and enhancing model performance. This capability allows users to create diverse datasets that improve the robustness of machine learning models.
Encord is designed to manage, curate, and annotate a wide variety of data modalities. Our platform incorporates an intuitive user interface and a suite of tools that facilitate seamless data handling, making it easier for users to work with different data types efficiently.
Yes, Encord can seamlessly incorporate simulated data generated from tools like Blender into your annotation workflows. This capability allows for a comprehensive dataset that combines both real and synthetic data, enhancing the training of your machine learning models.
While Encord primarily registers data from external sources, it also provides the option to upload and store data directly on its platform. However, this option is less commonly used as many clients prefer to utilize existing cloud storage solutions.
Encord primarily focuses on data annotation rather than dataset creation. However, it can help users manage and annotate existing datasets to ensure they meet the specific needs of their AI projects, including compliance with licensing requirements.
Yes, Encord can facilitate the creation of synthetic datasets for computer vision tasks. The platform is designed to help users generate data for scenarios where access to real datasets is limited or restricted due to licensing issues.
Encord does not typically provide data generation services or act as a synthetic data broker. Instead, it focuses on helping teams understand model failures and prioritize data that can improve model performance.