
The data infrastructure for foundation models that act in the physical world
From egocentric and teleoperation data collection in our own facilities to VLA sequence annotation and alignment at scale - Encord covers the full data pipeline for world models and vision-language-action systems.



VLA and world model training requires more than an annotation tool.
Teams need to collect embodied data at scale, structure video-language-action triplets precisely, curate for scenario diversity, and close the alignment loop — all without building bespoke infrastructure for each step. The teams moving fastest are the ones that don't split this across five vendors. Encord provides a single platform, backed by managed data services, that takes you from raw physical world capture to aligned foundation model training data.
“Encord brought together scalability, video-native annotation, clear label visibility, and the flexibility to support other modalities in a single, cohesive platform.”

Nick Gillian
Founder & Head of AI at Archetype AI
Built for world models and VLAs
Multi-sensor annotation, geospatial-native tooling, and managed data services - all in one platform.

Egocentric and teleoperation data collection
Encord collects egocentric, teleoperation, and embodied data from our own warehouse facilities. We handle structured physical collection programs so your team can focus on model architecture, not data logistics.
Egocentric and teleoperation data collection
Encord collects egocentric, teleoperation, and embodied data from our own warehouse facilities. We handle structured physical collection programs so your team can focus on model architecture, not data logistics.
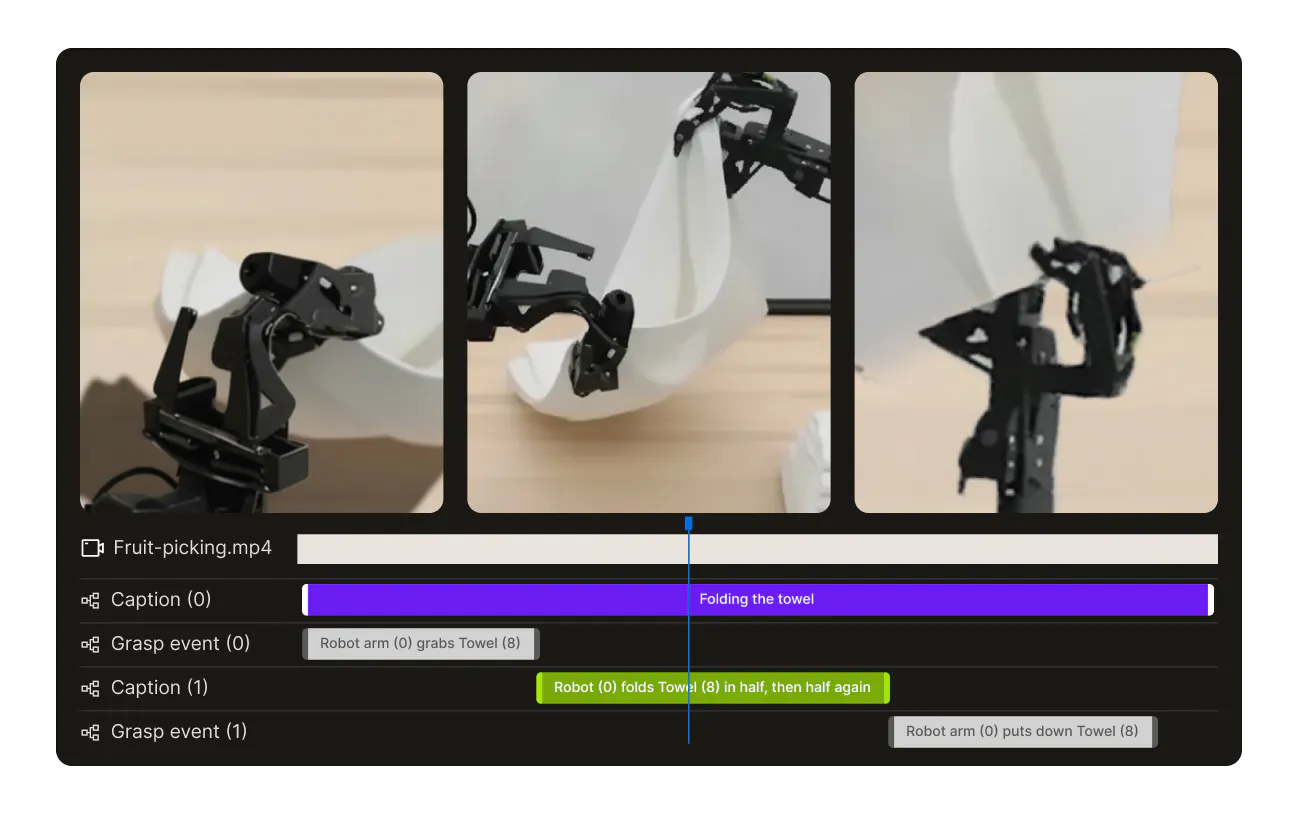
Paired VLA sequence annotation
Annotate video-language-action triplets with precise temporal alignment across observation, instruction, and action streams — the core training data format for VLA models. Covers manipulation, navigation, and multi-step task execution.

Multimodal embeddings and semantic search
Generate and query embeddings across video, language, and sensor modalities to find the training examples that matter — diverse scenarios, rare behaviors, and distribution gaps — before training runs.
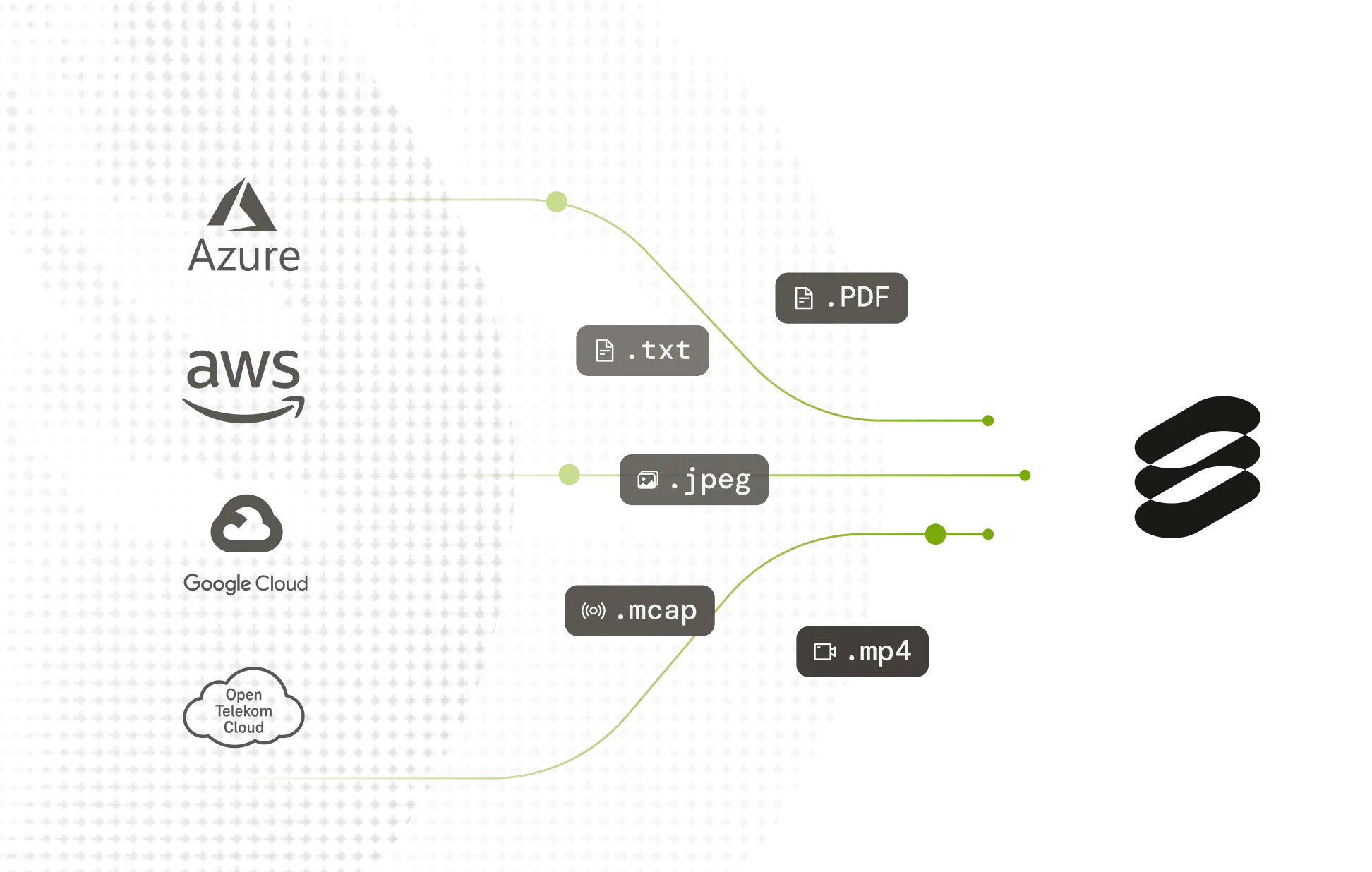
Petabyte-scale data management
Index, filter, and version multimodal datasets at the scale foundation model training requires. Full lineage tracking from raw collection through labeled training set.
Managed annotation services
Expert annotators for VLA and world model data — covering language instruction labeling, action trajectory annotation, preference ranking, and reward model training data. Encord's annotation services team works directly within the platform's quality control framework.

RLHF and preference alignment
Orchestrate human feedback workflows — rubric-based evaluation, pairwise comparison, reward model training — directly alongside your annotation pipelines. No separate tool, no handoff overhead.
RLHF and preference alignment
Orchestrate human feedback workflows — rubric-based evaluation, pairwise comparison, reward model training — directly alongside your annotation pipelines. No separate tool, no handoff overhead.
Our facility,
your protocol.
Whether you’re bringing custom hardware, defining novel task protocols, or scaling to thousands of hours - we adapt every aspect of the collection pipeline to your research requirements.
Supported Data Types

Video
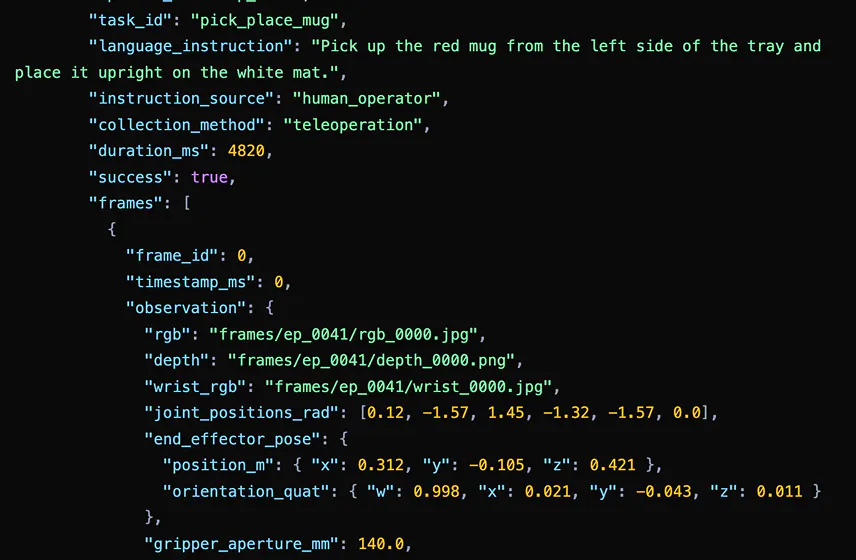
Instruction data

Action trajectories

LiDAR

RGB-D
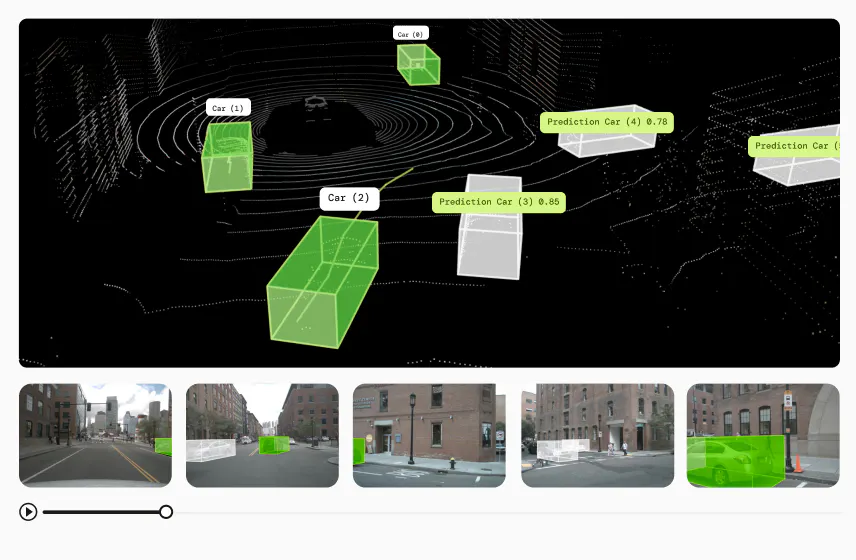
Sensor fusion

Teleop recordings

Egocentric video
Simulation outputs
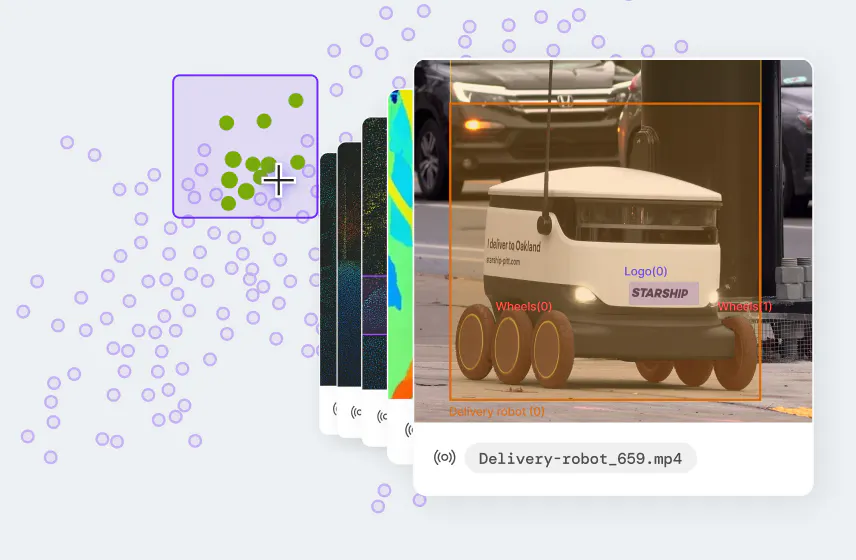
Multimodal embeddings
Proven in production
See how leading AI teams use Encord to move from data to deployment, faster.

Enterprise-grade.
Built for scale.
Designed for reliable AI.
Built for scale.
Designed for reliable AI.
API/SDK-first. Zero data migration. Your data stays in your cloud.
Visit trust centre


Get the data right
300+ of the best AI teams in the world use Encord. Join them.