Slicing Aided Hyper Inference (SAHI) for Small Object Detection | Explained

Small object detection in surveillance applications poses a significant challenge. The small and distant objects are often represented by a minimal number of pixels in an image and therefore lack the necessary details for high detection accuracy using conventional detectors.
Slicing Aided Hyper Inference (SAHI) is an open-source framework that was designed to address this issue. SAHI provides a generic pipeline for small object detection, including inference and fine-tuning capabilities.

Slicing Aided Hyper Inference (SAHI) detects small objects. Source
Before we dive into the details of Slicing Aided Hyper Inference (SAHI), let’s discuss object detection models and small object detection.

Small Object Detection
Small object detection is a subfield of computer vision and object detection that focuses on the task of detecting and localizing objects that are relatively small in size in an image or video.

Example of small objects from the xView dataset.
Applications of Small Object Detection
There are various applications of small object detection:
Surveillance and Security
In surveillance systems, small object detection is vital for identifying and tracking people, vehicles, suspicious packages, and other small objects in crowded areas or from a distance. This capability helps enhance security by enabling early threat detection and prevention.
Autonomous Driving
In autonomous vehicles, small object detection is essential for identifying and tracking pedestrians, cyclists, traffic signs, and other small objects on the road. This object detection is vital to ensuring the safety of both passengers and pedestrians.

Example from BDD100K dataset.
Robotics
Small object detection is used to enable robots to interact with and manipulate small objects in their environment, allowing them to grasp, pick, and place these small objects, thereby facilitating tasks like assembly, sorting, and object manipulation.
Medical Imaging
In the field of medical imaging, small object detection plays a crucial role in detecting and localizing abnormalities, tumors, lesions, or small structures within organs. This capability aids in early diagnosis, monitoring of disease progression, and treatment planning
Wildlife Conservation
Small object detection supports the monitoring and tracking of endangered species (including birds, insects, and marine creatures) enabling researchers and conservationists to collect data on population sizes, migration patterns, and habitat preferences.
Retail and Inventory Management
In retail settings, small object detection can be utilized for inventory management and shelf monitoring. This capability enables automated tracking of individual products, ensuring stock accuracy, and assisting in replenishment.
Quality Control and Manufacturing
Small object detection help identify defects or anomalies in manufacturing processes, including the detection of tiny scratches, cracks, or imperfections in products. By automating inspection tasks, small object detection enhances quality control and minimizes human error.
Aerial and Satellite Imagery
Small object detection is valuable in analyzing aerial or satellite imagery as it assists in the monitoring of small features like buildings, vehicles, and infrastructure. The capability also supports the detection of environmental changes for urban planning, disaster response, and environmental research.

Example of aerial detection from xView dataset.
Limitations of Traditional Object Detectors in Small Object Detection
Popular object detection models (such as Faster RCNN, YOLOv5, and SSD) are trained on a wide range of object categories and annotations. However, these object detectors often struggle with small object detection accuracy.
Let’s dive into potential reasons for the shortcomings of traditional object detectors:
Limited Receptive Field
The receptive field of a neuron or filter in a convolutional neural network (CNN) refers to the area of the input image that impacts its output. In traditional object detectors, the receptive field may be restricted, especially in the initial layers. As a result, there is insufficient contextual information for small objects, hindering the network's detection accuracy.
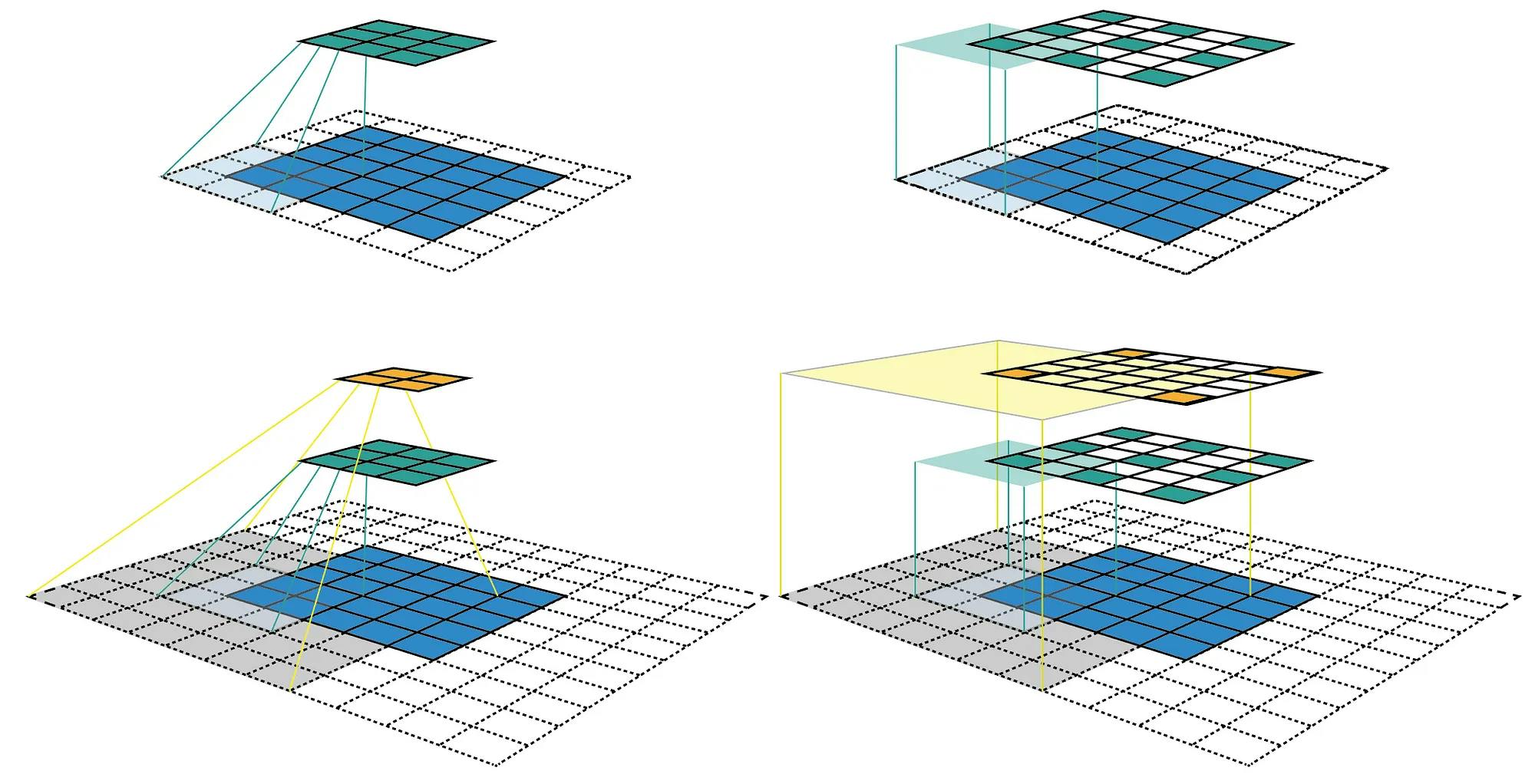
Receptive fields in convolutional neural networks. Source
Limited Spatial Resolution
Small objects typically occupy a limited number of pixels, leading to reduced spatial resolution in the image. Low resolution poses a challenge for traditional detectors that struggle to capture the intricate details and distinctive features required for the precise detection of small objects. The inadequate spatial resolution of small objects coupled with their limited receptive field, makes accurate detection and localization challenging.
Limited Contextual Information
Small objects may also lack the contextual information that traditional object detection models typically rely on. The limited spatial extent of small objects makes it difficult to capture sufficient contextual information, leading to increased false positives and lower detection accuracy.
 Note: Most pre-trained object detectors are trained on COCO, with an average dimension of 640x480 and a focus on large objects. This limits their effectiveness in detecting small objects directly, but SAHI provides a solution to overcome this limitation.
Note: Most pre-trained object detectors are trained on COCO, with an average dimension of 640x480 and a focus on large objects. This limits their effectiveness in detecting small objects directly, but SAHI provides a solution to overcome this limitation.
Class Imbalance
Object detection models may also exhibit a bias towards larger objects if trained on imbalanced datasets, in which the occurrence of small objects is significantly less frequent than that of larger objects. This bias can lead to a disproportionate emphasis on detecting and prioritizing larger objects, diminishing the detection performance of small objects. As a result, the limited representation of small objects in the training data may hinder the ability of traditional detectors to effectively identify and localize them in real-world scenarios.
💡 Read more about balanced vs imbalance datasets in Introduction to Balanced and Imbalanced Datasets in Machine Learning and find out 9 ways to balance your computer vision dataset. Existing Approaches for Small Object Detection
There are several techniques that assist with the detection of small objects in computer vision. Let’s take a look at the approaches used to overcome the limitations of traditional object detection models with poor detection accuracy:
Feature Pyramid Networks (FPN)
FPNs aim to capture multi-scale information by constructing feature pyramids with different resolutions. The FPN architecture consists of a bottom-up pathway that captures features at different resolutions and a top-down pathway that fuses and upsamples the feature maps to form a pyramid structure. This enables the network to aggregate context from coarser levels while preserving fine-grained information from lower resolutions, leading to an improved understanding of small object characteristics.
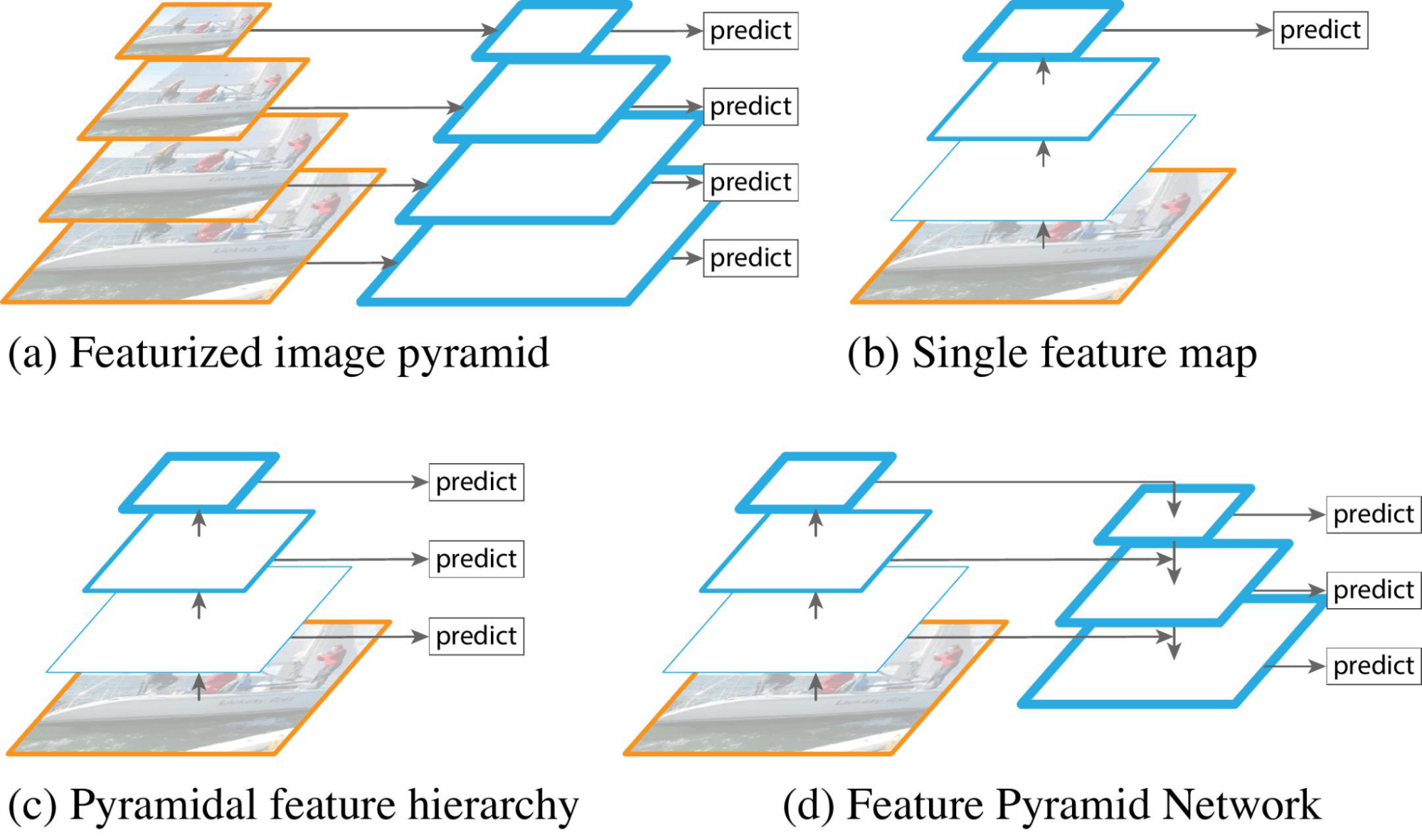
Illustration showing pyramid networks: (a) feature image pyramid, (b) single feature map, (c) pyramidal feature hierarchy, (d) feature pyramid network. Source
This approach overcomes the limitations of traditional object detection models with fixed receptive fields, as it enables the network to adaptively adjust its focus and leverage contextual information across various object sizes, significantly enhancing the performance of small object detection.
Sliding Window
The sliding window approach is a common technique employed for object detection, including small object detection. In this method, a fixed window, often square or rectangular, is moved systematically across the entire image at different locations and scales. At each position, the window is evaluated using a classifier or a similarity measure to determine if an object is present. For small object detection, the sliding window approach can be used with smaller window sizes and strides to capture finer details. Considering multiple scales and positions is necessary to enhance the chances of accurate detection.

Object detection using a sliding window.
The sliding window approach is computationally expensive, however, as it requires evaluation of the classifier or similarity measure at numerous window positions and scales. In small object detection, this drawback is exacerbated. Further, handling scale variations and aspect ratios of small objects efficiently can pose challenges for sliding window methods.
Single Shot MultiBox Detector (SSD)
Single shot multibox detector (SSD) is a popular object detection algorithm that performs real-time object detection by predicting object bounding boxes and class probabilities directly from convolutional feature maps.
In SSD, feature maps from different layers with varying receptive fields are used to detect objects at multiple scales. This multi-scale approach enables the detector to effectively capture the diverse range of small object sizes present in the image. By utilizing feature maps from multiple layers, SSD can effectively capture fine-grained details in earlier layers while also leveraging high-level semantic information from deeper layers, enhancing its ability to detect and localize small objects with greater accuracy.
💡 Learn more about single shot detection in What is One-Shot Learning in Computer Vision. Transfer Learning
Transfer learning is a valuable technique for small object detection, in which pre-trained models trained on large-scale datasets are adapted for the detection of small objects. By fine-tuning these models on datasets specific to the task, the pre-trained models can leverage their learned visual features and representations to better understand and detect small objects. Transfer learning addresses the limited data problem and reduces computational requirements by utilizing pre-existing knowledge, enabling efficient and accurate detection of small objects.
Data Augmentation
Data augmentation is another technique used to enhance small object detection. The data is augmented using various transformation techniques like random scaling, flipping, rotation, and cropping introducing variations in the appearance, scale, and context of small objects.
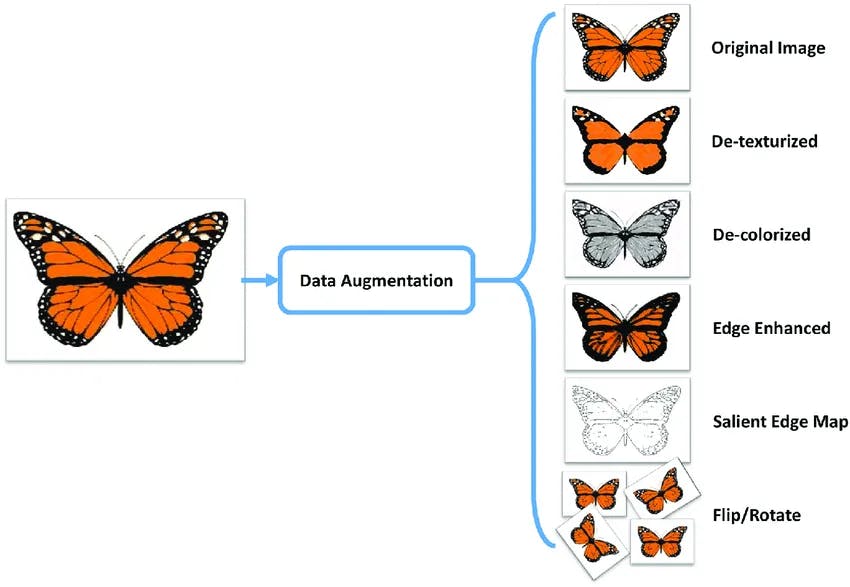
Example of augmentation. Source
Data augmentation helps the network generalize better and improves its robustness to different object sizes and orientations during inference. By exposing the model to augmented samples, it becomes more adept at handling the challenges posed by small objects, leading to improved detection performance in real-world scenarios.
💡 Read The Full Guide to Data Augmentation in Computer Vision for deeper insight. Slicing Aided Hyper Inference (SAHI)
SAHI is an innovative pipeline tailored for small object detection, leveraging slicing aided inference and fine-tuning techniques to revolutionize the detection process.
💡 Read the initial paper here. 
Slicing Aided Hyper Inference (SAHI) on Coral Reef. Source
SAHI Framework
SAHI addresses the small object detection limitations with a generic framework based on slicing in the fine-tuning and inference stages. By dividing the input images into overlapping patches, SAHI ensures that small objects have relatively larger pixel areas, enhancing their visibility within the network.
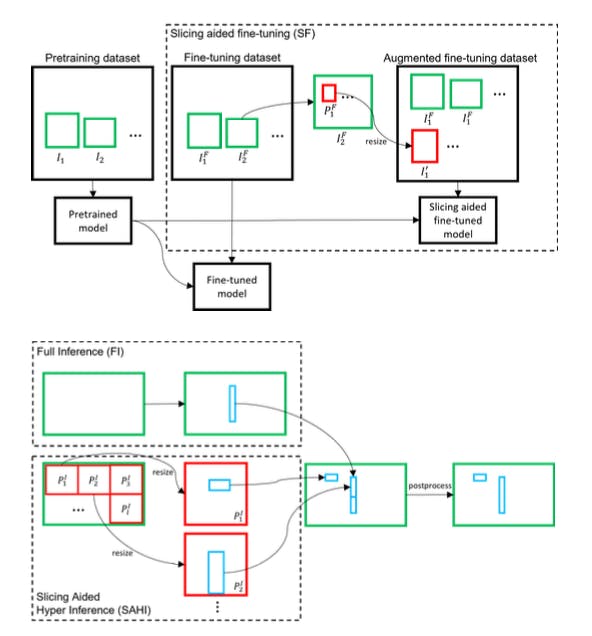
The overall framework of SAHI. Source
SAHI: Slicing Aided Fine Tuning
Slicing aided fine-tuning is a novel approach that augments the fine-tuning dataset by extracting patched from the original images. Widely used pre-training datasets like MS COCO and ImageNet primarily consist of low-resolution images (640 X 480) where larger objects dominate the scene, leading to limitations in small object detection for high-resolution images captured by advanced drones and surveillance cameras. To address this challenge, a novel approach is proposed to augment the fine-tuning dataset by extracting patches from the original images.
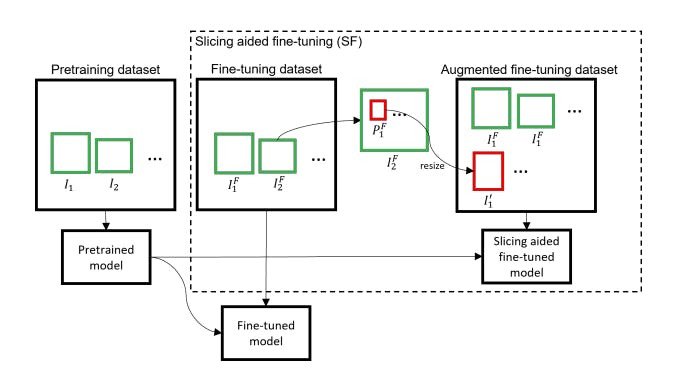
The proposed framework of slicing aided fine-tuning. Source
By dividing the high-resolution images into overlapping patches, the proposed slicing-aided fine-tuning technique ensures that small objects have relatively larger pixel areas within the patches. This augmentation strategy provides a more balanced representation of small objects, overcoming the bias towards larger objects in the original pre-training datasets.
The patches containing small objects are then used to fine-tune the pre-trained models, allowing them to better adapt and specialize in small object detection. This approach significantly improves the performance of the models in accurately localizing and recognizing small objects in high-resolution images, making them more suitable for applications such as drone-based surveillance and aerial monitoring.
SAHI: Slicing Aided Hyper Inference
Slicing-aided hyper inference is an effective technique employed during the inference step for object detection. The process begins by dividing the original query image into overlapping patches of size M × N. Each patch is then resized while maintaining the aspect ratio, and an independent object detection forward pass is applied to each patch. This allows for the detection of objects within the individual patches, capturing fine-grained details and improving the overall detection performance.
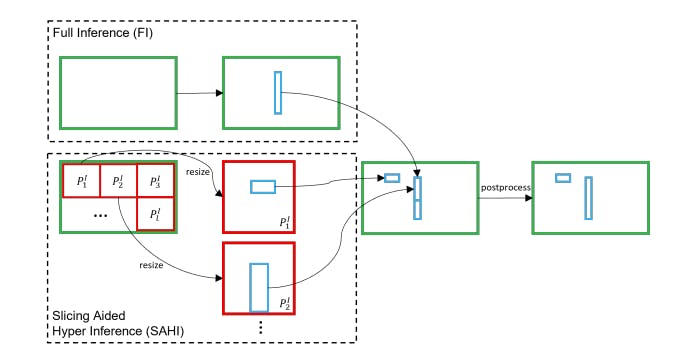
The framework of slicing aided hyper inference integrated with the detector. Source
In addition to the patch-wise inference, an optional full-inference step can be performed on the original image to detect larger objects. After obtaining the prediction results from both the overlapping patches and the full-inference step, a merging process is conducted using Non-Maximum Suppression (NMS). During NMS, boxes with Intersection over Union (IoU) ratios higher than a predefined matching threshold are considered matches. For each match, results with detection probabilities below a threshold are discarded, ensuring that only the most confident and non-overlapping detections are retained. This merging and filtering process consolidates the detection results from the patches and the full image, providing comprehensive and accurate object detection outputs.
💡 You can find SAHI on GitHub. Results: Slicing Aided Hyper Inference (SAHI)
SAHI's performance is assessed by incorporating the proposed techniques into three detectors: FCOS, VarifocalNet (VFNET), and TOOD, using the MMDetection framework. The evaluation utilizes datasets like VisDrone2019-Detection and xView, which consist of small objects (object width < 1% of image width). The evaluation follows the MS COCO protocol, including AP50 scores for overall and size-wise analysis.
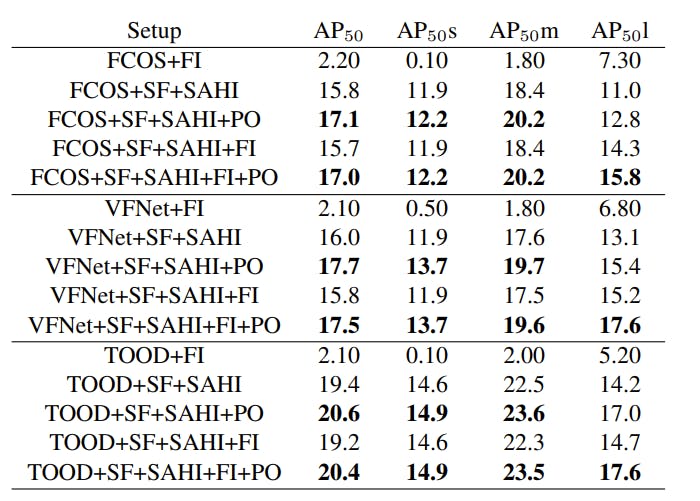
Mean average precision values calculated on xView validation split. SF = slicing aided fine-tuning, SAHI = slicing aided hyper inference, FI = full image inference, and PO = overlapping patches. Source
Note: One striking thing in the above table is that there is almost no performance result without SAHI for small objects (AP50s)! SAHI significantly improves object detection performance, increasing the average precision (AP) by 6.8%, 5.1%, and 5.3% for FCOS, VFNet, and TOOD detectors, respectively. By applying slicing-aided fine-tuning (SF), the cumulative AP gains reach an impressive 12.7%, 13.4%, and 14.5% for FCOS, VFNet, and TOOD detectors. Implementing a 25% overlap between slices during inference enhances the AP for small and medium objects as well as overall AP, with a minor decline in large object AP
SAHI, Slicing Aided Hyper Inference: Key Takeaways
- SAHI (Slicing Aided Hyper Inference) is a cutting-edge framework designed for small object detection, addressing the challenges posed by limited receptive fields, spatial resolution, contextual information, and class imbalance in traditional object detectors.
- SAHI utilizes slicing-aided fine-tuning to balance the representation of small objects in pre-training datasets, enabling models to better detect and localize small objects in high-resolution images.
- Slicing-aided fine-tuning augments the dataset by extracting patches from the images and resizing them to a larger size.
- During slicing aided hyper inference, the image is divided into smaller patches, and predictions are generated from larger resized versions of these patches and then converted back into the original image coordinated after NMS.
- SAHI can directly be integrated into any object detection inference pipeline and does not require pre-training.
SAHI, Slicing Aided Hyper Inference: Frequently Asked Questions
What is Small Object Detection?
Small object detection is a subfield of computer vision and object detection that focuses on the task of detecting and localizing objects that are relatively small in size in an image or video.
What is SAHI, Slicing Aided Hyper Inference?
SAHI (Slicing Aided Hyper Inference) is an open-source framework designed for small object detection. It introduces a pipeline that leverages slicing aided inference and fine-tuning techniques to improve the detection accuracy of small objects in images.
Does SAHI improve small object detection?
SAHI divides images into overlapping patches and utilizes patch-wise inference. This enhances the visibility and recognition of small objects, revolutionizing the way objects are detected in computer vision applications.
Recommended Reading
- Object Detection: Models, Use Cases, Examples
- YOLO models for Object Detection Explained [YOLOv8 Updated]
- 5 Ways to Reduce Bias in Computer Vision Datasets
- The Full Guide to Training Datasets for Machine Learning
- Object Detection: Models, Use Cases, Examples
- What is One-Shot Learning in Computer Vision
- 39 Computer Vision Terms You Should Know
- The Complete Guide to Image Annotation for Computer Vision
- How to Improve Datasets for Computer Vision
Sign-up for a free trial of Encord: The Data Engine for AI Model Development, used by the world’s pioneering computer vision teams.
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Frequently asked questions
Encord offers advanced segmentation capabilities that allow users to annotate one slice and apply that annotation to subsequent slices. This feature significantly reduces the manual workload associated with multi-slice data, streamlining the annotation process and improving overall efficiency.
Yes, Encord is designed to support the transition from bulk annotations to focused corner case annotations. The platform can help teams manage the shift towards utilizing pseudo-annotation pipelines while also accommodating specific needs for high-quality corner case annotations.
Yes, Encord supports model-aided annotation by allowing users to overlay predictions with ground truths, which helps in evaluating model performance post-deployment. This feature provides insights into what works and where improvements are needed in the annotation process.
Encord provides a comprehensive platform for managing the entire data pipeline, from curation and annotation to evaluation. This includes identifying edge cases to enhance model performance across various domains, including visual and text models.