10 Best Multimodal Annotation Tools 2026

Product Manager at Encord
This article discusses the significance of multimodal annotation, different data annotation types, techniques, and challenges, and introduces some popular multimodal annotation tools. It also explains the factors businesses must consider before investing in an annotation tool and concludes with a few key takeaways.
Building powerful artificial intelligence (AI) models requires a robust data processing workflow. Most importantly, it includes accurate data annotation to build high-quality datasets suitable for training. It’s a crucial step for supervised machine learning, where models learn complex patterns from annotated data and use the knowledge to predict new, unseen samples.
However, data annotation is a challenging task. Due to ever-increasing data volume, diverse data modalities, and the scarcity of high-quality domain-specific datasets, it is difficult for organizations and practitioners to streamline their machine learning (ML) development process.
What is Multimodal Annotation?
In multimodal learning, annotation involves labeling several data types, such as images, text, and audio. Multimodal data annotation tools enable practitioners to conduct auto-annotation for various objects, from 2D images, videos, Digital Imaging and Communications in Medicine (DICOM) data, and geospatial information to 3D point clouds. Multimodal AI is the core of future AI development with the market at an estimated USD 1.34 billion in 2023 and projected to grow at a CAGR of 35.8% from 2024 to 2030. (Source: Grand View Research)
Compare the 10 Best Multimodal Annotation Tools
Let’s discuss the top annotation tools businesses can use to streamline their ML workflow.
Comparison Guide at a Glance
| Tool | Modalities Supported | AI-Assisted / Automation | Collaboration & Workflow | QA & Review | Best Fit |
| Encord | Image, Video, Text, Audio, DICOM, NIfTI | AI pre-labels, active learning | Team roles, review stages | Built-in QA workflows | Enterprise multimodal + regulated datasets |
| SuperAnnotate | Image, Video, Text | Automation options + layered QA | collaboration + services | Tiered QA | Large teams + cloud pipelines |
| Labelbox | Image, Video, Text | Model-assisted labeling | Yes | Integrated review | Cloud CV/NLP workflows |
| Diffgram | Image, Video, Audio, Text | AI pre-labels | Yes | Review + versioning | Custom ML pipelines |
| VIA (VGG) | Image, Video, Audio | Manual + plugins | Basic | Manual review | Open-source standalone workflows |
| Label Studio | Image, Video, Text, Audio | ML backends | Yes | Review via plugins | Developer-controlled multimodal |
| Prodigy | Text, Audio, Image | Model-in-loop active learning | Limited | QA via scripts | Active learning / LLM workflows |
| Scale AI | Image, Video, Text, LiDAR | Automation + workforce | Managed + collaboration | Layered QA | Large enterprise labeling ops |
| Roboflow | Image, Video | Model assist + automation | Yes | Versioning + review | CV-first multimodal prep |
| Lightly | Any data (curation focus) | Embedding-based selection | Basic | Curation-oriented | Data selection & embedding workflows |
Encord Annotate
Encord Annotate is a labeling platform that supports several multimodal annotation techniques for images, videos, Digital Imaging and Communications in Medicine (DICOM), Neuroimaging Informatics Technology Initiative (NIfTI), Electrocardiograms (ECGs), and geospatial data.
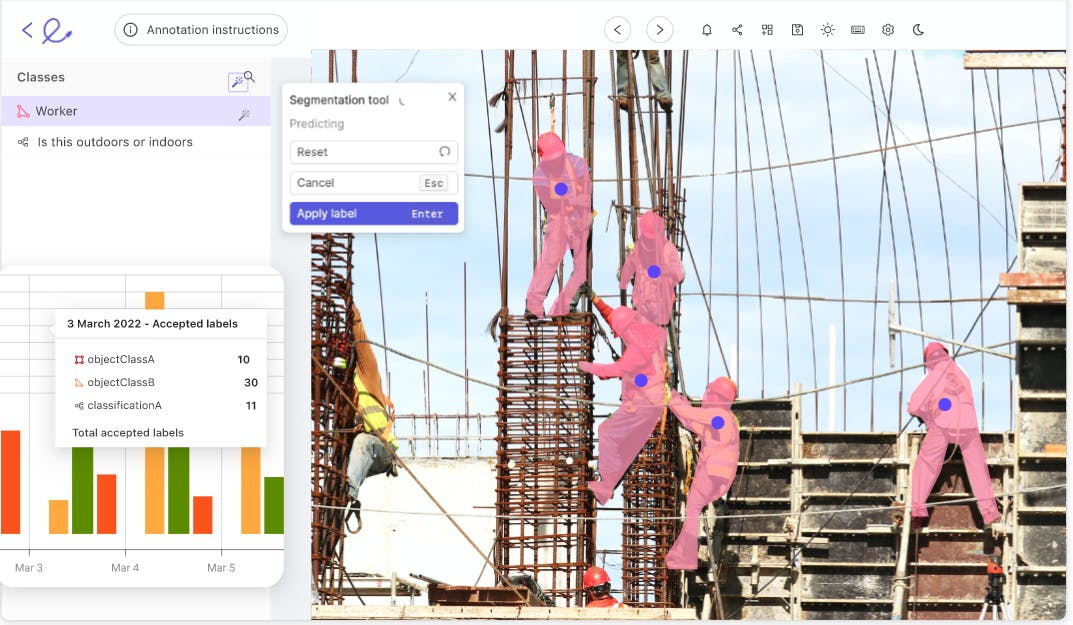
Benefits and Key Features
- Supports object detection, keypoint skeleton pose, hanging protocols, instance segmentation, action recognition, frame classifications, polygons, and polyline annotation.
- Helps experts develop high-quality labeling workflows through human-in-the-loop integration.
- Allows teams to build sophisticated labeling ontologies – a structured framework for categorizing data by enabling nested classification to create granular datasets with precise ground truth labels.
- Boosts the annotation workflow through AI-assisted automation. You can train few-shot models and use only a small labeled dataset to annotate the rest of the samples.
- Provides an integrated platform for managing all training data through an easy-to-use interface.
- Features performance analytics that let teams assess annotation quality and optimize where necessary.
- Supports several file formats for different data types.
- Allows teams to use the Segment Anything Model (SAM) for auto segmentation to annotate domain-specific data instantly.
Best For
- Teams that want to build large-scale computer vision models.
- Teams looking for expert support can use Encord, especially for labeling complex data.
- AI developers who work on diverse visual datasets and want a comprehensive annotation tool.
Labelbox
Labelbox is a multimodal platform that allows practitioners to annotate images, videos, geospatial data, text, audio, and HTML files.
Benefits and Key Features
- Offers a single efficiency metric to measure label quality.
- Allows organizations to develop custom workflows according to data type.
- Provides data analytics functionality to reduce labeling costs and monitor performance.
- Has collaboration tools to enhance workflows across different teams.
Best For
- Teams that want to economize on labeling costs.
- Teams working on visual and natural language processing (NLP) models, which require annotating images and textual data.
Pricing
LabelBox offers multiple tiers at different prices, including the Free, Starter, Standard, and Enterprise versions.
SuperAnnotate
SuperAnnotate helps teams speed up multimodal learning projects by providing comprehensive functions for annotating text, audio, images, videos, and point cloud data.
Benefits and Key Features
- Offers annotation tools for building training data for large language models (LLMs), such as image captions, question answers, instructions, etc.
- Teams can annotate audio clips to identify speech and sound.
Best For
- Teams struggling with project management due to poor collaboration among teammates.
- Building efficient multimodal data curation pipelines.
Price
SuperAnnotate offers a Free, Pro, and Enterprise version. Users must reach out to sales to get a price quote.
Computer Vision Annotation Tool (CVAT)
CVAT is a multimodal labeling tool primarily for computer vision tasks in healthcare, manufacturing, retail, automotive, etc.
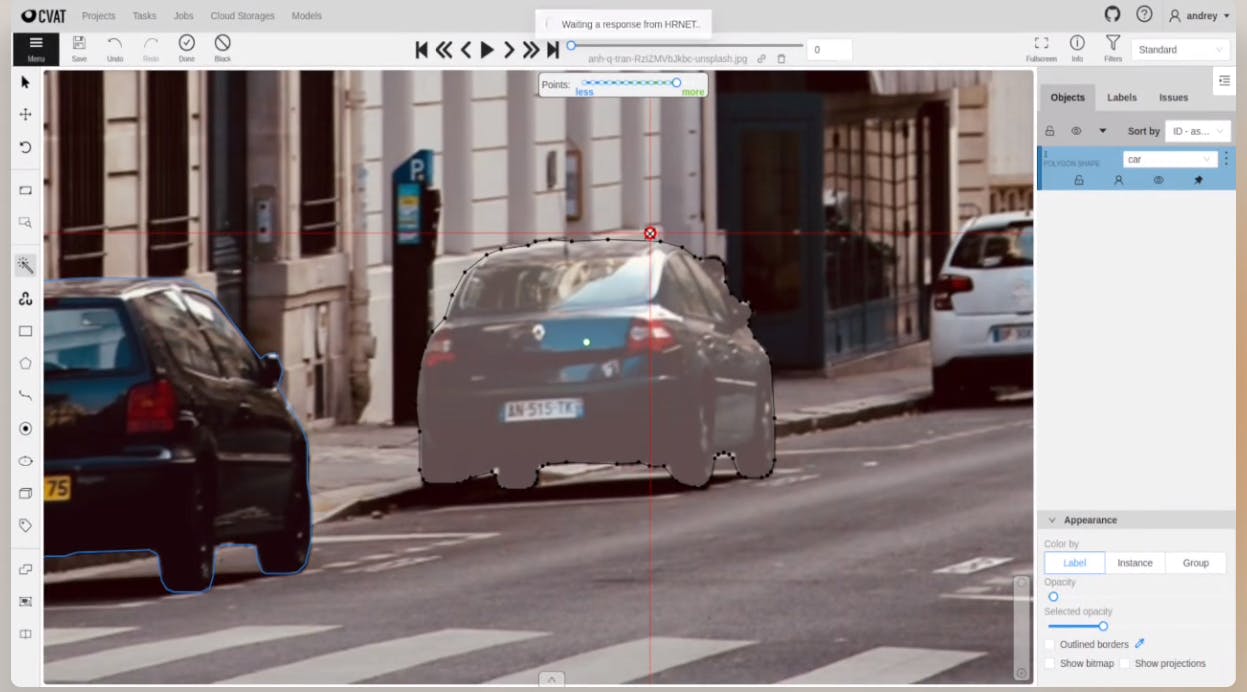
Benefits and Key Features
- It supports several image annotation techniques, such as 3D cuboids, object detection, semantic segmentation, etc.
- Features intelligent algorithms for boosting annotation efficiency.
- It offers integration with the cloud for data storage.
Best For
- Teams that want cloud-based data storage solutions.
- Teams looking for a specialized image annotation platform.
Pricing
CVAT, with cloud support, comes in three variants - Free, Solo, and Team. The Solo and Team versions cost USD 33 per month.
VGG Image Annotation (VIA)
VIA is a web-based manual annotation tool for image, audio, and video data, requiring no initial setup or configuration.

Benefits & Key Features
- Supports basic image annotation methods, including bounding boxes and polygons.
- Also features audio, face, and video annotation techniques.
- Offers a list annotation capability that allows experts to label a list of images.
Best For
Teams that want a low-cost annotation solution for computer vision.
Pricing
VIA is a free, open-source tool.
Basic.ai
Basic.ai offers a multimodal data annotation platform for 3D LiDAR point clouds, images, and videos.
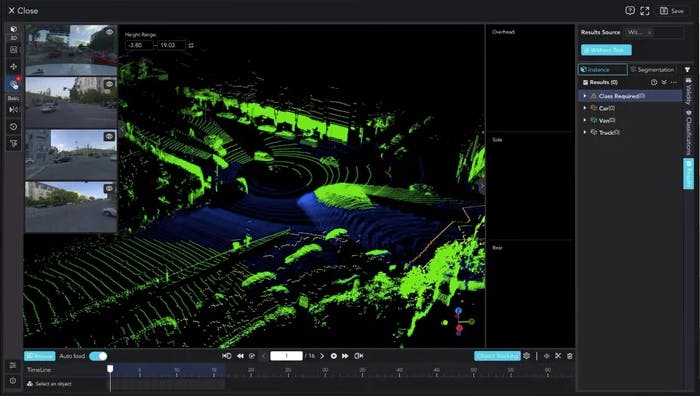
Basic.ai Data Annotation Dashboard
Benefits and Key Features
- Offers auto-annotation, segmentation, and tracking.
- Offers an AI-enabled quality control process to facilitate annotation review.
Best For
Teams looking to streamline data annotation workflows across industries like automotive, smart city, and robotics.
Pricing
Basic.ai offers free and team pricing plans.
Label Studio
Label Studio is an open-source multimodal data annotation tool for audio, text, images, HTML, videos, and time series data.
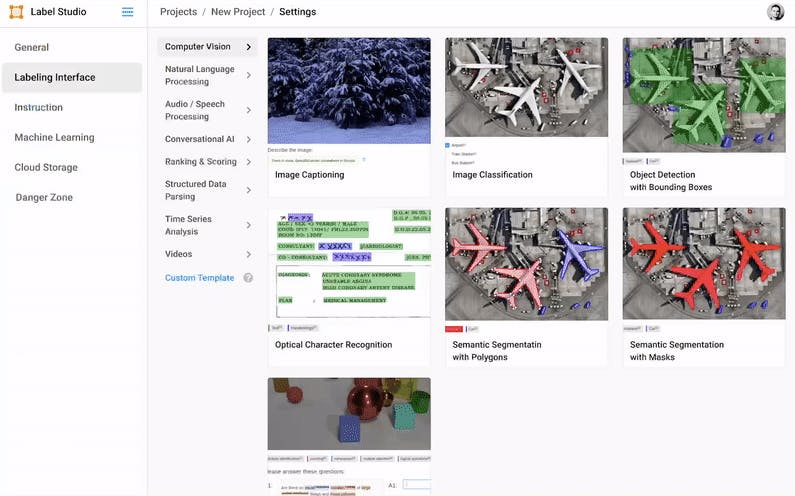
Benefits and Key Features
- Teams can perform text classification, audio segmentation, audio transcription, emotion recognition, named entity recognition, video classification, etc.
- Offers labeling templates for a variety of use cases.
- Offers imports via different formats like JSON, CSV, TSV, RAR, ZIP archives, S3, and Google Cloud Storage.
Best For
Large and small teams experimenting with data labeling tools for building fine-tuned AI models.
Price
Label Studio offers a paid enterprise edition. It also offers a free and open-source community edition.
Dataloop
Dataloop, the “data engine for AI,” offers a multimodal annotation platform for video, LiDAR, and sensor fusion labeling.
Dataloop Platform Interface
Benefits and Key Features
- Offers AI-assisted tools to automate labeling workflows.
- Offers tools to support internal and external labeling teams.
- Offers quality and validation tools to streamline annotation issues.
Best For
Large and small teams working in retail, agriculture, drones, and the medical industries.
Price
The vendor does not provide pricing. Reportedly, it starts from $85/month for 150 annotation tool hours.
Supervisely
Supervisely is a multimodal annotation solution with AI-assisted labeling.

Supervisely Dashboard
Benefits and Key Features
- Provides precise annotation for images and video.
- Features annotation tools for point cloud, LiDAR, and DICOM datasets.
- Uses AI to assist in custom labeling.
Best for
Teams looking for a labeling solution for domain-specific data.
Price
Supervisely offers a free community version and a paid enterprise edition.
KeyLabs
KeyLabs is a multimodal annotation tool with an interactive user interface for labeling graphical and video data.

KeyLabs Interface
Benefits and Key Features
- Offers a user-friendly interface for selecting appropriate annotation techniques like segmentation, classification, shape interpolation, etc.
- Allows users to convert data to JSON.
Best For
Teams looking for a tool with efficient collaboration and access control features.
Price
KeyLabs offers paid versions only. It has Startup, Business, Pro, and Enterprise editions.
Significance of Multimodal Annotation Tools
Global data production is increasing. Numerous public and proprietary data sources are curated every day. We need tools to organize and transform this data at scale to make it suitable for downstream AI tasks. This is why data annotation tools are in high demand. In fact, the global data annotation tools market is projected to grow to USD 14 billion by 2035, compared to USD 1 billion in 2022.
Since real-world data is multimodal, practitioners use multimodal annotation tools to curate datasets. Let’s look at a few factors that make these tools so important.
Efficient Model Training
The primary reason to use a multimodal annotation tool is to automate annotation processes for different modalities since manual data labeling is prone to human error and time-consuming. Such errors diminish training data quality and can lead to poor downstream models with low predictive potential.
High-quality Data Curation
A robust data curation workflow allows labelers to create, organize, and manage data. With multimodal annotation tools, labelers can quickly label data containing multiple modalities and add relevant categorizations. Data teams can readily feed such datasets into models and build high-quality ML pipelines.
Fine-tuning Foundation Models
For AI to address specific challenges, general-purpose multimodal foundation models often need to be fine-tuned. This requires carefully curated data that represents the particular business problem. Multimodal annotation tools help labelers label domain-specific data to train AI models for downstream tasks.
Flexibility in Model Applications
Multimodal annotation enables models to understand information from diverse modalities. This allows practitioners to use AI to the fullest extent in domains such as autonomous driving, medical diagnosis, emotion recognition, etc. However, annotating datasets for such diverse domains is challenging.
Automated multimodal annotation tools provide various labeling solutions, such as labeling and bounding box annotation for object detection and frame classification and complex polygon annotations for segmentation tasks.
Now that we have set the premise for multimodal annotation, let’s explore the technical aspects of this topic by discussing various data annotation types in the next section.
Data Annotation Types and Techniques
Before moving on to the list of the top multimodal annotation tools, let’s first consider the types of annotation techniques labelers use to categorize, classify, and annotate different modalities.
Image Annotation
Practitioners annotate images to help machine learning models learn to recognize different objects or entities they see in an image. This process helps with several AI tasks, such as image classification, image segmentation, and facial recognition.
Common image annotation techniques are:
Bounding Box Annotation
A bounding box is a rectangular shape drawn around the object of interest we want a model to recognize. For instance, labelers can draw rectangles around vehicles and people to train a model for classifying objects on the road. It is useful in cases where precise segmentation is not required, e.g., human detection in surveillance footage.
Bounding Box Annotation Example in Encord Annotate
Semantic Segmentation
It’s a more granular approach where practitioners label each pixel in an image to classify different regions. They draw a closed boundary around the object. Every pixel within the boundary is assigned a single label. For instance, in the illustration below, semantic segmentation draws boundaries for person, bicycle, and background.
Example of Image Segmentation in Encord Annotate
3D Cuboid Annotation
Cuboids are similar to bounding boxes, but instead of two-dimensional rectangles, they wrap three-dimensional cuboids around the object of interest.
Polygon Annotation
This image annotation technique involves drawing 2D shapes or polylines around the edges of the objects of interest for more pixel-perfect precision. Small lines trace a series of x-y coordinates along the edges of objects, making this annotation fine-tuned to various shapes.
Polygon and Polyline Annotation Examples in Encord Annotate
Keypoint Annotation
This annotation involves labeling particular anchor points or landmarks on an object at key locations. These anchor points can track changes in an object's shape, size, and position. It is helpful in tasks like human posture detection.
Primitive (Keypoint or Skelenton) Annotation in Encord Annotate
Text Annotation
Text annotation helps practitioners extract relevant information from text snippets by adding tags or assigning labels to documents or different sections or phrases in a document. Prominent text annotation techniques include:
Sentiment Annotation
Sentiment annotation is used in tasks like user review classification. Text documents are labeled based on the sentiment they represent, such as positive, negative, or neutral. The labels can be more granular depending on the task requirement, e.g., “Angry,” “Disgust,” “Happy,” “Elated,” “Sad,” etc.
Text Classification
It categorizes documents or longer texts into sub-topics or classes. It suits various domains, like legal, finance, and healthcare, to organize and filter documents or smaller pieces of text.
Entity Annotation
It concerns labeling entities within the text, such as names of people, organizations, countries, etc. Natural language processing (NLP) models use labeled entities to learn patterns in text and perform various tasks.
Named Entity Recognition Example
Parts-of-Speech (POS) Tagging
POS tagging involves labeling grammatical aspects, such as nouns, verbs, adjectives, etc., within a sentence.
Audio Annotation
Like text and image, audio annotation refers to labeling audio clips, verbal speech, etc., for training models to interpret audio data. Below are a few common methods.
Speech Transcription
Transcription annotation involves converting the entire speech in an audio or video into text and applying different tags and notes to the text. The annotated text helps train ML models to accurately convert speeches to text format.
Audio Classification
Audio classification involves assigning a single label to an audio clip. For instance, for emotion classification, these labels could be sentiments like happy, sad, angry, etc.; for music classification, these labels can be genres like Jazz, Rock, etc.
Sound Segment Labeling
This involves labeling different segments of an audio wave according to the task at hand. For instance, these labels could differentiate between different instruments and human vocals in a song or tag noise, silence, and sound segments in a clip.
Video Annotation
Video annotation is similar to image annotation since videos are a sequence of static frames. It involves labeling actions, tracking objects, identifying locations, etc., across video frames. Below are a few ways to annotate videos.
Object Tracking
Practitioners label moving objects by tracking their positions in each frame. This is usually done by drawing bounding boxes around the object in each frame.
Video Segmentation
Practitioners categorize the video into short clips based on what’s in each scene or changing camera angles, marking separate boundaries for background and foreground objects across video frames.
Location
Video annotators identify and tag the coordinates of objects of interest in video clips for training models that can recognize particular locations.
Challenges of Multimodal Annotation
Several challenges make multimodal annotation a difficult task for organizations and practitioners. Below are a few problems that teams face when labeling multimodal datasets:
- Data Complexity: As data variety and volume increase, it becomes difficult to segregate different data categories and identify the correct annotation technique. In particular, the emergence of new data types, such as LiDAR and geospatial data, makes identifying the appropriate labeling method challenging.
- Need for Specialized Skills: Expert intervention is necessary when labeling highly domain-specific data, such as medical images. The expertise required can sometimes be niche, making the process even more intricate.
- Absence of Universal Tools: Organizations must find different tools to perform various annotation tasks, as no single tool can meet all objectives.
- Correlations between Modalities: Practitioners must identify relationships between different modalities for correct labeling. For instance, labeling an image may require listening to an audio clip to understand the context. Individually annotating the two modalities can lead to low-quality training data.
- Compliance and Data Privacy: Strict data regulations mean annotators must be careful when analyzing sensitive data elements, such as faces, names, locations, emotions, etc. Incorrect labeling can introduce serious biases and potentially lead to unexpected data leakages.
- Cost: Developing an efficient labeling process is costly. It demands investment in robust storage platforms, specialized teams, and advanced tools.
These challenges make it difficult for AI teams to curate multimodal datasets and build high-quality AI models. However, there are several multimodal annotation tools available on the market that can make annotation workflows more efficient and productive for AI teams.
Let’s explore them in the next section.
Key Factors to Consider Before Selecting the Best Annotation Tool
Choosing a suitable annotation software is daunting as several options exist with different features. Here are the critical factors to prioritize:
- Data Modality Support: Teams must choose tools that support the data modalities they want to work on with all the suitable annotation techniques.
- Ease of Use: Tools with an interactive UI help teams learn new features quickly and reduce the chances of error.
- Security and Compliance: Organizations should opt for solutions that have robust access management and privacy protocols to ensure compliance.
- Scalability: Teams Organizations planning to expand operations should select scalable solutions with minimal dependency on the vendor.
- Integration: A tool seamlessly integrating with other systems helps businesses by lowering setup time and costs.
- Output Format: Tools that readily convert annotated data into an appropriate format are best for teams that don’t want to spend time writing custom code for format conversion.
- Collaboration and Productivity Features: Businesses with large teams working on a single project should select a tool with robust project management features.
- Smart Annotation Techniques: Support for intelligent annotation techniques, such as active learning and overlapping labels, can help teams that want to label extensive datasets.
- Quality Control: Tools should allow AI experts to review annotation samples to avoid errors and maintain a high-quality dataset.
- Community Support: A platform with sufficient community support, helper guides, documentation, etc., is beneficial as it helps teams resolve issues quickly.
- Pricing: Beyond affordability, ensure the tool offers a balance of cost and functionality to give the best return on investment.
Multimodal Annotation Tools: Key Takeaways
- Multimodal annotation refers to labeling different data modalities, such as text, video, audio, and image.
- The need for multimodal annotation tools will increase with rising data volumes and complexity.
- Automated multimodal annotation tools boost labeling speed and improve training data quality.
- Annotating multimodal datasets is challenging due to high costs, hidden correlations between data modalities, and the need for specialized skills.
- Teams must select tools to mitigate such challenges and speed up the ML model development lifecycle.
- There are many annotation tools available. Teams must select the one that suits them best according to price and usability.
Frequently Asked Questions
How do multimodal annotation workflows differ from single-modality workflows?
Multimodal workflows require aligning labels across different data types within the same dataset, such as synchronizing video frames with text or audio transcripts. This adds complexity compared with single-modality annotation, requiring tools that can manage timelines, cross-modal metadata, and coordinated review stages.
Can multimodal annotation tools handle synchronized labeling across video, audio, and text?
Yes, leading multimodal annotation platforms such as Encord provide synchronized labeling interfaces where teams can review and annotate video, audio, and text in a single workspace. Allowing time-aligned annotations across modalities, which is important for use cases like speech-driven video tagging, audiovisual event detection, and caption alignment. Built-in timeline views and cross-modal review workflows help keep annotations consistent across related data streams.
Can Encord integrate with custom annotation tools?
Yes, Encord can be evaluated as a solution to address pain points associated with existing custom annotation tools. It is designed to be scalable and user-friendly, making it a viable alternative for teams looking to enhance their annotation pipeline.
Explore More Multimodal annotation Resources:
Product Demo:
Learning guides:
- Top Multimodal datasets
- Guide to Multimodal Reinforcement Learning
- Top Multimodal Models
- Guide to Multimodal deep learning
Industry & Use case:
Tool Comparison:
Frequently asked questions
Multimodal annotation tools are software solutions that help users label training data from different data modalities, such as text, image, audio, and video.
Multimodal annotation tools help streamline the annotation workflow by automating the labeling process and providing several efficient labeling methods for different data types and use cases.
Image annotation through bounding boxes, polygons, and segmentation; text annotation through document categorization, sentiment classification, and entity recognition; audio annotation by speech transcription, audio classification, and emotion analysis.
Encord Annotate is a suitable alternative to CVAT, providing AI-assisted image and video annotation. You can also consider other tools like Labelbox, LabelImg, and VGG Image Annotator (VIA).
Encord Annotate is a popular tool for OCR annotation tasks. However, the best tool often depends on specific project requirements and personal preferences, as we discussed in this article.
Encord Annotate is a comprehensive image annotation solution offering several labeling methods, including object detection, keypoint skeleton pose, polygons, polylines, etc.
Yes, Encord is designed to facilitate collaboration among several users in the annotation process. It supports multiple annotators working on the same project, allowing for efficient review and management of annotations, which is crucial for projects requiring high accuracy and reliability.
Yes, Encord's annotation tools are versatile and can be customized to suit various sports and contexts. This adaptability allows teams to implement specific tagging strategies that align with the unique requirements of different sports, ensuring high-quality content delivery.
Encord offers a range of annotation services, including traditional bounding box and polygon annotation, as well as support for multi-modal and generative AI use cases. Our team is equipped to handle various types of annotated profiles to meet diverse client needs.
Yes, Encord's annotation platform is designed to be adaptable, enabling users to expand their projects to include a variety of sports. This flexibility allows for the application of multimodal models and enhanced audience engagement across multiple disciplines.
Encord supports a variety of annotation types beyond traditional bounding boxes, including text annotations and complex data structures necessary for multi-modal training. This helps in creating more contextual AI systems that go beyond simple detection tasks.
Encord offers an online annotation platform that facilitates real-time collaboration among team members. Unlike traditional offline tools, Encord enables multiple users to work together seamlessly, ensuring that annotations are consistent and efficient.
Yes, Encord can be evaluated as a solution to address pain points associated with existing custom annotation tools. It is designed to be scalable and user-friendly, making it a viable alternative for teams looking to enhance their annotation pipeline.
Encord's annotation tools are designed to facilitate the efficient labeling of data, which is essential for training machine learning models. The platform supports various annotation types and integrates smoothly with existing workflows.
Yes, Encord has the capability to render webpages within the annotation interface. This allows annotators to tag relevant data directly on the rendered webpage, enhancing the annotation experience.
Yes, Encord supports automation for skeleton annotations and similar tasks, enabling users to improve efficiency and accuracy in their annotation processes.