Mastering Anomaly Detection in AI Training Data

The success of artificial intelligence (AI) models depends heavily on the data. Poor data quality can degrade your model’s performance and cause customers to lose trust in your applications. According to a Gartner report, on average, low-quality data costs organizations around USD 12.9 million annually.
However, maintaining data quality becomes challenging as data volume and variety increase. The task requires organizations to build robust preprocessing and governance frameworks to ensure data is clean, consistent, and accurate. In particular, one of the challenges they face is detecting and resolving data anomalies.
This post will explore anomaly detection, its applications, techniques, and challenges. We will also see how Encord can help streamline anomaly detection workflows.
Why Anomaly Detection?
Anomaly detection algorithms (AD) forecast unusual behaviors that do not align with the expected outcome. These points in overall data lie far away from the normal data. For instance, consider a patient X-ray where physicians diagnose the presence of a disease such as pneumonia or kidney stone.

AD is key to ensuring the data used for decision-making is accurate and trustworthy. It helps:
- Improve Data Insights: In today’s digital age, data is abundant, and every decision is based on its insights. An accurate AD system ensures the data is clean, reliable, and anomaly-free.
- Save Costs: Flawed or skewed data can lead to poor decision-making, which may result in costly mistakes. By detecting and correcting anomalies, AD systems help ensure business decisions are based on accurate data, reducing the risk of financial loss.
Types of Anomaly Detection
Anomalies can be intentional or unintentional. Each type requires a unique fix based on the use case. Let’s explore these categories in more detail to understand their key differences.
Unintentional Anomalies
Noise and errors in the data cause unintentional anomalies. These abnormalities can be random or systemic errors due to faulty sensors or human errors in data curation. They make it harder to draw accurate insights from the data.
Intentional Anomalies
Intentional anomalies are data points that deviate from normal behavior due to planned actions or specific events. Unlike random outliers, these anomalies provide valuable insights by highlighting unusual but predictable occurrences.
For instance, retailers often anticipate a sales spike during peak seasons like Black Friday or Christmas, where planned promotions intentionally create a surge in sales. While this may appear as an anomaly in general data, it is an expected event.
Anomalies in Time Series Data
Anomalies in time series data can be point-based, collective, or contextual.
- Point Anomalies: These are individual data points that deviate from the rest. Errors, random fluctuations, or unusual events may cause them. For example, a patient’s blood pressure suddenly increases well above its usual range, indicating a potential health issue.
- Collective Anomalies: A group of data points that, together, deviate from the norm, even though each point may seem normal on its own. For instance, a normally varied set of purchases on an online clothing store suddenly sees many customers buying the same jacket at once.
- Contextual Anomalies: Data points that appear normal but become anomalous when viewed in context. For example, a temperature of 10°C may be normal in some regions during winter but unusual in others.
Anomaly Detection: Use Cases Across Industries
Anomaly detection has a wide range of applications across the industry. Let’s go over each briefly.
Finance Sector
AD can help identify fraudulent transactions, security breaches, and other financial inconsistencies. For instance, based on users’ historical data, it can help banks detect credit card fraud, trading irregularities, and money laundering incidents.
Manufacturing
AD helps in monitoring equipment and machine performance in the manufacturing domain. It can identify potential failures before they disrupt operations and cause costly downtime.
For example, anomaly detection systems can continuously analyze machine sensor data to detect unusual patterns in predictive maintenance, such as unexpected temperature fluctuations or vibration trends.
Maintenance teams can be involved by forecasting potential issues and flagging these anomalies in a timely manner before a critical failure occurs.
Healthcare
Anomaly detection can help reveal unusual patterns in patient health data, such as the presence of a disease in medical reports or errors in data acquisition. For instance, if a patient’s heart rate suddenly deviates from the normal pattern, the AD system can alert the doctor for immediate examination and treatment.
Cybersecurity
In the cybersecurity domain, AD algorithms often help in intrusion detection to identify suspicious network traffic or potential malware threats. For instance, a popular application is flagging email as spam if it contains a suspicious email address or comes from an unknown sender.
Anomaly Detection Techniques
Several AD detection methods exist for recognizing data outliers, including statistical, machine learning, and deep learning approaches. Let’s examine each of these techniques.
Statistical Methods
Statistical methods detect anomalies by identifying data points that deviate from expected trends using metrics like mean, z-scores, and standard deviations. These methods are generally easy to implement when the dataset size is small or follows a specific data distribution. Standard techniques include interquartile range (IQR) and percentiles.
- Percentile Method: Marks a data point that falls outside a specific percentile range based on observed data patterns.
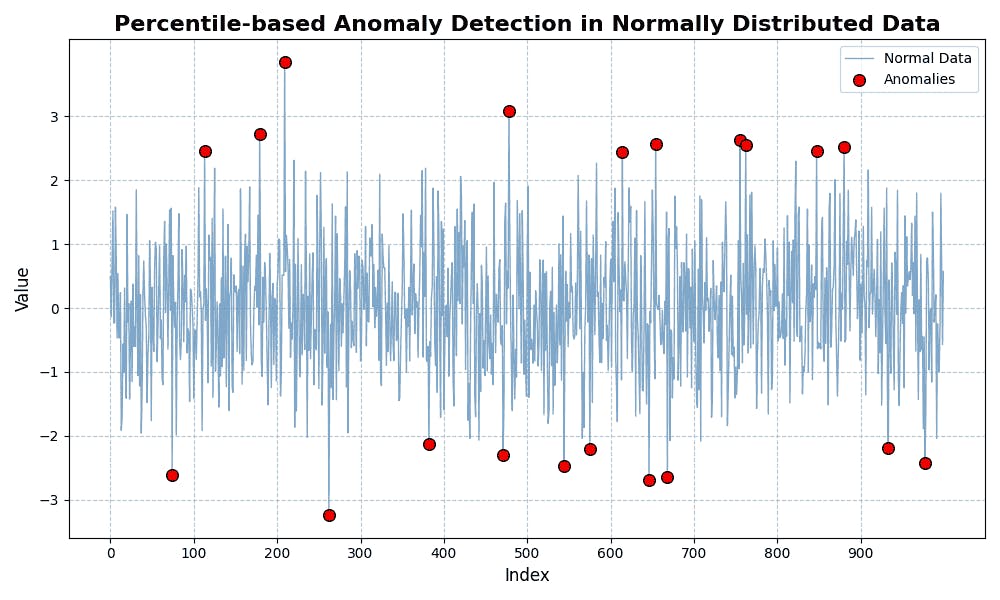
By Author
The figure above illustrates the percentile anomaly by showing the data points outside the 1st and 99th percentile range.
- IQR method: labels data points outside the data's first and third quartile as anomalies.

By Author
The figure illustrates the IQR method. It marks any data point outside the specified IQR range as an outlier, highlighting them in red circles.
Machine Learning Techniques
ML AD techniques are categorized into traditional supervised and unsupervised approaches as well as more advanced DL techniques. They require training data to build a learning classifier that separates expected data points from outliers.
Supervised Learning Methods
Supervised learning methods use labeled data that include normal and anomalous data points. The algorithm learns to draw a decision boundary between these data points. K-nearest neighbors (K-NN) and support vector machines (SVMs) are well-known examples.

By Author
K-NN identifies anomalies based on the distance between a data point and its neighbors. A point is considered anomalous if it is far from its nearest neighbors, indicating that it is different from the majority of the data.
SVM, in contrast, is a large-margin classifier that classifies data by finding a hyperplane that separates different classes. The hyperplane is the decision boundary that maximizes the distance between the nearest point of each class.
Unsupervised Learning Methods
Unsupervised models use unlabeled data to detect anomalies. They include methods like the Isolation Forest, local outlier factor (lof), and k-means.algorithm. They detect unusual patterns in data without knowing the expected outcome.
However, unsupervised algorithms do not indicate the significance of a particular anomaly. For instance, an unsupervised model may highlight anomalies in an X-ray image dataset. Since the anomalous images have no labels attached, there’s no way to directly associate the anomaly with a severity level or risk factor. This limitation can lead to false positives and false negatives. Popular unsupervised AD algorithms are
Deep Learning (DL) Methods
Unlike classical ML methods, which rely on simpler algorithms, DL techniques use more advanced and complex algorithms. While ML techniques may compute straightforward decision boundaries, DL involves neural networks for extracting intricate features within the data. An Autoencoder (AE) is a DL architecture often used for AD.
It consists of an encoder, which maps the input data to a lower-dimensional latent space, and a decoder, which reconstructs the original data from this latent representation. It uses the reconstruction loss to assign an anomaly score. A higher score indicates the presence of significant anomalies in the data sample.

Anomaly Detection Using Auto-Encoder
As the figure indicates, a data point is marked as an anomaly if the reconstruction error exceeds the threshold.
Building an Anomaly Detection Pipeline
Despite the above mentioned methods, detecting anomalies in extensive datasets can be challenging. A more efficient approach is to develop a robust detection pipeline that automatically flags anomalies as they occur.
While the exact steps to build a pipeline can vary from case to case, the guidelines below provide a practical starting point.
Identify Objectives and Define Expectations
Start by defining what types of anomalies you want to detect. This step also involves setting clear expectations for metrics like accuracy and false positive rate. The approach will ensure your pipeline detects anomalies according to your project’s requirements.
Data Collection and Preprocessing
Data collection and preprocessing are the next steps. It consists of the following:
- Data Acquisition: Acquire data that includes both normal and abnormal data. For instance, fraudulent activity detection may include transaction histories, known fraud cases, and user activities.
- Data Cleaning: Normalizing data spanning over different scales, handling missing values, properly addressing outlier values in the data, and validating data accuracy.
- Feature Engineering: Identifying features that capture the nuances in the data, creating new features, or addressing redundant features in a more compact feature space.
Select the Appropriate Model for Training
Selecting an appropriate model for your application is critical. Use classical ML techniques where low latency is desired. However, you can use more advanced algorithms if the objective is high accuracy. Let’s discuss some of the state-of-the-art (SOTA) models that could be used for building robust AD systems.
- Variational Autoencoders (VAE): VAEs are a more advanced form of AE that analyzes complex patterns in the data. VAE addresses the issue of an unregularized latent space. This means the VAE encoder also returns parameters of the latent distribution, such as the mean and standard deviation for each input. Unlike a regular autoencoder (AE), which learns direct mapping, VAE learns a probabilistic distribution over the latent space, enabling better generalization and sampling.

Encoder transforms high dimensional data (X) to latent space Z. Z with some mean and standard deviation projected back to the original data (X’). These architectures are suitable where the data is large and high accuracy is desired.
- Generative Adversarial Networks (GANS): GANS consists of a generator and discriminator. The generator creates the fake data, and the discriminator distinguishes this data from the real data. A large discriminator loss classifies each example into real or fake. The points classified as fake can be considered outliers. However, this requires that the generator is trained properly on the expected data distribution.
Model Training
To train a suitable model, ensure that the dataset is balanced between normal and anomalous data. If a balanced dataset is not available, it becomes crucial to explore alternative methods for handling the imbalance.
Techniques like weighted loss can help address data imbalance if balanced data is unavailable. Optimization of hyperparameters plays a key role in enhancing model performance by improving accuracy and reducing overfitting.
Evaluation
After the model has been trained, measure its performance using accuracy, precision, recall, F1, or any other relevant metric on unseen new data. This ensures that the application meets the performance standards.
Refinements
After successfully evaluating the model on the test set, the next step is to deploy it for user requests. Post-deployment, continuous monitoring of the anomaly detection system is crucial.
If there are changes in the data distribution, fine-tuning a new distribution can address it. Statistical metrics such as the Kolmogorov-Smirnov test and Chi-square test can be used to detect shifts in data distribution.
Anomaly Detection Challenges
While the AD system can be beneficial for predicting anomalous events, some challenges remain. Let's look at some common issues when implementing an anomaly detection system.
Data Quality
Poor data may involve incomplete datasets, inconsistent formats, different scales of features, duplicate data, and human error during data collection. These issues can lead to inaccurate anomaly detection, resulting in missed anomalies or excessive false positives.
Training Size
With limited data, the model may struggle to generalize well, leading to overfitting. In this case, the model learns the noise of the small dataset rather than generalizable features. This can result in poor performance on unseen data.
Additionally, detecting anomalies in a small dataset may cause the model to miss subtle or falsely flag normal data points as anomalous.
Imbalanced Distributions
AD methods that rely on supervised learning can suffer from a class imbalance in training datasets. In practice, most data points are normal. For instance, in a disease classification task, most samples are negative, with only a small proportion being positive. As a result, the model may lack sufficient anomalous data points, causing it to become biased toward the normal class.
False Positives
Another issue with AD systems is false alerts, which can happen due to an incorrect confidence threshold or models that are overfitting or underfitting.
Frequent false alerts can lead users to lose trust in the system and start ignoring them. However, if a legitimate alert is missed due to this loss of trust, it could have serious consequences.
{light_callout_start}} Learn how outlier detection can boost your data science workflow and improve training data: {{light_callout_end}
How Encord Ensures Clean and High-quality Data for Anomaly Detection Models
Developers can address the AD challenges using specialized tools for data preprocessing, validation, deployment, and refinement. Numerous open-source tools and frameworks are available; however, they may lack the advanced functionality needed to build accurate solutions for AD.
The development of AD systems can require more comprehensive third-party solutions with advanced features to address AD challenges in a single platform. Encord is one such option.
Encord is an end-to-end data management platform for efficient data curation, labeling, and evaluation. Let’s see how Encord’s features can help you mitigate some of the challenges discussed above.

Tagging label outliers with Encord Active
Key Features
- Managing Data Quality and Quantity for Anomaly Detection: Encord helps you manage multimodal data, including structured and unstructured data such as audio, video, text, and images in a large quantity.
- Appropriate Model Selection and Analysis: Using Encord Active, the user can assess data and AI model quality through different performance metrics to analyze its suitability for different scenarios. Encord’s Python SDK can also help develop custom monitoring pipelines.
- Scalability: Encord enables you to easily scale your Anomaly Detection (AD) models by handling large datasets. The platform allows you to upload up to 10,000 data units in a single dataset, and you can organize multiple datasets to manage larger projects. It also supports uploading up to 200,000 frames per video at once for video anomaly analysis.
G2 Review
Encord has a rating of 4.8/5 based on 60 reviews. Users highlight the tool’s simplicity, intuitive interface, and several annotation options as its most significant benefits.
However, they suggest a few areas for improvement, including more customization options for tool settings and faster model-assisted labeling.
Overall, Encord’s ease of setup and quick return on investments make it popular among AI experts.
{{light_callout_start} } Learn how to use Encord Active to enhance data quality using end-to-end data preprocessing techniques.
Anomaly Detection: Key Takeaways
The effectiveness of AD systems relies on data volume, quality, and choice of the algorithm. Below are some of the key points to remember regarding the AD system:
- Advantages of AD: AD offers several key benefits, such as improving data quality by identifying outliers, enhancing security through fraud detection, and providing early warnings for system failures or abnormal behavior.
- AD Challenges: Building an accurate AD model requires addressing issues such as data quality, data volume, imbalanced data distribution, and false alerts.
- Encord for AD: Encord offers data cleaning, annotation, and refinement solutions to develop precise and reliable anomaly detection solutions.