Top Computer Vision Models: Comparing the Best CV Models

Computer vision (CV) is driving today’s artificial intelligence (AI) advancements, enabling businesses to innovate in areas like healthcare and space.
According to a McKinsey report, CV ranks second among all other AI-based solutions based on the number of applications it serves. Its rapid growth is a testament to the significant value it generates for organizations in the current era.
However, with many frameworks emerging to address specific use cases, selecting the most suitable CV model for your needs can be challenging. If an ideal match is unavailable, you may need to build a custom model tailored to your requirements.
In this post, we will go over state-of-the-art (SOTA) CV models across various applications and learn how you can use Encord to create your own CV solutions.
Computer Vision Tasks
As CV models advance, their range of tasks continues to expand. However, experts mainly classify CV tasks into three common categories: image classification, object detection, and various forms of segmentation.
Image Classification
Image classification assigns a predefined category or label to an input image. The goal is to determine the primary object or scene within the image. Applications include medical imaging, facial recognition, and content tagging.

Algorithms like convolutional neural networks (CNNs) and transformers are common frameworks for achieving high accuracy in classification tasks.
Object Detection
Object detection identifies and localizes multiple objects within an image by drawing bounding boxes around them and classifying each detected object. It combines aspects of image classification and localization.

Widely used detection models include You-Only-Look-Once (YOLO) and Faster R-CNN. They enable real-time object detection and allow experts to use them in autonomous driving, video surveillance, and retail inventory management systems.
Image Segmentation
Segmentation is more complex than plain classification and detection. It divides an image into meaningful regions and assigns a label to each pixel. The task includes three types: semantic, instance, and panoptic segmentation.

Semantic vs. Instance vs. Panoptic Segmentation
- Semantic Segmentation: Assigns a class to each pixel and distinguishes between different regions in an image. It optimizes image processing in tasks like autonomous driving and medical image analysis.
- Instance Segmentation: Identifies and separates individual object instances within an image while assigning them a class. For example, an image can have multiple cats, and instance segmentation will identify each cat as a separate entity.
- Panoptic Segmentation: Unifies semantic and instance segmentation and assigns every pixel to either a specific object instance or a background class. It helps achieve efficiency in complex real-world visual tasks like robotics and augmented reality (AR).
Computer Vision Applications
Businesses commonly use CV deep learning models to automate operations and boost productivity. Below are examples of industries that leverage machine learning (ML) pipelines to optimize functions demanding high visual accuracy.
Manufacturing
Manufacturers use CV models for quality control, predictive maintenance, and warehouse automation. These models detect product defects, monitor assembly lines, and help create smart factories with autonomous robots for performing tedious tasks.
Advanced CV systems can identify missing components, ensure consistency in production, and enhance safety. Additionally, they enable manufacturers to optimize maintenance schedules and extend equipment lifespan.
Healthcare
CV assists in diagnostics, treatment planning, and patient monitoring in healthcare. Applications include analyzing medical images like X-rays, MRIs, and CT scans to detect abnormalities like tumors or fractures.
Additionally, CV enables real-time monitoring of a patient’s vital signs and supports robotic-assisted surgeries for precision and improved outcomes.
Transportation
As highlighted earlier, CV models form the backbone of modern autonomous vehicles, traffic management, and safety enforcement. CV systems detect objects, lanes, and pedestrians in autonomous driving. They ensure precise and safe navigation.
Moreover, CV facilitates real-time traffic monitoring, optimizes flow, and identifies violations like speeding. It enables authorities to manage urban transportation infrastructure more cost-effectively.
Agriculture
CV models enhance crop management, pest detection, and yield estimation in agriculture. Drones equipped with CV systems monitor field conditions. They pinpoint areas that need immediate attention.
The models also analyze plant health, detect diseases, and optimize irrigation. The techniques help in precision agriculture. The result is less resource waste, higher productivity, and more sustainable farming practices.
Top Computer Vision Models: A Comparison
The research community continually advances AI models for greater accuracy in CV tasks. In this section, we will categorize and compare various state-of-the-art (SOTA) frameworks based on the tasks outlined earlier.
Image Classification Models
CoCa
The Contrastive Captioner (CoCa) is a pre-trained model that integrates contrastive and generative learning. It combines contrastive loss to align image and text embeddings with a captioning loss to predict text tokens.
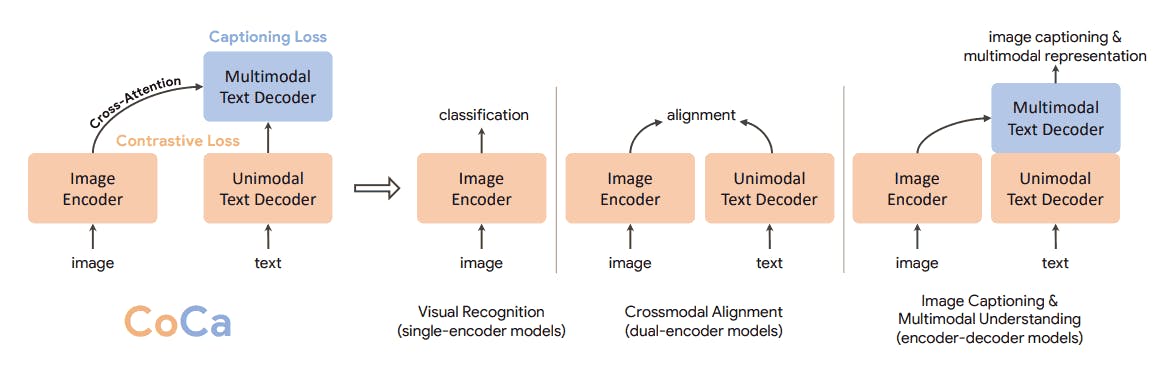
The technique generates high performance across diverse tasks, including image classification, cross-modal retrieval, and image captioning. It also demonstrates exceptional adaptability with minimal task-specific fine-tuning.
PaLI
The PaLI (Pathways Language and Image) model unifies language and vision modeling to perform multimodal tasks in multiple languages.

It uses a 4-billion-parameter vision transformer (ViT), multiple large language models (LLMs), and an extensive multilingual image-text dataset for training.
The data consists of 10B images and text in over 100 languages. PaLI achieves SOTA results in captioning, visual question-answering, and scene-text understanding.
CoAtNet-7
CoAtNet is a hybrid network combining convolutional and attention layers to balance generalization and model capacity. It leverages convolution's inductive biases for generalization and attention's scalability for large datasets.

Researchers merge convolutional and attention layers with relative attention and stack them to produce SOTA accuracy on ImageNet benchmarks. The framework offers superior efficiency, scalability, and convergence across varied data sizes and computational resources.
DaViT
DaViT (Dual Attention Vision Transformers) introduces a novel architecture combining spatial and channel self-attention to balance global context capture and computational efficiency.

The architecture utilizes spatial and channel tokens to define the token scope and feature dimensions. The two self-attention tokens produce detailed global and spatial interactions.
It achieves SOTA performance on ImageNet-1K, with top-1 accuracy of up to 90.4%. Researchers show the framework to be scalable across diverse tasks with different model sizes.
FixEfficientNet
FixEfficientNet enhances EfficientNet classifiers by addressing train-test discrepancies and employing updated training procedures. The FixEfficientNet-B0 variant reaches 79.3% top-1 accuracy on ImageNet using 5.3M parameters.

Basic EfficientNet Architecture
In contrast, FixEfficientNet-L2, trained on 300M unlabeled images with weak supervision, achieves 88.5% accuracy. The results show greater efficiency and robustness across benchmarks like ImageNet-v2 and Real Labels.
| Model | Top 1 Accuracy on ImageNet |
| CoCa | 91 |
| PaLI | 90.9 |
| CoAtNet-7 | 90.88 |
| DaViT | 90.4 |
| FixEfficientNet | 88.5 |
Object Detection Models
Co-DETR
Co-DETR introduces a collaborative hybrid assignment scheme to enhance Detection Transformer (DETR)-based object detectors. It improves encoder and decoder training with auxiliary heads using one-to-many label assignments.

The approach boosts detection accuracy and uses less GPU memory due to faster training. It achieves SOTA performance, including 66.0% AP on COCO test-dev and 67.9% AP on LVIS val.
InternImage
InternImage is a large-scale CNN-based foundation model leveraging deformable convolution for adaptive spatial aggregation and a large, effective receptive field.

The architecture decreases the inductive bias in legacy CNNs and increases the model’s ability to learn more robust patterns from extensive visual data. It achieves 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K.
Focal-Stable-DINO
Focal-Stable-DINO is a robust and reproducible object detector combining the powerful FocalNet-Huge backbone and the Stable-DETR with Improved deNoising anchOr boxes (DINO) detector.

The Stable-DINO detector solves the issue of multi-optimization paths by addressing the matching stability problem in several decoder layers.
With FocalNet-Huge as the backbone, the framework achieves 64.8 AP on COCO test-dev without complex testing techniques like test time augmentation. The model’s simplicity makes it ideal for further research and adaptability in object detection.
EVA
EVA is a vision-centric foundation model designed to push the limits of visual representation at scale using public data. Experts pre-train the model on NVIDIA A100-SXM4-40GB using PyTorch-based code.

The pretraining task is to reconstruct image-text visual features using visible image patches. The framework excels in natural language processing (NLP) and enhances multimodal models like CLIP with efficient scaling and robust transfer learning.
YOLOv7
YOLOv7 introduces a new SOTA real-time object detector, achieving optimal speed and accuracy trade-offs. It uses extended bag-of-freebies techniques, model scaling, and an innovative planned re-parameterized convolution.

The re-parameterization removes the identity connections in RepConv to increase gradient diversity for multiple feature maps. YOLOv7 outperforms previous YOLO models, such as YOLOv5, and achieves 56.8% AP on COCO with efficient inference.
| Model | Box Mean Average Precision (mAP) on COCO test-dev |
| Co-Detr | 66.0 |
| InternImage | 65.4 |
| Focal-Stable-DINO | 64.8 |
| EVA | 64.7 |
| YOLOv7 | 56.6 |
Image Segmentation
The sections below categorize segmentation models based on the semantic, instance, and panoptic segmentation tasks.
Semantic Segmentation
ONE-PEACE
ONE-PEACE is a 4B-parameter scalable model designed for seamless integration across vision, audio, and language modalities. Its flexible architecture combines modality adapters and a Transformer-based modality fusion encoder.

Experts pre-trained the framework with modality-agnostic tasks for alignment and fine-grained feature learning. The approach allows ONE-PEACE to achieve SOTA performance across diverse uni-modal and multimodal tasks, including semantic segmentation.
Mask2Former
Mask2Former is a versatile image segmentation model unifying panoptic, instance, and semantic segmentation tasks. It uses masked attention to extract localized features within predicted mask regions.

It also uses multi-scale high-resolution features with other optimizations, including changing the order of cross and self-attention and eliminating dropouts. Mask2Former outperforms specialized architectures, setting new SOTA benchmarks on COCO and ADE20K for segmentation tasks.
| Model | Validation mean Intersection over Union (mIoU) scores on ADE20K |
| ONE-PEACE | 63 |
| Mask2Former | 57.7 |
Instance Segmentation
Mask Frozen-DETR
Mask Frozen-DETR is an efficient instance segmentation framework that transforms DETR-based object detectors into robust segmenters. The method trains a lightweight mask network on the outputs of the frozen DETR-based object detector.

The objective is to predict the instance masks in the output’s bounding boxes. The technique allows the model to outperform Mask DINO on the COCO benchmark. The framework also reduces training time and GPU requirements by over 10x.
DiffusionInst-SwinL
DiffusionInst is a novel instance segmentation framework using diffusion models. It treats instances as instance-aware filters and formulates segmentation as a denoising process.

Diffusion Approach for Segmentation
The model achieves competitive performance on COCO and LVIS, outperforming traditional methods. It operates efficiently without region proposal network (RPN) inductive bias and supports various backbones such as ResNet and Swin transformers.
| Model | Mask AP on COCO Test-dev |
| Mask Frozen-DETR | 55.3 |
| DiffusionInst-SwinL | 48.3 |
Panoptic Segmentation
PanOptic SegFormer
Panoptic SegFormer is a transformer-based framework for panoptic segmentation. It features an efficient mask decoder, query decoupling strategy, and improved post-processing.

It efficiently handles multi-scale features and outperforms baseline DETR models by incorporating Deformable DETR. The framework achieves SOTA results with 56.2% Panoptic Quality (PQ) on COCO test-dev.
K-Net
K-Net is a unified framework for semantic, instance, and panoptic segmentation. It uses learnable kernels to generate masks for instances and stuff classes.

K-Net surpasses SOTA results in panoptic and semantic segmentation with a dynamic kernel update strategy. Users can train the model end-to-end with bipartite matching.
| Model | PQ metric on COCO Test-dev |
| Panoptic SegFormer | 56.2 |
| K-Net | 55.2 |
Challenges of Building Computer Vision Models
The different models listed above might create the impression that developing CV systems is straightforward. However, training and testing CV frameworks come with numerous challenges in practice. Below are some common issues developers often encounter when building CV systems.
- Data Quality and Quantity: High-quality and diverse datasets are essential for training accuracy. Insufficient or biased data can lead to poor generalization and unreliable predictions. Also, labeling data is labor-intensive and expensive, especially for complex tasks like object detection and segmentation.
- Model Complexity: CV models often comprise deep neural networks with millions of parameters. Optimizing such models demands substantial expertise, computational resources, and time. Complex architectures also risk overfitting, making it challenging to balance performance and generalization.
- Ethical Concerns: Ethical issues such as data privacy, bias, and misuse of CV technologies pose significant challenges. Models trained on biased datasets can perpetuate societal inequities. Improper use in surveillance or sensitive applications also raises concerns about fairness and accountability.
- Scalability: Deploying CV solutions at scale requires addressing computational and infrastructural constraints. Models must handle diverse real-world conditions, process data in real-time, and be adaptable to new tasks without requiring significant retraining.
Encord for Building Robust Computer Vision Models
Developers can tackle the above mentioned challenges by using specialized tools to streamline model training, validation, and deployment. While numerous open-source tools are available, they often lack the advanced functionality needed for modern, complex applications.
Modern applications require more comprehensive third-party solutions with advanced features to address use-case-specific scenarios. Encord is one such solution.
Encord is a data development platform for managing, curating and annotating large-scale multimodal AI data such as image, video, audio, document, text and DICOM files. Transform petabytes of unstructured data into high quality data for training, fine-tuning, and aligning AI models, fast.
Let’s explore how Encord’s features address the challenges discussed earlier.
Key Features
- Managing Data Quality and Quantity: Encord lets you manage extensive multimodal datasets, including text, audio, images, and videos, in a customizable interface. It also allows you to integrate SOTA models in your data workflows to automate reviews, annotation, and classification tasks.
- Addressing Model Complexity: With Encord Active, you can assess data and model quality using comprehensive performance metrics. The platform’s Python SDK can also help build custom monitoring pipelines and integrate them with Active to get alerts and adjust models according to changing environments.
- Mitigating Ethical Concerns: The platform adheres to globally recognized regulatory frameworks, such as the General Data Protection Regulation (GDPR), System and Organization Controls 2 (SOC 2 Type 1), AICPA SOC, and Health Insurance Portability and Accountability Act (HIPAA) standards. It also ensures data privacy using robust encryption protocols.
- Increasing Scalability: Encord can help you scale CV models by ingesting extensive multimodal datasets. For instance, the platform allows you to upload up to 10,000 data units at a time as a single dataset. You can create multiple datasets to manage larger projects and upload up to 200,000 frames per video at a time.
G2 Review
Encord has a rating of 4.8/5 based on 60 reviews. Users highlight the tool’s simplicity, intuitive interface, and several annotation options as its most significant benefits.
However, they suggest a few areas for improvement, including more customization options for tool settings and faster model-assisted labeling.
Overall, Encord’s ease of setup and quick return on investments make it popular among AI experts.
Computer Vision Models: Key Takeaways
The models discussed in this section represent just the tip of the iceberg. CV models will evolve exponentially as computational capabilities grow, unlocking new possibilities and opportunities.
Below are a few key points to remember regarding CV frameworks:
- Best CV Models: The best SOTA models include CoCa for classification, Co-Detr for detection, ONE-PEACE for semantic segmentation, Mask Frozen-DETR for instance segmentation, and Panoptic SegFormer for panoptic segmentation.
- CV Model Challenges: Building robust CV models requires managing data quality and quantity, model complexity, ethical concerns, and scalability issues.
- Encord for CV: Encord’s data curation and annotation features can help users develop large-scale CV models for complex real-world applications.
Frequently asked questions
Computer vision (CV) is a field of AI that enables computers to interpret and process visual data, such as images and videos.
Vision Transformers (ViTs), YOLO (You Only Look Once) series, Mask R-CNN, and EfficientNet are a few models with high-performance benchmarks in diverse CV tasks.
The top detection frameworks are co-DETR, InternImage, Focal-Stable-DINO, EVA, and YOLO.
Challenges include ensuring high-quality and sufficient data, managing model complexity, addressing ethical concerns, and achieving scalability in deployment.
Leading computer vision platforms include Encord, Labelbox, and SuperAnnotate.
Encord supports users in training models by offering tools for data labeling and management. Users can easily label data, manage large datasets, and target specific edge cases that are crucial for model accuracy. This streamlined process helps ensure that the models being trained are based on high-quality, relevant data.
Training data is crucial for enhancing the performance of Encord's computer vision models. High-quality, high-resolution images serve as the foundation for the model's ability to recognize and differentiate between similar-looking products, ultimately leading to better accuracy and reliability in product detection.
Encord provides an end-to-end data ops platform specifically designed for building machine learning models, particularly in computer vision. It streamlines the process of selecting datasets and annotating them, allowing users to efficiently prepare training data while integrating with existing workflows.
Encord allows for the implementation of various customizable and robust workflows, including model-in-the-loop workflows. This feature enables users to integrate advanced machine learning models into their annotation processes, enhancing the efficiency and effectiveness of data labeling.
Encord provides powerful tools for dataset creation, enabling users to label and curate video data effectively. With features designed for tracking models and person re-identification, users can create datasets from short clips of video, focusing on relevant interactions and behaviors.
Absolutely, Encord can be utilized for both image and video data, allowing teams to extract valuable information from various sources. This flexibility helps in generating a more diverse dataset, which is crucial for training robust machine learning models in sports analytics.
Encord facilitates fine-tuning by providing customers with the option to use the latest models out-of-the-box, while also allowing for customization through hyperparameter adjustments and the integration of additional features to meet specific project requirements.
Encord offers robust model evaluation capabilities that enable teams to visually explore changes in video data over time. This includes the ability to plot metrics and identify unusual or significant moments, facilitating a deeper analysis of model performance.
Encord is model-agnostic, meaning it can integrate with any machine learning model. Users can upload predictions from their models and utilize Encord's capabilities to evaluate performance and analyze results, facilitating better insights into model efficacy.