Top 10 Open Source Datasets for Machine Learning

Searching for a suitable dataset for your machine learning project can be time consuming.
As such, we have compiled a list of the top 10 open-source datasets spanning image recognition to natural language processing that will save you time and help you get started.
Whether you are a beginner or professional this diverse list of datasets will empower your machine learning advancements.
 💡To learn more read the Complete Guide to Open Source Data Annotation.
💡To learn more read the Complete Guide to Open Source Data Annotation. What are Open-Source Datasets?
Open-source datasets are publicly available datasets that are shared with no restrictions on usage or distribution. These datasets are typically released under open licenses, which allows researchers, developers, and enthusiasts to freely access, utilize, and contribute to the data. This fosters collaboration, innovation, and the advancement of research and development in fields such as machine learning, computer vision, and natural language processing.
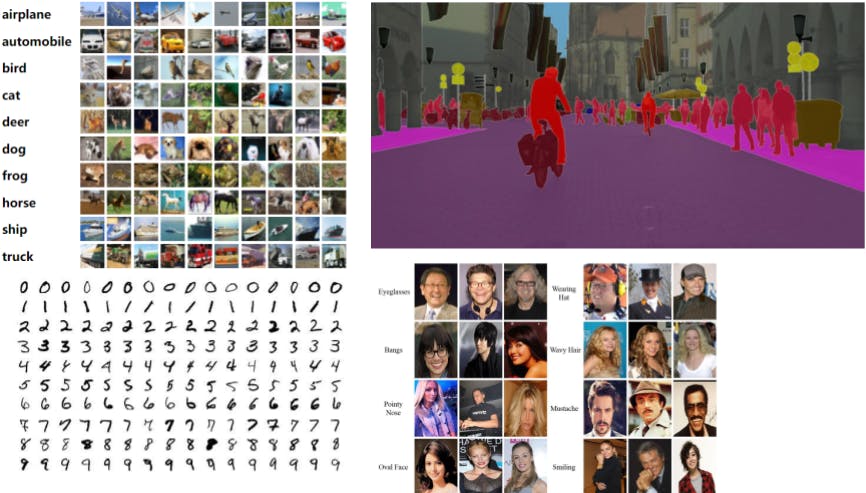
How do Machine Learning and Computer Vision Projects Benefit from Open-source Datasets?
Open-source datasets are valuable resources for machine learning and computer vision projects:
- Easy access to a vast amount of data without financial constraints
- Diverse samples for training robust and generalized models
- Standardized benchmarks for fair evaluations,
- Promotion of collaboration and reproducibility among researchers
- Encouragement of ethical considerations and community contributions
These benefits support researchers, expedite development, and foster creativity in the fields of machine learning and computer vision.

10 Open-Source Datasets for Machine Learning
SA-1B Dataset
SA-1B dataset consists of 11 million varied and high-resolution images along with 1.1 billion pixel-level annotations, making it suitable for training and evaluating advanced computer vision models.

This dataset was collected by Meta for their Segment Anything project and the images in the dataset are automatically generated by the Segment Anything Model (SAM). With the SA-1B dataset, researchers and developers can explore a wide range of applications in computer vision, including scene understanding, object recognition, instance segmentation, and image parsing. The dataset's rich annotations allow for detailed analysis and modeling of object boundaries, semantic regions, and fine-grained object attributes.
- Research Paper: Segment Anything
- Authors: Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
- Dataset Size: 11 million images, 1.1 billion masks, 1500*2250 image resolution
- License: Limited; Research purpose only
- Access Links: Official webpage
💡To learn more about the Segment Anything project, read our explainer post. VisualQA
The Visual Question Answering (VQA) dataset consists of 260,000 images that depict abstract scenes from COCO, multiple questions and answers per image, and an automatic evaluation metric, challenging machine learning models to comprehend images and answer open-ended questions by combining vision, language, and common knowledge.

This comprehensive dataset offers a wide range of applications, including image understanding, question generation, and multi-modal reasoning. With its large-scale and diverse nature, the VisualQA dataset provides a rich source of training and evaluation data for developing sophisticated AI algorithms. Researchers can leverage this dataset to enhance the capabilities of visual question-answering systems, allowing them to interpret images and accurately respond to human-generated questions.
- Research Paper: VQA: Visual Question Answering
- Authors: Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Dhruv Batra, Devi Parikh
- Dataset Size: 265,016 images
- License: CC By 4.0
- Access Links: Official webpage, Pytorch Dataset Loader
💡Read our explainer on ImageBIND, a new breakthrough for multimodal learning introduced by Meta. ADE20K
The ADE20K dataset provides over 20,000 diverse and densely annotated images which serves as a benchmark for developing computer vision models for semantic segmentation.

The dataset offers high-quality annotations and covers both object and stuff classes, providing a comprehensive representation of scenes. It was created by the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) and is available for research and non-commercial use. The significance of the ADE20K dataset lies in its capacity to drive research in scene understanding, object recognition, and image parsing, leading to advancements in computer vision techniques and benefiting diverse applications like autonomous driving, object detection, and image analysis.
- Research Paper: Scene Parsing Through ADE20K Dataset
- Authors: Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, Antonio Torralba
- Dataset Size: 25,574 training images, 2,000 validation images
- License: CC BSD-3 License Agreement
- Access Links: Official webpage, Pytorch Dataset,, Hugging Face
Youtube-8M
YouTube-8M is a large-scale video dataset containing 7 million YouTube videos annotated with a wide range of visual and audio labels for various machine learning tasks.

YouTube-8M is a valuable resource for machine learning tasks, allowing researchers and developers to train and assess models for video understanding, action recognition, video summarization, and visual feature extraction.
- Research Paper: YouTube-8M: A Large-Scale Video Classification Benchmark
- Authors: Sami Abu-El-Haija, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, Sudheendra Vijayanarasimhan
- Dataset Size: 7 million videos with 4716 classes
- License: CC By 4.0
- Access Links: Official webpage
Google’s Open Images
Google's Open Images is a publicly accessible dataset that provides 8 million labeled images, offering a valuable resource for various computer vision tasks and research.

Google's Open Images is used for various purposes such as object detection, image classification, and visual recognition. The dataset's importance lies in its comprehensive coverage and large-scale nature, enabling researchers and developers to train and evaluate advanced AI models.
- Research Paper: The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
- Authors: Alina Kuznetsova Hassan Rom Neil Alldrin Jasper Uijlings Ivan Krasin Jordi Pont-Tuset Shahab Kamali Stefan Popov Matteo Malloci Alexander Kolesnikov Tom Duerig Vittorio Ferrari
- Dataset Size: 8 million images
- License: CC By 4.0
- Access Links: Official webpage
MS COCO
MS COCO (Common Objects in Context) is a widely used large-scale dataset that contains 330,000 diverse images with rich annotations for tasks like object detection, segmentation, and captioning.

MS COCO (Common Objects in Context) is specifically designed for object detection, segmentation, and captioning tasks, offering detailed annotations for a wide range of objects in various real-world contexts. The dataset has become a benchmark for evaluating and advancing state-of-the-art models in visual understanding and has played a significant role in driving progress in the field of computer vision.
- Research Paper: Microsoft COCO: Common Objects in Context
- Authors: Tsung-Yi Lin Michael Maire Serge Belongie Lubomir Bourdev Ross Girshick James Hays Pietro Perona Deva Ramanan C. Lawrence Zitnick Piotr Dollar
- Dataset Size: 330,000 images, 1.5 million object instances, 80 object categories, and 91 stuff categories
- License: CC By 4.0
- Access Links: Official webpage, PyTorch, TensorFlow
CT Medical Images
The CT Medical Image dataset is a small sample extracted from the cancer imaging archive, comprised of the middle slice of CT images that meet specific criteria regarding age, modality, and contrast tags.

The dataset is designed to train models to recognize image textures, statistical patterns, and highly correlated features associated with these characteristics. This can enable the development of straightforward tools for automatically classifying misclassified images and identifying outliers that may indicate suspicious cases, inaccurate measurements, or inadequately calibrated machines.
- Research Paper: The Cancer Genome Atlas Lung Adenocarcinoma Collection
- Authors: Justin Kirby
- Dataset Size: 475 series of images collected from 69 unique patients.
- License: CC By 3.0
- Access Links: Kaggle
💡To find more healthcare datasets, read Top 10 Free Healthcare Datasets for Computer Vision. Aff-Wild
The Aff-Wild dataset consists of 564 videos of around 2.8 million frames with 554 subjects and is designed for the task of emotion recognition using facial images.

Aff-Wild provides a diverse collection of facial images captured under various conditions, including different head poses, illumination conditions, and occlusions. The dataset serves as a valuable resource for developing and evaluating algorithms and models for emotion recognition, gesture recognition, and action unit detection in computer vision.
- Research Paper: Deep Affect Prediction in-the-wild: Aff-Wild Database and Challenge, Deep Architectures, and Beyond
- Author: Dimitrios Kollias, Panagiotis Tzirakis, Mihalis A. Nicolaou, Athanasios Papaioannouk, Guoying Zhao, Bjorn Schuller, Irene Kotsia, Stefanos Zafeiriou
- Dataset Size: 564 videos of around 2.8 million frames with 554 subjects (326 of which are male and 228 female)
- License: non-commercial research purposes
- Access Links: Official Webpage
DensePose-COCO
DensePose-COCO consists of 50,000 images with dense human pose estimation annotations for each person in the COCO dataset, enabling a detailed understanding of the human body's pose and shape.

DensePose-COCO is an extension of the COCO dataset that provides dense human pose annotations, allowing precise mapping of body landmarks and segmentation. It serves as a benchmark for pose estimation and shapes understanding in computer vision research.
- Research Paper: DensePose: Dense Human Pose Estimation In The Wild
- Authors: Rıza Alp Guler, Natalia Neverova, Iasonas Kokkinos
- Dataset Size: 50,000 images from the COCO dataset, with annotations for more than 200,000 human instances
- License: CC By 4.0
- Access Links: Official Webpage
💡To find more, read Top 8 Free Datasets for Human Pose Estimation in Computer Vision,. BDD100K
The BDD100K dataset is a large-scale diverse driving video dataset that contains over 100,000 videos.

The BDD100K dataset is a valuable asset for advancing autonomous driving research, computer vision algorithms, and robotics. It plays a crucial role in improving perception systems and facilitating the development of intelligent transportation systems. With its diverse and comprehensive annotations, BDD100K is utilized for various computer vision tasks, including object detection, instance segmentation, and scene understanding, empowering researchers and developers to push the boundaries of computer vision technology in autonomous driving and transportation.
- Research Paper: BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning
- Authors: Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, Trevor Darrell
- Dataset Size: Over 100,000 driving videos (40 seconds each) collected from more than 50,000 rides, covering New York, San Francisco Bay Area
- License: Mixed license
- Access Links: Official Webpage
Use Open-Source Datasets for Computer Vision Projects with Encord
Encord enables easy one-command downloads of these open-source datasets and provides the flexibility to explore, analyze, and curate datasets tailored to your project's specific requirements. By utilizing the platform, you will streamline your data collection process and enhance the efficiency and effectiveness of your machine learning workflows.
To use open-source datasets in the Encord platform, simply follow these steps:
- Download the open-source dataset through the access links listed above
- Download Encord Active using the following commands. For more information, refer to the documentation.
python3.9 -m venv ea-venv source ea-venv/bin/activate # within venv pip install encord-active
- Download your open-source dataset using the following commands.
# within venv encord-active download
With those simple steps, you now have your dataset!
With Encord, you can accelerate the image and video labeling process of your machine learning project while also facilitating the analysis of your models.
Encord annotate empowers annotators with a diverse set of annotation types tailored for various computer vision applications. Meanwhile, Encord Active equips machine learning practitioners with a comprehensive toolset for data analysis, labeling, and assessing model quality.
Sign-up for a free trial of Encord: The Data Engine for AI Model Development, used by the world’s pioneering computer vision teams.
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Frequently asked questions
Encord's platform is designed to support the integration of multiple data types, including images and point cloud data from LiDAR sensors. This capability allows users to create comprehensive datasets that can enhance the performance of machine learning models by providing diverse inputs for training and evaluation.
Encord provides robust tools for data curation and annotation, specifically designed to streamline the process of preparing datasets for machine learning applications. This includes features that allow teams to efficiently label and organize data, ensuring high-quality inputs for model training.
Encord excels in providing comprehensive annotation capabilities that go beyond basic labeling. It allows for advanced evaluations and supports various machine learning workflows, ensuring that models are not only trained effectively but also validated through robust annotation processes.
Encord provides extensive support for organizations unfamiliar with data annotation processes. Our solutions engineers work closely with customers to ensure they understand the platform and can leverage its capabilities effectively, helping to maximize the value derived from their data.
Encord provides a robust infrastructure tailored for machine learning model training. This includes utilizing Databricks and Spark for data engineering, ensuring that the data pipeline is optimized for the demands of training advanced models, such as visual language action models.
Encord provides an all-in-one platform for ML data operations, addressing the needs of growing teams by offering tools for data curation, model evaluation, and annotation. This comprehensive solution helps streamline workflows and manage the complexities of scaling AI projects.
Encord is designed to handle large datasets effectively, accommodating significant data growth. While some platforms may offer enterprise licenses, Encord focuses on robust collaboration features, ensuring that teams can work seamlessly together as their dataset expands.
Yes, Encord is compatible with companies that utilize open-source machine learning models. The platform can help streamline the data preparation and annotation process, enhancing productivity while integrating with existing machine learning workflows.
Yes, Encord supports the creation of comprehensive data annotation pipelines specifically designed for crowd-sourced projects. The platform ensures a user-friendly interface to help teams manage their annotation tasks efficiently.
Encord provides comprehensive tools for data curation and annotation, enabling teams to efficiently organize and label large datasets, which is crucial for developing accurate machine learning models.