Convolutional Neural Networks (CNN) Overview

Product Manager at Encord
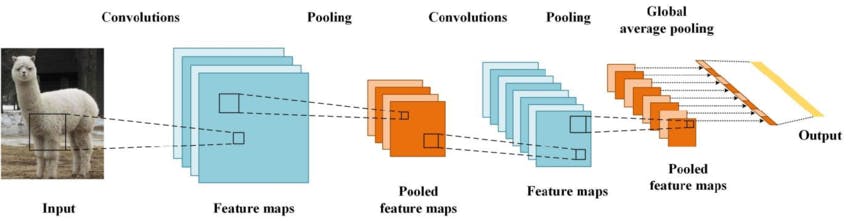
Convolutional Neural Networks (CNNs) are a powerful tool for image analysis that can be used for tasks such as image classification, object detection, and semantic segmentation.
As defined by Aparna Goel “A Convolutional Neural Network is a type of deep learning algorithm that is particularly well-suited for image recognition and processing tasks. It is made up of multiple layers, including convolutional layers, pooling layers, and fully connected layers.”
In this article, we will dive into:
- Basics of Convolutional Neural Networks
- Convolution and Filter Application
- Pooling Operations & Techniques
- Activation Functions in CNNs
- Architectures and Variants of CNNs
- Tips and Tricks for Training CNNs
- Applications of CNNs
- CNN: Key Takeaways

Basics of Convolutional Neural Networks
CNNs work by extracting features from images using convolutional layers, pooling layers, and activation functions. These layers allow CNNs to learn complex relationships between features, identify objects or features regardless of their position, and reduce the computational complexity of the network.
Feature maps
Feature maps are a key concept in CNNs, which are generated by convolving filters over the input image, and each filter specializes in detecting specific features. The feature maps serve as the input for subsequent layers, enabling the network to learn higher-level features and make accurate predictions.
Parameter sharing
Parameter sharing is another critical aspect of CNNs. It allows the network to detect similar patterns regardless of their location in the image, promoting spatial invariance. This enhances the network's robustness and generalization ability. Understanding these key components of CNNs is essential for unlocking their full potential in visual data analysis.
Convolutional Neural Networks vs Recurrent Neural Networks
While Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are different architectures designed for different tasks, they share some similarities in their ability to capture and process sequential data. Both CNNs and RNNs operate on local receptive fields. CNNs and some variants of RNNs, such as Long Short-Term Memory (LSTM), utilize parameter sharing. CNNs are also being increasingly used in conjunction with other machine learning techniques, such as natural language processing.
Convolutional Layer
Convolutional layers in CNNs extract features from input images through convolution, filter application, and the use of multiple filters.
Convolution and Filter Application
Convolution applies filters to the input image, sliding across and generating feature maps, while filters are small tensors with learnable weights, capturing specific patterns or features. Multiple filters detect various visual features simultaneously, enabling rich representation.
Padding and Stride Choices
Padding preserves spatial dimensions by adding pixels around the input image. Stride determines the shift of the filter's position during convolution. Proper choices control output size, spatial information, and receptive fields. Zero padding is a technique used in CNNs to maintain the spatial dimensions of feature maps when applying convolutional operations. It involves adding extra rows and columns of zeros around the input, which helps preserve the size and resolution of the feature maps during the convolution process and prevents information loss at the borders of the input data.
Multiple Filters for Feature Extraction
Each filter specializes in detecting specific patterns or features. Multiple filters capture diverse aspects of the input image simultaneously, while filter weights are learned through training, allowing adaptation to relevant patterns. The filter size in CNNs plays a crucial role in feature extraction, influencing the network's ability to detect and capture relevant patterns and structures in the input data.
Understanding convolution, padding, stride, and multiple filters is crucial for feature extraction in CNNs, facilitating the identification of patterns, spatial information capture, and building robust visual representations.
Pooling Operations
Pooling layers are an integral part of Convolutional Neural Networks (CNNs) and play a crucial role in downsampling feature maps while retaining important features. In this section, explore the purpose of pooling layers, commonly used pooling techniques such as max pooling and average pooling, and how pooling helps reduce spatial dimensions.
Purpose of Pooling Layers
Pooling layers are different type of layers, primarily employed to downsample the feature maps generated by convolutional layers. The downsampling process reduces the spatial dimensions of the feature maps, resulting in a compressed representation of the input. By reducing the spatial dimensions, pooling layers enhance computational efficiency and address the problem of overfitting by reducing the number of parameters in subsequent layers. Additionally, pooling layers help in capturing and retaining the most salient features while discarding less relevant or noisy information.
Pooling Techniques
Two popular pooling techniques employed in CNNs are max pooling and average pooling.
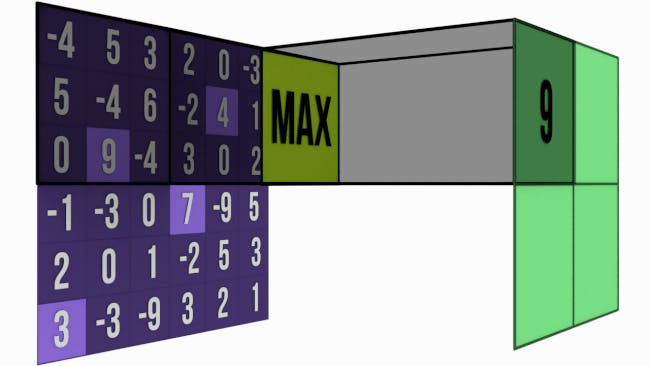
Max pooling selects the maximum value from a specific window or region within the feature map. It preserves the most prominent features detected by the corresponding convolutional filters.
Average pooling calculates the average value of the window, providing a smoothed representation of the features.
Both techniques contribute to reducing spatial dimensions while retaining important features, but they differ in their emphasis. Max pooling tends to focus on the most significant activations, while average pooling provides a more generalized representation of the features in the window.
Reducing Spatial Dimensions and Retaining Important Features
Pooling operations help reduce spatial dimensions while retaining crucial features in several ways. First, by downsampling the feature maps, pooling layers decrease the number of parameters, which in turn reduces computational complexity. This downsampling facilitates faster computation and enables the network to process larger input volumes efficiently. To add further context related to pooling operations in CNNs, it's worth mentioning that strides can serve the purpose of downsampling as well, particularly when the stride value is greater than 1.
Second, pooling layers act as a form of regularization, aiding in preventing overfitting by enforcing spatial invariance. By aggregating features within a pooling window, pooling layers ensure that small spatial shifts in the input do not significantly affect the output, promoting robustness and generalization.
Lastly, by selecting the maximum or average activations within each window, pooling layers retain the most important and informative features while reducing noise and irrelevant variations present in the feature maps.
Understanding the purpose of pooling layers, the techniques employed, and their impact on downsampling and feature retention provides valuable insights into the role of pooling in CNNs. These operations contribute to efficient computation, regularization, and the extraction of important visual features, ultimately enhancing the network's ability to learn and make accurate predictions on complex visual data.
Activation Functions in Convolutional Neural Networks (CNNs)
Activation functions are essential in Convolutional Neural Networks (CNNs) as they introduce non-linearity, enabling the network to learn complex feature relationships. In this section, the popular activation functions used in CNNs, including ReLU, sigmoid, and tanh, are discussed. The properties, advantages, and limitations of these activation functions are explored, highlighting their significance in introducing non-linearity to the network.
ReLU (Rectified Linear Unit)
ReLU is widely used, setting negative values to zero and keeping positive values unchanged. It promotes sparsity in activations, allowing the network to focus on relevant features. ReLU is computationally efficient and facilitates fast convergence during training. However, it can suffer from dead neurons and unbounded activations in deeper networks.
Sigmoid
Sigmoid squashes activations between 0 and 1, making it suitable for binary classification tasks and capturing non-linearity within a limited range. It is differentiable, enabling efficient backpropagation, but is susceptible to the vanishing gradient problem and may not be ideal for deep networks.
Tanh
Tanh maps activations to the range -1 to 1, capturing non-linearity within a bounded output. It has a steeper gradient than sigmoid, making it useful for learning complex representations and facilitating better gradient flow during backpropagation. However, it also faces the vanishing gradient problem.
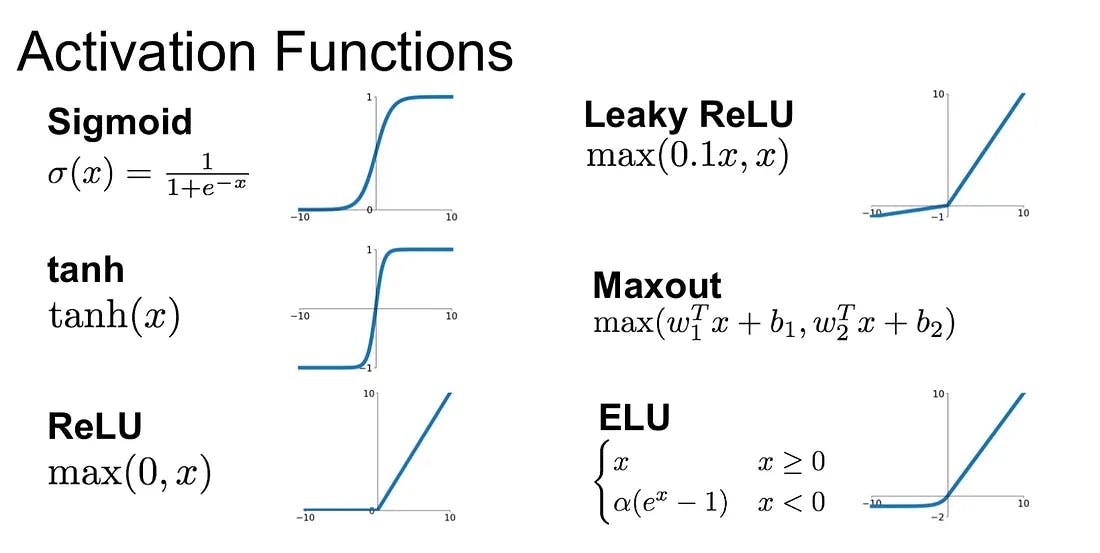
Activation functions are crucial as they introduce non-linearity, enabling CNNs to model complex relationships and capture intricate patterns. Non-linearity allows CNNs to approximate complex functions and tackle tasks like image recognition and object detection. Understanding the properties and trade-offs of activation functions empowers informed choices in designing CNN architectures, leveraging their strengths to unlock the network's full expressive power.
By selecting appropriate activation functions, CNNs can learn rich representations and effectively handle challenging tasks, enhancing their overall performance and capabilities.
Architectures and Variants of Convolutional Neural Networks (CNNs)
Architecture of a traditional CNN (Convolutional Neural Network) has witnessed significant advancements over the years, with various architectures and variants emerging as influential contributions to the field of computer vision. In this section, notable CNN architectures, such as LeNet-5, AlexNet, VGGNet, and ResNet, are discussed, highlighting their unique features, layer configurations, and contributions. Additionally, popular variants like InceptionNet, DenseNet, and MobileNet are mentioned.
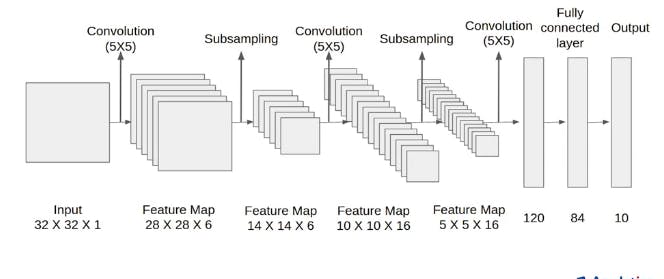
LeNet-5
LeNet-5, introduced by Yann LeCun et al. in 1998, was one of the pioneering CNN architectures. It was designed for handwritten digit recognition and consisted of two convolutional layers, followed by average pooling, fully connected layers, and a softmax output layer. LeNet-5's lightweight architecture and efficient use of shared weights laid the foundation for modern CNNs, influencing subsequent developments in the field.
AlexNet
AlexNet developed by Alex Krizhevsky et al. in 2012, made significant strides in image classification. It won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012 and achieved a significant improvement over previous methods. AlexNet featured a deeper architecture with multiple convolutional layers, introduced the concept of ReLU activations, and employed techniques like dropout for regularization. Its success paved the way for the resurgence of deep learning in computer vision.
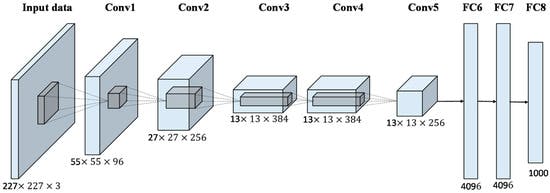
Pre-Trained AlexNet Architecture
VGGNet
VGGNet, proposed by Karen Simonyan and Andrew Zisserman in 2014, introduced deeper architectures with up to 19 layers. VGGNet's key characteristic was the consistent use of 3x3 convolutional filters throughout the network, which enabled better modeling of complex visual patterns. The VGGNet architecture is known for its simplicity and effectiveness, and it has served as a baseline for subsequent CNN models.
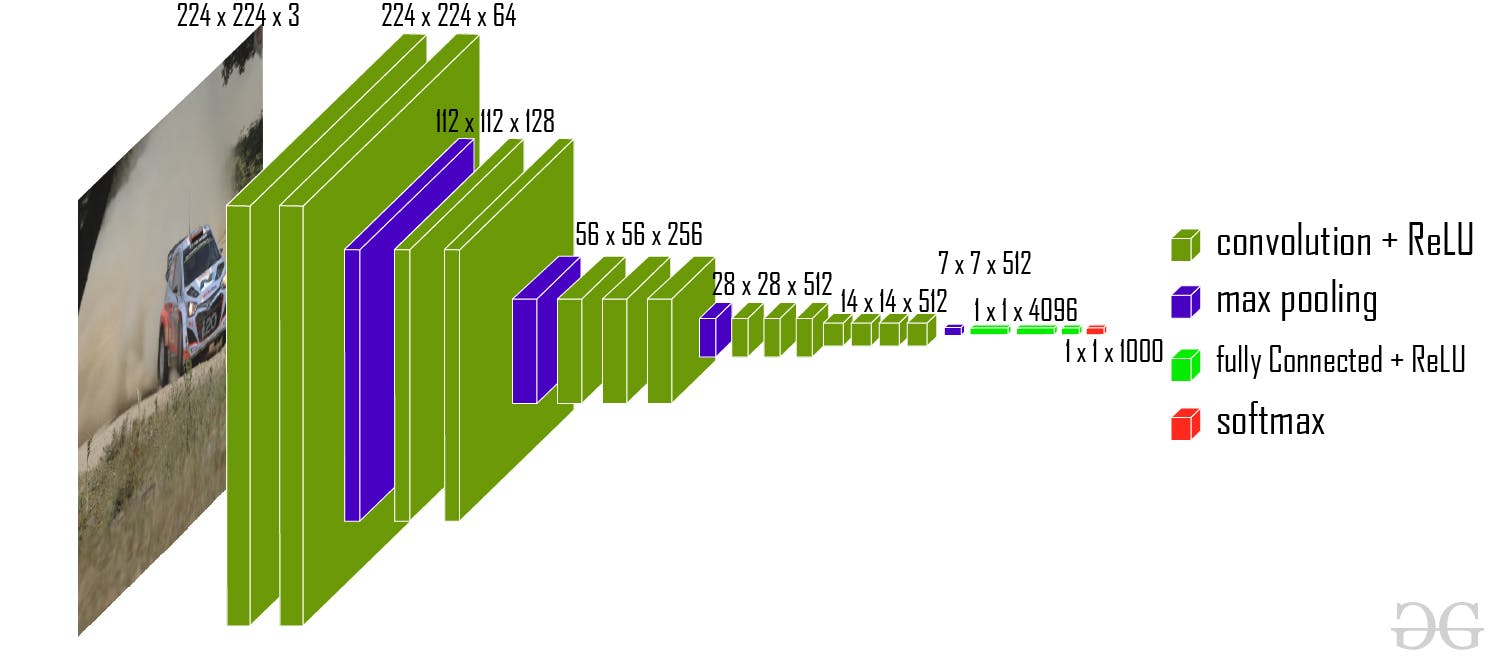
ResNet
ResNet developed by Kaiming He et al. in 2015, brought significant advancements in training very deep neural networks. ResNet introduced the concept of residual connections, allowing information to bypass certain layers and alleviating the vanishing gradient problem. This breakthrough enabled the successful training of CNNs with 50, 100, or even more layers. ResNet's skip connections revolutionized deep learning architectures and enabled the training of extremely deep and accurate networks.
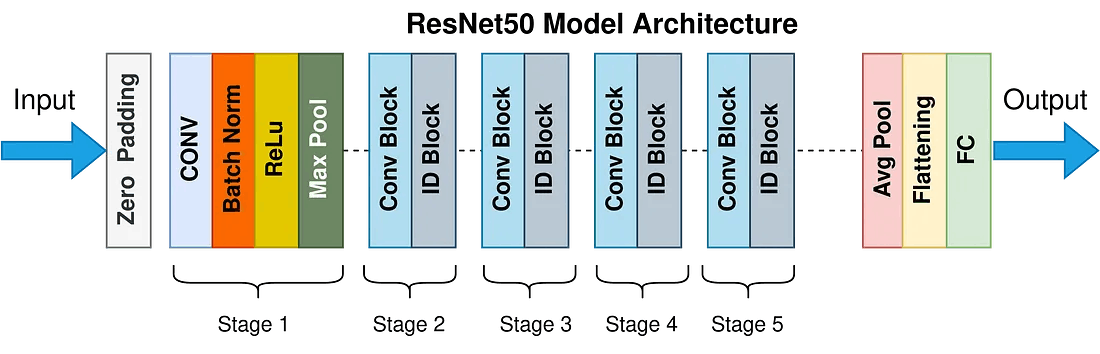
Some other notable variants are InceptionNet, DenseNet, and MobileNet that have made significant contributions to the field of computer vision. InceptionNet introduced the concept of inception modules,DenseNet featured dense connections between layers and MobileNet focused on efficient architectures for mobile and embedded devices.
Modifying the output layer and loss function allows CNNs to be utilized for regression tasks. Although CNNs are typically linked with classification tasks, they can also be employed to address regression problems involving continuous variable prediction or numeric value estimation.
Tips and Tricks for Training Convolutional Neural Networks (CNNs)
Training Convolutional Neural Networks (CNNs) effectively requires careful consideration of various factors and the application of specific algorithms and techniques. This section provides practical advice for training CNNs, including data augmentation, regularization algorithms, learning rate schedules, handling overfitting with algorithmic approaches, and improving generalization using advanced algorithms known as Hyperparameters.
Hyperparameters refer to the settings and configurations that are set before training the model. These parameters are not learned from the data but are manually defined by the user. Fine-tuning these hyperparameters can significantly impact the performance and training of the CNN model. Common metrics for training CNN models include accuracy, precision, recall, F1 score, and confusion metrics. It often requires experimentation and tuning to find the optimal combination of hyperparameters that results in the best model performance for a specific task or dataset. Another popular deep learning library, that provides a high-level interface for building and training neural networks, including CNNs is Keras.
Data augmentation
This is a powerful technique to expand the training dataset by applying random transformations to the existing data. It helps in reducing overfitting and improves model generalization. Common data augmentation techniques for images include random rotations, translations, flips, zooms, and brightness adjustments. Applying these transformations increases the diversity of the training data, enabling the model to learn robust and invariant features.
Regularization methods
Regularization methods prevent overfitting and improve model generalization. Two widely used regularization techniques are L1 and L2 regularization, which add penalties to the loss function based on the magnitudes of the model's weights. This discourages large weight values and promotes simpler models. Another effective technique is dropout, which randomly sets a fraction of the neurons to zero during training, forcing the network to learn more robust and redundant representations.
Learning Rate Schedules
Optimizing the learning rate is crucial for successful training. Gradually reducing the learning rate over time (learning rate decay) or decreasing it when the validation loss plateaus (learning rate scheduling) can help the model converge to better solutions. Techniques like step decay, exponential decay, or cyclical learning rates can be employed to find an optimal learning rate schedule for the specific task.
Normalization
In CNNs, normalization is an approach employed to preprocess input data and guarantee uniform scaling of features. Its purpose is to facilitate quicker convergence during training, prevent numerical instabilities, and enhance the network's overall stability and performance.
Applications of Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) have extended their impact beyond image classification, finding applications in various domains that require advanced visual analysis. This section highlights diverse applications of CNNs, such as object detection, semantic segmentation, and image generation.
 💡 Notable use cases and success stories in different domains can be found here.
💡 Notable use cases and success stories in different domains can be found here. Object Detection
CNNs have revolutionized object detection by enabling the precise localization and classification of objects within an image. Techniques like region-based CNNs (R-CNN), Faster R-CNN, and You Only Look Once (YOLO) have significantly advanced the field. Object detection has numerous applications, including autonomous driving, surveillance systems, and medical imaging.
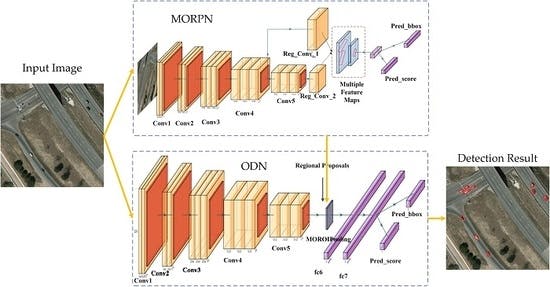
Semantic Segmentation
CNNs excel in semantic segmentation, where the goal is to assign a class label to each pixel in an image, enabling fine-grained understanding of object boundaries and detailed scene analysis. U-Net, Fully Convolutional Networks (FCN), and DeepLab are popular architectures for semantic segmentation. Applications range from medical image analysis and autonomous navigation to scene understanding in robotics.
💡 Interested in learning more about Semantic Segmentation? Read our Introduction to Semantic Segmentation. Image Generation
CNNs have demonstrated remarkable capabilities in generating realistic and novel images. Generative Adversarial Networks (GANs) leverage CNN architectures to learn the underlying distribution of training images and generate new samples. StyleGAN, CycleGAN, and Pix2Pix are notable examples that have been used for image synthesis, style transfer, and data augmentation.
CNNs excel in healthcare (diagnosis, patient outcomes), agriculture (crop health, disease detection), retail (product recognition, recommendations), security (surveillance, facial recognition), and entertainment (CGI, content recommendation).
💡Ready to bring your first machine learning model to life? Read How to Build Your First Machine Learning Model to kickstart your journey. Convolutional Neural Network (CNN): Key Takeaways
- Convolutional neural networks (CNNs) are a powerful tool for extracting meaningful features from visual data.
- CNNs are composed of a series of convolutional layers, pooling layers, and fully connected layers; convolutional layers apply filters to the input data to extract features, pooling layers reduce the size of the feature maps to prevent overfitting, and fully connected layers connect all neurons in one layer to all neurons in the next layer.
- CNNs can be used for a variety of tasks, including image classification, object detection, and semantic segmentation.
- Some notable CNN architectures include LeNet-5, AlexNet, VGGNet, and ResNet, InceptionNet, DenseNet, and MobileNet.
- CNNs are a rapidly evolving field, and new architectures and techniques are constantly being developed.
Frequently asked questions
A CNN is a kind of network architecture for deep learning algorithms that utilize convolution operation and is specifically used for image recognition and tasks that involve the processing of pixel data. There are other types of neural networks in deep learning, but for identifying and recognizing objects, CNNs are the network architecture of choice.
A convolutional neural network can have tens or hundreds of layers that each learn to detect different features of an image. Filters are applied to each training image at different resolutions, and the output of each convolved image is used as the input to the next layer. The filters can start as very simple features, such as brightness and edges, and increase in complexity to features that uniquely define the object.
Once trained, a CNN can be used to classify new images, or extract features for use in other applications such as object detection or image segmentation. CNNs have achieved state-of-the-art performance on a wide range of image recognition tasks, including object classification, object detection, and image segmentation.
CNNs also have some drawbacks that limit their performance and applicability. One of the main disadvantages of CNNs is that they require a large amount of labeled data to train effectively, which can be costly and time-consuming to obtain and annotate.
One of the future trends in CNN research is the development of more efficient architectures. Another trend is the development of new techniques for training CNNs, such as using reinforcement learning. CNNs are also being increasingly used in conjunction with other machine learning techniques, such as natural language processing.
Hyperparameters in CNNs refer to the settings and configurations that are set before training the model. These parameters are not learned from the data but are manually defined by the user. Examples of CNN hyperparameters include the learning rate, batch size, number of layers, filter size, kernel size, stride, activation functions, and dropout rate. Fine-tuning these hyperparameters can significantly impact the performance and training of the CNN model. It often requires experimentation and tuning to find the optimal combination of hyperparameters that results in the best model performance for a specific task or dataset.
CNNs are a class of deep learning models commonly used in data science for tasks like image recognition, object detection, and natural language processing. They excel at capturing spatial features in grid-like data structures, making them valuable for analyzing and extracting patterns from visual and sequential data.
Yes, ChatGPT can be used in conjunction with CNNs for various natural language processing tasks. While CNNs are typically used for feature extraction from textual data, ChatGPT can provide contextual understanding and generate human-like responses, complementing the feature extraction capabilities of CNNs.
Keras is a popular deep learning library that provides a high-level interface for building and training neural networks, including CNNs. It offers user-friendly functions and tools for defining CNN architectures, configuring layers, specifying loss functions, and optimizing network performance.
Common metrics for evaluating CNN models include mAP, IoU for detection/segmentations. These metrics measure the performance of the model in terms of classification accuracy and the ability to correctly identify different classes or categories.
Normalization is a technique used in CNNs to preprocess input data and ensure that the features have a consistent scale. It helps in achieving faster convergence during training, avoids numerical instabilities, and improves the overall stability and performance of the network.
Yes, CNNs can be adapted for regression tasks by modifying the output layer and loss function. While CNNs are commonly associated with classification tasks, they can also be employed for regression problems, such as predicting continuous variables or estimating numeric values.
Common types of layers in CNN architectures include convolutional layers, pooling layers, fully connected layers, and activation layers. These layers work together to extract features from input data, reduce dimensionality, and make predictions based on learned representations.
Zero padding is a technique used in CNNs to maintain the spatial dimensions of feature maps when applying convolutional operations. It involves adding extra rows and columns of zeros around the input, which helps preserve the size and resolution of the feature maps during the convolution process and prevents information loss at the borders of the input data.
Encord simplifies the ingestion and processing of various data modalities by providing a unified platform that handles labeling and testing, allowing for seamless integration of human input and automation. This ensures that companies can build better models faster by efficiently managing diverse data types.
Encord differentiates itself through its focus on user-friendly interfaces and powerful features tailored for machine learning applications. The platform is specifically designed to simplify the complexities of data annotation, making it easier for teams to manage large datasets and collaborate effectively.
Encord automates and streamlines data operations, integrating them with model operations throughout the entire machine learning pipeline. This connection ensures that model evaluation and data management are efficient, facilitating smoother transitions from data ingestion to model training and deployment.
Encord simplifies the addition of new features and functionalities by providing flexible labeling strategies and tools that can be readily adapted. This minimizes the need for extensive development of new tooling while ensuring that the labeling process remains effective as requirements evolve.
Encord allows for annotation flexibility, meaning the labels assigned to images can change depending on the specific project requirements. This adaptability is crucial for projects that involve object detection, as it accommodates varying labeling needs across different scenarios.
Encord supports seamless API integrations, enabling teams to easily upload data, manage annotations, and streamline the entire data operations process. This helps in reducing the workload and improving the efficiency of backend teams handling multiple API calls.
Encord supports two main methods for data uploads: directly to Encord from edge devices or through cloud integrations. Typically, data captured via a front-end application is placed into a cloud bucket, where it can be linked to Encord for further processing.
Encord is designed with user-friendliness in mind, making it accessible for teams that may not have a technical background. Its intuitive interface and comprehensive support features enable users to leverage powerful annotation tools effectively.
Encord offers specific tools for developing and refining facial recognition models. This includes features for annotating facial data, which is crucial for training models that require high accuracy in identifying and recognizing individuals.
Encord's API enables automation of the annotation workflow, making it easier to integrate with existing systems. This streamlines operations, especially when managing multiple pipelines simultaneously.