Data Lake Explained: A Comprehensive Guide for ML Teams

It has been 12 years since the New York Times published an interesting article on ‘The Age of Big Data,’ in which most of the talk and tooling were centered around analytics. Fast-forward to today, and we are continuously grappling with the influx of data at the petabyte (PB) and zettabyte (ZB) scales, which is getting increasingly complex in dimensions (images, videos, point cloud data, etc.).
It is clear that solutions that can help manage the size and complexity of data are needed for organizational success. This has urged data, AI, and technology teams to look towards three pivotal data management solutions: data lakes, data warehouses, and cloud services.
This article focuses on understanding data lakes as a data management solution for machine learning (ML) teams. You will learn:
- What a data lake is and how it differs from a data warehouse.
- Benefits and limitations of a data lake for ML teams.
- The data lake architecture.
- Best practices for setting up a data lake.
- On-premise vs. cloud-based data lakes.
- Computer vision use cases of data lakes.
- A data lake is a centralized repository for diverse, structured, and unstructured data.
- Key architecture components include Data Sources, Data Ingestion, Data Persistence and Storage, Data Processing Layer, Analytical Sandboxes, Data Lake Zones, and Data Consumption.
- Best practices for data lakes involve defining clear objectives, robust data governance, scalability, prioritizing security, encouraging a data-driven culture, and quality control.
- On-premises data lakes offer control and security; cloud-based data lakes provide scalability and cost efficiency.
- Data lakes are evolving with advanced analytics and computer vision use cases, emphasizing the need for adaptable systems and adopting forward-thinking strategies.
Overview: Data Warehousing, Data Lake, and Cloud Storage
Data Warehouses
A data warehouse is a single location where an organization's structured data is consolidated, transformed, and stored for query and analysis. The structured data is ideal for generating reports and conducting analytics that inform business decisions.
Limitations
- Limited agility in handling unstructured or semi-structured data.
- Can create data silos, hindering cross-departmental data sharing.
Data Lakes
A data lake stores vast amounts of raw datasets in their native format until needed, which includes structured, semi-structured, and unstructured data. This flexibility supports diverse applications, from computer vision use cases to real-time analytics.
Challenges
- Risk of becoming a "data swamp" if not properly managed, with unclear, unclean, or redundant data.
- Requires robust metadata and governance practices to ensure data is findable and usable.
Cloud Storage and Computing
Cloud computing encompasses a broad spectrum of services beyond storage, such as processing power and advanced analytics. Cloud storage refers explicitly to storing data on the internet through a cloud computing provider that manages and operates data storage as a service.
Risks
- Security concerns, requiring stringent data access controls and encryption.
- Potential for unexpected costs if usage is not monitored.
- Dependence on the service provider's reliability and continuity.
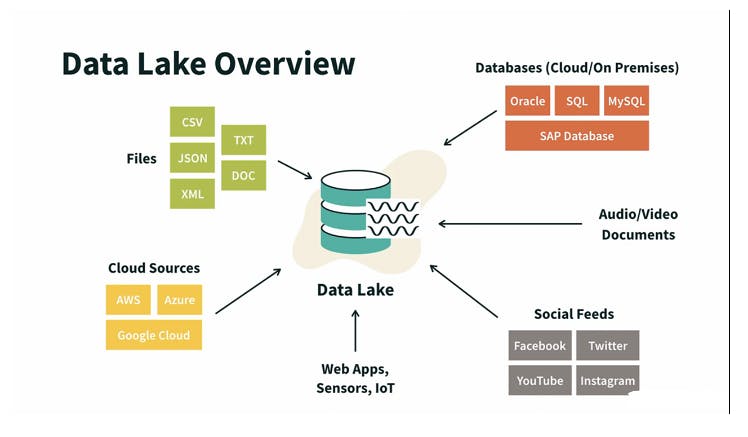
Data lake overview with the data being ingested from different sources.
Most ML teams misinterpret the role of data lakes and data warehouses, choosing an inappropriate management solution. Before delving into the rest of the article, let’s clarify how they differ.
Data Lake vs. Data Warehouse
Understanding the strengths and use cases of data lakes and warehouses can help your organization maximize its data assets. This can help create an efficient data infrastructure that supports various analytics, reporting, and ML needs.
Let’s compare a data lake to a data warehouse based on specific features.
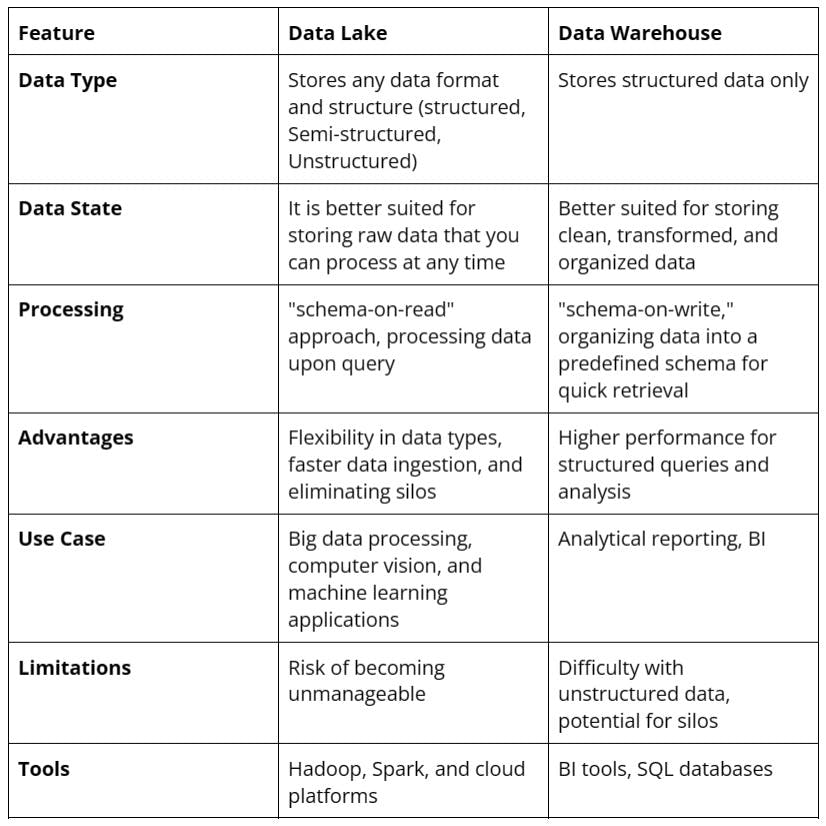
Choosing Between Data Lake and Data Warehouse
The choice between a data lake and a warehouse depends on the specific needs of the analysis. For an e-commerce organization analyzing structured sales data, a data warehouse offers the speed and efficiency required for such tasks.
However, a data lake (or a combination of both solutions) might be more appropriate for applications that require advanced computer vision (CV) techniques and large visual datasets (images, videos).
Benefits of a Data Lake
Data lakes offer myriad benefits to organizations using complex datasets for analytical insights, ML workloads, and operational efficiency. Here's an overview of the key benefits:
- Single Source of Truth: When you centralize data in data lakes, you get rid of data silos, which makes data more accessible across the whole organization. So, data lakes ensure that all the data in an organization is consistent and reliable by providing a single source of truth.
- Schema on Read: Unlike traditional databases that define data structure at write time (schema on write), data lakes allow the structure to be imposed at read time to offer flexibility in data analysis and utilization.
- Scalability and Cost-Effectiveness: Data lakes' cloud-based nature facilitates scalable storage solutions and computing resources, optimizing costs by reducing data duplication.
- Decoupling of Storage and Compute: Data lakes let different programs access the same data without being dependent on each other. This makes the system more flexible and helps it use its resources more efficiently.
Architectural Principles for Data Lake Design
When designing a data lake, consider these foundational principles:
- Decoupled Architecture: Data ingestion, processing, curation, and consumption should be independent to improve system resilience and adaptability.
- Tool Selection: Choose the appropriate tools and platforms based on data characteristics, ingestion, and processing requirements, avoiding a one-size-fits-all approach.
- Data Temperature Awareness: Classify data as hot (frequently accessed), warm (less frequently accessed), or cold (rarely accessed but retained for compliance) to optimize storage strategies and access patterns based on usage frequency.
- Leverage Managed Services: Use managed or serverless services to reduce operational overhead and focus on value-added activities.
- Immutability and Event Journaling: Design data lakes to be immutable, preserving historical data integrity and supporting comprehensive data analysis. They should also store and version the data labels.
- Cost-Conscious Design: Implement strategies (balancing performance, access needs, budget constraints) to manage and optimize costs without compromising data accessibility or functionality.
Data Lake Architecture
A robust data lake architecture is pivotal for harnessing the power of large datasets so organizations can store, process, and analyze them efficiently. This architecture typically comprises several layers dedicated to a specific function within the data management ecosystem. Below is an overview of these key components:
Data Sources
- Diverse Producers: Data lakes can ingest data from a myriad of sources, including, but not limited to, IoT devices, cameras, weblogs, social media, mobile apps, transactional databases (SQL, NoSQL), and external APIs. This inclusivity enables a holistic view of business operations and customer interactions.
- Multiple Formats: They accommodate a wide range of data formats, from structured data in CSVs and databases to unstructured data like videos, images, DICOM files, documents, and multimedia files, providing a unified repository for all organizational data. This, of course, does not exclude semi-structured data like XML and JSON files.
Data Ingestion
- Batch and Streaming: Data ingestion mechanisms in a data lake architecture support batch and real-time data flows. Use tools and services to auto-ingest the data so the system can effectively capture it.
- Validation and Metadata: Data is tagged with metadata during ingestion for easy retrieval, and initial validation checks are performed to ensure data quality and integrity.
Data Governance Zone
- Access Control and Auditing: Implementing robust access controls, encryption, and auditing capabilities ensures data security and privacy, crucial for maintaining trust and compliance.
- Metadata Management: Documenting data origins, formats, lineage, ownership, and usage history is central to governance. This component incorporates tools for managing metadata, which facilitates data discovery, lineage tracking, and cataloging, enhancing the usability and governance of the data lake.
Data Persistence and Staging
- Raw Data Storage: Data is initially stored in a staging area in raw, unprocessed form. This approach ensures that the original data is preserved for future processing needs and compliance requirements.
- Staging Area: Data may be staged or temporarily held in a dedicated area within the lake before processing. To efficiently handle the volume and variety of data, this area is built on scalable storage technologies, such as HDFS (Hadoop Distributed File System) or cloud-based storage services like Amazon S3.
Data Processing Layer
- Transformation and Enrichment: This layer transforms data into a more usable format, often involving data cleaning, enrichment, deduplication, anonymization, normalization, and aggregation processes. It also improves data quality and ensures reliability for downstream analysis.
- Processing Engines: To cater to various processing needs, the architecture should support multiple processing engines, such as Hadoop for batch processing, Spark for in-memory processing, and others for specific tasks like stream processing.
- Data Indexing: This component indexes processed data to facilitate faster search and retrieval. It is crucial for supporting efficient data exploration and curation.
Data Quality Monitoring
- Continuous Quality Checks: Implements automated processes for continuous monitoring of data quality, identifying issues like inconsistencies, duplications, or anomalies to maintain the accuracy, integrity, and reliability of the data lake.
- Quality Metrics and Alerts: Define and track data quality metrics, set up alert mechanisms for when data quality thresholds are breached, and enable proactive issue resolution.
Analytical Sandboxes
- Exploration and Experimentation: Computer vision engineers and data scientists can use analytical sandboxes to experiment with data sets, build models, and visually explore data (e.g., images, videos) and embeddings without impacting the integrity of the primary data (versioned data and labels).
- Tool Integration: These sandboxes support a wide range of analytics, data, and ML tools, giving users the flexibility and choice to work with their preferred technologies.
Data Consumption
- Access and Integration: Data stored in the data lake is accessible to various downstream applications and users, including BI tools, reporting systems, computer vision platforms, or custom applications. This accessibility ensures that insights from the data lake can drive decision-making across the organization.
- APIs and Data Services: For programmatic access, APIs and data services enable developers and applications to query and retrieve data from the data lake, integrating data-driven insights into business processes and applications.
Best Practices for Setting Up a Data Lake
Implementing a data lake requires careful consideration and adherence to best practices to be successful and sustainable. Here are some suggested best practices to help you set up a data lake that can grow with your organization’s changing and growing data needs:
#1. Define Clear Objectives and Scope
- Understand Your Data Needs: Before setting up a data lake, identify the types of data you plan to store, the insights you aim to derive, and the stakeholders who will consume this data. This understanding will guide your data lake's design, architecture, and governance model.
- Set Clear Objectives: Establish specific, measurable objectives for your data lake, such as improving data accessibility for analytics, supporting computer vision projects, or consolidating disparate data sources. These objectives will help prioritize features and guide decision-making throughout the setup process.
#2. Ensure Robust Data Governance
- Implement a Data Governance Framework: A strong governance framework is essential for maintaining data quality, managing access controls, and ensuring compliance with regulatory standards. This framework should include data ingestion, storage, management, and archival policies.
- Metadata Management: Cataloging data with metadata is crucial for making it discoverable (indexing, filtering, sorting) and understandable. Implement tools and processes to automatically capture metadata, including data source, tags, format, and access permissions, during ingestion or at rest.
#3. Focus on Scalability and Flexibility
- Choose Scalable Infrastructure: Whether on-premises or cloud-based, ensure your data lake infrastructure can scale to accommodate future data growth without significant rework or additional investment.
- Plan for Varied Data Types: Design your data lake to handle structured, semi-structured, and unstructured data. Flexibility in storing and processing different data types (images, videos, DICOM, blob files, etc.) ensures the data lake can support a wide range of use cases.
#4. Prioritize Security and Compliance
- Implement Strong Security Measures: Security is paramount for protecting sensitive data and maintaining user trust. Apply encryption in transit and at rest, manage access with role-based controls, and regularly audit data access and usage.
- Compliance and Data Privacy: Consider the legal and regulatory requirements relevant to your data. Incorporate compliance controls into your data lake's architecture and operations, including data retention policies and the right to be forgotten.
#5. Foster a Data-Driven Culture
- Encourage Collaboration: Promote collaboration between software engineers, CV engineers, data scientists, and analysts to ensure the data lake meets the diverse needs of its users. Regular feedback loops can help refine and enhance the data lake's utility.
- Education and Training: Invest in stakeholder training to maximize the data lake's value. Understanding how to use the data lake effectively can spur innovation and lead to new insights across the organization.
#6. Continuous Monitoring and Optimization
- Monitor Data Lake Health: Regularly monitor the data lake for performance, usage patterns, and data quality issues. This proactive approach can help identify and resolve problems before they impact users.
- Iterate and Optimize: Your organization's needs will evolve, and so will your data lake. Continuously assess its performance and utility, adjusting based on user feedback and changing business requirements.
Cloud-based Data Lake Platforms
Cloud-based data lake platforms offer scalable, flexible, and cost-effective solutions for storing and analyzing large amounts of data. These platforms provide Data Lake as a Service (DLaaS), which simplifies the setup and management of data lakes. This allows organizations to focus on deriving insights rather than infrastructure management.
Let's explore the architecture of data lake platforms provided by AWS, Azure, Snowflake, GCP, and their applications in multi-cloud environments.
AWS Data Lake Architecture
Amazon Web Services (AWS) provides a comprehensive and mature set of services to build a data lake. The core components include:
- Ingestion: AWS Glue for ETL processes and AWS Kinesis for real-time data streaming.
- Storage: Amazon S3 for scalable and secure data storage.
- Processing and Analysis: Amazon EMR is used for big data processing, AWS Glue for data preparation and loading, and Amazon Redshift for data warehousing.
- Consumption: Send your curated data to AWS SageMaker to run ML workloads or Amazon QuickSight to build visualizations, perform ad-hoc analysis, and quickly get business insights from data.
- Security and Governance: AWS Lake Formation automates the setup of a secure data lake, manages data access and permissions, and provides a centralized catalog for discovering and searching for data. As part of your ongoing security efforts, incorporate regular AWS pentests into your data lake management strategy. These assessments, when conducted by qualified security professionals, can help identify and mitigate potential threats, ensuring the continuous security and integrity of your valuable data assets.
Azure Data Lake Architecture
Azure's data lake architecture is centered around Azure Data Lake Storage (ADLS) Gen2, which combines the capabilities of Azure Blob Storage and ADLS Gen1. It offers large-scale data storage with a hierarchical namespace and a secure HDFS-compatible data lake.
- Ingestion: Azure Data Factory for ETL operations and Azure Event Hubs for real-time event processing.
- Storage: ADLS Gen2 for a highly scalable data lake foundation.
- Processing and Consumption: Azure Databricks for big data analytics running on Apache Spark, Azure Synapse Analytics for querying (SQL serverless) and analysis (Notebooks), and Azure HDInsight for Hadoop-based services. Power BI can connect to ADLS Gen2 directly to create interactive reports and dashboards.
- Security and Governance: Azure provides fine-grained access control with Azure Role-Based Access Control (RBAC) and secures data with Microsoft Entra ID.
Snowflake Data Lake Architecture
Snowflake's unique architecture separates compute and storage, allowing users to scale them independently. It offers a cloud-agnostic solution operating across AWS, Azure, and GCP.
- Ingestion: Within Snowflake, Snowpipe Streaming runs on top of Apache Kafka for real-time ingestion. Apache Kafka acts as the messaging broker between the source and Snowlake. You can run batch ingestion with Python scripts and the PUT command.
- Storage: Uses cloud provider's storage (S3, ADLS, or Google Cloud Storage) or internal (i.e., Snowflake) stages to store structured, unstructured, and semi-structured data in their native format.
- Processing and Curation: Snowflake's Virtual Warehouses provide dedicated compute resources for data processing for high performance and concurrency. Snowpark can implement business logic within existing programming languages.
- Data Sharing and Governance: Snowflake enables secure data sharing between Snowflake accounts with governance features for managing data access and security.
- Consumption: Snowflake provides native connectors for popular BI and data visualization tools, including Google Analytics and Looker. Snowflake Marketplace provides users access to a data marketplace to discover and access third-party data sets and services. Snowpark helps with features for end-to-end ML.
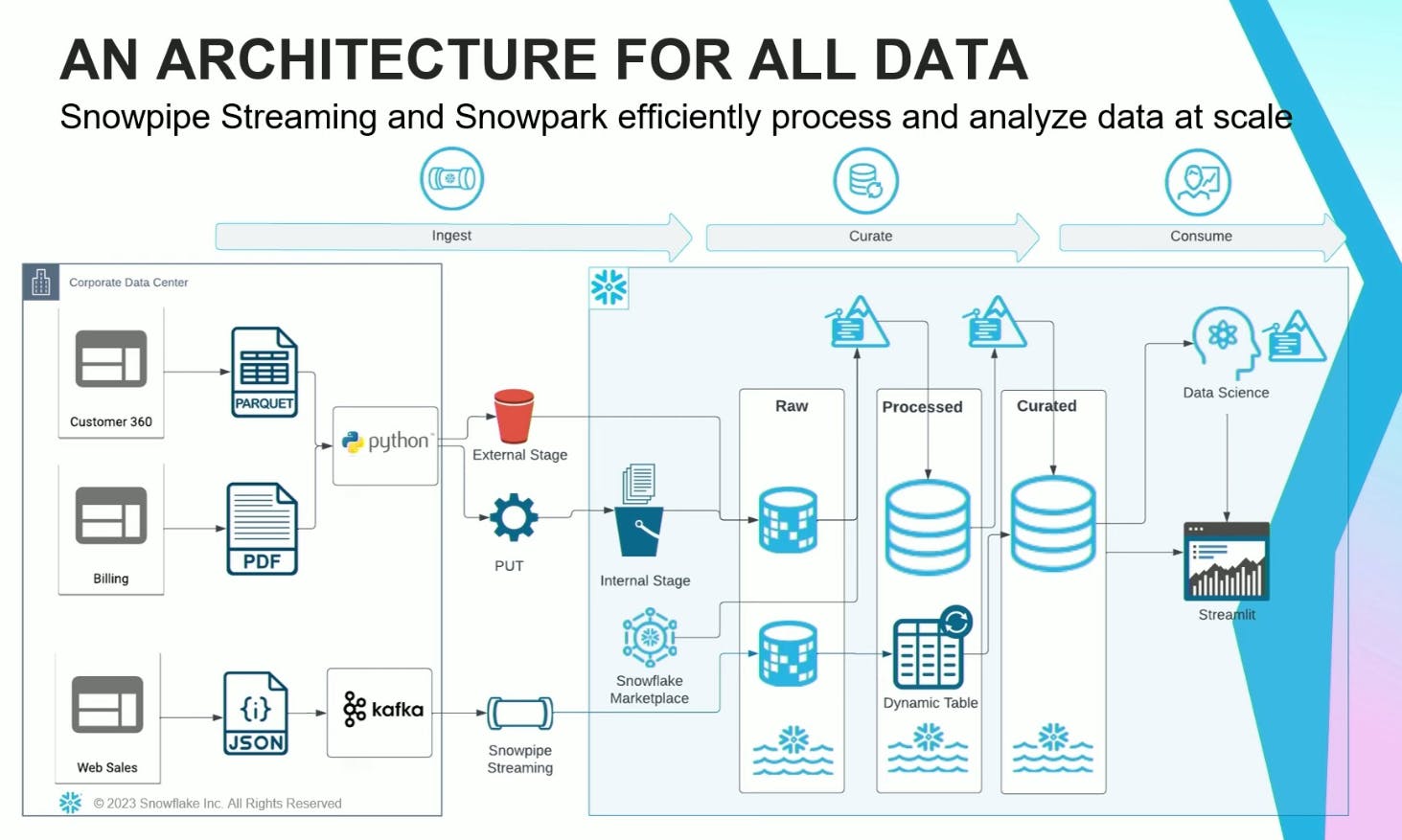
High-level architecture for running data lake workloads using Snowpark in Snowflake
Google Cloud Data Lake Architecture
In addition to various processing and analysis services, Google Cloud Platform (GCP) bases its data lake solutions on Google Cloud Storage (GCS), the primary data storage service.
- Ingestion: Cloud Pub/Sub for real-time messaging
- Storage: GCS offers durable and highly available object storage.
- Processing: Cloud Data Fusion offers pre-built transformations for batch and real-time processing, and Dataflow is for serverless stream and batch data processing.
- Consumption and Analysis: BigQuery provides serverless, highly scalable data analysis with an SQL-like interface. Dataproc runs Apache Hadoop and Spark jobs. Vertex AI provides machine learning capabilities to analyze and derive insights from lake data.
- Security and Governance: Cloud Identity and Access Management (IAM) controls resource access, and Cloud Data Loss Prevention (DLP) helps discover and protect sensitive data.
Data Lake Architecture on Multi-Cloud
Multi-cloud data lake architectures leverage services from multiple cloud providers, optimizing for performance, cost, and regulatory compliance. This approach often involves:
- Cloud-Agnostic Storage Solutions: Storing data in a manner accessible across cloud environments, either through multi-cloud storage services or by replicating data across cloud providers.
- Cross-Cloud Services Integration: This involves using best-of-breed services from different cloud providers for ingestion, processing, analysis, and governance, facilitated by data integration and orchestration tools.
- Unified Management and Governance: Implement multi-cloud management platforms to ensure consistent monitoring, security, and governance across cloud environments.
Implementing a multi-cloud data lake architecture requires careful planning and robust data management strategies to ensure seamless operation, data consistency, and compliance across cloud boundaries.
On-Premises Data Lakes and Cloud-based Data Lakes
Organizations looking to implement data lakes have two primary deployment models to consider: on-premises and cloud-based (although more recent approaches involve a hybrid of both solutions). Cost, scalability, security, and accessibility affect each model's advantages and disadvantages.
On-Premises Data Lakes: Advantages
- Control and Security: On-premises data lakes offer organizations complete control over their infrastructure, which can be crucial for industries with stringent regulatory and compliance requirements. This control also extends to data security, allowing organizations to tailor security measures, including cloud penetration testing, to their specific needs.
- Performance: With data stored locally, on-premises solutions can provide faster data access and processing speeds, which is beneficial for time-sensitive applications that require rapid data retrieval and analysis.
On-Premises Data Lakes: Challenges
- Cost and Scalability: Establishing an on-premises data lake requires a significant upfront investment in hardware and infrastructure. Scaling up can also require additional hardware purchases and be time-consuming.
- Maintenance: On-premises data lakes necessitate ongoing maintenance, including hardware upgrades, software updates, and security patches, which require dedicated IT staff and resources.
Cloud-based Data Lakes: Advantages
- Scalability and Flexibility: Cloud-based data lakes can change their storage and computing power based on changing data volumes and processing needs without changing hardware.
- Cost Efficiency: A pay-as-you-go pricing model allows organizations to avoid substantial upfront investments and only pay for their storage and computing resources, potentially reducing overall costs.
- Innovative Features: Cloud service providers always add new technologies and features to their services, giving businesses access to the most advanced data management and analytics tools.
Cloud-based Data Lakes: Challenges
- Data Security and Privacy: While cloud providers implement robust security measures, organizations may have concerns about storing sensitive data off-premises, particularly in industries with strict data sovereignty regulations.
- Dependence on Internet Connectivity: Access to cloud-based data lakes relies on stable internet connectivity. Any disruptions in connectivity can affect data access and processing, impacting operations.
Understanding these differences enables organizations to select the most appropriate data lake solution to support their data management strategy and business objectives.
Computer Vision Use Cases of Data Lakes
Data lakes are pivotal in powering computer vision applications across various industries by providing a scalable repository for storing and analyzing vast large image and video datasets in real-time. Here are some compelling use cases where data lakes improve computer vision applications:
Healthcare: Medical Imaging and Diagnosis
In healthcare, data lakes store vast collections of medical images (e.g., X-rays, MRIs, CT scans, PET) that, combined with data curation tools, can improve image quality, detect anomalies, and provide quantitative assessments. CV algorithms analyze these images in real time to diagnose diseases, monitor treatment progress, and plan surgeries.
Autonomous Vehicles: Navigation and Safety
Autonomous vehicle developers use data lakes to ingest and curate diverse datasets from vehicle sensors, including cameras, LiDAR, and radar. This data is crucial for training computer vision algorithms that enable autonomous driving capabilities, such as object detection, automated curb management, traffic sign recognition, and pedestrian tracking.
How Automotus increased mAP 20% by reducing their dataset size by 35% with visual data curation
Agriculture: Precision Farming
In the agricultural sector, data lakes store and curate visual data (images and videos) captured by drones or satellites over farmland. Computer vision techniques analyze this data to assess crop health, identify pest infestations, and evaluate water usage, so farmers can make informed decisions and apply treatments selectively.
Security and Surveillance: Threat Detection
Government and private security agencies use data lakes to compile video feeds from CCTV cameras in public spaces, airports, and critical infrastructure. Real-time analysis with computer vision helps detect suspicious activities, unattended objects, and unauthorized entries, triggering immediate responses to potential security threats.
ML Team's Data Lake Guide: Key Takeaways
Data lakes have become essential for scalable storage and processing of diverse data types in modern data management. They facilitate advanced analytics, including real-time applications like computer vision. Their ability to transform sectors ranging from finance to agriculture by enhancing operational efficiencies and providing actionable insights makes them invaluable.
As we look ahead:
- The continuous evolution of data lake architectures, especially within cloud-native and multi-cloud contexts, promises to bring forth advanced tools and services for improved data handling.
- This progression presents an opportunity for enterprises to transition from viewing data lakes merely as data repositories to leveraging them as strategic assets capable of building advanced CV applications.
- To maximize data lakes, address the problems associated with data governance, security, and quality. This will ensure that data remains a valuable organizational asset and a catalyst for data-driven decision-making and strategy formulation.
Frequently asked questions
Data lakes support vast data volumes and varieties (structured and unstructured), offering scalable storage and flexible schema-on-read capabilities.
The three layers are the storage, curation, and consumption layers.
Data governance in data lakes requires scalable access, quality, and metadata management policies.
Key considerations include assessing data migration costs, ensuring compatibility with cloud services, data security, and potential downtime during migration.
Choose a data lake based on your scalability needs, data diversity, processing requirements, security concerns, and integration capabilities with existing systems.
Data lakes integrate with existing tools through APIs, connectors, and data ingestion mechanisms, allowing seamless data flow and analytics.
Organizations ensure data security and compliance by implementing robust access controls, encryption, and adhering to industry-specific regulatory standards.
Encord provides a flexible platform designed to handle a wide range of annotation tasks across various satellite data types. Whether dealing with simple projects like field boundary detection or complex scenarios, Encord ensures efficient management of annotations tailored to the unique requirements of each project.
Encord provides a comprehensive platform designed for data curation and annotation specifically tailored for geospatial projects. This includes features that support effective labeling, ensuring data integrity, and facilitating easier model testing, which are crucial for teams focusing on geospatial AI applications.
Encord's annotation platform is designed to handle various data types and can support smart city applications by providing custom, high-quality annotations. The platform allows for efficient data labeling, including bounding box annotations, which are essential for training computer vision models in this field.
Encord seamlessly integrates with cloud storage systems, allowing you to stream collected data into the platform for various purposes. Once you've collected data and stored it in a cloud bucket, Encord can access that data for tasks such as dataset curation and annotation.
Encord enables precise measurements of vegetation distance from utility assets such as poles and towers, allowing utilities to maintain right-of-way standards. The platform supports various measurement needs, including the length of cross arms and spacing between assets.
Encord provides capabilities to visualize pre-annotation data alongside raw data, enabling users to verify, validate, and add comments on annotations. This feature supports the seamless integration of existing annotations with new data to enhance the annotation process.
Encord allows users to connect to different cloud storage buckets for data integration. By granting our service account permission to read and put objects in the bucket, the data can be streamed directly into the Encord UI, simplifying the data registration process.
Encord includes several efficiency tools to enhance the annotation workflow. Features like copy-pasting annotations and the merged point cloud view allow users to annotate with higher precision and speed, especially when dealing with static objects.
Encord supports various annotation types, including classification and segmentation, allowing users to configure their own labeling schema or ontology. This flexibility helps teams tailor their annotation processes to specific project needs.
Encord has collaborated with a diverse range of companies, including those in defense and geospatial surveillance sectors. This experience helps Encord understand and address unique challenges related to data annotation and management.